基于Transformer模型的轨道交通机器翻译系统设计
2024-05-07李子林刘庆猛李雪山
李子林,刘庆猛,李雪山
(中国铁道科学研究院集团有限公司 科学技术信息研究所,北京 100081)
近年来,中国铁路“走出去”的步伐不断加快,已成为“一带一路”建设和国际产能合作的一张靓丽名片。随着坦桑尼亚—赞比亚铁路(简称:坦赞铁路)、蒙巴萨—内罗毕铁路(简称:蒙内铁路)、中国—老挝铁路(简称:中老铁路)、匈牙利—塞尔维亚铁路(简称:匈塞铁路)、雅加达—万隆高速铁路(简称:雅万高铁)等国际铁路建设合作项目的顺利、稳步推进,以及《高速铁路设计基础设施》等技术标准的国际化,中国铁路生产经营、科技研发事业也不断迎来一系列新的国际机遇和挑战。铁路行业对外合作和技术交流的不断深入也对铁路从业人员掌握外国语言的能力提出了更高的要求。此外,在铁路科技自立自强背景下,国内铁路科研人员囿于语言障碍,无法快速、精准地查询和利用多语种科技文献,造成国外先进的铁路科技研发成果无法被充分了解、吸收和借鉴。鉴于此,立足轨道交通行业特点和现实需求,推出具有领域性、专业性和行业特色的机器翻译系统工具意义深远。
从基于循环神经网络(RNN,Recurrent Neural Network)到基于注意力机制、基于卷积神经网络(CNN,Convolutional Neural Network)的神经机器翻译方法[1-3],再发展至基于自注意力机制的Transformer模型的神经机器翻译(NMT, Neural Machine Translation)方法[4],神经机器翻译模型通过神经网络和注意力机制学习序列之间的映射优化了翻译性能,已成为机器翻译领域的主流模型。然而,聚焦小语种及特定行业领域的机器翻译系统仍处于探索发展期[5-6]。以谷歌、百度、DeepL等为代表的主流机器翻译系统在通用领域、常用语种翻译方面效果显著,但是在特定行业领域、小语种翻译等方面仍然有较大的优化空间。以轨道交通行业为例,主流机器翻译系统对专业术语、专有名词缩写、行业新词的机器翻译效果与通用领域翻译效果尚存差距。另外,满足本地化部署和信息安全保密要求亦是行业机器翻译系统研发和设计关注的重点。
基于上述研究,本文立足轨道交通行业特色,打造基于Transformer模型的轨道交通机器翻译系统——“铁译通”(RailTrans),面向行业用户,提供专业化、多元化、定制化、安全性强的机器翻译服务,为进一步丰富人工智能技术在铁路行业的应用场景提供支撑[7]。
1 系统总体架构
轨道交通机器翻译系统总体架构由应用层和翻译引擎实现层组成,如图1所示。
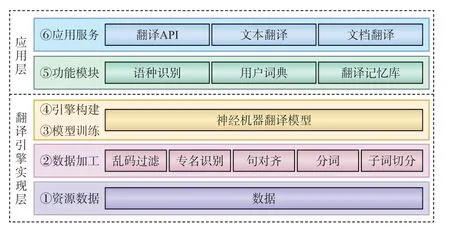
图1 轨道交通机器翻译系统总体架构
1.1 翻译引擎实现层
1.1.1 资源数据
主要用于存储双语句对、轨道交通领域术语词典等基本数据库资源。
1.1.2 数据加工
主要对资源数据层存储的数据进行结构化预处理,以确保训练系统所需要的数据可用,主要包括:乱码过滤、句对齐、中文分词、多国语分词、命名实体识别、子词切分等流程。
1.1.3 模型训练
采用基于Transformer模型进行神经机器翻译建模,同时,使用极大似然估计针对平行数据进行网络参数调优,进而可以使用此模型进行翻译引擎构建。自动评价方法使用双语互译质量评估辅助工具(BLEU,Bilingual Evaluation Understudy)来评价翻译质量,并根据评测结果的优缺点调整训练模型,最后得出翻译系统最佳模型。
1.1.4 引擎构建
对资源数据、数据加工及模型训练等模块进行统一调度管理,并将所有资源数据加载至内存,等待翻译任务进行解码。利用神经机器翻译解码技术,基于云平台结构搭建系统架构,使之具备分布式处理能力,同时不断扩展计算节点以进一步提高翻译性能。
1.2 应用层
1.2.1 功能模块
主要包括语种识别、用户词典等服务模块。语种识别主要是基于统计模型建模,自动识别输入句子的语言,以便于用户自动切换到所需语种。用户词典主要是面向轨道交通专业用户,提供嵌入轨道交通专业词库的领域翻译功能,根据用户需求添加术语词典,确保神经机器模型在深度学习中提高翻译性能。
1.2.2 应用服务
主要包括:翻译应用程序编程接口(API,Application Programming Interface),用于支持二次开发;基于Web的文本翻译、文档翻译,其中,文档格式支持pdf、txt、doc、docx、xls、ppt和pptx等常用格式;基于Web的浏览器翻译,其中,浏览器支持Chrome、Edge、360及其他基于Chrome内核的浏览器;基于Office插件的办公软件翻译,兼容微软Office和WPS,支持word、ppt、excel文档。
2 系统功能
轨道交通机器翻译系统的定位是面向国内轨道交通行业用户的高度安全性、专业化、个性化的机器翻译引擎,主要功能如下。
2.1 网页端翻译
网页端翻译功能主要适配浏览器端用户使用场景,分为文本翻译和文档翻译。其中,文本翻译具备5 000字符文字翻译能力,提供原文种自动识别、原文清空、译文复制、双语高亮等功能;文档翻译适配pdf、docx、txt、xls、xls、ppt、pptx、html等格式文档,具备列表显示、翻页、搜索、翻译进度、下载、删除、预览等功能,支持双语对照格式、译文docx格式下载。
2.2 翻译API及翻译插件
随着多语种信息指数级增长,机器翻译技术逐渐被融合应用到各类业务场景,为用户提供实时便捷的翻译服务[8]。鉴于此,本系统推出翻译API及各类翻译插件。文本翻译API,是基于HTTP协议的翻译API,用户可根据需要便捷地集成嵌入到业务平台或其他应用中;文档翻译API,通过API的方式可快速将文档翻译服务集成到现有业务系统;XML翻译API,可支持XML文本翻译,译文保留原始格式;特色术语库API,通过API调用添加行业特色语料,保证译文中术语翻译的准确性和一致性。Office翻译插件,用户下载插件到本地安装后,点选Office办公软件工具栏的“铁译通”按钮即可启动翻译服务;Web浏览器翻译插件,用户下载插件到本地安装后,点选Web浏览器辅助工具栏的“铁译通”即可启动网页翻译服务。
2.3 人工翻译
机器翻译在翻译效率方面优势明显,但针对轨道交通行业专业性强、术语量多、内容复杂的科研类文档,机器翻译与人工翻译相比在文章结构、用词精准度、语言流畅度等方面仍有较大差距。因此,本系统推出人工翻译功能,整合轨道交通翻译专家数据库,有效实现用户翻译需求与领域翻译专家“点对点”关联,完成人工翻译订单的在线投递、定向分配、任务返回与译文发布。
2.4 后台管理
提供用户(组)管理功能,可根据需要对特定用户(组)的基本信息进行增删改查,并对相应用户(组)的使用权限进行自定义设置;提供充值管理功能,按照流量计费制度对用户账号流量进行实时监测和自动充值提醒;提供人工翻译订单管理功能,对接收的人工翻译服务订单进行派单操作和费用配置;提供API管理功能,对API权限、流量、个性化定制等进行设置;此外,提供访问控制、访问统计、流量统计等访问日志功能。
3 关键技术
3.1 多语种数据处理与分析
多语种数据处理与分析主要包括多语言数据加工和多语种语言分析。大规模平行双语数据来源广泛,数字化过程中不免出现乱码问题,因此,须对非法字符、控制字符等进行乱码过滤等规范化处理。多语言数据加工主要通过集成分布式爬虫、数据标注、数据清洗等工具,对轨道交通行业多语言数据进行采集、规范化处理和加工,为后期多语种语言分析提供数据基础。
多语种语言分析能够支持中文句子级的自动分词、词性标注、命名实体识别、组块识别、成分句法分析等技术,对句子中的特殊信息进行预处理,主要包括数字、时间、日期、人名、地名和组织机构名等。在分词基础上,根据大规模语料进行子词统计,得到更符合语料的词汇表,同时,减少机器翻译中词汇表过大引起的速度问题。多语种语言分析平台强大的语料处理能力为高质量语料训练夯实基础,进而保证翻译质量的可信度。
3.2 Transformer模型及优化
Transformer神经网络模型仅使用自注意力机制和标准的前馈神经网络,不依赖循环单元或者卷积操作可以高效地描述任意距离之间的依赖关系,因此,非常适合处理语言文字序列。
轨道交通机器翻译系统以Transformer神经网络模型为基础,在算法层面进行创新,以提升模型编码和解码的性能。Transformer模型优化的方法多数是将模型加宽(Transformer-Big模型),但是,堆叠太多的层会因为梯度消失或梯度爆炸而导致模型难以训练,传统的层标准化(LN,Layer Normalization)是在残差连接之后进行,本文提出一种新的基于群体置换(Group-Permutation)的知识蒸馏方法,即将深的Transformer模型压缩为一个浅的轻量模型,并通过随机删除子层以引入扰动训练的子层跳跃(Skipping Sub-Layer)方法。基于Group-Permutation的知识蒸馏方法如图2所示。
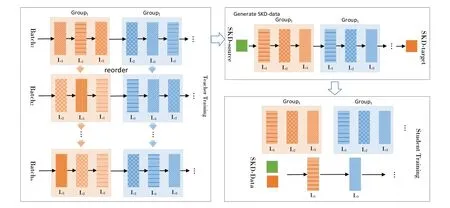
图2 基于Group-Permutation的知识蒸馏方法
其主要可分为如下3个步骤。
(1)在Teacher模型上应用Group-permutation的训练方法;
(2)通过Teacher模型生成SKD数据;
(3)利用得到的SKD数据训练Student模型。
轨道交通机器翻译系统引入翻译记忆(TM,Translation Memory),并融入神经机器翻译NMT模型进行训练。翻译记忆是保存信息所翻译专家历史翻译记录的数据库,其中,每个条目包含源语句子及其翻译。依托中国铁道科学研究院集团有限公司科学技术信息研究所翻译中心积累的丰富的优质翻译经验和语料,构成翻译记忆的基础,这些语料对于轨道交通领域的精准翻译非常重要。模型训练中,利用数据增广的方式将翻译记忆和训练数据拼接起来,同时,调整神经机器翻译的架构,使其能够处理翻译记忆信息,从中获得翻译知识。
3.3 专业语料库构建
经典神经机器翻译模型训练高度依赖双语平行语料库[9]。为确保轨道交通机器翻译系统的翻译专业性和精准度,构建双语平行专业语料库,从语料规模、语料采集、语料择选与规范化处理等维度进行规划与控制,为后期神经机器翻译模型的训练夯实基础。
4 应用场景
轨道交通机器翻译系统作为子系统纳入到了中国铁道科学研究院集团有限公司的“轨道交通专业知识服务系统(铁科院数字图书馆)”之中,面向轨道交通行业用户提供基础服务、特色服务和人工服务。
4.1 基础服务
主要包括:文本翻译、文档翻译服务。用户登录系统主界面后,手工录入或上传文档即可翻译。系统支持切换“领域翻译”“即时翻译”模式,用户可自定义翻译服务的时效性和专业化程度。例如,输入文本“cars per cut”,在“通用领域”模式翻译为“每辆车”,在“轨道领域”模式翻译为“钩车”,翻译结果的专业性更强。
4.2 特色服务
主要包括:插件翻译、文档转换处理等服务。相较于主流机器翻译引擎,本系统增加Office/WPS翻译插件、浏览器翻译插件服务,同步在线端的用户数据,真正实现“一个账号联通多种服务方式”。另外,推出“划词翻译”“翻译范围自定义”等个性化翻译工具,增设“文档转换处理”辅助翻译工具,提高文档翻译服务的用户满意度。
4.3 人工服务
本系统整合国内轨道交通行业翻译专家资源,增设人工翻译服务模块。用户可在线提交“翻译订单”,上传翻译示例文档,选择不同等级的翻译服务,并对翻译内容提出要求。本系统将根据“翻译订单”进行专家配对,为用户推荐目标领域的翻译专家完成翻译工作。
与商业机器翻译引擎相比,本系统应用优势如下。
(1)实现本地化部署,有效保障数据的安全性和保密性;
(2)利用专业语料库,提升领域翻译的专业性和精准度;
(3)提供多元化翻译服务,除网页端翻译服务外,提供Office等插件翻译和人工翻译服务,适配用户个性化的应用场景。
5 结束语
本文针对商用机器翻译引擎安全性无法保证、专业化领域翻译精准度低、翻译服务方式单一等问题,设计轨道交通机器翻译系统。通过应用知识蒸馏方法进行Transformer模型优化,构建轨道交通行业专业语料库,提升系统翻译的专业性和精准度,实现本地化部署与运营维护,保障数据的安全性和保密性;推出文本翻译、文档翻译、Office插件翻译等的多元化翻译服务,为轨道交通行业人员提供更加安全化、专业化、特色化的翻译工具。下一步,将丰富多语种语料库,增加文档翻译OCR识别等功能,优化翻译API性能,提升系统的稳定性和易用性。
