基于CUCKOO算法的RBF网络监督磁悬浮自适应控制
2024-04-25王思君
王思君
(云南省煤矿安全技术培训中心,云南昆明 650205)
0 引言
磁悬浮以不接触方式实现对象物体在目标位置的悬浮控制。因为没有机械接触,所以具有功耗低、污染小的优势。该技术在交通运输、航空航天以及工业生产中有可观的应用前景[1-2]。电磁场的分布特征使得对象系统具有明显的非线性和建模不确定性[3-4]。因此,悬浮控制策略的适应性改进是一个值得长期研究的问题。
从既有结论可见,PID方案控制结构简单,易于实现,但控制精度不高,对环境适应性差,于是相应改进方案成为关注方向。比如,以神经网络逼近、模糊控制等智能化方法得到控制律,可减小模型不确定性的影响[5];采用LQ优化测算控制参数,可降低控制参数选择对调试经验的依赖程度[6]。将智能优化算法与反馈控制相结合,采用分数阶控制可改进控制精度[7]。系统运行时的干扰因素是无法准确测量的,这里考虑如何在确保系统稳定性和鲁棒性的同时,提高系统的控制精度和自适应能力。
针对扰动不确定时的控制参数不容易整定问题,基于神经网络监督,采用前馈加反馈的监督控制方法确保系统具有良好的性能,提出基于RBF网络监督的神经网络监督控制(NNSC)。监督网络通过权值学习整定成为主控方式,而当系统出现干扰时,传统反馈控制器重新起作用,确保系统的稳定性和鲁棒性。以固高GML1001试验装置参数为基础数据,通过Matlab仿真验证并分析了所得方案的性能。
1 磁悬浮对象模型分析
单自由度磁悬浮试验装置的基本原理如图1所示。通过电磁线圈输入电流的调节来控制磁场引力F(i,x),当悬浮小球受到向上的电磁引力与其所受重力达到平衡时,小球便能悬浮在目标位置。从系统输入(输入电流i)到系统输出(悬浮距离x)之间的数学关系可以通过小球的力学分析和线圈的电磁分析得到。
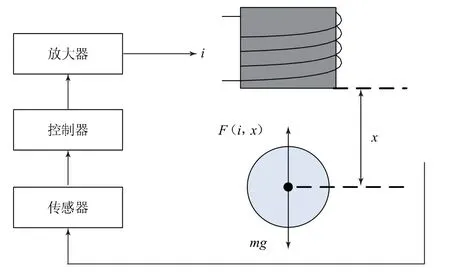
图1 悬浮装置原理分析
在图1所示系统中,忽略小球受到的不确定干扰力,则被控对象小球在此系统中只受电磁引力和自身重力的影响,其在竖直方向的动力学方程为:
式中:x为小球质心与电磁铁磁极之间的气隙(以磁极面为零点);m为小球的质量;g为重力加速度,g=9.8 m/s2。
假设电磁铁未工作在磁饱和状态下,且每匝线圈中通过的磁通量都是相同的,则瞬时绕组线圈电感为:
式中:μ0为空气磁导率,μ0=4π×10-7;S为电磁铁横截面积;N为线圈绕组匝数。
那么,磁场的能量为:
定义K=μ0SN2/2,则小球受到的电磁引力为:
可知,电磁引力与气隙是非线性的反比关系,这也是磁悬浮系统不稳定的根源所在。
当小球处于平衡状态(i0,x0)时,它所受合力为零,即:
在平衡位置对式(4)进行线性化处理,略去高阶项后,可得电磁铁绕组中的瞬时电流i、气隙x之间的关系模型为:
下面设计控制方案,实现调节控制电流使小球稳定悬浮在平衡位置的目的。
2 控制律设计
以式(6)为受控系统的基础模型,进行磁悬浮控制律的设计。
2.1 PD控制器设计
利用系统线性化模型,可以通过时域设计方式得到PD控制律[8]。记串联PD控制器的传递函数为:
通过稳定性判据,可知保持磁悬浮系统稳定须有:Kp<-0.113 3,Kd<0。
再考虑系统过渡过程性能,即超调量和调节时间要求,以欠阻尼闭环稳定为设计目标,通过模型匹配方法,可得到控制参数:Kp=-20,Kd=-0.072 8。
2.2 RBF网络监督控制
磁悬浮系统网络监督控制结构如图2所示。图中所示的控制环节由两部分组成:传统PD控制和基于RBF网络的监督控制。系统启动初始以PD控制实现闭环运行。同时,前馈RBF神经网络控制器以PD控制器的输出信息进行网络权值的学习,通过迭代调整逐步减弱反馈控制输入,实现RBF网络控制器从训练到主控的转变。事实上,此处RBF网络的本质是模拟了被控对象的逆模型[9]。但是,当外部干扰信号d显著变化时,反馈控制器会再次起主导作用。
图3为前馈RBF网络的内部结构。由于图2所示结构中的网络输入是一维的,所以,在图3中仅有一个输入。RBF网络只需要调节网络权向量W=[w1,…,wm]T,因而具有算法简单、运行快的优点。
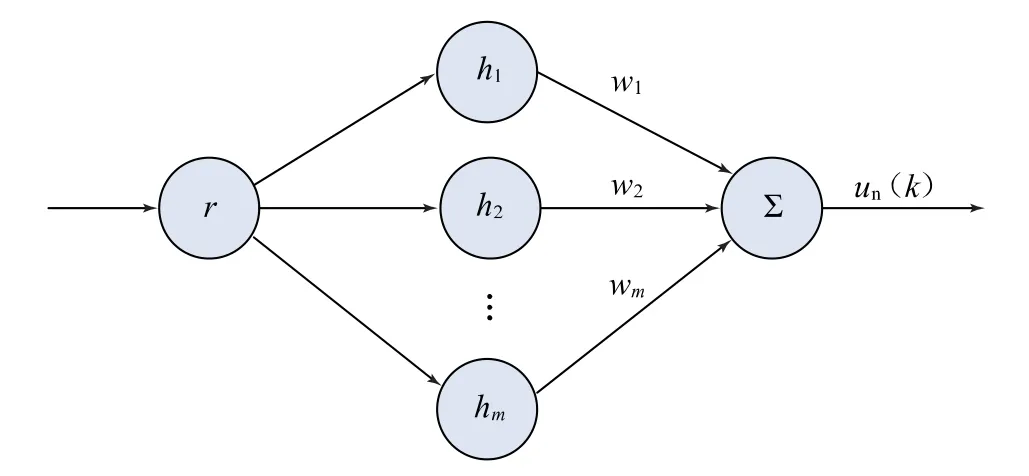
图3 RBF神经网络结构
网络输入为系统输入r(k),网络的径向基向量为H=[h1,…,hm]T,其中hj为高斯基函数,即:
式中:Cj为网络第j个节点的中心向量,Cj=[c11,…,c1m]T;bj为节点j的基宽参数,bj>0,j=1,…,m;并记B=[b1,…,bm]T为高斯函数的基宽参数。
则RBF网络的输出为:
式中:m为RBF网络隐层神经元的个数。
此时,所得控制律为:
式中:upd(k)和un(k)分别为PD控制器和RBF网络控制的输出分量(图2)。
根据神经网络监督控制原理,要想使得神经网络控制器占主导地位,设网络调整的性能指标为:
2.3 基于CUCKOO算法的网络权值调整
为实现神经网络权值的优化,进一步尝试采用搜索效率高、容易得到全局最优解的布谷鸟算法完成式(9)中网络权值的调整。
选择目标函数为:
记网络权值W=[w1,…,wm]T为巢穴位置,以式(12)为适应值,布谷鸟算法以迭代方式搜索最优巢穴,即为最优解。下面对最优解(巢穴)的搜索算法进行说明。
Step1,初始化。对巢穴位置初始化并作为最优位置向量,记g0=[W1(0),W2(0),…,Wn(0)]T。
Step2,位置更新。保留上一代最优巢穴位置分量Wb(k-1),进行全局随机探索游走,其搜索公式为:
这里,α为网络权值学习率,随机莱维飞行服从的分布为Levy~u=t-1-β,(0<β≤2)。
得到新巢穴的位置后,对其测试,并与上一代的巢穴gk-1=[W1(k-1),W2(k-1),…,Wn(k-1)]T进行对比,用适应值较好的巢穴位置替换较差的巢穴位置,从而得到较优的新的巢穴位置gk=[W1(k),W2(k),…,Wn(k)]T。
Step3,新解评估。用随机数r表示宿主鸟发现外来者的概率,并与预设概率pa比较,若r>pa,则随机重置Wp(k+1),反之保持,最后保留测试值较好的一组巢穴位置Wp(k+1)。测试这组巢穴,用较好的巢穴位置替代较差的巢穴位置,得到一组新的巢穴位置:gk=[W1(k),W2(k),…,Wn(k)]T。
Step4,迭代优化。找出最后得到的gk中最优的一个巢穴位置Wb(k)和最优值fmin。若达到预定的迭代次数或精度要求,则输出全局最优值fmin和对应的全局最优位置Wb(k)。反之,返回Step2继续迭代更新。
3 试验数据分析
在Matlab/Simulink软件环境下对所得系统的性能进行仿真分析,检验所得悬浮控制系统的有效性。系统分析重点为两个目标:
1)悬浮小球实现对目标位置的稳定快速跟踪;
2)在干扰存在时,系统具有一定的鲁棒性和自适应能力。
并通过比较分析反馈PD控制和网络监督控制的作用。
以固高GML1001磁悬浮试验装置参数构建对象仿真模型,其主要参数由表1给出。
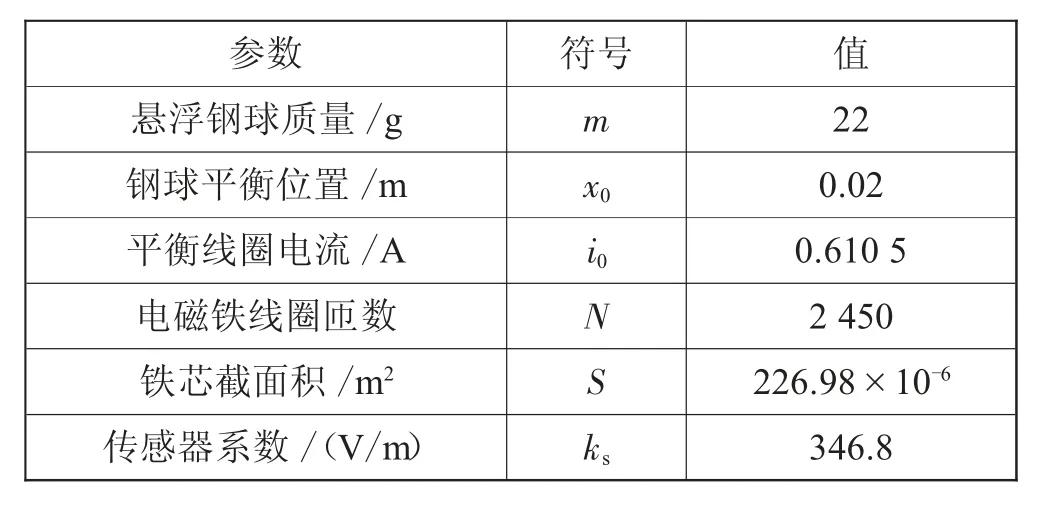
表1 悬浮系统主要参数列表
结合第1部分的模型分析,可得被控对象为:
取采样时间为1 ms,采用z变换进行离散化,经过变换后的离散化对象为:
设定目标信号为在平衡点上下浮动5 mm的位置,指令信号为幅值为0.005的方波信号。网络隐层神经元个数取为4,网络结构为1-4-1,网络的初始权值取0~1的随机值,高斯函数的参数值取Cj=[-2 -1 1 2]T,B=[0.5 0.5 0.5 0.5]T。采用控制律(10)和权值调整算法(13),网络权值学习率为α=0.05,预设概率pa=0.25。对所得系统进行仿真分析。权值搜索迭代设定为300,布谷鸟算法的迭代过程如图4所示。
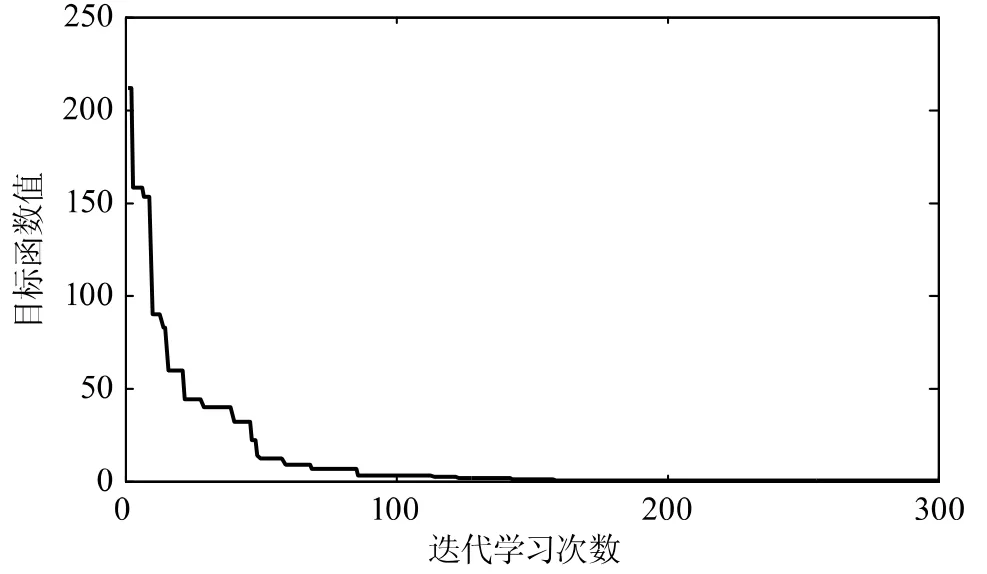
图4 布谷鸟算法迭代过程
3.1 跟踪性能分析
对目标方波信号进行跟踪,模拟随机干扰信号的影响,在控制分量中加入相当于控制信号强度10%的随机干扰,图5给出了系统的仿真输出。从图中可见,实线表示的小球悬浮位置准确跟踪了虚线表示的目标信号。在0.4 s对悬浮小球施加脉冲干扰(触碰),控制律能够很快消除不确定干扰所造成的影响。
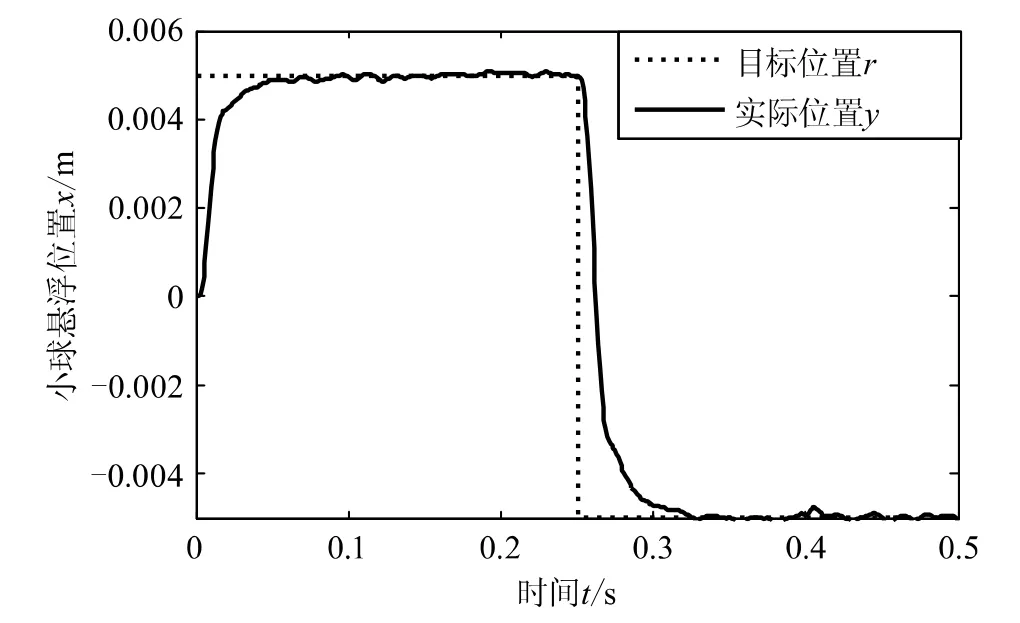
图5 随机干扰性的位置跟踪
图6 给出的是系统运行0.5 s时间内的控制律,同时给出反馈控制分量和前馈网络控制分量。从图中可以看出,当系统稳定运行时,前馈网络控制分量起主要作用,而当目标信号发生变化或者出现干扰时,反馈控制分量重新恢复作用,以此保证系统的稳定性及自适应能力。这正是网络监督控制的优势。
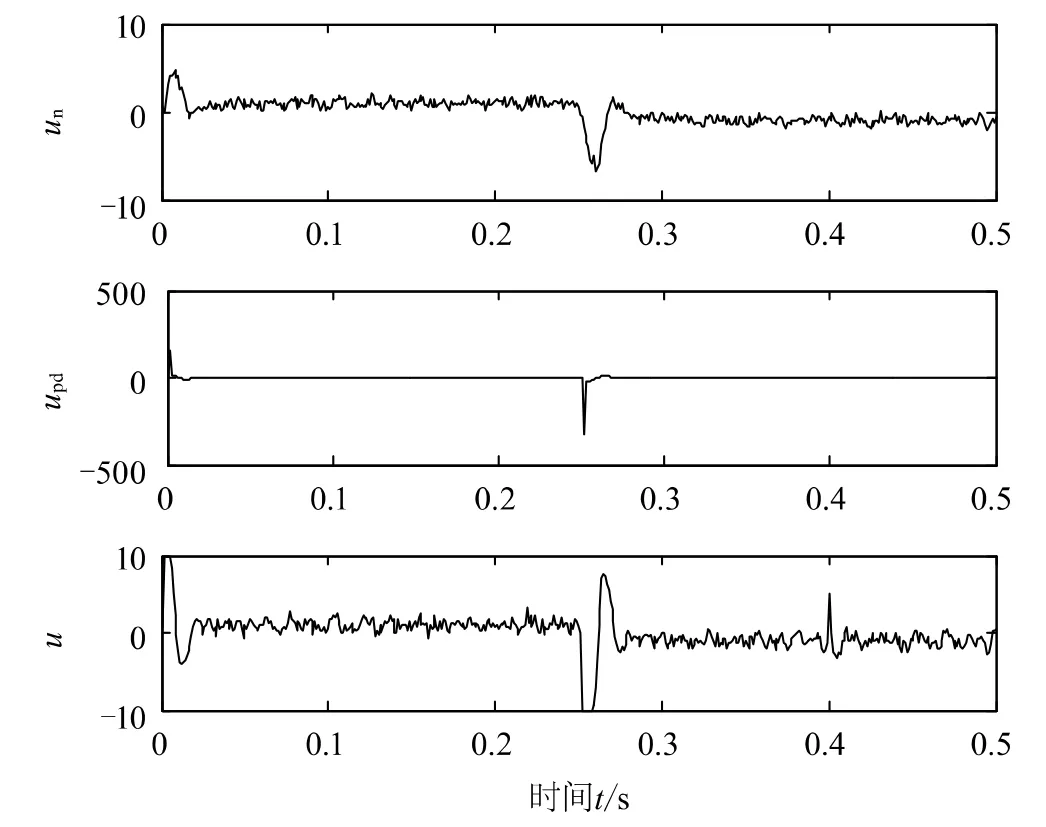
图6 随机干扰下的控制律
3.2 控制分量分析
进一步分析神经网络监督控制(NNSC)相对于PD反馈控制的优势。仅在0.1—0.2 s施加上述干扰,并在0.4 s模拟外部触碰脉冲。分别独立采用两种控制方案进行仿真,所得控制结果如图7所示。
从图中可见,仅用反馈控制时,系统对干扰信号仍具有较好的鲁棒性,能够克服其影响而保持稳定运行;但系统目标跟踪准确性受到影响,存在稳态误差。实线表示的网络监督控制方案NNSC则不存在稳态误差,仅仅在干扰影响下产生小幅波动。
表2比较了图7中两个输出信号的典型性能指标,可见增加了前馈监督的NNSC控制方案在过渡过程稳定性和跟踪精度方面都优于PD反馈控制。

表2 控制性能比较列表
图8对控制律分量进行了比较分析,PD控制量在0.25 s跟踪信号变化时短暂切换为主要控制信号。需要说明的是,PD控制量相对于网络控制量具有更好的快速性,其原因在于RBF网络权值的调整是基于反馈控制进行的。也就是说,NNSC控制的网络监督作用需要通过对系统前馈控制器的学习才能逐步成为主导,是网络的自学习过程。
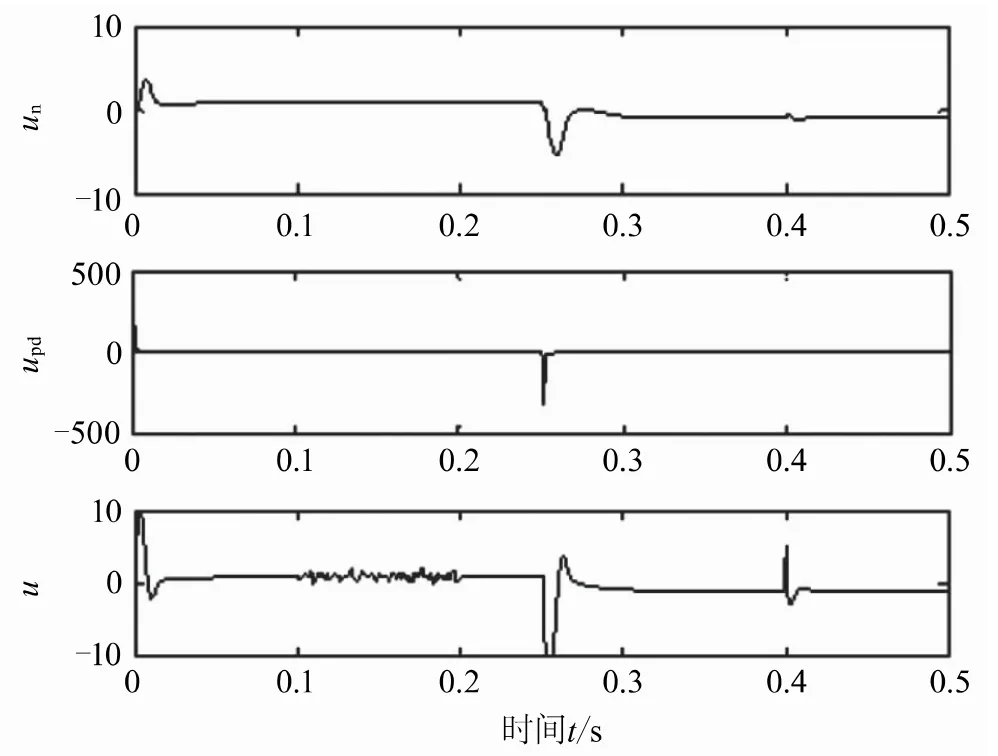
图8 图7对应的控制律
4 结论
磁悬浮技术在一些领域已经具有了一定试验性应用基础。目前,以提高系统控制精度、改良其容错性为目标的控制方案的研究成为值得长期关注的问题。结合试验数据,总结如下:
1)针对不确定干扰影响下的磁悬浮位置控制问题,提出基于前馈网络监督的NNSC控制方案,仿真结果验证了所得方案的有效性。以22 g小球为控制对象,0.04 s内实现了5 mm的位移控制,且对不确定干扰具有一定鲁棒性。
2)监督网需要对原有反馈控制器进行学习,以完成其网络权值的调整,这使得网络监督控制完全起主导作用需要一个过渡过程。
3)在拟合复杂非线性控制信号的问题中,神经网络的大规模并行计算、冗余性、自学习以及自适应能力可为控制理论带来生机。
