基于主成分分析法的自来水公司信用管理模型构建研究
2024-05-14李凡
李 凡
(苏州市能源发展集团有限公司,江苏 苏州 215000)
1 研究背景
党的十八大以来,国家高度重视社会信用的制度建设。2014年,国务院印发了《社会信用体系建设规划纲要(2014—2020年)》,其中提到,加强供水、供电、供热、燃气、电信、铁路、航空等关系人民群众日常生活行业企业的信用体系建设。2020年,国务院五部委联合发文,要求供水、供电、供气、供热行业规范收费标准,促进行业高质量发展,要求相关行业加快完善行业服务质量体系,提升行业整体服务质量。供水行业客户信用管理体系建设成为行业发展的热点问题和难点问题。
本文的研究对象S自来水有限公司是华东地区某发达地级市的市属国有供水公司,它历史悠久,是本省地级市中首家完成自来水深度处理全覆盖工艺的供水城市,主持和参与多项国家和省级行业标准制定,在供水行业内有着较高的声誉和影响力。近年来,S自来水公司的应收账款规模迅速扩大,导致占用企业资金过多,企业自身的周转率和周转速度减缓[1]。
不管是大公司还是中小企业,信用风险都是客观存在的,不能避免的,所以人们只能在风险发生之前去识别风险、转移风险来进一步降低风险,永远无法使其彻底消除[2]。如何有效提取对信用评估有重要影响的因素,基于科学方法论将这些因素相结合,形成用于客户信用评估的信用管理模型,来控制管理信用风险的成本,降低信用风险对公司经营的影响是行业研究的难点之一。
2 信用管理模型构建
本文采用主成分分析法来构建信用管理模型,主成分分析的优势在于,一方面,可以将多个杂乱无联系的变量进行分类以加强联系,将具有一定相关性和联系的变量归为一类,从而达到将含有大量原始变量的数据体降维的目的;另一方面,分析不同成分和原始变量的关系,通过成分矩阵可以获得不同主因子与原始变量之间的定量关系,从而获得原始变量在新的主成分因子中的贡献量,进而获得权重系数,为一些无法直接获取权重的问题提供科学的解题思路[3]。这里需要注意的是,因财务部门和业务部门的信用政策倾向不同,信用管理的建设应该独立于两者[4]。信用管理模型构建的主要步骤为:
2.1 特征量的选取
首先需要收集自来水销售客户的相关数据,这可能包括客户的付款历史、消费水量、延迟支付的次数、个人或企业的财务信息等。这些数据应是定量的和可度量的。
自来水销售客户的相关数据可以包括以下几类:
户表信息:即水费用户的基本信息,包括客户的年龄、户主性别、职业、家庭状况、户龄。户龄越长的,欠费可能性越低,户龄短的用户可能存在投资房产、出租房产等行为,易导致高欠费率。在家庭状况方面,家庭人口与欠费之间可能存在一定的相关性。二手房屋市场价格和欠费之间也存在一定相关性,总体上,房屋价格越高,自住率就越高,相应的欠费率就越低。
消费信息:包括客户的用水量、用水频率、用水习惯等。用水量即用户的账单水量,总体上,自来水居民户的用水量呈正态分布,一户一表居民户共474 156户,其中全年0度及以下用户40 127户,有水量的用户平均年用水量113立方米。用水频率和用水习惯影响居民用水的变化幅度,可以用方差或标准差的方式衡量用水量的波动性,标准差越大,数据之间的差异就越大;反之,标准差越小,数据之间的差异就越小。标准差的实证意义在于,标准差越小,客户的用水习惯越稳定,其欠费的可能性就越低。
付款历史:包括客户的付款方式、支付记录、逾期支付的情况、欠费情况等。客户的支付方式有柜台现金支付,手机网银以及微信、支付宝支付,银行代扣支付等形式。
支付记录:指统计用户的支付记录,主要统计用户支付销账日与开账日之间的天数,即客户在开账几天后完成付款。逾期支付情况即用户逾期付款及欠费的次数。
2.2 模型搭建的数据整理
模型建构的主要流程节点为数据预处理、运行主成分分析、模型公式确定、模型的验证与评估四个方面。
当把行李和牙具放到早已安排好的房间里的铁床上时,猴子一手提壶,一手端着茶杯,把她领了进来,又弯腰又点头,一会儿说原谅,一会儿说包涵——哼,可让他得了表现的机会。这是遗传因子的作用,比他爸爸在上司面前八面玲珑的本领还技高一筹。
模型的基本原理为通过主成分分析选取跟客户信用相关性最强的四个变量并根据成分矩阵明确各个变量的权重,建立针对供水行业的信用计算模型。
在S自来水公司的水费营销系统中提取2022年水费用户数据进行分析,从所获取数据中随机抽取某个月份的全部的水费用户数据作为分析对象,对选取样本的各指标进行筛选,选出与欠费天数相关性较高的指标数据作为建模依据。本次共选取232 718条缴费记录作为分析对象。
选取与欠费相关的客户信息作为自变量,其中影响因素主要包括客户年龄、户主性别、职业、家庭状况、户龄、消费水量、水量CV值(用水习惯和用水频率)、付款方式、支付记录、逾期支付的情况、欠费情况。以这些影响因素作为模型输入的变量进行模型构建。
基于Z-Score具有可加性和可分辨性的优势,对原始数据进行Z值标准化[5]。通过(x-μ)/σ将两组或多组数据转化为无单位的Z-Score分值,使得数据标准统一化,提高了数据可比性,削弱了数据解释性。(表1)
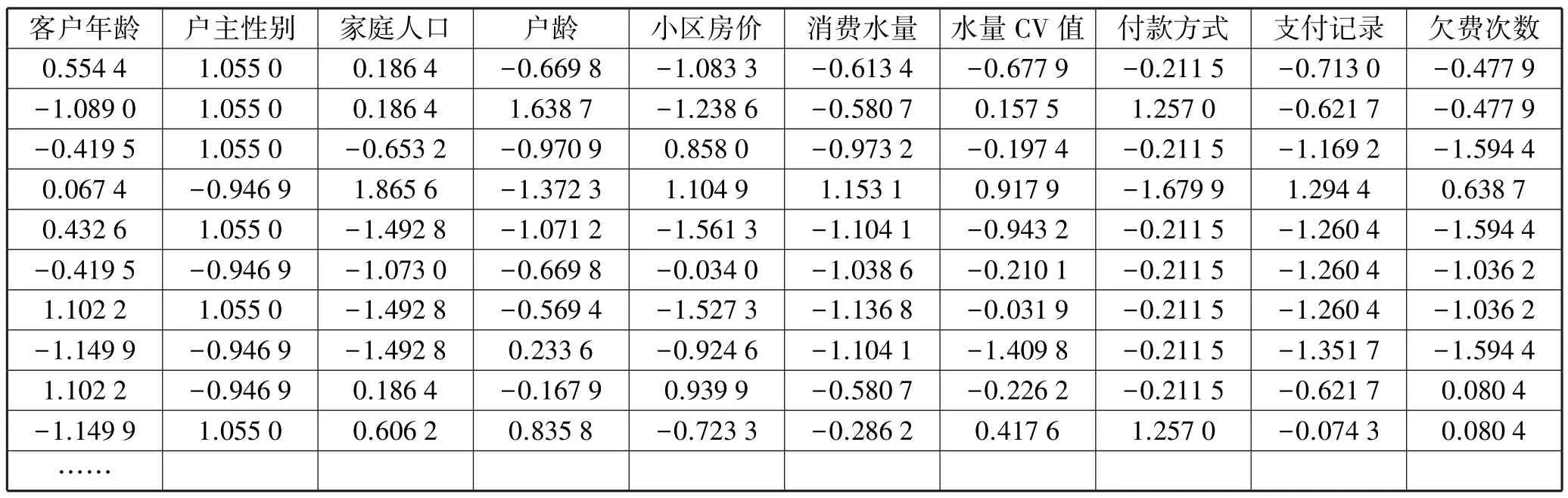
表1 Z值标准化后的样本矩阵(矩阵Z)
2.3 自变量相关性分析及模型建立
相关分析主要研究自变量与主变量之间的关系。主要通过各个自变量包括客户年龄、户主性别、职业、家庭状况、户龄、消费水量、水量CV值(用水习惯和用水频率)、付款方式、支付记录、逾期支付的情况、欠费情况和因变量欠费天数分别进行相关性计算,以获得相关性系数,从而衡量各个自变量分别与因变量之间的相关性强弱,为下一步主成分分析降维和企业客户信用管理计算公式做前期基础。
表2~表3为计算得出的协方差矩阵的特征值及其特征向量。

表2 特征值
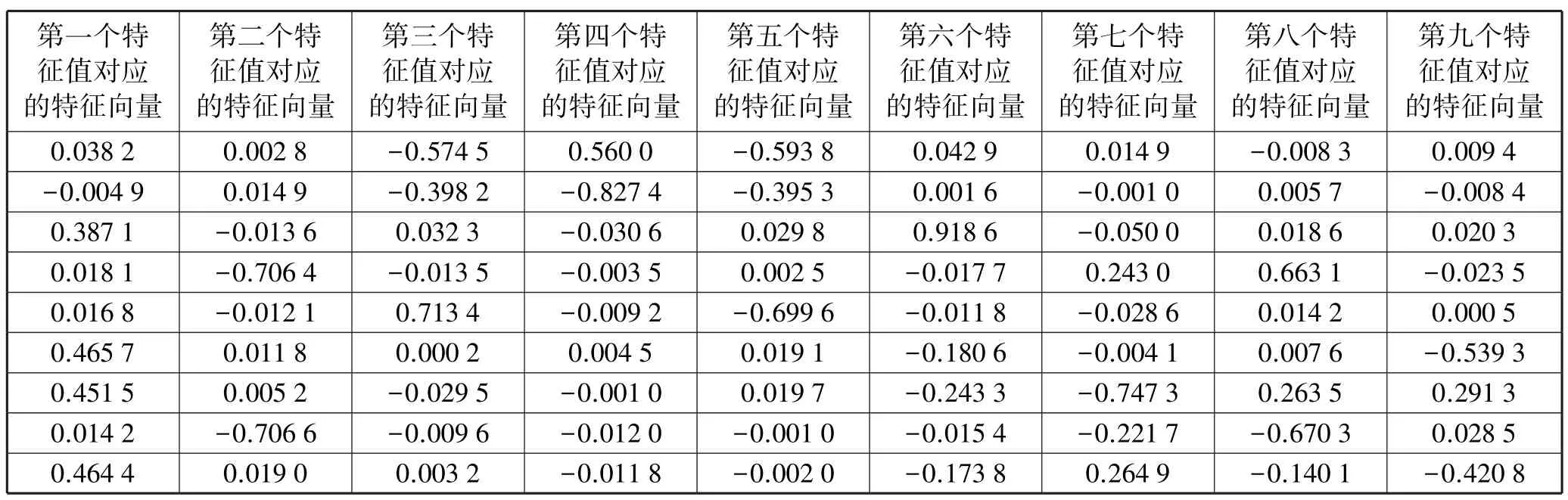
表3 特征值所对应的特征向量构成的矩阵
将以上特征值按从大到小的顺序排列,计算各主成分的贡献率及累积贡献率(表4)。

表4 主成分累积贡献率
根据方差累计贡献率一般为85%,选择5个主成分,前5个主成分的载荷因子矩阵,即最大的四个特征所对应的特征向量。
将最大的5个特征值按权重进行分配,即为主成分系数,得到主成分函数:
以上主成分函数结合对应的特征向量,即为自来水公司的信用管理模型。
3 基于模型计算调整管理模式
分层信用管理模式如表5所示。

表5 分层信用管理模式
信用值在200分以下的用户属于信用最优的一类用户,一般是自主用房,具有稳定的家庭人口和用水习惯,绝大部分通过代收代扣进行缴费,比较关心自身的信用值。出现欠费的情况,往往是因为家庭代扣银行账户余额不足、家庭临时外出、家庭迁址等,这种情况下,无须过早采取催讨措施,可等待用户自行发现后完成缴费。
信用值在200~400分的用户,属于信用优质用户,一般是自住用房,具有稳定的家庭人口和用水习惯,通过代收代扣或网上银行进行缴费,对自身信用值无感,出现欠费的情况往往是因为自身遗忘,非主观意愿,对这类用户,优先贴单通知,主要通过贴单通知加深其欠费印象,争取调整该类用户的缴费习惯,并在贴单通知上附上银行代收代扣的签约方式,鼓励其前往银行网点签订代收代扣协议。
信用值在400~600分的用户,属于信用一般用户,既有自住用房也有租赁用房,家庭人口不稳定,导致用水习惯不稳定,一般通过网上银行进行缴费。对这类用户,通过上门贴单和电话通知双管齐下通知其缴费,确保能够通知到人,另外满45天即关阀停水,防止账单过大导致企业发生较大损失。
信用值在600~800分的用户,属于信用较差用户,一般以租赁用房为主,这类用户的关阀停水期限为30天,如关阀停水后仍未及时缴费复开,则在满60天时予以拆表停水,拆表意味着中止供水服务,用户若要恢复供水必须走更为复杂的流程。因此在满60天,即下一个账期到来时予以拆表,施以较为严厉的催收措施。
信用值在800分以上的用户,属于信用极差的用户,对该类用户,在欠费满15日起即开始通过贴单和电话催讨的方式通知其缴费,且为避免二次上门的费用,在满30日起,直接予以拆表停水。
4 结语
基于主成分分析法,运用matlab软件工具对企业客户信用数据进行处理,形成客户信用管理模型,以该模型为基础调整信用管理模式,可以有差别地施加催讨政策。一方面,暂缓部分优质用户停水的催讨措施,给予优质用户一定的容错空间,可以减少催讨成本,同时提升客户的用水体验;另一方面,对信用等级较差的用户或有长期恶意欠费前科的用户,及时止损,减少中间环节,及时中止供水,可以更有效地进行水费催讨,提升企业的综合收益。
