基于注意力机制的轻量化YOLO v5s 蓝莓检测算法
2024-04-24刘拥民麻海志
刘拥民,张 炜,麻海志,刘 原,张 毅
(1.中南林业科技大学 计算机与信息工程学院,湖南 长沙 410004;2.中南林业科技大学 智慧林业云研究中心,湖南 长沙 410004)
蓝莓(越橘属)是人类五大健康食品之一,被公认为“世界水果之王”,因其美味的口感和各种功能成分(有机酸、酚类、矿物质和维生素)而备受青睐[1]。截至2020 年底,全球超过25 家跨国企业到我国投资蓝莓规模化种植生产,蓝莓栽培面积664万hm2,总产量3 472 万t[2]。然而,手工采摘蓝莓很麻烦,而且专业的采摘人员也很少。为了满足市场的实际需求,减轻人工压力和人工成本,能够识别蓝莓成熟度的采摘机器人正在逐渐取代人工操作[3]。此外,蓝莓成熟度的准确识别可为种植者及时提供果园蓝莓的成熟比例,从而合理安排采摘时间,进而减少未成熟果实损失。
目前国内外有关水果精准识别和成熟度分类等方面的研究已取得了一定进展。朱旭等[4]通过改进Faster R-CNN[5]算法,设计了一种对背景干扰、果实遮挡等因素具有良好鲁棒性和准确率的蓝莓果实识别模型,其对成熟果、半成熟果和未成熟果的识别准确率高达97.00%、95.00%和92.00%,平均识别准确率为94.67%。ZHENG 等[6]针对自然环境下绿色柑橘与背景颜色相似的问题,提出了一种名为YOLO BP 的多尺度卷积神经网络来检测自然环境中的绿色柑橘,其准确率、召回率和平均精度分别为86%、91%和91.55%。苏斐等[7]将YOLO v3[8]算法原骨干网络Darknet53 替换成轻量级的Mobilenet-v1 网络,检测绿熟期番茄验证集的平均精度均值为98.69%,测试集的平均精度均值达到98.28%,且改进后的模型大小缩小为原来的39.38%。陈仁凡等[9]针对温室环境下草莓快速准确识别的问题,在YOLO v5s 模型的主干中引入Shuffle_Block 作为特征提取网络并在颈部结构中使用全维度动态卷积模块ODConv,改进后的YOLOODM 模型的平均精度高达97.4%,且模型大小缩减了43%。李志军等[10]通过更换深度可分离卷积和添加注意力机制模块对YOLO v5 算法进行改进,解决网络中存在特征提取时无注意力偏好问题和参数冗余问题,从而提升检测准确度和减少网络参数量,其平均精度最高达到96.79%。YANG 等[11]为了实现蓝莓在密集粘连、遮挡严重的情况下快速准确的定位,设计了一个新的注意力模块NCBAM,并在YOLO v5s 模型中引入了小目标检测层和C3Ghost模块,从而提升了2.4 百分点的检测精度。但改进后的模型比原YOLO v5s 模型的网络参数量更大,因而提出在降低网络参数量和提高检测能力方面需进行更深入的研究。
模型的检测精度和参数量对目标检测在智慧农业移动设备中的使用有着极其重要的影响。所以考虑到模型的应用前景,需要减少模型的参数量并提高其检测准确性,从而使算法能部署到计算能力较低的设备,降低制造或购买设备的成本。以自然环境下的蓝莓为研究对象,在YOLO v5s 模型的基础上去除最大目标检测层的结构,并引入MHSA(Multi-head self-attention,多头自注意力)和S-PSA(Sequential polarized self-attention,顺序极化自注意力),提出一种基于注意力机制的轻量化YOLO v5s蓝莓检测算法。在预测蓝莓产量的同时,还能区分不同成熟度的蓝莓,以便在机械化采摘过程中能够准确地定位蓝莓果实,为现代自然环境下的智慧农业装备研发提供技术支撑。
1 材料和方法
1.1 试验数据获取
蓝莓成簇生长并分批次成熟,通常每簇中有1~3种成熟度蓝莓,即成熟果实、半成熟果实与未成熟果实[12]。本研究数据集是采集于江西省南昌市新建区的蓝莓果实公共数据集[11]。共采集了1 000 张蓝莓果实图像,采集类型为正面、侧面、重叠、遮挡和粘连。为了增加训练数据集中的样本数量,提高模型的鲁棒性并且更加逼真地模拟自然环境下的蓝莓果实,使用图像增强、添加噪声、调整亮度、旋转、平移、镜像和裁剪等数据增强方法[13]将数据集扩大为10 000个图像。数据集按照6∶2∶2的比例随机划分训练集、测试集和验证集,成熟蓝莓、半成熟蓝莓和未成熟蓝莓的标签数量分别为93 502、14 969、69 671 个。图1 显示了数据集的一部分样本,其中,图1a为原图,图1b—c为数据增强后的图片。

图1 数据集样本图片Fig.1 Dataset sample image
1.2 方法
1.2.1 网络模型 在现实的智能农业管理中,有限的硬件计算和存储资源会影响实时检测,所以自然环境下蓝莓检测算法的模型大小和检测精度尤其重要。作为单级检测模型,YOLO v5检测精度高、模型参数量小且检测速度快,其权重文件比YOLO v4[14]少了近90%。官方的YOLO v5 包含了YOLO v5s、YOLO v5m、YOLO v5l、YOLO v5x 4 种模型,它们的主要区别在于特征提取模块和卷积核不同,即网络深度和特征映射宽度不同,模型参数量和大小逐渐增加[15]。为了满足自然环境下蓝莓检测轻量化部署和实时检测的要求,选取检测速度最快和模型规模最小的YOLO v5s 作为基本检测模型,其网络结构如图2所示。

图2 YOLO v5s结构Fig.2 YOLO v5s structure
自然环境下的蓝莓检测存在果实小且密集、背景复杂且有枝叶遮挡、成熟度分布不均和检测的硬件设施条件有限等主要问题,因此,原始的YOLO v5s模型无法完全满足自然环境下蓝莓果实的检测需求,在检测准确度和模型轻量化等方面需要进一步优化。首先,为了减小模型的宽度、深度和参数量,加强模型识别小目标的能力,在YOLO v5s 主干网络和检测头的位置去除了最大目标检测层的结构。接 着,将MHSA 替 换 了SPPF(Spatial pyramid pooling-fast,快速空间金字塔池化)前原有的C3 模块,使模型学习到更全面的特征表示,增强模型对蓝莓图像中复杂的空间关系和上下文信息的理解能力。最后,在C3 模块中加入了S-PSA,以便模型能够更好地捕捉特征图中相邻区域之间的上下文依赖关系。改进后的网络结构如图3所示。
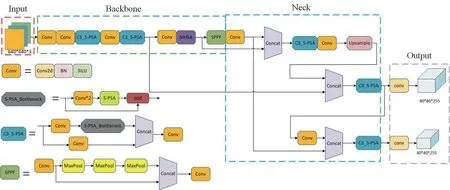
图3 改进后的YOLO v5s结构Fig.3 Improved YOLO v5s structure
1.2.2 小目标检测 原始YOLO v5s 模型中有3 个检测层,分别用于检测小目标、中目标和大目标[16]。由于蓝莓通常具有相对较小的尺寸,而最大目标检测层在原始YOLO v5s 中可能对蓝莓的检测效果并不理想。本研究在主干网络和检测头的位置去除了最大目标检测层的结构,从而减少模型的深度、宽度和参数量,加快模型的训练和推理速度,使模型可以在检测过程中更多地捕捉蓝莓的特定特征,从而获得更准确、更可靠的检测结果。
1.2.3 多头自注意力机制 MHSA是一种多头自注意力机制,最早是由VASWANI 等[17]在2017 年提出的。它在处理输入序列时能够自动捕捉序列之间的依赖关系,从而更好地理解上下文信息并提高模型性能。在传统的自注意力机制中,通过对输入序列中的每个位置进行加权求和,得到每个位置的表示向量。而MHSA 则将这个过程扩展到了多个头上,每个头都使用独立的权重矩阵来计算不同的表示向量,最终将不同头的结果在通道维度上拼接起来,以提高模型的表达能力和泛化能力。在目标检测中,图像通常被看作是一个多通道的矩阵,其中每个通道表示一些特征图。MHSA通过多个头的共同学习和组合可以帮助模型学习不同特征图之间的相互关系,并减少单个注意力头的过拟合风险,从而提高模型的表达能力和泛化能力。
具体来说,MHSA 的实现包括了3 个线性变换,分别是查询(Query)、键(Key)和值(Value)。MHSA先计算每个位置的查询向量和所有位置的键向量之间的相似度得分,然后使用softmax函数将得分归一化来获得注意力权重,最后利用这些权重对值向量进行加权求和得到输出。这个过程可以表示为:
其中,Q、K、V分别代表查询、键、值向量矩阵,dk代表每个头的维度,softmax函数将得分归一化。
1.2.4 极化自注意力机制 PSA(Polarized selfattention,极化自注意力)[18]使用正交的方式,在保证了低参数量的同时,保证了高通道分辨率和高空间分辨率[19]。此外,它在注意力机制中加入了非线性,使得拟合的输出更具有细腻度。本研究中使用PSA的串联形式,即S-PSA。它是先进行通道上的注意力计算,再进行空间上的注意力计算,其结构如图4所示。
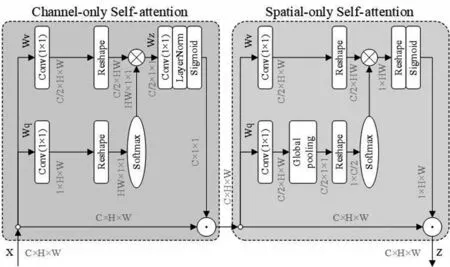
图4 S-PSA结构Fig.4 S-PSA structure
S-PSA 模块以顺序方式捕获特定于通道和特定于空间的信息,允许模型将不同级别的重要性分配给特征图中的不同空间位置和通道。本研究通过将该模块融入到C3模块中,从而更好地捕捉特征图中相邻区域之间的上下文依赖关系,有助于准确的对象定位、分类并提高其对空间的理解,同时保持与现有架构的兼容性。此外,S-PSA 模块通过关注信息空间和通道关系,使模型可以更好地处理对象被复杂视觉模式部分遮挡或包围的情况,有利于检测自然环境下被遮挡严重的蓝莓。
1.3 试验平台和评价指标
1.3.1 试验环境与参数设置 试验中使用的训练环境配置如表1 所示。训练的超参数设置如下:总迭代次数设置为25,迭代批量大小设置为16,工作线程数设置为8,初始学习率设置为0.001,权重衰减系数设置为0.000 5,动量因子为0.937。

表1 试验环境Tab.1 Test environment
1.3.2 评价指标 采用准确率(Precision,P)、召回率(Recall,R)、平均精度和参数量(Parameters)作为模型评价指标,公式如下:
其中,TP、FP和FN分别是识别正确、识别不正确和未识别的样本数量。准确率表示检测到的样本被正确识别的概率,召回率表示识别到某类样本的概率[20],AP 表示某个检测类别的平均精度。mAP是算法在识别3 种不同成熟度蓝莓时的平均准确率,n表示检测中的类别数量,n=3。i表示输入大小,f表示卷积核的大小,o表示输出大小[21]。
2 结果与分析
2.1 消融试验结果
为验证本研究提出的关于YOLO v5s 算法的3种改进方法,在数据集上进行消融试验以判断每个改进点的有效性。结果如表2 所示,模块1 中加入了MHSA,模块2 中加入了S-PSA,模块3 去除了最大目标检测层的结构。
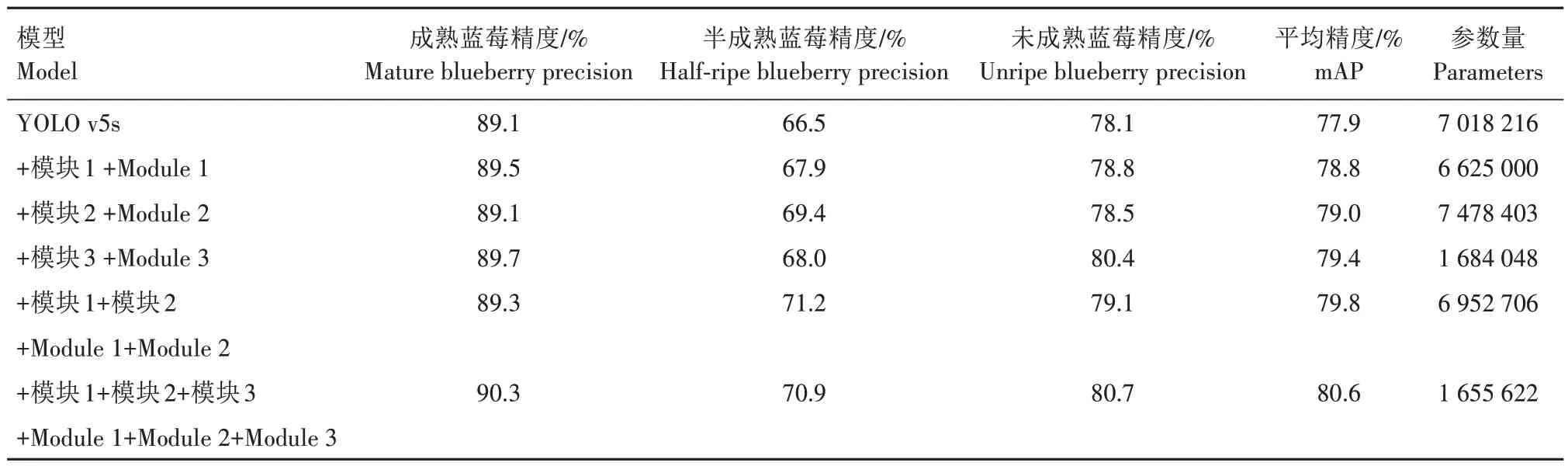
表2 YOLO v5s消融试验结果Tab.2 YOLO v5s ablation test results
如表2 所示,加入MHSA 后,3 种不同成熟度蓝莓的检测精度都有提升,平均精度相比原YOLO v5s模型提高0.9 百分点并降低了部分模型参数量。由于MHSA 增强了模型对蓝莓图像中复杂空间关系和上下文信息的理解能力,从而提高了模型的准确性和泛化能力。此外,加入的MHSA 的参数量小于SPPF 前原有的C3 模块的参数量,从而降低了部分模型参数量。加入S-PSA 后,半成熟蓝莓检测精度和平均精度分别提高2.9、1.1 百分点。因为S-PSA的加入能够更好地捕捉特征图中相邻区域之间的上下文依赖关系,有助于自然环境下蓝莓的检测。在原YOLO v5s 模型的基础上去除了最大目标检测层的结构后,3 种不同成熟度蓝莓的检测精度都有较大提升,平均精度提高了1.5 百分点且模型参数量减少至原YOLO v5s 模型的24%。在提高对蓝莓检测能力的同时,大大减少了模型的参数量,全面提升了模型的性能。3种模块同时加入YOLO v5s模型后,3 种不同成熟度蓝莓的检测精度分别提升1.2、4.4、2.6 百分点,平均精度提升2.7 百分点,模型参数量减少76.0%。成熟蓝莓检测精度与未成熟蓝莓检测精度提升较少的原因是,原有的成熟蓝莓检测精度较高,而未成熟蓝莓果实颜色与背景颜色较为相似且相对于成熟果实体积较小。
2.2 与其他常见轻量化模型对比试验结果
为了进一步证明本研究提出算法的有效性和优越性,将它与当前主流轻量化目标检测模型进行对比试验,结果如表3 所示。改进后的YOLO v5s模型相比于当前主流轻量化目标检测模型,有最高的准确率、召回率和平均精度,最少的模型参数量。虽然YOLO v5n 模型的参数量跟改进的YOLO v5s模型参数量相近,但其平均精度只有76.4%,而改进模型的平均精度有80.6%。此外,YOLO v8 模型的平均精度几乎跟改进的YOLO v5s 一样,但其参数量却是后者的6.7 倍。因此,本研究提出的算法相比当前主流轻量化目标检测模型,性能更加优越,检测自然环境下的蓝莓效果更好。

表3 与其他轻量化模型比较结果Tab.3 Comparison results with other lightweight models
3 结论与讨论
为实现自然环境下蓝莓果实的精确快速检测,解决蓝莓果实检测存在果实小且密集、成熟度分布不均、背景复杂等问题,提出了一种基于注意力机制的轻量化YOLO v5s 蓝莓检测算法。为了降低模型的参数量,增强对小目标的检测能力,在主干网络和检测头的位置去除了最大目标检测层的结构。通过在YOLO v5s中插入了MHSA,使模型学习到更全面的特征表示,增强模型对蓝莓图像中复杂的空间关系和上下文信息的理解能力。最后,在C3模块中加入了双重注意力机制S-PSA,使模型能够更好地捕捉特征图中相邻区域之间的上下文依赖关系。本试验结果表明,改进后的YOLO v5s 模型相比原YOLO v5s模型在成熟蓝莓、半成熟蓝莓和未成熟蓝莓的检测精度上分别提升1.2、4.4、2.6 百分点,平均精度提升2.7 百分点,模型参数量减少76.0%。此外,改进后的YOLO v5s 模型相比于当前主流轻量化目标检测模型,有最高的准确率、召回率和平均精度,最少的模型参数量。证明改进后的模型在检测自然环境下的蓝莓上有一定的优越性,能为蓝莓自动采摘系统提供准确的蓝莓定位且有利于部署到计算能力较低的硬件设备中,从而减少人工成本,提高蓝莓产业的经济效益。
