基于改进YOLOv5的卷烟品规智能识别模型研究
2024-06-03刘晓明王朋波陶建文刘艳平
刘晓明,陈 皓,王朋波,陶建文,刘艳平
(1.陕西省烟草公司商洛分公司,陕西 商洛 726000;2.商洛市烟草公司商州分公司,陕西 商洛 726000)
0 引言
随着人工智能(Artificial Intelligence,AI)技术迅速发展,深度学习计算机视觉商品识别模型如AlexNet[1]、ResNet[2]、Faster R-CNN[3]等虽然取得显著成果,但是因其参数庞大、计算复杂度高,导致在资源受限设备上的应用不足。YOLO系列模型通过回归问题形式实现目标检测,表现出优异的速度与精度平衡性。
YOLOv5凭借其小尺寸、低部署成本、高灵活性及快速检测优势[4-6],特别适合移动终端应用。CA注意力机制作为一种轻量级且易于嵌入的目标检测模块,其增强了网络特征表达力,同时关注通道注意力与位置信息。鉴于YOLOv5与CA注意力机制在识别效率和部署便捷性方面的优点,本文融合两者构建卷烟品规智能识别模型。该模型能够提取卷烟图像特征并建立品规图像特征模型,以高效准确地识别卷烟品规,从而降低库存盘点识别成本并提高工作效率。
在模型构建过程中,首先收集并标注卷烟图像数据,运用YOLOv5、自注意力机制和transform等算法训练识别模型;其次进行模型轻量化处理,确保实际应用时的识别精度;最后对优化后的模型进行评估,检验量化过程是否导致精度损失及其程度。若评估结果显示模型精度仍处于可接受范围内,则进一步转换模型,最终将模型部署到终端设备上。
1 YOLOv5 模型
YOLOv5模型由输入处理、特征提取、特征融合及预测输出4个部分构成。在实际应用中,由于卷烟图像尺寸、像素质量和亮度各异,模型需在输入端进行数据增强、自适应锚框设置和图片自适应缩放。数据增强通过随机调整图像属性(如亮度、对比度等)以及进行裁剪、拼接和缩放,以丰富训练集并减轻图形处理器(Graphics Processing Unit,GPU)负载,提高模型性能。自适应锚框利用K均值聚类算法根据目标标签自动优化大小,自适应图片缩放则确保模型能灵活应对不同尺寸的卷烟图像,提升其适用性和稳定性。
2 改进YOLOv5 模型
2.1 CA注意力机制
CA注意力机制是一种深度学习模型的空间结构理解增强工具,通过引入坐标信息来捕捉输入特征图中位置间的关系。该机制包括通道特征提取和通道注意力计算2个步骤:首先,通道特征提取过程对每个通道执行全局平均池化与最大值池化并融合生成通道特征;其次,经全连接层和sigmoid函数处理后,通道注意力计算过程为特征图各像素点分配权重以构建加权特征图,突出重要空间位置。
相较于轻量级网络的注意力方法,CA注意力机制具有3大优势:(1)提升特征表达力,自适应地优化通道权重,有效发掘并利用关键通道信息,增强特征辨别性;(2)减少冗余,通过抑制无关紧要的通道减少无效计算,聚焦核心特征,降低复杂度且提高泛化能力;(3)改善模型性能,在多通道数据处理上尤其显著,其能更好地识别并利用通道间的相互依赖关系,加深模型对输入数据的理解。因此,CA注意力机制在图像处理、视频分析等领域广泛应用,有效提升了模型在多通道输入下的建模效能和整体性能。
2.2 改进后的模型总体结构
针对卷烟品规目标识别任务,本文借助深度学习的强大特征提取和分类能力,最终构建了一个多隐含层、多神经元节点的深度学习模型,如图1所示。该模型能够有效地提取卷烟品规的关键特征,实现对卷烟品规的准确识别。该模型能够更好地捕捉图像中的局部特征和空间信息,具有更强的图像识别能力。同时,模型的多个隐含层和多个神经元节点设计,提高了模型的非线性拟合能力,使得模型能够更好地适应卷烟品规数据的复杂和多样化特征。通过大量的数据样本训练,该模型能够有效地学习并识别不同卷烟品规的图像特征,从而实现对卷烟品规的精确识别。
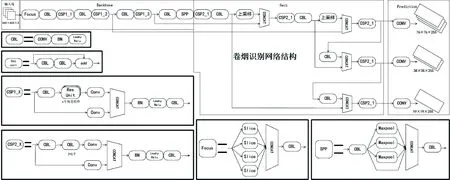
图1 改进的卷烟识别YOLOv5 模型结构
3 模型测试
测试硬件环境为Intel Xeon Gold 5318 H CPU(2.50 GHz, 64 GB RAM),配备Tesla V100 GPU(32 GB)及CUDA 10.2,在Linux x86_64系统上运行Python 3.7和PyTorch 1.8.1+cu102框架。当模型进行训练时,随机打乱数据集以避免固定分布,设置初始学习率为10-2、衰减率为0.94、批次大小为54,并进行100次迭代。采用Adam优化器与多类交叉熵损失函数,同时结合Checkpoint机制保存最优模型。针对过拟合问题,在全连接层前应用Dropout,概率设为0.3。
本次模型测试共采集数据集4800个,其中训练集为2880个,验证集为960个,测试集为960个。图像范围包括了在零售商户及烟库中分别采取的不同环境下的图像数据。
在测试集上YOLOv5和改进后的YOLOv5测试评估结果如表1所示。本文采用的模型算法精确度为89.7%,召回率为82.9%,mAP值为89.6%,其结果要优于改进前的算法。这些指标表明了该模型能够在数据集上实现较为准确的分类和识别,但也存在一定的潜在误差。在实际应用场景中,可以根据具体需要调整模型参数、数据集和训练策略,以提高模型的性能表现。如图2所示为目标检测结果示例,该模型能够有效地对多种不同类型的待测目标进行识别和分类。

表1 不同算法性能对比

图2 模型测试结果示例
4 结语
本文将YOLOv5与CA注意力机制结合,构建了一款卷烟品规智能识别模型,提升了对多通道输入数据的建模能力及模型性能和泛化性。实验结果显示,该系统在测试集上实现了89.7%的高识别准确率,相比仅使用YOLOv5时,其识别精度和mAP均有显著提升,尤其在卷烟品规图像识别方面表现出色。此研究成果预示着该模型在卷烟识别领域具有广阔的应用前景和较高的实用价值,能有效识别卷烟品规信息以支持生产和管理工作,不仅提高了效率,还降低了人工判断错误的风险。因此,对于提高卷烟品规识别的准确度和效率,该模型的研究具有重要意义。
