基于并行SDAE?Seq2Seq模型的轴承寿命预测方法
2024-06-07张俊杰王海瑞李亚朱贵富
张俊杰 王海瑞 李亚 朱贵富

基金项目:国家自然科学基金(批准号:61863016,61263023)资助的课题。
作者简介:张俊杰(1999-),硕士研究生,从事智能诊断技术的研究。
通讯作者:王海瑞(1969-),教授,博士研究生导师,从事智能诊断、边缘计算的研究,hrwang88@163.com。
引用本文:张俊杰,王海瑞,李亚,等.基于并行SDAE?Seq2Seq模型的轴承寿命预测方法[J].化工自动化及仪表,2024,
51(3):427-437.
摘 要 基于数据驱动的轴承寿命预测方法大多需要人工提取退化特征,而且对于不同工况下的轴承需要进行针对性优化,也是依赖专家知识和经验进行特征提取。为此,提出一种并行堆叠降噪自动编码器算法(PSDAE)来提取轴承退化特征,并结合Seq2Seq模型预测轴承剩余寿命。通过PSDAE直接对原始振动信号进行降噪、降维,得到退化特征,通过神经网络的学习和训练自动获得不同工况下的轴承退化特征。其次,引入注意力机制,将提取的特征输入Seq2Seq模型进行训练,并在PHM2012数据集上验证模型的预测效果。实验结果表明:PSDAE通过并行集成方式降低了模型的训练参数和整体误差,提取的退化特征在单调性和可预测性方面优于堆叠降噪自动编码器(SDAE),使用该退化特征有效减少了Seq2Seq模型的预测误差,提高了预测得分,具有更好的预测效果和稳定性。
关键词 并行堆叠降噪自动编码器算法 寿命预测 滚动轴承 特征提取 注意力机制 Seq2Seq模型
中图分类号 TP202.1 文献标志码 A 文章编号 1000?3932(2024)03?0427?11
轴承被广泛应用于旋转机械,任何轴承故障都会使机械系统偏离正常状态[1]。因此,对轴承进行健康监测和剩余使用寿命(RUL)预测意义重大。传统的可靠性评估方法依赖于概率统计数据,无法对单个轴承设备进行个性化的可靠性评估[2]。而通过专家知识和手动提取特征数据的方法,又难以解决当前机械设备数据量庞大、信息密度低及时效性较差等问题[3~5]。
近年来,由于全球计算机算力的骤增,深度学习技术在计算机视觉(CV)和自然语言处理(NLP)领域取得了极大的进展,一些用于CV和NLP领域的深度学习技术也可以应用于轴承的故障预测和健康管理(PHM)。采用基于数据驱动的方法对轴承温度、振幅、负载等信号进行采集分析,然后用于轴承的剩余寿命预测,可极大地减少对专家知识的依赖,也可避免基于模型驱动的方法过于复杂、难以建立准确有效数学模型等问题[6]。在基于数据驱动的轴承寿命预测问题上,文献[7]提出基于数据增强和卷积神经网络(CNN)的方法,将原始的18维时域信號和频域信号增强为108维后,用CNN处理高维特征,实现轴承RUL的预测。文献[8]通过卷积神经网络-双向长短时记忆网络(CNN?BiLSTM)模型提取更深层的故障特征,对深层特征进行SoftMax回归,实现了轴承的故障类别诊断。文献[9]通过卷积自编码网络提取频域特征,用k?means聚类和评价指标挑选出优质特征,最后通过长短时记忆网络(Long Short?Term Memory,LSTM)进行剩余寿命预测。这些方法需要对轴承原始数据进行特征提取和处理,依赖于专家知识和经验进行特征提取。综上所述,针对轴承的剩余寿命预测和健康监测,传统的统计特征难以反映整个轴承的退化过程,并且缺乏单调性、趋势性和鲁棒性,仍然需要对轴承样本进行特征提取,以提高剩余寿命预测的准确性和可靠性,此过程需要人工介入,增加了预测模型的人工成本,同时也限制了预测模型的适用性。
笔者提出一种用于预测轴承剩余使用寿命的方法,即利用并行堆叠降噪自动编码器(Parallel Stacked Denoising Autoencoder,PSDAE)结合序列到序列模型(Sequence to Sequence,Seq2Seq)提取退化特征并预测健康度指标。通过不同工况下的轴承振动数据训练PSDAE神经网络模型后,直接使用神经网络提取退化特征,不用再依赖专家经验和知识提取时域、频域和时频域的各种特征,免去人工特征处理步骤。
1 并行SDAE?Seq2Seq模型
1.1 堆叠降噪自动编码器
降噪自动编码器(Denoising Autoencoder,DAE)是一种神经网络模型,它利用反向传播算法使网络的输出值和输入值尽可能相等。DAE由一个编码器和一个解码器组成,将初始数据x加入噪声破坏后得到输入层的数据[x][~]。编码器通过函数f将[x][~]映射为隐藏层的数据y,确定性映射y通过权重和偏置决定,即有:
y=f([x][~])=s(W[x][~]+b)(1)
其中,W为m×n的权重矩阵;b是m维的偏置向量;s表示[x][~]和W以及偏置向量b所做的矩阵运算。
编码器通过映射函数将输入的n×i矩阵[x][~]压缩为低维数据。解码器则通过函数g(y)将y反向映射为z:
z=g(y)=s(W′y+b′)(2)
其中,W′是重建解码器的权重矩阵;b′是重建的偏置向量。
为了使编码器的输入和解码器的输出尽可能相等,需要对(W′,b′)和(W,b)迭代更新,以最小化重构误差l(x,z)。降噪自动编码器的结构如图1所示。
当输入数据的维度和编码器的输出维度相差过大时,隐藏层和输入层间的神经元差距极大,会增加模型的训练时间,并且可能导致过拟合。为了克服这个问题,文献[10]提出了堆叠降噪自动编码器(Stacked Denoising Autoencoder,SDAE)。SDAE的结构类似于多层感知机,如图2所示,通过堆叠多个DAE减少了每个DAE的权重参数和训练时间,SDAE网络可以较好地捕获信号分布的潜在特征,通过对原始数据的破坏和重建,实现对信号特征的压缩和更新。
1.2 融合注意力机制的Seq2Seq模型
1.2.1 Seq2Seq模型和注意力机制
Seq2Seq模型是循环神经网络的一种重要变体,由编码器和解码器组成[11],可以将原始序列数据转换到另外一个序列,对时序数据具有很好的处理能力,并且输入序列和输出序列长度是任意的。编码器通过计算将一个输入序列{y}转换为上下文变量c,然后解码器通过c逐步生成目标序列T。因此,在第t个时间步时,T的条件概率为:
P(T|T,T,…,T,c)=g(h,T,c)(3)
其中,h是时间步t的隐变量;g(·)是SoftMax激活函数。
如图3a所示,解码器通过变量c作为初始的隐变量,可以得到任意t时刻之前所有时间序列的信息,再结合所有的输入{y,k≤N},让模型可以得到准确的预测结果。但是当时间序列过长时,RNN编码器输出的最后一个隐变量会遗忘掉早期信息,只携带最近的信息,在这样的情况下注意力机制可以很好地改善RNN的这个问题。如图3b所示,注意力机制起到了一个控制门的效果,a是一个长度和输出隐变量长度一致的向量,它可以通过权重让解码器在每一个时间步的预测过程中,从隐变量h中获取最合适的信息。如图3b所示,在每一个时间步中,a是根据当前目标隐变量h和编码器的每一个隐变量h来计算的。
框架简图
1.2.2 门控循环单元GRU
在Seq2Seq模型中,通过两个循环神经网络作为编码器和解码器来处理时间序列数据,实现RUL预测。然而,普通的循环神经网络模型在长时间序列预测中存在梯度消失和梯度爆炸的问题,难以捕获当前变量与之前变量的相关性,为解决这个问题,文献[12]提出了LSTM。门控循环单元(Gated Recurrent Unit,GRU)作为LSTM的简化变体,减少了需要训练的参数量,降低了过拟合风险,同时在训练数据较大的情况下可以极大地缩短训练时长。因此,本研究在Seq2Seq模型中使用GRU作为编码器和解码器。
如图4所示,GRU中定义了两个门——重置门r和更新门z。r和h作哈达玛积后通过tanh激活函数来控制候选隐藏状态[h][~],然后将z和h的哈达玛积与(1-z)和[h][~]的哈达玛积相加得到隐藏状态h。h表示上一时刻的隐藏状态,y表示当前时刻的输入。
图4中:
r=σ(yW+hW+b)(4)
z=σ(yW+hW+b)(5)
[h][~]=tanh(yW+(r☉h)W+b)(6)
h=z☉h+(1-z)☉[h][~](7)
其中,σ表示Sigmoid激活函数,用于將两个门的输出控制在0~1之间;W和b分别表示相应变量所对应的权重和偏置矩阵。
通过重置门和更新门结构,GRU可以有效过滤无用的时间序列信息,捕获当前变量的长期依赖关系。重置门是一个和隐藏状态长度一样的向量,它通过Sigmoid激活函数输出一个0~1的值,来决定有多少信息不能传递到下一时刻,根据式(6),极端情况下如果r逼近0,那么历史信息将不会用于候选隐变量的计算。更新门和重置门一样,但需要训练的权重和偏置向量不同,它决定了有多少过去的信息可以传递到下一时刻,当更新门逼近0的情况下,传递到下一个时刻的信息由候选隐藏状态决定。
1.3 PSDAE?Seq2Seq模型
SDAE解决了DAE模型容易过拟合、训练时间长的问题,但也带来了一些新问题:通过堆叠多个DAE,并将每个DAE的隐藏层作为下一个DAE的输入层,SDAE将编码过程分解为多个部分,减少了每个DAE输入层和隐藏层之间神经元数量的差距,然而当输入数据的维度较大时,第1层的训练参数会非常庞大,使得输出层的信号和原始信号间的误差较大,容易出现过拟合,这会导致最终的编码结果与原始信号间的误差较大,无法捕捉到原始信号的潜在特征。
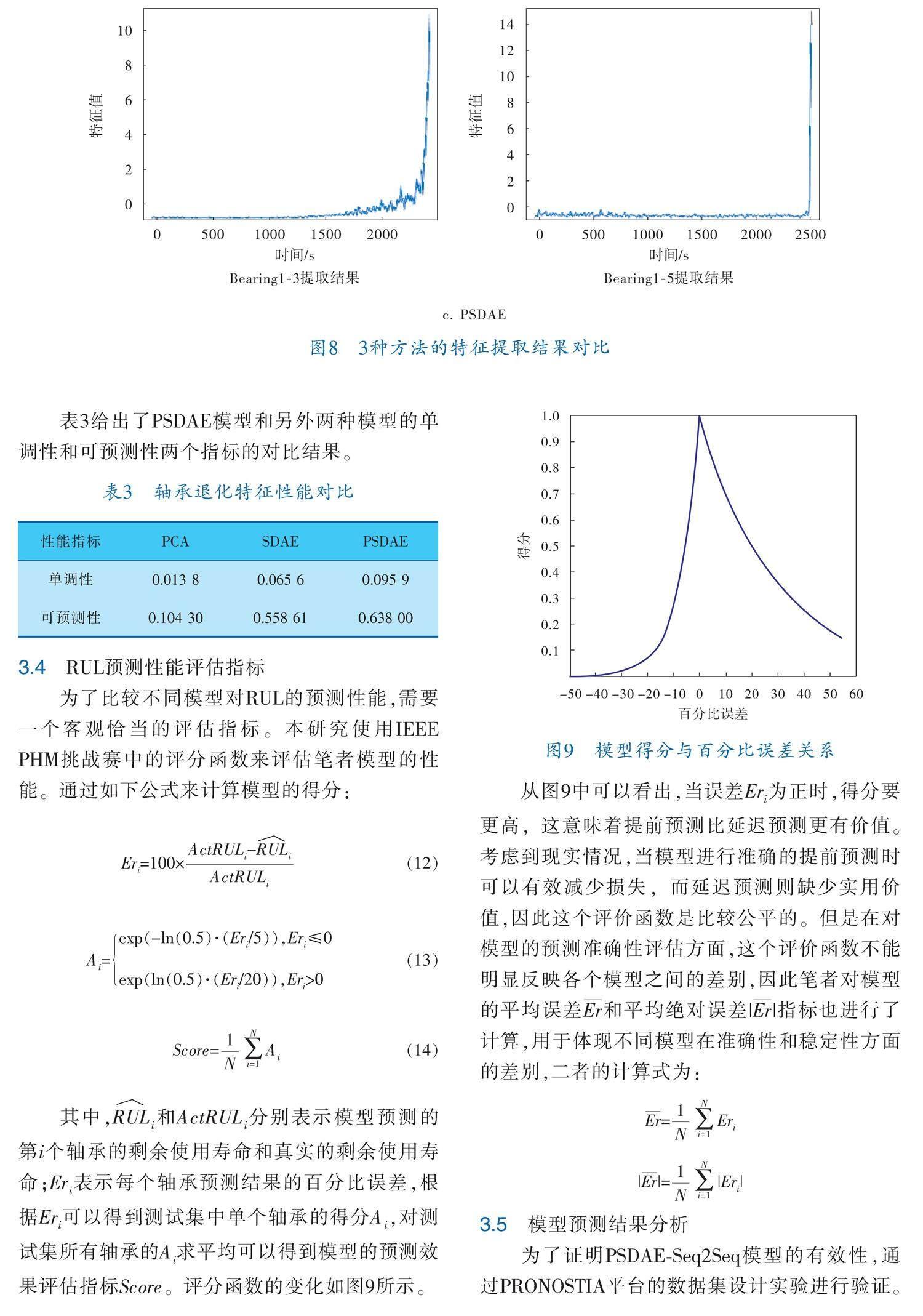
本研究通过并行集成的思想,在堆叠结构的第1层中构造多个DAE,每个DAE从原始信号的特征域中抽取m个采样数据,对其进行降噪编码。原始的轴承数据是一个N×M的矩阵(其中,N表示轴承的采样次数;M表示每个时刻的采样数据量,且N 0.1 s内的2 560个振动信号,如果一个轴承的使用寿命为28 000 s,那么用于PSDAE模型的原始数据就是一个28000×2560的矩阵。并行DAE的降噪过程如图5所示。将每个时间点采集的振动信号分为5段,将第1段信号x经过破坏、压缩、重建后得到还原后的信号z,根据两者的误差l(x,z)更新编码器权重得到最好的编码结果y,以此类推,得到所有分段信号的编码结果y~y。然后,根据5个编码器的误差计算编码结果的权重,误差越小的权重越大,将y~y按照权重加权融合后得到最后的编码结果y。 基于上述方法构造并行降噪编码器,作为堆叠降噪编码器的第1层,通过多个DAE将原始数据拆分,降低每个DAE的神经元数量,减少需要训练的参数量,从而降低总体误差。用训练好的并行堆叠降噪编码器对原始数据进行特征提取,将每个轴承的退化特征作为Seq2Seq模型的输入,通过退化特征预测轴承的健康指标。 如图6所示,在得到退化特征后,模型首先通过一个卷积层作为特征压缩器,将时间序列压缩到合适的大小,可以有效缩短训练时长,减少梯度消失和爆炸风险。然后通过GRU编码器编码特征序列,输出隐藏状态h。最后,GRU解码器对整个序列进行解码,一步一步地输出所预测的健康状态,在每一步中,根据编码器提供的整个信息的呈现进行注意力评分,以找出最重要的信息。 2 预测流程 2.1 数据预处理与退化特征提取 为了方便处理轴承信号,将原始数据中每个轴承的数据都转换为一个N×M的矩阵。为了减少对先验知识的依赖和人工计算的过程,本研究使用一种简单的健康指标,根据t时刻的剩余使用寿命RUL除以初始的剩余使用寿命RUL得到对应的健康指标HI,将健康指标作为预测模型的预测标签。通过HI得到预测模型标签的同时还可以实现对数据的归一化,将数据缩放至[0,1],消除单位对数据的限制,便于不同指标之间的比较。此外,数据的归一化可以提高模型的收敛速度,降低梯度爆炸的风险。HI的计算式如下: HI=(8) 原始的轴承振动信号通常是多维数据,而且可能存在噪声。为了提取轴承的退化特征,本研究采用PSDAE对振动信号进行降噪编码。这种方法通过并行编码的方式减少了首层编码器的神经元数量和权重参数,从而提高了特征提取的效率。PSDAE包括1层并行DAE网络和3层DAE网络,能够从原始振动信号中提取出一维的轴承退化特征。 堆叠结构的第1层中,将原始信号的2 560个采样维度的数据x分割为5个512维的数据,将每段数据重复地破坏、重建得到新的数据,将数据拼接后即可得到重建后的2 560维度的数据z,再根据二者间的损失函数L(x,z)调整并行降噪编码器的参数,直到误差收敛。最后将模型的隐藏层作为下一层的输入,对特征逐层编码,得到最终的退化特征。 2.2 预测轴承HI 通过PSDAE降噪编码后,获得了一个退化趋势明显的时序特征,将其放入Seq2Seq模型中,以轴承健康指标HI作为标签进行预测。经过GRU编码器编码后,通过注意力机制调节隐藏层权重,再通过GRU解码器对每个时刻的HI进行预测,最终获得每个时间点的预测HI。通过对HI曲线进行线性回归,可以得到最終的轴承寿命终止点,从而预测轴承的剩余使用寿命。整个模型的预测流程如图7所示。 3 实验验证 3.1 实验数据 本研究选用的实验数据为滚动轴承加速寿命台架试验采集的振动加速度数据,来源于电器电子工程师协会在2012年举办的PHM挑战赛[13]。实验数据来自PRONOSTIA平台,通过加速轴承性能退化实验得到轴承的全寿命周期振动数据。数据集包含3种工况下的17个滚动轴承振动数据,分别命名为Bearing1?1~Bearing1?7,Bearing2?1~ 2?7,Bearing3?1~Bearing3?3。数据每隔10 s采集一次,每次的采样频率为25.6 kHz,采样时间为 0.1 s,每次采集2 560个振动加速度。具体的实验过程和其他信息详见文献[13]。 本次实验使用3种工况下的所有轴承数据(表1),数据集中包含了所有轴承的全寿命周期振动信号数据,但是对于测试集的轴承,也提供了非全寿命周期的振动信号数据。本研究使用全寿命周期的轴承作为训练集,非全寿命周期的轴承作为测试集。缺乏最后阶段的振动信号无疑会提高轴承剩余寿命预测的难度,但是更符合实际工业生产的要求,模型需要根据其他轴承的退化过程以及当前轴承前期的振动信号,预测轴承后期的失效时刻,这样的预测更加有利于生产设备的维护和更换。 3.2 模型参数 为了获得更好的预测模型,笔者根据前人经验设置了模型的超参数。对于并行降噪自动编码器,对每一层的编码器和解码器逐层训练,参数设置为:随机失活概率(dropout)为0.1,迭代次数(epoch)为200,学习率0.02,编码器的激活函数为Sigmoid,解码器使用线性函数作为激活函数,模型损失函数为MSE(Mean Squared Error),分支大小(batchsize)设为256。分层训练完之后再对整个模型进行训练,学习率设置为0.005,batchsize为128(即训练过程中一次输入模型的一组样本的具体样本数量为128),其余超参数没有改变。 根据文献[14]将GRU编码器重置门的初始偏置设置为1,这样有利于神经网络学习数据时的时间依赖性。损失函数使用MSE,使用Adam优化算法作为参数优化器,将初始学习率设置为0.005。注意力机制的计算方法使用concat。笔者模型的具体参数见表2。 3.3 退化特征提取效果评估 轴承剩余使用寿命预测属于回归预测任务,轴承的退化过程本质上是一个随机连续变化的过程,一个良好的退化特征可以帮助模型建立有效的健康指标,提高RUL预测的准确性。因此,良好的退化特征应该满足两个指标: a. 曲线的单调性(Monotonicity,Mon)。退化过程是一个不可逆的过程,因此特征应该具有一定的单调性,单调性可以定量反映曲线的变化趋势,退化特征曲线的单调性对于神经网络模型的训练具有重要意义,单调性较好的退化特征可以降低模型训练的误差,在反向传播过程中帮助神经网络的权重很快确定下来,降低模型训练的难度。 b. 曲线的可预测性(Prognosability,Prog)。对于轴承寿命预测,退化特征在轴承失效时刻的可变性会对寿命预测的难度和准确度造成影响。当轴承失效时刻的特征变化较为明显时,可以让神经网络更容易获取退化特征和时间序列的潜在关系,从而更准确地预测健康指标。 特征单调性的计算式为: Mon= (9) sgn(t)=1 ,t>0 0 ,t=0 -1,t<0(10) 其中,N是测试集中第j个轴承的时间序列长度,sgn(·)是阶跃函数。 特征的可预测性计算式为: Prog=exp -,j=1,2,…,M(11) 其中,x表示第j个轴承的退化特征的值。 实验过程中,为了验证并行堆叠降噪自动编码器特征提取的效果,与普通堆叠降噪自动编码器、主成分分析方法(PCA)进行对比。模型训练完毕后,将3种方法在测试集的全寿命振动数据上进行实验,得到3种方法提取的降维数据。由于篇幅有限,因此图8仅展示3种方法在Bearing1?3和Bearing1?5上的效果。 对比分析图8中3种方法的特征提取结果可以发现,SDAE和PSDAE提取的特征单调性和可预测性都优于PCA。PSDAE相比于SDAE在轴承的失效时刻特征变化更明显,可变性明显优于SDAE,而且特征在失效时刻前更加平稳,特征的单调性也更加优秀。实验结果证明PSDAE提取的特征更加有利于轴承健康指标的预测。 表3给出了PSDAE模型和另外两种模型的单调性和可预测性两个指标的对比结果。 3.4 RUL预测性能评估指标 为了比较不同模型对RUL的预测性能,需要一个客观恰当的评估指标。本研究使用IEEE PHM挑战赛中的评分函数来评估笔者模型的性能。通过如下公式来计算模型的得分: Er=100×(12) A=exp(-ln(0.5)·( Er/5)), Er≤0 exp(ln(0.5)·( Er/20)), Er>0(13) Score=A(14) 其中,RUL和ActRUL分别表示模型预测的第i个轴承的剩余使用寿命和真实的剩余使用寿命;Er表示每个轴承预测结果的百分比误差,根据Er可以得到测试集中单个轴承的得分A,对测试集所有轴承的A求平均可以得到模型的预测效果评估指标Score。评分函数的变化如图9所示。 从图9中可以看出,当误差Er为正时,得分要更高,这意味着提前预测比延迟预测更有价值。考虑到现实情况,当模型进行准确的提前预测时可以有效减少损失,而延迟预测则缺少实用价值,因此这个评价函数是比较公平的。但是在对模型的预测准确性评估方面,这个评价函数不能明显反映各个模型之间的差别,因此笔者对模型的平均误差Er和平均绝对误差|Er|指标也进行了计算,用于体现不同模型在准确性和稳定性方面的差别,二者的计算式为: Er=Er |Er|=|Er| 3.5 模型预测结果分析 为了证明PSDAE?Seq2Seq模型的有效性,通过PRONOSTIA平台的数据集设计实验进行验证。通过训练数据集训练提出的模型之后,每一个测试轴承的RUL可以通过第2节描述的预测过程获得,每一个测试轴承的预测误差Er和实际得分A如图10所示。图10展示了测试数据集中共11个轴承的预测结果,可以看出,轴承1?4、1?5和1?6发生了延迟预测,预测的RUL大于实际RUL,3个轴承的预测误差为负数,因此3个轴承的得分较低。而且由于3个轴承的实际RUL较小,除以它之后得到了较高的百分比误差。除了这3个轴承(1?4、1?5、1?6)之外,笔者模型在其他轴承上的预测误差都比较好。 为了进一步验证PSDAE?Seq2Seq模型的性能,对使用SDAE融合优化的Seq2Seq模型、使用频域特征的Seq2Seq模型进行对比,并且与文献[15~17]中的相似工作进行对比,结果见表4,可以看出,第4列是笔者模型的预测RUL,第2列(当前时间)的值表示模型使用了多少个时间点的样本信号进行预测,Er、Er、Er分别表示PSDAE?Seq2Seq、SDAE?Seq2Seq和普通Seq2Seq模型的误差,最后3列数据是文献[15~17]的实验结果。 可以看出,笔者模型相较于其他模型,平均绝对误差和得分都是最高的。对比使用PSDAE的模型和使用SDAE的模型,使用PSDAE的模型的平均誤差和平均绝对误差的值明显要高于使用SDAE的模型,主要原因是SDAE模型的误差较大,退化特征中包含的潜在信息较少,导致不同轴承间预测准确性差异较大,降低了预测模型的稳定性和总体的准确性。此外,模型对3种工况下的轴承都有较好的预测得分,这是由于PSDAE模型通过训练后可以有效提取各种工况下轴承的退化特征,可以较好地提取不同工况振动信号中的潜在信息,在3种工况下都能提取出具有良好单调性和可预测性的退化特征。 从每个轴承的对比结果来看,笔者方法相较于其他方法在大部分轴承上的预测误差相差不大,但是个别轴承的预测精度相比于其他方法略有不足,说明笔者的方法可以适用于多种工况下的轴承寿命预测。总体来说,笔者模型给出了最准确的预测结果,在工程应用中更有价值,模型的预测更加稳定,但是精度有待提高。 4 结束语 在对轴承进行寿命预测时,由于轴承的个体差异,每个轴承的特征之间差异性较大,需要依赖大量的人工先验知识。SDAE模型可以对轴承振动信号进行自动降噪编码,但是当数据维度较大时,误差较大,收敛速度较慢。针对上述问题,笔者提出了基于PSDAE?Seq2Seq模型的轴承寿命预测方法,经过实验后得到以下结论: a. 通过PSDAE模型可以有效提取不同工况下的轴承特征,且退化特征的单调性和可预测性较好,不用再对振动信号进行特征工程处理,有效降低了对人工经验和专家知识的依赖。 b. 采用PSDAE模型提取退化特征有利于降低模型的误差。通过并行堆叠的方式降低了编码器输入层特征的维度,减少了训练参数,可以有效降低堆叠降噪编码器的误差。 c. PSDAE?Seq2Seq模型相比于SDAE?Seq2Seq模型,预测结果的平均误差降低了54.4%,在不同工况下的预测效果也较为稳定,具有更好的适用性和稳定性。 d. PSDAE?Seq2Seq模型预测结果更加准确、稳定,但是在对单个轴承的绝对精确度预测方面仍有待提高。 参 考 文 献 [1] JIA F,LEI Y G,LIN G,et al.Deep neural networks:A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data[J].Mechanical Systems and Signal Processing,2016,72:303-315. [2] 何正嘉,曹宏瑞,訾艳阳,等.机械设备运行可靠性评估的发展与思考[J].机械工程学报,2014,50(2):171-186. [3] BARALDI P,CANNARILE F,DI MAIO F,et al.Hierarchical k?nearest neighbors classification and binary differential evolution for fault diagnostics of automotive bearings operating under variable conditions[J].Engineering Applications of Artificial Intelligence,2016,56:1-13. [4] FEI S.Fault diagnosis of bearing under varying load conditions by utilizing composite features self?adaptive reduction?based RVM classifier[J].Journal of Vibration Engineering & Technologies,2017,5(3):269-276. [5] 雷亚国,贾峰,孔德同,等.大数据下机械智能故障诊断的机遇与挑战[J].机械工程学报, 2018,54(5):94-104. [6] ZAREI J,TAJEDDINI M A,KARIMI H R.Vibration analysis for bearing fault detection and classification using an intelligent filter[J].Mechatronics,2014,24(2):151-157. [7] 邹旺,吉畅,陈伟兴,等.基于数据增强和卷积神经网络的多轴承剩余寿命预测[J].机械设计,2021,38(8):84-90. [8] 董绍江,李洋.基于CNN?BiLSTM的滚动轴承变工况故障诊断方法[J].振动·测试与诊断,2022,42(5):1009-1016. [9] 李海浪,邹益胜,曾大懿,等.一种基于特征聚类和评价的轴承寿命预测新方法[J].振动与冲击,2022,41(5):141-150. [10] VINCENT P, LAROCHELLE H, LAJOIE I,et al.Stacked denoising autoencoders:Learning useful representations in a deep network with a local denoising criterion[J].Journal of Machine Learning Research,2010(12):3371-3408. [11] SUTSKEVER I,ORIOL V, QUOC V L. Sequence to sequence learning with neural networks[J].Advances in Neural Information Processing Systems,2014,27:9-22. [12] HOCHREITER S,SCHMIDHUBER J.Long Short?Term Memory[J].Neural Computation,1997,9(8):1735-1780. [13] NECTOUX P,GOURIVEAU R,MEDJAHER K,et al.Pronostia:An experimental platform for bearings accelerated degradation tests[C]//IEEE International Conference on Prognostics and Health Management.Piscataway,NJ:IEEE,2012. [14] JOZEFOWICZ R,ZAREMBA W,SUTSKEVER I.An empirical exploration of recurrent network architectures[C]//International Conference on Machine Learning.PMLR,2015:2342-2350. [15] SUTRISNO E,OH H,VASAN A S S.et al.Estimation of remaining useful life of ball bearings using data driven methodologies[C]//IEEE Conference on Prognostics and Health Management.Piscataway,NJ:IEEE,2012:1-7. [16] HINCHI A Z,TKIOUAT M.Rolling element bearing remaining useful life estimation based on a convolutional long?short?term memory network[J].Procedia Computer Science,2018,127:123-132. [17] HONG S,ZHOU Z,ZIO E,et al.Condition assessment for the performance degradation of bearing based on a combinatorial feature extraction method[J].Digital Signal Processing,2014,27:159-166. (收稿日期:2023-09-19,修回日期:2023-11-06) DOI:10.20030/j.cnki.1000?3932.202403009 Bearing Life Prediction Method Based on Parallel SDAE?Seq2Seq Model ZHANG Jun?jiea, WANG Hai?ruia, LI Yaa, ZHU Gui?fub ( a. Faculty of Information Engineering and Automation ; b. Information Technology Construction Center, Kunming University of Science and Technology) Abstract Most data?driven bearing life prediction methods need to manually extract degradation features, and for bearings under different working conditions, targeted optimization is needed, including relying on expert knowledge and experience to extract features. In this paper, a parallel stacked denoising autoencoder (PSDAE) algorithm was proposed to extract bearing degradation features, including having the Seq2Seq model combined to predict remaining life of the bearing. Through making use of PSDAE directly de?noise and dimensionally reduce original vibration signals, the degradation features were obtained, including automatically obtaining bearing degradation features under different working conditions through both learning and training of the neural network. In addition, the attention mechanism was introduced and the extracted features were input into the Seq2Seq model for training, and the prediction effect of the model was verified on the PHM2012 dataset. The experimental results show that, the PSDAE reduces training parameters and overall error of the model through parallel integration, and the extracted degradation features are better than stacked denoising autoencoder (SDAE) in terms of monotonicity and predictability. The use of the degradation features effectively reduces prediction error of the Seq2Seq model, improves prediction score and has better prediction effect and stability. Key words PSDAE, life prediction, rolling bearing,features extracting, attention mechanism, Seq2Seq model
