面向注塑产品工艺缺陷的知识图谱构建方法及应用
2024-05-11葛睿夫任志刚林江豪高祖标
葛睿夫,任志刚,林江豪,林 越,高祖标
(广东工业大学 自动化学院粤港澳离散制造智能化联合实验室,广东 广州 510006)
1 引言
现有的专家经验形成的手册依然以传统的文本形式呈现,在实际的检修过程中仔细查阅,存在知识定位难、知识获取效率低等困难.知识图谱作为一种有向图结构,具备对知识进行高效关联及检索的能力,利用知识图谱将传统的文本手册信息转化为专家知识载体,以信息检索手段进行知识定位,可有效解决知识定位难、获取效率低等困境.从多源异构数据中抽取出专家知识并构建领域知识图谱,从而为故障定位效率的提升赋能,也是未来注塑智能制造的发展方向.
知识图谱可将文本中包含的知识以更接近于人类认知世界的形式进行表达和描述,为海量知识的高效管理、组织和理解提供了可能[1].其应用形式广泛,主要包括推理[2-4]、搜索[5]、推荐[6-7].在推理方面,吴运兵等人[2]提出了一种基于路径张量分解的知识图谱推理算法,利用路径排列算法(path ranking algorithm,PRA)获得知识图谱中实体对间的关系路径,对其进行张量分解,并在迭代过程中采用交替最小二乘法;Graves等人[3]提出的可微分神经计算机(differentiable neural computer,DNC)由长短期记忆递归神经网络(long short-term memory,LSTM)控制器和外部存储矩阵两部分构成,通过训练后的LSTM与外部存储结构的不断交互过程,模拟人脑基于已有知识的推理过程,实现对三元组中空缺部分的推理.在搜索方面,孙小兵等人[5]针对开发人员bug 解决效率的提升问题,提出了基于bug知识图谱的探索化搜索方法.在推荐方面,Huang等人[6]基于序列推荐任务设计了特定的注意力机制,使不同语义路径的推荐结果权重得以量化,提升了模型可解释性;Wang等人[7]提出一种端到端的知识图谱注意力网络(knowledge graph attention network,KGAT),通过相邻节点的嵌入传播优化当前节点的嵌入表示,由此提升推荐模型的可解释性.
在工业故障诊断的知识图谱应用中,国内外均有一些相关研究.Liu等人[8]基于所提出的基于注意力机制的一维(attention-based one dimension,ATT-1D)、卷积神经网络(convolutional neural network,CNN)、门控循环单元(gated recurrent unit,GRU)模型,对轴承故障参数类型进行分类,并依托自定义的实体映射表实现参数向知识图谱实体的映射,实现了高效的轴承故障诊断.Meng等人[9]在所构建的电力故障文本数据集中,实现了电力设备实体及其故障的抽取,基于所获取的实体构建了电力故障诊断知识图谱.Xiao等人[10]在轴承故障诊断过程中,以故障数据的时、频域特征和故障描述本身作为节点,特征-故障的相关性作为边构建抽象知识图谱架构,提出的加权随机森林算法,充分利用知识图谱边信息提升了故障分类精度.Chi等人[11]基于工业互联网设备间连接复杂且建模困难的背景,综述了领域内基于知识本体推理构建知识图谱的研究进展,并展示了成功应用的案例.Feng等人[12]提出了一种用电信息采集系统的知识问答系统,实现了边与节点的高效遍历搜索,支持高效和智能化的采集与维护故障诊断,使得推理效率获得提高.Ou等人[13]针对如何实现电力传输中无人网络监控和自动运维的问题,在研究中使用故障信息和终端信息构建了知识图谱,实现了电力无线专网的决策制定和故障诊断.Liu等人[14]基于所提出的由铁路操作故障及其危害组成的因果网络构建铁路操作故障知识图谱,探索故障的潜在规则并提出预防措施.李乐乐等人[15]基于飞机维护和维修的相关知识研究知识图谱的构建和应用方法,利用SQLite数据库和知识图谱构建了飞机维护维修知识库,并利用数据库对飞机故障进行了时间和空间维度的分析.Chen等人[16]提出了一种基于本体的旋转机械故障诊断模型.他们首先构建了代表振动特征、控制措施、故障原因和故障名称的本体,用于信息采集和共享.然后,用语义Web规则语言建立描述规则.Melik-Merkumians等人[17]提出了一种基于本体的工业控制应用故障诊断系统.他们使用本体来建模系统组件的相关性、约束、依赖性,以及描述整个系统行为的系统状态.使用网络本体语言(web ontology language,OWL)构造推理机实现对潜在系统故障的诊断.Khadir和Dendanihadiby[18]研究了本体和基于案例的推理如何协同实现汽轮机的故障诊断和维护,案例的阐述、检索和改编是基于领域本体的.Xu等人[19]考虑了故障特征、故障模式之间的多对多关系,提出了一种新的基于置信规则的船用柴油机故障诊断专家系统.Samirmi等人[20]针对模糊概念的表示提出了模糊本体,并提出了一种基于深度学习的电力变压器故障诊断模糊本体推理器.除了抽象的概念联系之外,针对对物联网设备产生的信号数据的本体映射规范也有一些研究[21-25].
目前,国内外在针对知识图谱在工业领域故障诊断的应用研究,尚处于起步阶段,存在两个核心难题.一是故障诊断知识图谱的知识本体须由工业领域技术专家来进行定义,而工业体系庞杂、专家经验难以表述等现实问题大大增加了知识本体构建的难度;二是区别于通用领域的大规模语料,工业中各垂直领域能提供的可供知识抽取的有监督语料有限,在此情形下,如何提升模型抽取效果是亟待解决的核心问题.
针对知识图谱在注塑领域的应用难题,本文提出注塑领域知识图谱构建方法及其应用示范,主要贡献可总结如下:
1)构建了面向注塑领域机械故障的知识本体,以行业专家经验知识为依据,确定了知识图谱的节点要素和关联关系,为知识图谱构建提供知识支撑;
2)构建了注塑领域知识图谱,提出采用预训练语言模型的方法,将注塑领域知识拼接到模型学习过程,解决了注塑领域有监督训练语料不足的问题,实验结果表明该方法能有效提升知识抽取效果;
3)将知识图谱应用到实际的工业应用场景,验证了提出方法的有效性和可行性,为注塑工业知识自动化提供了一种应用模式.
本文其他部分内容组织如下: 第2节阐述了注塑领域知识图谱构建方法总体流程,对产品缺陷解决方案本体构成及知识抽取模型结构进行了说明;第3节从实验数据及标注策略介绍、实验设置、实验结果对比分析等几个方面对本文实验过程进行介绍,验证了模型结构的有效性;第4节对全文工作进行总结,结合当前的困境提出未来继续完善的方向.
2 注塑产品缺陷知识图谱构建
2.1 总体方法流程
面向注塑产品缺陷解决方案的知识图谱构建及应用流程如图1所示,具体描述如下.
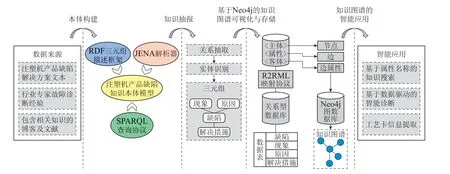
图1 注塑产品缺陷知识图谱构建流程Fig.1 Construction process of defect knowledge graph of injection molding product
1)根据原始语料情况和图谱需求确定实体类型和关系类型的分布情况,从而构建本体.构建完成的本体依靠JENA 解析器(基于JAVA的语义网应用框架,常用于解析本体模型),实现本体元数据向资源描述框架RDF(resource description framework),用于描述Web资源的特性及资源之间的关系的转化,并将本体按照<主体>-<属性>-<客体>的三元组形式进行解析和存储,且支持SPARQL查询语言对存储的三元组进行查询;
2)完成本体的构建以后,基于从原始语料中选取的语料划分出训练集和测试集,并对训练集和测试集进行关系标注和实体标注.搭建关系抽取模型并使用训练集进行训练,然后,在测试集上测试模型效果;
3)根据关系抽取模型预测的结果将训练集进行重复,每条重复的文本对应一种预测出的关系(原始文本中可能存在多种关系).在处理后的训练集上训练实体识别模型,在测试集上评估模型效果;
4)完成关系抽取与实体识别后,将抽取出的注塑产品缺陷知识通过R2RML(relational database to RDF mapping language)映射语言的的自定义词表,实现关系型数据库向RDF 数据集的转化,通过属性映射最终存储在Neo4j图数据库中形成知识图谱.
2.2 本体构建
一般情况下,本体可建模为[26]
各元素含义如下:
O: 本体模型;
C: 概念(类),某一类实体对象的集合;
R: 概念(实例)逻辑关系,指概念之间的交互作用关系(组成关系、继承关系及其他业务关系);
P: 概念(实例)属性关系,即概念具有的属性和属性值;
I: 实例(独立的实体),表示属于某种概念类的基本元素;
在本体中,关系类型是对其头尾实体类型的约束,即头尾实体类型的固定组合可能对应多种关系类型,但一种关系类型必定唯一对应一种实体类型的组合.
对于领域知识图谱,实体类型组合对应的关系类型相较于通用知识图谱更单一,即关系类型的定义可以简单化.故基于对从语料中构建的知识本体的了解,定义实体类型与关系类型如图2所示.
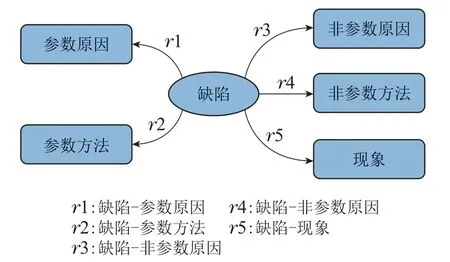
图2 实体类型与关系类型定义Fig.2 Definition of entity type and relationship type
基于本体定义的概念,图中“缺陷”为C,代表了各缺陷类型实体的集合;类型之间定义的关系集合
2.3 知识抽取模型研究
知识抽取模型架构如图3所示,其包含两个部分:关系抽取、实体识别.原始文本经过基于变换器的双向编码器表示(bidirectional encoder representations from transformers,BERT)编码层生成每个字符的嵌入向量,经过层归一化处理后输入动态卷积神经网络(dynamic CNN,DCNN)层进行特征提取.
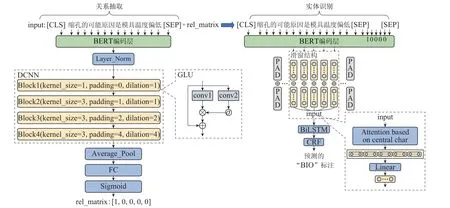
图3 知识抽取模型结构Fig.3 Model structure of information extraction
DCNN 层包含4个门控线性单元(gated linear unit,GLU)[27],每个单元包含两个形状相同、参数不同的一维卷积核.其中一个卷积核对输入进行卷积后经过Sigmoid进行激活,运算结果与另一个卷积核的卷积结果进行逐元素相乘,然后,以类似残差结构的方式与输入相加得到最终输出结果.
DCNN层的输出结果经过一维平均池化及全连接层后,输入Sigmoid层进行针对所有关系类别的二分类分值计算,将所有分值中大于0.5的置1,小于0.5的置0,得到最终的关系分类矩阵.预测出文本中包含的关系种类后,将其作为文本特征输入实体识别模型中识别出关系对应的首尾实体,输出最终的三元组结果.
2.3.1 BERT嵌入层
BERT嵌入由3个部分组成: Token嵌入、Segment嵌入和Position嵌入.BERT模型对字符级、词级、句子级,以及句间关系的特征信息能够进行充分的表述,大大增强了词向量模型的泛化能力.
1)Token嵌入.
Token嵌入是指将输入的序列按字编码成固定维度的向量的过程.在BERT中,维度默认为768.
在传递到Token嵌入层之前,输入的文本需要先经过标签化的过程,即将每个Token转化为词表中对应的序号,具体如图4所示.
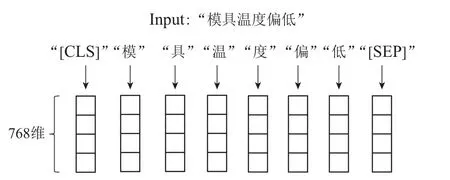
图4 Token嵌入Fig.4 Token embedding
单词切片向量化(word piece token,WPT)是Token嵌入采用的基本方法,是一种基于数据驱动的方法.这种方法专用于输入文本是英文的情况下,例如输入的文本中包含单词“playing”时,BERT会将其拆分为“play”和“ing”.
2)Segment嵌入.
Segment嵌入对输入句子对进行区分,从而,根据两个句子的语义相似度进行后续分类任务.在输入的句子对为“光影常见于产品结构有落差的位置”及“光影斑驳的湖面”的情况下,Segment嵌入形式如图5所示.

图5 Segment嵌入Fig.5 Segment embedding
3)Position嵌入.
输入BERT的文本属于时序数据,字词必须按照特定的顺序排列才能表达出正确的语义.
Position嵌入首先对输入序列中的各个位置赋予一个编号,编号唯一对应于Position嵌入中的某一行向量.在训练过程中,BERT会通过学习各个位置的向量表示来获取输入序列的顺序信息.
BERT的输入序列维度默认为512,即Position嵌入尺寸为(512,768).查找表中的行序号与输入序列中的位置编号一一对应.
4)合并表示.
以上提到了3种向量表示,其相关情况总结如表1所示.

表1 变量名及尺寸Table 1 Name and size of variable
2.3.2 门结构线性单元
定义GLU结构的输入为X=[x1x2···xn],则输出Y可由以下等式表示:
式中conv1(X)和conv2(X)表示输入经过两个形状相同、参数各异的一维卷积核后生成的两个特征矩阵.其中conv2(X)经过Sigmoid函数激活后,生成元素均在[0,1]区间的二维矩阵,该矩阵中的元素作为控制conv1(X)中信息流动的“门阀”与conv1(X)进行逐元素点乘.经过“信息过滤”的conv1(X)与输入相加,对输入信息进行复用,减少信息损耗,GLU结构图如图6所示.

图6 GLU结构图Fig.6 Structure diagram of GLU
2.3.3 滑窗结构
滑窗结构的输入为经BERT 层编码后的字向量Echar以WC(word-character)-LSTM[26]的方式引入词嵌入Eword的结果:在以词汇结尾的字符处拼接经过word2vec训练的词向量;有多个词汇以该字符结尾时将这些词向量进行平均;而无词汇以该字符结尾时则进行padding操作(“0”元素填充).
窗口尺寸设置为5,滑窗内每个元素的位置嵌入Eposition定义如表2所示.

表2 位置嵌入Table 2 Position embedding
综上,最终嵌入是按照字嵌入、词嵌入、位置嵌入的顺序进行拼接,可由下式表示:
滑窗在文本序列上以1字符的步长滑动,对窗口内字符序列对应的嵌入进行特征融合.这是通过在滑窗内计算中心元素与其他元素之间的注意力权值并对这些元素进行加权融合的.
滑动窗口的尺寸需要设置为奇数,以确保中心位置的元素存在.为确保滑窗滑动前后生成的嵌入数量一致,需要在文本序列头尾位置分别进行数量为npadding的padding操作将文本序列补全到特定的长度.令滑窗的尺寸为k,则npadding按照下式进行计算:
定义初始文本序列嵌入为X=[x0···xn],则对于序列中的字符嵌入xi,以其为作为中心元素的滑窗内元素分布情况为
滑窗内的注意力分值s可表示为
令模型中隐藏层的维度为dh,式(3)中定义的最终嵌入维度为dE,则上式中引入的3个可训练参数的尺寸定义为.由注意力分值归一化可得注意力权重αn,即
权重与对应嵌入相乘后进行拼接得到初始融合嵌入hconcat,再经过一个全连接层映射到隐层维度dh上,得到最终融合嵌入,表达式如下:
2.4 基于Neo4j的知识存储
Neo4j具备优于许多知识图谱构建工具的特点: 设计的灵活性、开发的便捷性及存储性能的优越性.
Neo4j的存储形式是图,这区别于常见的关系型数据库.图结构具备自然伸展的特性,这一点可以用来设计不通过索引遍历临近节点的算法: 以某个节点为起始节点,通过网状的连接关系快速获取临近节点.这种查询方式的优势是不受限于数据规模,因此,在知识图谱不断补全,数据不断增长的业务场景拥有较大优势.
图形界面的简洁性、数据可视化的直观性也是Neo4j的一大优点,结合以上提及的优点,采用Neo4j作为知识存储的工具.
3 实验结果与分析
3.1 数据与标注
注塑产品数据集基于对《精密注塑工艺与产品缺陷解决方案100例》和《注塑成型疑难问题及解答》手工整理,结合网络爬取文本筛选,标注形成.数据集总量为1555条文本,训练集与测试集按照4:1的比例进行划分(如表3).数据集中包含的关系类型有5种: “缺陷-现象”、“缺陷-参数原因”、“缺陷-参数方法”、“缺陷-非参数原因”、“缺陷-非参数方法”,各关系类型在数据集中出现的次数如表4所示.

表3 注塑产品缺陷训练集与测试集划分Table 3 Division of injection product defect training set and test set

表4 注塑产品缺陷关系类型分布Table 4 Distribution of defect relation types of injection products
图7为数据集样例,当识别出“缺陷-参数原因”关系时,将“缺料”中的“缺”标注为“B-SUB”,剩余部分标注为“I-SUB”;将“熔料温度太低”中的“熔”标注为“B-OB”,剩余部分标注为“I-OB”;非“subject”或“object”的部分全部标注为“O”.完整标注与关系类型标签拼接后输入实体识别模型.

图7 数据集样例Fig.7 Sample of dataset
为测试模型在通用领域数据集的命名实体识别效果,实验同时在人民日报数据集上展开,该数据集以1998年人民日报语料为对象,是得到人民日报社新闻信息中心许可的公开数据集.其中包含3种实体类型: LOC(地点名)、ORG(机构名)、PER(人名).各类型实体分布情况如表5所示.
3.2 实验设置
本实验硬件环境采用Intel i7-12700型号的CPU,NVIDIA GTX 3060型号GPU;编译环境为Python3.9,选用Pytorch框架,在模型中加入AdamW 优化器.各实验参数配置如表6所示.

表6 参数设置Table 6 Parameter settings
3.3 评价指标
知识抽取模型效果的评估标准主要包括准确率(precision,P)、召回率(recall,R)、F1值.具体公式如下:
3.4 结果与分析
在经典的BiLSTM(bidirectional long short-term memory)+CRF(conditional random field)模型中,LSTM增强了模型对长距离信息的感知能力,而双层LSTM叠加形成的BiLSTM从正反两个方向获取输入的文本时序特征向量,增强了对上下文信息的均衡获取能力,更好地捕获词汇在文本中表达的语义信息.CRF(条件随机场)接收经过BiLSTM编码的语义特征,通过训练转移矩阵与发射矩阵实现原始文本序列向标注序列的映射,达到抽取目标实体的目的.
本文所提出模型的创新点有两个方面: 一是将含注塑领域知识的原始文本和包含通识领域知识的人民日报数据集组合经Word2vec模型训练后生成词汇预训练向量,并将向量拼接在词汇在文本序列中的对应位置;二是引入滑窗结构,针对注塑领域缺陷解决方案文本表述规范的特点,加强了文本序列中单个字符对近距离上下文语义特征的捕获能力.
基于注塑领域数据集的实验中使用的对比模型均为实体识别模型,不对关系抽取模型作任何更改.实验结果如表7所示,以BERT+BiLSTM+CRF为基准模型,本文提出的模型准确率(P)提升了0.61%,召回率提升了0.72%,F1值提升了0.66%.如表7第3组实验结果所示,在基准模型中引入自注意力机制使得识别效果略有下降,这是因为自注意力机制的运算基于全局的文本特征,参数量较大,学习了更多的无效特征;如表7第2组实验结果所示,引入预训练词向量(+ew)使得输入的文本序列特征更为丰富,提高了模型的对领域词汇的识别能力,F1值提升了0.2%;由表7第4组实验结果可知,本文模型中引入的滑窗结构针对局部文本特征,参数量减小的同时加强了对近距离上下文特征的捕获,更适用于低资源、表述规范的领域数据集.实验中使用的所有模型的F1值曲线与损失值曲线分别如图8-9所示,图中曲线的变化均呈现快速收敛的趋势,这是由于小规模数据集所包含的语义特征并不丰富,模型在训练的过程中很容易学习到这些有限的特征.

表7 知识抽取效果Table 7 Effect of relationship extraction
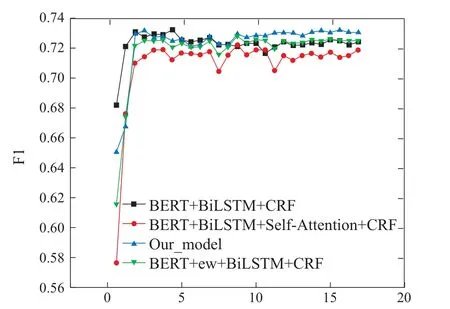
图8 F1值曲线Fig.8 Curves of F1

图9 loss值曲线Fig.9 Curves of loss
由于人民日报数据集中不存在关系标注,因此,基于该数据集的对比实验采用单独的实体识别模型.对比表8第3,4组实验结果可知,引入自注意力机制的模型获得了最佳效果,而所提出的模型并未取得较大优势.这是因为训练集数量充足,且目标实体在文本中的位置相对不规律,模型需要具备学习更复杂的位置特征的能力,而自注意力机制基于全局特征进行运算,相比于所提出模型有更强的学习能力.

表8 人民日报数据集实体识别效果Table 8 Entity recognition effect of People’s Daily dataset
4 总结与展望
本文研究了面向注塑产品缺陷的知识图谱全流程构建方法.以真实的注塑产品解决方案中的文本为数据源,通过专家归纳和总结文本中包含的概念分布,确定知识本体模型的结构,明确了非结构化文本中待抽取的实体类型和关系类型.依据关系和实体类型对原始语料进行标注,基于预训练模型,对专家知识进行学习,解决了面向小规模数据集的关系抽取和实体识别模型,实现了知识图谱的构建.
当前构建的注塑产品缺陷知识图谱包含3922个三元组,涵盖201个注塑产品缺陷种类.基于构建的知识图谱,面向实际注塑工业应用场景,实现了智能知识搜索、故障诊断及工艺卡解析等应用,作为示范项目依托博创“注塑云”进行了小范围的试点推广并取得了不错的效果.知识搜索可服务于作业工人的基础故障诊断技能培训及知识补充;故障诊断功能可实现面向故障的快速知识检索和解决方案确定;工艺卡解析功能将工艺卡表格中的信息自动解析并转化为结构化知识,自动更新知识图谱.为传统注塑的知识解析与抽取、管理与应用提供了一种知识自动化的应用模式.
未来的研究中,一方面可充分利用自然语言处理的技术,如构建面向特定工业领域的大规模预训练模型,进一步提升知识的自动抽取效果;二是基于生成式的自动问答技术,能够实现更优越的知识服务体验;三是可探索将注塑领域的知识图谱构建方法应用到其他领域,服务于智能制造,为工业4.0提供更多应用服务.
