基于大语言模型与语义增强的文本关系抽取算法
2024-04-23李敬灿肖萃林覃晓婷谢夏
李敬灿,肖萃林,覃晓婷,谢夏
(海南大学计算机科学与技术学院,海南 海口 570228)
0 引言
实体关系抽取是指从非结构化文本中识别并提取出头实体、关系和尾实体的三元组信息的过程。作为信息抽取的基本任务之一,其抽取准确性将直接影响到信息抽取的准确性。随着现代科学技术的快速发展,信息抽取应用越发广泛,在问答系统、金融、法律等领域都有重要作用,因此信息抽取尤其是语义信息准确性高的信息抽取越来越受到人们的重视。
目前,实体关系的三元组抽取方法主要分为管道和联合两类。管道方法通常是先识别出实体,然后再提取实体之间的关系以进行关系抽取。早期实体关系抽取主要依赖于卷积神经网络(CNN)来处理文本。然而,这些方法存在一些局限性,比如卷积核大小的固定性和所提取特征的单一性等问题。
随后,文献[1]采用CNN模型和注意力机制相结合的形式来进行关系抽取。研究人员也逐渐将基于循环神经网络(RNN)的方法应用于实体关系抽取任务,这些方法能更好地处理文本中的长期依赖关系。文献[2]设计了一种双向循环门控单元,并集成注意力机制,能够捕获更多有价值的字符级信息。文献[3]则提出一种基于最短依赖路径的长短时记忆(LSTM)网络,用于文本的关系分类,能够收集最短路径上的异构信息。
虽然管道方法能在一定程度上实现实体关系抽取的效果,但该方法在结构上存在错误累积和三元组重叠的问题,并且也会忽略掉实体识别和关系抽取直接的关联。三元组重叠问题可以分为一对一正常类(OO)、单个实体重叠类(SEO)和实体对重叠类(EPO)3种主要类型。一对一正常类没有实体重叠,每个三元组的实体都是独立的,不共享;单个实体重叠类存在一个实体在多个三元组中重叠,但其他实体不重叠;实体对重叠类,即多个实体对在不同三元组中重叠可能会涉及多对实体。文献[4]提出一种利用词序信息和依存树结构信息的树形结构,将长短时记忆模型转化为树形结构进行建模,以提取实体和实体关系。然而,这种方法仍然存在一定的先后性问题。为了应对这个问题,研究人员开始尝试采用联合抽取或所谓的“端到端抽取”方法,通过联合建模来同时处理实体识别和关系抽取任务。文献[5]提出一种新的模型,由集合预测网络直接并行解码实体关系三元组,这种方法能同时完成实体和关系的抽取,从而避免了误差的累积。但是由于关系和实体会被同时解码,这又会导致实体主客体间联系薄弱的问题。
近年来的大语言模型,特别是ChatGPT的出现在各行各业都掀起了一波热潮。大语言模型(LLM)的最近进展已经显示出它在各个领域的巨大潜力[6]。文献[7]基于大规模预训练语言模型,提出一种API实体关系联合抽取模型(AERJE)。文献[8]利用GPT-3和Flan-T5 Large模型在不同监督水平下评估它们在标准关系抽取任务上的性能,取得了很好的效果。但目前基于大模型的关系抽取方法大都针对无监督学习领域,对于有监督任务缺乏成熟的模型训练方法和微调策略。
本文提出一种基于大语言模型的关系抽取算法。首先对大型语言模型 Meta AI(LLaMA)进行微调训练,使其更加适应关系抽取的任务。为了增强关系和实体之间的交互,在提取关系的基础上使用自注意力机制来增强实体对之间的关联程度,增强关系和实体之间的信息共享,接着使用平均池化泛化到整个句子中。针对实体对设计一个过滤矩阵,并引入词性信息进行语义增强,根据过滤矩阵中实体对的相关性过滤掉无效的三元组,有效减少误差传播和重叠问题。最后对两个新闻文本数据集WebNLG[9]和NYT[10]进行评估。本文的工作主要有以下贡献:
1)设计一个新的端到端结构,并将大语言模型进行微调,使其更适合关系抽取的任务。
2)针对实体对设计一个过滤矩阵,并引入词性信息进行语义增强,根据过滤矩阵中实体对的相关性过滤掉无效的三元组。
3)在NYT和WebNLG数据集上进行全面的评估,验证模型的有效性。
1 相关工作
随着重叠三元组问题的出现,实体关系联合抽取任务的难度以及复杂度大幅提升。因为模型需要识别和区分这些重叠的实体以及与它们的相关关系。解决这个问题需要新的建模技巧和策略,以处理不同类型的实体重叠情况。
Seq2Seq方法最早由文献[11]引入,采用序列到序列模型直接生成三元组,避免生成大量无效信息,并且能够捕捉输入序列中的长距离依赖关系。文献[12]提出一个新的标注策略,使用简单的神经网络就可以标注关系实体信息,通过简化模型,有效地提高了实体关系抽取任务的性能。然而,在处理单实体重叠和实体对重叠时仍存在一些不足。随后的研究着重解决了这些问题,并将解决方案分为基于复制机制的方法和基于标注策略的方法。基于复制机制的方法如CopyRE模型[13],通过自回归解码器按顺序解码三元组,该模型在当时获得了最佳的结果。但是,因为解码方式的局限性,CopyRE模型可能无法完全识别实体,并且可能造成三元组彼此之间无法进行平衡交互。文献[5]提出一种集合预测网络模型,可以直接生成三元组集合,并且通过并行解码三元组的方式,解决三元组之间的交互失衡问题。
尽管Seq2Seq方法已经成为自然语言处理(NLP)领域解决各种问题的主要方法之一,但是NLP问题的复杂性和多样性使得有些问题可以更好地通过图来表示和解决。文献[14]提出一种动态图方法,引入跨度注意层用于获取所有候选实体的表示并构建跨度图,这个跨度图被输入到图注意力模型中,以动态学习实体跨度与关系的相互作用。此外,文献[15]设计一种具备多头自注意力和密集连接的图卷积网络,利用多头自注意力机制为不同的关系类型分配不同的权重,确保各种关系的概率空间不会互相排斥。动态图方法在处理重叠实体关系抽取问题时取得了一定的进展,但也存在一些问题,尤其在处理实体对重叠类问题时表现不佳。
近年来,研究人员设计了许多预训练语言模型,这些模型在大量未标记的语料库上运行了无监督学习,并且获得非常不错的特征表示。文献[16]利用BERT模型[17]最后两层输出的隐藏信息构建一个二维矩阵以表示特征,通过遮盖不相关的实体来获取实体位置信息,在最终性能方面表现出色,但时间复杂度较高。文献[18]则探索了一种新颖的模型架构,将Transformer和指针网络相结合,更好地提取实体和关系,并且集成了语法引导的网络,将句子中的语法信息纳入到编码器中,提高模型对句子中关键词的关注度。在上述研究的基础上,文献[19]利用BERT模型对句子进行编码和解码,在验证阶段采用校准算法,过滤掉了部分不符合源句子事实的三元组,提升了结果的准确性。此外,文献[20]提出一种包含3个步骤的算法用于提取重叠的实体关系。该算法利用BERT模型获取句子的上下文信息,并且将这些信息共享给下游的2个子任务:命名实体识别和实体关系抽取,用以提高训练模型的性能。然而,采取共享参数的方法进行下游任务训练,容易造成误差传播的问题。
本文算法采用大语言模型作为编码器,并对其进行微调来学习实体和关系的语义特征。首先使用自注意力机制来增强实体对之间关联程度,增强关系和实体之间的信息共享,接着使用平均池化泛化到整个句子中。针对实体对设计一个过滤矩阵,并引入词性信息进行语义增强,根据过滤矩阵中实体对的相关性过滤掉无效的三元组。
2 模型
本文提出的端到端系统包括4个模块:编码器,关系提取,实体提取和词性过滤矩阵。基于大语言模型与语义增强的关系抽取方法如图1所示(彩色效果见《计算机工程》官网HTML版)。

图1 基于大语言模型与语义增强的关系抽取方法Fig.1 Relation extraction method based on large-language model and semantic enhancement
2.1 编码器
本文算法采用LLaMA[21]作为语言编码器,将句子转换为特征向量。LLaMA是由 Meta AI 发布的一个开放且高效的大型基础语言模型,共有7B、13B、33B、65B 4种版本。因其训练的数据集来源都是公开的,从而保证了其工作的兼容性和可复现性。本文选择LLaMA-7B模型,并对其进行了微调,使其更适用于关系抽取的任务。
2.2 关系抽取模块
在得到编码器的特征向量hi之后,将它输入到关系抽取模块。一个句子中可能包含多个关系,所以可以将关系抽取认定为多分类任务。每抽取一个关系必定对应一对实体对,但如何在抽取关系时利用实体信息是一个难点。本文提出一种模拟实体的方法,首先使用自注意力机制来增强实体对之间关联程度,增强关系和实体之间的信息共享,接着使用平均池化泛化到整个句子中。具体公式如式(1)~式(3)所示:
E=Avgpool(Softmax((WqhiWk)(hi)T)Wvhi)
(1)
havg=Avgpool(hi)
(2)
Prel=ReLU(Wr·[havg;E]+br)
(3)
其中:Wq、Wk、Wv、Wr和br是可训练的权重矩阵;havg指整体句子的信息向量;Prel是指正确答案为某关系的概率大小;hi是编码器得到的特征向量;E是指整体的模拟实体信息向量。
2.3 实体抽取
如图1所示,为了处理句子中的特殊实体重叠模式,如SEO重叠和EPO重叠,设计2个序列标记操作来提取实体对中的主语和宾语。模型包含2个全连接层,然后输入到Softmax激活函数来预测对象的位置。其中,Psub表示主语实体的位置信息,Pobj表示宾语实体的位置信息。具体公式如式(4)、式(5)所示:
Psub=Softmax(WsubPrel+bsub)
(4)
Pobj=Softmax(WobjPrel+bobj)
(5)
其中:Prel是关系抽取的结果;Wsub、Wobj、bsub和bobj是可训练的权重矩阵。
2.4 词性过滤矩阵
过滤矩阵的目标是在预测三元组的过程中筛选出与主语和宾语之间相关性较高的实体,以提高预测的准确性。这意味着它专注于选择与给定主语和宾语之间的关系更为相关的实体,以降低误差并提高模型性能。之前的关系抽取和实体抽取,可以看作是一个完整的三元组预测过程。关系抽取中的自注意力机制可以加强实体和关系之间的联系,但是仅靠实体抽取模块来确定实体对,使得主语和宾语之间的联系确实有些薄弱。为了解决这个问题,本文设计一个实体过滤矩阵,旨在加强主语和宾语之间的联系。本文设计一个大小为n×n的矩阵,其中n表示句子的长度。矩阵中的每个数字(i,j)表示横坐标i位置的词和纵坐标j位置的词是一个实体对。在面对多种关系和实体的复杂场景时,每种关系都会生成对应的得分矩阵。当得分超过预设阈值时,表示对应的2个实体具有这种关系。
本文在实体过滤矩阵的基础上进一步提出名词矩阵的理念。其核心思想在于大部分关于实体的句子通常都是由名词或名词性短语构成的。对2个数据集进行统计,名词性实体占总实体的结果如表1所示。

表1 NYT和WebNLG数据集上实体的词性统计Table 1 Part of speech statistics of entities on NYT and WebNLG datasets
通过仅关注名词或名词性短语中的有意义的候选对象,能够降低在实体识别任务上出现错误的风险。为了在研究中融合这种观察,本文利用词性分析工具StanfordNLP[22]来鉴别句子中的词性,从而构造一个名词矩阵Me,其中每个格子代表一个词。矩阵中名词赋予值λ,非名词的格子则维持为0值。将实体过滤矩阵与名词矩阵对应元素相乘,得到最终的词性过滤矩阵,从而过滤掉实体抽取模块中错误的主语和宾语,提高三元组的准确性。具体计算公式如式(6)所示:
Pi,j=σ(Wm·[hi,hj]·Me+bm)
(6)
其中:Pi,j代表i,j位置实体的相关概率;Wm是可训练权重;hi、hj为给定句子中第i、j个单词的编码嵌入;Me是名词矩阵的权重。
2.5 损失函数
本文算法的损失函数包含3个模块的损失,分别是关系损失Lrel、实体损失Lent和语法损失Lfl,计算公式分别如式(7)~式(9)所示:
(1-yi)ln(1-Prel(i)))
(7)
(1-yi)ln(1-Pent(i)))
(8)
(1-ki,jmi,j)ln(1-Pm(i,j)))
(9)
其中:nr是关系种类的数量;ne是句子的长度;i和j表示矩阵的行和列;ki,j是矩阵的真值;Pi,j是图1中灰色矩阵中的预测结果。最后,将这三部分相加,得到最终的损失函数,如式(10)所示:
Ltotal=Lrel+Lent+Lfl
(10)
3 实验
3.1 实验设置
实验是在Intel Xeon E5 2.40 GHz CPU的服务器上进行的,内存大小为48 GB,GPU 型号为NVIDIA Tesla V100,Linux环境为CentOS 6.8, 选择PyTorch框架和Python语言搭建深度学习环境。在该模型上训练了110个epoch,选择Adam作为模型的优化器。对于NYT数据集batch size大小设置为64,WebNLG数据集batch size大小设置为6。设置解码器的学习速率为0.001,语法矩阵的λ值为0.6,实体抽取模块和关系抽取模块的阈值都是0.5,词性过滤矩阵的阈值为0.4,编码器的学习率为1×10-5。
3.2 数据集
NYT数据集汇集了来自其语料库的文本,其中包括118万条句子和24个预设的关系分类。WebNLG是一个更为复杂的数据集,其数据量相对较少,但关系类别却更为丰富。该数据集中有5 000条普通文本句子和246个关系类别。此数据集为不同算法提供了2种标签格式(NYT*、WebNLG*),为了得到更全面的评估,本文针对这两种标签格式进行了实验。
3.3 编码器实验
使用LoRA[23]技术对LLaMA模型进行训练微调。LoRA会冻结原模型 LLaMA 参数,通过往模型中加入额外的网络层,达到只训练这些新增网络层参数的能力。其中,lr=0.003,LoRAR=8,LoRA Alpha为16, LoRA Dropout为0.05。
将微调之后的LLaMA与T5small[21]、T5-base[24]、Roberta[25]、Albert[26]、BERT[17]、LLaMA进行实验对比,实验结果如表2所示。

表2 不同大语言模型作为编码器的实验结果Table 2 Experimental results of different large-language models as encoders %
评估结果表明,在普通文本NYT和WebNLG数据集上,微调之后的LLaMA模型在准确率、召回率和F1值得分方面都取得了最高的性能。与原始的LLaMA模型相比,微调之后的模型可以提供更好的指标,验证了对大模型微调训练的有效性。
为了验证模型大小对关系提取任务的影响,实验分别部署了T5small(6 000万个参数)和T5-base(2.2亿个参数)。可以看出,更大的T5模型并没有提供更高的性能。这表明更大的模型尺寸并不一定会转化为更好的结果。
3.4 词性过滤矩阵相关实验
为了验证词性过滤矩阵中的名词λ取何值时,模型能够取得最优的结果,在NYT数据集上进行实验,实验结果如图2所示。横坐标为λ的取值,纵坐标为F1值,当λ的取值为0.6时模型能够达到最优的效果。

图2 在NYT数据集上不同λ值的F1值结果Fig.2 F1 value results of different λ values on NYT dataset
进一步验证不同的分词工具对于模型的影响,本节设计了NLTK[27]、spaCy[28]和StanfordNLP分词工具的对比实验。NLTK是一个广泛使用的Python自然语言处理工具库;spaCy是世界上最快的工业级自然语言处理工具,支持多种自然语言处理基本功能。表3是算法在不同分词工具上的F1值,可以看出这3种工具对于模型结果的影响并不大,说明模型的效果并不依赖于特定的分词工具。

表3 本文算法在不同分词工具上的实验结果Table 3 Experimental results of this algorithm on different word segmentation tools %
3.5 普通文本实验
表4显示了本文模型在这2个数据集上与其他基线模型的比较,加粗表示性能最优。除少量的准确率或召回率略低于PRGC模型外,本文模型在4个数据集上都获取了最高的F1值。该模型在WebNLG和WebNLG*数据集上 F1值相较PRGC模型分别提高了 1.9和0.2个百分点,在 NYT 和NYT*数据集上 F1 值分别有0.4和0.1个百分点的提升。

表4 本文模型在NYT、WebNLG、NYT*和WebNLG*数据集上的实验结果Table 4 Experimental results of this model on NYT, WebNLG, NYT* and WebNLG* datasets %
3.6 三元组复杂场景实验
获得句子中的多个重叠实体是具有挑战性的提取任务,多个实体情况指的是多个实体三元组出现在同一句子中。实体重叠可以分为3种类型:一对一正常类(OO),实体对重叠类(EPO)和单个实体重叠类(SEO)。一对一是指与一个实体只和另一个实体匹配,并且这个实体对只有一种关系。实体对重叠是指一个实体与多个实体具有关系,单个实体重叠是指一个实体和另一个实体具有多个关系。
首先对多实体情景进行评估,评估具有1~4个或更多三元组的句子。其中N表示句子中实体三元组的数量。评价结果如表5所示,在普通文本数据集(NYT和WebNLG)上的F1值都超过了90%。即使是在复杂场景N≥4时,本文算法也能够提供稳定的F1值,其中,NYT的得分表现为92.9%,WebNLG为93.7%,NYT*为92.6%,WebNLG*为92.8%,表明算法处理多实体句子的有效性。

表5 本文算法在复杂三元组场景下的实验结果Table 5 Experimental results of this algorithm in complex triple scenarios %
在第2个评估中考察了3个不同方面的实体重叠场景。表5显示本文算法在简单的时间内达到了很高的精度,在一对一匹配场景时,NYT上F1值为92.9%,WebNLG为92.2%。算法在NYT和WebNLG数据集上的任何场景中都能获得90%以上的F1值,表明算法具有处理复杂场景的能力。
3.7 消融实验
本节进行了一组消融实验证明算法核心组件的有效性。算法由3个核心部分组成:关系抽取模块、实体抽取模块和词性过滤矩阵模块。实验结果如图3、图4所示。图中的Rel、Ent和FL分别表示关系抽取模块、实体抽取模块、词性过滤矩阵模块。图3是在WebNLG数据集上的实验,可以看出,将3个模块相结合的模型达到最佳性能。类似的情况也可以在图4 NYT数据集中看到。
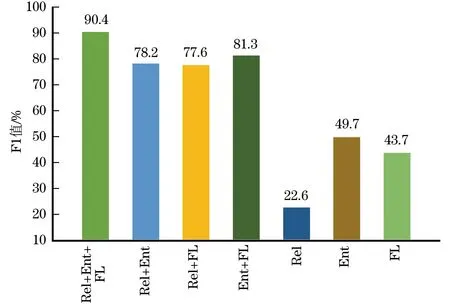
图3 本文算法在WebNLG数据集上的消融实验结果Fig.3 Ablation experimental results of this algorithm on WebNLG dataset

图4 本文算法在NYT数据集上的消融实验结果Fig.4 Ablation experimental results of this algorithm on NYT dataset
4 结束语
本文提出一种新的端到端关系抽取结构,该结构利用大语言模型的能力来自动学习关系的语义特征。首先在提取关系的基础上使用自注意力机制来增强实体对之间的关联程度,增强关系和实体之间的信息共享,然后使用平均池化泛化到整个句子中。针对实体对设计一个过滤矩阵,并引入词性信息进行语义增强,根据过滤矩阵中实体对的相关性过滤掉无效的三元组。实验结果表明,本文算法在NYT和WebNLG数据集上的F1值分别为93.1%和90.4%。下一步的工作包括3个方面:将在更多样化的数据集上进一步验证本文提出的算法;下游任务如知识图谱的构建,可以使用本文的技术进行开发;部署一个具有6亿个参数的大语言模型。
