一种基于CNN与位姿自适应的运动模型生成方法
2024-06-17童立靖,徐光亚,冯金芝

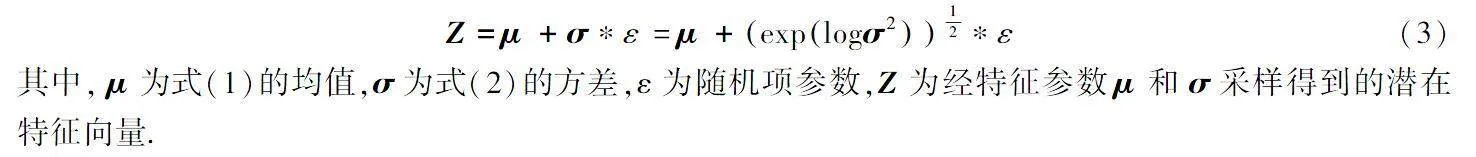

摘要:针对基于数据驱动的人体运动模型生成网络存在的模型生成精度不高,生成模型稳定性不好的问题,提出了一种基于CNN与位姿自适应的三维人体运动模型生成方法.首先,为提升人体运动模型生成网络中编码器对输入运动序列的特征提取效果,在变分自编码器中引入CNN卷积网络,便于更好地从运动数据中提取运动特征;其次,在运动生成网络中引入卷积网络,从而完成运动特征、路径参数与生成模型的自适应映射,并最终生成沿设定路径行进的三维人体运动模型.实验结果表明,与CAE算法以及CAE改进算法相比,该方法有效降低了重构损失,能够生成更加准确、自然的三维人体运动模型.
关键词:卷积神经网络;位姿自适应;运动模型生成;特征提取
中图分类号:TP391文献标志码:A
A Motion Generation Method Based on CNN and Pose Adaptation
TONG Lijing, XU Guangya, FENG Jinzhi
(School of Information, North China University of Technology, Beijing 100144, China)
Abstract: A 3D human motion model generation method based on CNN and pose adaptation is proposed to address the issues of low accuracy and poor stability of data-driven human motion model generation network. Firstly, to improve the feature extraction performance of the encoder in the human motion model generation network for input motion sequences, a CNN convolutional network is introduced into the variational autoencoder to better extract motion features from motion data. Secondly, a convolutional network is introduced into the motion generation network to achieve the adaptive mapping of motion features, path parameters, and generation model. Finally, a 3D human motion model is generated along the set path. The experimental results show that compared with CAE algorithm and CAE improved algorithm, the proposed method can effectively reduce the reconstruction losses and generate a more accurate and natural 3D human motion model.
Key words: convolutional neural network; posture adaptation; motion model generation; feature extraction
三维人体运动模型生成技术是计算机图形学和计算机视觉领域中一个重要研究方向[1].该技术的目标是:给定一组记录人体动作姿态的运动序列,借助相关算法从已知的运动序列中学习其中的运动机制,再通过数据重构的方式,在虚拟空间生成运动的人体模型[2-3].该技术被广泛应用于人体运动分析和识别、虚拟现实技术、电影特效和游戏制作等领域[4-7].
近些年来,深度学习开始应用于三维人体运动模型的生成技术中,常见的研究方向有结合图像的运动模型生成方法[8]、结合视频的方法[9]以及结合动作捕捉的方法[10].结合深度学习的三维人体运动模型生成技术,将神经网络强大的运算能力用于处理运动数据内在的抽象逻辑特征,极大地提高了运动生成的质量和效率[11-12].Holden等[13]提出一种用于运动合成与编辑的卷积神经网络结构,通过卷积神经网络获取运动序列的运动流形,运动流形通过解码重建运动序列,实现了角色模型的运动合成功能.Zhou等[14]在Holden团队研究的基础上,通过改变卷积网络的结构,使网络可以更好地从动作序列中获取运动特征,生成的角色运动包含更加丰富的运动特征.Holden等[15]又提出的一种PFNN方法,用于对三维人体模型进行建模生成以及运动的实时控制,该方法使用相位函数记录运动状态,使用RNN网络处理运动信息,通过更新运动数据,最终将运动数据处理后生成可控制的三维人体运动模型.Tang等[16]提出一种分层静态-动态编码器-解码器结构,该结构结合了残差CNN技术,其中动态模型用于预测人体的动态变化,静态模型用于记录最新的运动帧信息,两分支共同作用于虚拟人模型运动的生成和预测.Ling等[17]提出一种使用Motion VAEs的角色模型控制方法,采用了变分自编码器思想,其中编码器的输入为相邻的两帧运动数据Pt-1和Pt,并输出特征参数μ和σ,然后使用参数μ和σ确定潜在空间Z;解码器使用MANN-style混合专家神经网络,通过Pt-1和Z重建Pt,由解码器生成的Pt在训练或是运行期间会反馈给输入以用来预测下一帧动作.虽然这些基于数据驱动的人体运动模型生成方法均能够生成一定效果的人体运动模型,但仍然存在对运动特征提取不够精确、生成的三维人体运动模型在运动时运动连贯性不强,且生成的运动姿态有时不太稳定、易出现运动轨迹偏移和脚步滑动等问题[18].针对上述问题,本文提出了一种基于CNN与位姿自适应的运动模型生成方法.
1运动模型生成网络总体结构
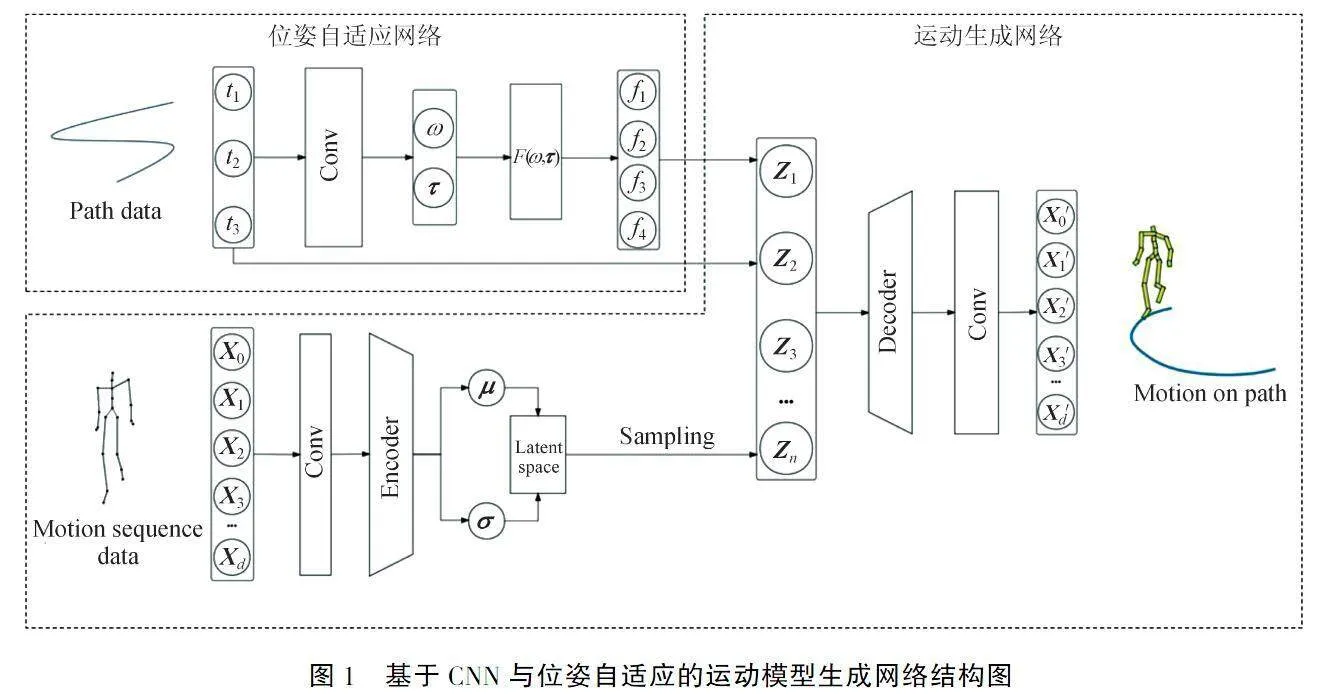
基于CNN与位姿自适应的运动模型生成网络整体结构如图1所示,分为运动生成网络与位姿自适应网络两部分.
在运动生成网络训练时,使用基于CNN的编码器对输入的运动数据X={X0,X1,X2…Xd}进行初始特征提取,提高网络对有效运动特征的学习能力,初始提取的运动特征向量经过VAE编码的处理生成特征参数:均值μ和标准差σ.由特征参数得到有关运动特征的潜在分布,从潜在分布中进行采样,得到潜在特征向量Z={Z1,Z2…Zn}.通过得到的潜在特征向量,对解码器进行网络训练,生成符合人体潜在运动特征的解码器网络.
在位姿自适应网络中,将给定的路径参数T输入到一个CNN卷积网络中,经位姿自适应机制的处理,得到相应的步态参数:步频ω和单步时长τ.将步态参数代入到步态矩阵函数公式,获得脚步与地面的接触参数.将路径参数与接触参数相结合,经卷积网络的映射采样得到潜在分布的潜在特征向量Z={Z1,Z2…Zn}.
最后,在运动模型生成时,使用训练完成的运动生成网络解码器对特征向量Z={Z1,Z2…Zn}解码,获取符合输入运动特征的运动序列,运动序列经处理后得到沿着给定路径运动的三维人体模型.
2基于CNN的运动生成网络
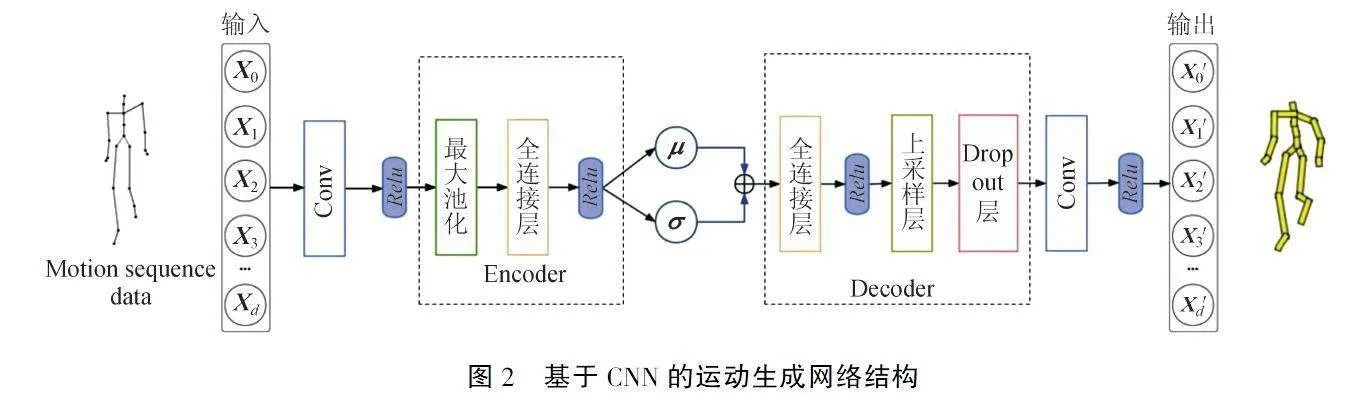
为了生成模型更加准确、自然,提升生成网络的运动特征提取能力,基于编码器和解码器两部分组成的运动生成网络如图2所示:编码器完成对运动特征的提取,解码器完成三维人体运动模型的生成,使得解码器输出的运动序列特征与输入尽可能一致.
2.1网络编码器的实现
在运动生成网络的编码器中,首先通过卷积层对人体运动数据在时间序列维度进行一维卷积操作X*W0+b0,其中W0∈Rw0*m*d,b0∈Rm.w0为卷积核大小,d为自由度,m为卷积核数量.然后进行最大池化操作,池化方向为时间步序列方向,记为P(·).其次,将池化层输出数据使用全连接层进行降维,记为D1(·),D2(·),再经过激活函数层,分别得到μi和logσi2,如式(1)REFZEqnNum900872\h、(2)REFZEqnNum660254\h所示.由μi和logσi2构成标准正态分布并进行采样,即可获得能够体现数据Xi特征的样本数据Zi.
μ=ReluD1PReluX*W0+b0(1)
logσ2=ReluD2PReluX*W0+b0(2)
考虑到在进行反向传播时,潜在空间采样操作无法直接进行逆向传导,根据重参数化方法,构造潜在空间的正态分布特征向量Z,如式(3)REFZEqnNum931463\h所示,以便在反向传播时训练模型参数.
Z=μ+σ*ε=μ+explogσ212*ε(3)
其中, μ为式(1)REFZEqnNum900872\h的均值,σ为式(2)REFZEqnNum660254\h的方差,ε为随机项参数,Z为经特征参数μ和σ采样得到的潜在特征向量.
2.2网络解码器的实现
在运动生成网络中,解码器的作用是将潜在空间分布中采样得到的潜在特征向量构造生成新的运动序列,解码器进行运动序列数据重构的解码操作记为DE(·).首先对Zi通过全连接层进行维度还原,记为D3(·);将还原后的特征数据经过上采样操作拓展特征数据的尺寸,记为U(·);然后在进行卷积操作前,加入Dropout层,增强网络的泛化能力,避免网络过拟合,记为DR(·);最后,经过卷积层还原并输出运动序列,如式(4)REFZEqnNum693066\h所示.
DE(Z)=DRUD3Z-b0*W0(4)
其中,在反卷积操作中,b0为偏置项,W0为卷积核,W0为W0的转置,*为反卷积操作,W0∈Rw0*m*d,W0∈Rm* d*w0,b0∈Rd.
3基于CNN的位姿自适应网络
为了改善运动生成网络生成模型的稳定性与自适应性,使用基于CNN的位姿自适应机制,使生成的三维人体运动模型运动姿态更加稳定、自然.
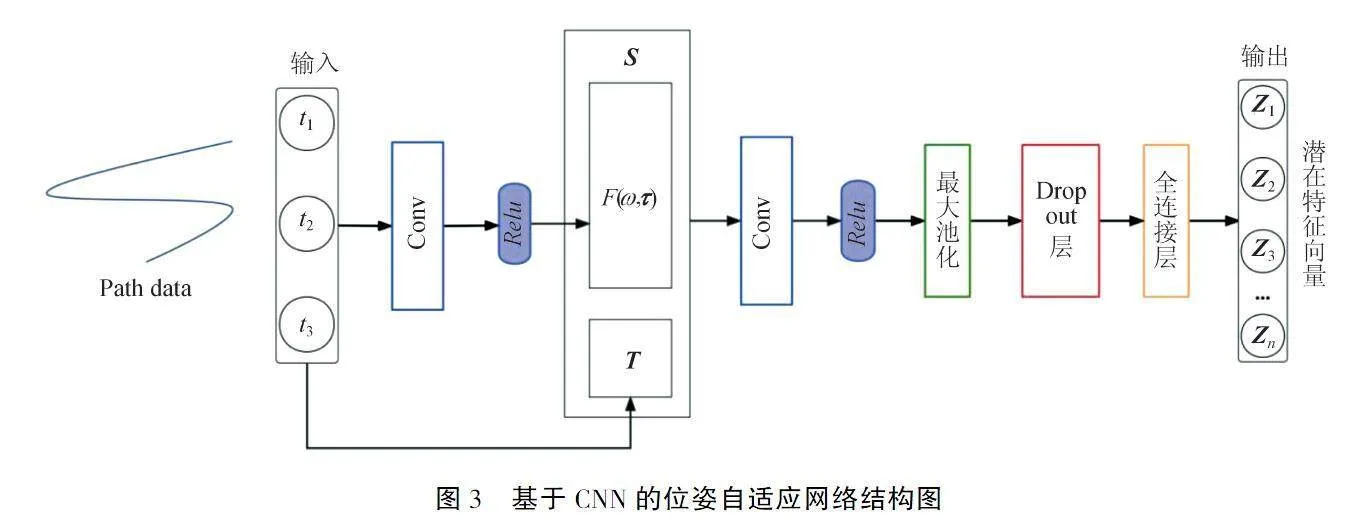
3.1位姿自适应网络结构
基于CNN的位姿自适应网络结构如图3所示,该网络将给定的路径参数,通过CNN卷积网络映射到潜在空间的特征向量,潜在特征向量根据路径参数对后续的步态输出具有一定的自适应调整作用.潜在特征向量经运动生成网络的解码器解码,输出模型运动序列数据,模型运动序列数据经渲染处理生成沿给定路径运动的三维人体运动模型.
将路径参数T={t1,t2,t3}作为输入,经过卷积网络得到运动步频参数ω和单步时长参数τ,τ={τlt,τlh,τrt,τrh}为左右脚和前后脚掌四个单步时长参数.由ω与τ构造步态矩阵F(ω,τ),F(ω,τ)∈{-1,1}n×4.由步态矩阵F(ω,τ)和路径参数T共同构成运动特征向量S=[T,F(ω,τ)],并将向量S映射到潜在空间,由运动特征向量S与潜在空间的潜在特征向量Z={Z1,Z2…Zn}之间形成的映射关系,可以针对路径信息和脚部与地面接触参数信息自适应地选取潜在特征向量生成运动序列,生成特征相符的运动序列.上述映射关系可由CNN卷积网络进行构造.
首先,将运动特征向量进行卷积操作,记为S*W1+b1,其中:W1为卷积核,b1为卷积偏置项,*为卷积操作.然后,进行最大池化操作,记为P(·).其次,Dropout层操作和全连接层操作分别记为DR(·)和D(·).最后,经全连接层进行降维后得到的数据映射相应的潜在特征向量,再经过解码器的解码获得运动序列.路径参数与潜在特征向量的映射关系Ψ(T)如式(5)REFZEqnNum410304\h所示:
Ψ(T)=DDRPReluS*W1+b1(5)
3.2位姿自适应机制
位姿自适应机制的引入能够在运动生成时自适应地计算模型脚部与地面的接触参数,优化模型的运动姿态,改善模型运动不稳定的问题.
在三维人体运动模型生成过程中,网络的输入为运动路径参数,为了计算路径参数对生成运动模型的影响,使用步态矩阵函数对生成模型脚部与地面的接触状态进行建模计算.选取左脚脚跟、左脚脚尖、右脚脚跟及右脚脚尖四个关节点与地面的接触时长τ={τlt,τlh,τrt,τrh}与模型步频ω作为函数输入,步态矩阵F(ω,τ)的计算如式(6)REFZEqnNum849782\h所示.
Fω,τ=signsincω+ah-bh-τlhsignsincω+at-bt-τltsignsincω+ah+π-bh-τrhsignsincω+at+π-bt-τrtT(6)
其中矩阵F(ω,τ)∈{-1,1}n×4为每一帧左脚跟lh、左脚趾lt、右脚跟rh和右脚趾rt与地面的接触状态,接触时为1,不接触时为-1.ah和at分别是调整脚跟和脚趾相位的系数,bh和bt分别是调整脚跟和脚尖接触持续时间的系数,c是可以缩放步进频率的常数,ω和τ为模型的运动频率与单步时长.
为生成图3中的潜在特征向量,需首先构建运动特征向量S,如式(7)REFZEqnNum163835\h所示:
S=[T,Fω,τ](7)
式中,ω和τ由卷积网络生成,式(7)REFZEqnNum163835\h的进一步展开如式(8)REFZEqnNum168304\h所示.
S=T,FReluT*W2ω+b2ω),Relu(T*W2τ+b2τ(8)
其中W2ω,b2ω为ω生成网络的卷积核与偏置项,W2τ,b2τ为τ生成网络的卷积核与偏置项.据式(8)REFZEqnNum168304\h中的运动特征向量S,代入式(5)REFZEqnNum410304\h可得潜在特征向量Ψ(T),潜在特征向量Ψ(T)代入式(4)REFZEqnNum693066\h,经过运动模型生成网络中解码器的解码,即可生成步态自适应于路径的运动模型序列.
4实验结果与分析
4.1实验参数
实验的硬件配置如下:CPU为IntelCorei5-12500H@2.5 GHz,内存为16 GB,内置GPU为
NVIDIA GeForce RTX2050,操作系统为Windows10.训练环境为Google Colab;训练GPU为Tesla T4、NVIDIA A100-SXM4-40GB.软件环境:python3.8、Keras2.10.0以及TensorFlow 2.10.0深度学习框架.
4.2对比实验
为验证基于CNN的运动生成网络的运动生成效果,将该网络同另外两种运动生成网络重构的运动序列进行对比,对比指标为重构误差.同时,选取运动序列间关节平滑性指标来对比不同算法重构序列的连续性.
4.2.1运动生成效果对比
1)重构损失对比
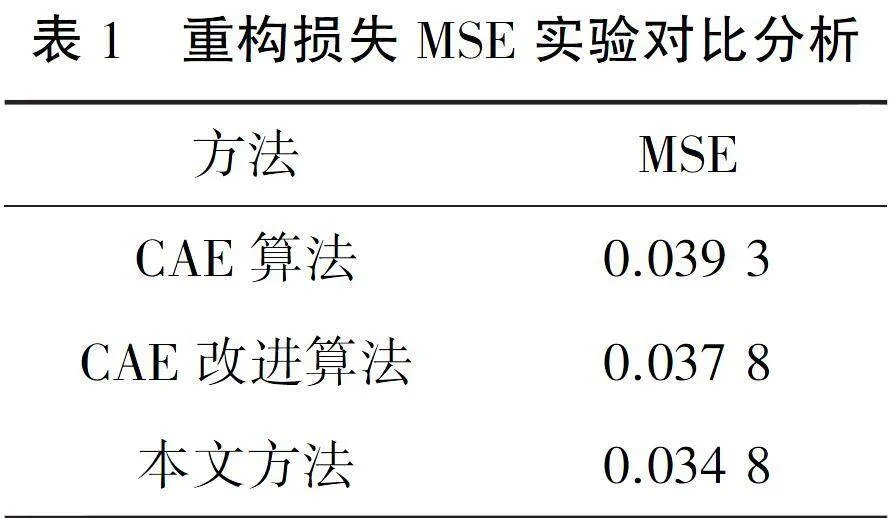
实验的数据集选用公开数据集CMU MOCAP运动捕捉数据集,选用均方误差(MSE)作为衡量指标.均方误差是指通过编码器提取运动序列特征,再通过解码器将运动特征重构为运动序列数据,计算重构运动序列数据与原始运动序列数据之间差值的一种衡量指标.MSE指标越大,运动重构情况越差.三种方法的重构损失对比如表1所示.
本文方法相比CAE算法[19],最终均方误差降低约0.004 5,相比CAE改进算法[20],均方误差降低约0.003,能够完成较为符合输入特征的运动重构.
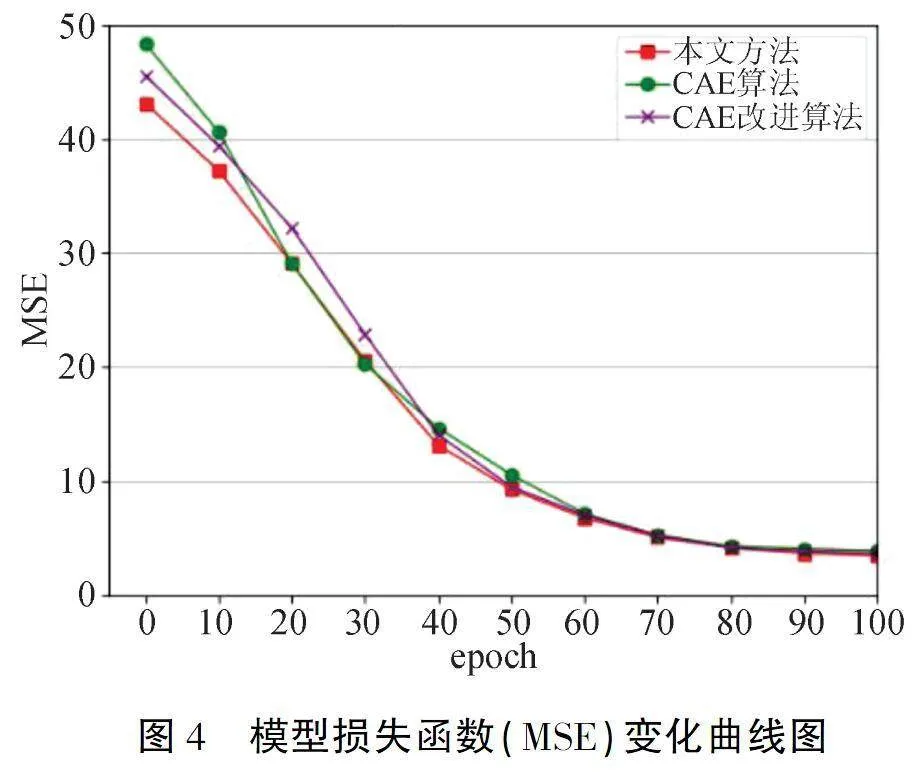
图4为在训练过程中,同时对上述三种网络迭代训练100轮后生成的损失曲线.其中X轴坐标为训练的轮数,即epoch;Y轴坐标为模型训练中的MSE误差大小(这里将MSE数值放大100倍以便于观察).从图4可以看出,三类算法模型随着迭代轮数的增加,误差值逐渐收敛并趋于稳定,最终误差值接近于0.03.当该模型迭代100轮时,三类算法模型的误差值达到最小.其中,本文的运动生成网络相较另外两种算法,曲线最终的误差值最低.
2)运动序列连续性对比
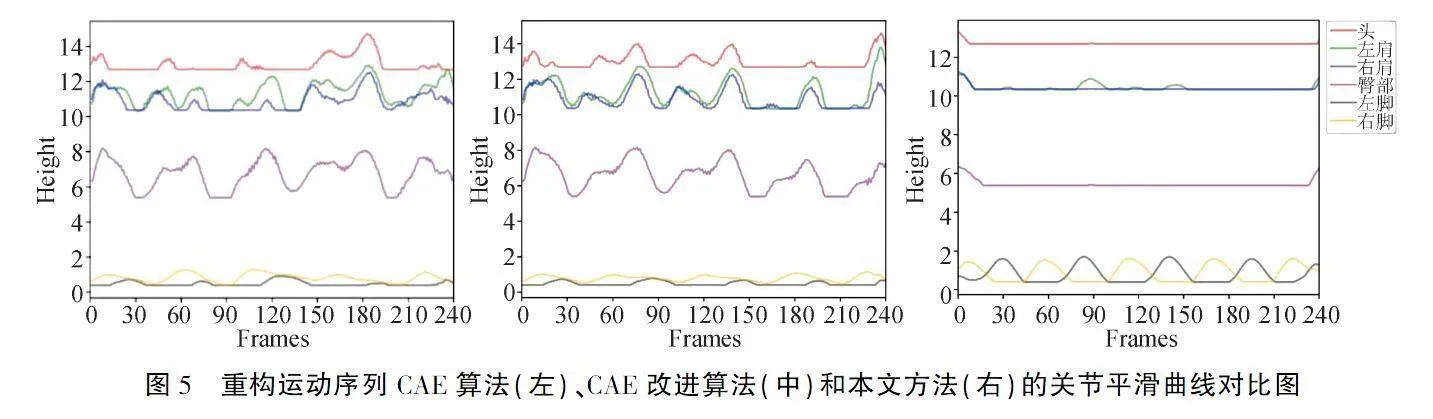
实验选取运动序列间关节平滑性的指标来对比不同算法模型在有关运动生成的连续性.首先,分别使用三种算法模型训练好的编码网络对运动序列进行编码,得到有关运动序列的潜在运动特征向量,再将特征向量通过解码器重构生成运动序列;然后,从运动序列中选取:头、左肩、右肩、臀部(根节点)、左脚、右脚六个关节的高度值,其高度曲线如图5所示.
图5中,横轴为生成运动序列的帧数,纵轴为关节对应的高度,不同颜色曲线代表不同关节在连续运动中的高度曲线.图5(右)较图5(左)、图5(中)的头、肩、臀的波动幅度较小,表明本文算法比CAE与CAE改进算法的运动稳定性好;图5(右)较图5(左)、图5(中)脚步的波动幅度较大,且规律性较强,表明本文算法能够提供较好的运动节奏.
4.2.2运动生成效果对比
从位姿稳定性、运动轨迹偏移程度以及足部滑动情况三个方面,将本文方法与CAE改进算法生成的运动模型进行对比.
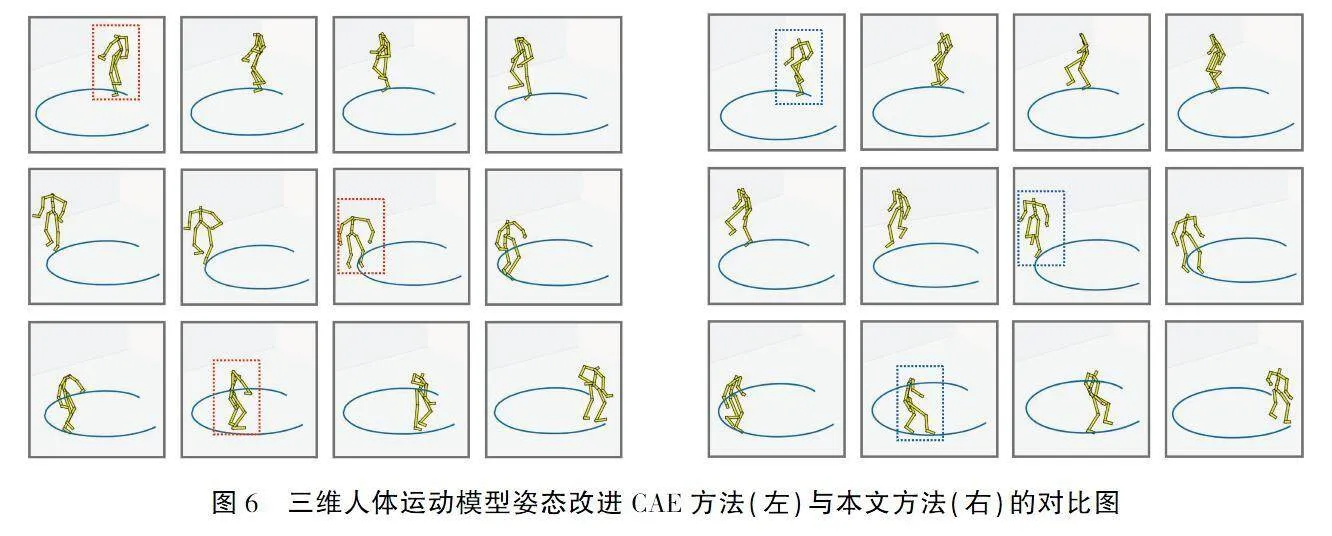
1)位姿稳定性对比
从生成动画中顺序选取12帧图像对比两种方法生成的模型姿态稳定性.图6(左)为CAE改进方法生成的三维人体运动模型姿态,图6(右)为本文方法生成的三维人体运动模型姿态.图6(左)第一行红框圈出的骨架手部关节扭曲变形较为严重,图6(左)第二行红框圈出的骨架位姿较为松散,图6(左)第三行红框圈出的骨架足部运动不够自然.而相比图6(右)中蓝框所圈的骨架,本文方法生成的三维人体模型在运动中骨架的摆动性较小,姿态更加自然、稳定.
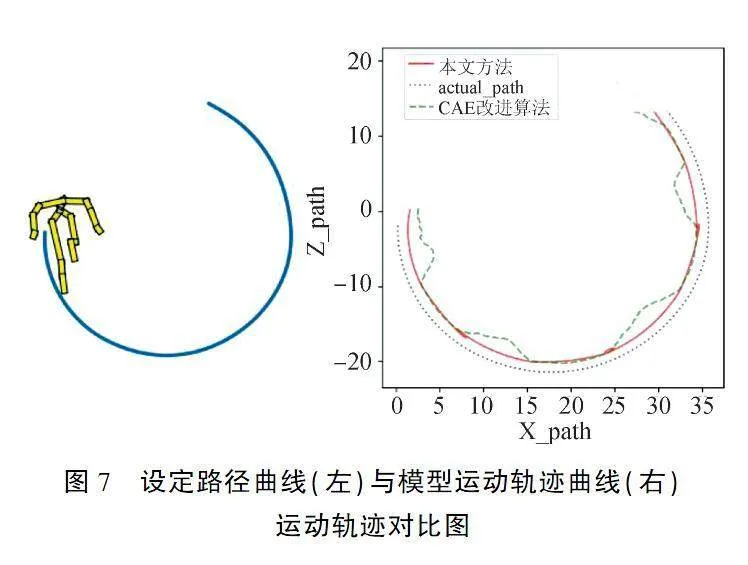
2)运动轨迹偏移对比
图7(左)为系统设定的路径曲线,图7(右)为两种方法实际生成的运动轨迹曲线.实线为本文方法生成模型运动时,模型根节点在地面的投影产生的运动轨迹,虚线曲线为CAE改进方法产生的运动轨迹,点线为设定路径.本文方法生成的运动轨迹相比于CAE改进算法更贴近于系统设定的路径,未出现较大的轨迹偏移.
3)足部滑动情况对比
图8为三维人体运动模型运动过程中左右脚距地面的高度曲线,其中实线为本文方法的高度曲线,虚线为CAE改进算法的高度曲线.当曲线高度长时间为零时,表明足部在运动中出现滑动情况.在图8(a)与8(b)的左脚高度轨迹中,CAE改进方法生成的运动模型在运动过程中,左脚接触地面时间较长,发生了足部滑动;而本文方法生成的三维人体运动模型在运动过程中,相比于CAE改进算法,足部与地面接触的时间较短,周期性较强.图8(c)与图8(d)分别为其右脚高度轨迹的对比情况,本文方法避免了悬空迈步的情形.
5结语
本文提出了一种基于CNN与位姿自适应的运动模型生成方法,使得生成的三维人体运动模型具有较好的准确性与稳定性.通过基于CNN的运动生成网络增强了对运动特征的提取能力,使得生成模型的准确性得以提升;通过在运动生成网络中引入位姿自适应机制,提高了运动模型对设定路径的自适应性.对比实验表明,该方法可生成较为准确和稳定的三维人体运动模型,并验证了该方法的有效性.
[参考文献]
[1]XUE Y.Analysis of computer graphic image design and visual communication design[C].2020 5th International Conference on Mechanical,Control and Computer Engineering.NJ:IEEE,2020:2449-2452.
[2]王艳芳,巩晓秋.计算机图形学与图形图像的处理技术研究[J].科技资讯,2022,20(4):16-18.
[3]张明君.三维动画与计算机图形图像理论研究[J].数字技术与应用,2020,38(5):55-56.
[4]马建晓,刘伟.基于实时权重的虚拟人运动合成方法[J].计算机技术与发展,2021,31(5):215-220.
[5]朱煜,赵江坤,王逸宁,等.基于深度学习的人体行为识别算法综述[J].自动化学报,2016,42(6):848-857.
[6]YANG Y,LUO X,HU X.Research on virtual human development based on motion capture[C].2022 International Conference on Culture-Oriented Science and Technology.NJ:IEEE,2022:216-220.
[7]黄珊珊,郭忠文,孔勇强.基于骨架模型的人体动作识别方法[J].中国海洋大学学报(自然科学版),2019,49(S2):164-169.
[8]NAKATSUKA C,XU J,TASAKA K.Learning joint twist rotation for 3D human pose estimation from a single image[C].16th International Joint Conference on Computer Vision,Imaging and Computer Graphics Theory and Applications.Setubal Portugal:SciTePress,2021:379-386.
[9]TAO S,ZHANG Z.Video-based 3D human pose estimation research[C].17th IEEE Conference on Industrial Electronics and Applications.NJ:IEEE,2022:485-490.
[10]周兵.基于深度学习的运动捕捉数据建模研究及其应用[D].泉州:华侨大学,2018.
[11]YANG Y,LIU G,GAO X.Motion guided attention learning for self-supervised 3D human action recognition[J].IEEE Transactions on Circuits and Systems for Video Technology,2022,32(12):8623-8634.
[12]LI J,VILLEGAS R,CEYLAN D,et al.Task-generic hierarchical human motion prior using VAEs[C].9th International Conference on 3D Vision.NJ:IEEE,2021:771-781.
[13]HOLDEN D,SAITO J,KOMURA T,et al.Learning motion manifolds with convolutional autoencoders[C].SIGGRAPH Asia,2015.NY:ACM,2015:1-4.
[14]ZHOU D,FENG X,YI P,et al.3D human motion synthesis based on convolutional neural network[J].IEEE Access,2019,7:66325-66335.
[15]HOLDEN D,KOMURA T,SAITO J.Phase-functioned neural networks for character control[J].ACM Transactions on Graphics,2017,36(4):42(1-13).
[16]TANG J,LIU J,YIN J Q.A Hierarchical static-dynamic encoder-decoder structure for 3D human motion prediction with residual CNNs[J].Mathematical Problems in Engineering,2020,2020:7064910(1-12).
[17]LING H Y,ZINNO F,CHENG G,et al.Character controllers using motion VAEs[J].ACM Transactions on Graphics,2020,39(4):40(1-12).
[18]ZHANG L,WANG F,GAO Z,et al.Research on the stationarity of hexapod robot posture adjustment[J].Sensors (Switzerland),2020,20(10):1-21.
[19]HOLDEN D,HABIBIE I,KUSAJIMA I,et al.Fast neural style transfer for motion data[J].IEEE Computer Graphics and Applications,2017,37(4):42-49.
[20]KAUFMANN M,AKSAN E,SONG J,et al.Convolutional autoencoders for human motion infilling[C].2020 International Conference on 3d Vision.NJ:IEEE,2020:918-927.
[责任编辑赵小侠]
