局部特征增强的转置自注意力图像超分辨率重建
2024-04-22孙阳丁建伟张琪邓琪瑶
孙阳,丁建伟,张琪,邓琪瑶
中国人民公安大学信息网络安全学院,北京 100038
0 引言
单图像超分辨率(single image super-resolution,SISR)技术旨在将低分辨率(low resolution,LR)图像重建为高分辨率(high resolution,HR)图像。相较于LR 图像来说,HR 图像具有更丰富的细节信息和更友好的视觉感知,图像质量和可用性都更高。SISR技术是图像复原领域的一个热点研究问题,通常应用于刑侦、遥感和医学诊断等领域。SISR 技术具有非常典型的不适定(ill-posed)特性,即一个LR 输入对应许多可能的HR 输出,映射空间太大,映射对象不唯一,具有非常大的挑战性。
常见的超分辨率技术主要分为以下3 类:基于插值的方法、基于重建的方法和基于学习的方法。基于插值的方法主要依赖于图像先验信息和统计模型等进行插值计算,具有简单易用和计算复杂度低的优点。然而插值得到的图像容易出现锯齿状的伪影,并且性能严重依赖于原始图像的质量。基于重建的方法通过融合同一场景下的多个低分辨率图像中的高频信息生成高分辨率图像。但是在实际场景中,难以收集足够多的低分辨率图像。此外,基于重建的方法对先验的依赖较强,生成的结果容易出现伪影或失真问题。基于学习的方法对大量HR和LR图像对的学习来构建高低分辨率字典,并通过深度学习网络进行图像重建。在这个过程中,算法从大量数据对中学习图像的特征和结构信息,从而实现更加准确的重建效果。相较于基于插值和基于重建的方法,基于学习的方法能够获得更多的高频信息,从而得到更清晰的纹理细节和更丰富的信息特征,在准确性和计算效率等方面具有很大的优势,因此受到越来越多的关注。
Dong 等人(2014)提出的SRCNN(convolutional neural network for image super-resolution)采用经典的端到端结构,通过简单的3 层卷积结构在保证图像质量的同时又可以实现高分辨率图像的快速重建,开创了基于学习的超分辨率技术的先河。Shi 等人(2016)提出的ESPCN(efficient sub-pixel convolutional neural network)方法提高了基于学习的方法的计算效率,获得了良好的重建效果。Kim 等人(2016)采用深度残差网络的思想,通过构建具有20 层的深度网络VDSR(accurate image superresolution using very deep convolutional network),获得了比SRCNN 更好的重建图像质量,证明加深网络深度有助于学习图像特征。Zhang 等人(2017)提出了深度卷积神经网络DnCNN(denoising convolutional neural network),通过学习图像残差进行去噪。Lim 等人(2017)通过舍弃SRResNet(super-resolution residual network)(Ledig 等,2017)中残差块的批归一化(batch normalization,BN)层并优化网络结构,使图像重建效果得到大幅提升。Zhang等人(2018a)首次将通道注意力(channel attention,CA)机制引入到SR任务中,提出的嵌套残差结构(residual in residual,RIR)成为目前SR 任务中残差块堆叠的标准范式,其所提出的RCAN(image super-resolution using very deep residual channel attention network)网络通过通道注意力机制区分不同通道特征对重建图像的贡献程度,自适应调整通道权重,图像重建质量获得极大程度的提升。
基于Transformer 的方法在自注意力(selfattention,SA)的建模方面具有出色的能力,因此在处理输入数据时可以更好地捕捉数据之间的关系,在自然语言处理领域大放异彩。Dosovitskiy 等人(2021)提出的ViT(vision Transformer)首次将广泛应用于自然语言处理(natural language processing,NLP)任务中的Transformer(Vaswani 等,2017)迁移至视觉任务中。其首先将输入图像经过一个嵌入层转换为一组一维向量,并通过多个自注意力层学习图像中的信息。SwinIR(image restoration using Swin Transformer)(Liang等,2021)将Swin Transformer(Liu等,2021)引入到SR任务中,将重建图像质量提高到了新的高度。通过将输入图像分割为很多小块,然后将每个小块作为Swin Transformer 的输入来处理图像,通过跨窗口交流保持对像素之间长距离关系的建模,显著减少了模型的计算成本,同时这也是Transformer 首次应用于SR 任务中。刘花成等人(2022)提出了一种用于模糊图像超分辨重建的Transformer 融合网络(Transformer fusion network,TFN),采用了双分支策略,在对模糊图像进行重建的同时能有效去除部分模糊特性。邱德粉等人(2023)根据红外图像的特性并针对深度网络中存在的特征冗余问题和计算效率问题,在超分辨率模块使用通道拆分策略,提出了一种使用高分辨率可见光图像引导红外图像进行超分辨率的神经网络模型。王美华等人(2022)使用Transformer模型计算图像深层语义信息,提出了TDATDN 单幅图像去雨算法。UFormer(U-shaped Transformer for image restoration)(Wang 等,2022)应用8 × 8 的局部窗口并引入U-Net(Ronneberge 等,2015)架构捕捉全局信息。ViT 将自注意力引入到视觉任务中,并在高级任务中表现优异。但在应用到图像超分辨率这类低级计算机视觉中,考虑到需要逐像素进行操作,其复杂性与输入特征图的尺寸呈平方关系,尤其是对于像素更多、分辨率更高的图像而言,需要的计算成本极高,这限制了Transformer 在低级计算机视觉任务中的使用。Mei 等人(2021)提出的NLSA(non-local sparse attention)通过将图像划分为不重叠的块,独立计算注意力,但这样会引入伪影并降低恢复图像的质量。SwinIR虽然也通过划分窗口进行自注意力的计算,但是其通过移位机制与其他窗口建立联系。然而SwinIR的计算量会随着窗口大小的增加而急速增长,同时局部窗口会限制上下文的聚合范围,不利于各像素之间长距离依赖关系的建模。
针对目前Transformer 在SR 任务中存在的一系列问题,本文提出一种全新的基于转置自注意力的超分辨率神经网络(super-resolution network based on transposed self-attention,SRTSA),主要的贡献点包括:1)提出了一个全局和局部信息提取模块(global and local information extraction block,GLEIB),该模块通过计算交叉协方差矩阵构建各像素点之间的长距离依赖关系对全局信息进行建模,同时引入通道注意力结构对局部信息进行建模。通过不同层级提取图像信息,提高模型的学习能力。2)在GLEIB 中构建一个全新的双门控深度卷积前馈网络(double gated-dconv feed-forward network,DGDFN),控制信息在模型中的流动,提高模型对特征的建模能力及其鲁棒性。3)提出的SRTSA 网络通过对图像的全局信息和局部信息进行建模,使用门控网络控制信息流动以进一步改善网络的学习能力。在5 个基准数据集上的测试结果验证了本文方法的先进性和有效性,在SR任务中展现出极大的优势。
1 本文方法
1.1 网络结构
本文提出的SRTSA 网络结构如图1 所示,主要由浅层特征提取模块、深层特征提取、上采样模块、重建模块4 部分组成。定义输入图像为ILR∈RH×W×C,输出图像ISR∈RH×W×C,H、W、C分别为图像的高度、宽度、通道数。

图1 SRTSA网络整体结构Fig.1 Overall architecture of the SRTSA network
首先,使用一个3 × 3 卷积从输入图像ILR中提取浅层特征F0,具体为
式中,HSF(·)表示卷积核大小为3 × 3 的卷积层,其可以将图像空间映射到更高的维度上。
然后,将F0送入深层特征提取模块中,可得
式中,HDF(·)表示深层特征提取模块,由M个全局和局部信息提取组(global and local information extraction groups,GLEIG)和1 个卷积层堆叠而成,GLEIG由N个GLEIB和1个卷积层构成,M和N的详细参数见2.1节。
深层特征FDF主要负责图像的高频部分的恢复,浅层特征F0负责图像低频部分的重建,因此需要将F0与FDF通过跳跃连接聚合再送到上采样模块中,得到
式中,HUP(·)表示由Shi 等人(2016)提出的ESPCN 一文中的亚像素卷积。它通过像素平移按给定上采样系数的比例采样。
经过上采样模块后将得到相应尺寸的特征图,最后,再将上采样特征FUP送入重建模块中,得到
式中,HREC(·)表示卷积核大小为3 × 3 的卷积层,用于将特征图转换为RGB 空间的SR 图像。HSRTSA(·)表示整个SRTSA模型映射。
1.2 全局和局部信息提取模块
全局和局部信息提取模块(GLEIB)结构如图2所示,该模块主要由3部分构成:
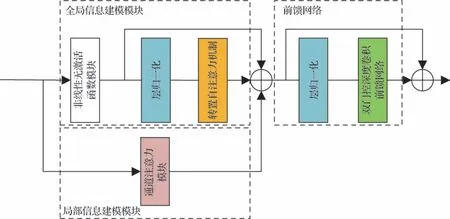
图2 全局和局部信息提取模块结构Fig.2 Architecture of the global and local information extraction block(GLEIB)
1)全局信息建模模块。主要通过转置自注意力机制计算交叉协方差矩阵进行图像全局关系建模。考虑到如果只在通道维度建立长距离关系相关的话会损失一些有用的空间纹理和结构信息,这些信息对于重建高质量图像十分重要。因此在采用转置自注意力机制前使用一种轻量高效的特征提取块进行简单关系建模保存部分空间结构信息。
2)局部信息建模模块。自然图像通常包含全局和局部信息结构,在对全局信息进行建模的同时也需要注意到图像部分特性具有局部性,因此使用通道注意力块补充局部信息,增强模型的学习能力。
3)双门控深度卷积前馈网络。DGDFN 通过在两个并行路径中采用门控机制抑制信息量较少的特征,并将筛选后的信息进行融合,进一步增强了模型对输入特征的建模能力,提高模型的性能。
1.2.1 全局信息建模模块
Transformer 中的计算资源主要消耗于自身的自注意力层中。对于一幅H×W像素的图像来说,其需要计算任意两个像素之间的相似度,计算复杂度为O(W2H2),将其应用于SR 任务中显然是十分困难的。SwinIR 采用的Swin Transformer 虽然通过划分窗口减轻了计算成本,但是划分窗口限制了聚合上下文的范围,不能有效连续提取特征。为了缓解这个问题,采用Zamir 等人(2022)提出的转置自注意力机制隐式构建全局注意力图。
转置自注意力机制的结构如图3 所示,输入由NAFBlock 输出的张量X∈RH×W×C经过一个层归一化(layer normalization,LN)之后生成张量Y∈RH×W×C。接着将Y输入到卷积核大小为1 × 1的卷积中聚合跨通道信息,然后使用3 × 3大小的深度卷积生成Q,K,V,具体为
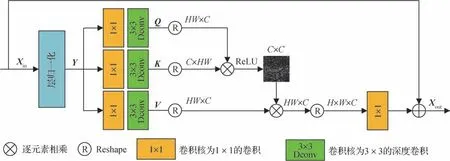
图3 转置自注意力机制结构图Fig.3 Architecture of transposed self-attention
式中,Wp(·)表示卷积核大小为1 × 1 的卷积,Wd(·)表示3 × 3的深度卷积。
接着通过Reshape 操作重塑Q和K,使其生成大小为RC×C的转置注意力图,而不是大小为RHW×HW的常规注意力图。整个过程可以表示为
式中,WP(·)表示1 × 1大小的卷积,fAttention为转置自注意力机制。
Li 等人(2023)提出经过softmax 归一化生成的自注意力会影响特征聚合。根据ReLU(rectified linear unit)激活函数自身的特点,可以在保留对图像重建呈积极效果的特征的同时去除负面特征,这样极大地提升了网络模型重建图像的性能。因此本文搭建的转置自注意力机制可以表示为
转置自注意力机制通过在通道维度对全局注意力图进行隐式建模很好地解决了计算复杂度与特征图空间维度呈二次方的关系,但是考虑到如果只在通道维度建立长距离依赖关系的话会损失一些有用的空间纹理和结构信息,这些信息对于重建高质量图像十分重要。因此在使用转置自注意力机制前需要对特征进行简单关系建模保存部分空间结构信息。
Chen 等人(2022)通过揭示GELU(Gaussian error linear unit)、GLU(gated linear unit)和通道注意力之间的联系,通过移除或替换非线性激活函数(例如sigmoid,ReLU,GELU),提出了一个适用于图像复原领域的简单基线模型非线性无激活函数模块(nonlinear activation free block,NAFBlock)。该模型通过将Transformer 内较为成熟的模块和机制应用于卷积神经网络中,提升了卷积神经网络的学习能力。NAFBlock 的网络结构如图4 所示,其主要由两个部分组成:移动卷积(mobile convolution,MBConv)模块和具有两个全连接层的前馈网络(feedforward network,FFN)。在MBConv 和FFN 之前都加入了层归一化(layer norm,LN)用于标准化输入数据,提高模型的泛化性能。同时对两个模块使用了残差连接,加速网络训练和收敛。整个过程可以表示为

图4 非线性无激活函数模块结构图Fig.4 Architecture of nonlinear activation free block
NAFBlock 通过引入SimpleGate 单元来替代非线性激活函数,给定输入X∈RH×W×C,将特征沿通道维度分割成两个特征X1和X2,X1、X2∈RH×W×C/2,然后使用线性门控来计算输出,具体计算为
式中,⊙表示逐元素相乘。由于简化的SimpleGate引入了非线性,所以常用的激活函数就不需要再加入到网络中。
需要注意的是,NAFBlock 分别在MBConv 和FFN 中采用正则化(dropout)技术随机丢弃部分神经元以达到减少模型过拟合、增强模型泛化性能的作用。但是GLEIB 将经过NAFBlock 进行简单关系建模后的特征送入转置自注意力机制中进行全局信息建模,为防止全局信息建模时特征信息不全,本文不使用NAFBlock 中的dropout 层以使得转置自注意力机制对所有特征进行全局关系建模,转而将舍弃部分内容增强模型泛化性能的任务交给转置自注意力机制中的ReLU激活函数。
1.2.2 局部信息建模模块
自然图像包含全局信息和局部信息,通常使用自注意力机制对图像的全局依赖关系进行建模,但是只使用自注意力机制对图像信息进行建模会丢失图像特有的局部相关性。图像局部信息只涵盖了几个像素,典型局部特征表现为边缘、局部色彩等,因此使用通道注意力块(channel attention block,CAB)对图像局部信息进行补充。
CAB 的结构如图5 所示,由两个标准的卷积层组成,两者之间使用GELU 激活函数,并且还包含一个通道注意力。CAB 通过压缩和扩展通道特征,以及通过通道注意力模块的自适应调整,实现了对输入特征的处理和提取。这个过程有助于提取重要的特征信息,并为后续模型提供更有代表性的特征表示。整个过程可以表示为

图5 通道注意力块结构图Fig.5 Architecture of channel attention block
式中,σ(·)表示GELU 激活函数,W(·)表示3 × 3 大小的卷积,CA(·)表示通道注意力机制。
1.2.3 双门控深度卷积前馈网络
在传统Transformer 中,FFN 通常包含两个线性变换层和一个非线性激活函数。第1 个线性变换层用于扩展特征通道,第2 个用于将通道减回原始输入维度。为了更好地捕捉输入图像的特征信息,本文在Restormer(Zamir 等,2022)的基础上提出一个全新的双门控深度卷积前馈网络(DGDFN),其结构如图6所示。

图6 双门控深度卷积前馈网络结构图Fig.6 Architecture of double gated-dconv feed-forward network
DGDFN 引入深度卷积对空间相邻像素的信息进行编码,丰富局部信息。在每条路径上都通过GELU 激活函数以实现双门控机制。在两个并行路径中将通过门控机制处理后的特征进行逐元素相乘操作,这样可以过滤掉两个路径中相应位置上特征向量中的较小值,从而减少信息量较少的特征的影响。之后逐元素求和操作将对应位置的特征值相加,以合并两个路径中有用的信息,同时由于双门控机制具有更强的非线性建模能力,因此可以学习更复杂的模式,提高模型的泛化性和建模能力。整个过程可以表示为
式中,σ(·)表示GELU激活函数,即门控机制,Wp(·)表示卷积核大小为1 × 1 的卷积,Wd(·)表示3 × 3 大小的深度卷积,⊙表示逐元素相乘。
1.3 损失函数
虽然L1损失函数、L2损失函数、感知损失以及对抗损失等多种损失函数的组合可以提高重建图像的视觉效果,但为了验证SRTSA 网络的有效性,本文采用了与上述相关工作相同的损失函数——L1损失函数进行优化。相较于其他损失函数,L1损失函数提供了稳定的梯度,并有助于模型快速收敛,使用L1损失函数进行优化是验证SR网络性能的可靠方式。给定包含N个LR-HR 图像对的训练集,通过最小化L1损失优化SRTSA的模型参数
式中,θ表示SRTSA网络模型的参数。
2 实验结果及分析
2.1 数据集及训练细节
本文使用DIV2K 数据集(Agustsson 和Timofte,2017)的800幅训练图像对SRTSA 网络进行训练,采用双三次插值法(Bicubic)得到×2、×3、×4 共3 个比例因子的低分辨率图像。为了增加训练图像的数据多样性,将这800 幅训练图像水平翻转或者随机旋转90°,180°,270°。在每次迭代中将16个48 × 48像素的低分辨率图像送入网络(batch size=16),使用Adam 优化器进行训练,其中,β1=0.9,β2=0.999,ε=1×10-8,初始学习率lr=5×10-4,总共迭代500 000次,迭代到200 000次时学习率减半。
使用具有不同特性的5 个标准测试集验证网络的有效性:Set5(Bevilacqua 等,2012)、Set14(Zeyde等,2012)、BSD100(Berkeley segmentation dataset 100)(Martin 等,2002)、Urban100(Huang 等,2015)、Manga109(Matsui 等,2017),并在输出图像的YCbCr空间Y 通道上计算峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似度(structural similarity,SSIM)指标评价SR 结果。使用PyTorch 框架在两张NVIDIA GeForce RTX 3090 显卡上训练模型。在整个网络中,为保持与SwinIR 模型进行公平对比,设置GLEIG 数M=6,GLEIB 数为N=6,CAB 输出缩放权重α=0.05,转置自注意力特征通道设置为120,多头数设置为6。
2.2 实验结果分析
为了展示SRTSA 模型的先进性,本文与Bicubic算法、SRCNN、VDSR、EDSR(enhanced deep residual network for single image super-resolution)、RCAN、SAN(second-order attention network for single image super-resolution)(Dai 等,2019)、HAN(single image super-resolution via a holistic attention network)(Niu等,2020)、NLSA、SwinIR 等模型在×2、×3、×4 共3 个比例因子上对PSNR指标和SSIM指标进行对比。较高的PSNR 值表示重建效果更好,SSIM 越接近1 表示SR图像与HR图像在结构上更为相似。
Chu 等人(2022)指出在图像复原工作中由于计算资源限制,一般都将要修复的图像裁剪成小块(Patch)送入到模型中进行训练。而在推理过程,一般则直接将需要修复的图像送入到网络中进行复原。这种模式存在着训练与推理过程的不一致性,对利用全局信息的模型会产生负面影响。因此在测试过程中采用Chu等人(2022)提出的测试时间局部转换器(test-time local converter,TLC)维持训练与推理过程的一致性。
按照2.1 节的实验设置对模型进行完整训练,得到×2、×3、×4 共3 个不同比例因子的PSNR 和SSIM,分别展示在表1—表3 中。可以看到,在×4 倍SR 任务中,SRTSA 较SwinIR 在Set5、Set14、BSD100和Urban100 上,PSNR 分别提升0.07 dB、0.01 dB、0.03 dB 和0.08 dB,SSIM 也有较大提升。在×3 倍SR 任务中,SRTSA 较SwinIR 在Set5、BSD100、Urban100 和Manga109 上,PSNR 分别提升0.02 dB、0.04 dB、0.15 dB 和0.02 dB,SSIM 在5 个测试集上都获得最佳指标。在×2 倍SR 任务中,SRTSA 较SwinIR在Set5、Set14、BSD100、Urban100和Manga109上,PSNR 分别提升0.03 dB、0.21 dB、0.05 dB、0.29 dB 和0.10 dB,SSIM 在除Manga109 以外的4个测试集上,分别提升0.000 4、0.001 6、0.000 9 和0.002 7,足以说明SRTSA的优势十分明显。
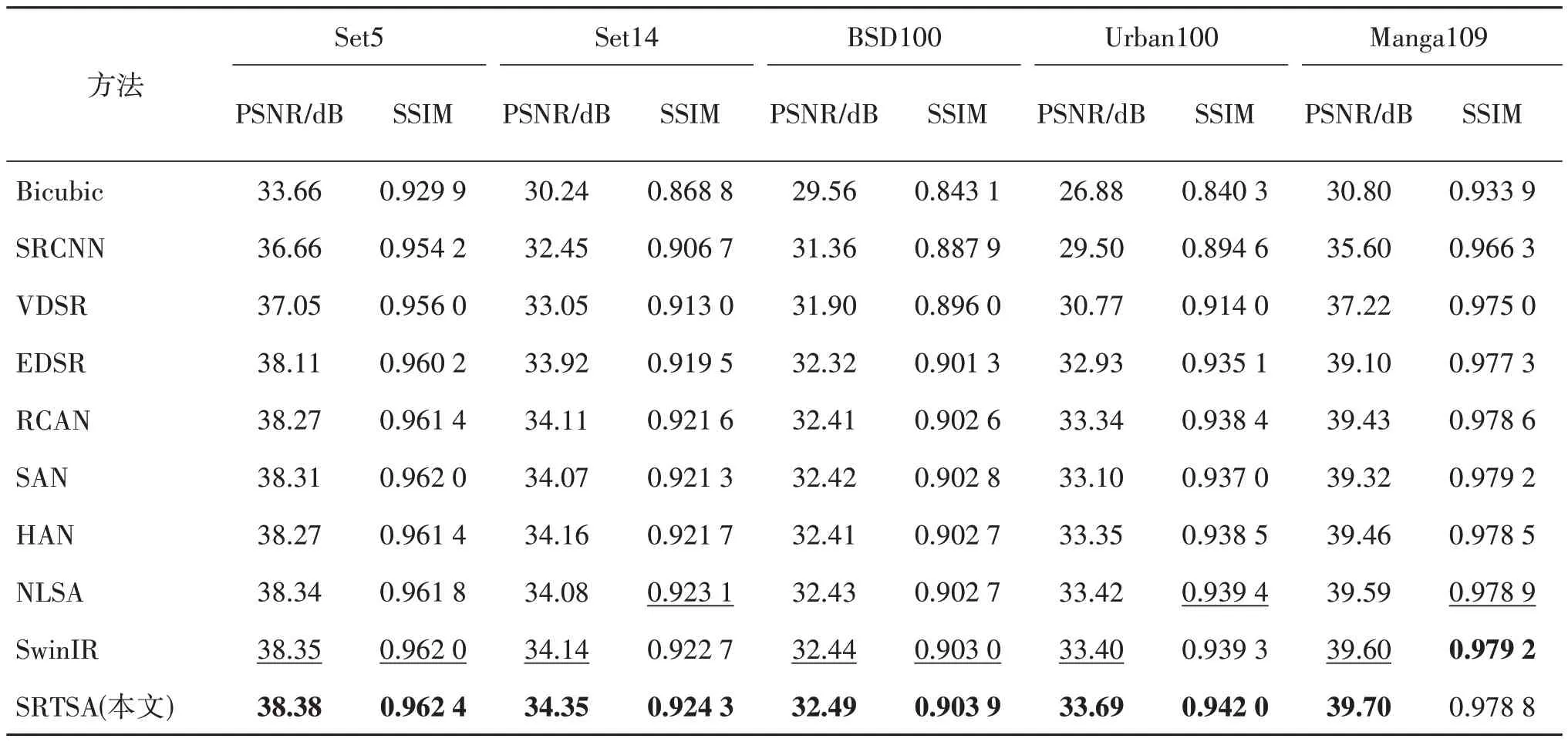
表1 各模型在不同数据集上的表现(×2)Table 1 Performance of each model on different datasets(scale×2)
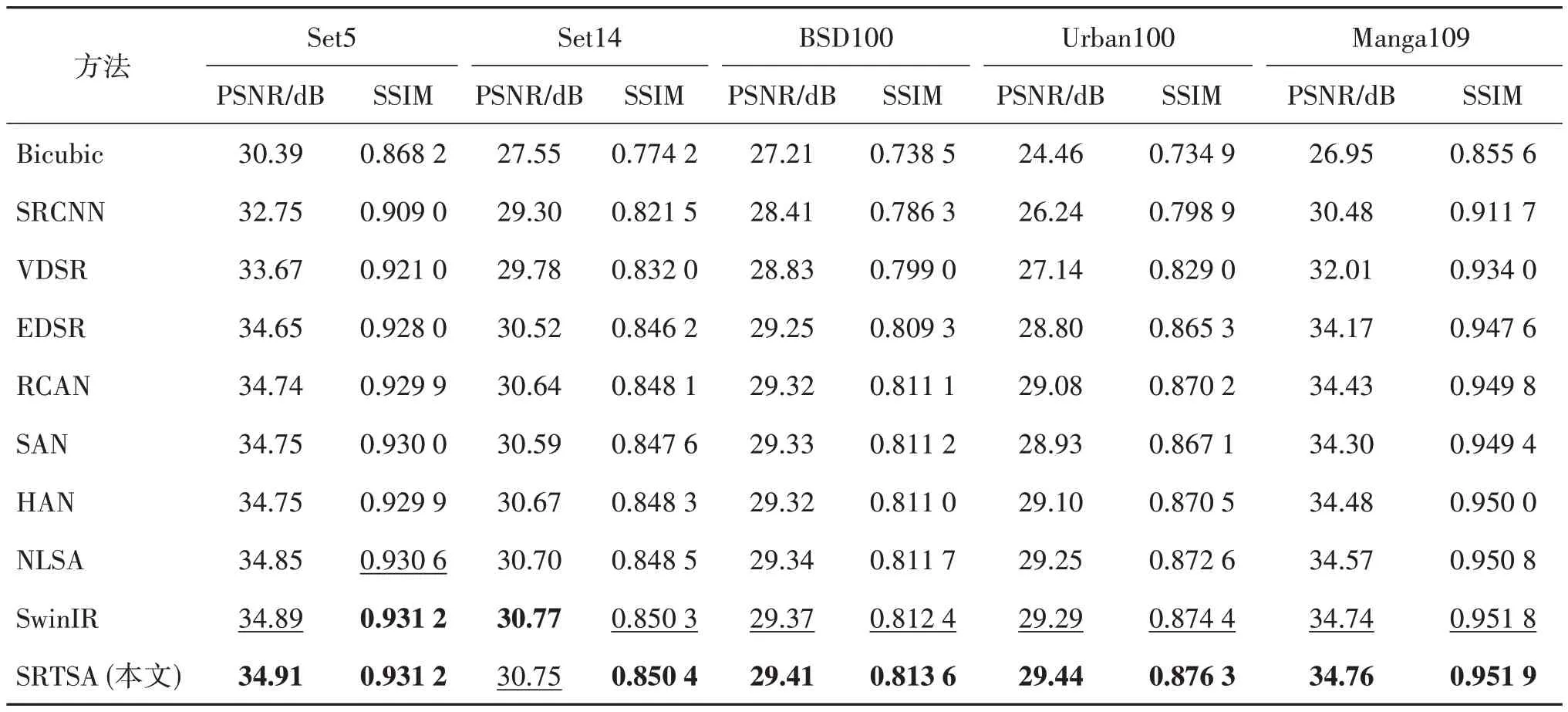
表2 各模型在不同数据集上的表现(×3)Table 2 Performance of each model on different datasets(scale×3)

表3 各模型在不同数据集上的表现(×4)Table 3 Performance of each model on different datasets(scale×4)
SRTSA 网络在BSD100 和Urban100 这两个包含丰富的结构和纹理信息且具有更高复杂度的测试集上的优势更为显著。说明SRTSA网络可以在复杂场景中保持高水平的细节保留和纹理重建能力,具有较强的结构感知能力和泛化性能,可以适应不同类型的图像数据并提供高质量的超分辨率重建图像。
图7 展示了Urban100 数据集044_img.png 图像通过不同算法模型重建得到的图像。可以看到,Bicubic 算法所重建图像十分模糊,VDSR、RDN(Zhang 等,2018b)等网络只能重建出图像较为模糊的轮廓且细节信息基本丢失,RCAN、SAN、SwinIR 可以重建出较为清晰的轮廓,但对于纹理结构的重建并不完善,SRTSA网络所重建的图像不但轮廓清晰,结构合理,并且对于细节纹理的恢复也最接近HR图像。

图7 Urban100数据集中044_img.png的测试结果(×4)Fig.7 Test results of 044_img.png in Urban100 dataset(scale×4)
图8 展示了Urban100 数据集092_img.png 图像经过不同模型重建后的效果对比。Bicubic 插值法得到的结果呈现出非常模糊的特征,几乎无法重建出图像的细节。基于深度学习的其他方法在重建过程中虽然保留了主要的轮廓信息,但在纹理结构和细节方面却存在明显的扭曲和伪影。而使用SRTSA网络进行重建的图像则具有纹理清晰、边缘锐利以及细节丰富等优点,通过恢复更多的信息获得更好的结果。

图8 Urban100数据集中092_img.png的测试结果(×4)Fig.8 Test results of 092_img.png in Urban100 dataset(scale×4)
图8 中,不同方法重建结果差异性较大是因为SR 任务是一个典型的不适定问题,LR 图像无法唯一确定对应的HR 图像。VDSR、EDSR 等SR 模型受感受野较小、模型学习能力较弱等限制,无法充分考虑图像的全局结构恢复细节信息,在生成SR图像时都出现了将竖状条纹重建为斜状条纹、交叉条纹或者出现伪影等错误范式。相比之下,SRTSA 通过对全局信息进行建模,获得更多纹理结构信息,极大地缓解了不适定问题,重建得到的SR 图像也与HR 图像更为相似。
2.3 局部归因分析
局部归因图(local attribution maps,LAM)是由Gu和Dong(2021)针对SR 领域具有不可解释性而提出的归因分析方法,通过局部归因图的形式将对输出结果产生强烈影响的像素重点标注出来。通过这种方式,可以很直观地看到SR网络的有效性。为了直观地展示SRTSA 的优势,本文将SRTSA 和SwinIR同时使用LAM工具进行比较,比较结果如图9所示。在LAM 中,作者提出扩散指数(diffusion index,DI)衡量LAM的结果,表示形式为
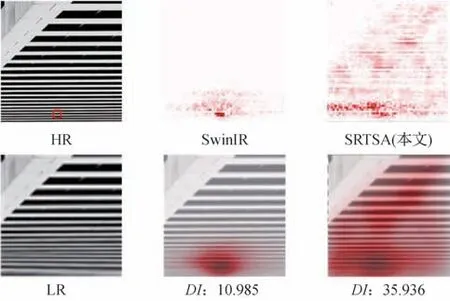
图9 不同模型的LAM结果Fig.9 LAM results for different models
式中,GI表示基尼系数(Gini index,GI)。GI是国际上通用衡量一个国家或者地区收入差距的指标。在LAM 中,GI是衡量LAM 差距的指标,它可以反映LAM 所涉及的像素范围。简单理解就是对于重建图像的某一部分来说,如果重建该部分只涉及少数像素点,则GI系数相对较高。因此DI和GI呈反比例关系,DI越大说明重建某一部分网络考虑到更多的像素点。
从图9 可以直观地看到,SRTSA 生成SR 图像时考虑到的像素范围远大于SwinIR 所考虑的像素范围。实验结果和客观指标评价、主观视觉感知高度一致,从可解释性的角度证明了SRTSA的优越性。
2.4 消融实验
为了验证SRTSA 网络各组成部分的有效性,本文对不同结构进行消融实验,并对实验结果进行对比分析。1)实验中把只有转置自注意力机制和门控前馈网络(GDFN)的模型作为Baseline;2)在Baseline上引入NAFBlock以验证其对特征进行的简单关系建模是否可以补充转置自注意力机制损失的部分空间纹理和结构信息;3)在Baseline 上引入CAB 验证补充局部信息是否可以增强图像重建效果;4)同时引入NAFBlock 和CAB 验证对特征进行简单关系建模是否与对特征进行局部关系建模产生冲突;5)由于DGDFN 相对独立,在实验4)的基础上引入DGDFN 即可验证其是否可以提高模型的建模能力。在消融实验中设置batch size=8,其余均按照2.1节的设置重新训练网络。
在Set5 测试集上的PSNR 如表4 所示。由表4中实验2)可知,在Baseline 模型的基础上引入NAFBlock 模块之后PSNR/SSIM 获得了0.01 dB/0.000 3的提升,说明对特征进行简单关系建模可以保存部分空间结构信息。实验3)结果表明,引入CAB 模块后,PSNR 和SSIM 分别提升了0.02 dB 和0.000 3,说明CAB 通过捕捉图像特有的局部相关性从而增强了网络的建模能力。在实验4)中,同时引入以上两个模块后,PSNR 和SSIM 分别提升了0.05 dB 和0.000 7。由实验5)可知,本文DGDFN 的PSNR 和SSIM 分别提升了0.03 dB 和0.000 9,说明DGDFN可以提高模型的泛化性能和建模能力,同样也说明在Transformer 模型中,自注意力机制和前馈网络均发挥着不可或缺的作用。它们共同构成了模型的核心组件,并相互协作以实现高效的特征提取和建模。
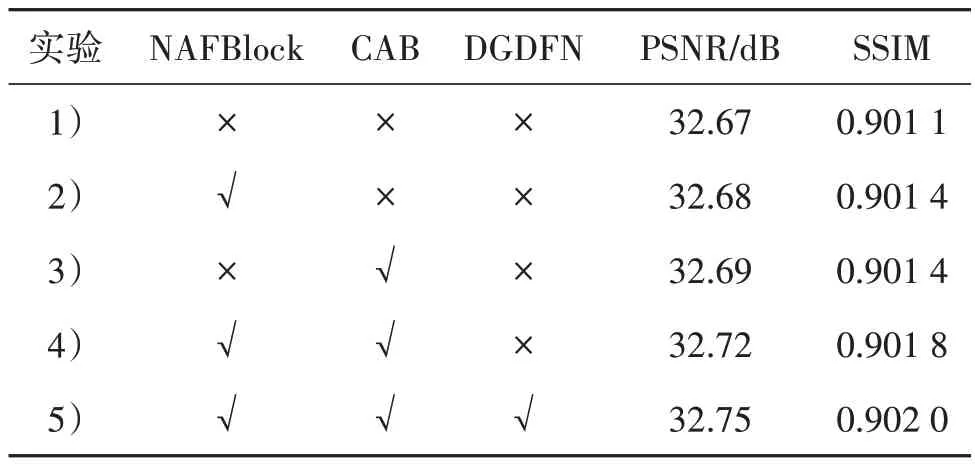
表4 在 Set5(×4)测试上的消融实验Table 4 Ablation study on Set5(scale×4)
同时,为了更直观地展示各个模块在SRTSA 模型中所做出的贡献,采用LAM 工具分析模型的感受野,过程性结果如图10所示。
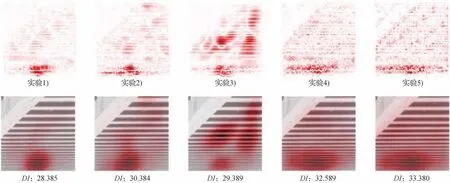
图10 过程性结果展示Fig.10 Process results display
3 结论
为了解决主流方法通过在窗口内使用自注意力机制,会限制特征聚合范围而导致图像重建效果不佳的问题,提出了基于转置自注意力机制的超分辨率网络(SRTSA)。通过转置自注意力机制和通道注意力模块分别对全局特征和局部特征进行建模,同时提出一个全新的双门控深度卷积前馈网络(DGDFN)提高模型的泛化性能。大量实验结果表明,本文方法在客观指标、主观视觉和模型可解释性方面均优于目前主流的单图像超分辨率算法。然而,本文算法也存在较多不足:1)用于局部信息增强的通道注意力块在大通道数时会使用较大参数量,使得模型推理速度变慢,后期将构建一个全新的轻量级局部信息增强模块对局部特征信息进行补充。2)尽管本文方法通过引入转置自注意力机制隐式构建全局上下文关系节省了较多的参数,但是全局信息建模网络结构较为冗余,使得网络复杂度更高。在未来的工作中,将设计一个更为简洁的自注意力机制用于图像全局信息的提取。
