基于多目标策略的高速铁路闭塞分区优化研究
2024-05-07刘伟玲
刘伟玲,张 慧
(1.中国铁路南昌局集团有限公司 电务部,南昌 330002;2.西安市轨道交通集团有限公司 运营分公司,西安 710000)
我国高速铁路采用能使列车在区间安全运行的自动闭塞方式,根据列车运行速度,区间的多个闭塞分区构成列车安全追踪运行间隔,闭塞分区的长度直接影响列车追踪间隔的精度[1]。若闭塞分区设置过长,虽能保证列车安全制动和舒适驾驶的需要,但会造成不必要的列车间隔距离浪费;若闭塞分区设置过短,虽能发挥线路的运输效率,但存在一定的安全风险和额外设备投资。因此,在进行闭塞分区设计时,须在确保列车运行安全的前提下满足运输效率、减少设备投资的要求。
目前,国内外许多学者对闭塞分区进行了相关研究。Gill D.C等人[2]面向城市轨道交通,采用多目标结合启发式的梯度算法求解闭塞分区的优化问题;Chang C.S等人[3]使用差分进化算法和遗传算法,研究城市轨道交通区间通过信号机的位置划分;Ke B.R等人[4]使用最大-最小蚁群系统,建立了以节能为目标的地铁线路区间固定闭塞分区布置方案;刘海东等人[5]将差分进化算法进行改进,并用于求解高速铁路闭塞分区的设计问题;王丹彤等人[6]通过整体分布优化算法,对高速铁路进站前的若干个闭塞分区进行优化,将列车区间和进站间隔进行整体考虑;还有一些学者考虑效率或经济策略,构建铁路区间闭塞分区分布模型,并利用遗传算法、差分进化算法、粒子群算法等对其进行求解[7-9]。
国外的相关研究多集中于城市轨道交通闭塞分区的布置,国内学者虽然已将智能寻优算法应用于求解干线普速铁路和200 km/h客运专线的闭塞分区布置问题上,但针对适用于CTCS-3级列车运行控制系统(简称:列控系统)要求的铁路闭塞分区研究相对较少,且得到的结果多与实际线路差距较大,其原因是布置方案并未综合考虑闭塞分区划分的实际需求,不能很好地应用于实际线路设计[10-12]。
本文基于CTCS-3级列控系统控车原理,综合考虑闭塞分区划分目标及影响因素,构建CTCS-3级列控系统下的高速铁路闭塞分区划分模型,并使用粒子群算法进行模型求解。
1 闭塞分区划分影响因素
高速铁路闭塞分区的设计应全面考虑影响闭塞分区长度及分界点位置的因素,如采用的列控系统、闭塞方式、线路条件、列车类型、安全制动距离、行车间隔和分相区位置及长度等。
1.1 列车安全制动距离
实现列车在区间安全追踪运行是闭塞分区设计划分的首要目标。列车安全制动距离是由列车有效制动距离、安全余量及司机和列控系统反应时间内的列车走行距离确定的。在进行闭塞分区划分时,应按码序显示条件进行列车安全制动距离检验。
1.2 列车种类
列车运行速度及性能决定了列车制动距离,因此,闭塞分区的设置应充分考虑在该线路上运行的列车参数。
1.3 区间信号显示制式
信号系统采取的闭塞方式及显示模式直接决定了两列车间能够间隔的最大闭塞分区数目及列车间隔距离。
1.4 列车追踪间隔及通过能力
列车追踪间隔、线路通过能力的要求是闭塞分区设置需满足的运营条件,也是闭塞分区设计的制约点。本文基于采用目标距离一次制动模式的CTCS-3级列控系统,在固定自动闭塞制式下,参考相关资料[13],计算列车运行间隔时间。
1.5 线路条件
线路条件是设计区间信号闭塞分区的基础数据,具体体现在计算列车安全制动距离时坡度等参数对列车制动减速度的影响。
1.6 分相区的位置及长度
分相区是一个接触网无牵引的区域,列车在区间需要依靠惯性惰行经过分相区,闭塞分区的设置应能保证列车安全通过分相区。
2 多目标策略下的闭塞分区划分模型
闭塞分区的划分应在满足各影响因素的条件下,主要考虑安全、效率、经济等3个方面的优化目标。三者相互约束,其中,安全是铁路运输的前提,在此前提下,建立高速铁路闭塞分区划分模型,如图1所示。

图1 闭塞分区划分示意
图中,甲、乙为2个相邻的车站;x0为甲站反向进站信号机的位置;xN+1为乙站进站信号机的位置;li为每个闭塞分区的长度;x1,x2,···,xN为闭塞分区分界点的位置;区间共N+1个闭塞分区。
2.1 目标函数
在满足行车安全和闭塞分区各约束条件的目标下,构建以闭塞分区数目最少和列车运行间隔最小的优化目标函数,公式为
式(1)中,I区,I接,I发分别为列车在区间运行、车站接车和发车的间隔时间。列车运行间隔时间I为各运行场景下行车间隔的最大值。
2.2 约束条件
根据影响闭塞分区设计的因素,建立闭塞分区划分模型的约束条件。
(1)区间信号分界条件
区间的所有分界点必须位于信号规定范围内,表示为
(2)闭塞分区长度条件
CTCS-3级列控系统区间闭塞分区通常设置为2 000 m左右,除列车进站接近区段和列车出站第一离去区段外,闭塞分区长度一般不大于3 000 m,不小于1 500 m[14],表示为
式(3)中,li为以xi信号点为防护分界闭塞分区的长度,i=2,3,···,N-1;L为区间总长度。
(3)列车安全制动距离
CTCS-3级列控系统区间满足安全追踪间隔运行可分配的码序最大数量为7。信号系统追踪码序匹配相应闭塞分区的长度之和须满足安全制动距离,表示为
式(4)中,为列车在x位置处以最高运行速度开始制动的最大常用制动距离;L附加为列车在制动附加时间的运行距离;L防为安全防护距离。
(4)出站一离去区段
一离去区段制约列车发车间隔,一离去区段位置x1至相邻信号点x0(反向进站信号机)的距离,须满足以出站最高限速vc运行至停车的制动距离,表示为
(5)进站接近区段
进站接近区段应设置相对较短,尽量缩短进站间隔时间以均衡车站和区间的行车间隔。进行闭塞分区布置时,接近区段起点信号分界xJ应满足
式(6)中,Lx为接近锁闭区段起始闭塞分区的长度。
(6)分相区约束条件
闭塞分区分界点不可设在分相区内,表示为
式(7)中,Fs为分相区断电标位置;Fe为分相区合电标位置。
分相区后的信号分界点须保证列车在该位置重新启动后安全通过分相区,表示为
分相区前方的闭塞分区分界点应满足以下条件,表示为
式(9)中,vf为列车安全过分相区的最小限速,取值30 km/h;Sf为分相终点至前方信号分界点的最小长度,取值300 m。
3 模型求解
本文选择在多目标优化问题求解方面已应用成熟的粒子群算法对本文建立的模型进行求解。
3.1 算法实现流程
粒子群算法求解流程如图2所示。
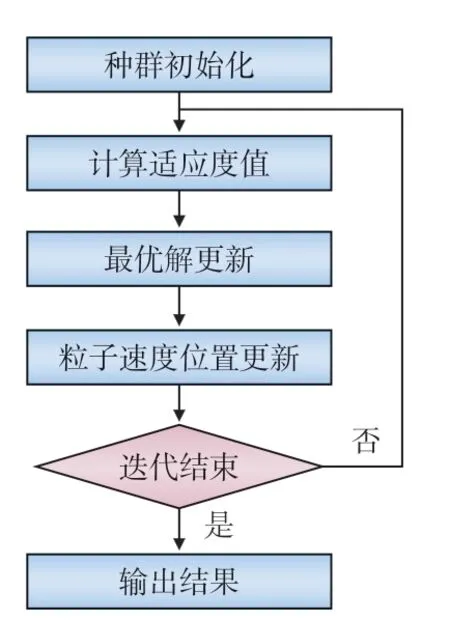
图2 粒子群算法求解流程
(1)随机生成初始化粒子的位置和速度;
(2)计算初始种群的适应度值,根据适应度值寻找初始种群中的最优解,为个体最优值;
(3)更新粒子的速度和位置,计算新粒子的适应度值,并与历史局部最优解进行适应度值比较,若优于历史,则进行更新;
(4)判断是否达到迭代终止条件,若达到终止条件,则输出最终的最优结果及算法迭代次数。
3.2 初始种群生成
用长度为N的数组表示一种迭代至第i代的模型求解结果,第N个分界点的位置为数组中的。
为了加快粒子收敛速度得到最优结果,需要生成一个较优初始解,便于后续进行准确有效的搜索。算法初始种群生成的流程如图3所示。

图3 初始化粒子流程
图3中,NP为初始种群的数量,从第1个种群p=1开始初始化;N为初始种群数组的长度,即划分的闭塞分区分界点数目,是在由式(3)确定的取值范围内随机产生的整数;xpj为粒子位置,表示第p个种群内的第j个闭塞分区分界点;R为粒子的搜索速度,取100~200范围内的随机数。
3.3 适应度函数构建
求解时将约束条件通过惩罚函数的引入算法,根据目标函数及相应的约束条件构建适应度函数,适应度函数值越小表示划分结果越好,公式为
式(10)中,1.1N表示划分的闭塞分区越少,适应度值越小。
Q1~Q7为惩罚函数,均为2.2节约束条件的具体体现,公式为
式(11)中,Q1为行车追踪时间约束的惩罚函数;In为当前划分方案下的列车间隔时间;H为规定的行车间隔。
式(12)中,Q2为除去进站接近区段和一离去区段外,闭塞分区最小长度与每个闭塞分区的长度的差值之和。
式(13)中,Q3为闭塞分区长度范围和超出区间分界范围约束的惩罚函数。
式(14)中,Q4为不满足在CTCS-3级列控系统码序间隔下安全制动距离的闭塞分区,N4为闭塞分区的个数。
式(15)中,Q5为一离去区段信号点的限制约束对应的惩罚函数。
式(16)中,Q6为进站接近区段信号点约束对应的惩罚函数;xc为接近区段分界的限制位置。
式(17)中,Q7为分相区约束的惩罚函数,N7为个数。α、β、χ、δ、ε、ϕ、η为惩罚因子,根据模型设计的目标函数和约束重要度取值。
3.4 种群更新
种群更新的速度和位置如下:
式(18)中,ω为惯性权重;c1、c2为常数;k为迭代次数;r1、r2为范围在0~1之间的随机数。
Xi=(xi1,xi2,···,xin)为粒子的位置;
Vi=(vi1,vi2,···,vin)为粒子的搜索速度;
Pi=(pi1,pi2,···,pin)为适应度值最优时种群内粒子的位置。
对于求解多目标最小化问题,若粒子总数为w,求解的全局最优值Pg为群体中所有粒子的最优位置,Pg=min(P0,P1,···,Pw)。
4 算例验证
本文选取CTCS-3级列控系统在京沪(北京—上海)高速铁路滕州东—枣庄下行区间的线路数据,使用多目标策略下的粒子群算法对闭塞分区划分模型进行求解。
4.1 计算数据设置
待划分的滕州东站—枣庄区间线路数据如表1所示,区间总长34 279 m。

表1 区间基本信息
区间包含电分相区的起止点里程信息如表2所示。

表2 区间分相区信息
选取CRH3型动车组制动参数计算列车安全制动距离,如表3所示。
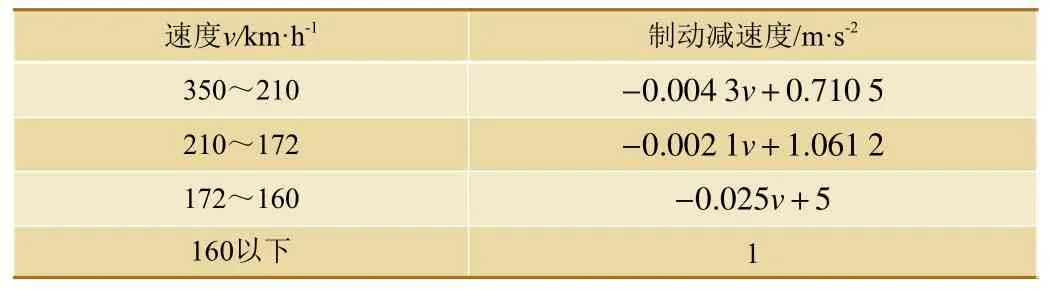
表3 CRH3型动车组相关参数
列车运行间隔时间计算相关参数根据文献[15]取值。
4.2 算法参数设置
利用MATLAB工具根据本文第3章描述的算法求解步骤编程求解,求解参数设置如下:初始种群设为30个,ω取0.7,c1=c2取1.49,迭代次数取200。在寻求最优结果过程中,适应度函数中各惩罚因子的取值可根据适应度函数计算结果和各约束条件的重要度进行调整,以便求得更满足优化目标的结果,本文求解得到的最终结果中,惩罚因子α、β、χ、δ、ε、ϕ、η取值依次为10、20、10、15、20、10、10。
4.3 结果分析
使用粒子群算法对滕州东—枣庄区间闭塞分区划分结果如表4所示。
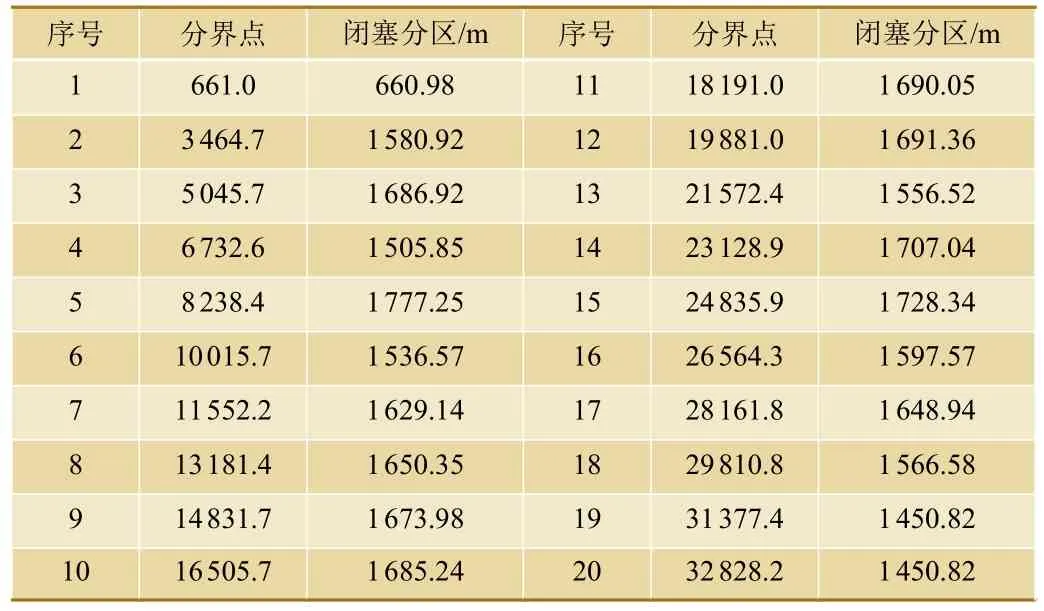
表4 闭塞分区划分结果
图4为闭塞分区划分算法的适应度函数变化曲线,算法最终趋于稳定,由图可知当迭代次数为46时,得到当前划分方案下的最优结果。

图4 算法适应度函数
计算该结果下的行车间隔时间,并与实际线路进行对比,结果如表5所示。
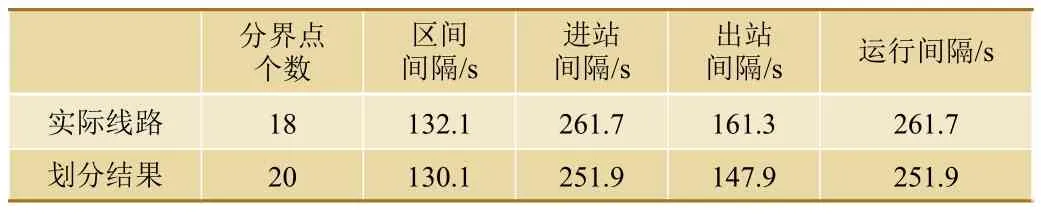
表5 划分结果对比
结果表明,通过本文提出的基于粒子群算法的高速铁路闭塞分区优化模型得到的划分结果比实际线路增加2个闭塞分区,列车运行间隔时间缩短9.8 s。闭塞分区的设置结果与实际线路较为接近,是均衡考虑了列车运行间隔时间和闭塞分区数目的结果,更好地贴近闭塞分区划分设计的实际需求。
5 结束语
本文以分析影响高速铁路区间闭塞分区长度和位置的因素为基础,从闭塞分区布置设计的实际需求出发,综合考虑闭塞分区划分的效率和经济目标,建立基于CTCS-3级列控系统的高速铁路闭塞分区优化模型,并将闭塞分区的设置问题转换为有约束条件的优化问题,最后使用多目标粒子群算法以京沪高速铁路滕州东—枣庄区间为例,求解得到满足闭塞分区划分目标和贴近实际线路设置的结果。该优化模型很好地表达了高速铁路闭塞分区的设计需求,对高速铁路闭塞分区的优化设计具有实际意义。
