基于Real ESRGAN的视频修复系统研究
2024-05-30黄杰夏远洋杨晓杰王思洁田佩刘涛
黄杰 夏远洋 杨晓杰 王思洁 田佩 刘涛
基金项目:2022年度重庆对外经贸学院科研项目(KYKJ202201)
第一作者简介:黄杰(2000-),男,助理实验师。研究方向为计算机技术与图形处理。
DOI:10.19981/j.CN23-1581/G3.2024.15.010
摘 要:图像修复和视频修复是计算机视觉的一项重要任务,其中图像修复又是视频修复的基础。为此,如何有效提升图像质量是实现视频质量提升的关键。传统的图像修复算法主要以样本信息为基础,通过对样本内容的扩撒来实现对破损区域的修复;由于这种方式对于图像样本有一定要求,从而制约传统图像修复技术的发展。为此,以生成新图像内容为基础的神经网络如GAN的出现,为图像修复技术转向深度学习提供方向。该课题主要以Real ESRGAN网络的图像修复技术为基础,通过对音频视频数据的隔离处理以及相同帧数据的优化和标记,构建视频修复处理流程。通过对随机视频样本的测试,并通过对单帧图片质量和视频数据流畅性与协调性的评估,该视频处理方法表现出较好的系统性能。
关键词:图像分割;神经网络;视频修复;Real ESRGAN;图像修复
中图分类号:TP301.6 文献标志码:A 文章编号:2095-2945(2024)15-0046-05
Abstract: Image repair and video repair is an important task of computer vision, in which image repair is the basis of video repair. Therefore, how to effectively improve the image quality is the key to improve the video quality. The traditional image restoration algorithm is mainly based on the sample information, through the expansion of the sample content to achieve the repair of the damaged area; because this method has certain requirements for image samples, which restricts the development of traditional image restoration technology. For this reason, the emergence of neural networks based on generating new image content, such as GAN, provides a direction for image restoration technology to turn to deep learning. This topic is mainly based on the image restoration technology of Real ESRGAN network. Through the isolation processing of audio and video data and the optimization and marking of the same frame data, the video restoration process is constructed. Through the test of random video samples and the evaluation of single-frame picture quality and video data fluency and coordination, the video processing method shows good system performance.
Keywords: image segmentation; neural network; video inpainting; Real ESRGAN; image inpainting
伴隨着互联网技术的发展,人类的社交生活也产生了极大的变化,线上社交逐步成为当前社交的主流,而社交媒介也从原始的文字逐步转变成了内容更加丰富的图片和视频。人们越来越喜欢通过图片和视频内容来分享自己日常的生活,但也因此需要对前期拍摄的内容进行大量的编辑和处理。此外,老照片、旧影像的内容因原始采集技术限制、介质老化以及保存不当等原因,出现斑点、划痕、模糊等问题,而这些内容往往都极具价值。因此,如何利用现有的技术对其进行增强、修复在计算机视觉领域极具价值。
图像修复和视频修复,主要是指利用图像或视频周围区域的信息,对图像或视频中的破损内容进行处理,以提升图像或视频原有的品质。其作为计算机视觉的一项重要任务,研究由来已久。最早的图像修复是将物理学热传导原理应用到图像环境中,通过将局部源信息(这里指未破损区域)平滑地传播到破损的孔区域并进行内容填充来实现[1]。后来,逐步发展为基于扩散、基于块和全局优化等相关方法[2-4]。这些传统的修复方法在一些纹理简单、内容复杂的图片和视频上能表现出较好的效果,但在面对复杂纹理时则不尽人意。主要原有在于:
1)传统图像和视频的修复方法缺乏自主生成未知的新内容的能力,导致原始内容出现大面积破损时,修复效果不佳;
2)传统图像和视频的修复方法缺乏泛化性,致使每次修复都需要重新实践一次。
因此,面对当前复杂的图像和视频的修复需要,传统的修复方法很难适用[5]。伴随着深度学习的兴起,神经网络模型在计算机视觉领域表现出了优异的效果[6-7],特别是如CNN、GAN等网络模型能够生成以假乱真的内容,给图像和视频修复领域带来了广泛的研究前景。本文主要基于Real ESRGAN神经网络模型,展开对视频修复内容的研究。
1 理论基础
Real ESRGAN神经网络是一种盲图像超分辨率模型,是在ESRGAN、SRGAN、GAN等网络模型的基础上发展而来,通过纯合成数据来进行训练,模拟出高分辨率图像变低分辩率过程,以低清图倒推出它的高清图的算法。为了更好了解该算法的原理,分别针对ESRGAN、SRGAN、GAN及CNN等网络模型进行了系统性的研究。
1.1 基于 CNN 的图像修复理论
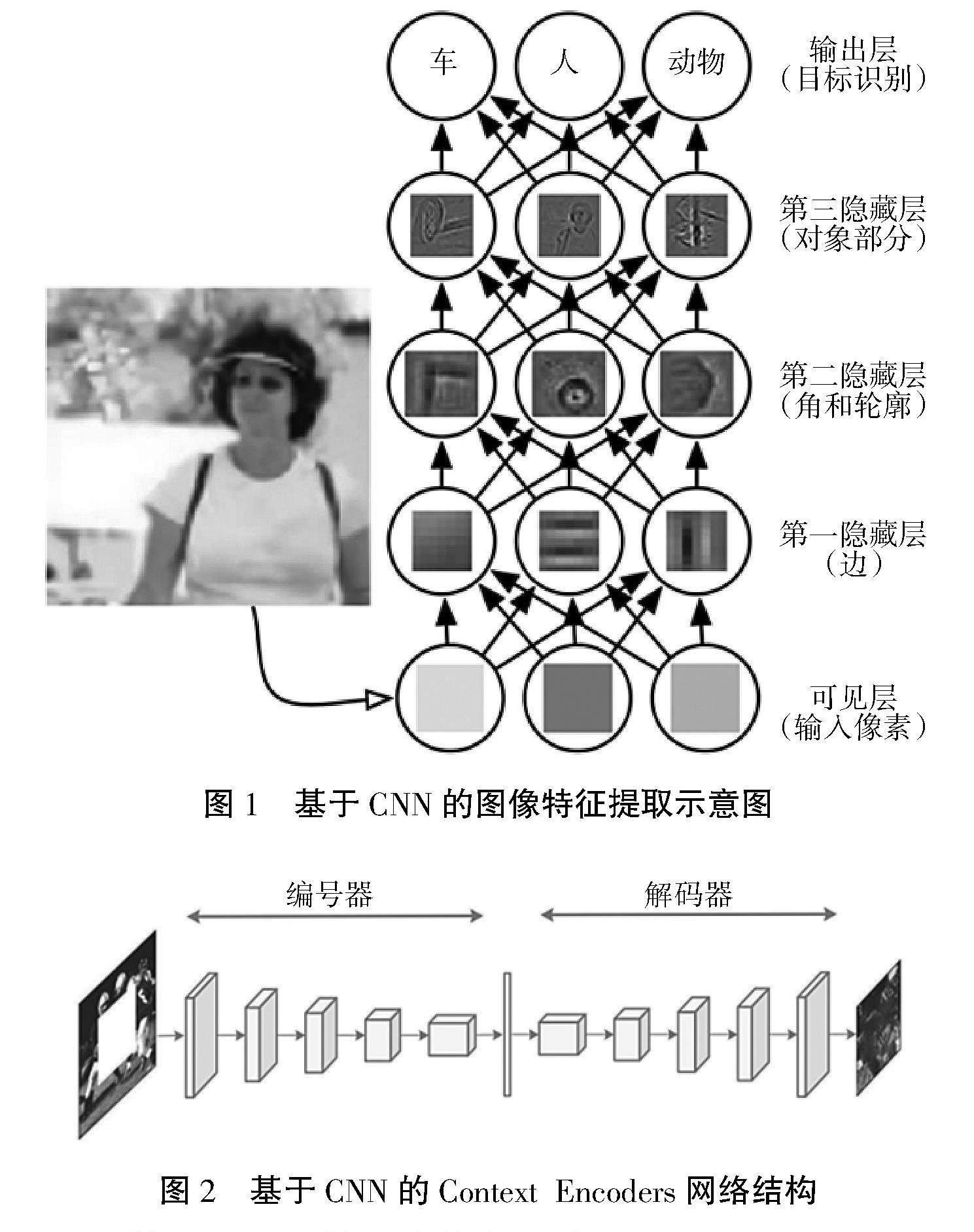
从低维像素信息抽取到高维特征信息呈现的过程是CNN网络实现特征提取的主要特征[8],而这种抽取特征的能力正是深度学习中图像和视频修复的理论基础。CNN特征提取编码器的功能主要借助多层隐含层来实现,具体如图1所示。在将整幅图像的像素信息传入网络后,为了逐步获取到较高维的边缘信息、轮廓信息等信息,CNN网络构建了3层隐藏层,第一层进行边特征提取,第二层实现角和轮廓特征提取,第三层构建对象特征提取,通过多层隐层之间的卷积和池化操作最终获取到图像中的高维对象信息,从而实现了对整幅图的抽象理解。
随后,Krizhevsky等[9]根据CNN的特征提取能力提出了 Context Encoders 网络,该网络通过将图像分类 中流行的 AlexNet 网络[10]和图像修复过程中的编码和解码相结合,构建了深度学习中经典的编解码图像修复方法,相关结构如图2所示。通过前侧嵌入5 层 AlexNet 结构实现特征提取编码器功能,后侧再使用 5 层AlexNet 结构生成特征解码器功能,从而实现图像从特征提取到特征还原的整个过程。
图1 基于CNN的图像特征提取示意图
图2 基于CNN的Context Encoders网络结构
1.2 基于 GAN 的图像修复理论
Context Encoders 网络有效解决了特征提取和特征还原的问题,但其严重依赖于图像内容本身,图像修复中关于的生成未知内容的能力一直没有得到很好的提升,因此能够生成未知图像内容的网络成为了当前图像修复亟待探索的问题。
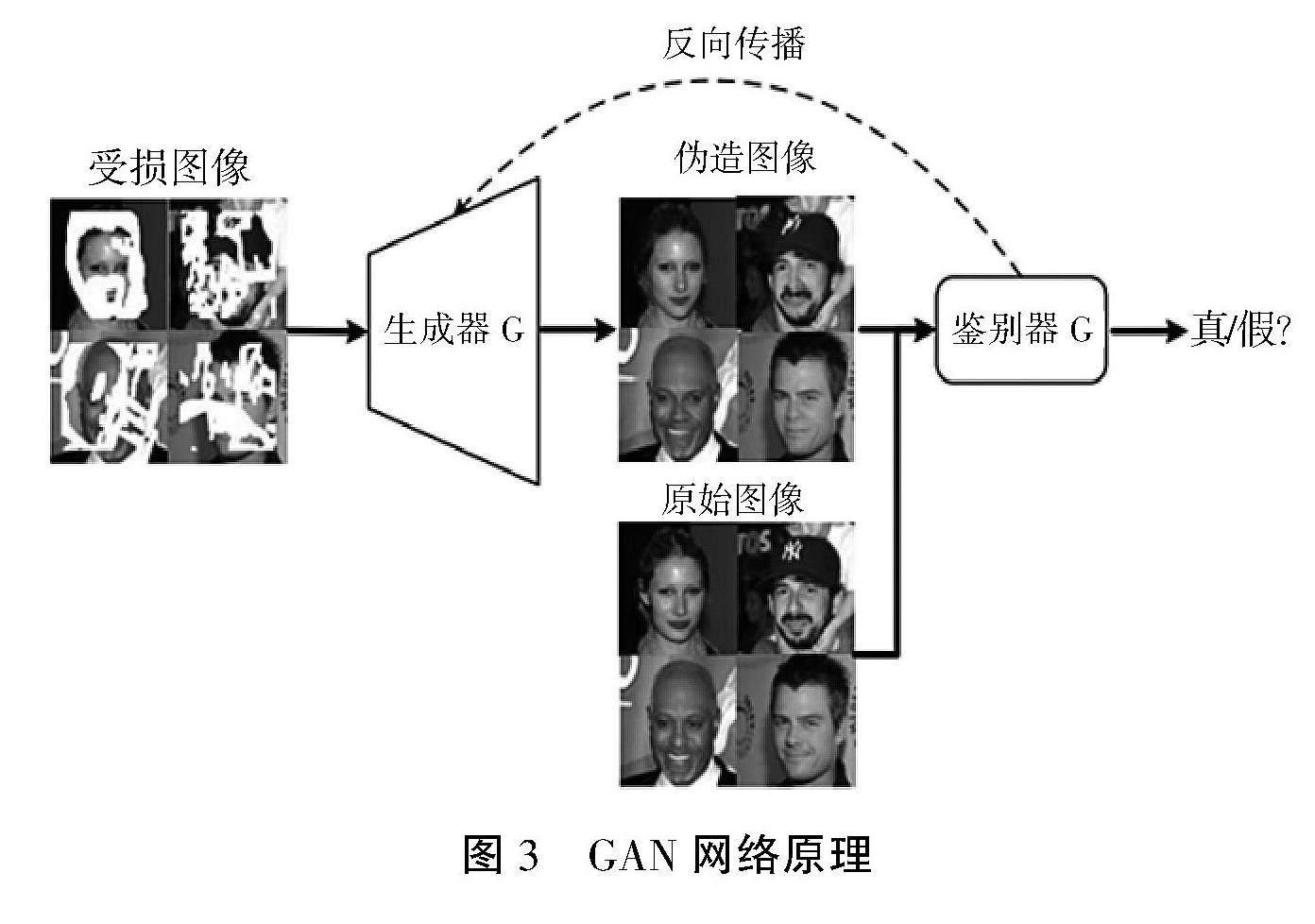
2014 年 Salimans等[11]创新性地提出了具有强大内容生成能力的GAN网络,瞬间引起了国内外学者的广泛关注。GAN网络原理图如图3 所示。GAN网络主要由2部分构成,分别是生成器G和鉴别器 D 2个部分,其中生成器G采用了编解码结构,通过对输入样本数据潜在概率分布的学习,输入随机噪声以生成伪造的样本数据;鉴别器D则是是一个特征提取的二分网络,用于判定输出的样本的状态,如果状态为真则判定标签为 1;否则判定标签为 0。鉴别器的主要目标是尽可能地区分样本状态,并通过结果反馈进行不断地优化调整,最终达到动态平衡的过程。
虽然GAN效果很好,但是常常面临着训练困难、梯度消失等问题,后续学者又在此基础上提出了 DCGAN、条件GAN、Wasserstein GAN、PatchGAN等改良版的 GAN网络[12],这些都在一定程度上对 GAN 难收敛、梯度消失等训练问题进行了改进,能够生成更高质量的图像。其中以Real ESRGAN、ESRGAN和SRGAN 等最为典型。
图3 GAN网络原理
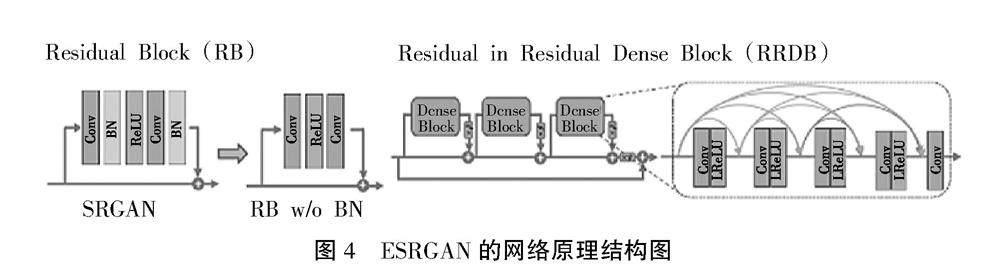
为了解决一个很大的上采样因子进行超分时,如何恢复出更精细的纹理细节问题,SRGAN提出了一个包含对抗adversarial loss和content loss的感知loss取代了MSE loss的方法。而ESRGAN网络则是针对SRGAN的一些改进,ESRGAN网络结构图如图4所示。其首先对生成器网络引入了一个残差密集连接模块Residual-in-Residual Dense Block (RDDB), 并且去掉了网络中所有的BN层,并且加入一个残差scaling操作使能够训练更深的网络结构;其次对判别器进行改进,由“这张图是真的还是假的”修改为“这张图是否比假的更真实一点”;最后对感知loss做了改进,使用VGG激活前的特征修订而不是SRGAN内的特征。
而Real ESRGAN是一个完全使用纯合成数据去尽可能贴近真实数据,然后去对现实生活中数据进行超分的一个方法。其生成器的结构和ESRGAN几乎一致,不同在于输入时不仅需要进行4倍下采样,还有1倍和2倍的下采样操作,同时为了减小计算量,还做了一个Pixel Unshuffle的操作,即将输入分辨率减小,通道增加。
2 视频修复算法的设计
基于Real ESRGAN 的视频修复研究主要从3个阶段进行,第一阶段是图像的分割,通过对视频的分割处理,降低运算过程;第二阶段是视频相关帧的预测,通过第一阶段分割的图形来有效去除图形中的相同像素信息;第三个是使用Real ESRGAN对图像进行超分率或者对视频的细节进行增强。具体流程如图5所示。
首先,加載原始视频数据,然后利用FFmpeg工具(FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为数据流的一种工具)对视频进行处理,这里主要是将音频内容和视频内容进行分离和切割。通过对分离的音频数据的分离,可以有效避免音频数据对视频数据内容的污染,通过对视频数据的切割,可以有效调节视频帧的间隔指数,从而有效调整图像运算的计算量。图像帧越多,对于图像计算的尺度就越大。
然后,加载切割后保存的图像帧,并针对相邻图像帧进行图像内容检测分析,若相邻帧之间的图像无明显差异,则会被视为相同的图像帧予以标记,并将重复图像帧进行删除,通过对所有图像帧进行检测分析,最终得到目标图像帧。在这个过程中,进行重复帧检测的目的亦是为了降低后续Real ESRGAN网络的运算压力,而图像帧标记的目的则是为了后期进行视频合成时,针对删除的图像帧进行内容替换,从而确保视频内容的完整性。
最后是利用Real ESRGAN 網络进行视频内容修复,通过网络拥有生成新内容的特性,并以目标图像帧为参考基准,针对生成的图像内容进行检测和评估,如果生成的图像帧内容达到评估要求,对其进行保存并参与下一轮图像内容的生成和评估,如此循环往复,从而得到最符合要求的图像帧。在经过Real ESRGAN 网络判定后,生成的图像内容需要首先还原成视频,然后才能将视频内容与音频内容进行合并,为了简化这一过程,依然借助FFmpeg来实现。
以上便是视频修复算法的完整过程,其中较难的点在于文件中音视和视频的合并和分割,以及视频内容的检测。而这2个过程主要通过FFmpeg工具和高斯混合模型GMM实现。
3实验分析与验证
本次课题研究主要以Real ESRGAN神经网络模型为基础,通过Python程序语言来实现算法流程。实验实践平台在Win10操作系统上,硬件参数:CPU为intelCorei5-6300HQ,2.30 GHz;内存为12.00 GB,实验中的数据来源于哔哩哔哩网络视频《罗小黑战记》数据,片长3 min19 s,屏幕分辨为450×360像素,经过本算法进行修复,视频像素分辨为提升为1 800×1 400,在人为对比观测下,视频内容有了显著的提升。
在实际的验证过程中,主要通过2个阶段来进行。第一阶段是对单帧图片内容进行评估,利用局部细节来观测生成的图片质量;第二阶段是针对合成后的视频进行评估,利用视频内容的流畅性和音频视频内容的协调性来观测合成后的视频质量。
这里以第389帧为例,来进行第一阶段的评估。相关内容如图6所示,左侧图像是处理前,右侧是图像处理后。
通过对389帧图像处理前后的对比,可以明显观测到处理前,图片的整体色彩偏淡,局部轮廓不清晰,总体效果模糊;而处理后的图片,色彩明亮,局部轮廓明显,总体效果清晰。因此可以有效判定处理后的图像质量更好。
(a) 第389帧处理前 (b) 第389帧处理后
图6 图片质量评估
同时在对合成前后的视频进行对比分析发现,视频前后的时长为发送变化,视频质量有明显提升;其次视频和音乐对象同轨,未发现音频和视频不同步的问题;因此可以判定合成后的视频对原始视频的修复有效。
4 结束结
本课题在充分应用Real ESRGAN神经网络的优势的同时,采取将视频内容转换成图片内容,并基于图形层面来实现对每一帧画面细节增强的做法较有效地解决了视频数据计算量大的问题,同时使用FFmpeg工具来实现音频数据和视频数据分离和合成的方式,有效实现了利用重新生成的内容来重构视频内容,从而达到视频修复的目的。但视频处理过程片长,这将是后期进行该项研究改进的一个主要方向之一。
参考文献:
[1] BERTALMIO M, SAPIRO G, CASELLES V, et al. Image inpainting[C]//International Conference on Computer Graphics and Interactive Techniques,2000:417-424.
[2] CRIMINISI A, PEREZ P, TOYAMA K. Region filling and object removal by exemplar-based image inpainting[J].IEEE Transactions on Image Processing,2004,13(9):1200-1212.
[3] AHIRE B A, DESHPANDE N A. Video inpainting of objects using modified patch based image inpainting algorithm[S].2014:1-5.
[4] 薄德智.基于深度学习的图像和视频修复方法的研究[D].上海:上海大学,2021.
[5] XIE J, XU L, CHEN E. Image denoising and inpainting with deep neural networks[C]//Neural Information Processing Systems,2012:341-349.
[6] ZHENG C, CHAM TJ, CAI J. Pluralistic image completion[C]//Computer Vision and Pattern Recognition,2019:1438-1447.
[7] GOODFELLOW I, BENGIO Y, COURVILLE A. Deep learning[M].The MIT Press,2016.
[8] PATHAK D, KRAHENBUHL P, DONAHUE J, et al. Context Encoders: feature learning by inpainting[C]//Computer Vision and Pattern Recognition,2016:2536-2544.
[9] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of The Acm,2017,60(6):84-90.
[10] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]//Neural Information Processing Systems,2014:2672-2680.
[11] SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs[C]//Neural Information Processing Systems,2016:2234-2242.
[12] ISOLA P, ZHU J-Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks[C]//Computer Vision and Pattern Recognition,2017:5967-5976.
