基于卷积神经网络的采血管铝箔帽状态检测方法
2024-05-13侯剑平赵万里孙千鹏王超刘聪
侯剑平,赵万里,孙千鹏,王超,刘聪
安图实验仪器(郑州)有限公司,河南 郑州 450016
引言
随着新的检测技术和自动化仪器的应用逐渐普及,更多的医院开始引入医学实验室自动化生化免疫检验流水线[1]。在流水线的运行过程中,采血管从冰箱取出后需要使用开封膜设备去掉铝箔帽。铝箔帽去膜失败会造成后续检测设备撞针,严重影响流水线的运行安全及作业人员的生物安全,因此采血管铝箔帽状态检测意义重大。
医学实验室自动化生化免疫检验流水线对检测设备的识别准确率要求极高,识别错误率不能高于十万分之一。同时,极高的检测通量对识别速度要求非常高,识别时间不能超过20 ms。由于采血管样本类型众多,采血管铝箔帽封膜和去膜失败状态复杂,以及存在大量管壁挂液样本的干扰,且前人研究的基于超声波检测技术[2]以及传统机器视觉的缺陷检测技术[3]只能适用于单一类型、正常情况下的采血管铝箔帽状态检测,无法满足实际检验过程中对复杂采血管铝箔帽状态的检测要求,因此该研究技术的识别准确率较低。
深度学习技术的快速发展使基于卷积神经网络的图像分类网络模型的识别精度越来越高。从VGGNet[4]、GoogleNet[5]到ResNet[6],识别错误率大幅降低至3.57%。随着嵌入式边缘侧应用场景的出现,图像分类网络模型正朝着轻量化的方向发展,DenseNet[7]、MobileNet[8]和ShuffleNet[9]等轻量化分类网络模型的参数量下降至10 M以内。目前,刘洋等[10]将轻量级卷积神经网络应用到植物病害识别,郑冬等[11]将轻量化卷积网络应用到车辆及行人检测,田苗等[12]将卷积神经网络应用到神经影像的应用研究中,张海涛等[13]将卷积神经网络应用到急性淋巴细胞白血病血液细胞显微图像的辅助诊断分类研究中,但还没有将卷积神经网络应用到采血管铝箔帽状态检测中的相关研究。
医学实验室自动化流水线内部预留的装配空间狭小,且由于需要兼顾成本,就要求必须使用边缘侧计算设备,使用更加轻量化的分类网络模型。针对以上问题,本文提出一种基于卷积神经网络的采血管铝箔帽状态检测方法,该方法使用知识蒸馏技术,分别设计了教师深网络和学生浅网络模型,通过教师网络指导学生网络进行知识蒸馏学习,最终得到的轻量化小模型可准确识别采血管铝箔帽状态。
1 方案设计
为了适应边缘侧计算设备较低的算力,同时满足较高检测通量的要求,本文提出了一种基于轻量化卷积神经分类网络模型的检测方法,该方法使用知识蒸馏技术分别设计教师网络和学生网络。首先训练相对复杂的教师网络模型,在取得较好的识别准确率后,使学生网络学习教师网络并进行知识蒸馏,最后训练得到同样较高识别准确率的学生网络模型。教师网络模型和学生网络模型均以ResNet 为基础,压缩网络深度,修改部分卷积层的参数,增加侧支和压缩与激励(Squeeze-and-Excitation,SE)模块。模型各层间激活函数使用高斯误差线性单元(Gaussian Error Linear Units,GELU)函数,模型训练损失函数选择Focal Loss 函数。教师网络和学生网络的唯一区别是教师网络比学生网络多1 个大层。教师网络模型的和学生网络模型的3D 网络结构分别如图1~2 所示,教师网络模型和学生网络模型的架构图分别如图3~4 所示。两种模型整体结构类似,主要由输入、主支、侧支和分类器4 部分组成。模型输入的是归一化之后的铝箔帽区域图像,输出的是铝箔帽状态识别结果,二分类结果分别对应“有铝箔帽”和“无铝箔帽”2 种状态。

图1 教师网络模型3D网络结构
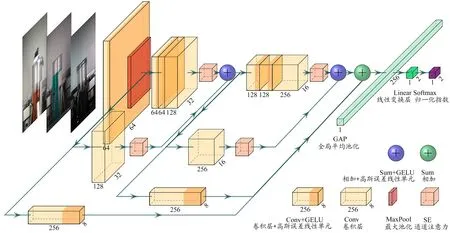
图2 学生网络模型3D网络结构

图3 教师网络模型架构
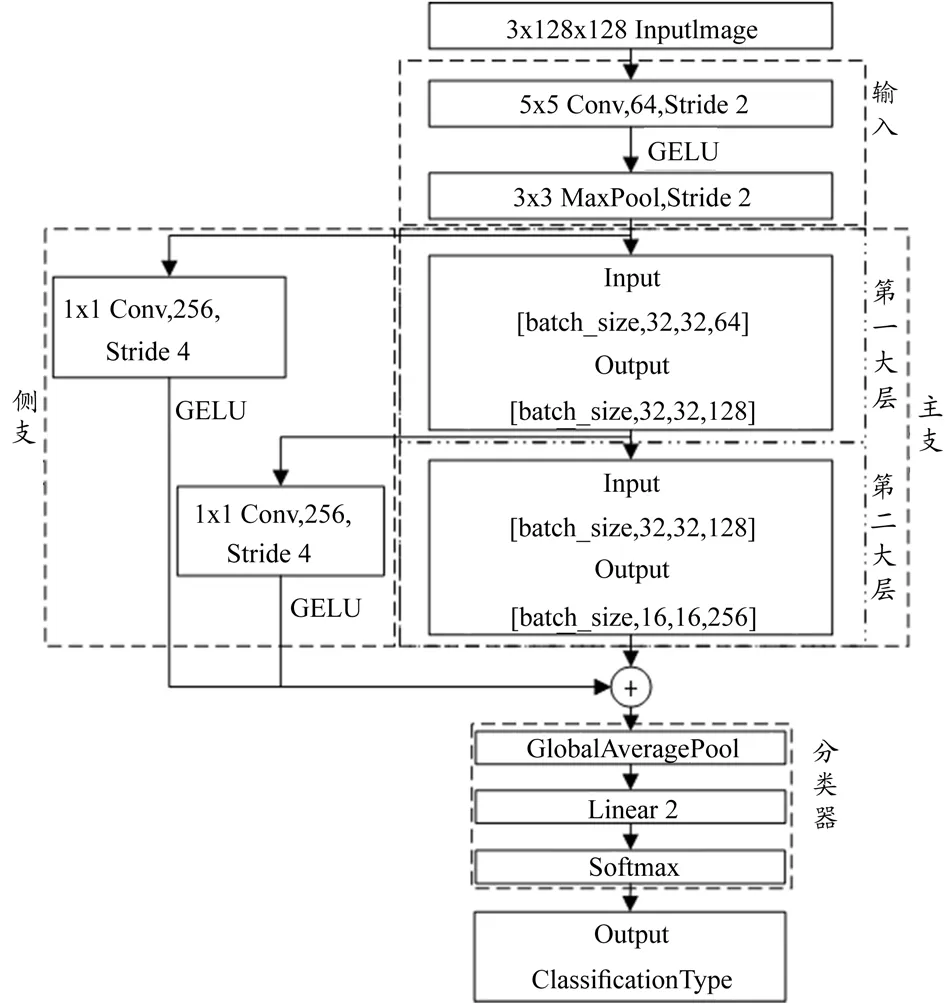
图4 学生网络模型架构
1.1 基本方法
1.1.1 Focal Loss损失函数
Focal Loss 损失函数[14]是在标准交叉熵损失函数的基础上修改得到的,是一种针对类别不平衡问题的损失函数,通过调整难易样本的权重来解决大多数样本易分类而少数样本难分类的问题。该函数可通过减少易分类样本的权重,使模型在训练时更专注于难分类的样本。
开封膜撕膜失败样本和管壁挂液干扰复杂多变,同时样本类别分布不均衡,且存在比较严重的难例样本挖掘问题;少量正样本所提供的关键信息难以被损失函数发现,使模型优化的方向不是正确的方向,从而造成部分样本误检,Focal Loss 损失函数正好可以解决这一难题。Focal Loss 损失函数的计算方式如公式(1)所示。
式中,tα为平衡因子,用来平衡正负样本的比例;pt为调节简单样本权重降低的速率,用来解决难例样本难以被训练的问题。本文取tα=0.25,pt=2。
1.1.2 知识蒸馏
知识蒸馏可用于压缩和加速模型,是一种基于“教师-学生网络思想”的迁移学习训练方法。该方法首先使用教师深层网络模型进行训练,获得一个识别成功率比较高的教师网络模型的权重文件,再使用学生浅层网络模型进行知识蒸馏学习,最终获得一个用于部署学生网络模型权重的文件。
知识蒸馏的核心是其损失函数L 的设计,本文使用的损失函数L 的计算方式如公式(2)~(5)所示。
式中,α和β是超参数,本文全部为1;vi和zi分别为样本使用教师网络和学生网络输出Softmax[15]前的值;N为样本总数;T为温度系数;L 为模型的损失函数;Lsoft为软损失函数又名为蒸馏损失函数;Lhard为硬损失函数又名为学生损失函数;和分别为教师网络模型和学生网络模型的输出类别概率值;此处k=1。
其中,当T值接近于0 时,输出的最大概率接近于1,而其他值趋近于0,接近于one-hot 形式;当T值接近于∞时,输出的概率值趋近于均匀分布;当T值等于1 时,输出的概率值就是标准的Softmax函数。本文T取值为3。
1.1.3 SE模块
SE 模块[16]主要包含压缩和激励两部分,其结构如图5 所示。这种注意力机制让模型更关注信息量最大的通道特征,抑制不重要的通道特征。网络可自动学习每个通道的重要性权重,并将注意力集中在最具区分性的通道上,有助于提升网络的表达能力和判别能力,进而改善模型在各种计算机视觉任务中的性能。

图5 SE注意力模块
1.1.4 GELU激活函数
本模型使用的激活函数是GELU 函数[17],其性能优于传统的修正线性单元(Rectified Linear Unit,ReLU)激活函数,可使网络更具稀疏性,防止梯度消失,增加网络的非线性。GELU 激活函数的计算方式如公式(6)所示。
式中,x为函数的输入;X~N( 0,1)为均值为0、标准差为1 的高斯正态分布函数。
通常情况下取µ=0 和σ=1 的标准正态分布函数,其近似的计算方式如公式(7)所示。
1.1.5 改进型BottleNeck残差块
改进型BottleNeck 残差块[6]的结构如图6 所示。在原始BottleNeck 残差块的基础上增加SE 模块,同时使用GELU 激活函数替代ReLU 激活函数,目的是为了在增加网络深度和非线性的前提下,尽可能减小网络的计算量和参数量,引用通道注意力机制,从而使更重要的通道获得更多的训练权重。

图6 改进型BottleNeck残差块结构
改进型BottleNeck 残差块的左侧分支分别使用1×1、3×3、1×1 的3 个卷积层进行特征提取,3 个卷积层之间使用GELU 函数进行激活,3 个卷积层之后是一层SE 模块。改进型BottleNeck 残差块右侧分支使用一个1×1 的卷积层改变输入数据的通道数,接下来是一层SE 注意力模块,用以保留上层网络所获取的特征信息,防止梯度弥散或梯度爆炸。改进型BottleNeck 残差块的左侧分支和右侧分支使用Add 汇总后,再使用GELU 函数进行激活。
改进型BottleNeck 残差块的计算方式如公式(8)所示。
式中,xl为上一层的输入 ;xl+1为l层的输出,同时是l+1 层的输入;h(xl)为输入的直接映射;F (xl,Wl)为残差部分。
1.2 模型结构
1.2.1 输入图像尺寸和模型输入
经典卷积神经分类网络模型的输入图像尺寸一般为224×224。经过对本模型的测试,发现输入图像尺寸为224×224 与128×128 对模型的识别准确率并无显著差异;同时,128×128 的输入图像尺寸使模型的推理速度得到了明显的提升。为了使得模型更加轻量化,更适合边缘侧的计算设备,本文使用128×128 作为模型的输入图像尺寸。
输入部分包括2 层网络结构,第一层使用Kernel 为5×5、Stride 为2 的卷积层提取输入图像中的一些细节特征,特别是边缘形状的浅层特征;第二层使用Kernel为3×3,Stride 为2 的最大池化层[7]进行池化,用来减少参数量,压缩特征,进一步简化网络复杂度,减少计算量和内存消耗。卷积层和最大池化层之间使用GELU函数进行激活。
1.2.2 模型主支和侧支
教师网络模型主支整体包括3 大层,每一大层是一个改进型BottleNeck 残差块。改进型BottleNeck 残差块的结构如图6 所示,在原始BottleNeck 残差块的基础上增加SE 模块,使用GELU 激活函数替代ReLU 激活函数。
教师网络模型主支的3 大层将数据通道数依次变为128、256、512。第二大层和第三大层中间层使用Stride 为2 的卷积层进行降采样,将数据的长和宽各减小50%,进一步压缩特征,减小网络的计算量和参数量。学生网络模型主支比教师网络少了一个大层,其他的结构和教师网络模型一样。主支使用比较深的网络结构,用以提取样本数据集中比较高级的特征信息。
教师网络模型包括3 个侧支,分别将输入、主支第一大层和主支第二大层的输出使用Kernel 为1×1,Stride 分别为4、4、2 的卷积层进行数据维度的整合,将数据降采样,输出通道变为512,再使用GELU 函数进行激活,最后与主支使用Add 进行汇总,合并为一个分支。学生网络比教师网络模型少一个侧支,两个卷积层的Stride 都是2,同时输出的通道变为256。
各个侧支分别从不同尺度不同深度获取样本数据集的特征信息后,将这些特征和主支获取到的特征进行融合,获得最终特征信息,提高模型的特征获取能力。
1.2.3 模型分类器
分类器包括3 层网络结构:第一层是全局池化层[18];第二层是线性变换层,将长度为512 的特征向量转换为长度为2 的特征向量;第三层是Softmax,计算每个分类的概率得分值。
2 模型构建与数据处理
2.1 数据集采集和预处理
训练数据集图像采集于医学实验室自动化生化免疫检验流水线。分别准备未封膜采血管样本2500 个,去膜成功采血管样本2500 个,未去膜采血管样本2500 个,去膜失败(包括铝箔帽翘起和铝箔帽残留)采血管样本2500 个,所有样本共计10000 个,其中包括直径13 mm和16 mm、长度75 mm 和100 mm 的采血管样本。采血管类型包括普通平口和螺纹口,采血管管壁包含各种颜色挂液。
未去膜采血管和去膜失败采血管样本属于“有铝箔帽”类型。未封膜采血管、去膜成功(包括各种挂液干扰)采血管样本均属于“无铝箔帽”类型。使用工业相机采集所有采血管样本图片共10000 张,各种类型的采血管样本图片如图7 所示。

图7 采血管铝箔帽区域图片
将采集到的10000 张样本图片中的未封膜样本和去膜成功样本照片放到OK 文件夹内,未去膜样本和去膜失败样本放到NG 文件夹内。使用随机函数的方式按照8 ∶2 的比例将所有图片划分为训练集和测试集,再将其分别放到train 和val 文件夹内,完成数据集的制作。
2.2 模型训练
本文使用PyTorch 深度学习软件平台进行模型的训练,使用图形处理器(Graphics Processing Unit,GPU)进行加速训练。具体的训练环境如下:
软件环境:Windows 10 专业版系统,CUDA 11.1 版本,PyTorch 1.8.2+cu111 版本,Python 3.6.13 版本。
硬件环境:Intel(R) Core(TM) i7-7700 CPU,NVIDIA GeForce GTX 1060 GPU,32G RAM。
模型训练的初始学习率=1×10-5,batch_size=32,Epochs=150。
训练过程包括教师网络模型的训练和学生网络模型的训练。对于教师网络模型的训练,需加载数据集中的训练集和验证集,选择教师网络模型,开始模型训练。训练过程中使用动态管理训练学习率的策略,首先使用初始学习率,动态监测实时准确率和损失,保存当前最高的准确率和对应最低的损失。如果连续10 个训练周期准确率没有进一步提高且损失没有进一步减少,则将学习率减少为原来的50%。经过150 个epoch 充分训练后,获得最佳训练模型文件。
教师网络模型训练过程的准确率曲线如图8 所示,经过100 个Epoch 训练后的准确率值达到了比较稳定的状态,最终值稳定在100%。本文模型训练过程的损失曲线如图9 所示,损失值经过快速下降以后,最终在0.005附近达到稳定状态。
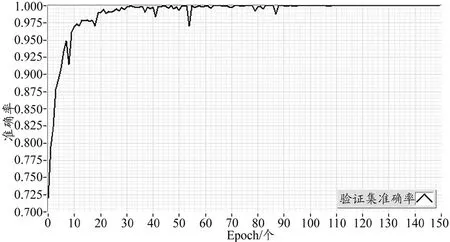
图8 教师网络模型训练过程的准确率曲线

图9 教师网络模型训练过程的损失曲线
学生网络和教师网络模型的训练过程基本相同,不同的是学生网络的损失函数使用的是知识蒸馏损失函数,通过学习教师网络进行知识蒸馏,最终取得了非常高的识别准确率,达到了100%。
2.3 模型测试
本文使用NVIDA Jetson Nano 边缘侧计算设备进行模型的测试,使用TensorRT 进行部署推理加速,具体的测试环境参数如下:
软件环境:Ubuntu18.04LTS 操作系统,CUDA 10.2.300版本,TensorRT 8.0.1.6 版本,QT 5.9.5 版本。
硬件环境:4-core ARM A57 1.43GHZ CPU,128-core Maxwell GPU,计算性能472GFLOPS,4G RAM。
测试过程如下:将模型训练获得的模型文件部署到TensorRT 环境中,再使用TensorRT 批量读取测试集并进行推理预测,记录所有样本的识别结果和推理时间,获得模型的识别准确率和识别速度。
经过测试,本文教师网络模型在Jetson Nano 边缘侧计算设备上的识别准确率达100%,识别速度达4.45 ms。本文学生网络模型在Jetson Nano 边缘侧计算设备上的识别准确率达100%,识别速度达3.42 ms。
2.4 评价指标
本文所提出的基于轻量化卷积神经分类网络的采血管铝箔帽状态识别模型应用在医学实验室自动化生化免疫检验流水线开封膜设备中,优先考虑识别准确率和识别速度2 个评价指标。识别准确率=正确分类的样本数/总数;识别速度为批量处理单个样本的平均识别时间。
除了上述2 个评价指标外,由于边缘侧计算设备嵌入式板载存储空间有限、内存及计算能力较弱,还需考虑模型的参数量以及浮点数计算量,并在尽可能高的识别准确率下,减小模型的参数量和浮点数计算量,提高识别速度,缩短识别时间。
3 结果
为了验证本文所提出的基于轻量化卷积神经分类模型的采血管铝箔帽状态识别模型的各项指标,分别与ResNet50、DenseNet121、MobileNetV2 以及ShuffleNetV2_0.5 卷积神经分类模型进行了对比测试。不同模型训练过程的准确率曲线如图10 所示,本文模型准确率曲线超过其他所有模型取得了最优结果,经过一个稳步增加过程后,最终的准确率值稳定在100%。

图10 不同模型准确率曲线对比
分别从准确率、参数量、浮点数计算量和识别速度等维度对不同模型进行对比测试,对比实验结果如表1所示。

表1 不同分类模型的实验结果对比
由表1 可知,本文教师网络和学生网络模型均取得了较好的识别准确率,达到了100%。ShuffleNetV2_0.5模型的浮点数计算量虽然是最小的,但其识别速度并没有本文教师网络和学生网络模型快,同时其准确率过低,无法满足需要。本文学生网络模型的参数量仅有0.354 M,浮点数计算量仅有0.165 GFlops,远优于其他模型,并且在Jetson Nano 边缘侧计算设备上的识别速度只有3.42 ms,远超其他网络模型。
4 讨论与结论
本文针对医学实验室自动化生化免疫检验流水线识别准确率和识别速度要求极高、采血管类型众多、采血管铝箔帽状态复杂以及管壁挂液干扰严重的问题进行了研究。前人基于超声波检测技术[2]和传统机器视觉方法[3]的研究无法适应如此复杂的情况,且识别准确率较低,因此本文提出了一种基于卷积神经网络的采血管铝箔帽状态检测方法。该方法首先采用轻量化的模型设计思想,通过减少模型的深度来降低参数量和计算量,同时,引入通道注意力机制,以提高样本特征的提取能力;此外,还采用了Focal Loss 损失函数来解决难例样本挖掘的问题,进一步优化了模型的性能;最后,通过教师网络指导学生网络模型进行知识蒸馏,得到了最终轻量化的小模型。
实验结果表明,学生网络模型的轻量化设计使其适用于资源有限的边缘计算设备,模型的参数量仅为0.354 M,浮点数计算量为0.165 GFlops,Jetson Nano 设备上识别速度为3.42 ms,而且在复杂的采血管情况下仍能实现100%的识别准确率,充分证明了该模型的轻量化、高效性和实用性。
下一步研究将继续探索轻量化卷积神经网络模型在其他目标分类、目标识别和目标分割任务中的应用,以实现算法的工程化部署和实际应用。这一研究方向的拓展将进一步提升该模型的价值和适用性,推动其在实际场景中的广泛应用和落地。
