基于YOLOv5模型的驾驶疲劳研究
2024-05-15蔡姗姗郭寒英
蔡姗姗,郭寒英
(西华大学,四川 成都 610039)
汽车在人们生活场景中扮演着不可或缺的角色,然而频繁发生的交通事故对驾驶员和行人的安全造成了巨大威胁。随着交通强国战略的落地实施,交通安全已然成为我国的重要研究课题。疲劳驾驶定义尚不明确,但多指驾驶员在长时间连续驾驶后,产生生理、心理机能失调而使得驾驶员处于危险驾驶状况的现象,疲劳驾驶和酒后驾车、超速驾驶一样,是引发道路交通事故的主要原因。道路上的危机是紧急但可预防的,因此预防驾驶疲劳对于确保道路交通安全至关重要,同时也是自动驾驶相关研究面对的关键挑战。
1 驾驶疲劳研究方法
疲劳检测是许多重要应用的需求,近年来研究人员对实现可靠的检测做了一系列深入研究。目前针对驾驶疲劳的检测方法主要分为以下四大类。
(1)基于机动车行为特征的检测方法:这种方法主要是借助汽车转向和轮胎轨迹来进行判断,李伟等[1]将驾驶员模拟驾驶试验时的方向盘数据和道路偏移值数据作为试验数据集,利用BP算法对神经网络模型进行训练,从而判断驾驶员是否存在疲劳驾驶的情况。这种方法检测准确率较高,但是容易受到外部自然环境、驾驶员自身水平等因素的影响。
(2)基于驾驶员生理特征的检测方法:驾驶员生理特征包括心电信号、心率、脑电信号等[2],马世伟等[3]通过分析被试者的脑电信号数据加上问卷调查相结合的方式,降低了个人因素的影响,得到了应用脑电检测技术能够客观地判定驾驶员的疲劳状态的结论,在当前研究领域内是检测驾驶员疲劳状态的黄金方法,但实际操作时需要借助昂贵的设备且某些与身体直接接触的传感器往往侵入性太强,纵然精度很高却并不建议使用。
(3)生物化学测试方法是通过检测驾驶员的体液来进行疲劳判定,这种方法只能用于事故后检测,可能对驾驶员造成创伤并产生抵触心理。
(4)目前许多学者转向基于面部表情和图像处理技术检测的方法,这种方法将各种驾驶员图像数据用于试验研究,大部分研究使用驾驶员的面部数据,试验成本低,对驾驶员的干扰程度低。胡习之等[4]提取实车数据集的驾驶员面部特征参数,再用优化SSD算法和连续自适应均值漂移跟踪算法来检测人脸区域,优化后人脸特征提取算法能有效反映驾驶员的疲劳状态,鲁棒性强。
随着计算机技术和图像数据采集技术的快速发展,基于面部表情识别的驾驶疲劳研究成为当前的主要研究趋势。基于这类方法的试验数据通常是用摄像机采集或者直接使用已经发布的开源驾驶数据,当驾驶员产生疲劳现象时可以从面部观察到许多明显的区别,比如频繁点头、打哈欠、眨眼甚至较小程度的闭眼[5]。打哈欠是判定驾驶员疲劳或困倦的重要指标,当一个人打哈欠时嘴巴张开持续时间较长,且其动作明显,较其他面部表情更容易识别,因此将从行驶时打哈欠这一面部表情入手进行驾驶员的疲劳研究。
2 数据集处理
2.1 数据集来源
当前各个平台上所发布的开源数据集种类丰富,加之实车试验较难开展,综合考虑之后采用阿布塔希等研究整理的YawDD开源数据集[6]进行关于哈欠的疲劳研究试验,此数据集中的所有视频都是由安装在前视镜或仪表盘上的摄像头在车内拍摄的,分类标准十分规范,在目前的研究领域得到了较为广泛的采用。
YawDD包含具有多个驾驶员面部特征的两个视频合集,视频的分辨率为640×480,帧率为30 fps。第二个数据集录制了不同种族的男性司机16个、女性司机13个的29个视频,包含正常驾驶、驾驶时说话或打哈欠。数据预处理部分首先将其按帧率提取成照片文件,由于同一个视频里面包含大量内容非常接近的帧,若将每一帧图片用作训练集或验证集,会大大增加图片标注的工作量而且不利于模型的学习,为了减少冗余和训练时间,对每个视频所产生的图片进行了抽样,共得图片文件5 580个,模型训练结束后选取YawDD第一个数据集中的视频直接测试或处理为图片后作为测试集。
2.2 数据集标注
首先使用脚本将所有图片以“000001.jpg”为例的方式重命名,然后采用图像标注软件LabelImg对图片进行标注[7],标注时将目标图像全部框住,标签为打哈欠和正常两种,标注时尽可能做到同一标准。
标注后每张图片都包含一个人工标注的标签,打哈欠标记为1,反之为0,为防止模型训练时回溯不够直观,标注时保存格式为txt格式,后续放入模型的文件转换为xml格式,文件保存了目标的坐标位置信息。将数据集里的图片模仿VOC2007数据集格式保存并按比例划分训练集和验证集,样本比例如表1所示。

表1 样本比例
为了检测驾驶员的哈欠情况,大多数研究方法是先集中在面部区域识别,再利用眼睛、鼻子的定位根据人脸的几何特征确定嘴部位置。然后通过使用多个卷积网络结构来判定,这种方法不仅复杂度很高,并且依赖于精确的面部检测。
车内复杂多变的驾驶员人脸位置和光照条件使得实时准确地检测出哈欠行为仍是一项很具有挑战性的任务。YOLOv5模型是当前目标检测领域具有代表性的单阶段目标检测算法,该算法以新的理念补充了YOLOv4模型,使其在速度与精度方面得到了很大提升。利用单一的网络体系结构YOLOv5网络模型直接对驾驶员面部进行检测来分析驾驶员的哈欠情况,可为实时疲劳预警相关研究提供参考。
3 YOLOv5网络模型
目标检测是要找出图像中感兴趣的目标并确定其在图像上的位置和类别。2016年Joseph Redmon率先提出了YOLO系列模型,与其他网络同等尺寸下的模型相比性能更强,从YOLOv1到YOLOv5的发展可以看出YOLO后期没有提出更为新颖的想法,而是更重视应用落地,目标检测领域的发展因它的出现受到了极大鼓舞。除以YOLO系列算法为代表的单阶段(one-stage)目标检测算法外,还有以RCNN系列算法为代表的两阶段(two-stage)以及多阶段(muti-stage)的目标检测算法,该系列算法整个过程需要先经过候选框生成网络再经过分类网络,故检测精度相对较高但训练时间较长。
YOLO网络模型由输入端、Backbone(主干网络)、Neck网络、Prediction(输出端)四个通用模块组成。为了满足不同场景的应用需求,按照网络深度和维度的不同可以将YOLOv5模型分为YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个版本,YOLOv5算法相较于YOLOv4的提升主要体现在以下几个方面。
首先,在图像输入端对图像文件进行了马赛克数据增强操作,该方法可根据输入图像的尺寸大小进行自适应填充。其次,为了使网络在进行下采样的时候不丢失样本的特征信息,设计了位于网络最前端的对输入数据进行切片操作Focus结构,同时降低了模型的计算复杂度,以加快模型训练速度。最后,YOLOv5将CSP结构用于Backbone层和Neck网络层,增强了网络对特征的融合能力,模型的网络结构如图1所示。

图1 YOLOv5s模型的网络结构图
在YOLOv5系列模型中,随着网络不断加深加宽,YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x检测精度逐步增高。YOLOv5s网络是深度最小、特征图宽度最小的网络模型,较其余三种模型而言具有更快的训练速度与检测速度。因此,基于对试验配置和检测速度的考虑选择模型大小仅有27MB的YOLOv5s网络进行研究。将图片数据集作为原始图像输入网络,通过损失计算预测物体的类别和位置信息,从而将复杂的目标检测问题转化为常见的回归问题得到模型训练结果。
4 试验结果分析
4.1 试验环境
试验平台是64位Windows11系统,处理器为12th Gen Intel(R)Core(TM)i7-12700F,显卡为NVIDIA GeForce RTX 3060Ti,深度学习环境采用PyTorch搭建,IDE工具采用Pycharm,开发环境为PyTorch1.11.0及Python3.9,将经过处理的数据集划分为训练集和验证集,占比为80%和20%,算法文件夹命名为YOLOv5-5.0。YOLOv5s.pt作为预训练权重加载到网络体系结构中,Batch size表示每次输入的样本数量,设为16,算法迭代次数设置为1 500次,初始学习率为0.01,动量和预设权重衰减系数分别设为0.937和0.000 5。试验参数如表2所示。
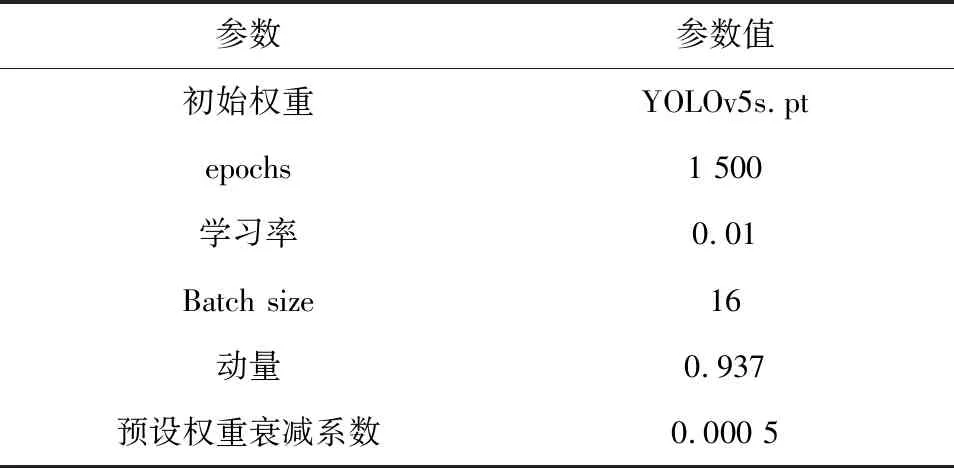
表2 试验参数配置表
4.2 模型训练及测试结果
将人工标注的5 580张图片数据集传入模型并修改相关数据配置文件,在上述试验环境下对图像数据集进行迭代训练1 500次,图中识别概率为保存两位有效数字结果,训练结果具体数值保存在results文本文件中。
模型经迭代训练结束得到最后一轮训练权重和最优权重,为了验证模型对哈欠的检测能力,将最优权重传入推理函数,从未经训练的YawDD数据集中随机提取8个视频、78张图片对模型效果进行测试。模型测试效果的检测精度平均在90%以上。
测试过程中被试者打哈欠时嘴巴张合幅度较小抑或是说话会导致极少数误检的情况;还有一种可能是训练集正样本比例较低的问题。总体而言模型的测试效果较好、较稳定,也证明了所训练模型用于实时监测驾驶员疲劳状态的可行性。
4.3 结果分析
从训练效果来看模型性能较好,本次试验引入目标检测领域常用的评价指标平均准确率mAP(mean Average Precision)、精确率(Precision)、召回率(Recall)和F1分数及每秒处理帧率(fps)来量化试验结果。模型的精确率与召回率如图2所示。
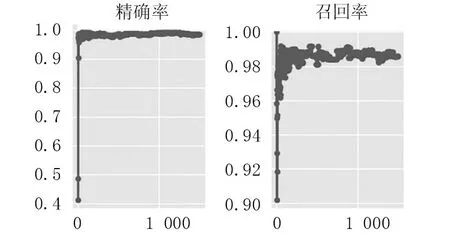
图2 模型的精确率与召回率
(1)精确率:在进行训练时模型认为正确也确实是正确的样本占模型认为正确的所有样本的概率,通常来说,精确率越高,分类器越好,计算公式为
(1)
式中:TP实际上是正样本,预测为正样本-哈欠状态被判定为打哈欠的次数;FP实际上是负样本,预测为正样本-正常状态被判定为打哈欠的次数。
(2)召回率:针对所有样本而言模型认为是正确且确实是正确的样本占所有正确样本的概率,用于衡量分类器找到所有正样本的能力,即召回率越高模型准确率越高,计算公式为
(2)
式中:FN实际上是正样本,预测为负样本-哈欠状态被判定为正常状态的次数。
(3)图3所示PR曲线表征的是精确率与召回率的关系,一般横坐标设置为Recall,纵坐标设置为Precision。图4所示为模型的mAP,AP是PR曲线下围成的面积,m表示平均,c表示类别,所有类别的AP平均值即mAP,AP越高说明模型性能越好。mAP@0.5表示在IoU阈值为0.5时的mAP值变化曲线,mAP@0.5∶0.95表示在IoU阈值以0.05步长从0.5到0.95变化时的mAP值变化曲线。这个参数适用于多标签图像分类,计算公式为
(3)

图3 PR曲线图

图4 mAP曲线图
(4)
精度和召回率反映了分类器分类性能的两个方面。通常都希望试验的P、R双高,但实际上它们是一个矛盾体,考虑两者之间的平衡点得到新的评价指标F1-score,也称为综合分类率,它能更好地反映模型检测结果,其数值越高模型性能越好。
目标检测任务的损失函数分为边界框回归损失和分类损失,YOLOv5直接使用Classification Error作为分类损失,以CIoU Loss作为边界框回归的 损失函数,损失函数值越低模型效果越好,如图5所示。

图5 验证集的损失均值
结合results文本文件和训练过程曲线变化图来看,随着迭代次数的增长,精确率与召回率都在98%或以上,mAP数值高达0.99且波动不大,各项损失函数值低至0.002。观察YOLOv5s模型算法的训练效果图可知各项重要指标的训练结果较好,说明试验所提出的哈欠行为检测模型性能良好,进一步体现了试验所训练的YOLOv5s模型作为驾驶疲劳检测模型的可靠性。
5 结论与讨论
可靠的疲劳驾驶研究是保障交通安全的重要基础,试验使用YOLOv5s网络模型对公开的YawDD数据集进行哈欠检测研究,模型训练集包含5 580张图片,测试集包含8个视频和78张图片。当迭代训练次数不断增加时,模型对“打哈欠”和“正常”的分类能力越来越强,训练和测试的准确率分别达到98%和94%,表明经过连续的训练过程后,模型在各方面表现出良好的性能。这种方法与其他现有研究相比更加简洁易操作,具有一定的实际意义。
不足的是仅仅考虑了驾驶员佩戴或不佩戴眼镜哈欠检测情况,未结合驾驶员眼部情况进行综合分析,且无法准确区分出驾驶员说话打哈欠和大笑的情况。后续研究可以从以下几个方面着手来提高试验的可靠性:第一,考虑晴天、雨天和雾霾等不同天气情况的检测效果;第二,结合驾驶员眼动情况进行综合研究;第三,增加正样本数量并考虑检测到驾驶员产生疲劳状态时提醒驾驶员安全驾驶的实时干预方法。为此,下一步研究拟在哈欠检测模型的基础上,将视频流作为输入建立在线哈欠行为检测系统。
