显著性引导的目标互补隐藏弱监督语义分割
2024-04-22白雪飞卢立彬王文剑
白雪飞,卢立彬,王文剑,2*
1.山西大学计算机与信息技术学院,太原 030006;2.计算智能与中文信息处理教育部重点实验室(山西大学),太原 030006
0 引言
语义分割作为计算机视觉领域一项基础且关键的任务,一直受到大量研究者的关注。在过去十几年中,基于深度学习的全监督语义分割方法取得了长足进步(Long 等,2015),促进了如自动驾驶、医学图像分析这样的实际应用。但是全监督语义分割方法依赖于完整的像素级标注,而构建大规模的像素级标注数据集需要昂贵的人力物力(青晨 等,2020)。
弱监督语义分割旨在使用点(Bearman 等,2016)、涂鸦(Lin 等,2016)、边界框(陈辰 等,2020)以及图像级标签(Kolesnikov 和Lampert,2016)等更便捷的方式达到与全监督标签同样的训练效果。其中,基于图像级标签的弱监督语义分割受到广泛关注。
图像级标签中只包含物体的类别信息,缺乏相应的位置和形状信息。目前基于图像级标签的弱监督语义分割方法可分为单阶段法和两阶段法两大类。
单阶段法直接利用图像级标签训练一个端到端的网络,如早期Pinheiro 和Collobert(2015)利用多示例学习方式实现弱监督语义分割。之后Papandreou等人(2015)利用期望最大(expectation maximization,EM)方法训练弱标签下的语义分割模型。Zhang 等人(2020)则使用分类分支来训练并行的分割分支。
单阶段法存在监督信息不足的问题,为解决这一问题,两阶段法首先利用图像的类别标签训练一个分类网络,生成一组类激活图(class activation map,CAM)(Zhou 等,2016),从而得到待分割物体的粗略位置信息。然后,结合一些后处理方法获取每个像素的类别伪标签并利用这些伪标签训练分割网络。如早期Zhou 等人(2016)探索用类激活图实现弱监督下目标的定位。Lee 等人(2019)利用类激活图生成定位线索图,然后将其作为伪标签训练分割网络。Li 等人(2021)对类激活图进行精调,再将其作为分割网络的伪标签。
但是这类方法存在一些亟待解决的关键问题。一方面,由分类网络生成的类激活图比较稀疏,往往只关注到物体中最具辨别性的区域,能从中获得的前景目标信息较有限。而且类激活图存在误激活,这可能对后续的分割任务造成错误指导;另一方面,分割网络的性能依赖于伪标签的质量,而获取精确的伪标签还需要物体的形状、边界等信息。但在图像级标签中,这些信息无法直接准确获取,伪标签的质量难以保证。因此如何获取准确、完整的类激活图以及生成高质量伪标签是基于图像级标签的弱监督语义分割领域中的两个关键问题。
在生成完整类激活图方面,研究者提出了很多方案。Wei 等人(2017)提出一种迭代擦除方法,在下一次训练前先擦除前一次得到的高响应区域,从而让网络能够激活目标物体的剩余区域。但这种迭代操作耗时且迭代次数较难确定,网络在后续迭代中可能会关注到物体以外的背景区域。Hou 等人(2018)提出一种自擦除网络,可以阻止背景区域的误激活,但当图像中有多个物体类别时分割效果不佳。Jiang 等人(2019)提出了一种注意力累积策略,通过整合网络不同训练阶段生成的类激活图来获取更完整的目标区域。这种方式虽然可以产生更多激活区域,但是会引入大量难以消除的噪声,导致最终分割精度下降。Chang 等人(2020)通过挖掘子类别信息使网络关注到那些并非最具辨别度的区域。但是从父类生成伪子类标签时需要用到聚类方法,导致训练时间的增加。Wang 等人(2020)利用等变机制提供的自监督信息来增强网络获取完整类激活图的能力,但是由于引入了仿射变换等额外操作,影响了网络训练速度。为了获得更多的激活区域,Singh和Lee(2017)先将图像划分为一系列固定大小的块,然后随机隐藏图像中的部分块,迫使网络寻找其他激活区域。但是这种隐藏方式会导致原始图像不能完整地参与每轮训练,造成训练数据的浪费。后来,Zhang 等人(2021)先将图像划分为互补的两部分,再分别获取两部分的类激活图并结合起来作为监督信息引导激活区域的扩展。这样,既可以完整利用图像信息,也有效扩大了激活区域。但这种划分方式有很大的随机性,不能保证前景物体较为均匀地分配。如果物体被完全分到了其中一部分,而另一部分只包含背景,这会导致训练效果不稳定。
类激活图的扩展方面也涌现出很多研究成果。Kolesnikov 和Lampert(2016)提出了扩展种子区域的原则,成为这一方向研究的基础。Huang 等人(2018)利用相邻像素间的类别关系来迭代扩展初始种子区域,但是迭代时间长,且最终结果不够精确。Ahn 和Kwak(2018)提出训练AffinityNet(affinity network)来学习像素之间的相似度,然后生成转移矩阵并通过随机游走扩展激活区域。之后,Ahn 等人(2019)又提出了IRNet(inter-pixel relations network),通过显式学习类边界进一步改进AffinityNet。由于AffinityNet 和IRNet 性能较好,目前已广泛用于类激活图的扩展。
在伪标签生成阶段,由于缺乏形状及边界信息作为监督,传统方法难以获取高质量伪标签。为此,一些工作结合了显著图来提高伪标签的可靠性。如Wang 等人(2018)提出在贝叶斯框架下利用显著性引导实现标签边界细化。Yao 等人(2021)利用显著图提供的形状信息获取初始标签。这些方法利用了显著图提供的监督,一定程度上提高了伪标签质量,但由于显著图无法提供物体类别信息,难以用于网络的训练阶段,所以这些方法对显著图所提供信息的利用程度有限。
为了解决上述问题,本文提出了一种显著性引导的目标互补隐藏弱监督语义分割算法,通过对显著图和类激活图进行有效利用和结合,提高弱监督语义分割方法的性能。
针对分类网络生成的类激活图不完整的问题,本文提出一种新的类激活图生成方法。首先,利用显著图提供的位置信息大致定位前景目标区域,再对目标区域进行互补随机隐藏,保证互补划分的有效性;然后,将互补图像对送入网络获得各自的类激活图,以合成具有更完整激活区域的类激活图,并将其作为监督信息训练网络,提高网络获取完整类激活图的能力。
为了减少误激活,进一步提升网络获取完整类激活图的能力,本文在网络训练过程中引入自注意力机制,通过一个双重注意力精调模块,根据空间和通道关系进一步精调类激活图。
为了获取更准确的伪标签,提高分割网络的性能,本文提出了一种标签迭代精调策略。首先,利用上述得到的类激活图生成初始伪标签训练分割网络,之后可用该分割网络获得预测结果。分割网络的预测结果往往比原始的伪标签更加准确,因而可以作为新的标签重新训练分割网络来获得更加健壮的模型。但是有时单纯地利用分割网络的预测结果未必能提高分割模型的精度,本文方法结合分割网络初步预测、显著图和类激活图对初步分割结果进行精调,以修正分割网络预测结果中的误分类像素。利用修正的预测结果作为更加准确的伪标签迭代训练分割模型可以更有效率地提升模型精度。
本文在PASCAL VOC 2012(pattern analysis,statistical modeling and computational learning visual object classes 2012)数据集(Everingham 等,2012)和COCO 2014(common objectes in context 2014)数据集上(Lin等,2014)进行了类激活图生成实验和语义分割实验,大量实验结果验证了本文方法的有效性。
1 本文方法
1.1 整体框架概述
本文提出了一种新的基于图像级标签的弱监督语义分割方法,整体结构如图1所示。
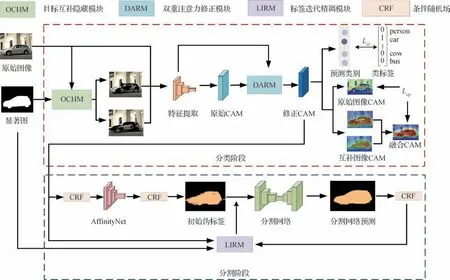
图1 整体框架Fig.1 Overall framework
模型的训练过程分为分类与分割两大阶段,包括3 个主要模块。其中,目标互补隐藏模块(object complementary hiding module,OCHM)生成目标互补图像对,双重注意力修正模块(dual attention refinement module,DARM)对获取到的类激活图进行修正,标签迭代精调模块(label iteration refinement module,LIRM)用于生成高质量伪标签。
首先,在分类阶段利用图像类别标签训练一个用于获取类激活图的分类网络。原始图像及其对应的显著图经过目标互补隐藏模块OCHM得到互补的两幅图像,然后将其与原始图像输入到分类网络进行特征提取,产生一个原始CAM,再经过双重注意力修正模块DARM 得到修正CAM。接下来,该类激活图所产生的预测标签将用于和真实类别标签计算分类损失,而互补图像的类激活图融合之后与原始图像的类激活图计算互补重构损失。
分割阶段利用分类网络生成的类激活图产生伪标签并训练分割网络。首先,获取类激活图并采用条件随机场(conditional random fields,CRF)修正后训练AffinityNet,进一步扩展激活区域得到初始伪标签,然后训练分割网络获得预测结果并通过CRF 进行修正。接下来,标签迭代精调模块通过预测结果、类激活图以及显著图获取新的伪标签,迭代训练分割网络。
1.2 显著性引导的目标互补隐藏OCHM
在训练获取类激活图的过程中,传统的分类网络会趋向于激活物体最具辨别性的区域,无法完整地定位目标。研究表明,对图像中目标的随机隐藏可以增强网络定位完整目标的能力(Singh 和Lee,2017),但是直接随机隐藏图像会导致一部分图像无法参与训练。采取互补隐藏方式可以利用全部的图像信息(Zhang 等,2021),但由于隐藏方式是随机的,存在仅仅隐藏了部分背景区域的情况,无法保证能按预想对目标物体进行隐藏。针对此问题,本文提出一种显著性引导的目标互补隐藏方法,利用显著图获取目标物体的位置信息,有效地将目标物体互补隐藏。
目标互补隐藏模块旨在获取原始图像的一对目标互补图像Ih和。Ih和在初始时设为与原始图像相同的值。与像素相比,以超像素块为基本单元能够在提高处理速度的同时,较准确地保留物体局部的轮廓信息。因此,首先对图像I∈R3×H×W进行超像素分割(Felzenszwalb 和Huttenlocher,2004)获取k个超像素块Si,i=1,…,k。定义显著图中显著区域为Is,非显著区域为。对每个超像素块Si,判断其是否位于显著区域Is中,如果是,则将其看做是目标区域,以50%的概率将Ih中对应于Si的区域进行隐藏,即将该区域中所有像素的值置为训练集图像均值,这样可以保证训练集和测试集之间的数据分布保持一致。如果图像Ih中超像素块Si所对应的区域是隐藏的,则在目标互补图像中保留相应区域;反之,在图像Ih中保留区域,在其目标互补图像中进行隐藏。而在显著区域以外的超像素块可看做是背景区域,在Ih和中予以保留。
如图2 所示,对于输入图像中的目标物体汽车,显著性引导的目标互补隐藏图像对生成算法可以在保留背景区域的同时,生成目标物体的互补对图像。整个过程如算法1描述,具体如下:
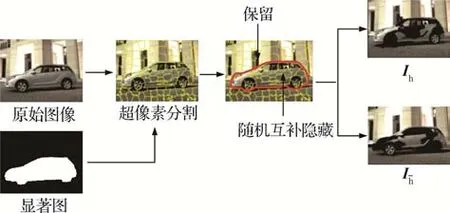
图2 显著性引导目标互补隐藏Fig.2 Saliency guided object complementary hiding
算法1 显著性引导的目标互补隐藏图像对生成算法。
输入:原始图像I,显著图E。
输出:目标互补图像对Ih和I-h。
1)初始化Ih和,令Ih==I。
2)对原始图像I进行超像素分割,获取k个超像素块Si。
3)对每个超像素块Si,执行下列操作:(1)若在E中显著区域内,执行(2);若不在,跳过该超像素块。(2)以50%概率隐藏Ih中对应Si的区域,若进行隐藏,则跳过该超像素块;若未进行隐藏,执行(3)。(3)将中对应于超像素块Si的区域进行隐藏。
1.3 类激活图生成
利用一个多标签分类网络,对1.2 小节中获取到的目标互补图像Ih和以及原始图像分别求其对应的类激活图。分类网络包含特征提取层、全局平均池化层和用于分类的全连接层。令C为数据集中所包含的总类别数,那么需要对C中每一个类别c分别求取其类激活图,而对于一幅图像来说,只有真实类别标签中存在的类别才有意义。定义输入图像某一类别c的类激活图为Yc∈RH×W,获取方式为
研究结果表明,与原始图像的类激活图相比,互补块的类激活图之和能挖掘出更多的目标物体区域(Zhang等,2021),即
式中,H为衡量类激活图所包含目标物体信息的函数。
由此可知,可以融合目标互补图像对的类激活图来获取更完整的目标区域。根据目标互补图像对的特性,对显著区域和非显著区域分别采取不同的融合策略。令分别是目标互补图像对的类激活图中与显著区域对应的部分,而分别是各自类激活图中与非显著性区域对应的部分。对于类激活图中与显著区域对应的部分,由于目标互补隐藏过程会带来明显差异,需要综合考虑两幅类激活图提供的信息,因此采用参数λ进行融合。若位于显著区域总的超像素块数为N,在Ih中隐藏块的数量为Nh,则λ=1-Nh/N,而=1-λ。对于类激活图中的非显著区域,直接取互补对类激活图中的对应位置最大值,以尽可能发现非显著区域中可能被忽略的目标物体。融合过程可表示为
式中,merge表示将得到的两部分合并成一幅完整的类激活图的函数,max 为对应位置求最大值的函数,表示融合后类别c的类激活图。
为了进一步引导分类网络激活更加完整的目标区域,利用上述融合方法得到的类激活图作为监督,与原始图像类激活图求L1 损失,定义互补重构损失Lcp为
1.4 双重注意力修正模块DARM
1.3 节中,用于生成类激活图的分类网络中卷积运算的感受野有限,从而导致同一类目标物体随着比例、照明和视角的变化,其对应的特征可能会随之产生一些差异。这些差异会引起类内不一致,对激活产生消极影响,使类激活图出现误分类的情况。此外,分类网络本身提取完整目标物体的能力较弱,仅利用显著性引导的目标互补隐藏方法还难以达到较好的扩展目标区域的效果。为解决上述问题,本文引入一个双重注意力修正模块,结合通道注意力和空间注意力,充分利用图像的全局信息对类激活图进行修正,从而进一步扩展激活区域。双重注意力修正模块如图3所示。
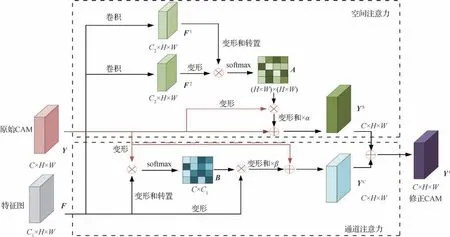
图3 双重注意力修正模块Fig.3 Dual attention refinement module
具体来讲,在空间上下文信息获取阶段,首先将特征图F送入卷积层生成特征图F1和F2,F1和F2变形为,其中N=H×W。之后将F1的转置矩阵与F2相乘,并通过一个softmax层生成空间注意力矩阵A∈RN×N,具体为
式中,aji为A中元素,表示位置i对位置j的影响,和为特征图中对应位置i和j的特征值。两个位置的特征表示越相似,其相似度越大。
接下来,将类激活图Y∈RC×H×W重整为RC×N,并与空间注意力图相乘得到修正后的类激活图,再乘以参数α并与原始的类激活图相加,参数α是一个可学习的标量,初始时设置为0 并逐渐分配更多权重。该参数允许网络在初始时先学习获取局部信息这一较简单的任务,再逐渐完成获取全局信息这一复杂任务。上述过程可表示为
式中,YS是原始类激活图和经过空间注意力修正后的类激活图的加权和,具有全局视野。相似的特征表示通过该方式会彼此增强,从而提高了类内一致性,减少了误分类的可能。
同理,可获得包含通道上下文信息的类激活图。首先,将Y变形为RC×N的矩阵,F变形并转置得到形为的矩阵,两个矩阵相乘并通过softmax 层获得通道注意力矩阵B∈,即
式中,B中元素bji表示第i个通道对第j个通道的影响程度。接着,B和F相乘的结果乘以参数β,并与原始类激活图求和,得到包含通道注意力信息的类激活图。该修正有助于提高特征的可辨别性,具体过程为
式中,YC为包含通道注意力信息的的类激活图。最后,将YS和YC求和得到双重注意力修正模块DARM的输出,即修正后的类激活图Y′。
1.5 损失函数
在图像级弱监督的背景下,本文训练分类网络时将图像级分类标签l作为监督。l为向量形式,lc为其第c个分量,值为1 表明第c类物体存在,值为0 则表示不存在第c类物体。在网络末端使用分类层得到预测向量z,zc表示z的第c个分量,由于要考虑到数据集中C-1个前景对象类别,可采用多标签软边界损失作为分类损失,具体为
式中,lcl为分类损失函数。定义原始图像得到的类激活图为Yo,目标互补图像对得到的类激活图分别为Yh和。相应地,定义由其得到的类预测向量分别为zo、zh和,因此,总分类损失Lcl定义为
为了增强网络激活更多目标区域的能力,还需考虑式(4)表示的重构损失Lcp。最后,总的损失函数Lal定义为
式中,γ用于平衡不同损失的权重,为了防止网络陷入局部最优,初始时将其设置为一个较小的值,在训练过程中逐渐增大它的值。
1.6 标签迭代精调模块LIRM
与人工标签相比,直接利用类激活图生成的伪掩码依然不能完整覆盖目标区域且存在一些噪声。因此,在用分类网络获取到类激活图后,还需要对其进行一些处理以生成能用于分割网络训练的伪标签。本文提出一个标签迭代精调模块LIRM,首先利用类激活图训练一个AffinityNet,通过随机游走方式扩散激活区域,并用CRF 精调目标物体边界。之后用上述流程得到的伪标签作为监督训练一个分割网络。
尽管用于训练的伪标签依然存在噪音,但卷积神经网络本身有一定的鲁棒性,其预测结果相比原始伪标签会有精度上的提升,所以一个简单有效的提升精度的方法就是用分割网络的预测作为标签再去迭代训练网络。但直接将预测结果作为伪标签迭代训练的效果提升有限。因为分割网络的预测结果尽管会更正一些初始伪标签中的错误,但其依然包含着一些误分类结果。本文结合了显著图、类激活图和分割网络的预测结果来获取更高质量的伪标签。显著图可以有效地区分前景物体和背景物体,但是无法分辨物体类别。类激活图可以精准定位物体类别但缺乏物体的完整形状信息。分割网络的预测可以提供比较完整的物体边界信息但是会掺杂误分类像素。通过充分利用3 种图提供的信息对伪标签进行精调,尽可能地减少误分类像素的影响。
初始伪标签依据类激活图生成,而类激活图只保留了每幅图像的类别标签中存在的类,所以由其得到的伪标签不存在没有的类别。但是由分割网络预测得到的标签可能会出现图像类别标签中不存在的类别,这部分像素的类别标签是可以确定存在误分类的,应该将其忽略以免给分割网络提供错误的指导。对应位置的新伪标签值具体为
式中,Tij表示对应位置的新伪标签值。其中,标记为255 的标签在训练过程中将会被忽略,这保证了网络免受这些误分类标签的影响。Oij表示分割网络的预测结果中第i行第j列的值,代表所对应的类别,如果Oij值为0,表明是背景类。
显著图可以较为准确地提供图像的背景区域,再结合类激活图可以修正一些被误分类为背景的像素。定义Eij,分别为显著图和类激活图中对应位置的值,若Eij不为0,且存在的值大于预定义的阈值t,则在新标签中置为类别c。若有多个类别的激活值满足上述条件,取激活值最大的类别作为新的伪标签,具体为
式中,argmax 为求最大值索引的函数。还有一类容易被忽略的情况就是分类标签中存在某类,但在分割预测中并未出现,且经过式(13)的修正后依然无该类别,造成这种情况的原因可能是该类别对应像素被误分类为背景像素。在弱监督背景下没有线索来纠正这种错误,因此选择将这种情况下的背景像素标签全部忽略,期待网络的自校正能力来发现未知的对象。该过程表示为
通过标签迭代精调模块得到的新伪标签用于迭代训练分割网络,以获得更高性能语义分割模型。
2 实验结果及分析
2.1 数据集与参数设置
实验在PASCAL VOC 2012 和COCO 2014 数据集上进行。PASCAL VOC 2012 数据集有20 个目标类别和一个背景类别,其中训练集图像10 582幅,验证集图像1 449 幅,测试集图像1 456 幅。COCO 2014数据集包含80个目标类别和一个背景类,其中训练集图像82 081 幅,验证集图像40 137 幅。在整个训练过程中只使用图像级标签。所有模型采用PyTorch 框架实现,在1 张40 GB 显存的Nvidia A100上进行训练,分类网络的初始参数是在ImageNet(Deng 等,2009)预训练获得的。在PASCAL VOC 2012 数据集进行分割实验时,分割网络参数通过COCO 2014数据集预训练获得。在COCO 2014数据集进行分割实验时,分割网络参数通过ImageNet 预训练获得。
分类网络中,本文采用Resnet-38(residual network-38)(Wu 等,2019)作为基干网络,图像根据最长边在[448,768]范围内随机缩放,然后裁减为448×448 像素大小输入网络。Batch Size 设置为8,训练轮次为8,初始学习率设置为0.01,采用Poly 策略进行参数更新,衰减率设置为0.9。
对于分割网络框架,本文采用了Deeplab v2(Chen 等,2018)框架,主干为Resnet101(He 等,2016),Batch Size为16,初始学习率设置为0.005,采用SGD(stochastic gradient descent)优化器,动量和权重衰减分别为0.9 和0.000 5,共进行20 000 次迭代训练。
为了验证本文方法的有效性,实验分为两部分。第1 部分对本文提出的类激活图生成算法进行验证,并与其他方法进行对比;第2 部分对比本文方法与几种经典的弱监督语义分割算法,并通过消融实验对本文模型中的模块进行有效性分析。实验中采用平均交并比(mean intersection over union,mIoU)作为评估指标。
2.2 类激活图生成实验
为了验证本文提出的目标互补隐藏方式生成类激活图的有效性,在PASCAL VOC 2012 训练集上获取类激活图进行评估。实验中通过遍历所有背景阈值并选择最佳阈值来评估类激活图效果。将多个尺度下生成的类激活图融合是提高精度常用的方式,本文在测试过程中也采用了这一方案,实验数据均采用多尺度融合下的平均交并比。
图4 以可视化形式对比了在入本文所提模块后所生成的类激活图。其中基线方法使用同一基干网络(Wu 等,2019),但只使用分类损失训练模型来获取类激活图(Zhou 等,2016)。图4(c)(d)表示只添加OCHM 和DARM 模块所生成的类激活图,图4(e)是综合使用OCHM 和DARM 模块后的结果。图中高亮显示的区域是分类网络激活的目标区域,从图4 中可以看到,使用单一模块可以提升类激活图的质量,但是还不够理想。本文方法综合利用两个模块,生成的类激活图可以覆盖更大的目标区域,产生更少的误激活。尤其是对于最后一行这种具有多重目标的实验图像,本文方法可以准确激活大部分目标区域。
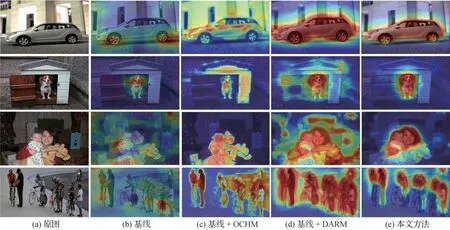
图4 CAM可视化对比Fig.4 Visual comparisons of CAM((a)original images;(b)baseline;(c)baseline+OCHM;(d)baseline+DARM;(e)ours)
表1 给出了本文方法、基线以及SEAM(selfsupervised equivariant attention mechanism)(Wang等,2020)方法在多种尺度下生成的类激活图和真实标签的平均交并比,最后一列表示采用多尺度融合下的类激活图精度。在进行多尺度融合时,先将同一图像按不同比例缩放后分别送入网络获取CAM,再将多个尺度的CAM 缩放至原图尺寸,最后将多个CAM 同一空间位置处的激活值进行累加得到融合后的CAM。分析表1 可以看出,本文方法在多个单一尺度上都超过了所对比方法,且在多尺度融合下达到了最优效果。

表1 多种尺度下类激活图生成精度比较Table 1 Accuracy comparison of CAM generated at multiple scales/%
表2 给出了本文方法与SEAM(Wang 等,2020)、Puzzle-CAM(Jo 和Yu,2021)、AdvCAM(Lee 等,2021a)和L2G(local to global)(Jiang等,2022)等类激活图生成方法的精度对比,可以看出,本文方法优于其他方法。
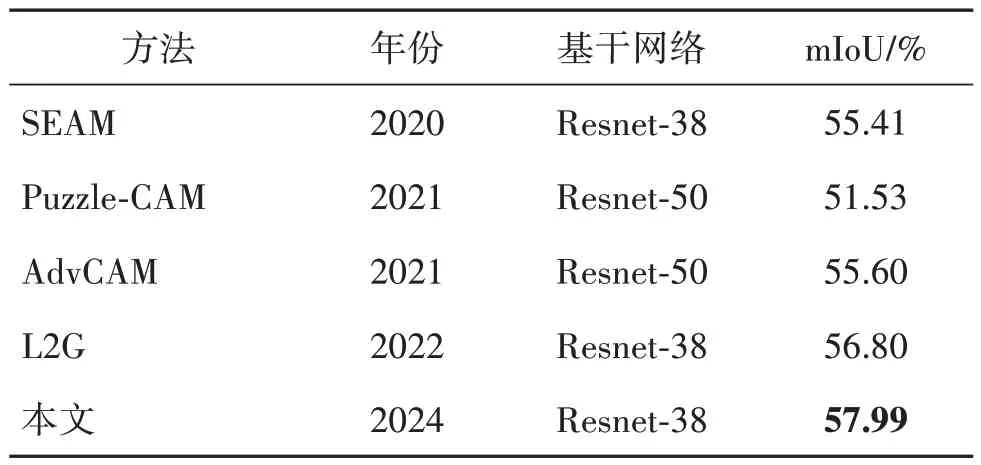
表2 各方法生成CAM精度对比Table 2 Accuracy comparisons of CAM generated by various methods
表3 给出了本文方法生成类激活图的消融实验结果。加入目标互补隐藏模块OCHM 后,与基线相比,交并比提高了3.94%。在加入双重注意力精调模块DARM 后,交并比又提高了6.27%。与基线方法相比,本文方法所生成的类激活图交并比可提高10.21%,验证了本文方法在生成完整类激活图方面的有效性。最终将本文方法生成的类激活图经过CRF处理后得到的伪标签精度达到了62.1%。
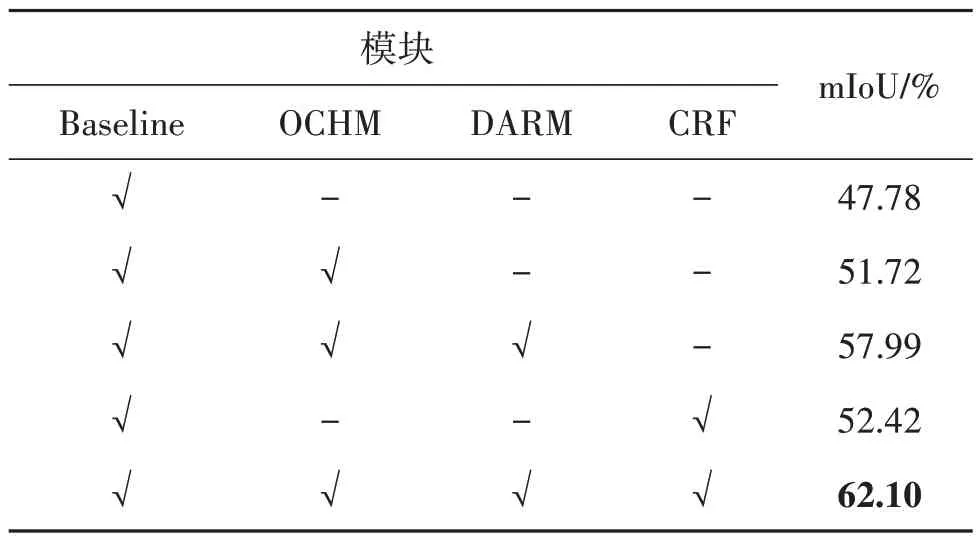
表3 CAM生成消融实验Table 3 Ablation experiment of CAM generation
此外,实验还探究了超像素块数对类激活图生成效果的影响,如图5 所示,横轴为超像素块数,纵轴为对应的平均交并比。实验结果表明,随着超像素块数的增加,平均交并比先呈现出增加的趋势,在块数为200 时达到峰值。之后,超像素块数的增加会导致平均交并比下降。因此,实验中默认超像素块数为200。
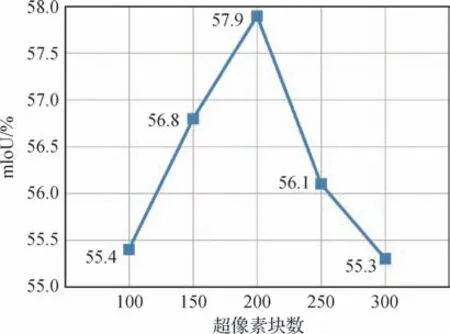
图5 不同超像素块数下的性能比较Fig.5 Performance comparison with different number of superpixel patches
2.3 弱监督语义分割实验
通过前文实验得到最佳类激活图后,利用其训练AffinityNet 生成转移矩阵,然后对类激活图进行随机游走便可获得初始伪标签。在所得伪标签的监督下,使用ResNet101 作为基干训练分割模型,以获得初步的分割结果。通过前述标签迭代精调模块LIRM 获取更加准确的伪标签。图6 对比了通过本文方法最终获取到的伪标签和真实标签,可以看出本文方法生成的伪标签非常接近真实标签,覆盖了大部分的目标区域。最后用经过LIRM 模块调整后的标签重新训练分割模型,获得最终的分割结果。

图6 伪标签与真实标签对比Fig.6 Comparison of pseduo labels and ground truth((a)original images;(b)ground truth;(c)pseudo labels)
分割实验首先在PASCAL VOC 2012 数据集上进行,对比算法包括SSDD(self-supervised difference detection)(Shimoda和Yanai,2019)、SEAM(Wang等,2020)、SBNet(semantic boundary network)(Liu 等,2021)、NSROM(non-salient region object mining)(Yao等,2021)、I2CRC(inter-and intra-class relation constraints)(Chen 等,2022b)和SIPE(self-supervised image-specific prototype exploration)(Chen 等,2022a)等方法。其中SSDD、SEAM、SBNet和SIPE 未使用显著图,而NSROM、I2CRC不同程度地使用了显著图提供的信息。
图7 展示了所提出方法和上述对比方法在一些验证集图像上的预测结果。在图7 第1 行这种背景较清晰的情况下,NSROM 的预测中瓶子和人的连接处出现了一定的误分类,SSDD 和SIPE 未能正确预测瓶子的轮廓,剩余模型都取得了较好的分割效果。在图7 第2 行出现了两类目标交错的情况,各模型只给出了大致准确的预测,在细节上有很大欠缺。在图中第3 行中,SSDD、SEAM 以及SBNet 的预测有较大偏差,原因可能是背景中的云与飞机机身颜色较为接近,导致其无法正确区分前背景。而NSROM、I2CRC 以及本文方法因为有显著图的修正,对前景和背景均能做出正确的划分。第4 行和第5 行选取了一些轮廓较复杂的目标,可以看出第4 行中SSDD、SEAM、SBNet、I2CRC 和SIPE 都未能完整预测目标,存在细节部位,如狗的尾巴缺失的情况。而第5 行中SSDD 将一些背景误分类为目标物体。图中第6 行选取了一个较复杂的场景,出现了多种目标类,且各目标类以及背景有颜色相近的部分。SBNet、NSROM、I2CRC 以及SIPE 对图中桌子的大片区域无法正确预测,而本文方法实现了最完整的预测。综合来看,本文模型在多种复杂情况下都取得了较好的分割效果,优于所对比方法。

图7 各方法在PASCAL VOC 2012验证集的分割结果对比Fig.7 Comparison of segmentation results of different methods on PASCAL VOC 2012 val set((a)original images;(b)ground truth;(c)SSDD;(d)SEAM;(e)SBNet;(f)NSROM;(g)I2CRC;(h)SIPE;(i)ours)
表4 详细列出了各分割模型在PASCAL VOC 2012 验证集上得到的21 个类别的mIoU 值对比,本文方法在13 个类别上优于所比较的方法。在背景类上取得了92% 的mIoU 值,相比其他方法取得了最高性能,表明本文方法有效利用显著图参与训练,取得了性能提升。另外,本文方法在bus、car、cat、cow和dog等类别取得了较好的效果。
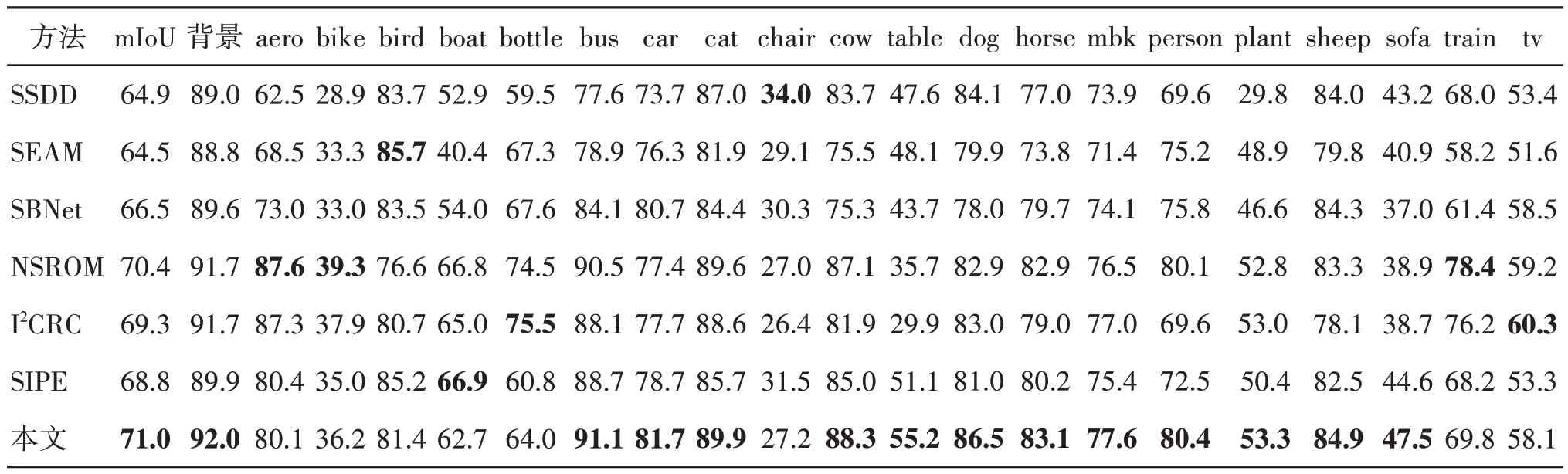
表4 各方法在PASCAL VOC 2012验证集上不同类别的mIoU值对比Table 4 The mIoU comparison of different classes and different methods on PASCAL VOC 2012 val set/%
表5 给出了各方法在验证集和测试集上的性能对比。与其他方法相比,本文所提出的弱监督语义分割框架在验证集和测试集上的性能均有明显提升,比排名第2 的算法在验证集上高出0.6%,在测试集上高出0.9%。

表5 各方法在 PASCAL VOC 2012验证集和测试集上的mIoU值对比Table 5 The mIoU comparison of different methods on PASCAL VOC 2012 val and test datasets/%
表6 列出了本文分割方法所用模块的消融实验结果,实验在验证集上进行,其中基线为直接用类激活图生成初始伪标签训练分割网络所得(Chen 等,2018)。本文框架与基线相比有6.9%的性能提升。其中本文所提标签迭代精调模块实现了2.2%的性能提升,证明了该模块的有效性。

表6 语义分割消融实验Table 6 Ablation experiment of semantic segmentation
为了进一步验证本文算法对于多目标和小尺寸目标的分割性能,在COCO 2014 数据集上进行了相关实验。与PASCAL VOC 2012 相比,该数据集类别更为丰富,且包含大量具有多个目标类别的图像,对算法性能提出了更高要求。表7 给出了本文方法和DSRG(deep seeded region growing)、SEAM、EPS(explicit pseudo-pixel supervision)(Lee 等,2021b)、SIPE 等算法在COCO 2014 验证集上的性能对比,可以看出,本文方法获得了0.5%的性能提升,进一步验证了本文方法的有效性。

表7 COCO 2014验证集上分割结果对比实验Table 7 Comparison experiments of segmentation results in COCO 2014 val dataset
3 结论
本文提出了一种显著性引导的目标互补隐藏弱监督语义分割方法,通过将显著图所定位的显著区域进行随机隐藏获得目标互补图像对,再将其送入网络分别获得类激活图,通过融合互补图像的类激活图可以获得更完整的激活区域,再用其作为监督引导网络扩展激活区域。此外,本文还加入了双重注意力修正模块来获取全局上下文信息以修正获得的类激活图。在伪标签的生成环节,提出了标签迭代精调策略,通过结合分割网络预测、类激活图以及显著图生成更高质量的伪标签。在Pascal VOC 2012 和COCO 2014 数据集上的大量实验证明了本文所提弱监督语义分割方法的优越性。
基于图像级标签的弱监督语义分割仍然是一个具有挑战性的问题,本文方法在一些容易和背景混淆的物体类别上的分割性能仍有待提高,今后将进一步研究提升伪标签在这类物体上的准确度,从而进一步提高分割性能。
