改进CycleGAN的素描头像到现实头像转换
2024-05-07林国军兰江海罗春兰
廖 振, 林国军, 胡 鑫, 游 松, 兰江海, 周 旭, 罗春兰
(四川轻化工大学 自动化与信息工程学院, 四川 宜宾 644000)
0 引言
在偏远地区,由于监控设备的覆盖率低等因素,无法采集到犯罪嫌疑人的视频信息.因此,警方往往会根据目击证人的描述,请法警绘制犯罪嫌疑人的素描头像.由于素描头像与现实头像模态差异大,若直接通过素描头像搜寻犯罪嫌疑人既耗时耗力,还可能会遗漏掉重要的案件线索.因此,将素描头像转换为现实头像,对警方初步锁定犯罪嫌疑人身份具有重大的现实意义.
素描头像转换为现实头像,归属于异质人脸图像合成的一个分支.当前,异质人脸图像合成主要有两种方法,分别是基于特征表达的传统合成方法和基于深度学习的方法.
基于特征表达的传统合成方法.通过将图像表达为许多特征块,对特征块进行特定的组合,就可以实现异质人脸图像的合成.以主成分分析方法[1]为例,主成分分析方法将人脸图像表达为特征矩阵与特征向量.因此,可以利用特征向量与特征矩阵的特定组合实现异质人脸图像的合成.然而,基于特征表达的传统合成方法需要成对的数据集和受控条件下拍摄的照片.
基于深度学习的方法.近年来,由于计算机计算性能的大幅提升,深度学习又一次成为各领域的研究热点.Zhang等[2]提出了采用由6个卷积层组成的网络来实现图片的跨域转换,但该网络转化的图片出现了模糊和伪影等问题.生成式对抗网络(generative adversarial network,GAN)[3]、变分自编码器 (variational auto-encoder,YAE)[4]和U-Net自编码器[5]等生成模型,因强大的生成能力在图像生成领域取得了巨大的成功,有效弥补了传统方法的不足.Pix2Pix[6]在图像生成领域取得了不错的效果,但Pix2Pix生成的图像趋于模糊化.原因是Pix2Pix为单一网络转换结构,无法保证转换前后图像在结构上的一致性.CycleGAN是Zhu等[7]提出的一种新型的生成对抗网络模型,该模型包含两个生成对抗网络的循环重建过程.与其他的模型相比,CycleGAN可以将图像从一个域映射到另一个域,再将生成的图像映射回来.这种双映射结构的网络能很好地保持生成图像的结构.
U-Net自编码器由编码器、解码器和跳层连接组成,具有对称的“U”形结构.编码器对输入图像压缩编码,解码器将编码器编码得到的特征上采样实现图像的转换.位于编码器与解码之间的跳层连接,将编码器中的低级特征与解码器中的高级特征采用通道连接的方式进行特征融合.这种融合方式能较好地保留转换前后图像所具有的共同特征,因此能极大地改善生成图像的质量.文献[8]指出,编码器在对输入图像进行压缩编码时,会导致一部分人脸特征丢失.Gatysl等[9]认为利用转置卷积进行上采样,会导致生成的图像具有较多的合成痕迹和变形细节.
综上,本文在CycleGAN和U-Net自编码器的基础上,提出了一种素描头像到现实头像的转换方法.首先,在U-Net自编码器的基础上增加了一个人脸特征提取器,以增强模型对输入图像的特征提取能力.其次,对转换头像与真实头像添加图像空间损失,以提升转换头像的质量.文献[10]指出,风格损失可以有效地解决由转置卷积上采样时引起的合成痕迹和变形细节.最后,对转换头像与真实头像添加风格损失,进一步提升转换头像的质量.
1 方法
1.1 改进模型的整体网络框架
改进模型的整体网络框架如图1所示.设真实的现实头像组成的集合为X,满足的分布为P(x),真实的素描头像组成的集合为Y,满足的分布为Q(y).整个网络由两个生成器(生成器G和生成器F)和两个鉴别器(鉴别器DX和鉴别器DY)组成.真实的现实头像xi经生成器G转换后为G(xi),G(xi)再经生成器F转换后为F(G(xi)),F(G(xi))为xi的重构图像.真实的素描头像yi经生成器F转换后为F(yi),F(yi)再经生成器G转换后为G(F(yi)),G(F(yi))为yi的重构图像.鉴别器DX鉴别真实的现实头像xi和转换的现实头像F(yi),鉴别器DY鉴别真实的素描头像yi和转换的素描头像G(xi).
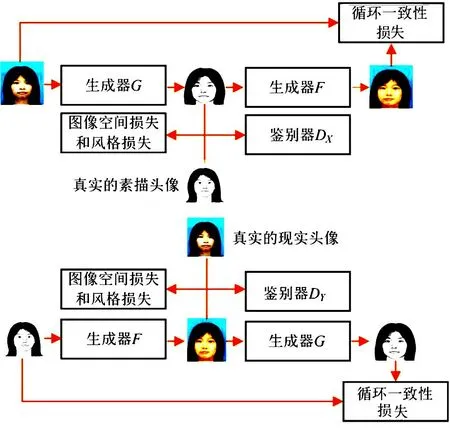
图1 改进模型的整体网络框架
1.2 U-Net自编码器优化
优化后的U-Net自编码器的网络结构如图2所示.改进模型的生成器为优化后的U-Net自编码器.人脸特征提取器提取输入图像后,提取出来的特征有3个通道;被融合的特征有64个通道,由于采取通道连接的方式进行特征融合,因此融合后的特征具有67个通道;最后对融合的特征做进一步解码处理.
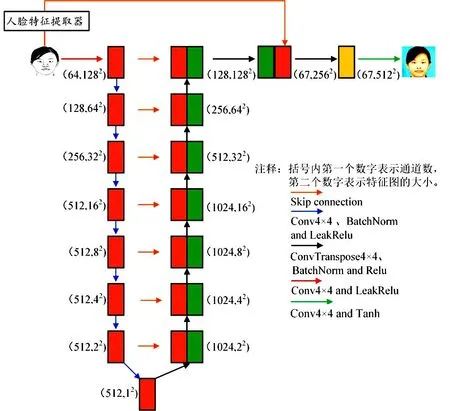
图2 优化后的U-Net自编码器的网络结构
1.2.1 人脸特征提取器设计
人脸特征提取器网络结构如图3所示.整个网络共有6层,自下而上分别为第1层、第2层、第3层、第4层、第5层和第6层.人脸特征提取器自右而左总共有4个特征提取分支,分别为第1特征提取分支、第2特征提取分支、第3特征提取分支和第4特征提取分支.
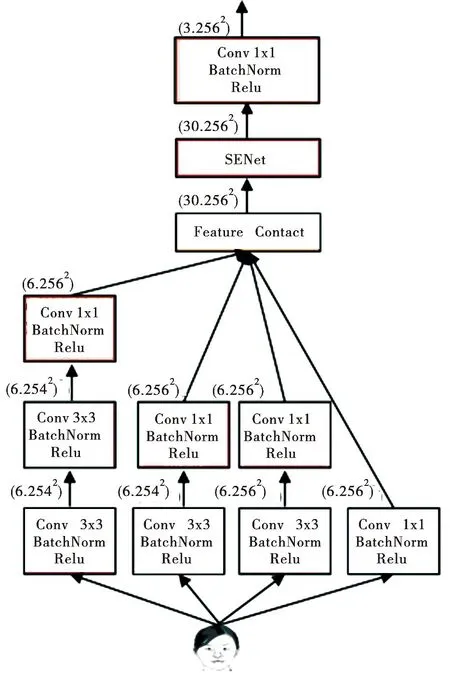
图3 人脸特征提取器的网络结构注:括号内第一个数字表示通道数,第二个数字表示特征图的大小.
第1特征提分支、第2特征提取和第4特征提取分支都是由卷积块(普通卷积→批量归一化(BatchNorm)→Relu激活函数)组成.第3特征提取分支由最大池化层和卷积块组成.第1特征提取分支由3个卷积块组成,该分支提取特征的语义信息丰富.第2特征提取分支由2个卷积块组成,该分支提取的特征语义信息相对丰富且细粒度较好.第4特征提取分支由1个卷积块组成,该分支提取的特征细粒度好,因此能很好地捕获图像的细节信息.第3特征提取分支由1个最大池化层和1个卷积块组成,该分支能很好地提取图像的纹理信息.将以上4个特征提取分支提取的特征采用通道连接的方式进行融合,因此融合的特征含有丰富的语义信息、细节信息和纹理信息.对融合的特征嵌入(squeeze-and-excitation networks,SENet)[11]注意力机制.SENet注意力机制是一种通道注意力机制,在模型的训练过程中,能为特征的各通道分配权重值,从而使模型达到更好的效果.最后,再采用1×1的卷积块降低特征的通道维数.
1.3 鉴别器
普通GAN的鉴别器将输入图像映射成一个评价值,该值是对整幅图像进行评价,即输入图像是否为真实图像的概率.本文鉴别器采用的是PatchGAN[6],网络结构如图4所示.PatchGAN将输入图像映射为一个30×30的矩阵,矩阵中的每一个值对应输入图像的某一区域是否为真实图像的概率,最后对矩阵中的元素求均值,将均值作为判定结果.因此,PatchGAN能很好地把控图像的局部特征,从而提升转换图像的质量.
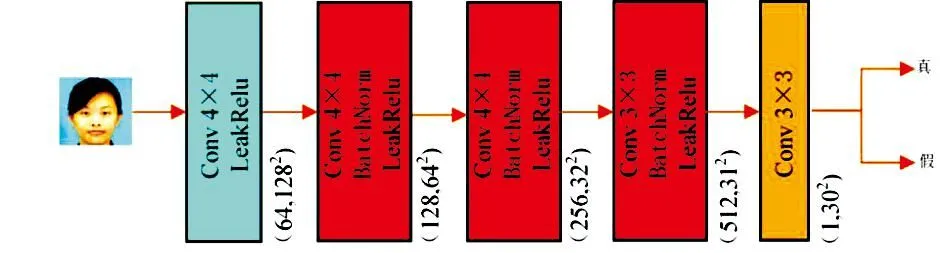
图4 鉴别器的网络结构注:括号内第一个数字表示通道数,第二个数字表示特征图的大小.
1.4 损失函数
1.4.1 转换头像与真实头像的图像空间损失
对转换头像和真实头像添加图像空间损失,图像空间损失的计算式为:
Lxy=λxyxi~P(x)‖G(xi)-yi‖1,
(1)
Lyx=λyxyi~Q(y)‖F(yi)-xi‖1,
(2)
式中:λxy和λyx为权重系数.
1.4.2 转换头像与真实头像的风格损失
采用在ImageNet数据集[12]上预训练好的VGG-19网络作为特征提取网络,输出特征提取网络的relu2_2层、relu3_4层、relu4_4层和relu5_2层的特征.Φ1(.)表示relu2_2层映射的特征,Φ2(.)表示relu3_4层映射的特征,Φ3(.)表示relu4_4层映射的特征,Φ4(.)表示relu5_2层映射的特征.(Φj(.))T(Φj(.))表示由Φj(.)构造的Gramm矩阵.因此,风格损失的计算式为:

(3)

(4)
式中:λs_x和λs_y为权重系数.
1.4.3 生成对抗损失
文献[13]指出,采用最小二乘损失作为生成对抗损失,能使模型的训练过程更加稳定.因此,生成对抗损失计算式为:
Lc_gan(G,F,D)=Lgan(G,DY,X,Y)+Lgan(F,DX,Y,X)=
Exi~P(x)[log(1-DX(G(xi)))]+
Eyi:Q(x)[log(1-DX(F(yi)))].
(5)
1.4.4 循环一致性损失
集合X中的任意一张图像xi,与其重构图像F(G(xi))应尽可能一致.同理,集合Y中的任意一张图像yi,与其重构图像G(F(yi))也应尽可能一致.因此,循环一致性损失的计算式为:
Lcxc=λcxcxi~P(x)‖F(G(xi))-xi‖1,
(6)
Lcyc=λcycyi~Q(x)‖G(F(yi))-yi‖1,
(7)
式中:λcxc和λcyc为权重系数.
1.4.5 本体映射损失
对于集合X中的任意一张图像xi,经生成器F转换后应与xi尽可能一致.同理,对于集合Y中的任意一张图像yi,经生成器G转换后也应与yi尽可能一致.因此,本体映射损失的计算式为:
Lxc=λxcxi~P(x)‖F(xi)-xi‖1,
(8)
Lyc=λycyi~Q(x)‖G(yi)-yi‖1,
(9)
式中:λxc和λyc为权重系数.
1.4.6 改进后模型的总损失函数
综上所述,改进后模型的总损失函数计算式为:
Ltotal=Lc_gan+Lcyc+Lcyc+Lyx+
Lxy+Lyc+Lxc+Lsx+Lsy.
(10)
2 实验设置、结果与分析
为验证改进模型的有效性,在CUHK数据集和XM2VTS数据集进行了不同模型(Pix2Pix、CycleGAN、BicycleGAN[14]和ComboGAN[14])的对比实验.
2.1 数据集介绍
CUHK数据集中有188对素描人脸头像.其中88对为训练集,100对为测试集.XM2VTS数据集中有295对素描人脸头像.其中100对为训练集,195对为测试集.将以上图像裁剪后调整到256×256.
2.2 实验设置
2.2.1 实验环境设置
实验在windows10系统环境下进行.GPU为NVIDIA GeForce RTX 3060,显存大小为12 GB;CPU为Intel(R)Core(TM)i7-4770;采用pytorch的框架进行训练和测试.
2.2.2 实验参数设置
在CUHK数据集和XM2VTS数据集训练时,批处理大小均设置为1,训练时均迭代200轮.在前100轮训练时学习率均设置为0.000 2,在后100轮训练时学习率从0.000 2线性衰减到0,均采用Adam优化器进行训练.在CUHK数据集训练时损失函数中各参数取值为:λcyc和λcxc均取6,λyc和λxc均取0.5,λxy和λyx取2,λsx和λsy均取200.在XM2VTS数据集训练时损失函数中各参数取值为:λcyc和λcxc均取5,λyc和λxc均取0.5,λxy和λyx均取1.5,λsx和λsy均取100.
2.3 实验结果评估
2.3.1 定性实验评估
图5中前两行为各模型在CUHK测试集上转换的现实头像,第三行和第四行为各模型在XM2VTS测试集上转换的现实头像.可以清楚地看出:改进模型转换的现实头像较其他模型转换的现实头像更清晰,与真实的现实头像更相似.
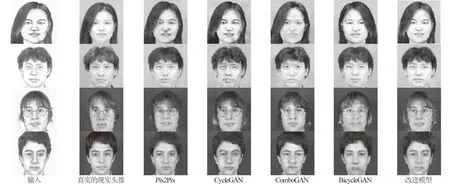
图5 各模型在CUHK测试集和XM2VTS测试集上转换的现实头像
2.3.2 定量实验评估
FID(fréchet inception distance)[3]是一种用于评估生成图像和真实图像分布差异的指标.FID值越小,表明生成图像与真实图像越逼真.
Rank-k[15]是人脸识别广泛应用的一个评价指标.现以素描头像的识别为例对其进行说明.设素描头像有m张,真实的现实头像也为m张,其中素描头像与真实的现实头像一一对应.真实的现实头像组成人脸数据库,对于每张输入素描头像,采用Dlib[16]库中的人脸识别模型提取输入图像与人脸数据库中的图像,得到每张图像的特征向量.然后比对输入图像的特征向量与人脸数据库中每张图像的特征向量,得到与人脸数据库中每张图像的相似度.若与输入图像最相似的前k个人脸中找到与之对应的现实头像,则yik记为1,否则yik记为0.由此,Rank-k的计算式为:
(11)
通常来说,在Rank-5以内的数据较准确,所以主要对比Rank-1到Rank-5的识别率.
表1总结了各模型将CUHK测试集中的素描头像转换成现实头像后现实头像的性能指标.同时,表1也总结了各模型将XM2VTS测试集中的素描头像转换成现实头像后现实头像的性能指标.由表1可知,在两个数据集上均满足改进模型转换的现实头像的FID值最小、Rank-1值最大.从而证明了改进模型转换的现实头像更逼真,人脸识别率更高.
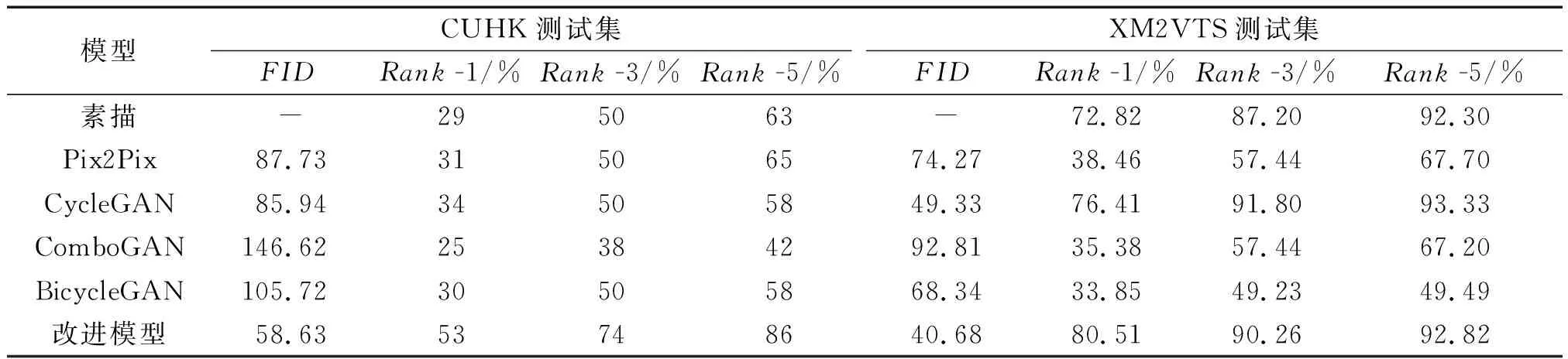
表1 CUHK数据集和XM2VTS数据集的性能评价指标
各模型将CUHK测试集中的素描头像转换成现实头像后,现实头像的人脸识别率如图6所示;将XM2VTS测试集中的素描头像转换成现实头像后,现实头像的人脸识别率如图7所示.由图6可知,改进模型转换的现实头像的人脸识别率曲线均高于其他模型,进一步证明了改进模型转换的现实头像的人脸识别率更佳.由图7可知,虽然改进模型转换的现实头像的人脸识别率曲线自Rank-1后略低于或与基础模型转换的现实头像的人脸识别率曲线持平,但改进模型转换的现实头像的Rank-1最大,因此Rank-1在实际中更具应用价值.
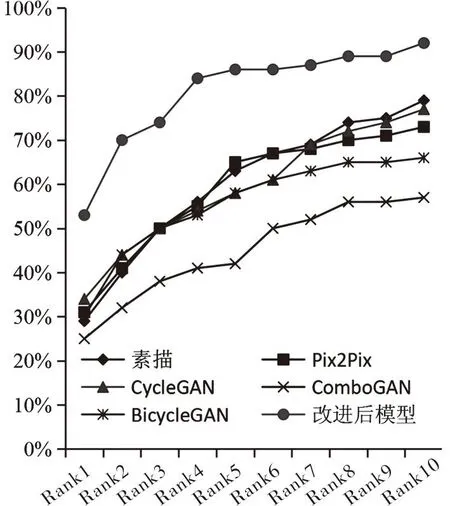
图6 各模型在CUHK数据集上人脸识别率
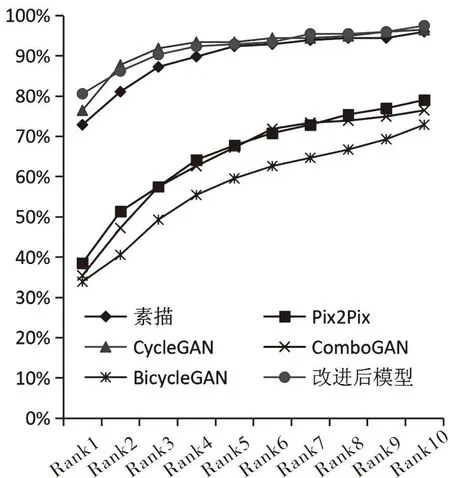
图7 各模型在XM2VTS数据集人脸识别率
2.4 消融实验
为验证人脸特征提取器、图像空间损失和风格损失对现实头像转换的有效性,在CUHK数据集做了消融实验.消融实验的实验组设置为:基础组为CycleGAN;第一组在基础组的基础上增加了一个人脸特征提取器;第二组在第一组的基础上添加图像空间损失;第三组在第二组的基础上添加风格损失,其中第三组为改进后的模型.
将各对照CUHK测试集中的素描头像转换成现实头像后现实头像的性能指标如表2所示.

表2 CUHK数据集的性能评价指标
由表2可知:第一组转换的现实头像的FID值较基础组下降了11.27,Rank-1较基础组提高了10%;第二组转换的现实头像的FID值较第二组下降了15.95,Rank-1较第二组提高了6%;第三组转换的现实头像的FID值较第一组下降了0.09,Rank-1较第一组提高了3%.综上,人脸特征提取器、图像空间损失和风格损失均可使转换的现实头像更逼真、人脸识别率更高.
各对照组将CUHK测试集中的素描头像转换成现实头像后,现实头像人脸识别率如图8所示.第一组转换的现实头像的人脸识别率曲线在基础组的上方;第二组转换的现实头像的人脸识别率曲线在第一组的上方;第三组转换的现实头像的人脸识别率曲线在第二组的上方.进一步证明了人脸特征提取器、图像空间损失和风格损失均可提高人脸识别率.

图8 各对照组在CUHK数据集上人脸识别率
消融实验的效果图如图9所示.基础组转换的现实头像视觉质量较差,面部出现了模糊;第一组转换的现实头像较基础组而言,视觉质量明显改善;第二组转换的现实头像量较第一组而言,无明显视觉差异;第三组转换的现实头像较其他对照组而言,视觉质量明显改善.

图9 在CUHK数据集上的消融实验效果图
3 结论
针对当前由素描头像转换的现实头像不够逼真和人脸识别率不高的问题,本文提出了一种由素描头像到现实头像的转换方法.首先,在U-Net自编码器的基础上增加了一个人脸特征提取器,增强了模型对特征的提取能力.其次,通过添加转换头像与真实头像的图像空间损失和风格损失,进一步提升了转换头像的质量.实验结果表明:改进模型转换的现实头像视觉质量更好,客观评价指标也更优.
为改善由转置卷积上采样时带来的转换的图像具有较多的合成痕迹和变形细节,本文对转换头像添加了风格损失.在计算风格损失时,采用了VGG-19网络提取图像的特征,该网络提取图像特征较慢,导致整个模型的训练时间较长.未来可考虑用其他预训练好特征提取网络来替换VGG-19网络,以此缩短模型的训练时长.也可考虑设计新的上采样模块替换转置卷积.
