基于听觉特征融合的煤矸识别方法研究
2024-04-29王世博饶柱石杨善国杨建华刘送永刘后广
杨 政, 王世博,2, 饶柱石, 杨善国,2, 杨建华,2, 刘送永,2, 刘后广,2
(1. 中国矿业大学 机电工程学院,江苏 徐州 221116;2. 中国矿业大学 江苏省矿山智能采掘装备协同创新中心,江苏 徐州 221116;3. 上海交通大学 机械系统与振动国家重点实验室,上海 200240)
在我国的能源资源中,煤炭占据主导地位,其中厚煤层(厚度≥3.5 m)的产量和储量均约占总量的45%[1]。放顶煤作为一种典型的厚煤层开采方法,具有较高的生产率和效率。然而,到目前为止,放顶煤过程中仍然需要人工判断顶煤垮落情况,以便操作液压支架[2]。这严重限制了煤炭开采的质量和数量,同时人工判断容易导致煤的过放或欠放。实现放顶煤过程的自动化,不仅可以解决上述问题,还可以让工人远离综放工作面,确保工人安全[3]。而煤矸的精准识别对实现综放开采自动化具有重要意义[4]。
为实现煤矸精准识别,近年来,研究人员对不同的煤矸识别方法进行了广泛研究,如自然γ射线法[5]、红外探测法[6]、图像识别法[7]和声音、振动信号分析法[8]等。上述方法多存在诸如安装困难、成本较高等问题[9]。因声音信号采集简便、实施成本低而被相关学者用于煤矸识别研究。基于煤和矸石的声音信号,袁源等[10]构建了放顶煤声音信号数据库,分别提取了时域、频域和时频域特征,并对各种方法进行了比较。研究发现,相较于时域特征和频域特征,以频谱频带能量占比该时频特征为特征参数,能更有效地区分煤矸特征,有助于提升煤矸识别准确率,并通过随机森林实现了较好的煤矸识别效果。Li等[11]提取煤矸垮落声音信号的无量纲参数构建特征向量,使用支持向量机进行分类。
上述基于煤和矸石声音信号的研究,为放顶煤过程中智能煤矸识别提供了基础。然而,这些研究大多忽略了放顶煤中的噪声影响。实际放顶煤现场操作环境复杂,难以避免需要在强背景噪声环境中工作。这些识别方法难以在煤矿开采中的实际环境中应用。现有的综放开采主要还是依靠工人耳听液压支架尾梁冲击声音来判断煤矸垮落情况,控制液压支架放顶煤过程[12]。能否模拟放煤工人听觉识别煤矸过程,将听觉系统引入煤矸识别算法中,提高强背景噪声下的煤矸识别准确率,是一个值得探索的问题。
人耳听觉系统具有优异的强噪声背景识别性能[13],很多学者探索将听觉感声特征应用到声场景识别中[14]。其中,基于人耳听觉外周前端对于不同频率敏感度所构建的Mel频谱,便是其中一种被广泛应用的听觉特征[15]。宋庆军等[16]基于Mel频谱提取了放顶煤声音信号的梅尔频率倒谱系数(Mel frequency cepstrum coefficient,MFCC)作为煤和矸石的识别特征,取得了很好的效果。但是Mel频谱仅模拟人耳听觉外周前端对于不同频率声音的感知,难以处理含有复杂噪声的声音信号。声音信号经人耳转换成听觉神经冲动,听觉神经冲动含有复杂的高级听觉特征以便大脑皮层进行分析,从而产生听觉[17]。因此,忽略了高层次听觉特征的识别算法严重影响其噪声环境下识别准确率。
因此,本文提出了一种融合低级听觉特征Mel频谱和高级听觉特征听觉神经递质发放率的放顶煤煤矸识别方法。首先,根据煤矸垮落声音信号频谱特点,建立了考虑听觉中枢的听觉模型;然后,利用听觉模型对煤矸垮落声音信号进行分析,经中耳模型、并联滤波器组耳蜗模型、内毛细胞转导模型和听觉神经突触模型处理后得到听觉神经递质发放率;再次,将听觉神经递质发放率与通过Mel频谱提取的Mel线索进行特征融合,得到煤矸声音听觉感知图;最后,基于听觉感知图,利用ConvNeXt模型进行煤矸识别,同时比较不同信噪比噪声下煤矸识别准确率。结果表明该方法可以有效地完成煤矸识别,且在强背景噪声下也具有较高的识别准确率。
1 听觉特征相关理论及方法框架
1.1 Mel频谱
Mel频谱是一种常用于声音信号处理的频谱。它基于人耳对于不同频率的敏感度,利用Mel滤波器对声音时频谱进行Mel尺度下的变换,将频率轴上的频率刻度转换为Mel刻度,变换后的时频谱称为Mel频谱。
首先,通过分帧、加窗等预处理确定煤矸声音信号范围。然后使用快速傅里叶变换将声音信号从时域变换到时频域,并利用一组Mel尺度三角形滤波器组进行带通滤波。最后,通过对数变换进行尺度映射,从而获得煤矸声音信号Mel时频谱矩阵。其中,Mel尺度与线性频率f之间的转换关系可表示为
(1)
1.2 听觉神经滤波器组模型
Bruce等[18]在早期听觉外周模型[19]的基础上,建立了一个听觉神经滤波器组模型,对听觉神经突触模型进行了改进,能够更好地解释神经递质的释放过程。
在该听觉计算模型基础上,根据煤矸垮落声音信号频谱特点,指定特征频率使之适用于煤矸识别任务。通过该模型可计算放顶煤过程中煤矸声音信号在不同特征频率下的神经递质发放率。该听觉模型主要分为四个部分:中耳模型、并联滤波器组耳蜗模型、内毛细胞转导模型和听觉神经突触模型。听觉模型具体结构如图1所示。
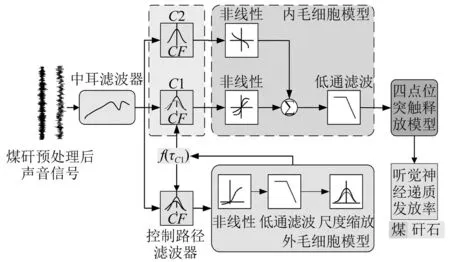
图1 用于煤矸识别的听觉神经滤波器组模型Fig.1 Auditory neuralfilter bank modeling for coal gangue recognition
中耳模型可对输入的煤矸声音信号进行放大增益,采用滤波器进行建模,由3个数字滤波器串联实现
(2)
耳蜗作为听觉外周中最重要的器官,可对煤矸声音信号进行频率分解。采用并行滤波器组进行建模。C1和C2两个并行滤波器二者共同模拟了基底膜的选频特性,可针对指定特征频率进行分析。外毛细胞模型可以调节C1滤波器的增益和带宽,进而对信号进行反馈控制。
随后,内毛细胞通过转导函数可分别得到C1和C2的转导响应,将其输入到低通滤波器中,可得到煤矸声音信号单一特征频率下的内毛细胞输出电位。
其中C1滤波器的转导函数为
Vihc,C1=Aihc[PC1]lg(1+2 000|PC1|)
(3)
式中,PC1为C1滤波器的输出信号,其中
Aihc[PC1]=
(4)
C2滤波器的转导函数公式为
Vihc,C2=signum(-PC2)×2×
0.1×lg[1.0+5×10-5×2 000×(PC2·CF)2]
(5)
式中:PC2为C2滤波器的输出信号;CF为特征频率。
听觉神经突触模型如图2所示。内毛细胞输出电位通过非线性处理,经幂律调整叠加后得到突触小泡平均释放速率Sout,经四位点突触释放与自适应转换,经过失效期的释放间隔,最终得到听觉神经递质发放率。
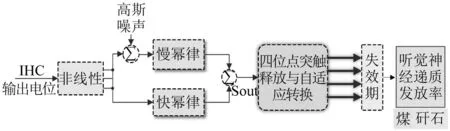
图2 听觉神经突触模型Fig.2 Auditory synaptic model
该模型通过指数分布来描述4个突触位点的释放间隔分布
(6)
τrd[n+1]=
(7)
式中:τrd以s为单位,表示激活时间间隔;Nrd[n]是在时间步长n期间发生的突触再激活事件的数量,持续时间为Δts,τrd被初始化为
τrd[0]=13.6×10-3+0.02×10-3×SR
(8)
式中,SR为每秒发放的神经递质分子数,由低、中、高三种神经纤维决定。本文中,为适用于煤矸声音信号,其值分别设置为1 s-1、10 s-1和70 s-1。
1.3 基于听觉特征融合的煤矸识别方法框架
基于听觉特征融合的煤矸识别方法框架如图3所示,主要由前期处理、听觉特征提取、听觉特征融合和煤矸识别四个阶段组成。

图3 基于听觉特征融合的煤矸识别方法框架Fig.3 Framework of coal and gangue recognition method based on auditory feature fusion
在前期处理阶段,首先利用测量传声器收集煤矸垮落冲击液压支架尾梁的声音信号;然后对收集的声音信号进行预处理,消除原始声音信号中趋势项和高频噪声的影响。在听觉特征提取阶段,使用听觉神经滤波器组模型分析预处理后的声音信号,经中耳模型、并联滤波器组耳蜗模型、内毛细胞转导模型和听觉神经突触模型处理后得到听觉神经递质发放率;利用Mel频谱提取预处理后声音信号的Mel线索。在特征融合阶段,对提取到的听觉特征进行尺度映射及标准化操作,经特征融合后得到煤矸声音听觉感知图。在煤矸识别阶段,基于得到的听觉感知图,利用ConvNeXt模型分析不同信噪比噪声下煤矸识别效果。
2 煤矸声音信号采集及预处理
2.1 数据采集
煤矸识别试验使用的放煤和放矸石声音信号来源于同煤大唐塔山煤矿有限公司8222综放工作面。工作面长度为230.5 m,平均厚度为14.36 m。选用爱华AWA14423测量传声器采集ZF17000/27.5/42D型液压支架上煤矸撞击尾梁声音数据。为了降低刮板输送机噪声对采集数据的影响,将测量传声器固定在液压支架支柱的液压管道上,具体安装位置如图4所示。放顶煤过程中,采用DH5925N数据采集系统记录声音数据,并手动记录两种工况的开始时间。
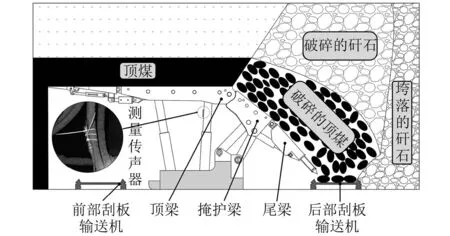
图4 测量传声器安装位置Fig.4 Measure microphones installation location
2.2 数据预处理
对采集到的声音信号进行截取操作,截取窗口为0.5 s,不足0.5 s去除,最终得到1 179个煤矸声音信号数据样本。对煤矸声音信号进行分析,得到各声音样本的时域波形及频谱,如图5所示。
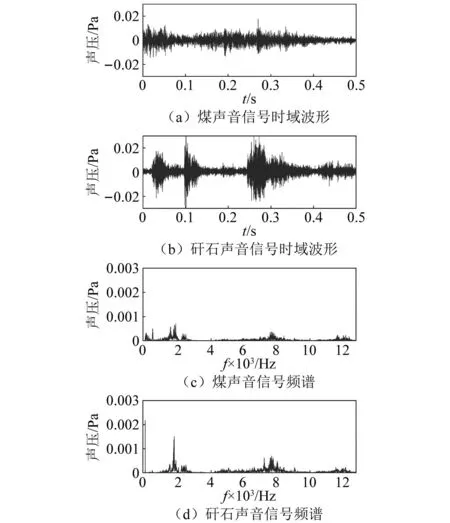
图5 煤和矸石声音信号时域波形以及煤和矸石声音信号频谱Fig.5 Time domain waveforms of coal and gangue sound signals; coal and gangue sound signal spectrum
由图5可知,煤和矸石声音信号频谱具有一定差异,煤声音信号频率多集中在200~1 800 Hz,而矸石声音信号多集中在1 500~2 800 Hz,并且矸石声音信号的能量较煤声音信号大。此外,因综放工作面环境复杂,以及采集过程中偶然因素的干扰,两类声音信号在采集过程中均引入了趋势项和高频噪声。为此,需要对采集的声音信号进行预处理。通过Sgolay滤波器消除原始信号趋势项,利用移动平均法对声音信号进行平滑处理,消除高频噪声对声音信号的影响。以矸石为例,预处理结果如图6所示。

图6 预处理前后矸石冲击液压支架声音信号频谱Fig.6 The spectrum of sound signal of gangue impact hydraulic support before and after pretreatment
由图6可知,经预处理后,原始信号低频趋势项信号和高频噪声得以消除。为便于后续抗噪性能验证,在预处理后的煤矸声音信号中分别添加不同信噪比的高斯噪声。
3 煤和矸石融合听觉特征提取
3.1 煤矸声音信号的Mel频谱峰值特征提取
根据煤矸声音样本的频率分布,设置Mel频谱处理范围为200~6 000 Hz,以此提取煤和矸石声音样本的Mel时频谱。为提高融合效果,提取Mel时频谱中的峰值特征进行特征融合。
基于局部二值模式[20],提出一种局部峰值特征(local peak feature,LPF)提取方法。使用3×3矩阵块提取峰值特征,矩阵块中心值记为gc,从中心值右侧开始,逆时针方向对矩阵块所处位置进行编号gp(p=0,…,7),通过与中间值比较计算LPF值
(9)
其中,中心点LPF值为
(10)
得到该矩阵块处的峰值特征后,从左到右,从上到下依次移动矩阵块进行LPF计算,以提取整个Mel时频矩阵的峰值特征。进行最大最小值归一化,将数值范围缩放到[0,1]区间内。提取到的Mel时频谱峰值特征称为Mel线索。图7显示了提取的煤冲击液压支架声音信号的Mel时频谱图和Mel线索图。
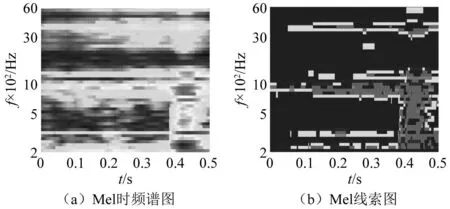
图7 煤冲击液压支架声音信号Mel时频谱图和Mel线索图Fig.7 Mel spectrum diagram and Mel clue diagram of sound signal of coal impact hydraulic support
3.2 煤矸声音信号的听觉神经递质发放率提取
由于听觉模型是对指定的特征频率进行分析,为满足煤矸识别任务要求,在提取高级听觉特征之前,首先需要指定特征频率。听觉系统对较低频率的频率变化比在较高频率下更敏感,因此使用对数刻度表示频率范围
CFs=logspace(lgfL,lgfH,ncf)
(11)
式中,fL,fH,ncf分别为最低特征频率、最高特征频率和特征频率数量。根据煤矸垮落声音信号频谱特点,分别设置fL=200 Hz、fH=6 000 Hz、ncf=49。由此生成了200~6 000 Hz范围内49个特征频率,如图8所示。
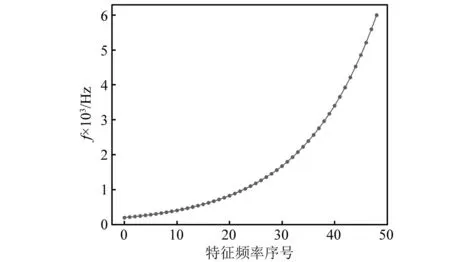
图8 听觉神经滤波器组模型特征频率分布Fig.8 Characteristic frequency distribution of auditory nerve filter bank model
将煤矸声音信号样本输入到听觉神经滤波器组模型进行处理。由中耳模型进行放大增益后输入并联滤波器组耳蜗模型,经频率选择以及内毛细胞转导得到内毛细胞输出电位,电位信号刺激听觉神经突触模型模拟神经递质释放过程,最终得到煤矸冲击液压支架声音信号的听觉神经递质发放率,如图9所示。
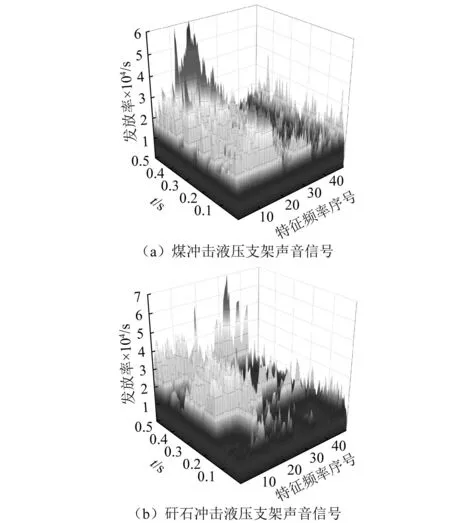
图9 煤矸冲击液压支架声音信号的听觉神经递质发放率Fig.9 Auditory neurotransmitter firing rate of sound signal from coal and gangue impact hydraulic support
由图9可知,相较于煤,矸石声音信号的听觉神经递质发放率峰值较大,但差异并不明显。然而,二者神经递质发放率的频率分布有着较大差异。煤声音信号较大值多集中在特征频率序号为8~25之间,即特征频率处于320~1 200 Hz之间。而矸石声音信号较大值多集中在特征频率序号为30~40之间,即特征频率处于1 560~3 170 Hz之间,具有明显的区分度。
3.3 听觉特征融合
为实现煤矸冲击液压支架声音信号的Mel线索特征与听觉神经递质发放率特征融合,需使两特征维度保持一致。图像缩放时,因使用了等间隔采样和插值算法[21],原有信息不会发生改变。受此启发,考虑对Mel线索矩阵使用二维插值算法进行尺度映射,使其与听觉神经递质发放率特征维度保持一致。为提高特征融合效果,分别对听觉神经递质发放率和Mel线索进行标准化,使其均服从均值为0,方差为1的标准分布。在机器学习中,当需要让两个矩阵相加时,为了保证加权和的范围在两个矩阵之间,通常要求两个权重之和为1[22]。为此,将权重之和限制为1。由此得融合矩阵FM
FMm×n=a×Melm×n+b×FRANm×n
(12)
式中: m×n为矩阵的维度;Mel和FRAN分别为Mel线索矩阵和听觉神经递质发放率矩阵;a,b分别为Mel线索矩阵和听觉神经递质发放率矩阵的权重系数,其值反映了两个矩阵的贡献率,局部最优特征融合权重系数可通过试验进一步确定。最后,根据融合矩阵得到煤矸声音听觉感知图。
4 煤矸识别试验验证
基于所构建的煤矸声音听觉感知图,按照7∶3的比例划分训练集和测试集,利用ConvNeXt[23]模型进行煤矸识别。该模型核心结构包括下采样层和ConvNeXt Block模块,通过在模型后端新加两个全连接层,便于模型权重迁移和特征层映射,模型结构如图10所示。
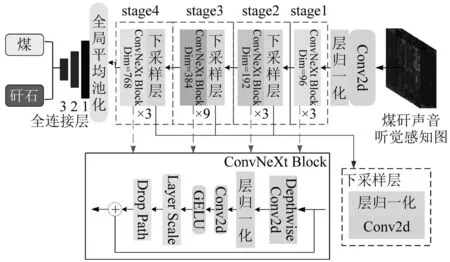
图10 用于煤矸识别的ConvNeXt模型结构Fig.10 ConvNext model structure for coal gangue recognition
利用Imagenet数据集进行预训练,学习源域数据得到模型权重后,在煤矸声音听觉感知图数据集上进行迁移学习[24]。Batchsize设置为32,迭代次数为200,利用Cosine Annealing Warm Restart函数对学习率进行动态调整。
4.1 听觉特征融合权重的确定
为确定听觉特征局部最优融合权重系数a和b,在SNR=-5 dB情况下,通过改变模型权重大小,将听觉感知图输入到ConvNeXt模型以识别准确率作为评价指标进行验证。以0.1为间隔依次改变听觉神经递质发放率权重系数b,ConvNeXt模型识别结果如图11所示。
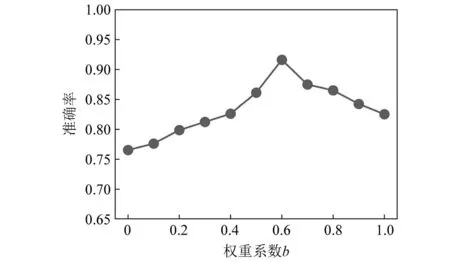
图11 不同权重系数b下的煤矸识别准确率(SNR=-5 dB)Fig.11 The recognition accuracy of coal and gangue with different weight coefficient b ( SNR=-5 dB )
由图11可知,在一定情况内,煤矸识别准确率随着权重系数b的增加而增加,进一步说明高级听觉特征听觉神经递质发放率的引入有助于煤矸识别。当权重系数b为0.6时,具有最大识别准确率,为91.52%。但当权重系数b超过0.6时,随着权重系数b的增加,识别准确率不断下降。这是因为此时融合特征中Mel线索比重不断降低,提供的全局特征进一步减少,而且高级听觉特征受限于特征频率,无法提供更广泛的特征信息。因此,局部最优权重系数a和b分别为0.4和0.6,由此得到了煤矸声音听觉感知图,如图12所示,并以此构建不同信噪比下的煤矸识别数据集。

图12 煤和矸石声音信号听觉感知图Fig.12 Coal and gangue sound signal auditory perception diagram
4.2 抗噪性能验证
基于所构建的不同信噪比下的煤矸识别数据集,利用ConvNeXt模型进行训练。为验证所提方法的抗噪性能,分别提取煤矸声音信号的Mel频谱图(Mel spectrograms,MSG)和时频谱图(Spectrograms,SG),利用ConvNeXt模型进行训练,同时使用时频谱频带能量占比结合随机森林(band energy ratio-random forest,BER-RF)的方法进行煤矸识别。将上述方法与所提基于Mel频谱-听觉神经递质发放率特征融合(Mel spectrum-firing rate of auditory neurotransmitter,Mel-FRAN)的方法进行比较,所得结果如图13所示。
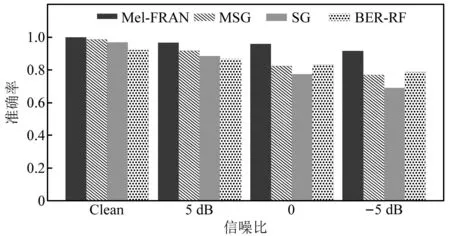
图13 不同识别方法和信噪比下的煤矸识别准确率Fig.13 The accuracy of coal gangue recognition under different recognition methods and SNR
t-SNE[25]是一种非线性降维方法,可将高维数据映射到2维或3维空间。分别对ConvNeXt模型中第二个连接层的输出以及时频谱频带能量占比特征进行t-SNE降维可视化,如图14所示。
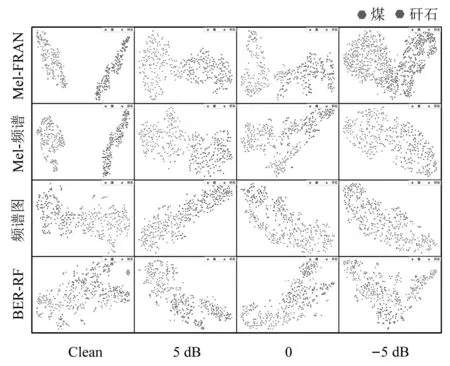
图14 t-SNE降维可视化结果Fig.14 Visualization results of t-SNE dimensionality reduction
结合图13和图14,在不添加噪声的情况下,所提方法相较其余三种方法,准确率提升并不明显。其中采用时频域特征结合随机森林的方法,煤矸识别性能明显低于其他基于深度学习的方法。随着SNR进一步降低,所有识别特征准确率均呈下降趋势,同时各种识别特征的聚类性能和特征间隔进一步降低。其中,采用频谱图方法的煤矸识别准确率下降最为明显,由96.7%降至68.9%。采用时频域特征结合随机森林的方法虽然下降并不明显,但是在SNR=-5 dB的情况下,准确率仅为78.64%。与之相反,所提方法在所有情况下准确率均能达到91%以上,尤其在SNR=-5 dB的情况下,准确率为91.52%,相较于其余三种方法具有较大优势。同时,所提方法在同类别样本中有着更好的聚类效果,在不同类别样本之间特征距离较大,这有助于分类器更容易地对煤和矸石声音样本进行分类。
此外,所提方法拥有较快的收敛速度,在SNR=-5 dB的情况下,其训练过程中测试集准确率及损失如图15所示。
计算准确率(Accuracy)、精确率(Precision)和召回率(Recall)以及F1-score,所得结果如表1所示,其中F1-score可达91.98%,验证了所提方法对噪声具有优越的鲁棒性。

表1 测试集煤矸识别评价指标(SNR=-5 dB)
4.3 煤矸识别实时性分析
为验证所提方法对于煤矸识别的实时性,统计所提方法在各个阶段的运行时间以及识别阶段的模型参数量。与BEF-RF煤矸识别方法比较,所得结果如表2所示。
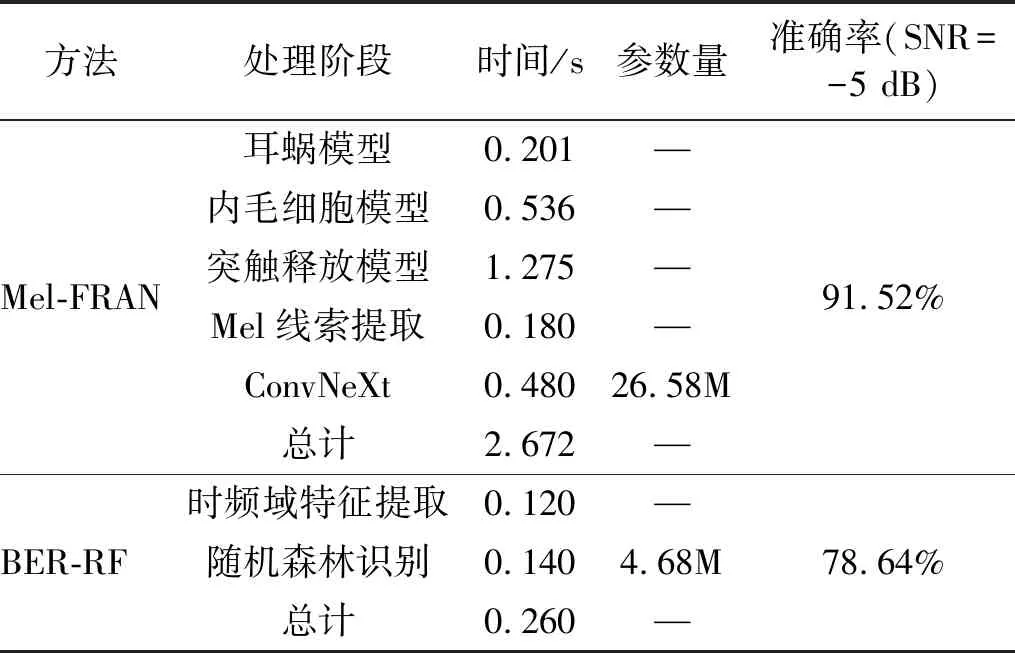
表2 基于Mel-FRAN及BER-RF方法的煤矸识别所用时间及模型参数量
由表2可知,所提方法用于煤矸识别时,计算开销较大,影响其实时性的主要为听觉模型中突触释放过程,花费约1.275 s。这主要是由于该模型引入了突触结合位点和三种不同速率的神经纤维,增加了模型复杂度。而使用时频域特征结合机器学习的方法,具有较快的识别速度,但是在SNR=-5 dB的情况下,准确率仅有78.64%。可见,本文所提出的基于听觉模型的方法显著提高了强背景噪声下煤矸识别准确率,但增大了计算量,后期将进一步改进算法,在维持高识别准确率的前提下,提升煤矸识别速度。
5 结 论
本文基于煤矸垮落冲击液压支架尾梁的声音信号,提出了一种融合低级听觉特征Mel频谱和高级听觉特征听觉神经递质发放率的放顶煤煤矸识别方法,基于听觉神经滤波器组模型构建了适用于煤矸识别任务的听觉模型,建立了听觉特征融合框架。利用ConvNeXt模型对不同信噪比下的声音信号进行了煤矸识别试验,得出以下结论:
(1) 融合后的听觉感知图既包含高级听觉特征又包含全局频率特征,相较于Mel频谱图和频谱图可以更好地表达煤和矸石垮落声音信号的特征,具有明显的区分度。
(2) 所提方法在所有SNR情况下煤矸识别准确率均能达到91%以上,尤其在SNR=-5 dB的高噪声情况下,准确率仍能达到91.52%,与其余方法相比具有较大优势,验证了所提方法对噪声具有优越的鲁棒性。
(3) 所提方法显著提高了强背景噪声下煤矸识别准确率,但增大了计算量,后期将进一步改进算法,在维持高识别准确率的前提下,提升煤矸识别速度。
