计算机自适应测验有效性检验的探索与优化
2024-06-16李心钰王超陆宏
李心钰 王超 陆宏
摘要:计算机自适应测验(Computerized Adaptive Testing,CAT)的有效性检验是评定测验生成过程以及解释测验结果是否恰当、合理的必要步骤,然而系统性探讨CAT有效性检验的研究相对较少。为弥补其不足,文章在剖析CAT有效性检验内涵的基础上,首先梳理了基于IRT的题库、模拟CAT与真实CAT有效性检验的基本内容。然后,文章针对题库中试题逐渐向多维度和多模态转变的特点,提出利用高阶因子模型与多质多法模型对多维度与多模态试题进行有效性检验的方法;同时建议从测验公平性的角度,检验CLT与CAT中个体人格特质对被试作答表现的影响是否具有跨组不变性,最终形成了一套符合时代发展的CAT有效性检验的完整流程,以期为CAT的持续改进及其在教育实践中的普及推广提供助力。
关键词:计算机自适应测验;有效性检验;多维度与多模态试题;测验公平性
【中图分类号】G40-057 【文献标识码】A 【论文编号】1009—8097(2024)06—0123—10 【DOI】10.3969/j.issn.1009-8097.2024.06.013
随着教育评价改革运动和计算机技术的迅猛发展,教育测量与评价理论的演进在不断深入,教育测验也逐步从传统的以经典测量理论(Classical Test Theory,CTT)为基础的线性测验,转向以项目反应理论(Item Response Theory,IRT)为依托的计算机自适应测验(Computerized Adaptive Testing,CAT),总体发展趋势呈现出尊重学生个体差异、注重因材施测的教育理念。IRT克服了CTT的诸多缺陷,使CAT能够利用更短的时间和更少的试题,实现对被试能力水平更精准的测量[1],但其测量结果的有效性检验却一直是横亘在教育测量与评价领域的难题之一。首先,CAT“一人一卷,千人千卷”的特点,使传统线性测验的有效性检验方式无法直接移植到CAT中。其次,伴随着CAT测评模式的衍生发展,能够同时评估被试在多个维度上能力水平的多维计算机自适应测验(Multidimensional Computerized Adaptive Testing,MCAT)引起研究者的广泛关注。同时,随着教育评价理念的不断演变,测验编制者试图将试题从单一的文本模态扩展至文本、图像、视频等混合模态,通过建构真实情境,评估被试解决实际问题的能力[2]。尽管基于多维度与多模态题库的CAT能够满足测验的更多需求,但适用于多维度与多模态试题的有效性检验方式始终没有成型。最后,在CAT环境下,被试人格特质对作答表现的影响机制是否会导致测验结果的不公平,进而影响CAT的有效性也是尚未解决的难题。基于此,本研究将在分别归纳总结CAT题库、模拟CAT、真实CAT有效性检验基本环节的基础上,提出适用于多维度与多模态试题有效性检验的特定方法,并设计以传统线性测验为校标,检验CAT是否具有测验公平性的实验方案,以期为CAT的持续改进及其在教育实践中的普及推广提供助力。
一 CAT有效性检验的内涵
1何为有效性检验
测验的效度也称有效性,是反映测验结果准确性的指标[3]。教育测量学初步形成于20世纪初,有效性检验亦兴起于该时期。1937年,Bingham[4]给出了有效性检验的操作定义,即有效性检验是指一项测验的成绩与采用其他客观方法进行测量的结果之间的相关系数,此时的有效性检验是简单、初级的,相关系数被赋予绝对化的意义。在此之后,有效性检验又逐步发展形成了分类效度、构念效度、基于论证的效度等多种检验模式[5]。
随着教育测量理论和实践的发展,测验的关注点已越来越多地放在对被试的诊断、评价和补救之上,因此对测验分数的解释和应用日益受到重视,测验有效性检验的定义也逐渐游离于传统定义之外。1985年,美国心理学会在颁布的《教育与心理测验标准》中给出了有效性检验的第一个形式化定义,即基于测量分数或其他评估形式所做出的推论的适当性[6]。由其定义可知,有效性检验主要具有两方面作用,一是为测验分数的解释和运用提供支持,二是审核特定分数在解释和使用上的合理性和恰当性。
时至今日,人们倾向于认为测验的有效性检验不是简单地通过一个或几个数量化指标就能得到充分表示的,而是实验、统计、理论等诸多方面证据的积累。换言之,有效性检验是一个收集有效性证据的过程,这个过程不是一个全或无的问题,而是一个程度大小的问题,其从测验编制开始,一直延续到测验结果的解释、应用等诸多环节[7]。
2 CAT有效性检验的重点环节
传统线性测验的有效性检验主要侧重于信效度的测量,与之不同,CAT有效性检验的着重点主要体现在以下环节:
①传统线性测验一般由命题人员从题库中选取特定的试题组成整套试卷提供给所有被试,其题库功能多为储存、检索试题。而CAT要在题库中为每一名被试挑选与其能力相匹配的试题,这样题库质量(如试题与模型的匹配程度、能够提供的信息量的大小等)是否符合要求就显得更为重要,如果题库质量存在问题,导致选题出现偏差,测验就可能无法达到预定的测量目标。因此,在CAT题库构建完成后,需要对题库的有效性进行检验,以确保CAT的顺利实施。
②CAT的测验结果是否能满足施测者的要求,与CAT中选题策略、能力估计的方法等技术细节息息相关,为了寻找最佳方案,往往需要比较多种不同的策略和方法。如果每种策略和方法的优劣都通过选取真实被试来获得,无疑将造成人力、财力的巨大消耗。但如果通过模拟CAT进行实验研究,不仅可以解决测验情境复杂时研究变量不易控制的问题,还能为研究者提供短时间内评测多种策略与方法的可能性,因此模拟CAT是有效性检验中不可或缺的组成部分。
③模拟CAT有着诸多便捷之处,但毋庸置疑的是,真实CAT的测验结果才更符合实际情况、更令人信服,模拟数据能否准确反映真实情境始终是令人存疑的。因此,尽管真实CAT需要开发题库、征集被试、现场测验,存在研究成本高、耗时长等问题;且真实被试还可能受到如测验环境、测验焦虑等不确定因素的干扰,但真实CAT依然是有效性检验中无可替代的环节。
二题库的有效性检验
建设一个高质量的题库是提升测验安全性、维护测验结果公平性的有力保障。题库构建的理论基础不外乎CTT和IRT两种,基于CTT题库的模型较为简单,投入成本较小,但其试题参数在不同情境下的可靠性和扩展性较差。因此,本研究中的题库指基于IRT的题库,此类题库的理论基础和技术手段相对复杂,但其试题参数适用于多种情境,如智能组卷、线性测验、自适应测验等。IRT题库的有效性检验通常包括假设检验、模型与数据的拟合性检验、项目功能差异(Differential Item Function,DIF)检验、测验信息量的计算[8]。
1 假设检验
IRT所包含的一切理论必须建立在单维性假设和局部独立性假设的基础之上,因此,IRT题库的假设检验包括:单维性检验和局部独立性检验。
(1)单维性检验
测验的单维性是指被试在测验中的表现只能由一种能力或因素进行解释,目前大多数关于测验有效性的研究仅局限于题库的单维性检验,涉及题库多维性检验的研究寥寥无几。IRT题库是否符合单维性主要从两方面进行考量,一是检验试题编制原则是否符合单维性;二是在收集测验数据的前提下,运用统计分析软件(如SPSS、AMOS、R语言等)进行探索性因子分析(Exploratory Factor Analysis,EFA)或验证性因子分析(Confirmatory Factor Analysis,CFA),EFA和CFA中单维性检验的判别指标分别是因子的方差解释量和拟合指数。以免费开源软件R语言为例,EFA和CFA可以分别使用R软件包的psych和lavaan加以实现。
(2)局部独立性检验
局部独立性指任何一个能力水平的被试在全部试题上的联合正答概率等于其在各试题上正答概率的乘积,其内涵表现在:①同一被试在某道试题上的正答概率独立于该被试在其他试题上的正答概率;②能力水平相同的被试群体在同一道试题上的正答概率相互独立。局部独立性是IRT中试题维持参数不变性的前提之一,其验证过程可以通过R语言软件包mirt分析试题残差间的相关来实现,若试题残差间的相关小于0.2,局部独立性成立,反之则存在局部依赖性。
2 模型与数据的拟合性检验
模型与数据的拟合既可以在一定程度上保证试题参数与被试能力水平估计的准确性,又可以使参加自适应测验的不同被试的能力水平具有可比性,因此模型与数据拟合性检验的目的是识别题库中拟合效果较差的试题并予以删除。模型与数据的拟合性检验可以通过R语言软件包mirt中的itemfit函数来完成,其检验统计量有S-X2、PV-Q1等[9]。以S-X2为例,p<0.001被视为模型与数据拟合性不佳,但当测验的样本量较大时,p值会随着样本量的增大而显著变小,这时研究者会倾向于将近似均方根误差RMSEA作为拟合检验统计量[10]。
3 项目功能差异检验
DIF检验旨在分析被试对测验试题的作答是否与其背景(如性别、种族或年龄等)相关,当来自不同背景的具有相同能力水平的被试,对同一道试题进行作答所产生的正答概率不同时,即代表该试题存在DIF。一个公正无偏测验中的试题不应存在DIF,一旦所测试题存在DIF,被试最终能力水平估计就会出现偏差。DIF检验可通过R语言软件包lodif实现,当效应统计量McFaddens pseudo R2<0.02时,DIF可忽略不计[11]。
4 测验信息量的计算
测验信息量反映了整个测验在评价被试能力水平时的信息贡献量,题库的测验信息量由试题信息量累加而成,各试题信息量之间互不影响,某一试题信息量的取值由试题参数和被试能力水平所决定。IRT中测验信息量的平方根的倒数构成了被试能力水平估计值的标准误,1与标准误平方之差的绝对值即该能力水平的测验信度。由此可知,题库所提供的测验信息量越大,对被试能力水平的估计越精准(标准误越小),测验信度越高。题库中试题信息量、测验信息量、能力估计标准误、测验信度范围的计算与绘制可分别通过R语言软件包mirt和ltm实现[12]。
三 CAT的有效性检验
1 模拟CAT的有效性检验
目前,模拟CAT已经成为研究CAT技术的重要手段之一,常用的模拟CAT有以下三种方法:①蒙特卡罗模拟,这是一种基于模拟随机数的统计抽样实验方法,测验中的参数如被试能力、试题难度等常被认为满足一定的经验概率分布,可以通过计算机的随机发生器预先模拟产生,其有效性检验主要是评估不同算法支持下CAT的性能,并对其优劣进行比较和评价;②事后模拟,即依据被试在题库中所有试题上的真实作答结果,模拟出被试在CAT中的试题作答序列和测验长度,其有效性检验主要是依据被试在常规线性测验中的作答结果,探究当测验以CAT的方式实施时,测验试题的减少数量;③混合式模拟,在实际的测验中,庞大的题库、测验安全约束等不允许被试对题库中的所有试题都进行作答,因此最终生成的试题反应矩阵是稀疏的,此时要使用混合式模拟来解决这一问题[13]。该方法首先使用蒙特卡罗模拟估计出被试在题库中未作答试题上的作答结果,得到稀疏矩阵中的缺失数据,然后使用事后模拟评估CAT的有效性。
根据模拟CAT研究的不同目的,蒙特卡罗模拟的有效性检验主要涉及以下三个方面:测验模拟返真性能、测验安全性、题库使用情况。其中,测验模拟返真性能常用均方根误差(RMSE)和偏差(Bias)进行评价,RMSE越小或Bias绝对值越趋近于零,模拟结果越准确;测验安全性常用测验重叠率、卡方统计量等指标进行评价,指标数值越小,测验安全性越高;题库使用情况常用题库使用率进行评价,在不降低测验效率的情况下,题库中区分度偏低的试题使用越充分,效果越好[14]。事后模拟和混合式模拟的有效性检验主要是分析测验效率,其评价指标为线性测验与CAT测验长度间的差异。一般情况下,模拟CAT及其有效性检验可通过R语言软件包mirtCAT实现,在选拔性、高利害的CAT中,着重检验测验的安全性;而在诊断性、低利害的CAT中更加关注被试能力估计的准确性[15]。
2 真实CAT的有效性检验
目前,线性测验作为教育测量与评价领域的常用测验形式已经获得了教育教学实践工作者的认可。因此,对真实CAT的有效性检验可以通过将其与计算机化线性测验(Computerized Linear Test,CLT)进行等效性研究来加以实施,两者的等效性比较主要从被试能力水平、测验信度、测验效度、测验效率的角度进行。
(1)被试能力水平的比较
为使CLT与CAT的被试能力水平具备可比性,应确保两者进行等效性研究的试题是源于同一个以IRT为基础开发的题库,且参加CLT与CAT的被试为相同被试或随机分配的两组被试。若为相同被试分别参加CLT和CAT,可直接比较两次测验获取的被试能力水平的排序是否一致;若为不同组被试,则可比较CLT与CAT被试能力水平的描述性统计特征,如比较能力水平分布曲线,观察其形状是否相似。
(2)测验信度的比较
在IRT构建的测验中,测验信息量取代了CTT的信度概念,测验信息量越大,表示测验的信度越高。就CLT而言,尽管每位被试所测的试题相同,但其能力水平不同,测验所能提供的信息量亦不相同,所得的测验信度系数最终表现为一个范围。在CAT中,测验信度的取值与测验的终止规则息息相关,若比较测验信度,则CAT的终止规则应采用固定长度法(CLT与CAT测验长度相同),此时CAT的信度系数同样存在一个范围。CLT与CAT测验信度的比较可通过对比测验信度系数的统计学特征(如平均值、标准差、最大值、最小值)来实现。
(3)测验效度的比较
在CLT与CAT测验效度的比较中,内容效度是较适宜的评价指标。CLT的试题由学科和测量专家按照课程目标、教学内容、评价目的等编制而得,一般具有良好的内容效度;而CAT利用选题策略进行适应性选题,这就意味着被试的能力水平不同,其所做的试题不同,试题考查的内容可能存在不平衡性。两者内容效度的比较按照以下步骤展开:①划分CAT高、中、低能力区间,选取每个能力区间处于中间值的被试的测验内容为代表;②以CLT为校标,比较CLT与CAT中各部分试题内容的数量和比例。
(4)测验效率的比较
考虑到CAT中测验终止规则的差异,CLT与CAT测验效率的比较主要从两方面进行考量:①测验所测试题数量相同时,测量精确度的比较;②测验达到相同测量精确度时,所测试题数量的比较。若CAT采用固定长度法的测验终止规则,测验效率的比较即被试能力估计值标准误的比较,标准误越小,测验效率越高;若CAT采用固定测量精确度的测验终止规则,测验效率的比较则为测验试题数量的比较,试题数量越少,测验效率越高。
四 题库及CAT有效性检验的优化
现有题库的有效性检验主要用于检验单维度和单一文本模态的题库。随着试题能力维度与模态的发展变化,基于多维度与多模态题库的CAT逐渐进入教育实践领域,但其有效性检验的方法至今鲜有涉及。另外,有研究显示,在CAT中被试的测验焦虑、自我效能感、认知风格会显著影响其作答成绩、作答时间、作答行为等作答表现[16]。因此,有必要对测验过程中更广泛的个体人格特质和作答表现之间的关联做进一步探讨,以便更全面地从测验公平性的角度检验CAT施测结果的有效性。
1 题库有效性检验的优化——多维度与多模态试题的有效性检验
本研究将以教师数字素养的题库为例,进行多维度与多模态试题的有效性检验。2022年12月,教育部发布了《教师数字素养》教育行业标准,旨在提升教师利用数字技术优化、创新和变革教育教学活动的意识、能力和责任[17]。《教师数字素养》规定了教师数字化意识、数字技术知识与技能、数字化应用、数字社会责任和专业发展五个能力维度的目标要求,其测量不仅应涉及教师在多维度认知领域的掌握、应用能力,还应通过多模态试题实现对分析、整合、评价能力的测量。本研究按照《教师数字素养》将题库中试题所测量的能力划分为五个维度,将试题的模态划分为文本、图像、视频三种,尝试通过构建高阶因子模型和多质多法模型对题库中多维度与多模态试题的有效性进行检验。
(1)高阶因子模型
高阶因子(High-order Factor)模型是由Hull等[18]提出的一种能够测量多维特质的模型,其原理是由一个高阶因子解释多个高度相关的低阶因子,并用低阶因子的残差解释各维度的独特性,可在多维度与多模态试题的有效性检验中评估能力高阶因子对不同测评方法的解释程度。
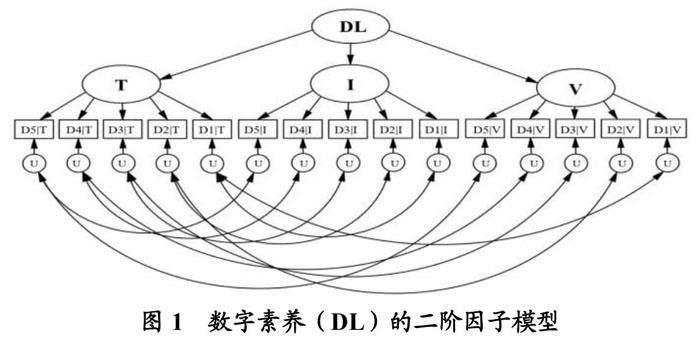
以教师数字素养题库的有效性检验为例,在高阶因子模型的构建过程中,首先将相同试题模态测评的每个能力维度上的试题得分平均值作为模型的指标,此处三种试题模态和五个能力维度的交叉形成模型包含15个指标,模型中测评相同能力维度的指标之间容许残差相关。然后,将文本类、图像类、视频类试题作为一阶因子,15个指标分别归属于这三个一阶因子。最后,抽取一个二阶因子(此处为数字素养),建立数字素养的二阶因子模型,如图1所示。
图中的DL代表数字素养(Digital Literacy),D1、D2、D3、D4、D5分别代表数字化意识、数字技术知识与技能、数字化应用、数字社会责任和专业发展能力;T、I、V分别代表文本(Text)类试题模态、图像(Image)类试题模态、视频(Video)类试题模态;U代表独特性(Uniqueness)。
最终,模型分析的结果将提供能力高阶因子对三个试题模态因子的标准化路径系数和解释率,以此检验题库中多模态试题对多维度数字素养能力的测量结果是否有效。
(2)多质多法模型
多质多法(Multitrait-Multimethod)的研究观点源于Campbell和Fiske,其理念是针对同一特质采用不同测量工具所得的测量结果之间相关程度应该较高,而测量不同特质的相同测量工具的测量结果之间相关程度应该较低[19]。通过分析多质多法模型中的相关矩阵,可以检验不同测量方法的会聚效度和不同特质之间的区分效度,以便准确了解不同测评手段测量不同特质的有效性。
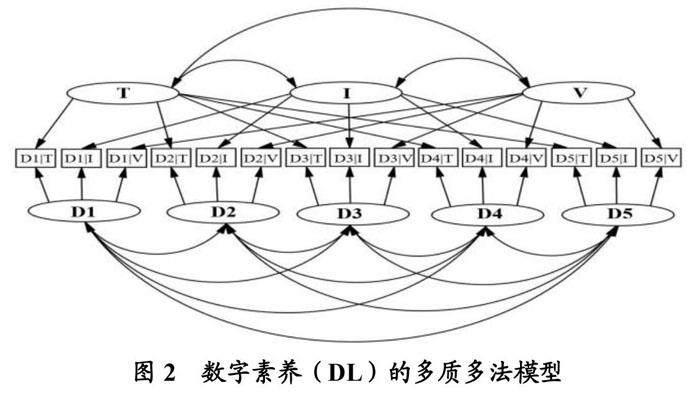
在教师数字素养的测量中,可基于三种试题模态和五个能力维度构建数字素养的多质多法模型,如图2所示。其中,三种试题模态和五个能力维度的交叉形成了模型所包含的15个指标,三种试题模态作为模型的3个方法潜因子,五个能力维度作为模型的5个特质潜因子,模型中的每一个指标都归属于1个方法因子和1个特质因子,方法因子之间、特质因子之间容许相关。
通过多质多法模型与数据的拟合程度、因子载荷和因子之间的相关性,可以考查不同模态试题测评相同能力维度的会聚效度和相同模态试题测评不同能力维度的区分效度,并比较不同模态试题测评不同能力维度时在有效性方面的差异。在多质多法模型中,良好的会聚效度代表不同方法测量同一能力时呈现出较高的相关性;而良好的区分效度则表现为同一方法能准确测量不同的能力,但不同能力间的相关则较低。
2 真实CAT有效性检验的优化——CLT与真实CAT测验公平性的比较
研究发现,在不同的测验环境中个体人格特质可能对被试的作答表现产生显著的影响。例如,Von der Embse等[20]通过对238项教育类测验进行元分析,发现课程测验成绩、平均绩点和高风险测验成绩与测验焦虑间表现出显著的负相关,这些测验涉及多种国家级考试及各类专业考试,测验形式既有纸笔类测验,也有计算机化线性测验和自适应测验。经过研究发现,在正答概率为0.5和0.7的CAT中,沉思-冲动型认知风格对被试的试题作答时间均有显著影响,且在测验由难变易(正答概率由0.5变为0.7)时,个体认知风格的差异与试题特征对试题作答时间的总效应显著降低[21]。此外,研究还证实,CAT中不同被试的作答行为差异与其人格特质息息相关[22]。
线性测验与自适应测验提供了不同的测验环境,而不同的测验环境可能会导致个体人格特质对作答表现(含作答成绩、作答时间、作答行为)的影响存在显著差异。由于教育实践领域已经普遍认同了线性测验的公平性,因此可以将线性测验作为校标,探究个体人格特质在CAT环境中是否会对作答表现产生更强的正面或负面影响,从而判定CAT是否具有测验的公平性。
(1)个体人格特质与被试作答表现
人格特质是个体中相对稳定的认知、情感和行为模式[23]。目前普遍认同的构成人格的基本要素或特质是美国心理学家Costa等[24]提出的大五人格特质,这是一种阐述人格特质的结构关系的理论,包含五个维度——神经质、宜人性、尽责性、开放性、外倾性。经过几十年的实证检验,大五人格特质已获得学界公认,且尽管该理论源自国外,但在不同文化、民族的群体中,大五人格特质均表现出跨文化的一致性。因此,本研究以大五人格特质为例,探究其在CLT和CAT测验环境中对被试作答表现的影响是否存在显著差异。
本研究中的作答表现是指在CLT和CAT中被试的作答成绩以及被试表现出来的作答时间和作答行为。其中,作答成绩指被试的能力水平;作答时间指被试在作答某一试题时,从开始作答到作答结束所用的时间;作答行为则是被试在做题过程中表现出来的外显行为,即解题行为和猜答行为。解题行为是指被试对试题做出认真思考并努力寻求正确答案的作答行为;猜答行为是指被试不浏览试题,或浏览试题但未经思考而直接猜测试题答案的作答行为。要识别解题行为和猜答行为,需要为每道试题指定一个时间阈值,本研究选用了Kong等[25]提出的标准阈值法作为区分解题行为和猜答行为的判别方法。
(2)大五人格对被试作答表现的影响机制
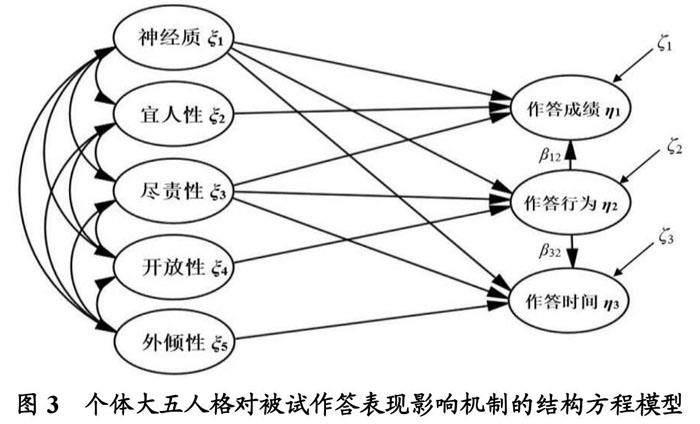
本研究根据个体大五人格的定义和大五人格对学习成绩、学习行为影响的文献综述[26][27],以及作答成绩、作答时间、作答行为之间的相互关系,做出如下假设:①被试的神经质、宜人性、尽责性对作答成绩有显著的影响;②被试的神经质、尽责性、外倾性对作答时间有显著的影响;③被试的神经质、尽责性、开放性对作答行为有显著影响;④被试的作答行为对作答成绩有显著的影响;⑤被试的作答行为对作答时间有显著影响;⑥被试的神经质、宜人性、尽责性、开放性、外倾性之间存在显著相关。根据上述假设,本研究构建了图3所示的个体大五人格对被试作答表现影响机制的结构方程模型,图中ξ是外源潜变量,η是内生潜变量,β描述了内生潜变量η之间的关系,ζ是结构方程的残差项,反映了η在方程中未能被解释的部分。
(3)跨组不变性检验
本研究通过多组结构方程模型分析来检验,在CLT与CAT中个体大五人格对被试作答表现的影响机制是否存在跨组不变性。
首先,利用总样本、CLT和CAT样本的作答数据分别与图3中的结构方程模型进行拟合,如果模型与数据拟合良好,该模型将作为基准模型用于后续的多组结构方程模型分析。
然后,在得到基准模型后,通过设置多个约束条件检验CLT和CAT之间是否存在不变性,当前面的约束条件不成立时,则不存在跨组不变性,后面的约束条件就不需要再检验了。可以设置的约束条件有:①设定结构系数相等,即B (CLT)=B (CAT),G (CLT)=G (CAT);②增设潜变量x的协方差矩阵F相等,即B (CLT)=B (CAT),G (CLT)=G (CAT),F (CLT)=F (CAT);③增设残差项?的协方差矩阵Y 相等,即B (CLT)=B (CAT),G (CLT)=G (CAT),F (CLT)=F (CAT),Y (CLT)=Y (CAT)。
最后,比较结构方程模型中外源潜变量对内生潜变量的直接效应和间接效应是否具有跨组不变性。
若检验结果显示CLT与CAT之间存在跨组不变性,表明CLT与CAT具有相似的测验公平性。若检验结果显示CLT与CAT之间不存在跨组不变性,则需要进一步分析CLT与CAT中大五人格特质对作答表现的影响孰强孰弱,若CAT强于CLT,则CAT的测验公平性差于CLT;若CAT弱于CLT,则CAT的测验公平性优于CLT。
五 结语
本研究在阐述CAT有效性检验内涵的基础上,探讨了题库、模拟CAT和真实CAT有效性检验的基本环节,并进一步提出了优化题库和真实CAT有效性检验的改进方法,从而形成了CAT有效性检验的完整流程。研究内容侧重于以定量的方法探讨CAT的有效性检验,但实际上,定性的方法也能为CAT的有效性检验提供证据。例如,在一次CAT施测前,并未告知被试将要进行的是自适应测验,施测后研究团队组织被试进行了座谈,座谈中有被试提及在测验中有一种特殊的感觉,即当自己有把握答对试题时,后续试题会变难;当自己遇到不会做的试题时,后续试题会变得容易。无疑,被试以自己的感知,为CAT中选题策略的有效性提供了强有力的证据。然而本研究提出的题库与真实CAT有效性检验的改进方法仅从理论层面做了探讨,尚未进行实践,因此在未来CAT有效性检验的研究中,研究团队将注重开展定量与定性方法结合的实证探索,从不同的角度为CAT的有效性检验积累更多证据,这更符合测验有效性检验的内涵,即有效性检验是一个收集证据的过程,它不是一个全或无的问题,而是一个程度大小的问题。
参考文献
[1]Weiss D J. Improving measurement quality and efficiency with adaptive testing[J]. Applied Psychological Measurement, 1982,(4):473-492.
[2]Wang Y, Lu H. Validating items of different modalities to assess the educational technology competency of pre-service teachers[J]. Computers & Education, 2021,162:104081.
[3][6]AERA, APA, NCME. Standards for educational and psychological testing[M]. Washington D C: American Educational Research Association, 1985:9、94.
[4]Bingham W V. Aptitudes and aptitude testing[M]. New York: Harper & Brothers, 1937:204.
[5]刘庆思.效度验证:教育考试亟需补齐的短板[J].中国考试,2018,(4):16-21.
[7]张厚粲,龚耀先.心理测量学[M].杭州:浙江教育出版社,2012:208.
[8]王玥,常淑娟,韩晓玲,等.基于项目反应理论的题库构建及其有效性检验——以“现代教育技术”公共课为例[J].现代教育技术,2019,(10):41-47.
[9]温忠麟,侯杰泰,马什赫伯特.结构方程模型检验:拟合指数与卡方准则[J].心理学报,2004,(2):186-194.
[10]Reeve B B, Hays R D, Bjorner J B, et al. Psychometric evaluation and calibration of health-related quality of life item banks: Plans for the patient-reported outcomes measurement information system (PROMIS)[J]. Medical Care, 2007,(5):22-31.
[11]Choi S W, Gibbons L E, Crane P K. Lordif: An R package for detecting differential item functioning using iterative hybrid ordinal logistic regression/item response theory and Monte Carlo simulations[J]. Journal of Statistical Software, 2011,(8):1-30.
[12]张宏.基于IRT的试题分析:R软件ltm包运用实例[J].中国考试,2012,(8):45-51.
[13]Smits N, Paap M C S, B?hnke J R. Some recommendations for developing multidimensional computerized adaptive tests for patient-reported outcomes[J]. Quality of Life Research, 2018,(4):1055-1063.
[14]Chang H H, Qian J, Ying Z. A-Stratified multistage computerized adaptive testing with b blocking[J]. Applied Psychological Measurement, 2001,(4):333-341.
[15]余嘉元,汪存友.项目反应理论参数估计研究中的蒙特卡罗方法[J].南京师大学报(社会科学版),2007,(1):87-91.
[16][21]陆宏,王玥,王超,等.计算机自适应测验中沉思-冲动型认知风格、能力水平、试题难度与试题作答时间的关系分析[J].现代教育技术, 2020,(10):91-97.
[17]教育部.关于发布《教师数字素养》教育行业标准的通知[OL].
[18]Hull J G, Lehn D A, Tedlie J C. A general approach to testing multifaceted personality constructs[J] Journal of Personality and Social Psychology, 1991,(6):932-945.
[19]Campbell D T, Fiske D W. Convergent and discriminant validation by the multitrait-multimethod matrix[J]. Psychological Bulletin, 1959,(2):81-105.
[20]Von der Embse N, Jester D, Roy D, et al. Test anxiety effects, predictors, and correlates: A 30-year meta-analytic review[J]. Journal of Affective Disorders, 2018,227:483-493.
[22]Lu H, Tian Y, Wang C. The influence of ability level and big five personality traits on examinees test-taking behaviour in computerised adaptive testing[J]. International Journal of Social Media and Interactive Learning Environments, 2018,(1):70-84.
[23]Steel P, Schmidt J, Shultz J. Refining the relationship between personality and subjective well-being[J] Psychological Bulletin, 2008,(1):138-161.
[24]Costa Jr P T, McCrae R R. From catalog to classification: Murrays needs and the five-factor model[J]. Journal of Personality & Social Psychology, 1988,(2):258-265.
[25]Kong X J, Wise S L, Bhola D S. Setting the response time threshold parameter to differentiate solution behavior from rapid-guessing behavior[J]. Educational & Psychological Measurement, 2007,(4):606-619.
[26]Wang H, Liu Y, Wang Z, et al. The influences of the big five personality traits on academic achievements: Chain mediating effect based on major identity and self-efficacy[J]. Frontiers in Psychology, 2023,(1):1-21.
[27]Tett R R, Jackson D N, Rothstein M, et al. Meta-analysis of personality-job performance relations: A reply to ones, mount, barrick, and hunter (1994)[J]. Personnel Psychology, 2010,(1):157-172.
The Investigation and Optimization of Validity Testing for Computerized Adaptive Testing
LIXin-YuWANG Chao LU Hong[Corresponding Author]
(Faculty of Education, Shandong Normal University, Jinan, Shandong, China 250014)
Abstract:The validity testing of computerized adaptive testing (CAT) is a necessary step in evaluating test generation and interpreting test results as appropriate and rational. However, systematic studies on CAT validity test were rarely conducted. In order to make up for the deficiency, based on the analysis of the connotation of CAT validity test, the firstly combed the basic contents of IRT-based question bank, simulated CAT and real CAT validity test. Then, according to the characteristics of the question bank gradually changing to multi-dimension and multi-mode, this paper put forward a method to check the validity of multi-dimension and multi-mode questions by using high-order factor model and multi-quality and multi-method model. Moreover, from the view of test fairness, it was suggested to test whether the influence of individual personality traits on participants response performance was invariable across groups between CLT and CAT. Finally, a whole procedure for verifying the validity of CAT that conformed to the development of The Times was formed, expecting to provide help for the continuous improvement of CAT and its popularization in educational practice.
Keywords:computerized adaptive testing; validity testing, multi-dimensional and multi-modal item; test fairness
作者简介:李心钰,在读博士,研究方向为计算机教育应用,邮箱为echo_lixinyu@163.com。
编辑:小时
