大型施工机械监管系统智能视频分析模型研究
2024-05-07郑相波姚国栋史方圆廖炜炼马清志
郑相波,姚国栋,史方圆,廖炜炼,马清志
(1.上海东华地方铁路开发有限公司,上海 200040;2.上海上铁互联信息技术有限公司,上海 200040;3.苏州大学 计算机科学与技术学院,苏州 215031)
随着我国铁路的快速发展,各类建设工程规模不断扩大。为应对施工人员多、设备物资分散、管理作业流程琐碎的情况,采用传统的人工巡视、手工纸质记录的工作方式,已无法满足大型项目管控的要求。在涉及大型施工机械的工地现场安全管理方面,存在现场情况复杂多变、施工队安全作业不规范、现场监理人员履职不到位等情况,尤其是在对入场的大型施工机械尺寸、型号的判定,以及机械安全边界入侵的预警等方面,存在安全隐患,且需要耗费大量人力。因此,亟需利用信息化手段,建设一套智能监管系统,解决建设工程中存在的“监管力度不强,监管手段落后”等难题。
众多学者针对上述情况进行了研究,刘祥敏[1]从管理角度提出针对临近铁路营业线大型机械设备施工安全的监管对策,涵盖落实安全监管制度、提高施工机械操作人员安全意识等,但缺乏从技术层面提升安全监管的有效措施;朱涨鑫等人[2]基于超宽带 (UWB,Ultra Wide Band) 技术提出一种施工机械与人员定位的风险预防及控制方法,并建立了可视化管控平台,然而,该方法难以低成本大面积铺开,且对大型机械型号的判定上存在安全隐患。近年来,随着人工智能技术的发展,深度学习模型被逐步应用于铁路安全的方方面面。徐鑫等人[3]基于YOLO(You Only Look Once)v5模型,建立铁路异物侵限检测模型。然而,针对临近铁路营业线的大型机械设备的施工安全智能监管仍有待进一步研究。
综上,本文设计了大型施工机械监管系统,并基于深度学习模型,设计了该系统中针对临近铁路营业线大型施工机械设备的智能视频分析模型,辅助施工监理单位完成对大型施工机械的各项监管工作。
1 系统总体架构
大型施工机械监管系统包括物理层、数据层、分析层和应用层,其总体架构如图1所示。

图1 大型施工机械监管系统总体架构
1.1 物理层
通过高清摄像头、智能网关等设备,从作业机械、施工人员等维度,准确快速采集铁路施工时大型机械的实时数据,同时,结合场地规划的具体信息,提高数据的有效性与精度。
1.2 数据层
包括施工现场实时视频流数据、业务数据,以及接口提供的实时入场机械与人员数据、施工场地涉及的铁路数据等信息,为智能分析决策提供数据支撑。
1.3 分析层
包括智能视觉分析决策与可视化仿真。其中,智能视觉分析决策通过人工智能、图像识别、大数据分析等技术,为智能监控与管理提供技术保障;可视化仿真主要通过数字孪生和UWB定位等技术,对大型施工机械进行多维度监管与智能预警。
1.4 应用层
包括智能监理模块与人工监理模块。其中,智能监理模块依托智能视觉分析决策,完成设备监控、人车监控、侵占判定、智能预警等多项任务,帮助监理人员及时掌握现场情况并作出决策;人工监理模块具有人工复查、统计分析、告警预警与监理日志管理等功能。
本文将重点研究分析层中用于智能视觉分析决策的智能视频分析模型的设计、数据收集和预处理策略,以及对模型的性能评估。
2 智能视频分析模型
智能视频分析模型的实时性与准确性是决定大型施工机械监管系统实用性的关键,本研究选用YOLOv6图像识别模型,并综合应用迁移学习、不平衡学习与数据增强等技术,增强YOLOv6模型的性能。
2.1 YOLOv6模型
YOLO系列模型在速度和精度间具有极佳的平衡,符合本文对施工区域大型施工机械监控视频实施自动监理的需求。YOLOv6模型包括3个部分:提取特征的Backbone层、处理特征的Neck层、执行预测的Head层,其架构如图2所示。

图2 YOLOv6模型架构
施工现场视频流的分辨率存在差异,为便于模型训练,设定将视频统一压缩并映射为640×640像素的输入标准,保障模型良好的泛化性能。此外,视频的压缩降低了模型的预测成本,可降低模型预测的延迟,提升吞吐量。
2.2 迁移学习
深度学习对训练数据集有很强的依赖性。模型的规模决定其能胜任任务的复杂程度,这是因为模型的表达空间必须足够大,才能发现数据的潜在模式[4]。而模型的规模与训练所需要的数据量基本上是线性关系[5]。面对大型机械的智能监理任务,需要收集海量数据才能满足高精度的预测要求。受计算资源与业务场景的限制,收集大量数据存在一定困难。
迁移学习可将在源域学习到的知识迁移到目标域中,从而克服训练集数据少的问题。本研究使用在16万张COCO标注数据集上预训练的YOLOv6-s目标检测模型作为迁移学习的预训练模型,并对其进行微调训练。
2.3 不平衡学习
铁路施工现场的大型机械种类繁多,且数量极不均衡。采用传统的训练方法会导致模型在数量多的机械上有更好的性能,对数量少的机械则精度较低。因此,需要采用不平衡学习技术,克服样本数量不均导致模型精度差的问题[6]。比较常用的是重采样与类别权重方法,其中,重采样是一种通过增加少数类样本或减少多数类样本,使得不同类别间的样本数量更平衡的方法,通常包括过采样与欠采样;类别权重方法则是在损失函数中为不同类别赋予不同的权重,使得模型更加关注少数类别[7],以抵消类别不平衡带来的影响,提高对少数类别的识别能力。本文采用了这两种方法对智能视频分析模型的训练图像进行不平衡学习处理。
3 数据集的生成
目前尚没有适用于铁路工地大型施工机械分类的公开数据集。本文基于真实铁路施工场景下的视频流数据,采用手工标注,并通过数据增强技术,生成用于训练YOLOv6模型的训练数据集。
3.1 数据采集与标注
本文在多个铁路施工现场通过对432台长方形固定机位和可移动的球形监控摄像头的实时观察,收集了约300条施工中的监控视频流,并通过专业人员的筛选,采集了3 600张大型施工机械图片,尺寸包含2 560×1 440、1 920×1 080、1 280×960、1 280×720及704×576共5种像素,构成了包含10类大型施工机械的数据集,随后在labelme软件中使用拉框标注法对这些图片进行标注,部分图片如图3所示。

图3 大型施工机械待检测图片(部分)
智能视频分析模型的检测目标包括:挖掘机(ECT ,Excavator)、装载机 (LD ,Loader)、叉装车(FL ,Forklifts)、泵车(PT ,Pump Truck)、汽车起重机(TC ,Truck Cranes)、履带起重机(CC ,Crawler Cranes)、随车起重机(TMC ,Truck Mounted Crane)、塔式起重机(TWC ,Tower Crane)、高空作业车(AWP ,Aerial Work Platforms)、旋挖钻机(RDR ,Rotary Drilling Rigs)等10类大型施工机械,其示例如图4所示。

图4 10类大型施工机械示例
3.2 数据特征与处理方法
3.2.1 数据特征
本文共收集到包含不同施工机械的图片3 600张,各类大型施工机械的数量占比如图5所示。

图5 原始数据集中的大型施工机械占比
其中, ECT占大型施工机械的62%,远超其余大型施工机械,而数量较少的AWP、PT、FL均仅占施工机械数据的1%,不同样本间的数量差异较大。此外,在施工现场视频流中会频繁出现遮挡、重叠的现象,且不同视频流间纵深差异大,同类目标的大小浮动可达10倍,增加了目标检测的难度。
3.2.2 数据处理技术应用
为解决数据集样本不平衡的问题,本文采用重采样技术,并结合数据增强技术。通过对不同类别的样本施加不同强度数据增强的方式,丰富数据集中的信息,并使用重采样技术缩小不同类样本数量间的差距,增强模型的稳定性和场景适应性。在综合考虑监控视频流数据中目标的形态学信息、方向信息的重要性及运动模糊现象的存在后,选用了左右镜像、亮度调节、颜色抖动、随机擦除、噪音、运动模糊随机组合等数据增强技术来增强数据的多样性,各类数据增强技术的效果如图6所示。

图6 各类数据增强技术效果示例
本文采用了Focal Loss作为损失函数,Focal Loss的核心思想是对于容易分类的样本(即分类器对其预测正确的样本)降低其权重,减少其对损失函数的贡献;同时,增加难以分类样本(即分类器对其预测错误的样本)的权重,增强其对损失函数的贡献。这样,模型就能对少数类别的样本有更高的关注度,从而提升少数类别样本的检测准确率。
3.2.3 训练集生成
将原始数据集按8∶2划分为训练集与验证集,对训练集使用数据增强,进行样本量平衡,最终训练集中共包括26 640张施工机械图片,验证集包括6 660张施工机械图片。各类别施工机械的数量与占比如图7所示。由图7可知,处理过后的数据集样本数量已较为平衡。

图7 训练集各样本数量与占比
3.3 训练环境与超参数设置
智能视频分析模型使用的训练环境如表1所示,超参数设置如表2所示。

表1 训练环境
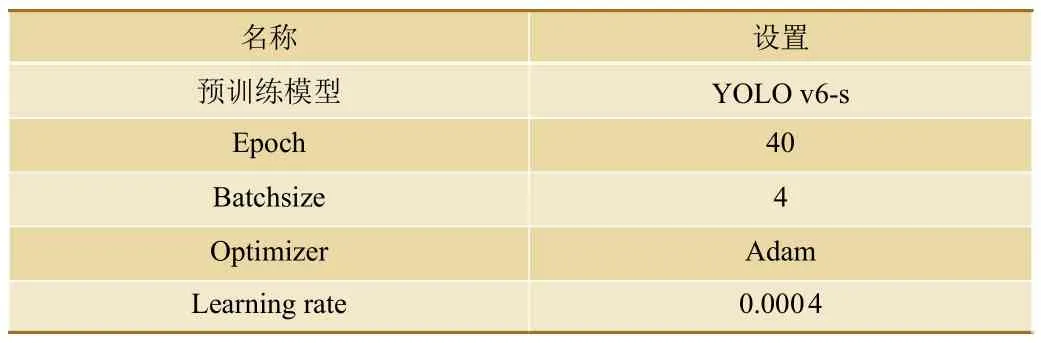
表2 超参数设置
3.4 评价指标
本文采用宏平均准确率(macro-ACC)、宏平均查全率(macro-R)、宏平均查准率(macro-P)、PR曲线下面积的平均值(mAP)、每秒传输帧数(FPS ,Frames Per Second)来评价模型定位、分类大型施工机械的能力与速度。
4 试验验证
为验证迁移学习和基于重采样的不平衡学习在智能视频分析模型中的效果,本文基于章节3中生成的3.33万张标注图片,分别将迁移学习、不平衡学习引入模型训练,并比较模型的检测效果。其中,不平衡学习的重采样技术依赖于数据增强相关技术。
4.1 效果对比
为验证迁移学习与不平衡学习对模型检测性能的提升,以及针对数据集特点使用的数据增强技术的效果,本文对比了原始YOLOv6模型与依次引入迁移学习、数据增强、不平衡学习的YOLOv6模型的定位与分类性能,如表3所示。

表3 不同模型训练方法的效果对比
由表3可看出,直接使用原始数据进行训练时,模型的mAP仅为0.129,macro-ACC仅有31.3%,这说明仅靠收集到的原始数据无法满足YOLOv6模型训练大型深度神经网络所需的数据量;而在使用YOLOv6-s模型作为预训练模型进行迁移学习后,mAP达到了0.537,macro-ACC达到了70.5%,说明在COCO数据集上学习到的知识有效转移到了本文任务上;在引入数据增强与不平衡学习后,mAP分别上涨了23.2%与18.7%,最终达到0.956,此时模型已能准确地定位各类大型施工机械并进行分类。
4.2 各大型施工机械的检测准确率指标对比
为进一步研究模型在识别不同类型大型施工机械时遇到的问题,以及不同模型训练方法起到的作用,在验证集上对各类大型施工机械的识别准确率指标进行了对比研究,结果如图8所示。ACC-1~ACC-4分别代表原始数据、引入迁移学习、引入迁移学习+数据增强、引入迁移学习+数据增强+不平衡学习方法后,模型对各类施工设备的检测准确率。

图8 各类大型施工机械ACC指标对比
由图8可看出,在直接使用原始数据集进行训练时,除了数量占比最大的ECT检测准确率较高,其余9种施工机械的准确率均较低,是由原始图像数量不平衡导致的;在使用预训练模型YOLOv6-s进行迁移学习后,少样本的大型施工机械检测准确率均有了显著提升;而在使用数据增强技术增加少样本类数据的多样性后,模型的稳定性与场景适应性有了进一步提升;在采用重采样和类别权重方法对样本数量进行平衡,增强模型对少数量样本的重视后,虽然ECT的检测准确率有少许下降,但其余9种大型施工机械的检测准确率均有了不同幅度的提升。
基于该模型的大型施工机械监管系统能够结合施工计划,把识别出的机械与计划下达的机械大类进行核对,如检测到超过计划下达的机械数量或类型,则生成预警、告警信息,提交人工监理模块进行核验,由人工监理模块进行复核和处置,实现高效率、高准确率的全天候安全监测。
5 结束语
本文设计了大型施工机械监管系统,重点阐述了该系统分析层中用于智能视觉分析决策的智能视频分析模型的设计、数据收集和预处理策略,以及模型性能评估,模型的宏平均准确率达到了94.0%、mAP达到了0.956、每秒检测帧数达到了84。基于该模型的本系统实现了对大型施工机械的快速、准确定位和分类,节约了大量监管人力。 未来可在大型机械的细粒度分类、机械施工区域侵入检测等方面进行进一步的研究。
