一种基于生成对抗网络的人脸运动模糊去除方法
2024-06-03曾孟佳
曾孟佳,户 哲,黄 旭*
(1.湖州师范学院 信息工程学院,浙江 湖州 313000;2.湖州学院 电子信息学院,浙江 湖州 313000;3.湖州市城市多维感知与智能计算重点实验室,浙江 湖州 313000)
0 引言
造成图像退化的原因多种多样,拍摄环境、人为干扰以及设备的好坏都可造成图像退化。由于物体和拍摄设备发生了相对运动而产生的运动模糊[1],是图像模糊中最为常见的一种,也会引发图像退化问题。模糊图像产生的原因是模糊核与图像内容发生了卷积,因此可以通过反解模糊核来恢复清晰图像。运动模糊是由相对运动产生的,与普通图像产生原理不同,不能直接利用模糊核反解方法使其恢复。
人脸识别技术在目标定位、追踪等场景中有着广泛应用,去除运动模糊则是其中重要的一环。本文针对人脸图像识别的特定场景,对运动模糊图像进行了清晰化研究,在人脸识别技术的推广应用中,起到一定的积极作用。
1 相关工作
在研究图像模糊处理的方向中,通常有2种去模糊方法。传统的修复方法为非盲去模糊,该方法已知模糊核,对模糊图像的模糊核进行反解从而得到清晰图像。但大多数情况下,图像模糊核未知,多幅图像的模糊核也不一致,因此模糊核反解方法缺少实际应用价值。深度学习方法不依赖于模糊核,在实际应用中有较好的推广价值。早期的模糊图像恢复通常为非盲去模糊[2],是在已知模糊核的情况下,研究如何获取清晰图像。通过对模糊图像进行反卷积操作,抵消模糊核对图像的卷积效果,从而得到相对清晰的图像。但这类算法用于处理实际场景中所恢复的图像时,处理后的图像在可视性方面不尽人意。随后,研究人员提出了基于迭代的去模糊方法[3],通过先验模型迭代优化模糊核,图像的去模糊效果虽然得到了一定提升,但是在运行速度和迭代次数上不能满足需求。
近年来,深度学习相关技术的快速发展为图像处理提供了一些新的方法和思路,越来越多的研究人员利用深度学习方法进行图像修复,取得了较大的进展。目前,人脸运动模糊去除方法大多采用深度学习方法。Sun等[4]基于卷积神经网络,根据其特性检测模糊核,达到了较好的效果。Gong等[5]采用卷积网络对图像进行运动流的预测,进而恢复了模糊图像。Kupyn等[6]首次在去运动模糊中引用了生成对抗网络技术,提出了DeblurGAN方法,在图像的修复结果方面和运算时间上都取得了相当好的成效。近年来,还出现了一些基于深度先验的盲去模糊算法[7],能够快速、准确地估计出清晰图像和模糊核,并有效抑制了图像复原过程中存在的噪声放大问题。
综上,深度学习算法在处理图像的运动模糊问题时效果良好。本文针对人脸运动模糊图像的恢复问题,提出了一种端到端的深度学习网络模型,该模型是以生成对抗网络为基础,将卷积网络和上采样网络相结合,通过加入多次跳跃连接提升网络对图像特征内容进行提取,并且通过加入全局跳跃连接,将网络的前端与末端相连接,得到最终的端到端网络结构,以提升人脸运动图像的去模糊效果。
2 算法介绍
2.1 数据集
本文基于人脸图像公开数据集(CelebFaces Attributes Dataset,CelebA),制作了人脸运动模糊数据集。在CelebA中选取清晰的人脸正面图像,使用Kuoyn等[6]提出的算法模拟图像线性运动,通过使用不同模糊核的卷积运算,获得人脸运动模糊图像,进一步生成所需的数据集。实验时,本文方法从CelebA中挑选了3000张清晰人脸图像,经模糊化处理后,选取2400张用于训练,剩余600张用于测试。
2.2 生成对抗网络
生成对抗网络(Generative Adversarial Networks,GAN)的基本理念由Goodfellow等[8]首次提出,网络结构主要由生成网络和判别网络构成,模型结构如图1所示。生成网络主要负责产生新的生成样本,鉴别器的作用是区别2个输入,做出判断。GAN的最终目标,是生成一个鉴别器无法辨别输入数据来源于哪一方的结果。在实际应用中,生成网络和对抗网络一般使用深层神经网络实现。
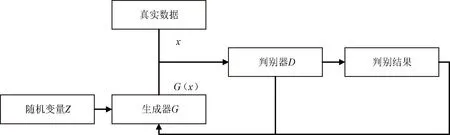
图1 GAN结构
GAN网络的目标函数如式(1)所示。
minGmaxDV(D,G)=Ex~pdas(x)[logD(x)+Ez~pz(z)[log(1-D(G((z))))]]
(1)
其中,生成模型G产生假的数据样本G(z)。生成器的作用是使产生的样本数据与真实的样本数据相同。判别器D的输入为2个部分,即真实的样本数据x和生成器产生的假的生成数据G(x)。判别器D的输出一般是介于(0,1)的概率值,表示判定的输入是真实分布的概率:如果输出结果越接近于1,则说明输入的数据越接近真实数据;相反,如果输出结果越接近于0,则表明输入的数据真实性越低。同时,判别器的数据结果会反馈给生成器并用于下一次训练。理想情况下,判别器无法判别输入数据的来源是真实样本还是生成样本,即当判别器每次输出的概率值均为1/2时,模型达到最优。GAN被广泛应用于各种图像领域,包括图像的超分辨率[8]、风格迁移[9]、图像生成技术[10]等。
2.3 网络结构
本文所用的神经网络模型结合了GAN和卷积网络2种结构,如图2所示。
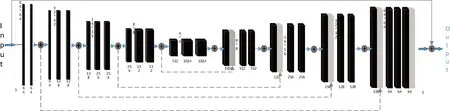
图2 生成网络模型
首先是生成网络,采用Encoder-Decoder结构的卷积神经网络作为生成模型。在Encoder-Decoder网络结构中添加多个跳跃连接层Skip-connection,将卷积过程中提取到的特征信息引入反卷积过程中。同时,引入全局跳跃连接可以提高网络对图像特征信息的复用,降低模糊图像到修复图像之间端到端学习的复杂度。生成网络由Encoder单元模块和Decoder单元模块组成。Encoder单元模块采用“卷积-BatchNormalization-激活函数”的形式。Decoder单元模块采用“反卷积-BatchNormalization-激活函数”的形式。
2.4 损失函数
损失函数作为机器学习和深度学习中的一个重要指标,在网络模型的训练中有着不可或缺的作用,能够影响模型的训练效果。整体网络结构基于GAN,损失函数由2个部分组成,如式(2)所示。
Lgloss=αLgan+βLcon
(2)
其中,Lgloss为最终的损失函数,α、β代表不同损失函数的权重,Lgan代表生成对抗网络中的对抗损失,Lcon代表内容损失。
对抗损失是GAN中较为核心的的一部分,其引导网络内部之间的对抗,对数据样本的分布情况进行拟合,实现算法模型的优化,最终通过判断输入图像的真假以获得所产生的损失。对抗损失模型如式(3)所示。
(3)
其中,I表示为模糊图像,函数G表示GAN中对模糊图像的处理过程,结果为修复后图像,函数D表示通过判别网络判定生成图像为真实图像的概率。
为生成具有清晰结构的去模糊图像,内容损失模型选用均方误差(Mean Square Error,MSE)进行计算,用以描述生成数据和真实数据之间的差距,如式(4)所示。
(4)
其中,n代表样本的数量,ωi代表第i个采样点的权重参数,xi是第i个采样点的真实值,yi是模型对第i个采样的预测值。
3 实验及结果
3.1 环境及参数说明
本实验中,CPU为Intel(R)i9-9700,GPU为NVIDIA GeForce RTX 3060,内存32 G,采用window10操作系统。开发软件使用PyCharm,开发语言为Python3.7,深度学习框架为PyTorch。训练过程中优化器的选择为Adam,学习速率设置为0.0001,训练轮次设置为300个epoch,batch size设置为8。训练设置为生成网络1次,鉴别网络5次。训练集和数据集均为本文制作的数据集。整个网络在GPU为NVIDIA 1060,内存为16 GB的电脑上训练,训练时长约为3天。
3.2 实验结果
本实验在加入多次的跳跃连接后加深了网络对信息的利用,生成图像的真实性和可视性存在更好的效果。经过对比试验和消融实验,本文选择最优的训练参数对实验集进行测试,最终的结果如图3所示。图3(b)所示修复后的结果相比于图3(a)所示原始的模糊图像,在清晰度方面有较大提高,生成图像的真实性和可视性更好。这说明本文所用方法能在一定程度上去除运动模糊,且效果良好。

图3 实验结果
4 结语
本文提出了一种基于GAN的端到端深度学习网络模型,通过训练自制人脸运动模糊图像数据集,在加入多次的跳跃连接后加深网络对信息的利用,在生成图像的真实性和可视性提升方面有着较好的效果。但是当图像的模糊程度发生改变,即图像的模糊核长度发生变化时,本文模型的效果相比于其他算法在高模糊图像的恢复效果方面结果较为相近。其原因可能是随着图像模糊程度的加深,整个网络对图像特征的提取作用也随之降低,导致生成的结果不尽如人意,以上问题将是后续研究的重点。
