基于指针标注的跨境民族文化实体关系抽取方法
2024-05-09杨振平毛存礼雷雄丽黄于欣张勇丙
杨振平,毛存礼,雷雄丽,黄于欣,张勇丙
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500;3. 昆明冶金高等专科学校,云南 昆明 650500)
0 引言
跨境民族是指随着社会历史的发展,源于同一族系下的民族成员生活在不同国家的民族,例如,中国傣族、缅甸掸族、泰国泰族、老挝佬族以及越南泰族均属于同一族系下的跨境民族群体,不同的民族进行文化交流并逐渐形成了跨境民族文化。跨境民族文化领域实体关系抽取的任务是从非结构化的跨境民族文化文本中抽取出饮食、文艺、建筑、节日实体和实体之间组成的关系。
目前,研究人员大多关注实体关系重叠问题,利用联合标注的方法解决实体关系重叠问题,例如Wei等人[1]提出了一种新型级联二进制标注实体策略的联合学习模型(A Novel Cascade Binary Tagging Framework for Relational Triple Extraction,CasRel),该框架预测句子中所有头实体,通过预测的头实体与对应的关系类型进行映射来预测尾实体,该模型较好地解决了实体关系抽取中的重叠实体关系问题。以上方法在通用领域实体关系抽取任务上已经取得了较好的效果,但是跨境民族文化领域的实体关系抽取任务相比通用领域还存在领域实体识别不准确、领域信息缺失以及关系重叠问题。
如表1所示,跨境民族文化文本中实体关系特征主要体现在单个实体重叠关系、实体对重叠关系以及多个实体对关系;文本中还存在大量的领域词语,如“浴佛节”“解夏节”“象脚鼓”等,这些词语使得文本的语义信息提取困难。跨境民族文化文本结构复杂,一段文本存在多个实体,实体对有多种不同的关系交叉互联。通用领域实体关系抽取模型对多实体、多关系文本进行抽取时,很容易错误匹配或者遗漏领域实体对,从而输出不完整的实体关系三元组,这也成为跨境民族文化实体关系抽取任务的挑战。
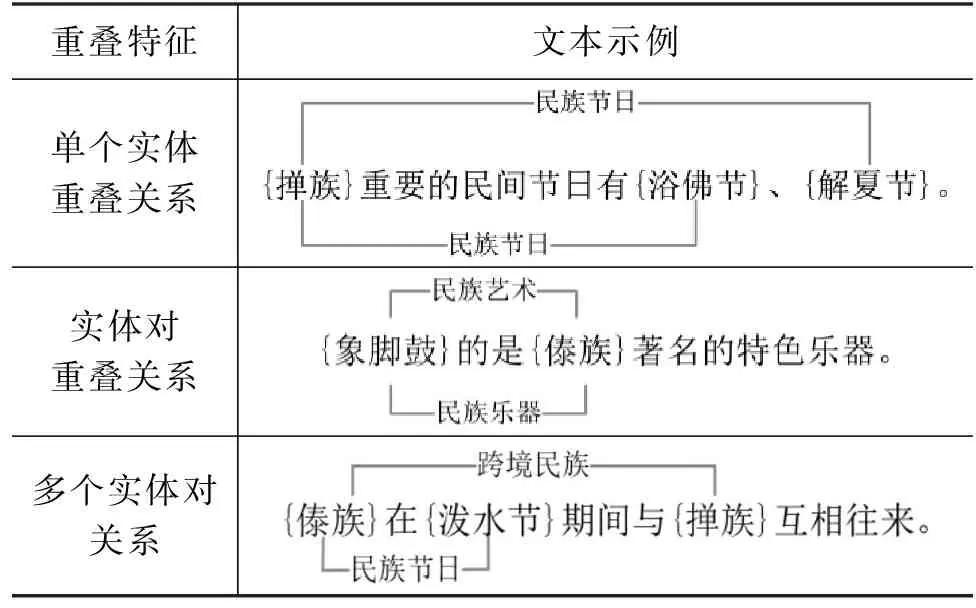
表1 文本重叠实体关系示例分析
针对实体关系抽取模型缺少领域信息造成上下文语义缺失、实体对存在关系重叠等问题,本文提出了基于指针标注的跨境民族文化实体关系抽取方法。本文主要贡献如下:
(1) 为了让模型能够学习到跨境民族文化领域特征表示,本文利用已构建的领域词典进行词向量训练,通过融入领域词典提取文本中的领域知识表示,进而增强文本领域特征。
(2) 通过Bi-LSTM[2]编码特征提取上下文语义信息,提升指针网络对底层实体预测的准确性。
(3) 采用分层的指针网络标注所有关系类型中的尾实体,将所有标注的头实体作为先验条件,通过多层指针网络依次对所有关系条件下标注头实体对应的尾实体。
利用跨境民族文化领域实体关系抽取方法获取领域信息,对于推动跨境民族文化研究工作具有重要的价值,可以有效地补充结构化的领域信息并发现一些关联关系,对于领域知识库的构建、信息检索等任务具有支撑作用。
1 相关工作
近年来,深度学习方法逐渐应用在通用领域和特定领域的实体关系抽取任务中,当前主流的方法是基于流水线和联合学习的实体关系抽取方法。
Zhong等人[3]提出了简单的流水线模型学习实体和关系的不同上下文表示、融合关系模型中的实体信息和整合全局上下文的重要性,流水线模型复杂度低,但是会造成错误传播问题。2016年Miwa等人[5]提出了一种端到端的实体关系联合抽取模型,通过学习句法树中不同节点之间的关系来进行关系抽取,该模型忽略了标签之间的长依赖关系问题。2017年Zheng等人[5]提出用层次级神经网络模型抽取实体与关系,通过Bi-LSTM层对输入共享词嵌入层进行编码,模型在训练时会更新共享参数来实现实体和关系抽取任务之间的关联。2017年Zheng等人[6]提出了基于联合标注策略的实体关系联合抽取方法,把实体标注和关系分类任务转换为序列标注任务,该模型不能够对重叠实体关系进行抽取。2018年Zeng等人[7]提出采用copy机制的实体关系三元组抽取方法,该方法实现了参数共享,解决了句子中单个实体关系重叠问题。实体关系联合抽取有效地解决了流水线模型中错误传播问题,但是在解决实体关系重叠问题上有待提升。
表格填充方法[8-10]在联合实体关系抽取任务中得到广泛应用,表格填充方法能够更直接表达实体关系直接的联系,有助于重叠实体关系的抽取。2019年Fu等人[11]提出了GraphRel模型用于解决实体关系重叠的问题,该模型利用图卷积网络(Graph Convolutional Network, GCN)[12]联合学习实体和关系,通过关系加权GCN考虑实体和关系之间的交互以更好地提取关系类型。2020年Wang等人[13]提出了TPLinker模型,该模型通过阶段联合提取实体和重叠关系,引入了一种新的标记方案对每种关系类型下的实体对的边界进行标注并对齐,它弥合了训练和推理之间的差距。2021年Zheng等人[14]提出了PRGC模型,设计一个预测潜在关系的组件,将实体提取限制在预测的关系子集上,然后用特定关系的标签处理实体对之间的重叠问题。
在跨境民族文化领域中,毛存礼等人[15]提出一种融合领域知识图谱的跨境民族文化分类方法,利用人工构建的领域知识库进行领域建模。在生物医学领域,曹明宇等人[16]提出了一种基于神经网络的药物实体与关系联合抽取方法,将药物实体及关系的联合抽取转化为端对端的序列标注任务进行药物实体与关系联合抽取,利用药物与药物之间的领域交互信息为模型提供领域知识。陆亮等人[17]在对话领域提出融入交互信息的实体关系抽取,使用交叉注意力机制来捕获对话交互过程中的关联信息。
以上的方法为解决跨境民族文化实体关系抽取任务中存在的实体关系重叠问题和领域问题提供了较好的思路,但是跨境民族文化领域文本中含有较多的领域词汇,造成模型获取文本语义信息困难。
2 跨境民族文化领域词典构建
针对跨境民族文化文本领域信息缺失的问题,本文构建了跨境民族文化领域词典。通过预训练语言模型训练词向量,本文一共收集了5 360个关于跨境民族文化的领域词语。部分领域词语如表2所示,这些领域词语边界模糊,导致现有的模型无法对领域信息做正确的语义表征。
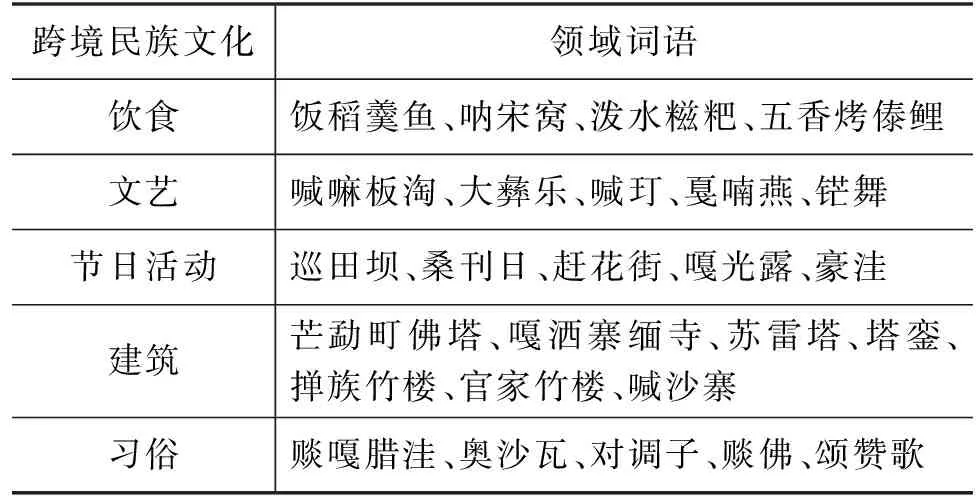
表2 跨境民族文化领域词语示例
基于切分的领域词语通过统计多个字符组合得到的字符串的频率, 并设置合适的阈值来对新词进行发现,定义的凝固度计算如式(1)所示。
(1)
其中,a、b、c是语料中相邻的字符,α表示预先设置的凝固度阈值;多个字符组成的词语一般设置比较高的凝固度阈值,防止如“葫芦笙”之类的词被错误切分为“葫芦”和“笙”。
3 基于指针标注的跨境民族文化实体关系抽取模型
本文提出了基于指针标注的跨境民族文化实体关系抽取方法,包含了四个部分: 领域词典信息特征融合层、Bi-LSTM特征编码层、基于指针网络的头实体预测层以及关系条件下的尾实体预测层,其模型架构如图1所示。
3.1 融入领域词典信息的特征表示
跨境民族文化领域中存在大量的领域词汇,在没有外部知识辅助的情况下,实体关系抽取模型无法有效获取语义信息,因此本文将领域词典信息融入模型中,对输入文本和领域词典进行特征编码表示,增强模型对跨境民族文化领域语义的表示能力。
字符特征编码使用BERT[18]的预训练模型进行字符向量表征,输入文本序列X={x1,x2,…,xn},利用BERT模型中的多头注意力机制计算更新字符向量矩阵,如式(2)所示。
G=BERT(X)
(2)
其中,G表示文本字符向量矩阵,BERT(·)为预训练语言模型。
采用CNN编码器提取领域词典信息特征编码表示,其目的是提取领域词典中词语信息的语义知识。如图2所示,利用领域词典对文本进行分词,然后匹配预训练词向量,得到领域词向量矩阵E。
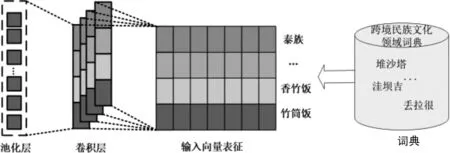
图2 领域词典信息特征编码表示
通过CNN[19]网络对词向量进行卷积操作,提取领域词典信息特征,通过设置卷积核大小来提取文本的n-gram特征,如式(3)所示。
oi=W·E[i:i+h]
(3)
其中,E表示领域词向量矩阵,W为权重矩阵。利用K个不同的卷积核获取多个特征表示,获得K维的n-gram特征向量矩阵,通过使用最大池化层汇聚,最后输出最终的编码表示,如式(4)所示。
(4)
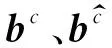
将得到的字符向量表示和领域词典信息表示进行融合,得到融入词典信息的文本表征,如式(5)所示。
D=[G;Z]
(5)
其中,G为式(2)中得到的字符向量表示,Z为式(4)得到的领域词典信息表示。
3.2 融入领域特征信息的上下文特征编码
为了提升模型预测头实体的效果,本文采用Bi-LSTM网络层提取上下文信息表征,如式(6)所示。
(6)
其中,σ(·)表示sigmoid激活函数,Wi、Wf表示训练参数矩阵,bi、bf、bc表示偏置向量,tanh(·)表示非线性函数。将D={d1,d2,…,dn}输入到Bi-LSTM中提取上下文特征,新的隐藏状态hi由上一次的隐藏状态hi-1和当前的输入di计算获取,如式(7)所示。
(7)
3.3 基于指针网络的头实体标注
本文采用指针网络[20]对头实体的位置进行标注,需要标注文本中所有头实体片段以确保后续在所有关系条件下的尾实体标注的准确性。
如图1所示,将Bi-LSTM输出的特征向量hi输入到两个指针网络层中,预测跨境民族文化文本中所有头实体的开始位置概率和结束位置概率,如式(8)、式(9)所示。
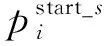
相邻指针检测需要符合开始位置在前、结束位置在后的原则,这样的策略能够保持实体标注的完整性。如果句子中存在多个头实体,只有满足开始位置和结束位置自然连续性,才能被正确检测为给定的句子中实体跨度,从输入文本中标注头实体的概率如式(10)所示。
(10)
3.4 关系条件下的尾实体指针标注
针对跨境民族文化实体关系抽取中存在的实体关系重叠问题,本文采用多层指针网络标注来抽取实体关系三元组。如图3所示,文本“泰族著名的香竹饭又称竹筒饭。”中存在两个实体关系重叠的三元组,模型在“特色饮食”关系类型下标注尾实体“香竹饭”的开始位置和结尾位置;在“别名”关系类型下标注尾实体“竹筒饭”的开始位置和结尾位置。
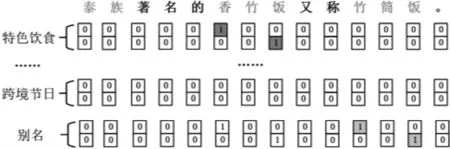
图3 重叠实体关系抽取示例
通过头实体对应的特征向量融入到Bi-LSTM输出的特征向量中以增强模型整体的依赖性,更好地标注关系对应的尾实体位置。输入向量是融合了已标注的头实体向量,预测所有头实体对应关系下的尾实体开始位置概率和结束位置概率,如式(11)、式(12)所示。
(11)
(12)
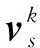
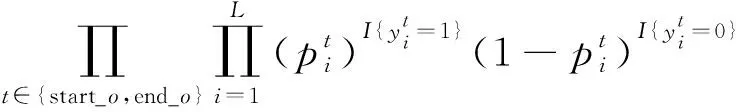
(13)
4 实验分析
4.1 跨境民族文化实体关系抽取数据集
本文根据领域特点定义了17种关系类型,包括跨境节日、民族歌舞、宗教信仰、建筑特色、民族乐器、跨境民族、包含、民族节日、活动和别名等关系。如图4所示,一共构建了18 000条高质量的实体关系数据集,统计了训练集、验证集和测试集中文本数量、实体关系三元组数量以及重叠实体关系的数量。

图4 数据集统计
4.2 实验参数设置
实验使用Adamax优化器来优化所有训练的参数,实验具体参数设置如表3所示。

表3 模型参数的设置
4.3 实验评价指标
本文的评价指标是通过精确率(Precision)、召回率(Recall)和F1值来对模型进行评估,如式(14)~式(16)所示。
其中,TP表示模型输出的正确三元组数量,FP表示模型输出的错误三元组数量,FN表示模型未能预测的正确三元组数量。
4.4 实验结果与分析
为了验证本文方法有效性,设计了一组对比实验;设计了两组消融实验,分别为模型中不同编码层对模型效果的影响和卷积层数量对领域词典信息抽取的影响。
实验一: 不同方法实验结果对比
为了验证本文方法的有效性,与基线方法进行了对比,四种对比方法如下:
(1)GraphRel模型: 2019年Fu等人[11]提出了基于图卷积网络的实体关系抽取方法,它将实体对分割为几个词对,考虑对所有的词对进行预测的实体关系抽取方法。
(2)TPLinker模型: 2020年Wang等人[13]利用实体与关系的交互信息和依赖关系,提取出不受偏差影响的各种重叠关系的联合模型。
(3)PRGC模型: 2021年Zheng等人[14]设计的一个预测潜在关系的模块,将实体提取限制在预测的关系子集上,然后用特定关系的标签处理实体对关系重叠的问题。
(4)CasRel模型: 2020年Wei等人[1]提出了基于级联二进制标注的实体关系三元组抽取方法,通过标注头实体及对应关系类型下的尾实体实现实体关系抽取方法。
(5)本文方法: 首先基于BERT生成字符向量表征,通过CNN特征编码器对领域词向量进行编码,然后融入到字符向量表征中增强领域信息,通过LSTM对特征向量进一步提取上下文特征,最后利用指针网络标注实体关系的方法。
如表4所示,本文方法F1值达到了82.50%,相较于其他三个对比模型都有一定的提升,本文方法在字符向量表征中融入了领域知识,将领域信息表示更好地融合到了模型中。GraphRel模型将字符向量与词性表征相融合后输入到Bi-LSTM中提取信息,通过GCN对句法依赖树编码,实验效果取决于训练过程中依赖分词的质量和词性标注的质量,在特定领域上的实体关系抽取效果相对较差。PRGC和TPLinker模型效果相对较好,为了避免偏差影响模型效果,使用了复杂的解码器,导致稀疏的标签提取能力较弱。
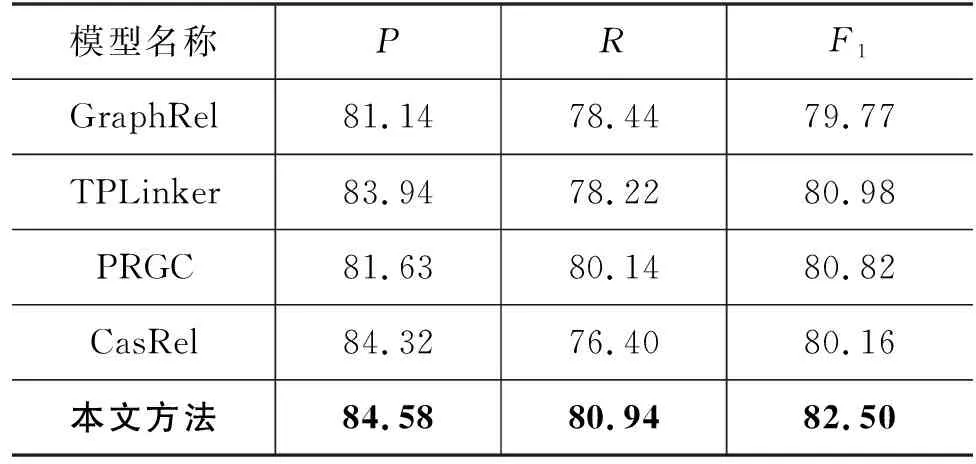
表4 对比实验结果 (单位: %)
本文方法相比于CasRel模型效果提升了2.34%,CasRel模型通过BERT直接生成词向量表征,然后通过二进制标注器进行头实体标注,在预测所有头实体时不准确,使得融入头实体向量带来误差传播的问题。本文方法效果优于CaseRel模型的主要原因是本文方法在BERT生成字符向量的基础上加入了CNN编码器提取领域信息之后融入到了字符向量中增强领域信息,然后加入Bi-LSTM进一步提取上下文语义信息,提升了指针网络标注头实体位置的正确性。
实验二: 不同编码层的实验结果对比
为了验证本文方法融合不同编码层的有效性,设计了去除领域词典融入层、去除CNN编码层以及去除LSTM特征提取层的消融实验,其他层保持不变进行模型训练。
如图5所示,去除领域词典融入层的实验相较于本文方法F1值下降了2.29%,仅仅是字符层面的表征,没有词语层面的信息融合,模型在缺少领域词典信息的表示后,会造成模型对文本中的领域词汇编码能力下降,不能有效地编码领域特征表示。
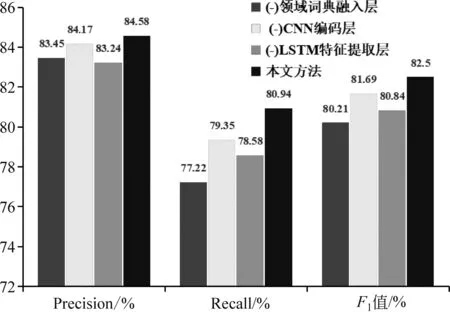
图5 不同编码层实验结果
对于去除CNN编码层的实验,相较于本文方法实验,F1值下降了0.81%,领域词典信息表征未通过CNN编码导致特征表示融合时无法融入重要的特征,使得模型无法有效地利用领域词典信息,表明CNN对领域词汇局部特征提取的有效性。对于去除LSTM特征提取层的实验,相较于本文方法F1值下降了1.66%,表明Bi-LSTM能够有效地提取特征表示中的长短期时间步的依赖信息,即提取文本上下文的语义信息。本文方法将BERT预训练模型所表示的字符向量和领域词典信息向量进行融合, 通过CNN编码器和Bi-LSTM特征提取层后得到的特征表示对模型效果有明显的提升。
实验三: 卷积层数对领域词典信息提取的影响
为了验证CNN卷积层数对领域词典信息提取的影响,本文设计了卷积层数分别为2、3、4、5层进行对比,选择合适卷积层数得到集合的最优组合,使得模型效果最佳。
如表5所示,当卷积层数为2时,卷积网络提升感受野的能力不足,造成模型性能提升不大;卷积网络在参数规模相同的情况下,卷积层越小,计算复杂度就越低。当卷积网络的层数为3时,模型达到最佳效果;在第3层后,随着层数的增加,模型的整体性能均有所下降。当卷积层数为5层时,准确率有所提高,但是整体F1值比3层的效果差。
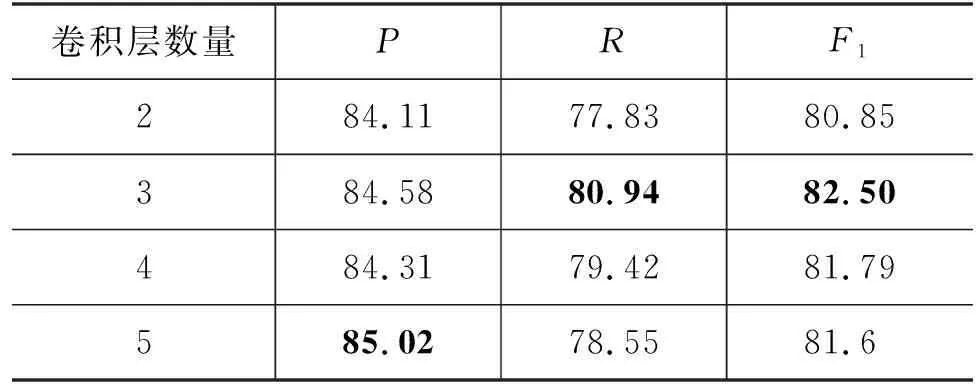
表5 卷积层数量对实验的影响 (单位: %)
5 实例分析
为了验证本文方法在跨境民族文化实体关系抽取上的效果,在本节中选择了两个实例进行分析,将基线CasRel模型方法和本文方法进行了对比。
如表6所示,在第一个实例中,存在重叠的头实体“傣族”,CasRel模型将三元组中对应的尾实体错误标注为“旱傣和水傣”。在第二个实例中,将头实体和对应的关系都抽取错误,这是由于基线模型在缺乏领域信息的辅助下将“泼水节”实体错误标注为“泼水”,导致实体关系抽取错误。本文方法在融入领域词典信息后能够更准确地标注领域实体并正确输出重叠实体关系三元组。

表6 实例分析
6 结论
针对跨境民族文化实体关系抽取任务中存在的实体关系重叠和领域信息缺失问题,本文提出了基于指针标注的跨境民族文化实体关系抽取方法,在字符向量表示中加入领域信息增强上下文表征能力,利用多层指针网络标注方法提升重叠实体关系抽取的效果。实验表明,本文方法在跨境民族文化实体关系抽取任务上有一定的性能提升。
