基于改进YOLO-Pose轻量模型的多人姿态估计
2024-05-30李传江汪著名张崇明
李传江 汪著名 张崇明
摘 要: YOLO-Pose作为人体姿态估计算法模型,在精度和速度上有着不错的表现,但其在复杂和有遮挡的场景下存在误检率较大的问题,并且模型的复杂度仍然有优化的空间. 针对这几个问题,通过选取Slim-neck模块和Res2Net模块,重新设计其特征融合层,减少其计算量和参数量,提高特征提取能力,在提升精度的同时,使模型轻量化;引入EIoU损失函数,加快边框检测的收敛速度,并提高定位的准确性. 在压缩的OC_Human数据集上进行测试,改进后的模型与YOLO-Pose相比,P值、mAP@0.5和mAP@.5:95分别提高了10.6,3.1和2.9个百分点. 此外,参数量和计算量也分别减少了16.7%和19.3%,在精度和轻量化方面均有所提升,为其应用在资源有限的边缘计算设备提供了可能性.
关键词: 人体姿态估计; YOLO-Pose; 轻量化; Slim-neck
中图分类号: TP 394.1 文献标志码: A 文章编号: 1000-5137(2024)02-0188-07
Multi-person pose estimation based on an improved lightweight YOLO-Pose model
LI Chuanjiang, WANG Zhuming, ZHANG Chongming*
(College of Information,Mechanical and Electrical Engineering,Shanghai Normal University,Shanghai 201418,China)
Abstract: YOLO-Pose as a human pose estimation algorithm model had a good performance in terms of accuracy and speed, which suffered from a large false detection rate in complex and occluded scenes on the other hand. There was still room for optimization of the model complexity. In this paper, these issues were addressed by incorporating the Slim-neck module and Res2Net module to redesign the feature fusion layer, reducing computational and parameter overhead while enhancing the information extraction capability of feature extraction. Furthermore, the EIoU loss function was introduced to accelerate the convergence speed of bounding box detection and to improve localization accuracy. Experimental results on the compressed OC_Human dataset demonstrated that the improved model achieved a 10.6% improvement in P-value, a 3.1% increase in mAP@0.5, and a 2.9% increase in mAP@.5:95 compared to the original YOLO-Pose model, respectively. Moreover, the amount of parameters (Params) and computational complexity (GFLOPs) were reduced by 16.7% and 19.3%, respectively. The improved model showed enhanced accuracy and lightweight characteristics, which was suitable for deployment on resource-constrained edge computing devices.
Key words: human pose estimation; YOLO-Pose; lightweighting; Slim-neck
0 引言
人体姿态估计是计算机视觉领域的重要研究方向之一,在人机交互、动作捕捉和姿态分析等许多应用领域具有重要的研究意义[1]. 近年来,随着深度学习的快速发展,基于深度學习的人体姿态估计方法取得了显著的进展. 相较于传统基于图结构模型和形变部件模型的人体姿态估计算法,基于深度学习的人体姿态估计算法在准确性和时效性方面都有明显的提升[2].
基于深度学习的多人姿态估计算法主要分为自顶向下和自底向上这两类检测方法[3]. 自顶向下的方法首先对所有人体轮廓进行识别,随后进行单人姿态估计,常见的算法如HRNet[4],CPN[5],CPM[6]等;自底向上的方法与自顶向下相反,首先检测人体关键点,提取关键点的特征,并预测出候选关键点,然后对候选关键点分组,常见的算法如OpenPose[7],Hourglass[8]及HigherHRNet[9]等. 采用自顶向下的方法,目标越多计算量越大. 而自底向上的方法虽然与人数无关,且拥有较快的检测速度,但是如果人与人之间有重叠的部分,预测候选关键点之后的分组就变得较为困难.
YOLO-Pose[10]能实现目标检测与人体姿态估计的功能,与自顶向下的方法不同,其基于YOLOv5[11]不需要使用独立的目标检测算法和单独的人体姿态估计网络来定位关键点. 另外,YOLOv5省略了关键点的后处理步骤和多次前向传播过程,这也与自底向上的方法不同[12]. 基于YOLOv7[13]和YOLOv8[14]的人體姿态估计算法进一步提升了精度. 虽然基于YOLO系列的人体姿态估计算法在精度和速度方面都更具优势,但该系列模型需优先处理人体目标检测结果,再进行相应位置的人体关键点回归操作,若人体目标检测结果有误,会直接影响人体姿态估计的准确性[15]. 在日常生活中,人体呈现出不同的姿态分布,基于YOLO系列的人体姿态估计在复杂的场景和存在遮挡的环境中误检率较高. 针对YOLO系列的人体姿态估计的识别问题,本文作者提出改进的YOLO-Pose模型,对比YOLOv7-Pose和YOLOv8-Pose,在保证模型精度提升的同时,改进的YOLO-Pose模型能降低参数量并减少运算量.
1 模型的改进
1.1 YOLO-Pose
作为一种新型无热图的联合检测方法,YOLO-Pose融合了自顶向下和自底向上两种人体姿态估计算法的优点,使每个被检测到的边界框都有一个与之关联的姿态,不需要通过额外步骤来将关键点组合成一个骨架,省去了自底向上方法的后期处理操作. 因此,YOLO-Pose仅通过一次前向传递就能完成所有人的定位和姿态估计. 此外,YOLO-Pose还引入了object keypoint similarity (OKS)损失函数,可以进行端到端的训练,并优化了OKS的度量.
1.2 改进YOLO-Pose方法
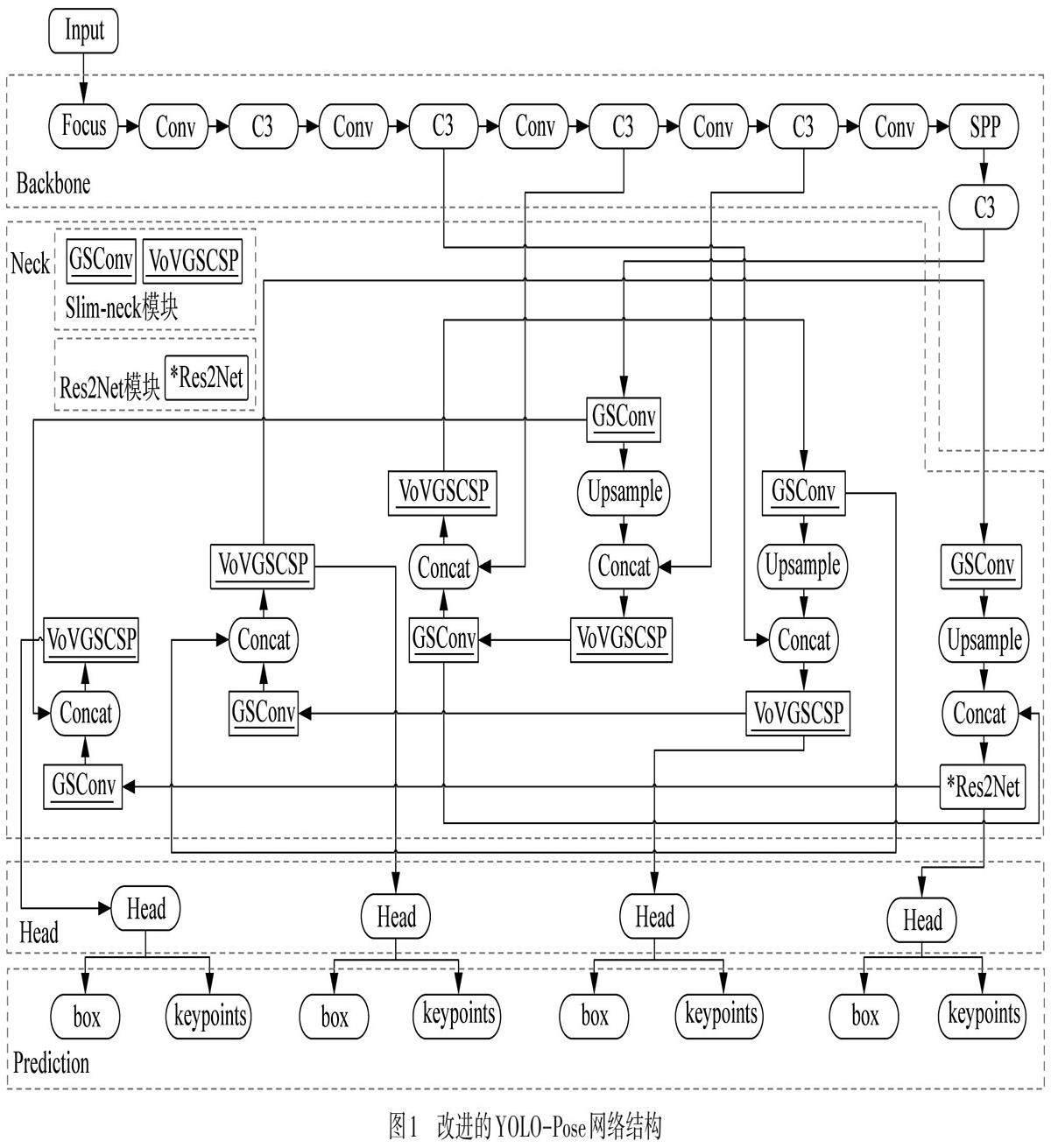
本文作者对YOLO-Pose的改进如图1所示. 基于YOLOv5网络框架,模型分为输入端(Input)、骨干网络层(Backbone)、特征融合层(Neck)、目标检测层(Head)和输出端(Prediction). 将YOLOv5中Neck层的一个C3卷积,用Res2Net模块(即图1中的*Res2Net)替换.Res2Net可以提取丰富的特征信息,从而提升模型的精度. 同时,将Neck层中的Conv和其余的C3卷积网络分别替换成Slim-neck模块的GSConv和VoV-GSCSP卷积网络(即图1中的GSConv和VoVGSCSP). 最后,将CIoU损失函数更换为EIoU损失函数,在训练时加速检测边框的定位与回归收敛速度.
1.3 Slim-neck模块
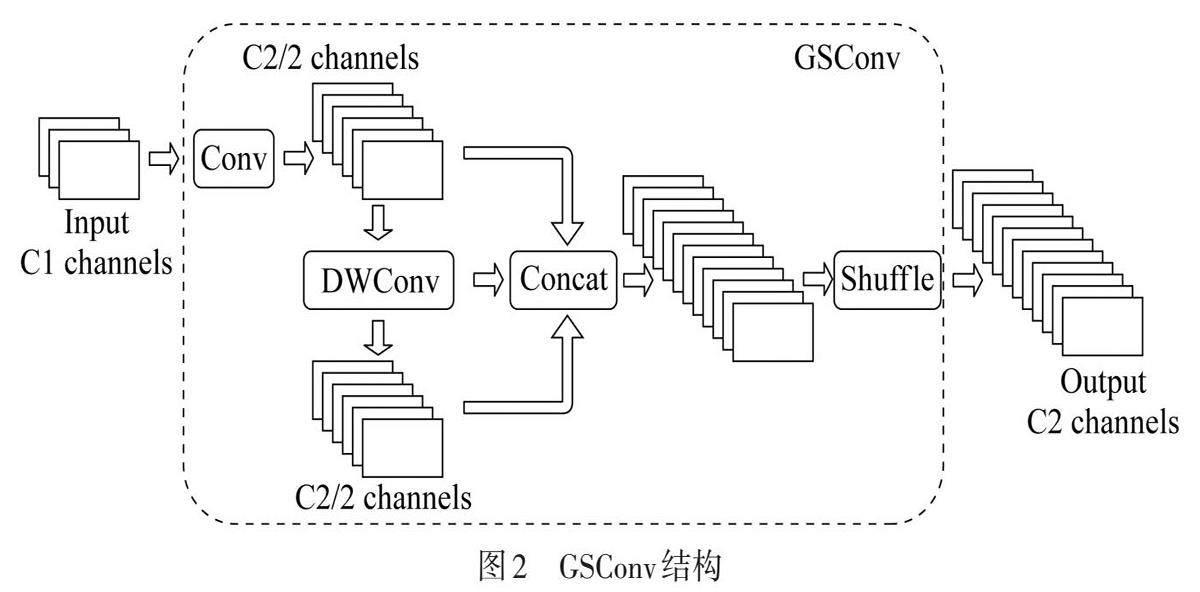
Slim-neck引入了一种新的卷积方法GSConv来替换标准卷积Conv. 在GSConv方法中,首先需要通过Conv的卷积处理,接着对处理的结果进行深度可分离卷积(DWConv)处理,最后将两个卷积处理的结果拼接(Concat)起来进行混洗(Shuffle)操作[16],如图2所示.
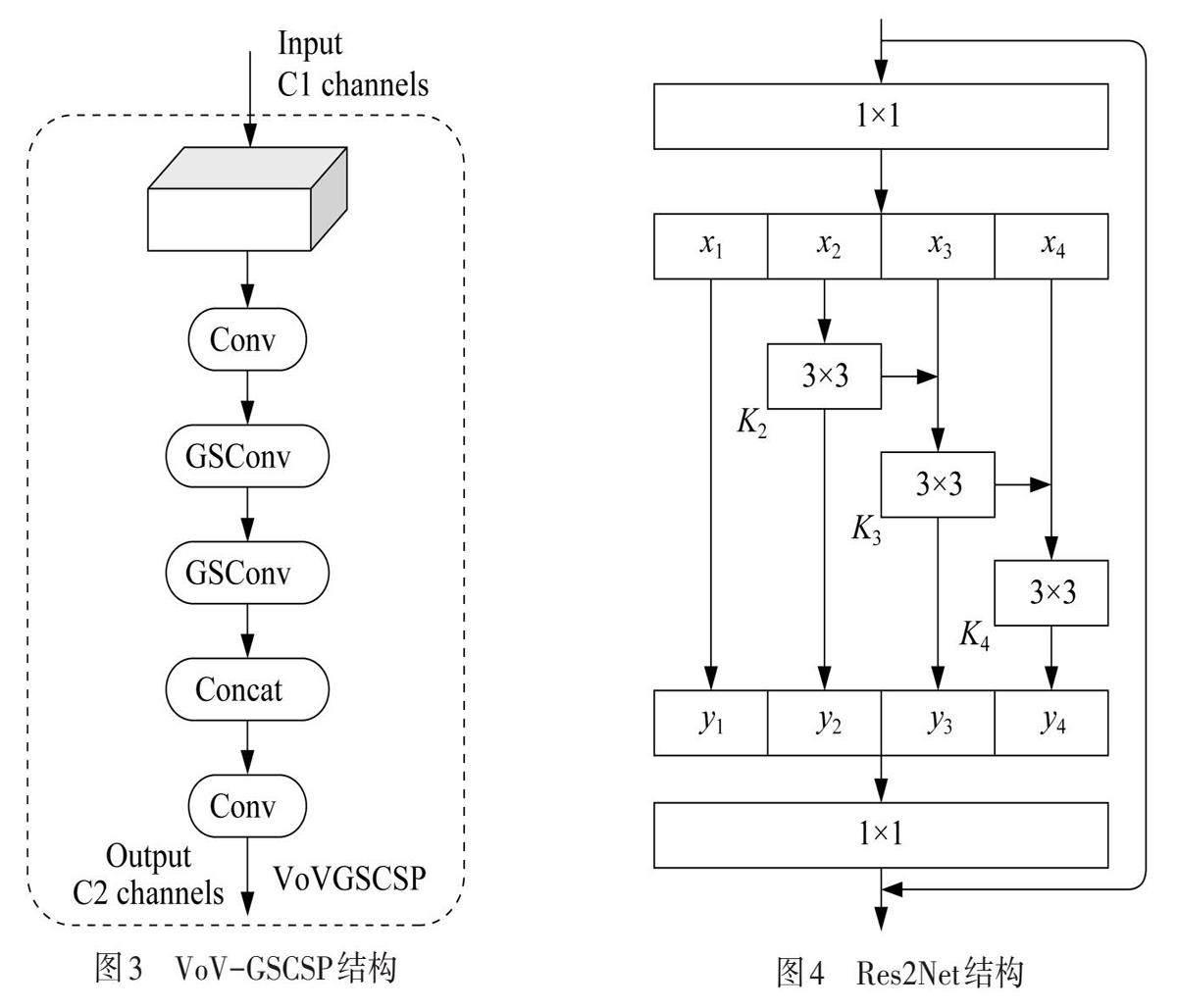
此外,通过采用一次性聚合策略,构建VoV-GSCSP模块,如图3所示. 本文作者将YOLO-Pose模型网络特征融合层中大部分的C3模块替换为VoV-GSCSP模块,在减少原有计算量并降低复杂度的同时,确保其精度不受影响.
1.4 Res2net模块
基于ResNet[17]模型,Res2Net模块将原有的卷积操作分解为多个子模块,每个子模块都能够利用更丰富的特征信息,从而增强了网络的表达能力[18],如图4所示. Res2Net模块能够更好地捕获不同尺度的特征信息,而无需增加网络的深度. Res2Net模块包含多分支的残差块,这些分支各自拥有独立的卷积层,负责处理不同分辨率的特征. 通过将这些分支的输出串联起来,Res2Net模块能够同时学习低分辨率和高分辨率的特征表示,从而提高了网络的感知能力. 在YOLO-Pose模型中的特征融合层加入Res2Net模块,进一步提高特征提取的能力,使模型在不增加网络深度的同时,提高网络的精度.
1.5 EIoU损失函数
传统的IoU损失函数![]() 在两个边界框不相交时,无法提供有效的梯度更新,且无法反映边界之间的距离远近,导致收敛速度较慢[19]. CIoU损失函数
在两个边界框不相交时,无法提供有效的梯度更新,且无法反映边界之间的距离远近,导致收敛速度较慢[19]. CIoU损失函数![]() 引入了纵横比
引入了纵横比![]() 来考虑边界框的纵横比差异,
来考虑边界框的纵横比差异,
![]() , (1)
, (1)
其中,![]() 是预测框的中心位置点
是预测框的中心位置点![]()
![]() 是真實框的中心位置点
是真實框的中心位置点![]()
![]() 是预测框和真实框中心点之间的欧式距离;c是预测框和真实框最小外接矩形对角线的长度
是预测框和真实框中心点之间的欧式距离;c是预测框和真实框最小外接矩形对角线的长度![]()
![]() 是平衡参数
是平衡参数![]()
![]() 是用来评估预测框和真实框宽高比一致性的参数.
是用来评估预测框和真实框宽高比一致性的参数.
然而,![]() 并没有直接考虑边界框的宽度和高度与其置信度的真实差异[20]. 另外,
并没有直接考虑边界框的宽度和高度与其置信度的真实差异[20]. 另外,![]() 无法提供足够的梯度信号来引导网络正确地调整边界框的宽度和高度.对此,EIoU给出了改进的损失函数
无法提供足够的梯度信号来引导网络正确地调整边界框的宽度和高度.对此,EIoU给出了改进的损失函数
![]() , (2)
, (2)
其中,![]() 分别为预测及真实的边界框宽度;
分别为预测及真实的边界框宽度;![]() 分别为预测及真实的边界框高度;
分别为预测及真实的边界框高度;![]() 是覆盖预测框和真实框最小封闭框的宽度
是覆盖预测框和真实框最小封闭框的宽度![]()
![]() 覆盖预测框和真实框最小封闭框的高度.
覆盖预测框和真实框最小封闭框的高度.
![]() 的宽、高损失直接使预测框与真实框的宽、高度之差最小化,使得算法收敛速度较快[21]. 采用
的宽、高损失直接使预测框与真实框的宽、高度之差最小化,使得算法收敛速度较快[21]. 采用![]() 替换
替换![]() ,在加快檢测边框回归收敛速度的同时,提升网络模型的精度.
,在加快檢测边框回归收敛速度的同时,提升网络模型的精度.
2 实验结果与分析
2.1 数据集准备
本研究实验在数据集OC_Human上进行,该数据集共有5 081张标注的图片[22]. 由于数据集的图片中大部分人体被遮挡且背景较为复杂,对人体姿态的估计具有较大难度. 在原有数据集的基础上做了进一步压缩,从5 081张图片选取了1 000张图片按照8∶2的比例划分为800张训练集图片和200张测试集图片.
2.2 实验平台及参数
本实验采用的模型训练和测试平台为GPU服务器,配置参数如表1所示.
统一设置YOLO模型训练超参数:初始学习率为0.01,周期学习率为0.20,采用warmup优化策略,开启Mosaic数据增强和翻转方式,动量因子为0.937,训练迭代次数为300次,输入的图片尺寸为640 pixels×640 pixels,批次为16,均无预训练权重.
2.3 评估指标
在姿态估计评估指标中,精确率P、召回率R、平均精度AP和平均精度均值mAP为常见的评估指标,
![]() , (3)
, (3)
![]() , (4)
, (4)
![]() , (5)
, (5)
![]() , (6)
, (6)
其中,![]() 为真实正样例;
为真实正样例;![]() 为错误正样例;
为错误正样例;![]() 为错误反样例;
为错误反样例;![]() 为R的精度值;c为类别的数量.
为R的精度值;c为类别的数量.
用mAP@0.5表示![]() 的阈值为0.50时的精度值,用mAP@.5:95表示
的阈值为0.50时的精度值,用mAP@.5:95表示![]() .阈值从0.50到0.95,步长为0.05,即阈值分别为0.50,0.55,…,0.90,0.95时的平均精度值. 参数量用来表示模型的空间复杂度,每秒10亿次的浮点运算次数(GFLOPs)用来表示模型的时间复杂度.
.阈值从0.50到0.95,步长为0.05,即阈值分别为0.50,0.55,…,0.90,0.95时的平均精度值. 参数量用来表示模型的空间复杂度,每秒10亿次的浮点运算次数(GFLOPs)用来表示模型的时间复杂度.
2.4 对比实验
在OC_Human数据集上实验结果如表2所示. 可以看出,相较于其他网络模型,YOLOv7-Pose的R值最大,而改进的YOLO-Pose整体优于其他网络模型,其P值为81.2%,mAP@0.5为69.2%,mAP@.5:95为41.3%,相较于YOLO-Pose分别增加了10.6,3.1和2.9个百分点;参数量下降到了10 MB,GFLOPs下降到了13.8,分别减少了16.7%和19.3%.
实验结果表明:改进的YOLO-Pose模型在提升精度的同时,降低了模型复杂度,减少了计算量,在轻量化方面也有一定的提升.
2.5 消融实验
消融实验的结果如表3所示. 从实验结果可以得出,加入Slim-neck模块后,网络模型的整体精度和性能都有所提升,参数量减少了16.7%,P值、mAP@0.5和mAP@.5:95分别增加了5.3,2.8和0.3个百分点,但R值有所下降;在此基础上,加入Res2Net模块,虽然P值有所下降,但整体的精度仍有提升,mAP@0.5和mAP@.5:95分别增加了3.1和1.8个百分点;再将网络模型的CIoU损失函数替换为EIoU损失函数,虽然R值下降了2.3个百分点,但P值和mAP@.5:95提升明显,分别增加了9.6和2.9个百分點.
3 结语
本文作者改进了YOLO-Pose网络模型,引入Slim-neck模块,在提升模型精度的同时实现了模型的轻量化;添加Res2Net模块,改善了网络特征提取的性能,并增加了网络层的感受野,进一步提升模型的精度;通过EIoU改良损失函数,提高检测框回归的收敛速度和精度. 实验结果表明:本研究的改进方法较之原YOLO-Pose,在OC_Human数据集上的执行精度更高,并更为轻量化. 由于本研究对实验数据集进行了一定的压缩,虽然有效减少了训练的成本和训练的时间,但会降低模型的泛化能力,故在保证精度的同时,更加充分、高效地使用数据集训练是未来研究的方向.
参考文献:
[1] 张欣毅, 张运楚, 王菲, 等. 改进YOLOpose的轻量化多人姿态检测模型 [J/OL]. 小型微型计算机系统, 2023 [2023-10-10]. https://link.cnki.net/urlid/21.1106.TP.20230918.1654.015.
ZHANG X Y, ZHANG Y C, WANG F, et al. Lightweight multiplayer pose detection model with improved YOLO pose [J/OL]. Journal of Chinese Computer Systems, 2023 [2023-10-10]. https://link.cnki.net/urlid/21.1106.TP.20230918.1654.015.
[2] 王珂, 陈启腾, 陈伟, 等. 基于深度学习的二维人体姿态估计综述 [J/OL]. 郑州大学学报(理学版),2023 [2023-10-10]. https://doi.org/10.13705/j.issn.1671-6841.2022334.
WANG K, CHEN Q T, CHEN W, et al. Overview of 2D human pose estimation based on deep learning [J]. Journal of Zhengzhou University(Natural Science Edition), 2023 [2023-10-10]. https://doi.org/10.13705/j.issn.1671-6841.2022334.
[3] 安胜彪, 贾鹏园, 白宇. 基于HRNet的高效人体姿态估计算法 [J]. 无线电工程, 2023,53(9):2028-2035.
AN S B, JIA P Y, BAI Y. An efficient human pose estimation algorithm based on HRNet [J]. Radio Engineering, 2023, 53(9):2028-2035.
[4] SUN K, XIAO B, LIU D, etal. Deep high-resolution representation learning for human pose estimation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach:IEEE, 2019:3349-3364.
[5] CHEN Y L, WANG Z C, PENG Y X, et al. Cascaded pyramid network for multi-person pose estimation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City:IEEE, 2018:7103-7112.
[6] WEI S E, RAMAKRISHNA V, KANADE T, et al. Convolutional pose machines [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas:IEEE, 2016:4724-4732.
[7] CAO Z, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu:IEEE, 2017:1302-1310.
[8] NEWELL A, YANG K, DENG J. Stacked hourglass networks for human pose estimation [C]// European Conference on Computer Vision. Amsterdam:Springer, 2016:483-499.
[9] CHENG B W, XIAO B, WANG J D, et al. HigherHRNet:scale-aware representation learning for bottom-up human pose estimation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle:IEEE, 2020:5385-5394.
[10] MAJI D, NAGORI S, MATHEWM, et al. Yolo-pose: enhancing yolo for multi person pose estimation using object keypoint similarity loss [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New Orleans:IEEE, 2022:2636-2645.
[11] ZHU X K, LYU S C, WANG X, et al. TPH-YOLOv5: improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios [C]// IEEE/CVF International Conference on Computer Vision Workshops. Montreal:IEEE, 2021:2778-2788.
[12] 王红霞, 李枝峻, 顾鹏. 基于YOLOPose的人体姿态估计轻量级网络 [J]. 沈阳理工大学学报, 2023, 42(6):10-16.
WANG H X, LI Z J, GU P. A lightweight network for human pose estimation based on YOLOPose [J]. Journal of Shenyang Ligong University, 2023, 42(6):10-16.
[13] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver:IEEE, 2023:7464-7475.
[14] ABOAH A, WANG B, BAGCI U, et al. Real-time multi-class helmet violation detection using few-shot data sampling technique and YOLOv8 [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver:IEEE, 2023:5350-5358.
[15] 王名赫, 徐望明, 蔣昊坤. 一种改进的轻量级人体姿态估计算法 [J]. 液晶与显示, 2023, 38(7):955-963.
WANG M H, XU W M, JIANG H K. Improved lightweight human pose estimation algorithm [J]. Chinese Journal of Liquid Crystals and Displays, 2023, 38(7):955-963.
[16] LI H L, LI J, WEI H B, et al. Slim-neck by GSConv: a better design paradigm of detector architectures for autonomous vehicles [J/OL]. arXiv: 2206.02424, 2022 [2023-10-10]. http:// arxiv.org/abs/2206.02424.
[17] TARG S, DIOGO A, KEVIN L. Resnet in resnet: generalizing residual architectures [J/OL]. arXiv: 1603.08029, 2016[2023-10-10]. http:// arxiv.org/abs/163.08029.
[18] GAO S H, CHENG M M, ZHAO K, et al. Res2net: a new multi-scale backbone architecture [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(2):652-662.
[19] ZHENG Z H, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression [C] // Conference on Artificial Intelligence. New York:AAAI, 2020:12993-13000.
[20] 赵江河, 王海瑞, 朱贵富, 等. 改进CenterNet的小目标安全帽检测算法 [J]. 陕西理工大学学报(自然科学版), 2023,39(3):40-47.
ZHAO J H, WANG H R, ZHU F G, et al. Algorithm of small target helmet detection based on improved CenterNet [J]. Journal of Shaanxi University of Technology (Natural Science Edition), 2023,39(3):40-47.
[21] ZHEN Z, DENG Z J, WU Z P, et al. An improved EIoU-Yolov5 algorithm for blood cell detection and counting [C] //2022 5th International Conference on Pattern Recognition and Artificial Intelligence. Chengdu:IEEE, 2022:989-993.
[22] KHIRODKAR R, CHARI V, AGRAWAL A, et al. Multi-instance pose networks: rethinking top-down pose estimation [C] // IEEE/CVF International Conference on Computer Vision. Montreal:IEEE, 2021:3102-3111.
(责任编辑:包震宇,郁慧)
DOI: 10.3969/J.ISSN.1000-5137.2024.02.007
收稿日期: 2023-12-25
作者简介: 李传江(1978—), 男, 教授, 主要从事人工智能与机器学习、智能机器人和医工融合产品开发等方面的研究. E-mail: licj@shnu.edu.cn
* 通信作者: 张崇明(1973—), 男, 副教授, 主要从事智能硬件和人工智能应用技术方面的研究. E-mail: czhang@shnu.edu.cn
引用格式: 李传江, 汪著名, 张崇明. 基于改进YOLO-Pose轻量模型的多人姿态估计 [J]. 上海师范大学学报 (自然科学版中英文), 2024,53(2):188?194.
Citation format: LI C J, WANG Z M, ZHANG C M. An improved lightweight algorithm for multi-person pose estimation based on YOLO-Pose [J]. Journal of Shanghai Normal University (Natural Sciences), 2024,53(2):188?194.
