Apache Flink流式计算模型在数据处理中的应用与性能优化研究
2024-05-19徐海霞
徐海霞

摘要:文章旨在研究Apache Flink流式计算模型在数据处理中的应用与性能优化。先从可扩展性、容错性和数据并行处理能力三个方面对Apache Flink流式计算框架技术特点进行论述,再对Apache Flink流式计算框架核心思想与工作流程进行研究,并提出一套执行数据处理任务的Java源码,再从并行计算、数据存储和传输、算法参数、系统配置、资源管理与调度、检查点和容错机制、编码和序列化等方面就如何进行Apache Flink性能优化进行分析,最后通过实验手段就优化性能进行分析。实验结果表明,优化后的平均响应时间显著减少,吞吐量相应增加,调整并行度和内存分配等参数可显著提升系统性能,但还需要考虑任务调度和资源分配等方面的综合因素,因此,Apache Flink流式计算框架调优策略具有一定的应用价值。
关键词:流式计算;Apache Flink;大规模数据处理;性能优化;并行计算
中图分类号:TP311 文獻标识码:A
文章编号:1009-3044(2024)07-0071-03
开放科学(资源服务)标识码(OSID)
随着互联网、物联网、社交媒体等信息源的不断增加,组织和分析海量数据已经变得日益复杂,大规模数据处理已经为信息领域带来新的挑战。大数据涵盖了各种类型,包括结构化数据(如数据库中的表格数据)、半结构化数据(如XML、JSON格式的文档)以及非结构化数据(如文本、图像和视频),处理这些数据需要高效的算法和系统来提取有价值的信息和支持决策,传统的单机处理和集中式计算模型已经显得力不从心,数据量的急剧增加导致了存储、计算和通信等方面存在瓶颈,数据处理时间大幅度延长,因此,寻找更加高效、可扩展的数据处理方法成为当务之急。Apache Flink作为流式计算框架,适用于大规模数据的处理和分析,在实时处理、高吞吐量、容错性、灵活的窗口操作以及丰富的API支持等方面具有众多优势,使得Flink成为处理复杂数据的理想选择。
1 Apache Flink流式计算框架技术特点
1.1 可扩展性
Apache Flink采用基于流的计算模型,具备出色的可扩展性,允许用户在处理无边界数据流时轻松地扩展计算能力。Flink可以通过简单地增加计算节点的数量来水平扩展,每个节点都可以独立地处理数据流,而无需对整个系统进行大规模改动,动态的资源管理机制,可以根据工作负载的变化自动调整计算资源的分配,确保系统在不同规模的数据处理任务中都能高效运行。
1.2 容错性
容错性是大规模数据处理框架中不可或缺的技术特点,尤其是在长时间运行的流处理任务中。Flink通过定期生成任务的检查点(checkpoint) 来记录任务的状态,在发生故障时系统可以使用最近的检查点来恢复任务的状态,从而避免数据丢失和任务重新计算。提供Exactly-Once语义,确保每个事件都被处理一次且仅一次,即使在发生故障时,系统也能够保持数据处理的准确性和一致性。
1.3 数据并行处理能力
用户可以根据实际需求配置Flink的容错性级别,平衡容错开销和系统性能。Flink通过数据并行处理的方式实现高效的大规模数据处理,将流处理任务划分为多个子任务,每个子任务在一个独立的并行线程上执行,这种任务并行度的设计允许系统在多个计算节点上同时处理数据,提高整体计算能力。支持事件时间处理,允许在有序和无序事件流中处理数据,有助于保持数据处理的准确性,并支持窗口操作,例如时间窗口和会话窗口。采用流水线执行模型,使数据在各个算子之间流动,减少了数据在节点之间的传输和复制开销,提高了数据处理的效率[1]。
通过这些技术特点,Apache Flink在大规模数据处理场景中表现出色,为用户提供了高效、可扩展且容错性强的流式计算解决方案。
2 Apache Flink流式计算框架核心思想与工作流程
Apache Flink流式计算框架作为新型分布算法,将大规模数据处理任务划分为一系列小的、连续的数据流操作,每个操作形成一个计算阶段,可以在集群的不同节点上并行执行。数据以流的形式在不同计算阶段之间传递,避免了显式的数据共享和同步,提高了整个系统的效率,同时,Flink使用异步、非阻塞的消息传递模型,通过轻量级的异步通信实现节点之间的协调。数据以流的形式加载并实时地从各种数据源获取,预处理包括数据清洗、转换等操作,可以更好地确保数据质量和格式的一致性,任务调度器根据数据流图和集群状态动态地调度任务,并通过任务管理器将任务分配给空闲的计算节点以实现负载均衡,在每个计算节点上,Flink并行执行不同的数据流操作,充分利用集群的计算资源,实现高效的大规模数据处理,计算完成后,Flink通过流式的方式将结果输出,支持多种输出目标,例如文件、数据库或其他流处理应用[2]。
3 DataStream API执行数据处理任务
Apache Flink作为一个分布式流处理框架,在Flink中定义的计算逻辑通常采用高级API,如DataStream API或Table API,采用Java执行数据处理任务源码为:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkExample {
public static void main(String[] args) throws Exception {
// 创建流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从数据源读取数据流
DataStream
// 转换和处理数据
DataStream
.map(new Tokenizer())
.keyBy(0) // 按第一个元素(用户ID) 分组
.sum(1); // 计算第二个元素(数据值)的总和
// 输出结果
sumStream.print();
// 执行任务
env.execute("Flink Example");
}
// 定义一个简单的MapFunction用于数据转换
public static final class Tokenizer implements MapFunction
@Override
public Tuple2
// 假设数据格式为 "UserID,Value"
String[] tokens = value.split(",");
return new Tuple2<>(tokens[0], Integer.parseInt(tokens[1]));
}
}
}
Flink流处理任务定义了一个MapFunction来解析和转换输入数据。在实际应用中,任务的复杂性和算法的具体形式将取决于需要解决的问题,而Flink提供了丰富的操作符和API,可以有效应对各种复杂的分布式数据处理算法[3]。
4 Apache Flink性能优化
4.1 并行计算优化
Apache Flink的流处理模型允许用户在运行时动态调整任务的并行度,通过合理调整并行度充分利用集群资源,提高任务的处理速度。将多个操作符组成操作链,减少数据在不同算子之间的序列化和反序列化開销,提高计算效率。对于涉及外部存储或服务的异步IO操作,可以采用异步的方式进行避免计算节点的等待时间,提高并行计算效率。
4.2 数据存储和传输优化
使用本地存储减少数据在节点之间的传输开销,特别是窄依赖的操作,在同一节点上执行,减少网络通信。使用高效的数据压缩算法,减小数据在网络传输和存储过程中的体积,降低传输开销。选择Flink默认支持的Kryo以减小数据序列化和反序列化的开销,调整网络缓冲区大小,使其适应集群规模和网络延迟,以提高数据传输效率。
4.3 算法参数调优
窗口操作合理选择窗口大小和滑动间隔参数,平衡数据处理的准确性和性能,迭代算法优化迭代次数、收敛条件等参数,以加速算法的收敛过程。调整任务管理器和任务执行器的内存分配,确保系统在大规模数据处理任务中充分利用资源。
4.4 系统配置调优
采用动态的检查点触发机制,根据系统负载和任务性质动态调整检查点的生成频率,高负载时可以降低触发频率,降低性能开销,而低负载时可以增加触发频率,提高系统容错性,对不同的任务设置不同的检查点触发策略,确保不同任务的容错机制更加灵活。
4.5 资源管理与调度
Flink支持动态资源分配,可以根据任务的实时需求调整计算资源的分配情况,避免资源浪费,确保任务在不同计算节点上的负载均衡,避免出现某些节点过载而其他节点闲置的情况。
4.6 检查点和容错机制优化
调整检查点的触发频率,确保在保证数据一致性的前提下,不会过于频繁地生成检查点,以减小性能开销,采用高效的存储系统来保存检查点,以提高检查点的存取速度。对检查点进行压缩和归档,减小存储空间占用,提高数据的读写效率,使用压缩算法和有效的存储结构,以降低整体系统负担[4]。
4.7 编码和序列化优化
采用性能较好的序列化框架,如Avro、Protocol Buffers等,以减小数据序列化和反序列化的开销,尽可能采用自定义的数据结构,以减小数据在内存中的存储和传输开销。采用自定义的数据结构,避免使用过于复杂的数据类型,精简的数据结构能够减小数据在内存中的存储开销,提高序列化和反序列化的效率。使用紧凑的数据表示形式,如使用整数代替字符串标识符,以降低数据传输时的带宽占用[5]。
5 实验效果分析
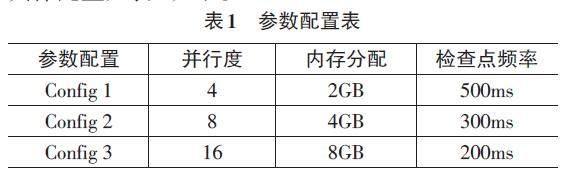
为深入了解Apache Flink在不同参数配置下的性能表现,采用平均响应时间(Response Time) 和吞吐量(Throughput) 来评估系统的实时性和处理能力,选择了三种不同的参数配置,分别代表不同的调优策略。具体配置如表1如示。
为了评估系统在处理不同规模数据集时的性能,使用不同大小的数据集进行测试。保持相同的性能指标,即平均响应时间和吞吐量,以确保实验结果的可比性,选择三个不同规模的数据集,分别是小规模(Small) 、中规模(Medium) 、大规模(Large) ,执行每个数据集规模下的实验,使用相同的参数配置,监测系统的性能表现,并记录实验结果如表3所示。
6 实验效果评价
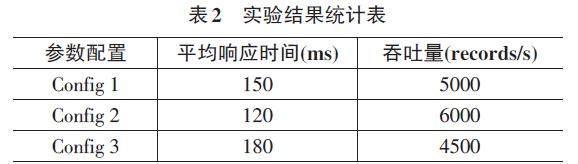
通过比较Config 1和Config 2的实验结果,在Config 2中平均响应时间显著减少,吞吐量相应增加,表明增加并行度和调整内存分配等参数可以显著提升系统性能。比较Config 2和Config 3可以发现,虽然在Config 3中增加了并行度,但注意到平均响应时间却有所增加,在某些情况下增加并行度并不总是线性地提高性能,还需要考虑任务调度和资源分配等方面的综合因素。从不同规模数据集的实验结果来看,随着数据规模的增加,平均响应时间呈上升趋势而吞吐量逐渐下降。表明系统在处理大规模数据时可能会面临一些性能瓶颈,需要更多的优化策略来应对。
7 结束语
综上所述,通过深入剖析Apache Flink流式计算框架在大规模数据处理中的性能与优化,可以发现调整任务的并行度和选择合适的窗口大小、滑动间隔等参数,直接关系到系统的实时性和吞吐量, Config 2的优异表现提示了适度的并行度和内存分配的重要性。此外,不同规模数据集下的实验表明系统在面对大规模数据时的挑战时,采用动态调整策略可为系统提供更灵活的应对手段,但性能波动的原因仍需进一步研究,总体而言,Apache Flink流式计算框架可提供更深层次的性能分析和更智能的调优策略。
参考文献:
[1] 王肇康.分布式图处理若干算法与统一图处理编程框架研究[D].南京:南京大学,2021.
[2] 朱光辉.分布式与自动化大数据智能分析算法与编程计算平台[D].南京:南京大学,2020.
[3] 母亚双.分布式决策树算法在分类问题中的研究与实现[D].大连:大连理工大学,2018.
[4] 司鲁.数据规约中分布式实例选取关键技术研究[D].长沙:国防科学技术大学,2017.
[5] 刘健.Hadoop平台下的分布式聚类算法研究与实现[D].沈阳:东北大学,2013.
【通联编辑:张薇】
