MAFFCL:基于掩码注意力机制的校园网络日志特征融合模型
2024-06-21黄礼成于春燕



摘 要:校园网络日志反映了学生用户的上网行为特征。近年来,应用深度学习技术分析海量的校园网络日志数据,受到越来越多研究人员的关注。由于每个学生上网的时间和频率不同,校园网络日志数据在记录时间和存储空间上的分布存在不规则性。这类教育数据在深度学习中通常存在高维稀疏矩阵问题,这导致了难以直接有效地从中提取特征。现有研究大多采用具备先验知识的特征工程方法来筛选相关特征来解决高维稀疏矩阵问题。显然,这些方法不能完全避免高维稀疏矩阵带来的影响。文章提出的对比学习模型 MAFFCL(Masked Attentional Feature Fusion Contrastive Learning)能够进行特征融合,从而有效地提取特征。MAFFCL 在对比学习中进行特征融合,并在融合时屏蔽高维稀疏矩阵中的填充向量。此外,MAFFCL 还通过随机调换原始数据部分特征的顺序来进行数据增强,以此增强模型学习能力。为了验证模型的性能,利用真实的校园网络日志进行了两个下游预测任务,一个是对学生学业风险情况的预测,另一个是学生成绩分级的预测。实验结果表明,在两个下游任务中,使用MAFFCL模型预测的准确率分别比其他经典模型高出5.2%和6%。
关键词:MAFFCL;特征融合;教育数据挖掘;对比学习;学生成绩预测
中图分类号:TP39 ""文献标识码:A ""文章编号:1673-1794(2024)02-0062-08
作者简介:黄礼成,安徽理工大学计算机科学与工程学院硕士生,研究方向:深度学习算法和教育数据挖掘(安徽 淮南 232000);于春燕,滁州学院计算机与信息工程学院教授,研究方向:大数据、智慧校园和机器学习(安徽 滁州 239000)。
基金项目:安徽省高等教育研究计划项目“基于多模态数据融合的特征建模与应用”(2022AH040153);滁州学院重点项目“面向行为干预的特征建模研究与应用”(2022XJZD13)
收稿日期:2024-01-15
1 引言
EDM(教育数据挖掘)是教育领域面向未来的研究方向,目标是提高教学效率和质量[1]。EDM是一种从教育环境中探索和开发独特类型数据的方法,即把海量的教育数据资源转化为有意义的教育信息和知识[2]。EDM技术可以为教育决策者提供基于数据的模型,为教育科学决策提供支持[3]。它还可以对学生个体的学习情况进行具体分析评估,从而实施个性化教育。教育数据挖掘技术在教育领域的应用可以提高教学效率,改善教学效果,促进教学质量的提高。近二十年来,随着网络学习资源的日益丰富、教育软件的广泛应用以及互联网在教育领域的普及,产生了海量的教育数据资源[4-5]。高校等传统教育机构存储着大量的教育信息[6]。如今,基于互联网的教育系统已广泛普及,因此,包含大量反映学生特征信息的教育数据被存储在校园网络日志中[7]。
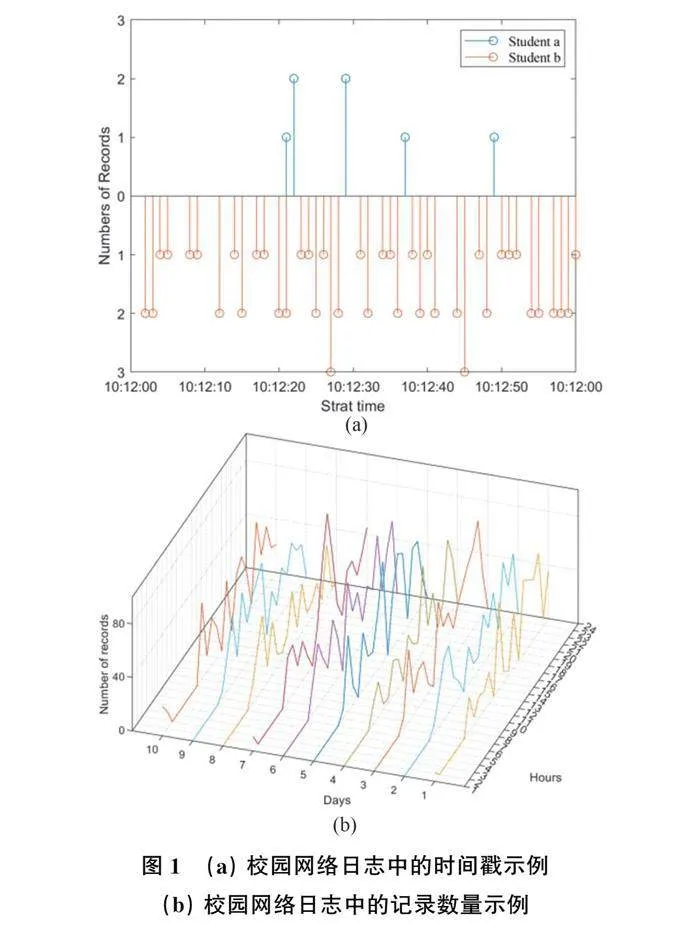
校园网络日志数据是一种典型的教育数据。高校学生终端通过访问校园网获取网络资源,由此产生了海量的校园网络日志数据。校园网络日志是由在线学生用户的上网行为记录生成的日志文件,记录用户的网络活动,记录学生用户与信息访问系统的交互信息[8]。数据可概括为两类属性:时间属性和序列属性[9]。时间属性包括学生在线行为的时间戳、持续时间等。序列属性表示上网行为之间的关系和排序方式。由于校园网络日志记录的内容是真实学生用户的上网行为,而这些真实上网行为的发生时间、持续时间和频率都具有很大的随机性,导致校园网络日志记录的信息在时间和空间分布上具有很强的不规则性。如图1所示,某一天属于不同学生的上网记录数量不等,从几条记录到几千条记录不等。通过传统的特征工程方法处理此类网络日志数据得到的特征是一个高维稀疏矩阵。高维稀疏矩阵在后续的模型构建和学习中表现不佳。
因此,如何有效地从校园网络日志中提取学生的上网行为特征是一个关键问题。针对这一问题,提出了一种MAFFCL模型,通过融合的方法有效地提取在线行为特征。
贡献如下:
(1)提出一种特征融合的对比学习模型MAFFCL。MAFFCL模型利用了“校园网络日志中同一用户相邻记录点的在线行为可能存在某种相似性”这一先验知识进行特征融合。同时,MAFFCL可以扩展应用到具有相似先验知识结构的教育数据,对其进行学习训练。
(2)增强预处理方法的特征表达能力。为了更好地融合和提取学生在线行为特征,利用网络日志数据中潜在的文本语义属性,对数据中大量不同属性的离散变量分别进行embedding编码,使特征融合后具有更强的特征表达能力。
(3)进行有效的数据增强。由于每条在线行为记录中不同属性信息的数据顺序并不影响特征信息的表达,因此采用交换不同属性数据顺序的方法进行数据增强。
(4)采用真实数据集进行实验验证。基于真实校园网络日志数据对模型进行预训练。并执行下游任务进行预测分析实验。实验结果表明,使用MAFFCL模型进行预测的准确率远高于不使用MAFFCL的模型进行预测的准确率。
2 相关工作
教育数据挖掘是研究教育学中学习分析的一种重要方法。相应地,近年来教育数据挖掘研究也取得了丰硕的成果。本章节将介绍近年来教育数据挖掘研究领域中校园网络日志数据挖掘的相关工作以及相关对比学习的发展情况。
2.1 校园网络日志数据挖掘
大多数研究侧重于通过挖掘网站访问记录和社交网络信息等网络日志数据来分析学生的上网行为。例如,Alvarez P等[13]挖掘学生在线学习管理系统生成的日志文件,构建线性时间逻辑(LTL)模型,以检验课程设置的合理性、学生学习的健康性等。Masrom等[14]从网络日志中挖掘在线社交网络的特征信息,从学术目的、人格问题、网络沉迷和知识共享行为等方面研究其对学生学习成绩的影响。Khamis等[15]利用教育数据挖掘方法构建了学生特定网络使用行为的综合成绩预测模型,包括分类、回归、聚类和相关等。Xu等[16]挖掘了学生的上网数据,并进行了表征分析,得到了上网频率、上网流量、上网时间、上网时长等四个特征,用于预测学生成绩。
2.2 对比学习
对比学习是一种自监督的、与任务无关的深度学习技术,它允许模型在没有标签的情况下学习数据[17-18]。近年来,许多研究者专注于对比学习的研究,并取得了丰硕的成果。对比学习根据对比样本对分为两类,即正负样本对的对比学习和异质正样本对的对比学习[19]。一,正负样本对比学习。Tian等[20]提出了CMC(Contrastive Multiview Coding),利用物体的原始图像、深度信息、表面法线和分割图像四个视角来构建更多的异构正样本数据。CMC 将任务从两个视角扩展到多个视角,并以更广泛的方式定义正样本。He 和 Chen 等[21-23]提出了 MoCo、MoCo v2和MoCo v3,将之前的对比学习方法推广到动态字典查询问题中。MoCo 使用队列而不是内存库来存储负样本,使用动量来更新编码器而不是用动量更新来更新特征。MoCo v2相较于MoCo使用更多的数据增强方式、增加MLP层、调整学习率和更多的训练次数。MoCo v3 将骨干网络从 ResNet[24]换成了ViT[25],整体框架基本不变。二,异质正样本对比学习。Grill等[26]提出的 BYOL(Bootstrap Your Own Latent)模型提出了一种不使用负样本学习的自监督学习,只使用异质正样本进行自监督学习,相当于根据同一图像的另一个视图的特征来预测其中一个视图的特征。其损失函数为MSE损失。Chen等[27]提出的SimSiam只需要使用异构正样本,不需要负样本,不需要较大的批量,也不需要动量编码器,并使用MSE损失,进一步简化了异构正样本比较学习的建模,同时能够取得良好的效果。
总之,以往关于校园网络日志挖掘的研究工作大多倾向于使用特征工程方法,针对专门问题筛选出日志中一部分相关度较高的信息,如社交信息、访问过的网站信息等进行学习和预测。这种方法虽然能有效解决某些特定问题,但缺乏一定的可扩展性。另外,由于上网行为在校园网络日志中的分布是随机的、不规则的,因此很难直接进行建模和学习。因此,针对上述问题,本研究提出了一种对比学习模型MAFFCL,用于融合和提取在线行为特征,以获得更好的学习性能。该模型是一种自监督学习模型,具有良好的可扩展性。
3 问题陈述
本章节描述了日志中上网行为记录的不规则分布以及上网行为之间隐含的相似性,并将其形式化。
3.1 问题描述
校园网络日志数据是学生上网行为的真实记录,而学生的上网行为具有很强的随机性,这必然导致学生上网行为记录在日志中的分布不规则[28-29],如图 1所示。这种高度不规则的分布使得很难通过对网络日志数据进行特征工程处理来直接有效地获取特征。
但通过观察数据发现,上网行为存在相似性,如图2所示。由于玩游戏、听音乐等上网行为有一定的持续时间,即在这个持续时间内有多条网络日志记录来存储上网行为信息。因此,同一个人在相邻时间点的上网行为可能具有一定的语义相似性。文章要做的就是让模型能够总结出相似的上网行为,也就是说,试图利用这种相似性进行上网行为融合和特征提取。
3.2 形式化
用符号 x 表示在线行为。 x 包括不同的属性信息,如日期、地点、时间戳、持续时间、上游流量、下游流量、流量总和、访问网站类型、终端类型等,如表1所示,有ξ个属性。在公式(1)中,符号x.αi表示上网行为的第i个属性数据,即
4 MAFFCL机制
本章节介绍MAFFCL的机制,包括架构、预测网络、目标生成网络和损失函数。
4.1 MAFFCL架构
模型架构分为两部分,一部分是预测网络,另一部分是目标生成网络。损失计算分别在这两个网络输出的特征向量上进行。预测网络的任务是进行预测,主要由两层组成,即P(Projection head)和编码器。目标生成网络的任务是生成预测目标,主要由动量编码器组成。特别是,梯度更新在预测网络中进行,而不在目标网络中进行。同时,梯度更新的权重和偏置参数通过动量(momentum)更新到目标生成网络中。
MAFFCL模型是一种融合型对比学习模型。首先,如第3.1章节所述,它利用网络日志中记录的数据的相似性进行数据融合。其次,它利用校园网络日志中记录的各种属性数据可以依次交换进行数据增强,如公式(4)所示,来开展对比学习。模型架构如图3所示。
4.2 预测网络
4.2.1 编码器
MAFFCL 编码器的基本思想是使用注意力机制(attention mechanism)来进行特征融合。其工作原理如图 4 所示。如第 3.1章节所述,每个学生的输入数据大小都是不同的。为了让模型能够学习,输入数据需要经过填充至一致大小。将填充数据定义为无效数据,将非填充数据定义为有效数据。在编码器中,对填充的无效数据进行掩码(masked),然后通过注意力机制对有效数据进行融合,从而得到融合特征。
5 实验和结果
本章节介绍基于实际数据的实验和结果,包括数据集、实验设置和下游任务的实验表现。
5.1 数据集
本研究收集了安徽省某高校的校园网络日志数据。共收集了4400名学生持续90天的校园网络日志数据。每条日志记录都包含学号、时间、流量、位置等信息。样本如表1所示。特别对校园网络日志数据进行了脱敏处理,以确保网络用户的隐私不被泄露。
为了适应对比学习,校园网络日志的部分属性数据都采用embedding编码方法[33-34]进行数据预处理。首先,删除x.duration=0或x.sum_traffic=0的无效数据。然后,分别对在线行为中不同属性的离散数据进行embedding编码,并分别对流量和持续时间等连续数据进行单位统一化和归一化处理。特别的是,对日期属性信息进行索引编码后再进行embedding编码。为了在融合过程中获得更好的特征表达。
5.2 实验设置
5.2.1 预训练设置
本实验使用深度学习框架Pytorch构建MAFFCL模型。在预训练过程中,选择Adam optimization梯度下降方法。初始学习率lr设置为10-3,学习率每 50遍减半。经过预训练后,编码器会得到融合和提取的特征,用于预测下游任务。
5.2.2 下游任务及其设置
为了验证模型的性能,设计两个下游任务,即高危学生预测(Task-I)和学生学业风险预测(Task-II)。Task-I是指预测学生是否有不及格的风险。Task-II是指预测学生的平均学分绩点(GPA)分级,分为优秀、中等、较差三个等级。
下游任务实验使用从预训练编码器获得的融合特征作为输入,然后将其输入MLP和 softmax层进行进一步训练,以实现下游任务预测。训练采用亚当优化(Adam optimization)梯度下降方法,初始学习率设定为10-4。训练共计100遍,学习率每 25 遍减半。
5.3 实验结果
本研究对动量参数φ和顺序交换比率γ(校园网络日志属性数据的顺序交换比率)进行了消融实验,并对不同对比学习模型的性能进行了对比实验。特别是,基于下游任务对上述实验的性能进行了评估。
表2展示了不同动量更新超参数φ情况下的下游任务预测准确度。由表2中可知,当动量参数为0时,预测失败。这表明,当φ=0时,预训练模型找到了一个崩溃解,未能成功完成特征提取。而当φ≠0时,编码器输出的特征信息能够完成下游任务的预测。其中当φ=0.999时,两个预测下游任务达到了最佳准确度。这表明,合理设置动量更新超参数φ能有效增加模型训练准确度,避免预训练失败。
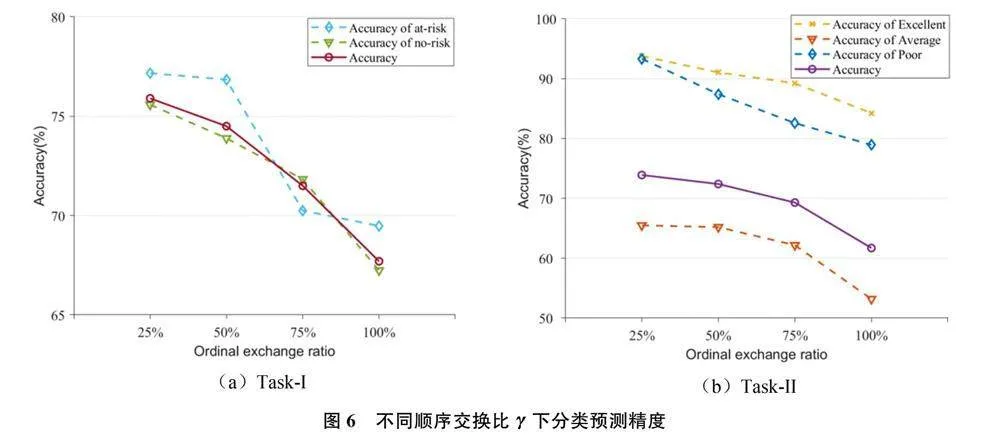
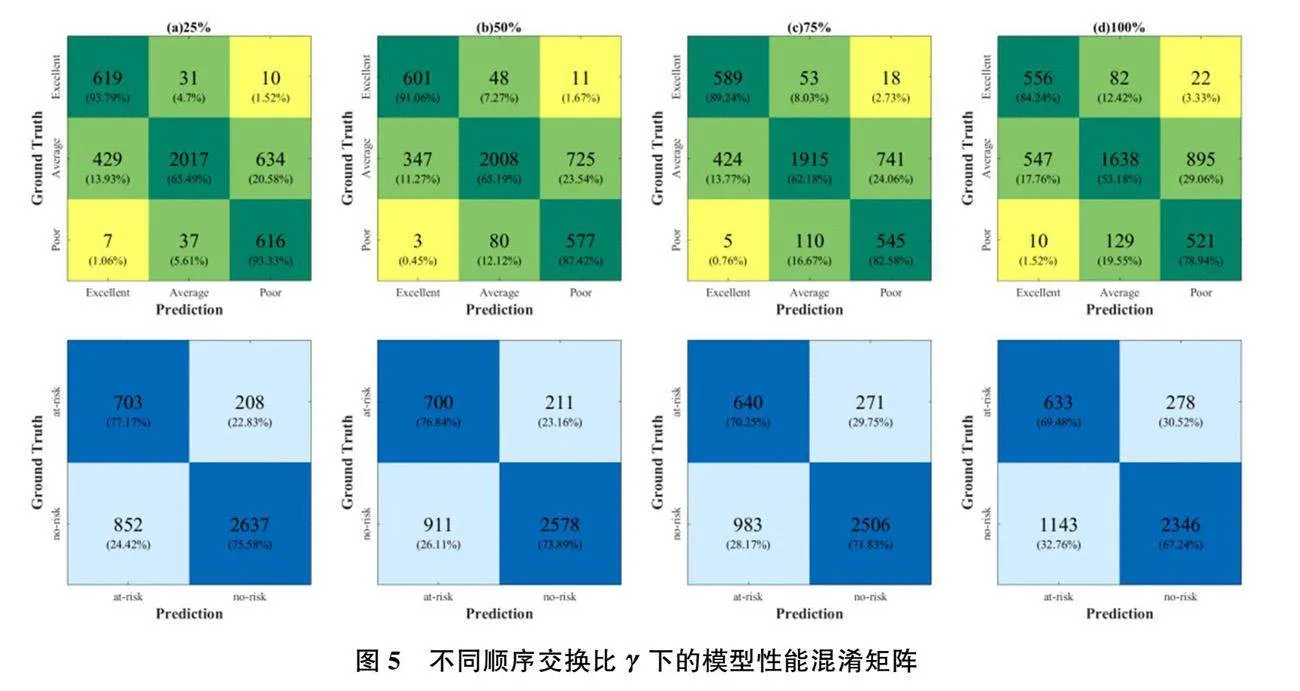
图5展示了不同顺序交换比(ordinal exchange ratio)γ下的模型性能混淆矩阵图。图6展示了不同顺序交换比γ的下游任务中各分类预测准确率。当γ= 25%时,下游任务Task-I和Task-II的预测准确率最高。在Task-I中,预测有学业风险类(at-risk)学生的准确率在γ= 25%时分别比γ= 50%, γ = 75%和γ= 100% 高0.33%、6.92%和7.69%,而预测无学业风险类(no-risk)学生的准确率分别比γ= 50%,γ = 75%和γ= 100%高1.69%、3.75%和8.34%。各类别的预测准确率与顺序交换比率γ呈负相关,这在Task-II中也是如此。这表明,在预训练过程中,较高的γ会导致模型学习正样本对特征相似性的能力降低。
在Task-II中,当γ= 25%时,对优秀和较差两个区间的学生的预测准确率最高,分别为 93.79%和93.33%。差生(较差类学生,Poor performance students)被预测为优生(优秀类学生,Excellent performance students)的概率为1.06%,而优生被预测为差生的概率为1.52%。这说明差生和优生的网络行为特征在特征空间中距离较远。实际成绩处于中等区间的学生的预测准确率为65.49%,被预测为优生和差生的概率分别为13.93%和20.58%,优生和差生被预测为中等类学生(Average performance students)的概率分别为4.7%和5.61%。这表明,在特征空间中,中等类学生的网络行为特征与优生特征之间的距离大于它与差生特征之间的距离。
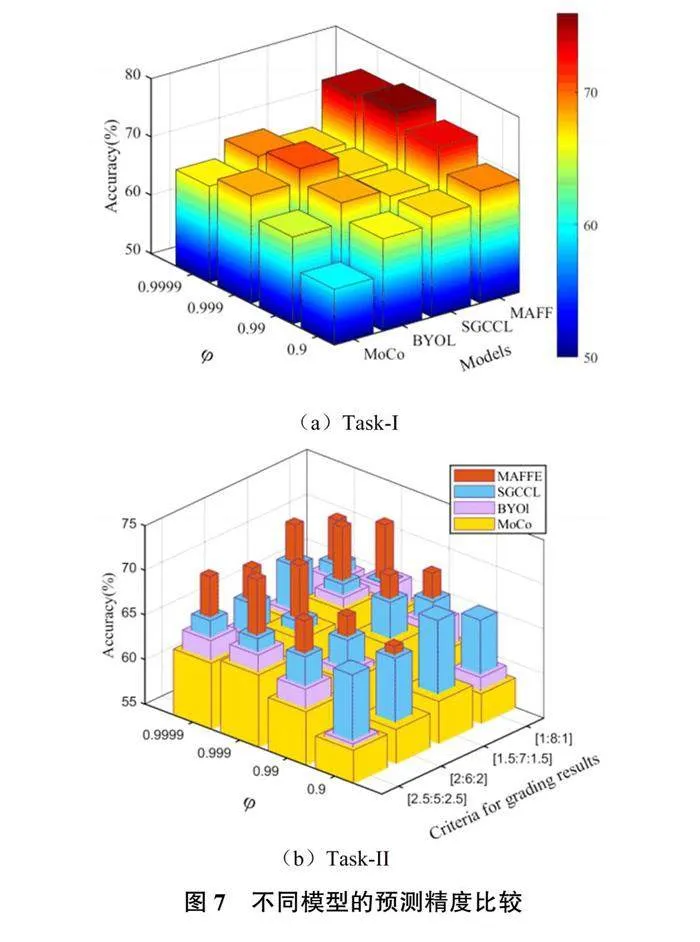
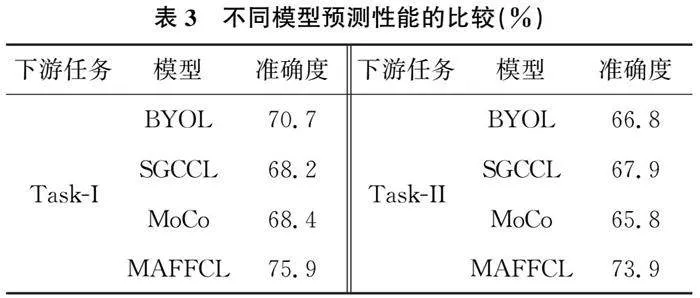
表3比较了不同模型预测精度。与BYOL、MoCo和SGCCL[35]相比,MAFFCL模型的准确率分别在两个下游任务上至少高出5.2%、6%。这表明,MAFFCL的特征融合层在提取学生在线行为特征方面更为有效。
值得注意的是,SGCCL没有动量参数,因此该模型的性能在图7中x 轴(动量参数φ)方向上保持不变。在图 7(b)中,y轴(criteria for grading results)显示了学生成绩的不同评分比例。在图7(a)中,当动量参数φ= 0.999时,BYOL和MoCo的准确率高于SGCCL,而当φ= 0.9和φ= 0.99时,SGCCL的准确率高于BYOL和MoCo。这说明适当的动量参数φ有利于提高模型的精度。在图7(b)中,按照优生人数∶中等生人数∶差生人数=(1.5∶7∶1.5)对学生成绩进行分区的预测准确率高于其他分区方法。这说明不同的评分标准对准确率有一定程度的影响。从使用学生上网行为预测成绩的角度来看,按照优生人数∶中等生人数∶差生人数=(1.5∶7∶1.5)的比例划分成绩区间可能是最佳的方法。
6 结论
文章提出了一种能够从校园网络日志中融合并提取学生上网行为特征的模型MAFFCL。该模型基于注意力机制进行特征融合提取,并通过对比学习优化特征泛化能力。预训练的编码器被用于两个下游任务:预测问题学生(Task-I)和预测学生成绩分级(Task-II)。数据集来自安徽省某大学 4400 名学生的校园网络日志数据。对动量参数φ和序数交换比γ进行了一系列消融实验。同时还对其他传统模型的准确性进行了对比实验。实验结果表明,采用MAFFCL模型对两个下游任务的预测准确率比传统的对比学习模型分别提高了5.2%和6%。这表明MAFFCL模型在预训练阶段提取在线行为特征的效果更好。
MAFFCL模型具有良好的泛化和可扩展性。它适用于学习具有不规则分布的时序性教育数据,如校园餐饮数据和校园超市购物数据。不过,MAFFCL模型只能学习单一模式的教育数据,对哪些因素导致学生成绩不佳缺乏深入了解。因此,在未来的工作中,需将模型扩展到多模态教育数据挖掘,同时提高模型的可解释性。
[参 考 文 献]
[1] ROMERO C,VENTURA S.Educational data mining and learning analytics:An updated survey[J].Wiley interdisciplinary reviews:Data mining and knowledge discovery,2020,10(3):e1355.
[2] BAKHSHINATEGH B,ZAIANE O,ELATIA S,et al.Educational data mining applications and tasks:A survey of the last 10 years[J].Education and Information Technologies,2018,23:537-553.
[3] JI H,PARK K,JO J,et al.Mining students activities from a computer supported collaborative learning system based on peer to peer network[J].Peer-to-Peer Networking and Applications,2016,9:465-476.
[4] PAPAMITSIOU Z,ECONOMIDES A.Learning analytics and educational data mining in practice:A systematic literature review of empirical evidence[J].Journal of Educational Technology amp; Society,2014,17(4):49-64.
[5] ONAN A.Sentiment analysis on massive open online course evaluations:a text mining and deep learning approach[J].Computer Applications in Engineering Education,2021,29(3):572-589.
[6] ROMERO C,ROMERO JR,VENTURA S.A survey on pre-processing educational data[J].Educational data mining: applications and trends,2014:29-64.
[7] ZENG D,WU G, PANG S,et al.Research and implementation of campus network mass log collection platform based on elastic stack[C]//Third International Conference on Electronics and Communication.Network and Computer Technology(ECNCT 2021).SPIE,2022,12167:519-526.
[8] LI X,ZHU X,ZHU X,et al.Student academic performance prediction using deep multi-source behavior sequential network[C]//Advances in Knowledge Discovery and Data Mining:24th Pacific-Asia Conference.Singapore:Springer International Publishing,2020:567-579.
[9] SCHARKOW M.The accuracy of self-reported internet use-A validation study using client log data[J].Communication Methods and Measures,2016,10(1):13-27.
[10] BETETA X,NAVARRO J,VERNET D,et al.Automatic tutoring system to support cross-disciplinary training in Big Data[J].The Journal of Supercomputing,2021,77:1818-1852.
[11] WU H,LUO X,ZHOU MC.Advancing non-negative latent factorization of tensors with diversified regularization schemes[J].IEEE Transactions on Services Computing,2020,15(3):1334-1344.
[12] ZHAO H,LIU Z,YAO X,et al.A machine learning-based sentiment analysis of online product reviews with a novel term weighting and feature selection approach[J].Information Processing amp; Management,2021,58(5):102656.
[13] LVAREZ P,FABRA J,et al.Alignment of teacher's plan and students' use of LMS resources.Analysis of Moodle logs[C]//2016 15th International Conference on Information Technology Based Higher Education and Training (ITHET).Istanbul:ITHET,2016:1-8.
[14] MASROM M,BUSALIM A,ABUHASSNA H,et al.Understanding students' behavior in online social networks:a systematic literature review[J].TechnoLearn An International Journal of Educational Technology,2021,18(6):1-27.
[15] KHAMIS S,AHMAD M,AHMAD A,et al.Internet use behaviour model for predicting students' performance[J].Expert Systems,2022,39.
[16] XU X,WANG J,PENG H,et al.Prediction of academic performance associated with internet usage behaviors using machine learning algorithms[J].Computers in Human Behavior,2019,98:166-173.
[17] RANI V,NABI S T,KUMAR M,et al.Self-supervised learning:A succinct review[J].Archives of Computational Methods in Engineering,2023,30(4):2761-2775.
[18] LIU X,ZHANG F,HOU Z,et al.Self-supervised Learning:Generative or Contrastive[J].IEEE Transactions on Knowledge and Data Engineering,2021,99:1.
[19] WANG R,WU Z,WENG Z,et al.Cross-domain contrastive learning for unsupervised domain adaptation[J].IEEE Transactions on Multimedia,2023,25:1665-1673.
[20] TIAN Y,KRISHNAN D,ISOLA P.Contrastive multiview coding[C]//Computer Vision-ECCV 2020:16th European Conference.Glasgow:Springer,2020:776-794.
[21] HE K,FAN H,WU Y,et al.Momentum contrast for unsupervised visual representation learning[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.Virtual:IEEE/CVF,2020:9729-9738.
[22] CHEN X,FAN H,GIRSHICK R,et al.Improved baselines with momentum contrastive learning[J].arXiv preprint arXiv,2020,2003:04297.
[23] CHEN X,XIE S,HE K.An empirical study of training self-supervised vision transformers.[C]//CVF International Conference on Computer Vision (ICCV).Virtual:IEEE /CVF,2021:9620-9629.
[24] HE K,ZHANG X,REN S,et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.Las Vegas:IEEE,2016:770-778.
[25] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al.An image is worth 16x16 words:Transformers for image recognition at scale[J].arXiv preprint arXiv,2020,2010: 11929.
[26] GRILL J B,STRUB F,ALTCH F,et al.Bootstrap your own latent-a new approach to self-supervised learning[J].Advances in neural information processing systems,2020,33:21271-21284.
[27] CHEN X,HE K.Exploring simple siamese representation learning[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.Virtual:IEEE/CVF,2021:15750-15758.
[28] ZHANG X,XU Y,LIN Q,et al.Robust log-based anomaly detection on unstable log data[C]//Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering.Tallinn Estonia:ACM,2019:807-817.
[29] ABBASI M,SHAHRAKI A,TAHERKORDI A.Deep learning for network traffic monitoring and analysis (NTMA):A survey[J].Computer Communications,2021,170:19-41.
[30] CHEN J,TAM D,RAFFEL C,et al.An empirical survey of data augmentation for limited data learning in NLP[J].Transactions of the Association for Computational Linguistics,2023,11:191-211.
[31] HU F,CHEN A,WANG Z,et al.Lightweight attentional feature fusion:A new baseline for text-to-video retrieval[C]//European Conference on Computer Vision.Cham:Springer Nature Switzerland,2022:444-461.
[32] NGUYEN V A,SHAFIEEZADEH-ABADEH S,KUHN D,et al.Bridging Bayesian and minimax mean square error estimation via Wasserstein distributionally robust optimization[J].Mathematics of Operations Research,2023,48(1):1-37.
[33] NANDINI V,UMA MAHESWARI P.Automatic assessment of descriptive answers in online examination system using semantic relational features[J].The Journal of Supercomputing,2020,76(6):4430-4448.
[34] GUAN R,ZHANG H,LIANG Y,et al.Deep feature-based text clustering and its explanation[J].IEEE Transactions on Knowledge and Data Engineering,2020,34(8):3669-3680.
[35] LI B,GUO T,ZHU X,et al.SGCCL:siamese graph contrastive consensus learning for personalized recommendation[C]//Proceedings of the sixteenth ACM international conference on web search and data mining.2023:589-597.
责任编辑:陈星宇
