数据驱动的公众科学实践:基于社会公平视角的考察
2024-07-01张双志刘华锦
张双志 刘华锦

摘 要 公众科学作为一种数据驱动的开放科学实践正在蓬勃发展,但现有文献对公众科学所折射出的社会公平问题关注较少,这不利于包容性开放科学运动的推进。为了弥合这一差距,文章基于社会公平和数据价值链构建分析框架,对涉及医疗健康、环境保护、社会治理等议题的公众科学项目进行案例研究。案例分析结果表明,公众科学在分配、程序、过程和结果公平方面存在诸多挑战,这需要系统弥合数据从收集、存储、分析到使用全链条上的公平缺口,以确保形成更加公平的数据驱动的公众科学,促使科学更好地服务社会大众。
关键词 公众科学;数据驱动;社会公平;数据价值链
分类号 G315
DOI 10.16810/j.cnki.1672-514X.2024.05.002
Data-Driven Citizen Science Practice: an Examination From the Perspective of Social Equity
Zhang Shuangzhi, Liu Huajin
Abstract Citizen science is a data-driven open science practice that is thriving, but existing literature pays less attention to the social equity issues reflected by citizen science, which is not conducive to the promotion of the inclusive open science movement. In order to bridge this gap, this article constructs an analytical framework based on social equity and data value chain, and conducts case studies on citizen science projects related to issues such as healthcare, environmental protection, and urban governance. Research has found that citizen science faces many challenges in terms of fairness in distribution, procedures, processes, and outcomes, this requires a system to bridge the equity gap in the entire chain of data collection, storage, analysis, and use, in order to ensure the promotion of more fair data-driven citizen science and better serve the public.
Keywords Citizen science. Data driven. Social equity. Data value chain.
0 引言
从19世纪中叶到20世纪末的气象分析、鸟类统计等研究活动中公众参与科学已初见端倪,到1989年出版的《技术评论》(Technological Review)杂志上,科学共同体正式采用“公众科学”(Citizen Science)这一术语。特别是1992年康奈尔大学“公众参与的鸟类学”项目正式获得美国国家自然科学基金(NSF)的资助立项,公众科学由此正式确立并进入学界视野[1],与之相关的研究文献也不断涌现。传统意义上的公众科学主要是让公众协助科学家收集数据或进行一些简单的数据分析,类似于“数据众包”(Data Crowdsourcing)[2]。但这明显低估了公众的集体创造潜力,他们其实可以参与科学研究的任何方面,这包括从数据收集、存储、分析到结果使用的全过程[3]。公众主要以智力形式,或以智力周边的知识、工具、资源等方式参与科学技术研究、科学社会学、科学传播和环境正义等领域[4]。公众科学常常表现为“对话”或“参与”模式,公众、科学家、政策制定者等利益相关者均可从中获益。
随着大数据、云计算、人工智能等新一代信息技术的迅猛发展,公众参与科学的形式日益数字化、网络化和智能化,公众科学在全球的应用场景不再局限于自然科学研究,在医疗健康[5]、环境保护[6]、社会治理[7]等领域出现了大量应用案例,这意味着公众生活的许多方面都可以转化为研究数据。新一代信息技术不仅广泛影响着公众、科学家和政策制定者,也深刻改变了科学研究范式。但现有文献大都强调了公众科学在改变研究物质条件上具有意想不到的潜力[8-9],例如“SETI@home”的参与者为项目组累计贡献了价值10亿美元的数据计算时间及1012瓦时的电力资源[10]。公众大规模参与科学在促进知识共同生产的同时,也使公众的利益诉求在科学家专属的知识领域中得到不同形式和程度的体现,而这些非专业参与者的观点在知识历史上长期处于边缘化境地。但鲜有研究涉及讨论公众科学对公众、科学家和政策制定者潜在的社会公平效益,这为本文重新审视公众科学的社会公平议题留下了研究空间。
数字时代的公众科学作为一种数据驱动的实践,模糊了科学家和公众之间的界限,将前者纳入社会和政治议程,并允许后者以前所未有的方式和难以想象的规模收集和共享数据,这当然也带来了一些有趣且空前的挑战。对公众来说,在提升数据可信度的同时,也要确保他们收集的数据不被用于损害其利益的政策议程;对科学家来说,数字时代的公众科学将他们卷入了一个本可以避免的政治和社会争论之中;对政策制定者来说,以公众利益为核心的数据被允许参与公共治理领域的辩论,这有可能为公众支持的非专业政策论点提供证据支撑,在一定程度上侵蚀了官方的权威性。简言之,负责收集数据的公众与处理数据的科学家在需求和价值观之间存在诸多矛盾,这给政策制定者的决策带来了困惑。为此,本文基于社会公平和数据价值链的二维分析框架,对嵌入数据中的社会技术组合进行系统梳理,以揭示数据驱动的公众科学实践中社会公平的具体表征、面临的挑战及可能的因应对策,为塑造更加公平的公众科学提供数据治理领域的学理思考。
1 开放科学环境下公众科学及其面临的治理议题
公众科学在历史上主要应用于自然研究领域,例如候鸟物种计数、生物野外监测、业余天文学等。随着公众在知识生产中的独特作用日益凸显,公众科学在医疗健康、政策制定、研究改进等方面也有着较为深入的应用。在医疗健康方面,Open Humans[11]、PatientsLikeMe[12]等平台允许志愿者上传、连接和存储来自各种来源的个人健康数据(例如,基因测试数据、存储在社交媒体上的数据等),志愿者可以选择将这些数据公开或授权用于特定项目的科学研究。在政策制定方面,公众科学本身也是一种科学社会运动,公众在参与科学研究的过程中既会加深对相关议题的认识,也会通过研究成果对相关政策的制定产生影响。例如,马里兰大学的“社区参与、环境公正与健康”(CEEJH)实验室,通过实施公众科学项目促使决策者和公众在环境保护议题上的协商共治[13]。在研究改进方面,公众科学对研究过程的改善主要表现在增加获取研究资金的渠道、创新研究方法和同行评议机制、以众包形式共同出版研究成果等。例如,青年学者及女性学者在寻求传统研究资金来源时有时可能会处于不利地位,但他(她)们却是公众科学研究资金资助最多的群体[14],这无疑会对现有的研究格局带来一些积极的影响。
近年来,新一代信息技术的迅猛发展在很大程度上改变了公众参与科学的方式,为知识的共同生产带来新的可能性[15]。信息技术打破了知识共同生产中客观存在的组织壁垒,从而有效降低大规模公众参与知识生产的成本,并在此过程中重塑公众与大学、政府及产业之间的结构关系[16]。组织壁垒的消解有助于催生开源社区的同行生产、维基百科的分布式生产等去中心化的知识共同生产模式,并在信息技术的支持下实现相关数据在平台上的互联互通,从而推动公众参与知识生产模式的数智化转型。知识共同生产的数字化演变也对公众科学项目中用于数据分析的方法提出了更高的要求,例如通过机器学习识别和筛选“现实世界”(与实验室环境相反)中数据收集通常存在的背景噪音[17],从而提升了数据分析结果的可信度。欧盟委员会资助的“参与式可持续环境城市生活”(PULSE)项目就通过智能手机、可穿戴传感器、物联网等设备实现多维度数据集成,为公众在城市移动时实时提供与环境污染相关的公共健康风险资讯[18]。虽然这本身并非没有风险,大数据、人工智能、云计算等技术的介入却会降低公众参与科学研究的贡献度,从而削弱公众科学的参与范围、行动力度与实施效果[19],由此面对开放科学环境下的公众科学面临着治理议题。
公众科学作为开放科学的一个突出应用领域,鲜明体现了Science2.0时代的开放性和协作性。那么,依据公众参与能力、方式和程度的不同,将公众科学项目划分为咨询型、协作型和改革型[4],也有研究文献将其区分为科学商店模式、参与式行动研究模式与自适应研究模式[20]。近年来,信息技术的加持使得公众科学领域也出现了诸多新的变化,例如在平台建设、研究方法、成果应用、志愿者招募和维持等方面都有所创新。在研究边界议题上,公众科学通常被解释得相当宽泛,甚至被误用或包装为一些没有研究成果的众包活动,这明显损害了公众科学的可信度[21],因此需要对其内涵和边界达成共识;在公众参与议题上,如何构建一条完整的“参与链”,促使公众全程参与科学研究的任何环节,而不仅是让公众协助完成数据收集或简单的分析任务;在数据质量议题上,确保数据的高质量是关乎公众科学研究成果是否可信的核心[22],需要在数据隐私、安全和知情权、数据集成、数据确权、数据共享等方面达成统一的数据管理规则[23];在伦理道德议题上,警惕某些项目通过众包的运行方式无偿或以较低酬劳占据公众的知识成果[24],这可能会使公众面临过度工作、增加经济负担、易受骚扰等风险。
虽然公众科学是一项有其历史根源的科学事业,不同时期开展公众科学所面临的挑战也比较相似。但数字技术的引入之后公众科学发生了重大改变,即数字技术正通过公众科学重塑公众、科学家和政策制定者之间的社会互动关系。深受大数据的影响,科学研究已经迈入数据驱动时代(The Data-Driven Era)[25],公众科学也正式成为科学事业的一个重要组成部分,这一实践变革为数字时代的公众科学创造了诸多新兴研究领域。其中,从社会公平视角探讨公众科学的数据治理,对深入推进开放科学的包容性发展是一个至关重要的议题。鉴于此,本文构建了社会公平与数据价值链的二维分析框架,采用案例研究方法厘清公众科学与社会公平之间的互动耦合机理,在一定程度上丰富了现有的公众科学研究内容。
2 社会公平与数据价值链的二维分析框架
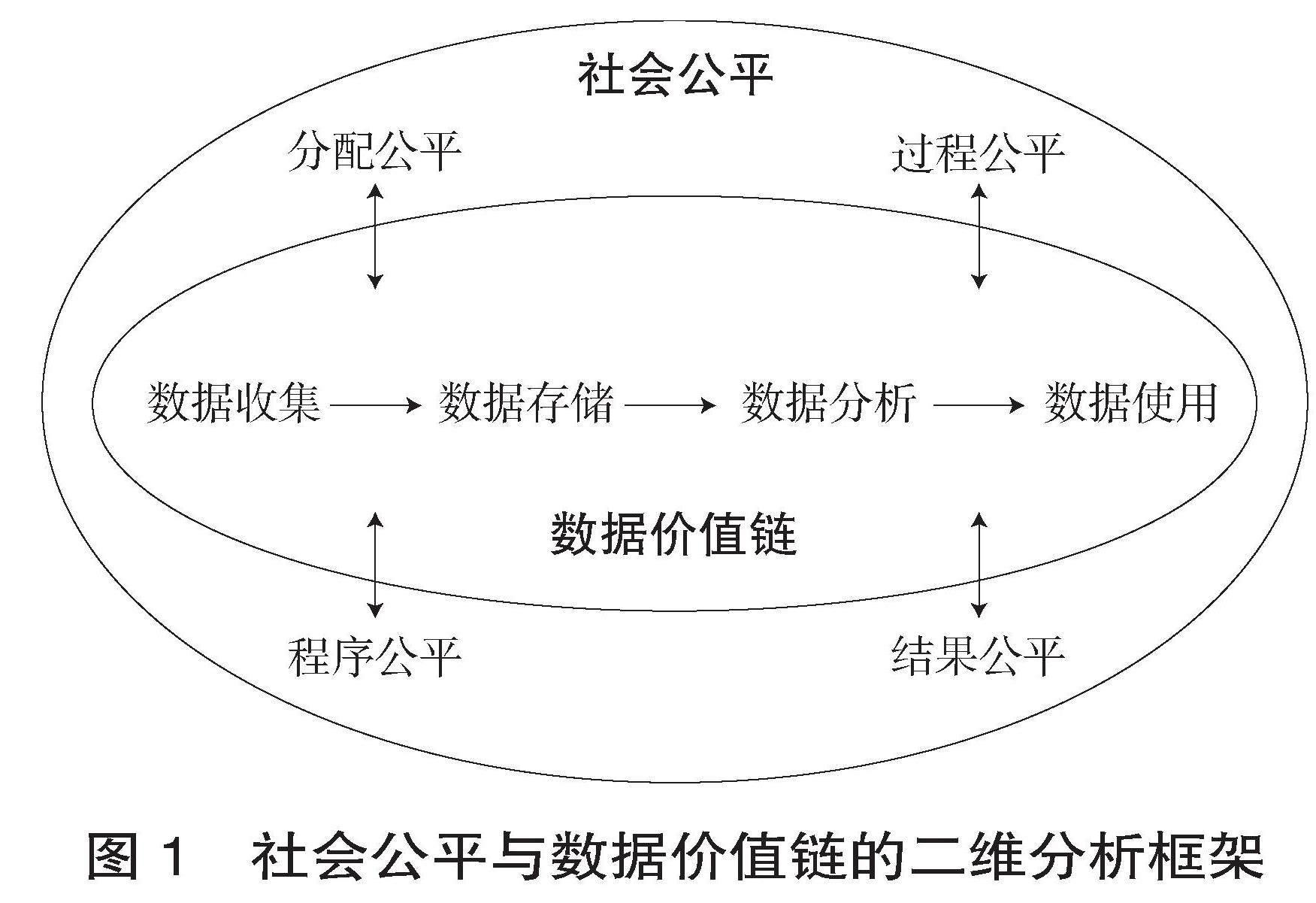
探讨公众科学如何影响社会公平,应致力于回答以下两个问题:一是数据驱动的公众科学实践对社会公平产生哪些影响,二是数据驱动的公众科学实践是如何影响社会公平的。为了解决这些问题,本文基于社会公平和数据价值链两个维度构建了分析框架,如图1所示。
2.1 社会公平
虽然公众科学在数据驱动型科学研究中具有降低成本、提高效率等好处,但越来越依赖数据驱动的公众科学可能会对社会公平产生侵蚀。因为公众收集的数据在某种程度上反映了当前经济社会发展的差异性,假如政府依据这些带有偏差的数据制定政策或提供公共服务,有可能会使弱势群体处于更加不利的地位。这里引入Johnson和Svara的“社会公平”(Social Equity)理论[26],从分配公平、程序公平、过程公平和结果公平四个维度去深入理解公众科学所关涉的社会公平。分配公平,指为社会地位、文化价值观等差异显著的个人或群体公平分配与数据相关的资源,与机会准入、资源获取有关;程序公平是基于权利的数据公平,包括数据访问权、数据所有权、数据隐私权、数据代表权等基本的数据权利;过程公平关注质量,指向不同个人或群体提供的基于数据驱动的知识服务质量是否具有一致性;结果公平是工具性数据公平,指数据使用的结果是否对所涉及的个人或群体产生相同的影响。
2.2 数据价值链
为了理解数据驱动的公众科学实践在不同阶段是如何影响社会公平的,本文参照L?fgren和Webster的研究成果[27],引入“数据价值链”(Data Value Chain)这一分析维度。该维度按照依次关联的逻辑,将数据全生命周期管理分为数据收集、数据存储、数据分析和数据使用四个阶段。数据收集指利用调查、访谈、贴身传感器、智能手机等方式获取数据,这涉及到采集“谁的数据”,与分配公平相关;数据存储是指将数据存储在数据库、数据中心或“云”上,关涉公众对存储的数据是否享有基本的数据权利;数据分析指利用机器学习、深度学习等算法对数据资源进行挖掘,探寻事物之间的相关关系或因果关系,其中算法的参数设置与过程公平所关注的知识服务质量密切相关;数据使用主要是指决策者对数据分析结果的利用,这可能对公众的实际获取或感知满意度产生影响,属于结果公平的范畴。因此,数据价值链为分析公众科学在哪些阶段如何促进或阻碍社会公平提供了一个连续性视角。
3 聚焦社会公平议题的典型案例
鉴于本文的研究问题具有现实性,且旨在探讨明确的发生机理,所以宜采用案例研究法对数据驱动的公众科学实践中所关涉的社会公平展开经验分析,打开公众科学与社会公平之间的数据“黑箱”,助力包容性开放科学运动的推进。对此,从主题、研究设计、实施过程、结果评价方面对众多公众科学项目进行筛选,选取6个聚焦社会公平议题的典型案例,涉及医疗健康、气候变化、环境保护、政策制定等议题,这有效保证了案例选取的多样性。
案例1:“像我一样的病人”(PatientsLikeMe,简称PLM)。PLM源自美国一位患“肌萎缩性侧索硬化”(ALS)病症的家人和朋友们,为了将分散在不同地区的ALS患者聚集起来共享和交流病情,在2011年创建了这一网络平台。PatientsLikeMe是一种基于网络的数据合作社,通过整合23andMe、Apple Health、Twitter等多种渠道的数据源,实现对个人健康数据的汇聚共享和开发利用,现已发展成为全球最大的病友分享平台,病种也从最初的ALS一种激增至2800多种疾病。
案例2:“历史天气”(Old Weather,简称OW)。OW是由英国气象局和公众科学组织Zooniverse于2010年共同发起,通过招募公众志愿者根据OW课题组发布的研究任务,自行选择将何种船舶日志转录为数字化文本并上传至oldweather.org网站上,为气象局进行天气预测提供源源不断的数据,有助于提高对气候环境变化的科学认知。
案例3:“极端公众科学”(Extreme Citizen Science,简称ExCiteS)。ExCiteS是一个位于伦敦大学学院的研究小组发起,旨在支持多样化和难以接触的人群参与科学。该小组不仅指导英国伦敦刘易舍姆区佩皮斯住宅区居民收集数据并创建表征周边噪声水平的数字地图,也在非洲刚果、卡麦隆等国家支持土著居民对当地自然资源进行团体测绘,记录非法的采伐捕猎活动,从而广泛深入参与保护家园的治理活动。
案例4:“可持续环境下的参与式城市生活”(The Participatory Urban Living for Sustainable Environments,简称PULSE)。PULSE由欧盟委员
会提供资助,将公众收集的数据进行集成,为城市治理提供信息支撑。例如,位于法国巴黎的PULSE试验点从公众可穿戴设备和智能手机中萃取与析出有关空气污染、哮喘高发区等数据,帮助公众及时掌握与全市公共健康风险危机管理方面的资讯。
案例5:“地面真相2.0”(Ground Truth 2.0,简称GT2.0)。GT2.0是一项由欧盟委员会资助的公众科学计划,在全球一共设置了6个公众观测站,鼓励公众、科学家、政策制定者利用公众科学研究范式,就当地居民感兴趣的议题进行研究。目前,该项目涉及美国密歇根州佛林特市含铅量超标的水污染事件、荷兰阿姆斯特丹的城市地表水治理、赞比亚的可持续资源开发利用等多种案例。
案例6:“共同行动科学计划”(Doing It Together Science,简称DITOs)。DITOs获得欧盟最
大的科研和创新资助计划“地平线2020”(Horizon
2020)划拨近350万欧元的资助,通过公开演讲、科普会议、纪录片放映、甚至是一辆“科学巴士”等860项活动吸引了来自9个欧洲国家50多万公众的积极参与,重塑了公众、科学家、政策制定者在环境保护、公共服务等议题的宣传推广方面的合作生态。
4 数据驱动的公众科学实践对社会公平产生的具体影响
通过对公众科学6个案例所涉及的社会公平维度,以及数据价值链环节进行标记后形成证据链,以此探讨公众科学从数据收集到数据使用过程中所折射的社会公平,为推动更加公平的公众科学实践提供学理支撑。数据驱动的公众科学实践可能指向社会公平的一个或多个维度,其中涉及最多的是过程公平,其次是结果公平,最后是程序公平和分配公平。接下来,从分配公平、程序公平、过程公平和结果公平四个方面依次分析数据驱动的公众科学实践对社会公平的具体影响,表1列示了几个典型的公众科学案例中所涉及的社会公平议题。
(1)分配公平。选择收集个人和群体的哪些数据是公众科学在一开始设计时须考虑的要素,但往往容易忽略收集哪些个人和群体,这关涉到数据收集的代表性问题。例如,PULSE由于主要采集数字活跃用户的数据,绘制出的公共健康实时地图可能只是反映这些活跃用户所在街区的情况,而那些没有资金购置可穿戴设备或智能手机、亦或是缺乏必要的数字素养的弱势群体,就几乎不能在PULSE的项目实施中留下数字痕迹,这就导致有关公共健康保障的资源分配存在不公平现象。而弱势群体的数据“不可见”(Invisible)往往也是造成政治排斥与边缘化的一个重要因素,所以收集“谁的数据”会在很大程度上影响资源配置,公众科学的设计者应对此给予足够关注,力图缓解“数据差距”(Data Gaps)对社会公平可能造成的侵蚀。
(2)程序公平。随着公众科学的应用场景越来越丰富,科学家、政策制定者意识到公众不仅代表免费劳动力,还拥有可观的分布式计算能力,这显然为开展科学研究节省了经费支出。但有相当一部分公众科学在实施过程中,只想着让公众收集数据、甚至是关于他们个人隐私的敏感数据,而在基本的数据权利保护方面却做得远远不够。例如,OW的数据处理在某种程度上是汲取性的,因为公众收集和转录的数据明显有利于英国气象局、商业用户等机构,数据上传后的处理也缺乏透明度,公众并没有直接从他们的劳动中受益,这在数据所有权方面造成了不公平。当然,有的公众科学项目在保障基本的数据权利方面做得较好,如PLM的平台架构及隐私保护协议不仅允许参与者可以访问上传的数据和了解数据的流通过程,还保障其充分享有数据“被遗忘的权利”,即他们可以撤销和删除在平台上记录的个人数据。
(3)过程公平。科学家、政策制定者在利用公众群体智慧的优势来降低成本和提高效率的同时,也要为公众参与科学提供必要的知识服务,以更好地吸引和激励他们为项目长期提供高质量的数据。ExCiteS是一个不论个人的背景或文化水平,旨在提高公众参与度的研究小组。例如,该小组为推进刚果盆地土著居民进行自然资源的群体测绘,特意开发了一种“以图代字”的资源测绘设备,以解决诸如识字和语言障碍、不熟悉智能手机及互联网接入受限等问题。同时,该小组还和当地中介机构合作,开展数字素养培训,提升当地居民运用测绘设备的技能和利用调查数据进行维权宣传的意识。而英国气象局作为OW项目的主要受益者,在意的是如何利用数据训练预测气候变化的模型,并经常向参与者提出一些难度系数较大的新任务,但并不为他们完成这些任务提供必要的知识服务支持。
(4)结果公平。工具性数据公平关注谁从基于数据的决策中受益的问题,着力纠正由于数据驱动可能导致的不公平。GT2.0项目中佛林特市的居民在弗吉尼亚理工大学的支持下,对全市的水样进行了系统的数据采集和科学分析,以此否定了具有误导性的官方结论,并就含铅量超标的水污染事件向最高法院起诉当地政府官员。荷兰阿姆斯特丹鼓励居民参与对水质的监测行动,通过众多观测点数据的汇聚共享形成对城市地表水治理的实时动态地图,这为改善城市居住环境提供了数据支持。DITOs在伦敦大学学院的协调下专注于围绕公众科学的政策宣传,鼓励非政府组织、高等院校等机构提供多样化支持,促使公众深度参与科学研究及相关科学决策。爱沙尼亚政府就借助DITOs在为期14周的在线征集活动中,收到公众提出的3000多条提案意见,其中7条意见对修改法律或制定新法律做出了贡献。
5 数据驱动的公众科学实践对社会公平可能存在的影响路径
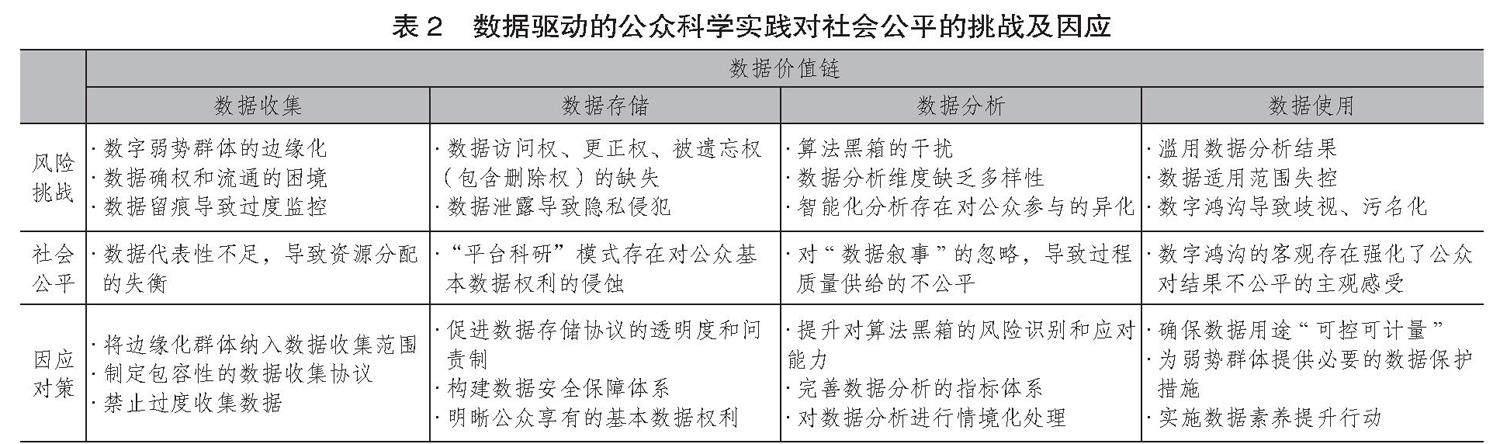
在前文分析的基础上,利用数据价值链维度进一步分析数据驱动的公众科学实践对社会公平可能存在的影响路径。数据价值链不应被视为一个线性模型,而应是一个递归演化的过程,其每一个环节都有可能对社会公平产生影响,其中数据收集和数据使用受到的关注度较高,数据分析次之,而数据存储的关注度最低。表2具体列示了数据价值链各个环节所面临的风险挑战、对应的社会公平议题,以及政府为促进社会公平可选择的因应对策。
(1)数据收集。公众科学的数据可通过调查、社交媒体及手机、可穿戴设备等进行收集,其中缺乏移动设备或数字能力不足的弱势群体就可能不在数据收集范围之内,由此产生数据代表性不足的问题。当然,这只是产生数据代表性不足的客观原因,其主观原因可能是公众由于担心过度监控,而主动选择“数字隐形”,以避免留下数字痕迹。数据的缺失不仅直接影响公众科学项目的预期成效,还会使政府在制定公共服务政策时产生不公平。为了确保数据的代表性,政府可在公众科学的资助审查中加大对数据收集的论证,要求受资助方设计一个可以弥合数据差距的收集方案,重点将较难触及或处于边缘处境的弱势群体纳入其中,并为他们有效参与数据收集活动提供必要的数字素养和硬件培训。另一方面,针对主观上存在的数字隐形问题,科学家应主动邀请公众一起定义应收集哪些数据、包括具体的数据维度,重点关注数据所蕴含的政治历史背景,以规避后续的数据分析可能会造成的歧视。
(2)数据存储。从技术视角来看,数据存储是指记录和保存数字信息,以供当前或未来使用的磁性、光学或机械介质。但数据存储不单纯是一个技术问题,也是一个涉及基本数据权利的社会技术问题。由于PLM采用了隐私保护协议,参与者不仅拥有访问、撤销或删除已上传数据的权利,并能根据贡献度的大小获取数据共享后的相关服务。与之相比,虽然OW不收集和使用个人隐私数据,参与者也可以在平台上访问数据,但数据上传后的使用缺乏透明度。英国气象局将公众上传的数据进行加工后生成数据产品,在市场上进行销售赚取利润,然而公众并没有从中受益,这在数据所有权方面造成了不公平。政府在资助指南中应要求科学家提交一份安全透明且具有问责效力的数据存储协议,未来可进一步根据数据存储的共性需求委托相关机构进行关键技术攻关,为公众科学的大规模发展提供数据安全基础设施支撑。
(3)数据分析。公众往往由于缺乏必备的专业知识或工具,而不能参与数据分析,这项任务通常由科学家承担。但对于公众提供的数据,科学家一般只是将其视为一串数字符号,未深入理解这些数据中所蕴藏的历史文化和当地特色。那么,这样的分析结果可能会强化数据背后的制度偏见,形成一种基于数据的社会建构,集中反映了数据生产者的价值观和信念。此外,随着人工智能越来越多地被用于分析数据,从而将公众、科学家从繁琐枯燥的数据清洗、分析中解放出来,使他们能以最符合其兴趣、技能和潜力的方式为科学作贡献。但这并非没有风险,算法黑箱的存在会出现连算法工程师都不能理解的分析结果,这些结果可能会导致新的歧视。为了规避数据分析环节的不公平,政府在资助公众科学项目时可要求受资助方提交数据分析模型展开伦理审查,也可要求在算法设计中加入利益相关者的隐性知识和价值观,将数据分析置于更大的政治历史系统之中进行考察。
(4)数据使用。公众生成的数据通常被视为有价值的信息和知识来源,有助于科学研究和政府决策,所以数据使用关注数据分析结果带来的社会建构价值。佩皮斯住宅区居民创建的噪声动态地图,质疑了政府城市建设规划的不合理性,促使议会暂停了相关决策的审批,这无疑将给当地社会治理带来深远影响。但也不是所有的数据都能被正确使用,数据可能是为了某一目的而收集的,但数据的分析结果往往又被用于其他目的或被别的管理机构重复使用,这可能导致数据滥用、权力不对称等。例如在刚果盆地的热带雨林保护中,官商合谋限制了数据的使用范围,土著居民收集的数据并未对当地生态系统保护产生变革影响。其实与公众相比,科学家、政府等利益相关者从数据分析结果的使用中受益更多,公众反而可能成为被自己收集的数据所驱动的治理对象。为此,政府应采取必要的措施促进公众对科学研究的全过程参与,加强公众与政府、科学家之间的可信协作,打造共创型的公众科学模式。
6 结语
本文基于社会公平与数据价值链的二维分析框架对公众科学案例展开系统研究,发现政策制定者、科学家选择收集哪些个人和群体的哪些数据,以及如何存储、分析和将这些数据用于何种特定目的,对社会公平带来的影响是复杂的。虽然公众逐渐成为数据主体,但他们既没有权利也没有足够的数字素养去了解自己的数据是如何被收集、存储、分析和使用的。数据驱动造成的不公平主要由作为数据供给方的公众来承担,而科学家、政策制定者等数据使用方却享有数据产生的效益,但不用对此承担责任。案例分析结果表明,公众的“贡献性专业知识”是由社会政治的迫切需求引导的,而非遵循其所致力的科学研究的迫切需求,这就使得公众科学并不总是以预期的方式塑造公众、科学家和政策制定者之间的关系。
数据驱动的公众科学实践中的不公平,主要是由数据代表性不足、数据滥用、隐私泄露等问题引起,区块链、隐私计算等数据安全技术对此提供了解决路径。基于隐私计算将公众收集的数据解构为不可见的“具体信息”和可用的“计算价值”,实现“数据可用不可见”;在此基础上,通过区块链对“计算价值”进行确权、存证及流通,达成数据“使用可控可计量”,从而在“原始数据不出域”的前提下释放数据价值。简言之,区块链和隐私计算的融合创新在数据驱动的公众科学实践中应用广阔,例如确认数据来源(提高数据代表性)、界定数据使用范围(避免数据滥用)、追溯数据流通过程(确保权责分明)、防范数据安全风险(保护数据隐私)等。解决这些数据问题是科学设计公众科学项目的关键环节,以便形成公众对科学家、政策制定者工作的合理预期和情感认同,从而助力包容性开放科学运动的推进。
*本文系教育部人文社会科学研究青年基金项目“基于区块链技术的公众科学治理方式创新研究”(项目编号:22YJC630207)、成都市软科学研究项目“面向西部(成都)科学城的科学数据可信流通路径研究”(项目编号:2023-RK00-00019-ZF)成果之一。
张双志 刘华锦:数据驱动的公众科学实践:基于社会公平视角的考察
Zhang Shuangzhi, Liu Huajin : Data-Driven Citizen Science Practice: an Examination From the Perspective of Social Equity
参考文献:
WIGGINS A, WILBANKS J. The rise of citizen science in health and biomedical research[J].American Journal of Bioethics,2019,19(8):3-14.
UHLMANN E L. Scientific utopia III: crowdsourcing science[J].Perspectives on Psychological Science ,
2019,14(5):711-733.
IRWIN A. No PhDs needed: how citizen science is transforming research[J].Nature,2018(562):480-482.
杨正.“公众科学”研究:公民参与科学新方式[J].科学学研究,2018,36(9):1537-1544.
BLASIMME A, VAYENA E, HAFEN E. Democratizing health research through data cooperatives[J].Philosophy & Technology,2018,31(3):473-479.
JOLLYMORE A. Citizen science for water quality
monitoring: data implications of citizen perspectives[J].
Journal of Environmental Management,2017(200):
456-467.
University of Maryland. Sacoby wilson: biography
[EB/OL].[2023-08-01].https://sph.umd.edu/people/sacoby-wilson.
牛毅冲,赵宇翔,朱庆华.基于科研众包模式的公众科学项目运作机制初探:以Evolution MegaLab为例[J].图书情报工作,2017,61(1):5-13.
HECKER S. Citizen science: innovation in open science, society and policy[M].London: University College London Press,2018:3.
BONNEY R. Citizen science: a developing tool for expanding science knowledge and scientific literacy[J].Bioscience,2009,59(11):977-984.
Open humans (homepage)[EB/OL].[2023-06-01].https://www.openhumans.org.
Patientslikeme (homepage)[EB/OL].[2023-08-01].https://www.patientslikeme.com.
Community Engagement, Environmental Justice, Health (CEEJH). Our mission[EB/OL].[2023-07-29].https://www.ceejhlab.org/our-mission.
ELSE H. Crowdfunding research flips sciences traditional reward model[EB/OL].[2023-07-11].https://www.nature.com/articles/d41586-019-00104-1.
JAMES W. Citizen science in the digital age: Rhetoric science and public engagement[M].Tuscaloosa: The University of Alabama Press,2017:11.
武学超.模式Ⅲ知识生产的理论阐释:内涵、
情境、特质与大学向度[J].科学学研究,2014,
32(9):1297-1305.
SINGH G. Smart patrolling: an efficient road surface monitoring using smartphone sensors and crowdsourcing[J].Pervasive and Mobile Computing,2017(40):71-88.
BRANDI L. Emerging developments in citizen science: Reflecting on areas of innovation[EB/OL].[2023-07-29].https://www.rand.org/pubs/research_reports/RR4401.html.
LIM C C. Mapping urban air quality using mobile sampling with low-cost sensors and machine learning in Seoul, South Korea[J].Environment International,2019(131):105022.
金瑛,张晓林,胡智慧.公众科学的发展与挑战[J].图书情报工作,2019,63(13):28-33.
HEIGL F. Opinion: toward an international definition of citizen science[J].Proceedings of the National Academy of Sciences of the United States of America,2019,116(17):8089-8092.
HINCKSON E. Citizen science applied to building healthier community environments: Advancing the field through shared construct and measurement development[J].International Journal of Behavioral Nutrition and Physical Activity,2017(14):1-13.
BOWSER A. Accounting for privacy in citizen science: ethical research in a context of openness[C].In CSCW 17: Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing,2017:2124-2136.
ETTLINGER N. Open innovation and its discontents[J].Geoforum,2017(80):61-71.
张双志,张学梅.“元宇宙+研究型图书馆”:为开放科学赋能[J].新世纪图书馆,2023(6):67-73.
JOHNSON N J, JAMES H. Svara. Justice for all: promoting social equity in public administration[M].
New York:Routledge,2011:6-7.
L?FGREN K, WEBSTER C W R. The value of big data in government: the case of ‘smart cities[J].Big Data & Society,2020,7(1):1-22.
周翔,叶文平,李新春.数智化知识编排与组织动态能力演化:基于小米科技的案例研究[J].管理世界,2023,39(1):138-156.
RUIJER E, PORUMBESCU G, PORTER R, et al.
Social equity in the data era: a systematic literature
review of data-driven public service research[J].Public Administration Review, 2023,83(2):316-332.
张双志 刘华锦:数据驱动的公众科学实践:基于社会公平视角的考察
Zhang Shuangzhi, Liu Huajin : Data-Driven Citizen Science Practice: an Examination From the Perspective of Social Equity
张双志 成都大学师范学院副研究员。 四川成都,610106。
刘华锦 成都大学师范学院教授。 四川成都,610106。
(收稿日期:2023-08-11 编校:曹晓文,左静远)
