基于改进YOLOv5的加筋土桥台裂缝识别方法
2024-06-21李莹朱晨




摘 要:在加筋土桥台裂缝识别的问题中,由于裂缝过于不规则且细小裂缝较多,存在误检和识别率低等情况,为了准确地识别出加筋土桥台表面的裂缝,本研究提出一种基于YOLOv5和自适应特征融合ASFF的加筋土桥台裂缝识别算法。根据模块式土工合成材料加筋土桥台承载力模型试验,建立桥台裂缝验证数据集,利用改进的YOLOv5算法,识别桥台桥座中的裂缝区域。在模型建立时,为了对不同特征层进行上采样和下采样,将Neck结构中的特征融合算法改为ASFF自适应特征融合算法,以此来加强对细小裂缝的识别。除此之外,为避免在复杂背景的图像中出现误检的现象,本模型引入注意力机制CBAM,让模型重点关注桥台裂缝区域,抑制无用信息。经过实验表明,加筋土桥台裂缝位置识别准确率达到81.2%,平均精度89.2%,改进后的YOLOv5较原模型精度提升了5.9%,mAP@0.5提升了3.2%。结果表明基于改进后的YOLOv5加筋土桥台裂缝识别算法,提高了裂缝识别的准确度,具有较强的研究价值。
关键词:加筋土桥台;裂缝识别;YOLOv5;自适应特征融合
中图分类号:TP321 ""文献标识码:A ""文章编号:1673-1794(2024)02-0041-06
作者简介:李莹,滁州城市职业学院管理与信息学院教师,硕士,研究方向:大数据技术、人工智能(安徽 滁州 239000);通信作者:朱晨,河北工业大学土木与交通学院博士生,研究方向:加筋土结构抗震专业(天津300131)。
基金项目:中国地震局地震科技星火计划项目“强震动作用下台阶式加筋土挡墙破坏机理研究”( XH23067YA);滁州城市职业学院自然科研项目“基于深度学习算法的农作物病害识别研究”(2023zkyb02)
收稿日期:2023-09-10
1 引言
加筋土结构是工程支护的重要角色之一,在桥梁系统中,加筋土桥台因具有缓解桥头跳车问题、经济、施工快速等优点得到广泛的应用。但随着时间的推移,在车辆荷载、温度循环变化等外部作用下,加筋土桥台墙面、桥座等构件会产生一定裂缝[1]REF_Ref127452552\r\h\*MERGEFORMAT。加筋土桥台裂缝的产生会导致保护层对内部土工格栅的保护失效,降低结构的稳定性。因此,加筋土桥台裂缝识别尤为重要。目前,桥台裂缝识别的主要形式仍为目测和人工测量,这种方法不仅费时费力,还会出现误检漏检等现象。随着图像数字化发展,利用先进的图像数字技术对裂缝进行识别成为有效的检测方法,通过图像数字化技术,将裂缝信息提取出来,该方法与传统的人工识别相比,其检测结果更加准确。
传统的裂缝识别采用的是基于图像特征的提取方法,如图像分割、种子跟踪等。张振海等[2]REF_Ref152877470\r\h\*MERGEFORMAT通过对图像进行增强处理,凸显图像特征,再对图像去噪,最后用图像分割算法得到裂缝二值化图像。张硕等[3]REF_Ref152875690\r\h\*MERGEFORMAT提出一种基于种子扩散的裂缝识别方法,该方法实现了裂缝自动跟踪,但该方法需要事先埋好种子点,不能达到实时检测的要求。孙晓贺等[4]REF_Ref153273509\r\h\*MERGEFORMAT针对裂缝识别的抗干扰能力差等问题,提出了基于改进的种子填充算法的混凝土裂缝识别。英红等[5]REF_Ref152876023\r\h\*MERGEFORMAT通过实验表明,传统的图像识别方法在环境较为简单的情况下识别的准确率较高,裂缝一旦处于复杂的环境中,传统的图像识别方法的局限性就显示出来了。
由上述可以看出,传统的图像识别方法可以检测出裂缝区域,但易受复杂环境干扰,实时性差,且存在一定的误检率。因此,基于智能算法的裂缝识别尤为重要。近几年,随着人工智能的发展,基于深度学习的目标检测逐渐应用到各行各业。很多学者也将深度学习应用到了地面、桥梁、隧道等结构上的裂缝识别,这些深度学习算法在裂缝识别领域也得到了广泛的应用。Kim等[6]REF_Ref152878015\r\h\*MERGEFORMAT利用卷积神经网络对隧道裂缝进行识别,以此来提高检测的准确率。吴子燕等[7]REF_Ref153139722\r\h\*MERGEFORMAT结合卷积神经网络和区域生长方法对建筑裂缝区域进行识别,通过实验表明,Inception-V3网络检测效果最好,能识别出大部分裂缝区域。随着深度学习的发展,YOLO系列算法应运而生,刘星等[8]REF_Ref152878107\r\h\*MERGEFORMAT为了提高地表裂缝识别的精确度,使用YOLOv3算法对地面裂缝进行识别,并利用PeleeNet与YOLOv3相结合,该目标检测算法提高了特征的提取率。余加勇等[9]REF_Ref153273400\r\h\*MERGEFORMAT为识别出桥梁裂缝区域,利用YOLOv5定位区域位置,再结合U-Net3+算法分割出裂缝形状。高志鑫等[10]REF_Ref128571523\r\h\*MERGEFORMAT为了可以在较短的时间内,精确地识别混凝土表面的裂缝,利用机器学习中的LightGBM模型架构,根据图像的像素点,提出基于轻梯度提升树建立自动识别与分类模型,识别效果较好。
上述方法可以有效地检测出路面或者建筑上的缝隙,但是对于一些细小的裂缝,仍很难检测出来。基于此,本研究提出了基于YOLOv5和自适应特征融合ASFF的裂缝识别算法,并引入注意力机制CBAM,以此来提高模型对于细小裂缝的检测效果。
2 裂缝识别算法
2.1 YOLOv5算法
YOLOv5算法是目标检测领域重要的算法之一。
其由四个部分组成,分别为输入端、Backbone、Neck和Head。其中输入端对图像数据进行增强操作,YOLOv5中包含13种数据增强方法,包括色调变换、饱和度变换、缩放、图像翻转、图像融合等,通过数据增强可以提高模型的泛化能力。Backbone是YOLOv5的骨架网络,包含多个卷积块,主要用来提取图片中的特征区域,Backbone的输出作为Neck的输入。Neck接受了若干个来自Backbone阶段的特征图,然后对这些特征图进行相应的处理以后,再将其输出。目前主流的Neck包括FNP、BiFNP、PANet等,在YOLOv5模型中,使用的是PANet网络[11]。
YOLOv5的整体思想是将图片作为网络的输入端,利用回归的思想,对目标的位置以及类别进行预测。为了提高网络模型的运行速率,对样本图片进行变换,以此来增加正样本的数量。在样本训练的过程中,为了减少样本的训练时间,YOLOv5采用先验框的方式,对样本中的目标区域进行划分,因此,YOLOv5具有模型小、速度快、精度高等优点,比传统的裂缝识别算法更适用于加筋土桥台表面裂缝的检测。
2.2 自适应特征融合ASFF
在YOLOv5算法中,特征融合网络是以PANet为主要框架,对数据特征进行双向融合[12]。但该方法经过测试,并不能有效地检测出细小裂缝,桥台的裂缝形状复杂且粗细分布不均,检测模型需要更好地提取不同程度的裂缝特征。基于此,本研究提出将自适应特征融合网络ASFF作为裂缝识别的特征融合模型。
ASFF(Adaptively Spatial Feature Fusion)自适应空间特征融合算法由LIUS等[13]提出,其目的是使网络能够自适应地去学习每一层上的特征值,这样才能提取到特征中的重要信息。其结构图如图1所示,对不同Level上的特征图进行大小的变换,然后再将结果加权相乘之后再进行相加,经过融合后,Level1、Level2、Level3有相应的融合系数α1、β3、γ3,计算后得到新的融合特征。
x1、x2、x3分别为Level1、Level2、Level3的特征,这些不同层次的特征经过权重系数的变换,得到了新的融合特征ASFF-3,如式(1)所示。
ylij=αlij·x1→lij+βlij·x2→lij+γlij·x3→lij(1)
L表示Level层数,当L等于3时,表示需相加1~3层输出的特征大小与通道数相同,对不同层次的特征进行上采样或者下采样。权重α、β、γ是三层特征图通过1×1卷积得出,再通过归一化将其变换到范围[0,1]之间,且相加之后为1,如式(2)所示。
alij=eλlaijeλlaij+eλlβij+eλlγij(2)
2.3 注意力机制改进
注意力机制就是关注重点的信息,忽视不重要的信息,从大量的信息中获取少量核心的信息,在裂缝识别中,缝隙的区域特征是全局图像中的重要识别区域,而在图像中,由于环境的复杂,导致在裂缝的识别过程中,出现误检的现象。因此,在YOLOv5模型中,为了让模型更加关注有用的信息,抑制无用的信息,在模型中引入注意力机制。
注意力机制包括接受通道数的方式和不接受通道数的方式,例如SENet利用AvgPool提取各个通道里的特征信息,并利用全连接层连接计算出权值的大小[14]。虽然该模型体量较小,但是SENet忽视了空间之间的前后关系。为了获取空间注意力信息,关注不同空间之间的关系,CBAM利用低通道数和卷积来捕获信息,增加在空间方向上的关注度[15]。
CBAM结合通道和空间注意力,解决模型缺少注意力偏好的问题。先对每一个特征图得出一个分数,关注不同通道的重要程度,得到一个新的特征图。接下来,这个特征图再关注空间信息,学习到空间的分布,得到最终的特征图。CBAM注意力机制模型包括两个模块,通道注意力模块和空间注意力模块[16]。
通道注意力模块首先对每一个特征图进行最大池化和平均池化,对新的特征进行先升维再降维的操作,最后将得出的特征积相加,经过sigmod后,得出分数。空间注意力模块是对通道注意力模块的补充,其更关注的是目标区域的位置信息。CBAM注意力机制示意图如图2所示。
图2中第一个虚线框是通道注意力区域,第二个虚线框是空间注意力区域,在特征图输入后,通道注意力对该特征进行GAP、GMP变换,再经过MLP得到通道注意力权重并将其归一化,最后再与原始图像的特征矩阵相乘,完成通道注意力对原始特征的重新计算,其计算公式如式(3)所示。
Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))""""""""" =σ(W1(W0(Fcavg))+W1(W0(Fcmax)))(3)
上式中,Fcavg表示平均池化特征,Fcmax表示最大池化特征,特征计算完毕后送入共享多层感知机MLP网络。根据特征空间内部来产生空间注意力特征图Ms(F)∈RH,W,利用平均池化和最大池化将特征图拼接在一起,最终特征计算过程如式(4)所示。
Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))(4)
2.4 改进YOLOv5算法
在进行裂缝识别实验时,通过构建YOLOv5网络模型,来进行模型的建立。为了对不同特征层进行上采样和下采样,将Neck结构中的特征融合算法改为ASFF自适应特征融合算法,以此来加强对细小裂缝的识别。为避免在复杂背景的图像中出现误检的现象,本模型引入注意力机制CBAM,让模型重点关注桥台裂缝区域,抑制无用信息,改进后的YOLOv5模型如图3所示。
3 基于YOLOv5与自适应特征融合的加筋土桥台裂缝识别
由于加筋土桥台裂缝粗细不均,因此,将YOLOv5网络中的特征融合算法改为ASFF自适应特征融合网络,通过不同的权重设置,来达到特征融合的目的。再结合CBAM注意力机制,从空间注意力和通道注意力两个方面来获取权重,以此来加强对不同层面的特征提取,提高裂缝识别精度。
本研究测试对象来自试验——模块式土工合成材料加筋土桥台承载力模型试验[17],如图4所示。试验中,GRS桥台模型由下部结构、上部结构以及桥座组成,在试验中,随着千斤顶力量的增加,桥台桥座开始出现裂缝,本模型的验证图片来自于该试验中的裂缝区域。
3.1 数据集
本研究主要针对加筋土桥台裂缝进行识别。训练集由1769张裂缝图片组成,按照7∶3的比例划分为训练集以及测试集。数据准备好后,利用Labelimg工具对图片进行标注。图片分辨率为1400*1200像素。具体统计数据见表1。
3.2 数据增强
为了提高模型的泛化能力,YOLOv5对图像进行了增强操作,除了基本的图像增强外,如色调变换、饱和度变换、缩放等,YOLOv5还利用了Mosaic方法对图像进行增强,该种方法将4张图片通过随机缩放或裁剪后,再由其拼接为一张完整的图片,以此来增加样本的丰富性[18]。拼接图片如图5所示。
3.3 数据训练
将收集的原始1769张裂缝图片利用LabelImg工具进行标注。并以7∶3的比例将数据集划分为训练集与测试集。将桥台实验中实验图片作为验证集。
加筋土桥台裂缝识别模型训练时所采用的是迁移学习的方法,迁移学习是利用模型已学习到的知识来改进新的学习任务的学习效果。本实验将由COCO128数据集预训练而来的YOLOv5模型作为训练的初始模型,通过实验找到模型的最优实验参数,设置训练批量大小为 32张、输入图像 1400×1200 pixels、最大训练轮数为300次,与此同时,为了避免在训练的过程中出现过拟合的现象,本研究将采用网络输出的最佳训练权重来构建桥台裂缝识别模型,实验环境配置如表2所示,模型训练参数如表3所示。
3.4 评价指标
评价指标包括准确率(Precision)、召回率(Recall)、平均精度均值(Mean Average Precision),将带有裂缝的加筋土桥台图像送入裂缝检测模型,统计正确检测的数量TP以及错误检测数量FP,最终得出评价指标P、R、mAP50,计算公式如式(5)~(7)所示。
P=TPTP+FP×100%(5)
R=TPTP+FN×100%(6)
mAP=1c∑ci=1APi(7)
4 实验与分析
4.1 测试对象
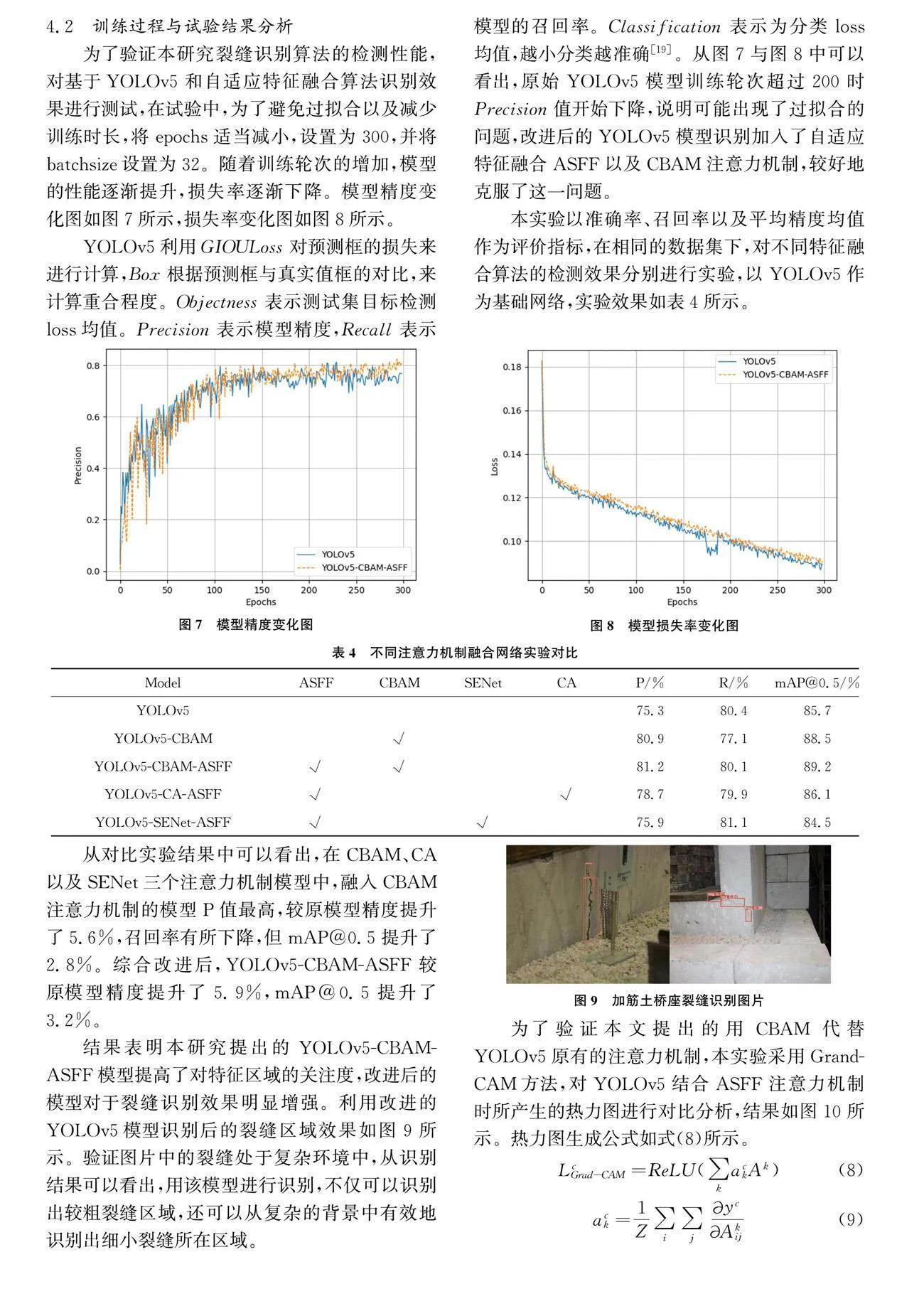
验证图片选自模块式土工合成材料加筋土桥台承载力模型试验中的桥台桥座裂缝图像,随着桥座竖向荷载增加,桥座开始出现裂缝。本实验将利用改进的YOLOv5网络模型对桥台桥座裂缝进行识别,将Neck结构中的特征融合算法改为ASFF自适应特征融合算法,并引入注意力机制CBAM,抑制无用信息,验证图像如图6所示。
4.2 训练过程与试验结果分析
为了验证本研究裂缝识别算法的检测性能,对基于YOLOv5和自适应特征融合算法识别效果进行测试,在试验中,为了避免过拟合以及减少训练时长,将epochs适当减小,设置为300,并将batchsize设置为32。随着训练轮次的增加,模型的性能逐渐提升,损失率逐渐下降。模型精度变化图如图7所示,损失率变化图如图8所示。
YOLOv5利用GIOULoss对预测框的损失来进行计算,Box根据预测框与真实值框的对比,来计算重合程度。Objectness表示测试集目标检测loss均值。Precision表示模型精度,Recall表示模型的召回率。Classification表示为分类loss均值,越小分类越准确[19]REF_Ref144321769\r\h\*MERGEFORMAT。从图7与图8中可以看出,原始YOLOv5模型训练轮次超过200时Precision值开始下降,说明可能出现了过拟合的问题,改进后的YOLOv5模型识别加入了自适应特征融合ASFF以及CBAM注意力机制,较好地克服了这一问题。
本实验以准确率、召回率以及平均精度均值作为评价指标,在相同的数据集下,对不同特征融合算法的检测效果分别进行实验,以YOLOv5作为基础网络,实验效果如表4所示。
从对比实验结果中可以看出,在CBAM、CA以及SENet三个注意力机制模型中,融入CBAM注意力机制的模型P值最高,较原模型精度提升了5.6%,召回率有所下降,但mAP@0.5提升了2.8%。综合改进后,YOLOv5-CBAM-ASFF较原模型精度提升了5.9%,mAP@0.5提升了3.2%。
结果表明本研究提出的YOLOv5-CBAM-ASFF模型提高了对特征区域的关注度,改进后的模型对于裂缝识别效果明显增强。利用改进的YOLOv5模型识别后的裂缝区域效果如图9所示。验证图片中的裂缝处于复杂环境中,从识别结果可以看出,用该模型进行识别,不仅可以识别出较粗裂缝区域,还可以从复杂的背景中有效地识别出细小裂缝所在区域。
为了验证本文提出的用CBAM代替YOLOv5原有的注意力机制,本实验采用Grand-CAM方法,对YOLOv5结合ASFF注意力机制时所产生的热力图进行对比分析,结果如图10所示。热力图生成公式如式(8)所示。
LcGrad-CAM=ReLU(∑kackAk)(8)
ack=1Z∑i∑jycAkij(9)
式(8)中,A表示某个卷积层输出的特征层,k表示在特征层A中的第k个通道,c表示模型中的类别,Ak表示特征层A中通道数k,ack表示Ak的权重[20]。其中,ack的计算公式如式(9)所示。
通过实验,得出热力图识别结果如图10所示。改进后的YOLOv5能够更好地捕捉特征部位,热力图覆盖更加明显,不仅关注通道信息,也关注了位置信息,并且减少非重要区域的特征权重,加强了对细小裂缝的识别。
5 总结
文章针对加筋土桥台裂缝识别率低及误检等情况,提出了一种基于YOLOv5与自适应特征融合的加筋土桥台裂缝检测方法,将YOLOv5中的Neck部分的PANet改为ASFF自适应特征融合,并结合CBAM注意力机制,加强对细小裂缝区域的特征捕获。该方法采用深度学习模型对加筋土桥台裂缝图像进行分析,识别裂缝位置。在对加筋土桥台表面裂缝区域的检测中,识别准确率达到81.2%,平均精度89.2%,改进后的YOLOv5较原模型精度提升了5.9%,mAP@0.5提升了3.2%。实验结果表明,该方法能有效识别桥台实验中桥座裂缝位置,且精度较原模型有所提高。在后续中研究中,可对裂缝标注更加精细化,以此来进一步提高模型的检测精度。
[参 考 文 献]
[1]
张逍, 徐超, 王裘申, 等. 加筋土桥台承载特性的载荷试验研究[J]. 岩土力学,2020,41(12):4027-4034.
[2] 张振海,尹晓珍,王阳萍,等.基于特征分析的图像式地铁隧道裂缝检测方法研究[J].铁道科学与工程学报,2019,16(11):2791-2800.
[3] 张硕,张尤赛,许智勋,等.一种基于种子点扩散的隧道裂缝半自动提取方法[J].计算机与数字工程,2017,45(2):387-391.
[4] 孙晓贺,施成华,刘凌晖,等.基于改进的种子填充算法的混凝土裂缝图像识别系统[J].华南理工大学学报(自然科学版),2022,50(5):127-136.
[5] 英红,刘杨.基于动态最短路径识别水泥路面裂缝的方法[J].郑州大学学报(理学版),2017,49(2):84-90.
[6] KIM J,SHIM S,CHA Y,et al.Lightweight pixel-wise segmentationfor efficient concrete crack detection using hierarchical convolu-tional neural network[J].Smart Materials and Structures, 2021,30(4) :045023.
[7] 吴子燕,贾大卫,王其昂.基于卷积神经网络与区域生长法的建筑裂缝识别[J].应用基础与工程科学学报,2022,30(2):317-327.
[8] 刘星,莫思特,张江,等.轻量化模型的PeleeNet_yolov3地表裂缝识别[J].哈尔滨工业大学学报,2023,55(4):81-89.
[9] 余加勇,刘宝麟,尹东,等.基于YOLOv5和U-Net3+的桥梁裂缝智能识别与测量[J].湖南大学学报(自然科学版),2023,50(5):65-73.
[10] 高治鑫,包腾飞,李扬涛.基于机器学习的混凝土坝表面裂缝快速识别方法[J].水电能源科学,2022,40(4):95-98.
[11] ULTRALYTICS.YOLOv5 (2020)[EB/OL].(2020-06-10)[2022-06-01].https://github.com/ultralytics/ ultra-lytics/yolov5.
[12] 冷坤,秦伦明,王悉.基于CA-ASFF-YOLOv4的交通标志识别研究[J].计算机工程与应用,2023,59(17):169-177.
[13] LIU S,HUANG D,WANG Y.Learning Spatial Fusion for Single-Shot Object Detection[J].arXiv Preprints,2019,arXiv:1911.09516.
[14] JIE H,LI S,GANG S,et al.Squeeze-and-excitation networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,42(8):2011-2023.
[15] 胡丹丹,张忠婷,牛国臣.融合CBAM注意力机制与可变形卷积的车道线检测[J/OL].北京航空航天大学学报,1-14[2024-03-06].https://doi.org/10.13700/j.bh.1001-5965.2022.0601.
[16] WOO S,PARK J,LEE J Y,et al.CBAM: convolutional blockattention module[EB/OL].(2023-02-20)[2022-10-02].https://arxiv.org/abs/1807.06514.
[17] 朱晨.模块式加筋土桥台承载力模型试验研究及数值模拟[D].河北:防灾科技学院,2021:12-13.
[18] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once: unified, real-time object detection[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE,2016:779-788.
[19] REDMON J,FARHADI A.YOLO9000:Better,faster,stronger[C]//Proceedings of the IEEE Conference on Computer vision and Pattern Recognition.New York:IEEE,2017:7263-7271.
[20] REDMON J,FARHADI A.Yolov3: An incremental improvement[J].arXiv,2018: 1804.02767.
Crack Identification of Reinforced Soil Abutment Based on Improved YOLOv5
Li Ying, Zhu Chen
Abstract: In the problem of crack identification of reinforced soil abutment, the cracks are too irregular and there are many small cracks, resulting in 1 detection and low recognition rate. In order to accurately identify cracks on the surface of reinforced soil abutment, a crack identification algorithm based on YOLOv5 and adaptive feature fusion ASFF is proposed in this paper. According to the bearing capacity model test of modular geosynthetic reinforced soil abutment, the data set of abutment crack verification is established, and the crack area in the abutment is identified by the improved YOLOv5 algorithm. In order to up-sample and down-sample different feature layers, the feature fusion algorithm in Neck structure was changed to ASFF adaptive feature fusion algorithm to enhance the recognition of small cracks. In addition, in order to avoid the phenomenon of 1 detection in images with complex background, the attention mechanism CBAM is introduced in this model to make the model focus on the crack area of the abutment and suppress useless information. Experiments show that the crack location identification accuracy of reinforced soil abutment reaches 81.2% and the average accuracy is 89.2%. Compared with the original model, the accuracy of the improved YOLOv5 is increased by 5.9% and mAP@0.5 by 3.2%. The results show that the improved YOLOv5 reinforced soil abutment crack identification algorithm improves the accuracy of crack identification and has strong research value.
Key words:reinforced earth abutment; crack identification; YOLOv5; adaptive feature
fusion
责任编辑:陈星宇
