基于多示例学习图卷积网络的隐写者检测
2024-04-30钟圣华
钟圣华 张 智,2
图像隐写者检测技术是一项通过对用户传播的图像进行综合分析、侦测,来发现那些试图将隐秘信息隐藏在图片中进行隐秘通信的隐写者的信息安全技术.在真实的社交网络中,隐写者检测十分困难.一方面,基于图像的隐写算法可以帮助隐写者在不改变图像外观的前提下,将隐秘信息嵌入图像中.另一方面,隐写者使用隐写术和有效载荷[1]等相关参数往往是无法预知的,这进一步增加了隐写者检测的难度.与试图捕获载密图像和载体图像之间的差异的隐写分析方法不同,隐写者检测更关注隐写者与非隐写者之间的差异.
现有的隐写者检测方法中,为了模拟真实场景中隐写者数量远远少于正常用户的情况,常常假设在测试的过程中,用户中只有一个隐写者存在,采用异常检测或排序的方法将预测的隐写者概率最高的用户作为隐写者进行输出.
因此,通用的隐写者检测方法通常由两部分组成: 特征提取和基于特征的聚类或离群值检测.Ker 等[1]首次将隐写者检测转换为聚类问题进行研究,从每张图像中提取PEV-274 特征[2],并使用最大平均差异计算每对用户之间的距离,再通过层次聚类算法来区分隐写者与非隐写者.此后,Ker等[3-4]进一步改进之前的工作,用局部离群值因子方法代替层次聚类算法,计算用户的异常程度并进行排序,异常值最高的用户被检测为隐写者.2016 年,Li 等[5]提出使用高阶联合特征作为图像的隐写分析特征,并集成多个层次聚类器来检测隐写者.2017 年,Zheng 等[6]首次提出一种基于深度学习方法的隐写者检测框架,使用深度残差网络来提取图像特征,最后使用聚合性层次聚类算法识别隐写者.2018 年,Zheng 等[7]进一步改进特征提取模型,并提出一种用于隐写者检测任务的多分类深度神经网络,与传统方法和其他深度学习方法相比,该模型在标准数据集上实现了最好的性能.尽管这些方法的特征提取部分有所不同,但是在用户表征、用户之间相似性的度量和可疑用户的检测等步骤没有本质差异.在这些方法中,每名用户的表征由其所分享的所有图像的特征分布拼接而成,在此基础上,计算用户的特征分布之间的相似度,找出与其他用户差异较大的用户,进而确定隐写者.2020 年以来,Zhang 等[8-9]将用户分享的图像及其相关关系建模成图,提出相似性累积图卷积单元,能够增强相似特征分布,从而发现载密图像构成的子图,对其进行加权,以获得更有效的用户表征,这也是迄今为止唯一使用图神经网络模型进行隐写者检测的方法.
本文将隐写者检测形式化成多示例学习(Multiple-instance learning,MIL)任务,并提出基于多示例学习图卷积网络的隐写者检测算法(Steganographer detection algorithm based on multiple-instance learning graph convolutional network,MILGCN).该算法通过共性增强图卷积网络(Graph convolutional network,GCN) 有效增加正示例的共性特征,通过注意力示例包表征模块自适应地构建更具有区分力的示例包表征,并设计多示例学习损失约束.与现有算法相比,提升了空域和频域、已知和未知隐写术等多种隐写策略情况下的隐写者检测准确率.相比于Zhang 等[8-9]的工作,本文提出一种新的基于图的用户表征模型,能够针对不同嵌入策略做到对分享的图像数量鲁棒.相比于文献[8-9]中基于规则构建的图重建和边池化方法,本文提出自适应的图构建和归一化方法,并通过损失进行约束,自适应地攻击不同隐写策略;相比于文献[8-9]中将节点视为同等重要的展平读出和平均读出,本文进一步设计新的图读出方式,能够载密图像构建具有区分力的图表征.
本文内容安排如下: 第1 节回顾图神经网络的相关工作;第2 节给出基于多示例学习的通用隐写者检测方法的详细介绍;第3 节给出一系列实验,以验证提出方法的有效性;第4 节对全文工作进行总结,并给出进一步的研究思路.
1 图神经网络的相关工作
最近,基于深度学习的方法已经在图结构数据的分类和聚类任务上获得了成功的应用,实际应用领域包括恶意软件分析、图像分类、动作识别、物体分类等[10].其中,图卷积网络通过将适用于分析欧氏数据结构的传统卷积神经网络泛化到图等非欧结构数据上,实现了图结构上的卷积运算,取得了显著的研究进展并获得了广泛的关注.在这些方法中,图卷积方法通常被分为两类,即基于谱域的图卷积方法和基于空域的图卷积方法[9].
谱域图卷积方法源于谱图理论,可以看作傅立叶变换在图上的推广[11].该类方法通过对拉普拉斯矩阵的特征分解,定义了图上的拉普拉斯变换和拉普拉斯逆变换.该工作通过傅立叶变换将图变换到谱域进行卷积,再通过傅立叶逆变换将卷积结果变换回图.在此基础上,Defferrard 等[11]进一步提出一种卷积核的多项式近似方法,将节点聚合信息的范围限制在k阶邻居节点内.在此基础上,Kipf 和Welling[12]将节点聚合信息的范围限制在一阶邻域内,再次对卷积计算进行近似,提出最为常用的图卷积网络.
与基于谱域的方法不同,基于空域的方法并未将图映射到傅立叶域,而是将卷积操作形式化为一种“块级操作”,基于这种块级操作,卷积操作通过聚合块级区域(图上的每个节点及其邻域) 的信息构建新的节点特征表示.2017 年,Hamilton 等[13]提出GraphSAGE 并将图结构数据上的卷积操作形式化为三个主要步骤,利用对节点排列具有不变性的函数(如均值、和、极大值等) 聚合节点的邻域信息.2018 年,Ying 等[14]提出一个可微分的图池化网络DiffPool,来生成层次化的图的表征.通过可微分的方式,模型能够自适应地对图中的节点进行池化,从而得到新的表征.最近,注意力机制在图深度学习领域取得了突出的成就,这类方法使用注意力机制为重要的节点、邻居节点和特征赋予更高的权重.2018 年,Veličković 等[15]提出图注意力网络(Graph attention network,GAT),在该模型中,注意力机制被用于计算在聚合来自邻居节点的信息时不同邻居节点的权重值.近年来的研究表明,基于谱域的图卷积方法和基于空域的图卷积方法并不是完全对立的,一些谱域的方法能够形式化为在空域应用某种卷积核进行卷积.
2 基于多示例学习图卷积网络的隐写者检测框架
多示例学习是有监督学习中的一种特殊形式.相比于对一系列独立标注的样本进行分类,在多示例学习任务中,学习器以一系列被标注的包(Bag)作为输入,每个包包含若干个未标注的样本,即示例(Instance)[16-19].如果包中的所有示例都为负样本,那么这个包则被标注为负包.另一方面,如果包中含有至少一个正示例,则包被标记为正包.在隐写者检测任务中,只要用户分享的图像中包含至少一张载密图像,则这个用户就应当被检测为隐写者.只有当用户分享的所有图像都为载体图像时,用户应当被判别为正常用户.毋庸置疑,隐写者检测任务的目标和多示例学习在本质上是一致的.因此,本文将隐写者检测任务形式化为多示例学习任务.
本文提出的基于多示例学习图卷积网络的隐写者检测算法,将社交网络中的用户及其分享的图像作为输入,区分隐写者和正常用户.如图1 所示,在多示例学习的框架下包含4 个主要组成部分,即特征提取网络、共性增强图卷积网络、注意力示例包表征网络和分类网络.需要注意的是,本文提出的模型在训练和测试过程中有所不同.在训练过程中,以示例包的分类作为目标,所以构建的是分类网络.在测试过程中,采用与以往隐写者检测一致的实验设置,即将预测的隐写者概率最高的用户作为隐写者输出.
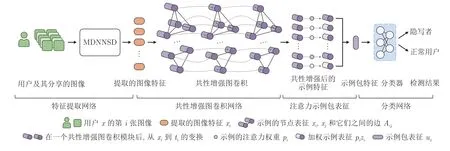
图1 基于多示例学习图卷积网络的隐写者检测框架Fig.1 Steganographer detection framework based on multiple-instance learning graph convolutional network
首先使用基于多类别深度神经网络的隐写者检测(Multiclass deep neural networks based steganographer detection,MDNNSD)[7],针对用户分享的每一张图像提取特征,得到用户对应的特征集合 {x1,···,xn}.这里,将提取到的特征表示为橙色圆角矩形,其中第i个圆角矩形表示用户分享的第i张图像所对应的特征.接着,将特征作为示例包中的示例,将特征集合作为示例包,构建图结构.其中,紫色圆柱表示示例所对应的特征,圆柱的高度表示特征的维度,紫色圆柱之间的连线代表图结构中的连接示例特征的边.在图结构上进行卷积,实现示例特征的分析和降维,降维的过程使用箭头指示.在多次卷积后,可以得到分析和降维后的特征集合 {t1,···,tn}.这里,将得到的示例特征按顺序排列,绘制为新的紫色圆柱.在此基础上,使用注意力图读出计算每个示例特征的重要程度,并根据重要程度对示例特征进行加权,加权后的结果使用不同深浅的紫色圆柱表示.最终,对加权后的示例特征进行汇总,得到图的表征,并使用箭头指示得到的示例包表征ux.之后,将示例包表征输入由蓝色示意图表示的多层感知器中,得到隐写者和正常用户.在表1 中,给出了模型中使用的主要变量的介绍.

表1 使用的变量符号及对应说明Table 1 The variable symbols and their corresponding descriptions
2.1 基于多分类扩张残差网络进行示例表征
本文致力于设计新的隐写者检测方法,而对单张图像的表征,本文直接使用目前最前沿隐写者检测中的特征提取方法,即MDNNSD[7],来从每张分享图像中提取特征向量.具体来说,在Zheng 等[7]的工作中,使用包含特征提取器µ:Mcha×h×w(R)→M1×d(R) 和分类器π:M1×d(R)→M1×cls(R) 的多分类扩张残差网络.其中,c ha,h,w分别表示输入多分类扩张残差网络的图像的通道数、高度和宽度,d表示MDNNSD 提取的特征维度数,cls 表示MDNNSD 预测得到的样本属于某类的概率中的类别数.这里,本文使用MDNNSD 中的特征提取器µ对用户x分享的第i张图像Ii进行特征提取,得到用户x分享的第i张图像Ii的特征xi=µ(Ii).对于分享了n张图像的用户x,本文使用用户分享的所有图像对应的特征向量 {x1,···,xn} 共同构成用户x所对应的示例包的表征.
2.2 使用共性增强图卷积网络进行示例分析
隐写者嵌入秘密信息的过程中有多种批量隐写策略.对于固定的有效载荷,隐写者可能将有效载荷分散在多数分享图像中,以降低每张载密图像的嵌入信息量,从而降低被发现的可能;也可能挑选少数分享图像,集中嵌入秘密信息,通过大量的载体图像遮掩载密图像的存在.然而,现有的隐写者检测工作通常将用户分享的每张图像视为从相同分布中独立采样的个体,用户分享的所有图像的特征分布作为用户的特征表征,从而计算用户之间的差异并将异常用户作为隐写者.而当载密图像占比较小或是载密图像包含的嵌入信息较少时,隐写者的表征将与正常用户的表征极为相近,无法有效检测出隐写者.
为了解决该问题,依托于本文对隐写者检测的多示例学习的形式化,提出共性增强图卷积网络进行示例分析,利用批量图像间的相关关系增强用户表征中的正示例的模式特征.相关工作已经表明,在多示例学习任务中,示例包中的示例并不是独立存在的,每个示例都和包中的其他示例有千丝万缕的联系.对示例间的依赖关系进行建模,有利于提取并增强相互关联的正示例的共性特征,凸显出其与负示例共性特征的差异.在隐写者检测任务中,示例(用户所分享图像)相关关系无疑也是客观存在的,例如,隐写者传播的载密图像也可能共享相似的隐写方法或者有效载荷.利用这一特点,本文提出一种示例分析方法,增强示例包(用户)中正示例(载密图像) 的共有模式特征,使之与负示例(正常图像)的模式特征区分开,进而能够简化发现包含正示例的正示例包(隐写者)的任务.
然而,这些关联关系属于非欧的数据结构,无法使用基于欧氏空间的深度学习方法进行建模.因此,目前仍鲜有基于深度学习的相关工作利用这种关联关系完成多示例学习任务.
本文提出用图对这种数据结构进行表示,将包Bx中的示例 {x1,···,xn} 作为节点,将节点之间的关联关系建模为边,进而使用图卷积来处理节点间的关联信息.在此基础上,提出共性增强图卷积模块,并使用λb个共性增强图卷积模块对示例包中的示例进行分析.具体而言,共性增强图卷积模块的结构如图2(a)所示,下面将具体介绍共性增强图卷积模块的构成.
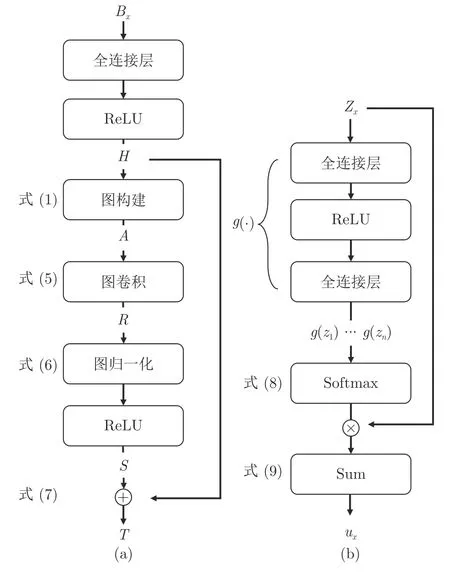
图2 隐写者检测框架中两个模块((a) 共性增强图卷积模块;(b) 注意力读出模块)Fig.2 Two modules in steganographer detection framework ((a) The commonness enhancement graph convolutional network module;(b) The attention readout module)
1) 构建示例包的图结构
共性增强图卷积模块的第一步是构建示例包的图结构.示例包的图结构可以分为两部分: 一部分是选取示例表征中与特定模式相关的特征作为图结构中的图节点,另一部分是根据图节点之间的关联关系创建图结构中的边.只有构建的图结构准确表达示例间关联关系时,图卷积模块才能利用示例间的关联关系完成学习任务.
目前,图卷积领域的研究已经在图构建问题上取得了一定进展,大多数工作将给定的特征向量作为节点,致力于针对节点特征提出相似度度量方法,例如欧氏距离、余弦相似度、热核函数等方法,从而构建节点间的边.然而,相似度度量方法的设计往往依赖于先验知识和专家系统,面对复杂多样的数据特征,很难通过事先设计来表达不同语义、含义抽象的多种关联关系.因此,本文提出一种可学习的节点表征和相似度度量方法,通过反向传播训练模型自适应地构建图结构.
具体而言,对于共性增强图卷积模块的第i个输入示例特征vi,首先设计特征提取函数f:M1×d(R)→M1×d′(R) 对d维特征向量vi进行变换,得到d′维特征向量hi=f(vi) 作为节点i的特征表示.其中,特征提取函数f包括一个全连接层和一个线性整流单元(Rectified linear unit,ReLU).在训练过程中,通过优化函数f中的参数,模型将自适应地提取vi中与检测目标相关的模式特征.
接着,使用向量内积计算不同节点中与任务相关的模式特征的交互,作为节点间关联关系的表征.具体来说,对于节点i和节点j,使用f(vi)fT(vj) 表示节点之间的关联关系,并且使用Sigmoid 函数将其归一化到(0,1)范围内.数学上,对于一个有n个示例的示例包,本文使用n×n维的邻接矩阵A表示图结构中的边.对于不同示例之间可能存在不同程度的关联关系,本文使用Aij表示边的权重
由上式可知,Aij是一个0 到1 之间的实数,其中0表示示例i与示例j完全不相关,而1 表示两节点完全相关.
2) 利用图卷积聚合示例间的共性特征
共性增强图卷积模块的第二步是根据步骤1)中构建的图结构,对示例包中的示例进行卷积运算,聚合当前示例和具有相近模式特征的示例,并提取公共的模式特征.
参照现有图卷积领域的研究成果[12],本文类比欧氏空间中的卷积运算定义了示例包对应的图结构上的卷积运算.具体而言,将与当前示例节点处于同一包内的其他示例节点定义为卷积运算的邻域.接着,使用上文中计算得到的示例节点之间边的权重作为权,对邻域内的示例节点的特征向量进行加权平均,将得到的新特征向量作为当前示例节点的表征.由式(1) 可知,与当前节点模式特征相关联的邻居节点将具有更大的权重.为了在卷积运算中保留当前节点自身的特征,本文在卷积运算的基础上,以常数 1 作为权重,为当前节点添加了自环,共同参与卷积运算.最终,节点i的聚合结果ri可以由下式计算得到
其中,Ni表示节点i的一阶邻居节点.不难发现,式(2)等价于
其中,H表示用户分享图像的特征构成的矩阵,R为聚合后的特征矩阵.在式(3)中,如果示例节点i与示例包中的较多示例相关,那么ri将会较大.否则,如果示例节点i与其他示例节点都不相关,那么ri将会较小.相关工作表明,在这种情况下,特征矩阵H与邻接矩阵A相乘会使得特征向量hi的尺度发生变化.经过多次卷积之后,这种数值变化可能会造成数值不稳定、梯度爆炸或弥散等问题.因此,本文限制了hi的数值区间,并对聚合结果进行归一化.在式(3)的基础上,卷积层被形式化为
其中,D是图上的度矩阵,,通过使用度矩阵进行对称归一化,能够消除示例包中与当前示例相关的数量对卷积运算结果的数值范围产生的影响,从而有利于模型收敛.
最后,参照现有图卷积领域的研究成果[12],本文类比欧氏空间中卷积运算的权重共享机制,使用一个参数矩阵W对聚合结果进行仿射变换,提取聚合结果中与隐写者检测相关的示例间共享的模式特征,数学上可以表示为
其中,W表示对聚合结果进行仿射变换的可训练的参数矩阵,特别地,本文使用Xavier 方法对其进行了初始化.
3) 使用图归一化解决深层图卷积过平滑问题
相比于单层图卷积网络,多层图卷积网络能够显著地大幅度提高模型性能.然而,多层图卷积会导致输出的特征产生过平滑的问题,使得不同类别的节点特征变得不可区分.在深度学习领域中,现有工作普遍认为归一化技术能够有效解决深层网络的训练问题.其中,批量归一化被广泛应用在深度学习模型中,在批量维度进行归一化操作.然而,这些方法无法被直接应用在图卷积网络中.近年来,一些现有工作提出了图上的归一化方法.目前,图归一化被认为能够有效地抑制深层图卷积过程中的过平滑问题.因此,本文使用一种用于多示例学习的新型图归一化方法.
一方面,本文不希望在图卷积运算后,示例包内的节点表征趋于一致,即示例包内的节点的特征分布塌缩到向量空间中的一点,因此本文提出在图卷积运算后对包内示例节点的特征分布进行重整,重新将示例包中示例的特征向量缩放到模长为1 的向量空间内.另一方面,为防止均值偏移过大导致出现神经元坏死现象,本文同时矫正示例特征向量所处向量空间的均值.数学上,归一化后的示例节点的特征向量si可以表示为
其中,Ni为图中第i个示例节点的所有邻居节点.
实验过程中发现,在多示例学习中,示例包内示例特征的均值信息和尺度信息分别独立地对模型性能产生影响.在一个示例包内,当所有或大多数示例的特征向量都带有正示例的模式或者负示例的模式时,示例特征的均值能够有效帮助区分该示例包.在一个示例包内,当其同时包含数量相当的正示例和负示例时,示例包内示例特征的方差较大,则说明示例包内同时包含两种示例,即必然包含正示例,因此示例包的方差也能够有效区分该示例包.综合上述两点,相比于传统的先进行均值归一化,再将均值归一化的结果进行尺度归一化的图归一化方法,本文将均值归一化和尺度归一化解耦,同时基于输入节点特征向量rj进行归一化.
接着,本文使用ReLU 对示例包内归一化后的示例节点特征si进行激活,得到示例包和示例表征,S=[ReLU(s1),···,ReLU(sn)]T.
4) 使用残差连接计算新的示例表征
由于图像内容的差异,图中的一些节点与其他同类节点特征的相似度较小,因此,其对应的特征可能会在多层卷积中丢失.为缓解该问题,本文参照相关工作构建一个残差连接层,将共性增强图卷积模块的输入特征H直接与图归一化的输出特征S相连.数学上,可以将残差连接层定义为
其中,T表示残差连接操作的输出特征矩阵,T=[t1,···,tn]T,其中ti为共性增强图卷积模块输出的第i个示例特征.
2.3 基于注意力的示例包表征
在使用共性增强图卷积网络进行示例分析后,为对示例包进行正确检测,还需要根据示例特征构建示例包的特征表示.本文将用户x经过共性增强图卷积模块的输出表示为Zx=[z1,···,zn]T.其中,zi对应于第i张图片进行示例分析后的特征表示.现有的隐写者检测工作通常将用户分享的每张图片视为同等重要的个体,根据用户分享的所有图像的特征分布作为用户的特征分布,计算用户之间的差异并检测异常用户作为隐写者.然而,在载密图像占比较小或是载密图像包含的嵌入信息较少的情况下,隐写者的表征将与正常用户的表征极为相近,无法有效检测出隐写者.
为解决该问题,本文依托对隐写者检测任务的多示例学习形式化,提出注意力示例包表征模块,自适应地构建更具有区分力的示例包表征.与多示例学习的定义一致,只要示例包中包含至少一个正示例,该示例包就应当被判定为正示例包.因此,带有正示例模式特征的示例包,在表征和示例包检测的过程中应当被予以更多的关注.基于上述考虑,本文设计注意力读出模块(图2(b)),根据示例中包含的正负示例模式对示例包中的示例赋予不同权值,形成示例包的表征.
为自适应地识别示例包中符合正示例模式特征的示例,并对其施加更显著的注意力,本文使用注意力计算函数g(·) 来根据示例的特征分布计算其对应示例在示例包表征过程中的重要程度.其中注意力计算函数g(·) 包括两个全连接层,在第一个全连接层后,使用ReLU 作为激活函数.在训练过程中,模型通过调整g(·) 中的训练参数,将能够针对符合正示例模式特征的示例输出更高的数值.
在此基础上,使用Softmax 函数对示例包中所有示例的重要程度进行归一化,得到每个示例在表征示例包过程中的权重得分pi
接着,使用式(8)中计算得到的权重值作为权,以示例包中每个示例特征的加权平均作为示例包的表征ux
相比于现有工作中使用平均、合并等方法建立的示例包表征,本文提出的示例包表征方法能够自适应地学习并对正示例赋予更高的权重,从而提高示例包表征的区分能力.
2.4 基于多种损失约束的示例包分类
在得到基于注意力的示例包表征ux之后,将其送入由一个全连接层和一个Softmax 激活函数构成的分类器,最终完成示例包的分类任务.需要注意的是,本文提出的模型其训练过程和测试过程有所不同,在训练过程中,以示例包的分类作为目标,而在测试的过程中,采用与以往隐写者检测一致的实验设置,即将预测的隐写者概率最高的用户作为隐写者输出.
本文设计的模型MILGCN 在优化过程中是端到端的,即,使用多个损失函数加权求和,并将得到的损失进行反向传播,更新网络中的所有模块.在训练分类模型的过程中,所使用的损失函数由三部分构成
其中,Lbag为多示例分类损失,Lentropy为熵正则损失,Lcontrastive为对比学习损失.λ1,λ2,λ3为三个超参数,分别表示多示例分类损失、熵正则损失和对比学习损失作为训练目标的权重.下面分别介绍三个损失函数.
多示例分类损失: 多示例分类损失用于指导模型对隐写者和正常用户进行正确分类.复杂的样本特征可能会导致这些示例(图像)的预测结果有较大偏差,对于最终分类结果的意义有限,并不能得到令人满意的包的预测结果.与此相反,相比于注重示例的准确性,多示例学习更注重包的预测标签是否符合真实标签.因此,本文提出一个多示例分类损失来优化图卷积神经网络.如式(11)所示,使用包(用户)的二分类逻辑损失来优化模型,使最终输出结果能够对隐写者和正常用户进行分类
其中,Yi表示第i个用户(包)的标签,模型预测其为隐写者的概率为ρi,m表示用户(包)的总数量.多示例分类损失忽略单个示例类别的不确定性,而更重视全局信息,这增强了整个框架的鲁棒性.
熵正则损失: 熵正则损失用于指导模型在根据示例表征构建示例包表征的过程中,利用先验信息抓取带有正示例模式特征的示例,构建示例包的表征.现有的隐写者检测相关工作已经表明,隐写者在分享图像和嵌入秘密信息的过程中有多种策略选择.对于固定的有效载荷,隐写者可能将有效载荷分散在多数分享图像中,每张载密图像的嵌入信息较少,这时,关注尽可能多的分享图像,即使用分享图像特征的均值作为用户表征能够更有效地检测隐写者.隐写者也可能将有效载荷分散在少数分享图像中,每张载密图像的嵌入信息较多,这时,关注尽可能少的分享图像,使用最有嫌疑的图像特征作为用户表征则更为高效.
尽管本文设计的注意力模块能够自适应地学习攻击不同的隐写策略,能够通过学习判别应当关注的示例,但是,当隐写者检测人员明确知晓训练集合中隐写者使用的嵌入策略时,本文也提供了损失函数融入隐写者检测人员对于嵌入策略的先验知识,帮助模型更快收敛,提升模型性能
其中,λe为超参数,当隐写者检测人员认为隐写者更可能将有效载荷分散在较少的分享图像中时,λe将被设置成+1.通过最小化Lentropy,模型将学习给出低熵的示例包构建方式,即,以更大的概率对尽可能少的正示例赋予更大权重,作为示例包的表征.这种损失设计有利于模型在正示例占比较低时,仍能分辨出其中正示例的模式特征.反之,当隐写者检测人员认为隐写者更可能将秘密信息以较低有效载荷分散在较多的分享图像中时,λe将被设置成-1.通过最小化Lentropy,模型将学习给出高熵的示例包构建方式,即,使用尽可能多的正示例特征相互佐证,检测隐写者.
对比学习损失: 对比学习损失用于引导模型在提取示例特征、构建示例包的过程中,尽量保留示例间的关联关系和差异性.对比学习旨在将包含同类模式特征(例如正示例特征)的示例表征映射到向量空间中相近的区域,对包含不同类别模式特征的示例表征进行区分,映射到相距较远的区域,从而帮助构建有效的图结构进行示例分析和示例包表征.
正如上文中提到的,由于图像特征的复杂性,直接对示例的模式特征进行约束可能会导致因图像内容的差异而得到不令人满意的映射函数.因此,相比于直接使用示例特征进行引导,本文受到多示例学习的启发,通过引导模型保留同类示例包间的相似性、不同类示例包间的差异性,间接地迫使模型保留作为示例包组成部分的主要示例特征间的相似性和差异性.最终,提出对比学习损失
其中,ϕ(i,j) 为指示函数,用于指示示例包i和示例包j是否为同一类别的示例包.当示例包i和示例包j同时为正示例包或负示例包时,ϕ(i,j)=1;当示例包i和示例包j中的一个为正示例包、一个为负示例包时,ϕ(i,j)=0.当示例包属于同一类别时,对比学习损失最小化两示例包表征间的欧氏距离‖ui-uj‖2,提高同类示例包特征及其包含示例特征的相似性.当示例包不属于同一类别时,对比学习损失最小化两示例包表征间的欧氏距离的相反数-‖ui-uj‖2,提高不同类别示例包特征及其包含示例特征的差异性.因此该损失可以最大化不同类别示例包间的差异,最小化相同类别示例包间的差异,以区分不同类别的示例和示例包.
3 实验评估
为验证所提出的模型,本文在两个隐写者检测基准数据集上进行一系列验证实验.首先,使用隐写者检测基准数据集对所提出的MILGCN 模型在隐写者使用不同隐写术时的检测性能进行验证.在空域中,本文在标准数据集BOSSbase ver 1.01[20]上进行实验,对不同方法检测使用空域隐写术的隐写者的性能进行对比分析.在频域中,使用JPEG算法在80 质量因子的参数下对BOSSbase ver 1.01上的图像进行压缩,将其中的图像转换为JPEG 图像,并在得到的BOSSbase ver 1.01 JPEG 基准数据集上进行实验[21],对不同方法检测使用频域隐写术的隐写者的性能进行对比分析.与之前隐写者检测的已有工作一致,本文使用的方法和对比方法都采用真阳性率进行评估.
本文在实验过程中对比分析了大量不同隐写者检测算法.其中包括: 结合传统隐写分析模型SRMQ1[22]与层次聚类的隐写者检测框架SRMQ1_SD,目前最前沿的隐写者检测方法MDNNSD,结合基于生成对抗网络(Generative adversarial network,GAN) 的隐写方法SSGAN[23]与层次聚类的隐写者检测框架得出的SSGAN_SD,多示例学习任务中的前沿方法MILNN[24],著名的基于图的模型GAT[15]、GraphSAGE[13]、AGNN[25]、GCN[12]和DiffPool[14],以及迄今为止唯一用于隐写者检测任务的基于图的深度学习模型SAGCN.其中,MDNNSD 是基于深度学习提取特征,再与传统的聚类方法结合的隐写者检测方法[7].相比于其他现有隐写者检测方法,例如PEV_SD 和基于最前沿隐写分析方法XuNet[26]构建的隐写者检测框架XuNet_SD,MDNNSD 取得了最好的隐写者检测性能.因此,本文选取MSD 作为代表,进行着重的对比分析.近年来,基于GAN 的隐写术和隐写分析技术取得了巨大的成功,因此,本文将已有的基于GAN 的隐写方法SSGAN 与层次聚类的隐写者检测方法结合,得到隐写者检测框架SSGAN_SD,来对本文提出的模型与基于GAN 的隐写者检测模型进行对比.特别地,在对比过程中,本文使用GAN 方法学习得到的判别器被用作特征提取器,用来从用户分享的图像中提取隐写分析特征,并在此基础上使用MMD 距离度量用户表征之间的差异,并使用层次分析算法来检测隐写者.为说明本文设计的MILGCN 在图结构和图卷积方向上的性能提升,本文对比了Zhang 等[8-9]设计的SAGCN 模型,并使用著名的基于图的方法(例如GAT、GraphSAGE、AGNN、GCN 和DiffPool) 中的图卷积层替换SAGCN框架中的核心部分——相似度累积图卷积单元,来与其他基于图的深度学习算法进行比较.
就实验设置而言,在对本文提出的网络结构进行验证时,将MILGCN 中共性增强图卷积模块的数量λb设置为2 个,并使用λ1=1.0 作为多示例分类损失的权重,λ2=0.01 作为熵正则损失的权重,λ3=0.01作为对比学习损失的权重.这三种损失函数的权重设置遵循重要性原则,多示例分类损失是为之后的检测服务的,是本文的任务目标,因此其权重比其他两种大.另外,将权重值在{-10,-1,-0.10,-0.01, 0.01, 0.10, 1, 10}范围中进行搜索,选取较好的结果.在训练阶段,本文使用随机梯度下降法来最小化损失函数,初始学习率设置为0.001,动量设置为0.9.本文还使用L2 正则化以避免过拟合并提高泛化能力,并将正则化项的权重设置为0.01.本文的实验设置与基于图卷积的隐写者检测方法SAGCN[8-9]基本相同,唯一的区别是本文中设计的MILGCN 模型无须使用序列训练方法,即可有效收敛并检测使用不同有效载荷的隐写者.在实验过程中,给定基准数据集BOSSbase ver 1.01 和BOSSbase ver 1.01 JPEG,首先使用实验中所探究的隐写术,从0.5 到0.05 的嵌入率,生成载体图像对应的载密图像.对于每种嵌入率,分别有20 000张载体图像和载密图像.每个批次的训练中生成50 个正常用户,每个用户分享200 张从20 000 张载体图像中有放回抽样得到的载体图像;生成50 个隐写者,每个隐写者分享200 张从20 000 张载密图像中有放回抽样得到的载密图像.本文在训练集上训练80 轮,每轮训练包含600 个批次,每个批次包含100 个用户样本,因此共60 000 个用户混合在一起随机打乱,作为训练集训练MILGCN.在测试阶段,每次实验中的用户数量被设置为100,包括1 名隐写者和99 名正常用户,每个用户分享200 张图像.该实验设置模拟了真实环境中经常出现的现象,即在众多用户中只有1 名隐写者或者不存在隐写者.在不同实验中,使用不同的隐写术和有效载荷生成隐写者分享的载密图像,使用的隐写术包括: SUNIWARD[27]、HUGO-BD[28]、WOW[29]、MiPod[30]、J-UNIWARD[27]、nsF5[31]、UERD[32]等.与之前已有的隐写者检测工作一致,所有的统计实验都重复100 次,并在文中汇报平均的检测准确率,即真阳率.衡量嵌入率的单位分为空域的bpp (Bit per pixel)和频率域的bpnzAC (Bit per non zero DCT coefcient),前者表示每像素嵌入的比特数,后者表示每个非零的DCT 系数中嵌入的比特数.此外,本文中的全部模型及实验使用PyTorch 在4 张Tesla V100上完成.
3.1 基于空域的隐写者检测性能评估与对比
3.1.1 已知隐写术情况下的隐写者检测
在本节中,本文在最常使用的隐写者检测基准数据集BOSSbase ver 1.01 上进行初步实验,在已知测试阶段图像隐写者所使用的隐写术的条件下,对所提出的模型的效率和效果进行检验.具体而言,隐写者检测基准数据集BOSSbase ver 1.01 中包含10 000 张自然图像的灰度图,其尺寸为512×512像素.根据之前隐写分析和隐写者检测任务的通用实验设置[7-9,33],本文将数据集中的每张图像切分为4 个互相不重叠子图,其中子图的尺寸为256×256像素.与前文描述的将所有载荷的样本进行训练不同,在此实验的训练阶段,只使用S-UNIWARD 隐写术在给定有效载荷下对每张载体图像嵌入秘密信息得到对应的载密图像,进而将得到的载体图像和载密图像组合为用户作为训练样本.在训练阶段的每个批次中,本文采样50 名正常用户,每名正常用户分享200 张载体图像,并采样50 名隐写者,每名隐写者分享200 张载密图像,每轮训练采样100 个批次的用户对模型进行优化.
同样地,测试样本由剩余的20 000 张图像使用同样的方法构成.在测试阶段的每次实验中,被测方法被要求从100 名用户中检测出1 名隐写者.特别地,本文在20 000 张载体图像中随机选择200 张载体图像对应的载密图像,构成1 名图像隐写者,剩余的19 800 张载体图像被随机选择并分配给99个正常用户.为验证在隐写者检测人员已知隐写者使用的图像隐写术时本文提出方法的有效性,在本节实验中保持测试阶段隐写者使用的图像隐写术与训练阶段相同.即,在训练阶段,本文隐写者使用SUNIWARD 作为图像隐写术嵌入秘密信息生成载密图像,在生成的60 000 个用户中,隐写者使用的有效载荷包括0.05 bpp、0.1 bpp、0.2 bpp、0.3 bpp、0.4 bpp 和0.5 bpp.在测试阶段,隐写者分享的每张图像中同样只包含使用S-UNIWARD 图像隐写术嵌入的秘密信息.本文分别在5 种不同的有效载荷上进行测试,其中包括0.05 bpp、0.1 bpp、0.2 bpp、0.3 bpp 和0.4 bpp.
如表2 所示,本文首先对比隐写者检测中的相关工作.根据相关工作[7],MDNNSD 和XuNet_SD这些隐写分析方法直接用于隐写者检测任务的检测结果对比,会取得更好的检测效果.然而,与现有的在实验环境中进行研究的隐写者检测任务不同,在实际应用中,图像隐写者通常会使用批量隐写术,将秘密信息分散在多张图像中,使用较小的嵌入率在每张图像中嵌入秘密信息,从而隐蔽自己.所以本文更关注在困难情况下,即当有效载荷较低时,不同方法是否能够检测出图像隐写者.因此,本文进一步对比图卷积神经网络在隐写者检测中的应用效果.正如上文所提到的,当有效载荷小于0.1 bpp时,SAGCN、MILGCN 和其他基于图深度学习的模型都能够取得比MDNNSD 更好的性能.与之相对的是,本文提出的MILGCN 进一步超越了SAGCN,在有效载荷为0.05 bpp 的困难情况下取得了更好的隐写者检测效果.尽管生成对抗网络在很多领域取得了突破进展[34-41],但SSGAN_SD 效果较差,这主要是因为SSGAN 原本设计的目的是通过对抗训练得到一种自适应的隐写术而不是得到隐写分析模型,因此在设计过程中,相对于其他工作,SSGAN_SD 的判别器结构简单、判别能力差.
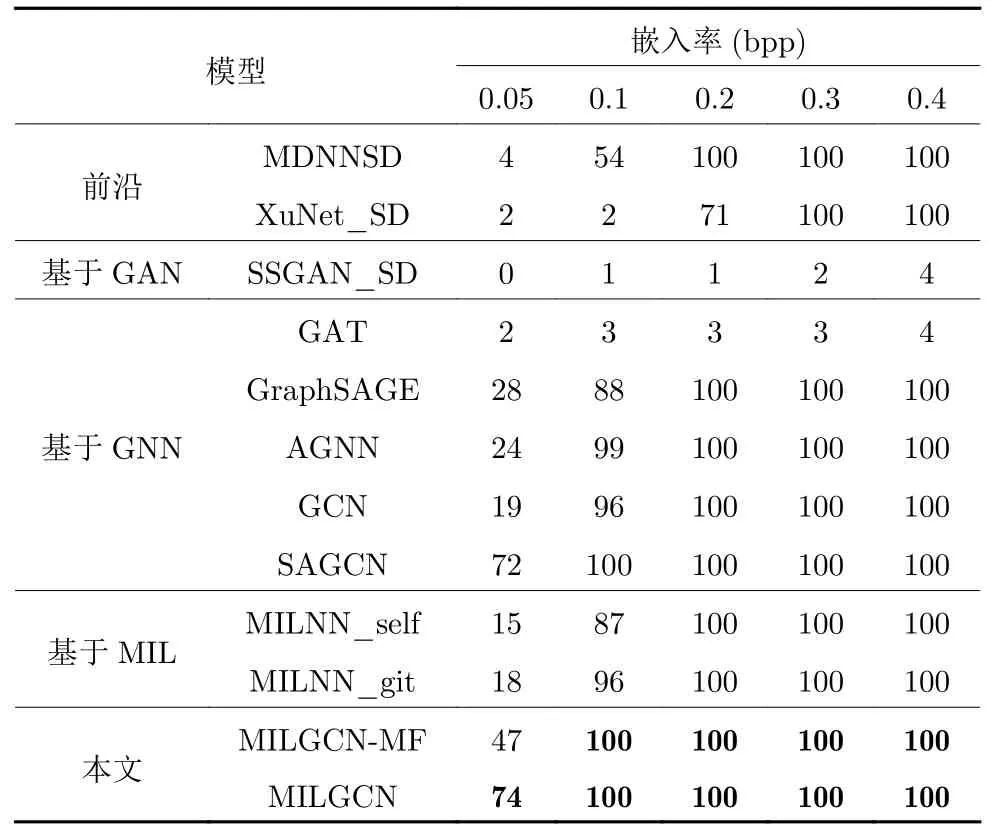
表2 已知隐写者使用相同图像隐写术(S-UNIWARD) 时的隐写者检测准确率(%),嵌入率从0.05 bpp 到0.4 bppTable 2 Steganography detection accuracy rate (%)when steganographers use the same image steganography(S-UNIWARD),while the embedding payload is from 0.05 bpp to 0.4 bpp
正如上文所提到的,本文创新性地提出将隐写者检测任务形式化为多示例学习问题,从而开辟了将现有多示例学习方法应用于隐写者检测任务的路径.因此,本文进一步将此前Pevný 等[24]提出的最优的多示例学习神经网络应用在隐写者检测问题中进行对比.具体而言,一方面,本文沿用Pevný 等[24]在论文中汇报的设置,自行在隐写者检测问题上复现其提出的方法,将该方法称为MILNN-self,并提供了MILNN-self 的隐写者检测性能.另一方面,本文也参考并应用Github 社区中实现的Pevný 等[24]提出的方法,并提供了其在隐写者检测任务上的实验结果,后者称其为MILNN-git.值得注意的是,MILNN-git 中的模型实现与Pevný 等[24]的工作略有不同,其模型包含了一个隐藏层、一个平均最大池化层和两个输出单元,除了最后一个输出单元使用Tanh 作为激活函数外,所有隐藏层使用Sigmoid作为激活函数,模型在训练过程中最小化交叉熵损失.实验结果表明,MILNN-git 能够在隐写者检测问题上取得比MDNNSD 更好的效果.同时,无论隐写者使用的有效载荷如何变化,本文提出的多示例学习图卷积网络都强于任何版本的MILNN 多示例学习模型.
除此以外,本文还比较了传统图归一化方法和本文提出的新型图归一化方法.具体而言,将本文中使用的归一化方法修改为传统图归一化方法(即先进行均值归一化再将均值归一化的结果进行尺度归一化),得到MILGCN-MF 模型作为对比方法.从表2 中可以看出,在隐写者使用的有效载荷较高时(大于等于0.1 bpp),MILGCN-MF 和MILGCN 的性能没有差异,都能够有效检测出100 名用户中包含的隐写者,这表明在简单情况下,两种归一化方法都能够有效地帮助模型构建具有区分能力的示例表征.但是,当有效载荷较低时(为0.05 bpp),MILGCN-MF 的性能产生了约 30% 的下滑.当隐写者分享的有效载荷较低时,正示例包和负示例包分布相近,特征差异不明显.在这种情况下,使用原有的图归一化方法导致性能下降,意味着先进行均值归一化再进行方差归一化使得部分特征的区分能力丢失.与此相对,本文提出的图归一化方法能够记录原始特征中的均值和方差,在归一化的过程中保留和识别特征分布间的差异,得到更好的检测效果.
最近还有一些新的隐写分析方法被提出,如果不采用层次聚类的方法将其改造为隐写者检测方法,而是使用其隐写分析模型的输出概率作为每张图像是载密图像的概率,并使用用户的所有图像预测为载密图像的平均概率作为该用户为隐写者的概率,也可以得到与最新的隐写分析方法相比较的结果.具体而言,在训练阶段,隐写者使用S-UNIWARD作为图像隐写术,隐写者检测模型学习在正常用户中检测使用0.2 bpp 嵌入率对分享图像嵌入秘密信息的隐写者.这里,隐写者分享的图像均为载密图像,正常用户分享的图像均为载体图像.在测试阶段,模型需要从100 名用户中找出1 名隐写者.其中,每名用户分享200 张图像,隐写者仍然使用SUNIWARD 作为图像隐写术,使用0.2 bpp 嵌入率对分享图像嵌入秘密信息.根据实验的不同,隐写者分享的载密图像可能占比其分享的所有图像的10%、3 0%、5 0%、9 0% 或 1 00%.本文进行100 次实验,并记录模型在隐写者检测过程中的平均准确率,如表3 所示.在SRNet-AVG 方法中,本文将SRNet[42]直接用于隐写者检测,预测用户分享的每一张图像可能是载密图像的概率,并使用该用户的每一张图像预测为载密图像的平均概率作为该用户为隐写者的概率.在SRNet-MILGCN 方法中,使用本文提出的MILGCN 作为隐写者检测算法,将SRNet 提取的特征作为MILGCN 的输入预测用户为隐写者的概率.由表3 可见,无论使用哪种方法,模型都能够在载密图像占比超过 1 0% 的情况下有效检测出隐写者.这是由于隐写者使用的隐写术和有效载荷已知,训练好的SRNet 能够较为准确地检测出使用该隐写术和载荷嵌入秘密信息的载密图像.当隐写者分享的载密图像较多时,数量众多的载密图像容易被SRNet 检测到,从而使得隐写者区别于正常用户.而当载密图像占其分享的所有图像比例较低时,SRNet-AVG 和SRNet-MILGCN 都产生了较大的性能下滑,相比于SRNet-AVG,本文提出的SRNet-MILGCN 取得了接近 1 0% 的性能提升,表明本文设计的模型能够更好地对抗将隐秘信息嵌入较少图像的批量隐写策略.这是由于MILGCN 能够利用共性增强图卷积网络和注意力图读出模块自适应地突出示例包中正示例的模式特征,构建示例包表征进行分类.在这种设计下,正示例所对应的载密图像的模式特征更容易被模型发现.
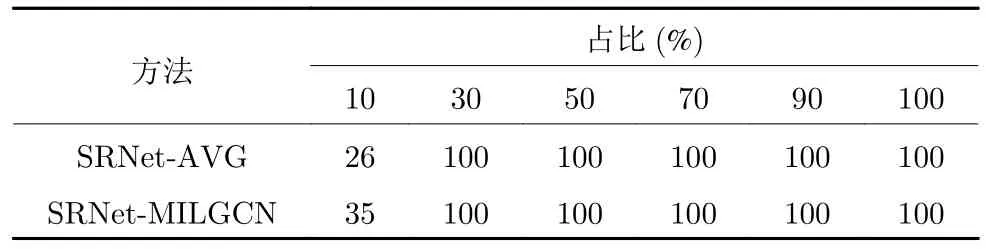
表3 当测试阶段隐写者使用相同隐写术(S-UNIWARD)和分享的载密图像数量占总图像数量为10%到100%时,SRNet-AVG 和SRNet-MILGCN 的检测成功率 (%)Table 3 The accurate rate (%) of SRNet-AVG and SRNet-MILGCN when the number of shared secret images is from 10% to 100% of the total number of images and the steganographer uses the same steganography(S-UNIWARD) in test
3.1.2 对用户分享图像数量变化的探究
在真实应用场景的社交网络中,用户分享的图像数量是海量的.因此,本文进一步松弛现有工作在实验中对用户分享的图像数量的约束,在隐写者检测任务上进行实验来研究用户分享的图像数量对隐写者检测性能的影响.具体而言,本节保持其他设置与第3.1.1 节中的实验设置相同,验证当用户分享图像的数量为100、200、400 和600 张时,模型检测使用不同有效载荷在分享图像中嵌入秘密信息的隐写者的性能.
如表4 所示,当隐写者使用大于0.1 bpp 的有效载荷在分享图像中嵌入秘密信息时,无论隐写者分享的图像数量如何变化,本文提出的MILGCN和Zhang 等[8-9]设计的SAGCN 都能够准确地检测出隐写者,这说明本文提出的方法对用户分享图像数量的变化具有鲁棒性.当有效载荷等于或小于0.1 bpp 时,发现所有方法对隐写者的检测性能随着用户分享图像数量的减少而下降.这种现象是由于当隐写者分享的图像数量或有效载荷较少时,隐写者在分享图像中嵌入的秘密信息的总量较少,这使得隐写者的特征分布与正常用户的特征分布差异较小,更加难以区分.同时,由于隐写者和用户都分享了较少的图像,图像数量的不足使得图像间的关联信息十分有限,模型难以利用这些关联关系增强用户所对应的示例包中正示例的公共特征,进而导致模型无法区分隐写者与众多正常的用户.
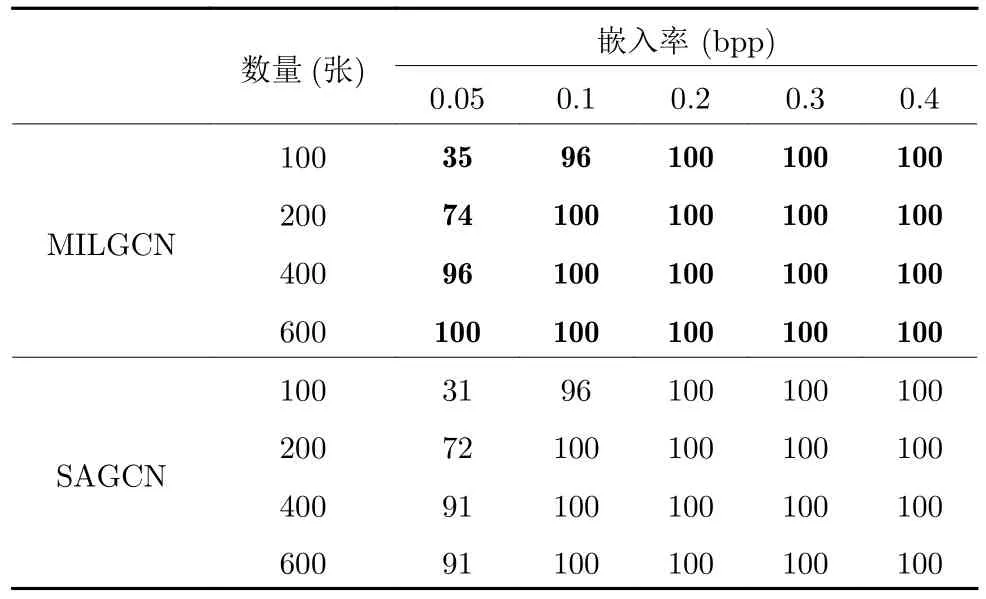
表4 当用户分享不同数量的图像时,使用MILGCN和SAGCN 进行隐写者检测的准确率(%),嵌入率从0.05 bpp 到0.4 bppTable 4 Steganography detection accuracy rate (%)of MILGCN and SAGCN when users share different numbers of images,while the embedding payload is from 0.05 bpp to 0.4 bpp
尽管如此,无论用户分享的图像数量如何变化,本文设计的MILGCN 都能够超过此前最佳隐写者检测算法SAGCN,取得令人满意的效果.值得注意的是,当用户分享的图像数量为600 张时,即使隐写者使用非常低的有效载荷,即0.05 bpp 的有效载荷嵌入秘密信息,本文提出的MILGCN 依然能够聚合分散在示例包中正示例的模式特征,对用户形成具有区分能力的示例包表征,并对隐写者进行正确检测.
3.1.3 隐写术未知情况下对使用比例嵌入策略的隐写者检测
在本节中,进一步放宽两个基础假设.一方面,检测者在对社交网络中用户分享的图像进行分析时,无法预知隐写者使用的图像隐写术.因此,本文放宽了图像隐写者在训练阶段和测试阶段使用的图像隐写术为相同隐写术的假设,探讨在隐写术错配情况下本文提出模型的隐写者检测性能.另一方面,在真实应用场景中,隐写者可能使用批量图像隐写策略,在分享的图像中同时分享载体图像和载密图像以防止自己被发现.因此,本文放宽了隐写者分享的图像都是载密图像的假设,探究隐写者分享的图像中载密图像占某一比例时模型的隐写者检测性能.
具体而言,在训练阶段,隐写者仍使用S-UNIWARD 作为图像隐写术.S-UNIWARD 在隐写、隐写分析、隐写者检测任务中被认为是更为通用的设置,常常用来作为训练模型中载密数据所使用的隐写术,在本文对比方法SAGCN 中,也采用其作为隐写术未知情况下的实验设置.隐写者检测模型学习在正常用户中检测使用0.5 bpp、0.4 bpp、0.3 bpp、0.2 bpp、0.1 bpp 或0.05 bpp 嵌入率对分享图像嵌入秘密信息的隐写者.这里,隐写者分享的图像均为载密图像,正常用户分享的图像均为载体图像.
在测试阶段,隐写者将其使用的图像隐写术替换为与训练阶段不同的隐写术,特别地,本文中研究探讨的错配隐写术包括现阶段图像隐写术和隐写者检测领域普遍使用的HUGO-BD、WOW、HILL和MiPOD 等.在每次实验中,模型需要从100 名用户中找出1 名隐写者.其中,每名用户分享200张图像,隐写者使用的有效载荷为0.2 bpp,根据实验的不同,隐写者分享的载密图像可能占比其分享的所有图像的 1 0%、3 0%、5 0%、9 0% 或 1 00%.本文进行100 次实验,并记录模型在检测隐写者过程中的平均准确率.
图3 展示了当隐写者在测试阶段使用不同图像隐写术时不同方法检测隐写者的性能.容易发现,在图像隐写术错配的情况下,无论隐写者选择使用何种图像隐写术,当隐写者分享的载密图像占其分享图像的数量 1 00% 时,所有基于图的模型都能够正确检测出隐写者.此外,还可以发现所有隐写者检测方法的性能都随着隐写者分享的载密图像占比的升高而升高,这是由于当隐写者分享的载密图像占比较低时,隐写者分享的图像大部分为自然图像,即载体图像,在这种情况下,隐写者的表征将与正常用户非常接近,模型难以正确区分隐写者和正常用户.然而,即使在隐写者分享的载密图像占比低于 5 0% 的情况下,本文提出的MILGCN 依然能够取得较好的效果.特别的是,在大多数情况下,MILGCN 的检测准确率曲线覆盖了其他方法的检测准确率曲线,这说明MILGCN 能够取得比SAGCN及其他基于图的隐写者检测方法更好的性能.这是由于本文提出的MILGCN 是针对隐写者检测问题的多示例学习形式化提出的,在设计过程中考虑了正示例占比较低的情况,能够使用共性增强图卷积网络来增强示例包中正示例的公共模式特征,并使用基于注意力的示例包表示选择识别到的正示例模式特征作为示例包表征,从而区分正负示例包.实验结果表明,本文提出的方法对不同隐写术具有良好的泛化性,在隐写者分享的载密图像占比较低时也能取得较好的检测性能.从图3 中还可以发现,GCN 的性能稍差于SAGCN,而当隐写者分享的载密图像占比较低时,AGNN 检测隐写者的准确率都是最低的,这种差异源自于图结构的构建方式不同.MILGCN 依托于示例节点特征间的内积计算节点的关联关系,在损失函数约束下,正示例的特征分布相近,并与负示例的特征分布区分开,因而具有共性的示例节点关联关系更强,在此基础上,在图卷积过程中,正示例间的共性特征被增强,从而使得模型能够构建具备区分力的用户表征.而GCN和SAGCN 基于热核函数计算节点之间的相似度,当隐写者分享的图像中同时包含载体图像和载密图像时,载密图像和载体图像所对应图结构中的节点特征相似度较小,而载密图像之间或载体图像之间的节点特征相似度较大,在图卷积过程中,相似的节点可以识别和累积载密图像节点间共有的模式特征,从而区分隐写者和正常用户的分布差异.与之相反的是,AGNN 在构建图的过程中,利用的是注意力机制,在训练过程中,隐写者分享的图像均为载密图像,这导致AGNN 缺少对构建载体图像与载密图像关联关系的泛化能力,因而性能下降.此外,GraphSAGE 使用采样方法和平均聚合器来构建节点的邻域并进行卷积运算,如果载体图像与载密图像之间差异较大,其能够学习到边的权重,累积同类节点的特征.但对于譬如HILL 这样难以攻击的隐写术,载密图像与载体图像之间特征分布相近,所以GraphSAGE 的效果也会有所下降,而本文提出的MILGCN 泛化性能最好.

图3 当测试阶段隐写者使用不同隐写术、分享的载密图像数量占总图像数量的10%到100%时,不同的基于图的隐写者检测方法检测准确率Fig.3 The accurate rate of different graph-based steganographer detection methods when the number of shared secret images is from 10% to 100% of the total number of images and the steganographer uses different steganography in test
除此以外,探讨一下本文的方法在什么比例下将完全失效.首先对“完全失效”进行定义,当从100 个用户中检测1 名隐写者的成功率接近 1 % 时,模型的检测性能等同于随机猜测的性能,可以认为模型完全失效.在此基础上,本文添加了实验,探讨在用户分享的载密图像占比较低时,模型的检测性能是如何接近完全失效的.这里,保持本节中实验的设置不变,测试隐写者分享的载密图像占其分享的所有图像 5 % 时模型的检测性能.本文进行100次实验,并记录模型在检测隐写者过程中的平均准确率,实验结果如表5 所示.

表5 在隐写术错配情况下,当分享的载密图像数量占比5%时,MILGCN 取得的隐写者检测准确率(%)Table 5 Steganography detection accuracy rate (%) in the case of steganography mismatch when the number of shared secret images is 5% of the total number of images
可以发现,MILGCN 在隐写术错配的情况下,对于较为容易攻击的隐写术HUGO-BD,即使在载密图像占比仅为 5 % 的情况下,仍有 6% 的成功率能够检测出隐写者.当隐写者使用MiPOD 隐写术时,MILGCN 仅能够以 3% 的成功率检测出载密图像占比为 5 % 的隐写者,检测性能接近完全失效的性能.可见 5 % 的载密图像占比是非常困难的检测场景,因此建议将本文提出的方法用于隐写者分享的图像占比超过 5 % 的场景中.
上文中都使用S-UNIWARD 作为训练数据的图像隐写术,这主要是因为本文希望在训练模型时,即使只使用一种隐写术得到载密图像,训练得到的模型也可以在其他隐写术得到的载密图像组成的测试集上取得不错的结果.而S-UNIWARD 在隐写、隐写分析、隐写者检测任务中,被认为是更为通用的设置,因而常常拿它来作为训练模型中载密数据所使用的隐写术,在本文的重要对比方法SAGCN中,也采用其作为隐写术未知情况下的实验设置,综合上述原因,本文也采用了这样的设置.在表6中,添加了使用HILL 作为训练数据的隐写术实验.选择HILL 的原因如下: 1) 在隐写术中,HILL 被认为是安全性能最高,也是最难攻破的隐写术,各种隐写分析算法在其上的准确率较低;2) 与S-UNIWARD 相比,HILL 的嵌入概率图完全不同,因此,可以进一步检测本文所提方法的泛化能力.具体而言,在训练阶段,隐写者使用HILL 作为图像隐写术,隐写者检测模型学习在正常用户中检测使用0.5 bpp、0.4 bpp、0.3 bpp、0.2 bpp、0.1 bpp 或0.05 bpp 嵌入率对分享图像嵌入秘密信息的隐写者.这里,隐写者分享的图像均为载密图像,正常用户分享的图像均为载体图像.在测试阶段,隐写者使用HUGO-BD、WOW、HILL、MiPOD 等多种隐写术,嵌入率为0.2 bpp.在每次实验中,模型需要从100 名用户中找出1 名隐写者.其中,每名用户分享200 张图像,根据实验的不同,隐写者分享的载密图像可能占比其分享的所有图像的 10% 或 30%.本文进行100 次实验,并记录模型在检测隐写者过程中的平均准确率.
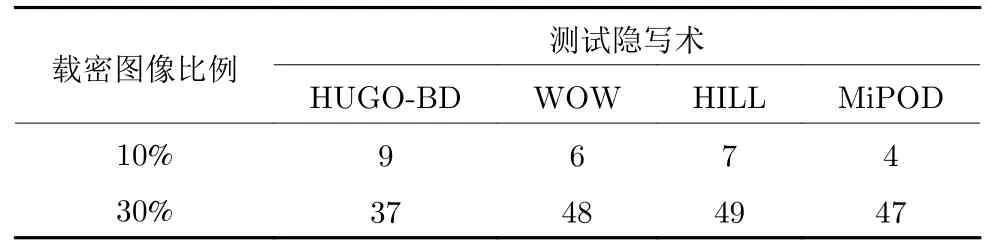
表6 训练模型使用HILL 作为隐写术,分享的载密图像数量占比10%或30%,MILGCN取得的隐写者检测准确率(%)Table 6 Steganography detection accuracy rate (%)when the steganography used for training is HILL and the number of shared secret images is 10% or 30% of the total number of images
为更好地展示本文示例包表征过程与结果,对用户所对应示例包的图表征进行可视化.首先,绘制不同用户对应示例包的图结构示意图.如图4(a)所示,在隐写术未知情况下对使用比例嵌入策略的隐写者检测的实验中,随机选择一名使用MiPOD作为隐写术的隐写者,其分享的载密图像占比 70%.绘制这名用户分享图像所对应示例包的图结构示意图.其中,节点表示分享的图像,节点上的数字1 表示该图像为载密图像,数字0 表示该图像为载体图像.节点间使用边相连,带有颜色的加粗边表示具有紧密关联关系的图像.通常,载密图像之间关联紧密(对应红色加粗边),都具有隐写所带有的模式特征,部分正常图像可能由于具有相同的纹理(对应蓝色加粗边),也相互关联.这时,该图结构在第一层图卷积中的邻接矩阵如图4(b) 所示.其中,深红色代表较大的邻接矩阵元素值,白色代表较小的邻接矩阵元素值.可以发现,当用户为隐写者且分享的载密图像较多时,模型能够学习构建邻接矩阵,将较多的载密图像相互关联,提取和增强其共有的正示例模式特征.为与隐写者的图结构进行对比,随机选择一名正常用户进行可视化.如图4(c) 所示,正常用户分享的图像都为载体图像(用数字0标注),部分载体图像间具有相同的模式特征.该图结构在第一层图卷积中的邻接矩阵如图4(d) 所示,可以发现,相比于隐写者对应的图结构,正常用户的图结构中因为不存在载密图像,因此节点间的关联关系较弱,部分载体图像间存在关联关系,共同增强了负示例特征.可视化结果表明本文所提模型能够按照预期工作,从而区分隐写者和正常用户.

图4 隐写者和正常用户所对应图结构的可视化Fig.4 Visualization of graph structures corresponding to steganographer and normal user
除此以外,本文还进一步测试将隐写者检测问题形式化为分类问题情况下的正检率和误检率
其中,TP表示模型预测为隐写者中的真实隐写者数量,FP表示模型预测为隐写者中的正常用户数量,TN表示模型预测为正常用户中的正常用户数量.具体而言,在训练阶段隐写者使用S-UNIWARD作为图像隐写术,嵌入率为0.4 bpp,在测试阶段隐写者分享的载密图像占比为 0 %、50% 和 100%,阈值为0.5、0.7、0.9,本文使用被测方法预测每名用户属于隐写者的概率,并将概率高于阈值的用户输出为隐写者.可以发现,当隐写者分享的载密图像占比为 0 % 时,正检率都不存在(因为此时隐写者也表现为正常用户,用户中不存在应当被检测到的隐写者),阈值为0.5 时,误检率为 7.98%;阈值为0.7 时,误检率为 0.87%;阈值为0.9 时,误检率为 0 %.当隐写者分享的载密图像占比为 50% 时,阈值为0.5 时,正检率为 10.29%,误检率为 8.10%;阈值为0.7 时,正检率为 37.33%,误检率为 0.95%;阈值为0.9 时,正检率为NaN (表示非数),误检率为 0 %.当隐写者分享的载密图像占比为 100% 时,阈值为0.5 时,正检率为 10.79%,误检率为 8.34%;阈值为0.7 时,正检率为 58.82%,误检率为 0.71%;阈值为0.9 时,正检率为NaN,误检率为 0 %.从该结果可以发现,当隐写者分享的载密图像占比为 50% 和 100% 时,模型的正检率随着阈值的提高而提高,当阈值为0.7 时,模型的正检率以较大差值超过了阈值为0.5时的正检率.这主要受益于本文提出的网络结构和损失函数设计,正常用户被预测为隐写者的概率相对较低,随着阈值的提高这些用户被判别为正常用户,而隐写者被预测为隐写者的概率相对较高,尽管阈值提高,这些用户仍然能被判别为隐写者.而当阈值为0.9 时,模型将所有用户预测为正常用户,此时TP+FP为零,故正检率不为实数.这意味着虽然相对于正常用户,隐写者被正确预测为隐写者的概率较高,但当阈值提高到0.9 时,模型对隐写者的预测概率小于阈值.这是由于相对于丰富的图像内容而言,图像中嵌入的秘密信息难以被识别,模型很难以较高的置信度来区分隐写者与正常用户.值得注意的是,将其形式化为分类问题时首先需要判定未知用户是否存在隐写者,并在某个阈值水平下正确检测出隐写者.这需要对隐写者预测的置信度具有较高的绝对水平,而原有的隐写者检测定义只需要模型在隐写者预测的置信度上具有较高的相对水平(相对于正常用户) 即可.因此,使用分类问题来度量更加困难,计划在未来工作中进一步研究和探讨如何提升隐写者预测置信度的绝对水平.
3.2 基于频域的隐写者检测性能评估与对比
在本节中,本文进一步考虑隐写者检测中的跨域问题.现有工作通常使用BOSSbase ver 1.0.1 的JPEG 版本来检测当图像隐写者使用频域隐写术在JPEG 图像的频率系数中嵌入信息时不同隐写者检测方法的检测性能.因此,在本节中,将上文中的实验设置扩展到频率域.具体而言,首先将BOSSbase ver 1.0.1 中的图像切分成4 个互不重叠的子图,每张子图的尺寸为 2 56×256 像素.进一步,利用MATLAB 中的imwrite 函数,使用JPEG 算法在80 质量因子参数下对每张被切分的子图进行压缩,并使用频域图像隐写术生成对应的载密图像.在隐写者检测过程中,与Holub 等[21]在其工作中对JPEG 域中图像的隐写分析过程一致,输入图像被解压缩至空域,接着MDNNSD 被用于从解压缩的图像中提取特征.与在空域中的实验设置相似,在训练阶段,首先从所有子图样本中随机选择20 000张载体图像,并使用J-UNIWARD 隐写术在不同嵌入率的有效载荷下生成载密图像,特别地,本文中使用的有效载荷包括0.4 bpnzAC、0.3 bpnzAC、0.2 bpnzAC、0.1 bpnzAC 和0.05 bpnzAC.进而,本文将得到的载体图像和载密图像组合为用户作为训练样本.在训练阶段的每个批次中,本文采样50名正常用户,每名正常用户分享200 张载体图像,并采样50 名图像隐写者,每名隐写者分享200 张载密图像,每轮训练采样100 个批次的用户对模型进行优化.在测试阶段,本文在每个实验中随机选择100 个用户,每个用户分享200 张图像,隐写者检测模型被要求从100 个用户中检测出唯一的1 名隐写者.因此,本文在20 000 张载体图像中随机选择200 张载体图像对应的载密图像,构成1 名图像隐写者,剩余的19 800 张载体图像被随机选择并分配给99 个正常用户.在此基础上,本文统计不同隐写者检测模型的检测准确率,所有统计实验进行100 次,最终得到所有统计结果的平均值.
3.2.1 已知隐写术情况下的隐写者检测
为验证在隐写者检测人员已知隐写者使用的图像隐写术时本文方法的有效性,在本节实验中保持测试阶段隐写者使用的图像隐写术与训练阶段相同,使用不同模型对使用不同嵌入率在图像中嵌入秘密信息的隐写者进行检测并记录检测模型的性能.具体而言,在测试阶段,隐写者分享的每张图像中只包含使用J-UNIWARD 图像隐写术嵌入的秘密信息.同时,与空域隐写者检测的实验设置类似,本文在5 种不同的有效载荷上进行测试,其中包括0.4 bpnzAC、0.3 bpnzAC、0.2 bpnzAC、0.1 bpnzAC 和0.05 bpnzAC.
如表7 所示,本文首先对比隐写者检测与隐写分析领域的相关工作.其中,JRM 富特征提取模型和PEV-274 特征提取模型是经典的用于JPEG 图像的隐写分析模型,在隐写分析任务中取得了良好的性能.本文将JRM 与层次聚类算法结合在一起,构成基于JRM 的隐写者检测框架JRM_SD,以评估其在隐写者检测任务上的性能.同时,本文也将PEV 与层次聚类算法结合在一起,构成基于PEV的隐写者检测框架PEV_SD,进行对比分析.从表7中可以看出,PEV_SD 无法有效地检测出使用JUNIWARD 作为图像隐写术的隐写者,这是由于PEV_SD 方法基于PEV-274 特征进行分析,无法检测出使用内容自适应图像隐写术J-UNIWARD嵌入秘密信息的载密图像并构建具有区分力的特征.与PEV_SD 相比,JRM_SD 能够更有效地攻击使用J-UNIWARD 作为图像隐写术的隐写者,但检测性能仍然有限.当隐写者使用0.4 bpnzAC嵌入率嵌入秘密信息时,尽管JRM_SD 联合使用了最前沿的富特征提取模型和一个优化检测器,也只能获得接近 50% 的检测准确率.
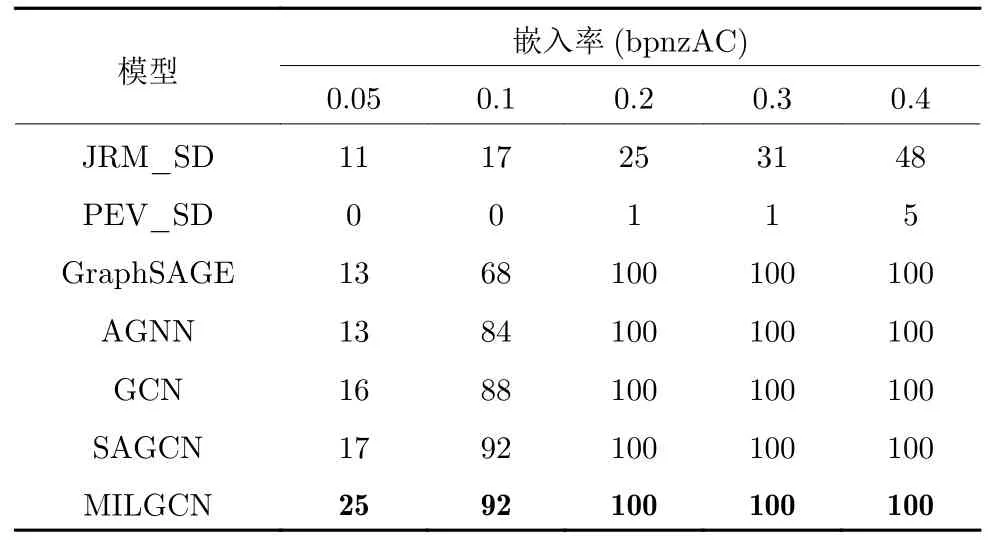
表7 已知隐写者使用相同图像隐写术(J-UNIWARD)时的隐写者检测准确率(%),嵌入率从0.05 bpnzAC 到0.4 bpnzACTable 7 Steganography detection accuracy rate (%)when steganographer use the same image steganography(J-UNIWARD) and the embedding payload is from 0.05 bpnzAC to 0.4 bpnzAC
接着,本文进一步将图神经网络领域的相关工作应用在JPEG 图像的隐写者检测任务中,对比图神经网络领域的相关工作.从表7 中可以发现,基于图神经网络的隐写者检测方法的性能远超于现有隐写者检测与隐写分析领域相关工作的性能,表明图神经网络在利用用户分享的图片间的关联关系进行隐写者检测的有效性.其中,SAGCN 仅次于本文提出的MILGCN,取得了超过其他基于图神经网络的隐写者检测方法的性能.与之相对的,本文提出的MILGCN 在隐写者使用较低的嵌入率嵌入信息的困难情况下,相比SAGCN 的性能有了进一步提升.这是由于当嵌入率较低时,隐写者与正常用户的特征分布极为相近,而本文提出的MILGCN 通过基于多示例学习的设计增加了其区分性.具体而言,本文提出的共性增强图卷积网络能够有效增加正示例的共性特征,在此基础上,基于注意力机制的图表征能够根据识别的正示例模式特征构建具有区分力的图表征,进而正确检测出隐写者.
此外还测试了使用比例策略进行嵌入时的情况,实验的训练部分与本节的实验设置相同,测试部分: 隐写者使用J-UNIWARD 隐写术,嵌入率为0.2 bpnzAC,分享的载密图像占其分享的所有图像的 10%、30%、50%、70%、90% 或 100%.本文进行100 次实验,并记录模型在检测隐写者过程中的平均准确率.可以发现,在载密图像数量占比大于等于 70% 的情况下,本文的方法都能达到 100%的准确率;在占比 50% 的情况下,准确率为 94%;占比 30% 的情况下,准确率为 47% ;占比 10% 的情况下,准确率为 30%.MILGCN 的性能随着隐写者分享的载密图像占比的升高而升高,这种现象与空域上的实验结果一致,是由于当隐写者分享的载密图像占比较低时,隐写者分享的图像大部分为自然图像,即载体图像.在这种情况下,隐写者的表征将与正常用户非常接近,模型难以正确区分隐写者与正常用户.反之,随着用户分享的载密图像占比升高,隐写者的表征与正常用户差异变大,模型将能够更好地区分二者.此外,相比于检测使用空域隐写术的隐写者,可以发现在检测使用频域隐写术的隐写者时,模型只能够在载密图像占比较高时保持较高的检测性能,当载密图像占比较低时,模型的检测准确率会产生更大的下降.这是由于频域隐写术的检测比空域隐写术的检测更为困难,因此在载密图像占比较低时,隐写者与正常用户的区分性会比空域隐写术设置下更低.
3.2.2 隐写术未知情况下的隐写者检测
正如在上文中提到的,隐写者检测人员在对社交网络中用户分享的图像进行分析时,无法预先知道隐写者使用的图像隐写术.因此,本文放宽了图像隐写者在训练阶段和测试阶段使用的图像隐写术为相同隐写术的假设,探讨在隐写术错配情况下本文所提模型的检测性能.具体而言,在训练阶段隐写者使用J-UNIWARD 作为隐写术嵌入秘密信息,以此设置进行训练得到模型.在测试阶段,隐写者分享的每张图像中包含与训练阶段使用不同的图像隐写术,如nsF5、UERD.同时,与空域隐写者检测的实验设置类似,本文在5 种不同的有效载荷上进行测试,其中包括0.4 bpnzAC、0.3 bpnzAC、0.2 bpnzAC、0.1 bpnzAC 和0.05 bpnzAC.
在表8 中,可以发现,当有效载荷在0.1~ 0.4 bpnzAC 区间时,尽管在测试阶段隐写者使用的图像隐写术与训练阶段不同,但是无论隐写者使用哪种隐写术,本文方法仍能够获得超过 90% 的检测准确率.通过将表7 与表8 进行对比,可以发现在隐写术错配时,隐写者检测模型的性能甚至超过了在训练数据集和测试数据集中使用相同的J-UNIWARD 作为图像隐写术时的性能.这是由于JUNIWARD 作为近年来提出的前沿的内容自适应图像隐写术,相比于nsF5 和UERD 更难攻破,因此,当J-UNIWARD作为图像隐写术时,载密图像与载体图像的特征分布极为相近、难以区分,不利于基于特征分布构建有效的图结构并提取载密图像的公共模式特征.相比而言,使用nsF5 和UERD作为图像隐写术嵌入秘密信息的载密图像的特征分布与载体图像的特征分布差异较大.特别地,还能够发现在隐写术错配的情况下,本文方法也能超过其他隐写者检测方法取得最好的性能,这说明MILGCN 确实能够有效提取正示例共享的模式特征,即识别的载密图像模式特征,并与载体图像的模式特征区分开.
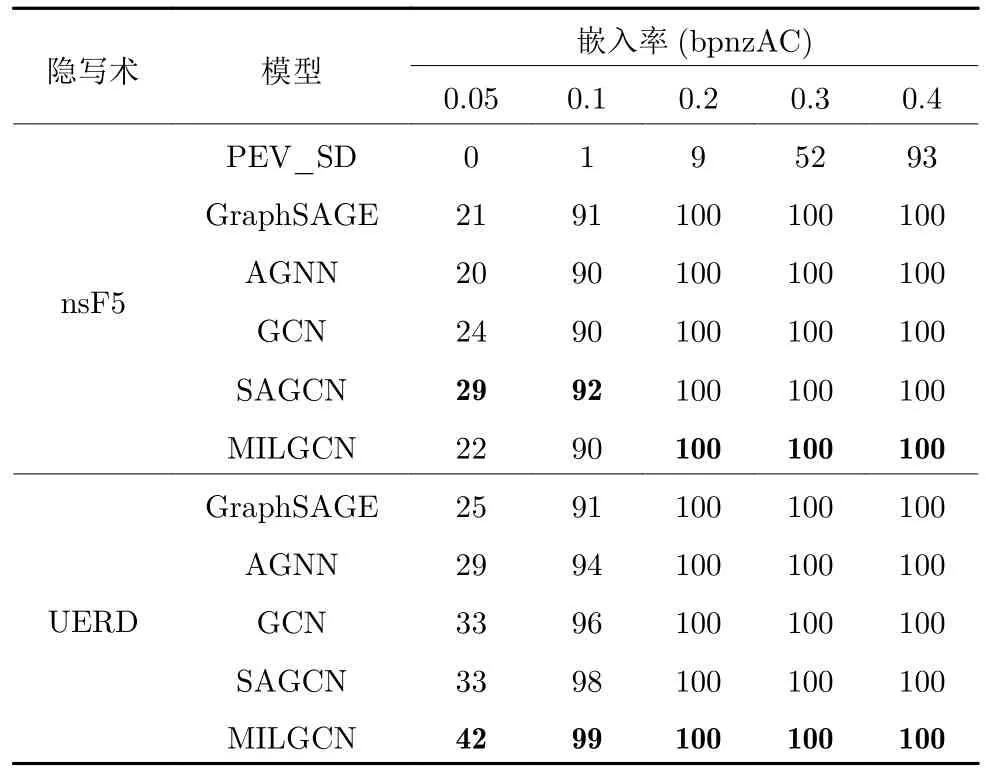
表8 当测试阶段隐写者使用nsF5 或UERD 等图像隐写术嵌入秘密信息时,不同方法的隐写者检测准确率(%),嵌入率从0.05 bpnzAC 到0.4 bpnzACTable 8 Steganography detection accurate rate (%) of different methods when steganographer uses nsF5 or UERD as image steganography in the testing phase and the embedding payload is from 0.05 bpnzAC to 0.4 bpnzAC
当隐写者使用的有效载荷为0.05 bpnzAC 时,尽管本文提出的方法在性能上稍强于其他基于图的方法,但所有方法都无法有效检测出隐写者.这是由于秘密信息在JPEG 的压缩过程中丢失了,当有效载荷较低时,载密图像与载体图像非常相似.因此,对于模型而言,很难区分隐写者和正常图像的特征.与空域中隐写者检测方法相比,频域中隐写者检测框架的性能相对较低,这也说明在压缩到JPEG 格式过程中,存在信息的丢失.
3.2.3 计算复杂度分析
在这一部分,提供本文方法MILGCN 和其他几种对比方法的计算复杂度分析.首先使用ptflops 软件包计算不同方法的计算复杂度,并使用浮点运算数量来度量.具体来说,给定一个模型,构建分享200 张图像的100 个用户样本作为输入,计算其中哪一个用户为隐写者.在计算过程中,对于指数、开根号、乘法、加法、比较等操作,均将其计数为一次浮点运算,而对于数据复制、移动等操作,则不进行计数.最终,得到计算单个样本的浮点运算次数并进行统计报告.除此以外,还度量不同方法在推断过程中所需的CPU 时间,以说明设计方法在推理和部署方面的可用性.这里,本文运行200个批次样本的推理,并统计样本推理所需的平均时间.其中,每个批次包含100 个用户样本.表9 中,还提供了不同模型所包含的参数量.
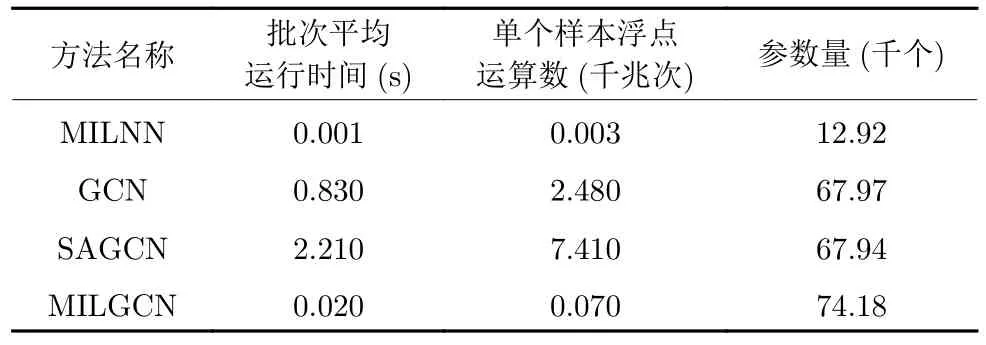
表9 计算复杂度分析Table 9 The analysis of computational complexity
从表9 中可以发现,尽管本文提出的MILGCN具有相对较多的参数,但仍与基于图的方法GCN和SAGCN 保持在同一量级上.与此同时,还可以发现,虽然参数量相对较大,但MILGCN 所需的浮点运算数和批次平均运行时间要比基于图的方法GCN 和SAGCN 小很多.这是由于这些方法在构建图的过程中,使用欧氏距离度量特征集合中两两图像特征对的关联关系,具有较高的时间复杂度.而本文通过自适应的学习方法取代了基于欧氏距离的图构建方法,大幅降低了运算量.这使得本文提出的MILGCN 不但在检测性能上占有优势,也在运行效率上远超其他基于图的方法,接近于简单模型MILNN 的水平.
4 结论与未来工作
近年来,隐写者在分散秘密信息嵌入图像的策略选择上越来越多样.因此,本文扩展基于图的隐写者检测方法,进一步探究应对不同嵌入策略的通用隐写者检测方案.本文提出一种基于多示例学习图卷积网络的隐写者检测算法,将隐写者检测形式化为多示例学习任务.在多示例学习任务的形式化下,用户分享的图像对应于示例,用户对应于示例包.在此基础上,本文设计多示例学习图卷积网络,在正示例占比较低或特征分布与负示例相近的情况下,能够识别和区分正示例的模式特征.其中,本文设计的共性增强图卷积能够自适应地突出示例包中正示例的模式特征,而注意力图读出模块能够自适应地构建示例包表征,并根据具有区分力的表征对用户进行正确检测.实验表明,本文设计的模型能够对抗多种批量隐写术和隐写策略.在未来工作中,将研究当载密图像数量占比很小情况下有效的隐写者检测方法.
