基于SSA-LSTM 的风速异常波动检测方法
2024-05-23邓立军袁金波尚文天
邓立军 ,袁金波 ,刘 剑 ,尚文天
(1.辽宁工程技术大学 安全科学与工程学院, 辽宁 葫芦岛 125105;2.辽宁工程技术大学 矿山热动力灾害与防治教育部重点实验室, 辽宁 葫芦岛 125105)
0 引 言
风门开闭会引起通风系统及关联巷道风流发生波动。当风门处于静止状态(保持关闭或保持敞开),即无扰动条件下,风速传感器监测数据在湍流脉动作用下呈现无周期、非线性的小幅度波动[1]。而在风门开闭过程中,关联巷道风速传感器监测数据会出现短时异常波动。由于湍流脉动的作用,风速传感器监测数据存在大量噪声,传统统计方法无法精确检测风速传感器监测数据中的异常波动,存在漏报率和误报率高的问题,给预警与控制带来较大困难,因此需尽早检测风速异常波动。风速传感器监测数据可视为一类非线性、非平稳时间序列数据。为尽可能地提取时间序列数据中的有效信息,排除噪声干扰,有学者将时间序列数据分解成具有不同时间尺度的若干分量,并对单一分量进行分析和重组,从而实现噪声分离[2]。目前常用的时间序列数据降噪方法——傅里叶变换(Fourier Transform,FT)、小波分析(Wavelet Analysis,WA)、经验模态分解(Empirical Mode Decomposition,EMD) 和SSA(Singular Spectrum Analysis,SSA)等均对时间序列数据有着较好的降噪作用。然而,傅里叶变换只适用于平稳的数据分析,在处理非平稳数据时有着一定的局限性[3];小波分析降噪过程中,虽能对非平稳数据进行分解,但其小波基、分解层和小波阈值等相关参数受人为影响因素较多,容易出现偏差[4];EMD 可根据原始数据本身特征将数据分解为多个本征模态分量,实现了数据的自适应分解,被广泛应用于数据降噪领域,但由于EMD 在分解过程中极易出现模态混叠以及端点效应,在一定程度上影响了EMD 的降噪效果[5];SSA 可有效规避以上问题,因其具备不需要复杂先验信息的数据处理优势,成为了解析优化非线性时序数据十分有效的技术手段[6-7]。
为深度挖掘时间序列数据内在关联关系及数据特征,在时间序列异常检测领域大量学者针对深度学习方法进行研究及应用[8]。邓华伟等[9]利用随机森林提取网络流量数据特征,构建LSTM(Long Short Term Memory,LSTM)神经网络模型,实现网络流量异常检测。龚向阳等[10]提出一种基于深度残差LSTM的视频异常行为识别算法,将登杆作业的多个视频序列作为输入数据,通过深度残差网络获得多个视频序列的特征,进一步将融合后的特征作为LSTM网络输入,实现登杆作业异常行为的识别。蔡兴旭等[11]提出基于LSTM 的桥梁传感器异常检测方法,通过小波变换与奇异谱分析对传感器数据进行预处理,基于贝叶斯优化算法以及LSTM 构建时间序列异常检测模型,最终通过学习异常报警阈值实现潜在异常检测。田亮等[12]提出了基于数据驱动的故障诊断方法,通过LSTM 神经网络的预测能力和证据理论的多源信息融合能力来对引风机轴承的状态进行诊断。除LSTM 以外,ARIMA、BP、CNN 等方法也可用于时间序列数据异常检测。但ARIMA 很难用来挖掘时间序列数据之间的非线性关系,预测精度较差[13]。BP 网络对波动性较强的时间序列数据预测效果较低且泛化能力较弱[14-15]。CNN 的池化层会丢失大量有价值的信息,降低局部与整体的相关性[16]。
综上所述,SSA 方法能够较好的分离非线性时间序列数据中的噪声,LSTM 方法对时间序列数据有着较好的预测效果且泛化能力强,笔者提出一种基于SSA-LSTM 的风速异常波动检测方法。首先采用SSA 对原始风速数据序列进行重组,分离湍流脉动噪声,然后利用LSTM 对SSA 重组后的风速序列数据进行重构,最后利用对数概率密度函数计算原始数据与LSTM 重构数据的异常分数,并拟定异常报警阈值,从而实现风速传感器监测数据中的异常波动检测[17]。
1 SSA 与LSTM 算法原理
1.1 奇异谱分析法(SSA)
风速传感器监测数据中由于湍流脉动作用存在大量噪声,为去除这部分噪声,提高异常检测性能,引入SSA 方法。SSA 是一种处理非线性时间序列数据的方法,通过对所要研究的时间序列进行嵌入、分解、分组、重组4 个步骤处理,提取主要趋势成分,以达到降噪的目的。主要步骤如下:
1)嵌入:将一维时间序列 [x1,x2,···,xn]以长度为l的时间窗口进行映射,形成k个长度为l的向量,其中k=n-l+1,组成的轨迹矩阵[18]如下:
2)分解:对得到的轨迹矩阵进行奇异值分解(SVD):
式中:d为非零奇异值的数量,d=rank(X)≤min(l,m);Ui、Vi为X的左右奇异向量。
3)分组:为去除数据中多余的噪点,若数据X的组成是由有用信号S和噪声E组成,即X=S+E,分组是为了尽可能将E部分去除。前r个较大的奇异值组成的数据即可被认为是有用数据,则d-r部分则为噪声部分,因此,选择合适的r值即可实现数据和噪声分离的效果。
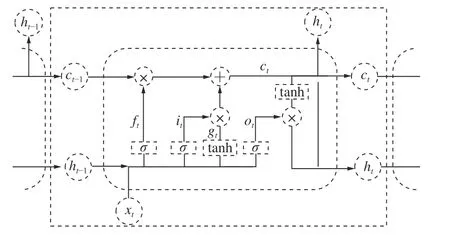
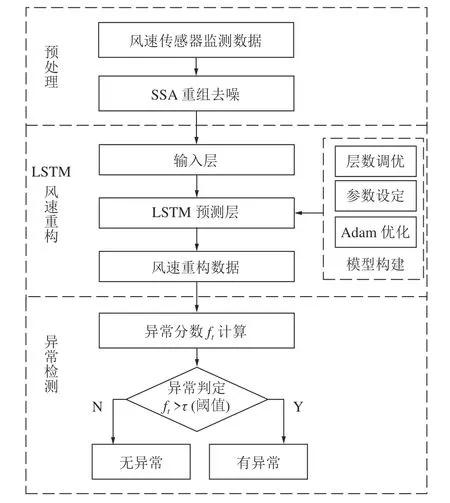
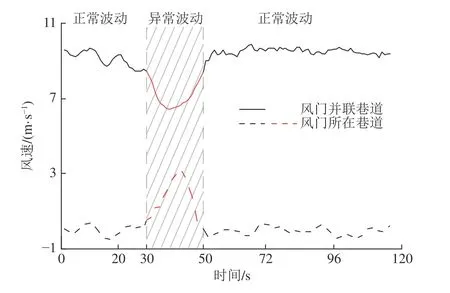
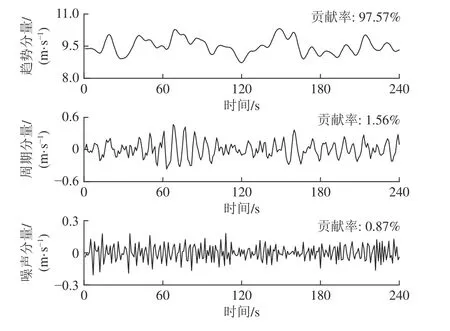
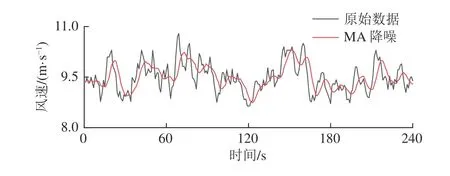
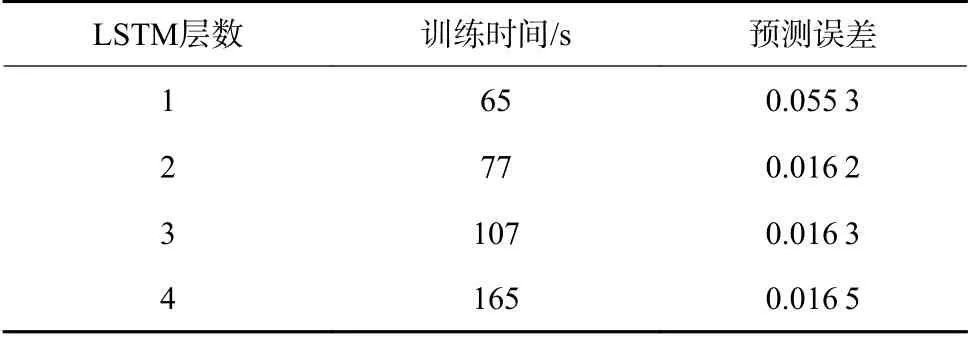
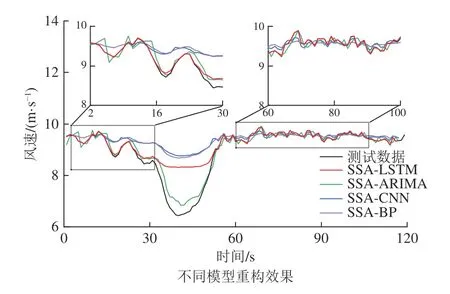
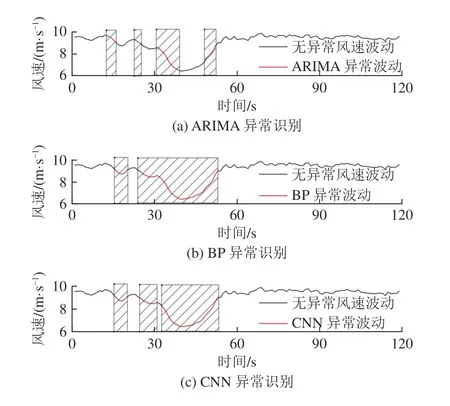
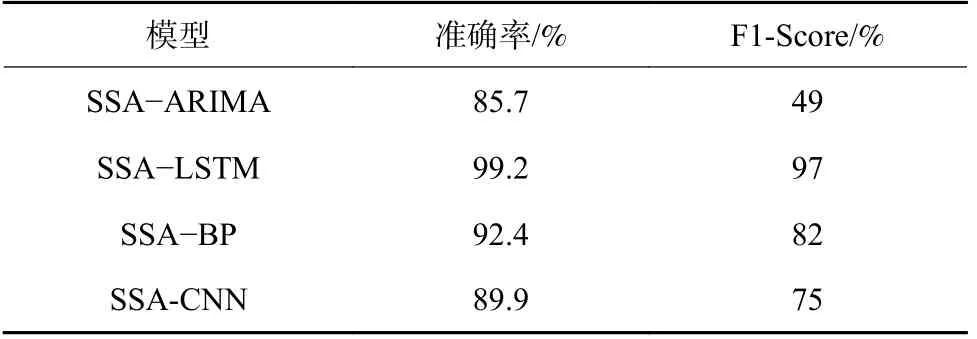
4)重组:重组是利用对角平均化将上述分组得到的矩阵转化成所需的长度为n的重构序列RC。令代表分组后得到的任一矩阵,为矩阵中的各元素。设,,当l LSTM 神经网络是RNN 神经网络的改进版,除继承了RNN 的结构类型外,新建遗忘门对输入的数据信息进行选择性遗忘,有效地避免了隐藏层权重在迭代多次后出现梯度消失或梯度爆炸的情况的发生[19]。 LSTM 神经网络继承了RNN 的结构类型外,增加了门的思维来对参数进行筛选,其中遗忘门决定了将多少上一时刻的细胞状态ct-1保留下来;输入门决定了将当前输入xt是否保留至当前细胞状态ct中,避免不重要的记忆信息进入细胞;输出门决定传入下一时刻的输出信息,如图1 所示。 图1 LSTM 单元结构Fig.1 LSTM unit structure 图1 中,将sigmoid 和tanh 函数作为激活函数,遗忘门、输入门、输出门将传入的信息受权重矩阵和偏置向量的影响,将得到新的输出矩阵和新的细胞状态,主要公式如下: 式中:ft为遗忘门;it为输入门;gt为细胞状态的输入;ot为输出门;ct-1和ct为上一时刻和当前时刻的细胞状态;ht-1和ht为上一时刻和当前时刻的输出;Wf,Wi,Wc,Wo和bi,bf,bc,bo分别为LSTM 三个门不同状态下的权重矩阵和偏置向量。 SSA-LSTM 风速异常波动检测方法可分为预处理、LSTM 风速重构和风速异常波动检测3 部分,主要流程如图2 所示。 图2 风速异常波动检测Fig.2 Wind speed abnormal fluctuation detection 采用SSA 可将风速传感器监测数据分解为趋势分量、周期分量和噪声分量,再重构趋势分量和周期分量,以达到去除数据中存在的噪声的目的。 构建LSTM 风速重构模型,该模型分为3 个部分:输入层、隐藏层和输出层。首先输入层主要对原始风速监测数据进行预处理和数据集划分;然后基于隐藏层对训练集进行训练,通过Adam 优化算法对LSTM 神经网络权值进行更新,不断调整网络层数得到最优网络结构,并添加Dropout 层防止过拟合;最后,输出层根据隐藏层中训练的模型进行预测,得到重构风速。 重构风速误差是t-1 之前的历史数据对t时刻风速预测值与t时刻实际风速的差值,计算该误差的对数概率密度作为异常分数,并设定阈值 τ用于判定异常风速:异常分数在阈值以下,则该点出现异常,否则正常。为减少异常检测误判,阈值 τ取训练集异常分数最小值。异常分数计算公式如公式(5)所示,异常分数越小,t时刻风速属于异常波动区间概率越大[20]。 为验证方法的有效性,试验数据来源课题组前期的风门开闭风流扰动试验[21]。试验装置满足几何相似与动力相似,整体相似比为1∶16。设定入口风速为8 m/s,在风门串联巷道、风门所在巷道迎风侧、风门所在巷道通风侧、风门并联巷道布置4 个风速测点。试验参数包括开闭角度、风门开闭速度、风门敞开时间3 个变量,构成96 种工况,共得到4 000 组无扰动(风门保持关闭或敞开)风速监测数据以及120 组有扰动(风门开闭动态过程)风速监测数据。 风门开闭时间分别为t1=30 s,t2=50 s,风门开闭过程中,风门所在巷道及前后巷道风流会产生“向上”的异常波动;并联巷道风流会产生“向下”的异常波动,如图3 所示。 图3 风门所在巷道和并联巷道风速波动Fig.3 Air velocity fluctuations of air tunnel and parallel tunnel 由于不同巷道的风速不同,在预处理之前需将不同的风速时间序列数据进行滑移处理。取某一段序列数据的无扰动区域风速均值作为基准线,计算其它段序列的无扰动区域风速均值与基准线的差值,将序列段垂直滑移到基准线。 基于前文所述SSA 方法对数据样本进行降噪处理,分解出的趋势分量、周期分量、噪声分量及贡献率如图4 所示。 图4 数据分量及贡献率Fig.4 Data component and contribution rate 由图4 可知,湍流脉动产生的噪声其贡献率占比很小,不足1%,周期分量和趋势分量可以反映整体的风速波动情况,因此可以将噪声分量去除。 利用SSA 方法将趋势分量和周期分量进行重构,重构前后结果如图5 所示,SSA 方法可以很好地剔除原始风速数据中的湍流脉动噪声,以更光滑的曲线保留整体的风速波动情况。 图5 SSA 降噪与原始数据拟合Fig.5 SSA noise reduction and real data fitting figure 为评估SSA 方法的降噪性能,本文选取传统的滑动平均法(Moving Average,MA)和小波分析法(Wavelet Analysis,WA)与SSA 方法进行对比,对比结果如图6、图7 所示。 图6 WA 降噪与原始数据拟合Fig.6 WA noise reduction and real data fitting figure 图7 MA 降噪与原始数据拟合效果Fig.7 MA noise reduction and real data fitting figure 由图6 可知,小波降噪法虽然对原始风速数据起到了一定的降噪效果,但是却丢失了过多的趋势细节信息;滑动平均降噪因其窗口大小不同,会致使数据结果向后进行滑移,误差较大,如图7 所示。最后,选用信噪比(Signal Noise Ratio,SNR)和皮尔逊相关系数(Pearson Correlation Coefficient,PCC)对SSA、MA、WA 后的数据进行评估。在两个评价指标中,SNR 越大,代表降噪效果越好;PCC 值越接近1,代表曲线与原曲线拟合效果越好。公式如下: 式中:xt为t时刻实际风速值;yt为t时刻降噪后的风速值。 式中:µx为实际风速值的均值;σx为实际风速值的标准差;µy为降噪后的风速均值;σy为降噪后的风速标准差,计算结果见表1。 表1 降噪方法评价对比Table 1 Evaluation comparison of noise reduction methods 从结果上看,利用SSA 对数据降噪后的信噪比为75.12,线性相关系数为0.987 1,降噪能力都优于MA 和WA。 采用深度学习库Keras 构建LSTM 风速重构模型,后端采用基于C++开发的TensorFlow-GPU 开源框架。将数据按照一定比例进行划分,其中4 000 组无扰动风速数据作为训练集样本,120 组有扰动风速数据作为测试集样本。LSTM 模型构建时对比不同层数下的预测效果,选取合适的隐藏层层数,确定模型相关参数,其中神经元个数为64,步长为10,学习率为0.01,Dropout 的比例为0.5。 理论上LSTM 隐藏层层数越多,预测数据曲线拟合能力越强。但层数增多,神经网络结构越来越复杂,训练时间越来越长,容易出现过拟合现象,泛化能力变差。分别比较了隐层数为1、2、3、4 时LSTM 的预测效果,结果如图8、表2 所示。 表2 训练时间以及预测误差Table 2 Training time and prediction error 图8 不同LSTM 隐层预测效果Fig.8 Different LSTM prediction effects 图8 中,单层LSTM 预测结果与实际值偏差较大;二、三、四层LSTM 在无扰动区域预测结果与实际值均较吻合,但在有扰动区域,三、四层LSTM 出现过拟合现象,有扰动区域风速预测结果与实际值过于接近,而二层LSTM 具有良好的区分效果。随着层数的增加,LSTM 模型训练时间也会增加,但误差并没有显著下降。综合考虑,二层LSTM 模型预测效果是最优的。 计算训练集实际风速与LSTM 重构风速的误差,依据式(5)计算训练集中每个风速对应的异常分数,计算结果如图9 所示。取异常分数最小值作为阈值τ。 图9 重构误差与异常分数曲线Fig.9 Reconstruction error and anomaly score curves 3.4.1风门所在巷道风速波动异常检测 当风门处于静止状态(保持关闭或保持敞开),风速传感器监测数据在8.5~9.5 m/s 范围内波动,风门开闭过程中,风门所在巷道及前后巷道风速会增大,产生“向上”的风速异常波动。如图10 所示,在30~50 s 时,风门开闭,风速超出正常波动范围,最大风速达到了12.8 m/s,属于异常波动范围。选取风门所在巷道风速监测数据中的测试集序列,将预处理后的序列数据进行LSTM 风速重构,LSTM 在30~50 s 是能根据历史风速波动数据信息重构正确的风速波动趋势。计算重构误差的异常分数,以上文设定的阈值τ进行异常检测。使用斜线填充将小于阈值的风速数据时间区间进行标记,小于阈值的时间风速区间范围为31~50 s,与实际风门开闭时间区间接近,证明了所提方法的可行性。 3.4.2风门并联巷道风速波动异常检测 风门开闭过程中,风门并联巷道会减小,产生“向下”的风速异常波动。如图11 所示,风速正常波动8.5~9.5 m/s 内上下波动时属于正常风速数据,但在30~50 s 时,风门开闭时,风速偏离正常波动范围,最小风速达到了6.5 m/s,属于异常波动范围。 图11 并联巷道异常划分Fig.11 Parallel tunnel anomaly division 为验证方法的风速重构效果及异常检测的准确率,以SSA-ARIMA、SSA-CNN 和SSA-BP 模型进行比较,各模型均采用与SSA-LSTM 模型相同的数据集,如图12、图13 所示。 图12 不同模型重构效果Fig.12 Different model reconstruction effects 图13 其他各模型异常检测Fig.13 Anomaly detection figure for other models 1)重构效果对比分析。不同模型的风速重构效果如图12 所示,在10~30 s 的正常风速波动段中,巷道风流受湍流脉动的影响出现了小幅的风速波动,SSA-BP 与SSA-CNN 模型重构数据波动趋势较为平稳,无法对因湍流脉动导致的小幅风速波动数据进行正确拟合;SSA-LSTM 和SSA-ARIMA 模型重构曲线与实际风速曲线接近,表明二者对正常风速段中的小幅湍流脉动可正确重构。在30~50 s 的异常风速波动段中,风门开闭,风速波动趋势发生大幅波动,SSA-ARIMA 模型重构数据与实际异常波动数据接近,出现过拟合现象;SSA-BP、SSA-CNN 和SSALSTM 模型重构数据波动趋势较为平稳,对异常风速波动进行逆重构效果较好。在60~100 s 的正常风速波动段中,巷道风流受湍流脉动影响较小且无风门开闭等影响风流改变的现象出现,风速波动较为平稳,各模型重构曲线与实际风速曲线拟合良好。SSA-LSTM 模型能正确重构因湍流脉动导致的小幅波动风速数据,也能对异常风速数据进行逆重构,在4 个模型中重构能力最好。 2)异常检测效果对比分析。以准确率和F1-Score 为评价指标对不同模型进行评价分析。准确率表示模型重构正确的数据样本占整体风速数据样本的比重;F1-Score 是精确率和召回率的调和平均,可以较为全面地评价模型的异常检测效果,F1-Score越大说明模型检测效果越好,结果见表3。 表3 不同模型异常检测评价指标Table 3 Evaluation metrics for anomaly detection in different models SSA-ARIMA 模型异常检测精度较差,误将13、14、23 s 时刻的风速检测为异常风速,仅正确识别出了38%的风速异常波动数据;SSA-BP 与SSA-CNN模型异常检测精度接近,但均误将因湍流脉动导致的小幅波动识别为异常风速波动;SSA-LSTM 模型不仅正确识别出异常波动区间,且当风速出现小幅波动时具有较好的鲁棒性,相较于其他模型,本文所提模型表现最优,异常检测的准确率和F1-Score 分别达到了99.2%和97%。 1)SSA 方法可以将风速传感器监测数据序列中的趋势分量、周期分量和噪声分量有效分离,提高信噪比,能够有效去除因湍流脉动产生的数据噪声,去噪效果明显,有助于提高风速重构效果和异常检测准确率。 2)当监测数据无异常波动时,SSA-LSTM 模型能够捕捉风速监测传感器数据中的隐藏特征,能根据历史风速波动数据信息重构正确的无异常风速波动趋势;当监测数据出现异常波动时,利用对数概率密度函数计算实际风速与SSA-LSTM 模型重构风速的异常得分,取异常分数最小值作为阈值,根据阈值检测监测数据是否属于异常风速。 3)SSA-LSTM 模型相对于SSA-BP、SSA-CNN、SSA-ARIMA 模型明显具有更优的重构效果和异常检测准确率,能正确重构因湍流脉动导致的小幅波动风速数据,进而提高了异常检测的准确率。经验证该模型的检测准确率和F1-Score 指标也优于其它模型。 4)由于矿井生产活动复杂,导致风流出现异常波动的因素可能还包括罐笼提升、矿车运行等,出现异常波动的规律、趋势也有一定的差别,因此在矿井风流异常检测研究中,多因素、多特征的风速异常检测可为下一步的研究目标。1.2 长短期记忆网络(LSTM)
2 SSA-LSTM 风速异常波动检测方法
2.1 预处理
2.2 LSTM 风速重构
2.3 风速异常波动检测
3 试验验证
3.1 预处理



3.2 LSTM 风速重构模型
3.3 LSTM 隐藏层调优

3.4 风速波动异常检测


3.5 模型对比分析
4 结 论
