基于YOLO v7的海量烟支外观缺陷快速自动标注方法
2024-05-30吕献周蒋铭李庆松吴仕超余茜
吕献周 蒋铭 李庆松 吴仕超 余茜


基金项目:红云红河烟草(集团)有限责任公司科技项目(HYHH2022ZK01)
第一作者简介:吕献周(1986-),男,工程师。研究方向为卷烟工艺质量管理。
*通信作者:余茜(2000-),女,硕士研究生。研究方向为机器学习,统计学习。
DOI:10.19981/j.CN23-1581/G3.2024.15.009
摘 要:图像标注作为监督式机器学习的关键环节,在处理海量的烟支缺陷数据时,传统的人工标注方法由于耗时长和主观性强等缺点显得不够高效。针对烟支缺陷检测领域中大量图像数据的自动化标注挑战,该文以YOLO v7作为基线网络,并进行一系列经验性的改进,以解决传统人工标注过程中存在的高成本和低效率问题。通过对YOLO v7的结构进行创新性调整,如合并neck层和head层,并引入Rep VGG结构,实现烟支图像的高效自动标注。实验结果表明,改进后的YOLO v7和YOLO v7-tiny在真实烟支数据集上的标注错误率分别为7.3%和6.56%,其中YOLO v7-tiny展现最快的标注速度。这项研究不仅在提高标注效率和准确性方面取得显著进步,还为烟支缺陷检测领域提供一种经济高效的自动化处理方案。
关键词:YOLO v7;烟支外观缺陷检测;自动标注;RepConv;VGG
中图分类号:F768.29 文献标志码:A 文章编号:2095-2945(2024)15-0040-06
Abstract: Image tagging is a key part of supervised machine learning. When dealing with massive cigarette defect data, the traditional manual labeling method is not efficient because of its long time and strong subjectivity. Aiming at the challenge of automatic labeling of a large number of image data in the field of cigarette defect detection, this paper uses YOLO v7 as the baseline network and makes a series of empirical improvements to solve the problems of high cost and low efficiency in the traditional manual labeling process. Through the innovative adjustment of the structure of YOLO v7, such as merging neck layer and head layer, and introducing Rep VGG structure, the efficient automatic label of cigarette image is realized. The experimental results show that the labeling error rates of the improved YOLO v7 and YOLO v7-tiny on the real cigarette data set are 7.3% and 6.56% respectively, and YOLO v7-tiny shows the fastest labeling speed. This study has not only made remarkable progress in improving the efficiency and accuracy of labeling, but also provides an economical and efficient automatic processing scheme for cigarette defect detection.
Keywords: YOLO v7; cigarette appearance defect detection; automatic labeling; RepConv; VGG
在烟草行业中,烟支外观质量的控制对于保证产品一致性和消费者满意度至关重要。传统的烟支外观检测主要依赖于人工视觉检测,这一过程不仅耗时耗力,而且在面对高速生产线上海量烟支的检测任务时,其效率和准确性受到严重限制。人工标注作为一种传统方法,尽管具有一定的灵活性,但在面对海量数据的处理时,常常因为人为疲劳、判断标准不一致等因素导致标注质量不稳定,从而影响最终的产品质量检测。
针对上述问题,本研究提出了一种基于YOLO v7的海量烟支外观缺陷快速自动标注技术。YOLO v7作为最新的目标检测算法之一,以其高效的检测速度和优秀的识别准确性而受到关注。我们利用YOLO v7的先进性能,结合烟支外观特点,开发了一种自动化的缺陷检测和标注系统。该系统不仅可以显著提高标注速度,降低人力成本,还能通过连续的学习和调整,不断提高对缺陷识别的准确度。该方法不仅为烟草行业提供了一种新的质量控制方法,还为类似的高速生产线产品质量检测提供了参考。通过自动化和智能化的技术手段,我们能够更有效地保证产品质量,提高生产效率,同时也为深度学习在工业应用中的推广提供了一个成功案例。
YOLO(You Only Look Once)[1-2]是一种流行的目标检测算法,其能够在较短的时间内高效地检测图片中的物体。因此,将YOLO算法应用于烟支外观缺陷检测可以有效提高烟支外观缺陷检测的准确性和效率。除了YOLO,目标检测的其他算法还有R-CNN[3-4]、Faster R-CNN[5-6]和SSD[7]等都在深度学习领域取得大量的科研成果。Li等[8]通过改进YOLO模型将其全部卷积化,在钢带表面缺陷检测中达到97.5%的精度和95.86%的召回率。Zhu等[9]提出TPH-YOLO v5模型,在YOLO v5基础上用了变形预测头TPH并整合了卷积块注意力模型CBAM,与基准模型(YOLO v5)相比提高了约7%。Wang等[10]提出了一種可训练的自由包导向解决方案将灵活高效的训练工具与所提出的架构和复合缩放方法相结合,在所有已知的实时物体检测器中,YOLO v7在GPU V100上以30 fps或更高的速度检测物体,准确性最高,达到 56.8% AP。Yong[11]等基于YOLO v5s结合注意力机制提出了一种用于卷烟外观两阶段图像缺陷检测的改进模型,平均精度达到了91.6%。
目前,在目标检测领域还没有看到结合自动标注技术用于烟支外观缺陷检测方面的研究。烟支缺陷检测模型需要大量数据。在烟支生产线中需要将存在缺陷的烟支检测出来并进行剔除,在训练模型时需要大量的缺陷样本数据。数据标注过程成本较高,需要耗费大量的人力与时间成本,且存在部分主观性,对后续训练模型存在一定程度的影响。基于YOLO v7精度更高,速度更快,能够处理高分辨率图像的优点。
1 YOLO v7的工作流程介绍
图1为YOLO v7的工作流程,包括如下几方面的内容。
1.1 输入图像预处理
在YOLO v7的工作流程中,图像预处理是第一步且至关重要的环节。预处理的主要目标是将原始输入图像转换成适合后续网络处理的格式。这通常包括图像的归一化和缩放。归一化处理是指将图像数据的数值范围调整至一个标准化的区间,通常是0到1或-1到1之间,这样可以加快网络的收敛速度并提高训练过程的稳定性。归一化处理后,图像的每个像素值都会被转换为一个小数,反映原像素值与最大可能像素值之间的比例。图像缩放则是调整图像的尺寸以符合模型输入的要求。
1.2 特征提取阶段
一旦图像被预处理,它接着被送入卷积神经网络(CNN)进行特征提取。在这个阶段,CNN通过多个卷积层来学习和提取图像的特征。卷积层通过应用一系列的滤波器(也称为核),在图像上滑动并计算局部区域的点积,以此来提取图像的局部特征。随着网络层次的加深,所提取的特征从简单的边缘和纹理逐渐转变为更复杂的形状和对象部分。在每个卷积层之后,通常会有一个激活函数,如ReLU,用于增加网络的非线性处理能力。此外,某些层还会使用池化(pooling)操作,以减少特征图的空间尺寸,从而降低计算量并增加特征的抽象级别。这一过程不仅提高了网络对图像中重要特征的敏感度,还降低了对背景噪声的敏感性,从而使模型能够更好地学习图像中的重要信息。
图1 YOLO v7的工作流程
1.3 构建特征提取网络(Backbone Network)
继特征提取阶段之后,YOLO v7的工作流程进入构建特征提取网络(Backbone Network)的步骤。Backbone Network的核心作用是进一步提高模型对图像特征的表达能力。这一网络通常由多个卷积层、池化层和残差结构组成。残差结构是一种特殊的网络设计,它允许信息跨越多个层次直接传递,从而解决了在深层网络中常见的梯度消失和爆炸问题。通过这种方式,Backbone Network能够在不丢失关键信息的情况下,更深入地学习和提取图像的高级特征。此外,为了应对不同尺度的图像特征,Backbone Network还会采用多尺度特征提取策略,这意味着网络能够同时关注图像的粗粒度和细粒度特征。这种多层次、多尺度的特征提取策略极大地增强了模型的表现力,使其能够更准确地识别和定位图像中的各种目标。
1.4 特征融合网络构建(Neck Network)
特征融合网络(Neck Network)的构建是YOLO v7工作流程的下一个关键步骤。Neck Network的主要任务是将Backbone Network提取的不同层次的特征进行有效的融合。为了实现这一目的,Neck Network通常包括多个卷积层、上采样和降采样操作。上采样操作用于增加特征图的空间分辨率,使得深层的高级特征能够与浅层的低级特征结合,从而捕捉到更加丰富的空间信息。相反,降采样操作则用于减少特征图的空间分辨率,使得浅层的低级特征能够与深层的高级特征结合,以增强模型对于全局信息的感知能力。通过这种方式,Neck Network能够整合不同层次的特征,使模型在处理不同尺度的目标时更加灵活和高效。此外,这一阶段的操作还包括多种特征融合策略,如特征金字塔网络(FPN)或其他先进的特征融合技术,以进一步提升模型的性能和鲁棒性。
1.5 检测头的加入(Detection Head)
在特征融合网络(Neck Network)之后,YOLO v7的工作流程进入到加入检测头(Detection Head)的阶段。每个检测头负责处理不同尺度的目标检测任务,并预测目标的类别和位置信息。在实际应用中,这意味着模型能够同时处理小尺寸目标、中等尺寸目标以及大尺寸目标的检测。每个检测头通常包含多个卷积层,这些卷积层专门针对特定尺度的特征图进行处理。在此基础上,每个检测头还会对目标的边界框、置信度以及类别进行预测。这些预测是通过在特征图上应用一系列的锚框(anchor boxes)来完成的。锚框是预定义的不同形状和大小的框,它们帮助模型锚定并预测图像中的对象。每个锚框与一个特定类别的概率以及四个边界框偏移量相关联。通过这种方式,检测头能够为每个锚框生成一个预测,包括目标的类别、位置和置信度。这一阶段的关键在于确保模型能够有效地识别和定位图像中的多种目标,同时保持高准确度和低误检率。
1.6 输出解码(Decode)
解码阶段的目的是将检测头输出的信息转化为实际的目标位置和类别信息。这通常涉及对目标边界框的位置、大小进行调整,以及将类别概率转换为具体的类别标签。解码过程对于将模型的预测转化为实际可用的结果至关重要。
1.7 目标信息筛选与过滤
在这一步骤中,系统将解码后的目标信息进行筛选和过滤。这包括去除低置信度的预测、应用非极大值抑制(NMS)等方法來减少重叠检测框。这个过程的目的是确保最终输出的检测结果既准确又可靠。
1.8 最终检测结果输出
最后阶段,系统输出最终的目标检测结果。这些结果包括了每个检测到的对象的类别、位置(通常是边界框坐标)和置信度。这些信息对于后续的应用,如烟支外观缺陷检测和剔除,至关重要。
2 烟支外观自动标注流程
为烟支外观缺陷自动标注流程图,烟支外观缺陷数据准备、烟支外观缺陷检测模型训练、烟支外观缺陷自动标注3个部分组成。
2.1 烟支外观缺陷数据准备
在此阶段,双机位相机系统捕获的烟支图像数据,经过存储和预处理后,需进行初步的缺陷标注。这里可以引入YOLO v7的初始模型进行半自动标注,利用其高效的检测能力快速识别显著的缺陷特征。这样不仅加速了标注过程,而且提高了数据集的初始质量。这些数据集将为接下来的模型训练提供基础。
2.2 烟支外观缺陷检测模型训练
在模型训练阶段,加载经过预处理和初步标注的烟支外观缺陷数据集,并使用YOLO v7进行训练。YOLO v7的优势在于其快速且准确的特征提取能力,能够有效地处理烟支的各种缺陷特征。在训练过程中,通过不断调整候选框尺寸和优化网络参数,YOLO v7模型能够更精确地学习到烟支缺陷的特征。训练过程中损失函数的收敛表明模型已经有效学习到了烟支外观缺陷的识别特征。
2.3 烟支外观缺陷自动标注
最后阶段,在自动标注阶段,加载训练好的YOLO v7模型来处理新的烟支外观缺陷数据。YOLO v7的高效检测能力能够快速准确地识别并标注出烟支的缺陷区域。通过自动标注,大大减少了人工参与的需求,提高了标注的效率和一致性。标注完成后的结果可以用于后续的分析和质量控制。
3 实验结果与分析
3.1 标注图片速度对比
图2展示了不同版本的YOLO v7模型在推理时间(inference)、非極大值抑制时间(nms)和总时间(total)方面的性能比较。时间单位是毫秒(ms),越低表示效率越高。这些模型可能是针对特定任务的不同优化版本或大小变体,例如针对速度、准确性或资源占用的优化。以下是对图表的详细分析。
①YOLO v7:原始的YOLO v7模型在推理时间上为4 ms,非极大值抑制时间为1.4 ms,总时间合计为5.4 ms。这可以视为我们比较的基线。②YOLO v7x:这个版本的推理时间稍长(6.4 ms),非极大值抑制时间(1.3 ms)与原始YOLO v7相比略微减少,总时间为7.7 ms,表明这个版本可能在推理准确性上有所增强,但牺牲了一定的速度。③YOLO v7-w6:在此版本中,推理时间为4 ms,非极大值抑制时间为1.7 ms,总时间为5.7 ms。这显示了相对于原始YOLO v7,它在总时间上有所改进。④YOLO v7-d6:推理时间为7.9 ms,非极大值抑制时间为1.6 ms,总时间为9.4 ms。这可能是一个针对更复杂任务设计的版本,具有较长的推理时间。⑤YOLO v7-e6:推理时间为6 ms,非极大值抑制时间为1.5 ms,总时间为7.5 ms。这个版本在推理时间和非极大值抑制时间上都表现出适中的性能。⑥YOLO v7-e6e:这个版本具有最长的推理时间9.2 ms,非极大值抑制时间为1.3 ms,总时间为10.5 ms。它可能是最为复杂的版本,可能在准确性上有所提升,但在速度上损失较大。⑦YOLO v7-tiny:如其名,这可能是一个轻量级版本,具有最短的推理时间(1 ms),非极大值抑制时间(1.1 ms),总时间仅为2.1 ms。这表明它非常快速,但可能在准确性或检测能力上有所妥协。
图2 不同模型性能比较
总体来说,不同的模型版本之间在速度和可能的准确性上存在权衡。选择哪个模型版本将取决于特定应用的要求,例如在对实时性要求高的场景中,可能会选择YOLO v7-tiny,而在需要更高准确性的场景中,可能会选择YOLO v7-e6e或YOLO v7-d6。在实际应用中,还需要考虑模型的复杂性、资源消耗以及目标检测任务的具体需求。
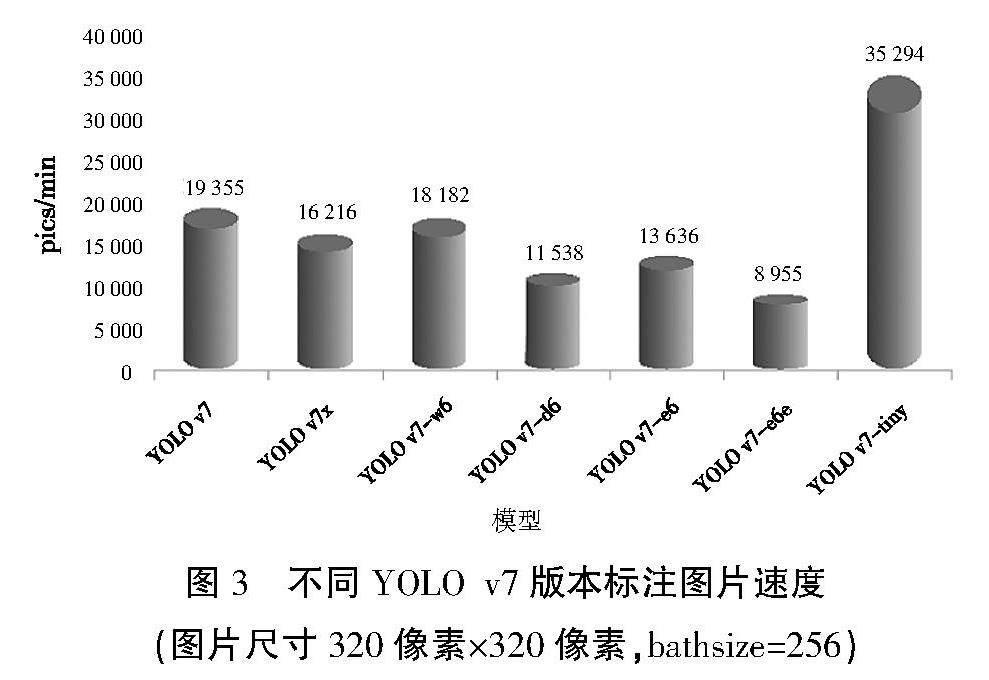
图3展示了不同版本的YOLOv7模型在处理320像素×320像素分辨率图片、批量大小为256时的标注速度性能。性能指标是每秒可以处理的图片数(单位为 pics/min,即张/分钟),速度越快表示模型效率越高。以下是对图表的概要性分析。
①YOLO v7:基线模型,处理速度约为19 000 pics/min。②YOLO v7x:略低于基线,处理速度约为16 000 pics/min,可能由于模型更复杂或进行了更深层次的分析,影响了处理速度。③YOLO v7-w6:处理速度为18 000 pics/min,接近基线模型,表明优化可能侧重于其他方面,如准确性或特征提取。④YOLO v7-d6:处理速度降到11 000 pics/min,此下降可能表明该版本进行了更为复杂的操作,需要更多的计算资源。⑤YOLO v7-e6:处理速度为13 000 pics/min,比YOLO v7-d6有所提高,处理速度略高于YOLO v7-e6e,但仍低于基线。⑥YOLO v7-e6e:约为9 000 pics/min,表明这两个模型可能在性能上有细微的区别。⑦YOLO v7-tiny:显著高于其他所有模型,以约35 000 pics/min的速度处理图片,这反映了其轻量级设计,旨在提供极高的处理速度,虽然可能牺牲了一些准确度或功能性。
图3 不同YOLO v7版本标注图片速度
(图片尺寸320像素×320像素,bathsize=256)
总结来看,不同的模型版本在处理速度上有显著差异,从YOLO v7-tiny的极高速度到YOLO v7-d6的较低速度,这些差异可能反映了模型复杂性、准确性和计算效率之间的平衡。在实际应用中,选择哪个版本将取决于特定任务的需求,如对速度的敏感度、可接受的准确度损失,以及可用的计算资源。
3.2 YOLO v7自动标注结果展示
在圖4中,使用了YOLO v7模型来自动标注274张图片,这些图片涉及烟支生产过程中的8种不同缺陷类别,具体包括刺破、夹沫、爆口、接装纸异常、遮挡异常、褶皱以及正常的卷烟纸部分和接装纸部分。这些类别代表了烟支生产和包装过程中可能出现的典型问题,其中一些是明显的缺陷,而其他的则是正常的生产过程特征。自动化标注系统的任务是将每张图片中的特征准确分类和标记。
在自动标注完成后,通过进一步的验证发现,有20张图片发生了标注错误,包括误标和漏标的情况。误标是指错误地为图片中的对象分配了错误的类别标签,而漏标则是指未能识别并标记出应当被标注的对象。标注错误率计算为错误标注的图片数量除以总标注图片数量,再乘以100%,在这种情况下,标注错误率为7.3%。这一数值提供了关于YOLO v7在当前配置下针对特定任务的性能的直观理解。
3.3 YOLO v7-tiny 自动标注结果展示
在图5中,使用YOLO v7-tiny轻量级版本对数据集进行自动标注,其中这些图片的类别与YOLO v7模型中的类别一致。在这274张图片中,有18张存在标注错误,包括误标和漏标,计算得出的标注错误率为6.56%。在考虑图像尺寸对标注效果的影响时,发现使用512像素×512像素的图像尺寸比320像素×320像素的尺寸更为有效。此外,综合考虑模型大小、平均精度均值(mAP)、推理时间以及处理图像的数量,我们认为选择YOLO v7及YOLO v7-tiny作为自动图像标注工具是较为合适的选择。
在对比分析YOLO v7与YOLO v7-tiny 2个模型时,发现主要差异体现在准确性、模型大小和处理速度3个方面,见表1。YOLO v7在平均精度均值(mAP)上略高于YOLO v7-tiny(0.839∶0.824),表明其在识别准确性上有细微的优势。然而,这种优势是以较大的模型大小(74.8 MB)和较慢的处理速度(11 111张/min)为代价的。相比之下,YOLO v7-tiny虽然在准确性上略逊一筹,但它的模型大小显著更小(12.3 MB),且处理速度远快于YOLO v7(28 571张/min)。这使得YOLO v7-tiny更适用于资源受限或需要快速处理大量数据的场景,而YOLO v7则更适合对准确度要求较高的应用。因此,根据具体应用的需求和限制,选择两者之一是关键。
表1 YOLO v7与YOLO v7-tiny的各指标
4 结束语
本文研究基于YOLO v7的烟支外观缺陷的快速自动标注技术。YOLO v7以其出色的检测精度、高效的处理速度,以及对高分辨率图像的强大处理能力,成为本研究的核心技术。通过运用YOLO v7的这些优势,有效地生成大量高质量的训练数据,为构建更精确的烟支缺陷检测模型提供了坚实的基础。相较于传统手工标注方法,本技术具有以下几个显著优点。
1)提高标注效率:相比人工逐一标注,YOLO技术显著提升了标注速度,降低了人工成本。
2)提高标注准确率:利用深度学习算法的强大图像识别能力,YOLO技术能更准确地识别和标注目标,减少了标注误差。
3)可扩展性强:作为基于深度学习的模型,YOLO技术具有良好的可扩展性。通过增加训练数据和调整模型参数,可以进一步提高标注的准确率,并适应多样的标注场景和需求。
4)适用范围广:YOLO技术可应用于各类图像标注场景,如物体检测、人脸识别、车辆识别等,具备广泛的适用性。
综上所述,本研究提出的基于YOLO v7的烟支外观缺陷自动标注技术,在该领域中展现出显著的潜力和广泛的应用潜力。未来,计划进一步探索新版本的YOLO模型在烟支图像标注中的潜在应用和优化方向,以持续提升标注准确性和效率。
参考文献:
[1] REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]//Computer Vision & Pattern Recognition.IEEE,2016.
[2] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the IEEE conference on computer vision and pattern recognition,2017.
[3] GIRSHICK R, DONAHUE J, DARRELL T,et al.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]//IEEE Computer Society,2014.
[4] HE K, GKIOXARI G,PIOTR DOLL?魣R, et al. Mask R-CNN[C]//IEEE Transactions on Pattern Analysis & Machine Intelligence,2017.
[5] GIRSHICK R. Fast r-cnn[C]// Proceedings of the IEEE international conference on computer vision,2015.
[6] REN S, HE K, GIRSHICK R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015. 28.
[7] LIU W, ANGUELOV D, ERHAN D, et al. Ssd: Single shot multibox detector[C]//Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part I 14,2016.
[8] LI J, SU Z, GENG J, et al.Real-time detection of steel strip surface defects based on improved yolo detection network[J]. IFAC-PapersOnLine,2018,51(21):76-81.
[9] ZHU X, LYU S, WANG X, et al. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios[C]// Proceedings of the IEEE/CVF international conference on computer vision,2021.
[10] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//arXiv.arXiv,2022.
[11] YONG P, JIANG D, LYV X Z, et al. Efficient and High-performance Cigarette Appearance Detection Based on YOLOv5[C]// In 2023 International Conference on Intelligent Perception and Computer Vision (CIPCV),2023:7-12.
