基于VSD-YOLOv5s的轻量化注塑齿轮缺陷检测*
2024-04-29黄周林李鑫炎张美洲
申 飞,周 敏,黄周林,李鑫炎,张美洲
(武汉科技大学a.冶金装备及其控制教育部重点实验室;b.机械传动与制造工程湖北省重点实验室;c.精密制造研究院,武汉 430081)
0 引言
在注塑齿轮生产过程中,由于温度、注塑时间等因素影响,齿轮可能出现表面黑点、轮齿变形、轮齿缺失等缺陷。由于齿轮缺陷检测过程往往十分复杂,检测设备也较为昂贵,因此在实际生产中迫切需要对齿轮进行快速检测和分析[1]。传统齿轮制造过程中的检测方式以人工检测为主,但是人工检测不可避免地会出现错检、漏检等问题。机器视觉检测是一种非接触式无损检测,在高速、精细和重复的制造过程中更加可靠,与传统的检测方法相比,具有不可替代的优越性。
陈硕等[2]提出利用广泛的Canny算子提取出待检齿轮的轮廓,通过计算机求解出轮廓之间的距离,但该方法可能在提取轮廓时出现误差且识别速度较低。郭冕等[3]提出以模态分解模型将齿轮信号分解,并通过BP神经网络,实现微型塑料齿轮缺陷检测,但该方法在齿轮信号除噪声方面检测识别精度低、鲁棒性差。杨亚等[4]采用SURF算法对于齿轮的特征进行匹配,获取缺陷信息后采用OSTU算法对缺陷进行分割处理并分类,但是该方法不能很好的分类缺陷。JEONGHYEON等[5]采用声波频率分析法,采用CNN模型进行分析缺陷,数据分析需要大量时间,导致检测效率降低。仇娇慧等[6]提出一种改进的YOLOv5网络模型,但该模型中的主干网络C3结构以及添加的注意力机制结构导致参数量上升、识别速度降低。
基于上述问题,本文提出一种改进的YOLOv5s(即VSD-YOLOv5s)网络模型。该网络模型使用轻量化ShuffleNetv2主干网络,引入SE注意力机制及DIOU-NMS方法,提升注塑齿轮缺陷检测的识别精度与识别速度。
1 YOLOv5s网络模型结构
YOLOv5包含4个版本的目标检测网络模型,即YOLOv5s、YOLOv5m、YOLOv51和YOLOv5x,模型的规模和训练参数的数量在4个版本中依次增加[7],其中,YOLOv5s网络模型最快。考虑到缺陷检测需要严格的实时性,本文以最简单、最快的网络模型YOLOv5s作为基准,来完成表面缺陷的在线检测。YOLOv5s的结构由4部分组成,输入端、Backbone网络、Neck网络、Prediction输出端,如图1所示。输入端采用自适应图像填充、自适应锚框计算和Mosaic数据增强,以提升检测的准确性;在Backbone网络中,使用了Focus模块、C3主干网络模块和卷积模块。Focus模块主要用于切片操作,通过增加特征图的维度来缩小特征图的尺寸,同时保留图像特征信息。C3主干网络模块中的残差结构有效防止梯度消失,使得特征更加细致;Neck网络中主要包含C3网络模块、上采样和下采样过程,降低计算量,同时提高特征融合能力和信息保留度。Prediction输出端中使用NMS后处理方法筛选多个目标锚框,抑制无效信息,以提高识别准确性。
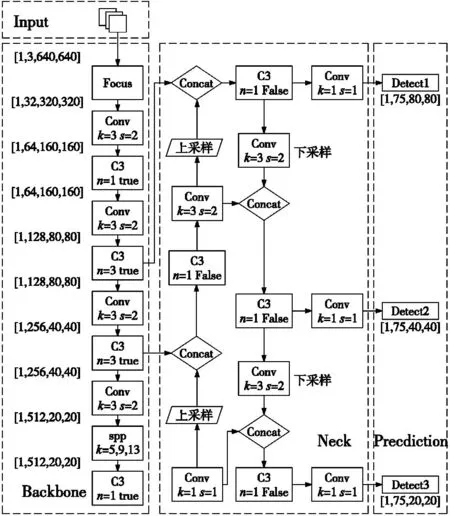
图1 YOLOv5s网络模型结构
2 改进的YOLOv5s网络模型
为了满足注塑齿轮表面缺陷在线检测的速度和识别精度要求,本文提出了一种VSD-YOLOv5s网络模型,对YOLOv5s的结构进行了修改,能够检测不规则和细小的齿轮缺陷。
2.1 将主干网络C3替换为ShuffleNetV2
YOLOv5s中主干网络C3,如图2所示,旨在更好地提取图像的深层特征。C3主要由Bottleneck、Conv2d、BN+SiLU激活函数组成,输入通道分为两个分支,通过两个分支的卷积运算,将特征映射中的通道数减半。然后特征映射通过第二分支中的Conv2d层、BN层和瓶颈层,并利用Concat层对两个分支进行深度融合[8-9]。最后,通过连续穿过Conv2d层和BN层生成模块的输出特征映射,特征映射的大小与主干网络C3的输入大小相同。

图2 主干网络C3
YOLOv5s主干特征提取网络采用C3网络结构,带来较大的参数量,识别速度较慢,应用受限。因此本文将主干特征提取网络替换为更轻量的ShuffleNetV2网络结构,以实现网络模型的轻量化,提升识别速度和识别精度。
如图3所示,本文使用先进的ShuffleNetv2单元,其中Channel Split操作将通道数平均分成两部分,代替了原有的分组卷积结构。每个分支中的卷积层输入、输出通道数均相同,其中一个分支不进行任何操作以减少基本单元数。针对ShuffleNetv2中单元块的下采样,不再采用Channel Split,通过在每个分支中添加stride=2代替原有的Channel Split模块以提高模型容量及检测效率。最后使用Concat、Channle Shuffle代替原有的Add、ReLU模块以增加模型通道之间的信息交流。综合上述改动,特征图空间大小将减半,且使模型具有较高的模型容量和检测效率,减小了模型的计算复杂度,降低了模型的内存占用率,极大地提高了模型的计算效率。
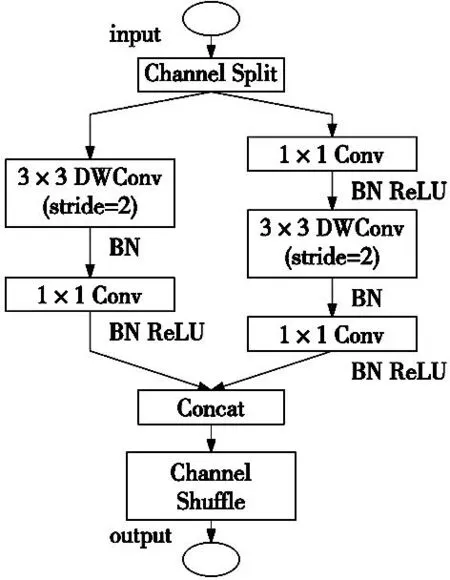
图3 基本ShuffleNetv2单元
2.2 引入SE注意力机制模块
注意力机制是指重点关注检测部分而忽略无关要素,SE注意力机制模块,如图4所示。首先,对特征映射进行压缩操作以获得通道的全局特征;然后,对全局特征进行激励操作,以学习通道之间的关系,并获取不同通道的权重;最后,对原始特征映射进行乘法操作,得到最终的特征。这个机制有助于模型更加注重信息量最大的通道特征,同时抑制那些不重要的通道特征[10]。
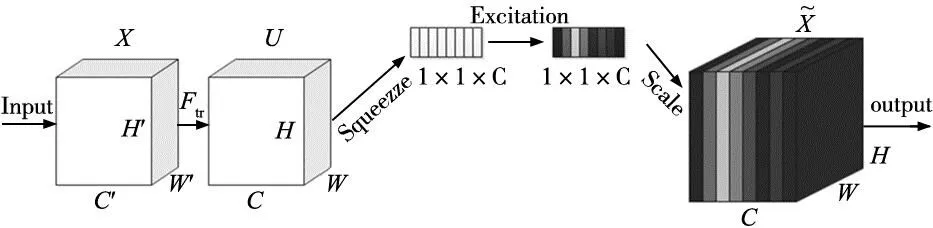
图4 SE注意力机制
本文通过引入SE注意力机制模块,以建立卷积特征通道之间的相互依赖性来提高网络的表示能力。首先,输入特征图X,让其经过Ftr操作生成特征图U;然后,进行Squeeze 操作、Excitation操作,Scale操作。Squeeze操作是一种压缩操作,它将输入图像的高度H和宽度W都压缩为1,但通道数不变的矩阵。通常使用全局平均“池化”操作来实现,以确保最终特征包含输入图像的所有信息。Excitation操作对通过Squeeze操作生成的1×1×C特征图进行维度降低和恢复操作,使用全连接层获取不同通道的权重,自动关注具有最高权重的通道。Scale操作是一种简单的加权运算操作,它将Excitation操作生成的特征图与输入特征图通过Sigmoid激活函数进行Channel运算,得到输出值。
2.3 将NMS改进为DIOU-NMS
在YOLOv5s原有的NMS中,使用IOU度量来抑制冗余检测框,IOU的全称为交并比,即表示为预测边框A(Prediction box)和真实边框B(Ground truth box)的交集和并集的比值。IOU的计算公式为:
(1)
但IOU度量法并未将两个框之间的中心点距离考虑在抑制标准之内,此时模型检测到的遗漏框和错误框的数量将会增加。考虑到以上情况,为提高模型检测的准确性[11-12],本文使用DIOU-NMS方法,其计算函数方程可以定义为:
(2)
式中:Si表示第i个检测框对应的置信度得分,RDIOU(M,bi)表示基于DIOU的检测框交叉比,M表示置信度得分最高的检测框,bi表示剩余检测框集合中的第i个检测框,Nt表示设定的阈值。本文DIOU损失函数[13-15]的惩罚项可以定义为:
(3)
如图5所示,c是覆盖两个锚框的最小封闭框的对角线长度,d=ρ2(b,bgt)是两个锚框的中心点的距离。其中b和bgt分别表示和的中心点,ρ为欧氏距离,c为覆盖两个框的最小包围框的对角线长度。DIOU损失函数可以定义为:
(4)
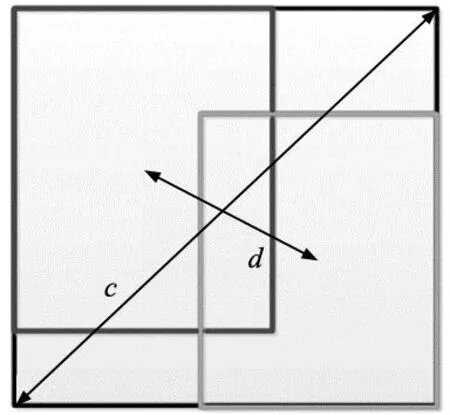
图5 边界框的DIOU损失
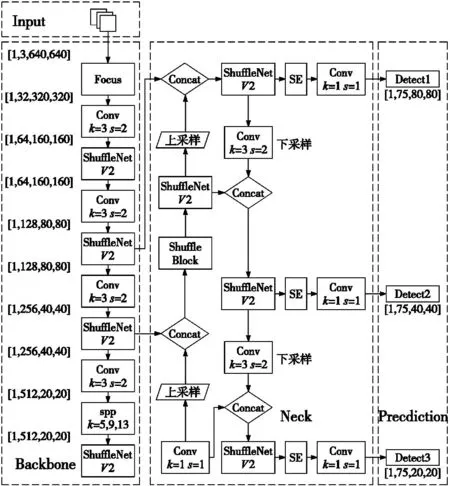
图6 改进后的YOLOv5s网络模型结构
以此来看,DIOU损失函数不是按外接矩形和并集面积的差值,而是同时最小化外接矩形的面积和两框中心点的距离,这会使得网络更倾向于移动边界框的位置来减少损失函数。因此,考虑到影响边界框检测的3个几何因素,即重叠区域、中心点距离和纵横比,并在此基础上将DIOU-NMS方法添加到本文的模型中,从而加快了模型的收敛速度,提高了模型的性能。
3 结果与分析
实验环境:在该实验中使用的计算机中央处理单元(CPU型号)是Intel(R)Core(TM)i7-12700F CPU@2.10 GHz,并且运行存储器是16 GB。图形处理器(GPU型号)为NVIDIA GeForce RTX 1080独立显卡,显存为8 GB。采用64位Windows 10操作系统作为软件环境,PyCharm作为开发平台,PyTorch作为深度学习框架,Python作为编程语言,CUDA 11.3版本并行计算框架作为开发平台,如图7所示。

图7 注塑齿轮缺陷检测平台环境
实验数据集共包含2000张分辨率为640×640的图片,按照8∶2的比例划分为数据集和验证集。在训练过程中,设置每批次训练16张图片,初始学习率为0.003,IOU阈值为0.5,针对所有参照模型均按照这些参数训练300个Epoch。
数据集预处理:采用自制的齿轮缺陷数据集,其中主要包括轮齿变形、轮齿缺失、表面黑点3种情况,如图8所示。运用VSD-YOLOv5s模型进行缺陷检测,采用Mosaic增强方法和自适应锚框方法对于数据集进行前期处理。

图8 轮齿破损、轮齿缺失、表面黑点缺陷图
本文VSD-YOLOv5s模型的模型评估指标主要包括准确率(P)、召回率(R),平均识别精度(MAP)、识别速度(FPS)。
(5)
(6)
(7)
式中:TP表示正确识别齿轮缺陷,FP表示对齿轮缺陷识别的错误分类,FN表示不明齿轮缺陷,C表示齿轮缺陷对象类别的数量,k表示IOU阈值,N表示阈值的IOU数量,P(k)表示识别精度,R(k)表示召回率。
如图9所示,为了对VSD-YOLOv5s模型的检测性能进行全面评估,本文采用YOLOv5s和VSD-YOLOv5s作为纵向比较模型、采用经典的目标检测模型Fast-RCNN作为横向比较模型,设置相同的实验参数,上述模型的检测效果表1所示。
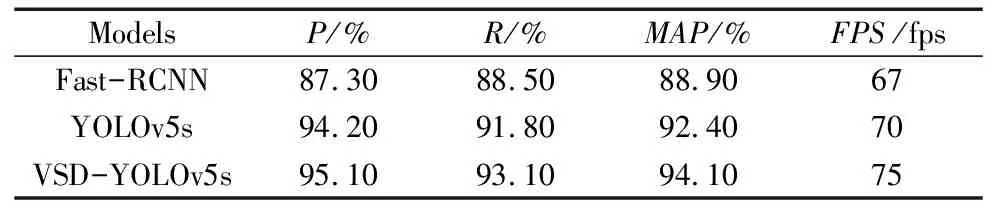
表1 模型检测效果对比

图9 VSD-YOLOv5s模型测试集检测
由表1的实验结果可知,VSD-YOLOv5s的MAP达到94.1%,准确率达到95.1%,相较于另外3种模型有所提升,对各类表面缺陷具有良好的检测效果,识别速度相较于YOLOv5s,FPS提高5 fps。因此,与YOLOv5s,Fast-RCNN两种模型相比,VSD-YOLOv5s模型具有优越的检测性能,取得了最佳的检测效果,能够满足在线缺陷检测系统的较高识别精度需求。
本文将3种模型在测试过程中产生的准确率以及召回率记录并绘制P-R曲线图,如图10所示,通过P-R曲线我们可以看到VSD-YOLOv5s模型的性能优于Fast-RCNN和YOLOv5s。
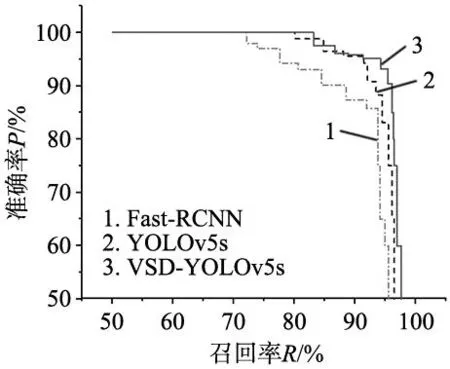
图10 缺陷检测3种模型的P-R曲线
为了验证不同改进方法对YOLOv5s模型性能的影响,本文对多种改进方法进行了比较与讨论,如表2所示。“√”表明网络模型中加入此模块,而“×”表明网络模型中没有加入此模块。原YOLOv5s模型的大小是14.58 MB,FPS为70 fps。使用ShuffleNetV2模块的轻量级ShuffleNetV2-YOLOv5s模型的大小减少到7.95 MB,FPS提升到74 fps。结果表明,当在模型中加入ShuffleNetV2时,可达到模型轻量化的效果并提升识别速度;单独使用SE模块时,YOLOv5s模型的MAP从91.2%增加到 92.1%。ShuffleNetV2-YOLOv5s模型的MAP从91.80%增加到93.8%。当SE注意力机制、DIOU-NMS以及ShuffleNetV2同时应用时,相比于原模型,VSD-YOLOv5s模型的识别准确率提升了0.9%,识别精度提升了1.7%,识别速度提升了5 fps,模型的性能得到了全面改善,达到最优。

表2 VSD-YOLOv5s改进模型与其他模型对比
4 结论
针对注塑齿轮缺陷检测存在的问题,提出一种VSD-YOLOv5s的齿轮缺陷检测轻量化网络模型结构,在改进后的模型架构中,使用了轻量级的ShuffleNetV2模块,为了准确识别注塑齿轮缺陷的不同种类,在模型中引入SE注意力机制,将NMS改进为DIOU-NMS方法加速模型的收敛,在不同测试集进行测试验证VSD-YOLOv5s网络模型的可行性,实验结果表明,模型满足在线检测系统对高实时性、低漏检率和低误检率的要求,结构更简化,复杂度更低,检测识别精度更高。未来在模型的实际应用中,将建立缺陷样本库,并及时收集和完善样本库,提升检测效果。
