基于照度与场景纹理注意力图的低光图像增强
2024-04-22赵明华汶怡春都双丽胡静石程李鹏
赵明华,汶怡春,都双丽,胡静,石程,李鹏
西安理工大学计算机科学与工程学院,西安 710048
0 引言
在低光照条件下获取的图像往往具有亮度低、对比度低、细节模糊以及高噪声等视觉降质问题,常见的低照度图像类型如图1 所示(Li 等,2022a),这些问题不但会影响人眼的视觉观感,还会降低现有视觉智能感知设备的识别、检测、分析和理解能力。低光照图像增强旨在恢复拍摄场景的信息,以获得具有完整结构和细节,且清晰自然的图像,是高级计算机视觉任务进行预处理的基础,在多个新兴的计算机视觉领域引起了广泛的关注。

图1 常见的低照度图像类型Fig.1 Common types of low-light images((a)backlit;(b)uneven light;(c)indoor low-light;(d)extremely low-light;(e)colored light;(f)noise)
围绕“低光照影像增强”,涌现出大量行之有效的方法,包括传统模型驱动方法和基于深度学习的方法。传统模型驱动的增强算法可分为3 类:基于分布映射、基于Retinex 的模型优化和基于融合的低照度图像增强算法(马龙 等,2022)。
基于分布映射的方法一般在空域或频域利用线性或非线性函数来拉伸低照度图像的亮度和对比度(郭永坤 等,2022),如对数函数校正(Peli,1990),S曲线(Yuan和Sun,2012)以及常用的直方图均衡化(Abdullah-Al-Wadud 等,2007),从而使图像中亮度不同的像素尽可能分布均匀以达到增强图像的目的。但基于分布映射的方法未考虑像素的空间分布,增强后的图像常存在过度曝光和颜色失真等问题。
基于Retinex 理论的低照度图像增强方法利用人眼视觉特性以及色彩恒常性,认为人眼或图像采集设备所感知的物体亮度由物体本身的反射分量和环境光照这两个因素决定,大部分工作聚焦在分析反射分量和光照分量的视觉结构特征,并构建正则化约束上,很多加权变分约束模型被提出。Fu 等人(2016)提出了基于对数域的加权变分模型,用于同时估算光照和反射量。Xu 等人(2020a)发现利用指数级局部平均变分作为加权权重,在 Retinex分解时可生成原图的卡通—纹理图。江泽涛等人(2021)引入Attention机制和密集卷积块实现低照度图像的亮度和对比度提升。但上述方法均未考虑增强时伴随的噪声放大问题。都双丽等人(2023)结合局部相对变分和非局部自相似原理,提出了一种Retinex 分解和去噪模型,在增强图像亮度的同时有效去除图像噪声。
基于融合的增强算法通过融合曝光水平不同的多幅图像恢复场景信息。Ying等人(2017)提出了多尺度权重矩阵融合策略。Wang 等人(2020)利用YUV 颜色空间中的图像细节信息辅助融合。赵明华等人(2022)通过深度抠图技术融合逆光区和原图像,实现图像增强的同时避免过曝光。由于传统模型驱动增强方法仅从对比度或动态范围等单一角度分析,实现亮度提升,常出现局部欠增强、过增强及色彩失真等问题,且处理噪声时具有高耗时问题。
深度学习技术在诸多领域表现出色,越来越多的基于深度学习的低照度图像增强算法被提出,性能提升显著。早期,大部分工作聚焦在图像亮度提升方面,通过设计不同的网络模型来提升增强效果,应用较为广泛的是类U-Net 结构。Chen 等人(2018)使用长短曝光在静态场景下采集并构建低光照图像增强数据集,提出了基于U-Net 的全卷积增强网络模型;Ren 等人(2019)利用内容流和边缘流弥补了现有增强算法在结构细节上的损失;Lyu 等人(2020)、Zhao 等人(2022)分别提出了轻量化、速度快并可部署到移动设备端上的类U-Net 结构和基于Retinex 分解的增强方法。Jiang 等人(2021)基于U-Net 提出了一种无监督增强模型(EnlightenGan)。拉普拉斯金字塔也是常用的结构(Lim 和Kim,2021)。此外,部分学者聚焦于设计多分支结构,如Xu 等人(2020b)将低光照图像分为低频和高频两个分支进行恢复和增强。
上述方法专注于图像亮度提升和色彩还原,忽略了增强时伴随着噪声放大的问题。尤其针对照度特别低的图像,噪声污染严重。为此,部分同时考虑噪声抑制和亮度提升的工作相继提出。Lore 等人(2017)通过堆叠稀疏自编码器降低噪声影响的同时提高图像对比度。Wang等人(2019b)根据照度和噪声的耦合关系利用两个子网络分别进行照度和噪声估计,使用循环渐进机制感知两者之间的内在关系,实现低光图像增强。Wang 等人(2019a)将深度学习技术与Retinex理论相结合实现增强和去噪。
由于真实采集的低照度图像亮度差异大、失真度不同以及噪声污染强度不同,且针对同一幅图像不同区域的亮度和噪声强度也存在显著差异,导致预训练的模型用于真实数据时会出现图像整体或局部欠增强和过增强问题。为此,部分学者引入注意力机制,借助预估计的图像照度和噪声强度来引导亮度提升和噪声抑制。Lyu 等人(2021)设计两个深度分支来估计照度与噪声图,用于引导曝光提升和去噪。Xu 等人(2022)利用信噪比图先验来动态决定引入非局部特征的比重,噪声越强的区域,增强时引入的非局部特征比重越高。
但是,上述方法在构建噪声注意力机制时需要显式地估计噪声的强度,即需要去噪模块。而噪声分布复杂、强度多变,传统模型驱动的去噪算法常会出现过度去噪和去噪不全问题,直接导致生成的噪声引导图可靠性低。如果构建有监督的深度去噪模型,需要“低光照下含噪声和低光照下不含噪声”图像对,该数据很难获取,多采用合成的数据,而训练的模型用于真实数据时深度域适应问题突出。
为此,本文提出了一种新的基于注意力机制的增强方法,不需要显式地估计噪声的强度。受Wang等人(2019c)提出的吸收—散射成像模型的启发,本文通过低照度图像的最小通道约束图预估计正常曝光图像的照度和纹理注意力图,该图含有丰富的场景纹理信息和图像照度信息。由于低照度图像的最小通道约束图具有噪声抑制和纹理凸显作用,对图像照度和噪声强度变化具有一定的鲁棒性,故本文提出了一种基于低照度图像的最小通道约束图的注意力机制构建方法。利用生成的照度和纹理预估计信息来引导特征提取和融合,实现亮度提升和噪声抑制。本文方法可以处理不同亮度的低照度图像,且对于极低照度图像也可以得到良好的增强效果。
1 本文低照度图像增强方法
本文提出的基于照度和场景纹理粗估计的低照度图像增强算法流程如图2 所示,其整体流程包括低照度图像的最小通道约束图计算、照度和场景纹理注意力图估计以及基于照度和场景纹理注意力图的图像增强3 个模块,下面对各部分进行详细介绍。

图2 算法流程图Fig.2 The flow chart of our method
1.1 低照度图像的最小通道约束图生成
Wang 等人(2019c)指出低照度图像的最小通道约束图具有噪声抑制和纹理突显作用。因此本文基于低照度图像的最小通道约束图来估计照度和场景纹理注意力图。正常光照条件下拍摄的影像,RGB三通道的光照强度趋近于相同,但是低光照条件下拍摄的影像RGB 三通道的光照强度常呈现明显差异,形成色彩偏差。为此,本文利用暗通道先验原理估计RGB 每个通道的光照强度,然后进行色彩均衡处理,使各通道的光照强度趋于相近,其处理的具体过程如下。
对于待增强的低照度图像Ilow,首先,估计其暗通道图Idark,在暗通道图中根据本文所选数据集的暗通道像素分布选取亮度值排在前10%的像素点,根据实验经验,该比例的提高会使图像整体亮度减弱,部分细节纹理会弱化,不利于为后续增强模块提供引导信息。令这些像素点构成集合Ω1,则每个颜色通道的光照强度Ac,c∈{r,g,b}的计算为
对于正常曝光图像Inormal,无需色彩校正过程,其最小通道约束图Snormal可表示为
图3 显示了相同场景下不同曝光度的图像未经色彩均衡化结果(1-Ilow)、色彩均衡化结果以及最终生成的最小通道约束图。前3 幅是不同曝光度的低照度图像,最后一幅是正常曝光图像。如图3(b)所示,未经色彩均衡化的图像整体泛白,有用的纹理信息非常少。经过色彩均衡化后的图像在对比度、亮度和细节纹理特征上的信息都更丰富,如图3(c)所示。此外,如图3(d)所示,经过均衡化后的最小通道约束图含有丰富的纹理信息,且有一定的噪声抑制作用。但是当图像照度很低时,其最小通道约束图仍有明显的噪声,如图3(d)第3行所示。为了获取可靠的场景纹理信息,本文利用低光照图像的最小通道约束图来估计正常照度图像的照度和纹理注意力图。

图3 相同场景不同曝光度的图像均衡化结果及最小通道约束示意图Fig.3 Color equalization results and the minimum channel constraints map for images with different exposure levels((a)images with different exposure levels;(b)un-equalized maps(1-IIow);(c)color equalization results(1-);(d)the minimum channel constraints maps)
1.2 照度和场景纹理注意力图估计
图像噪声是指图像在拍摄和传输过程中所受到的随机信号干扰问题,一般来说,图像亮度越高,图像噪声越小,反之噪声越大。对于照度特别低的图像,用2.1 节所述方法生成的最小通道约束图含有较明显的噪声,为了消除噪声对后续增强阶段的错误引导,本文构建了基于U-Net 网络的照度和场纹理注意力图计算分支,学习低照度图像的最小通道约束Slow图和正常曝光图像的最小通道约束图Snormal间的映射机制,使得经过照度和场景纹理粗估计模块生成的注意力图即含有丰富的场景纹理信息和与正常曝光图像相近的照度信息,用于后续增强模块的信息引导,使网络关注于真实场景信息而非噪声,并引导照度不均匀图像对不同区域的亮度调节程度,有效避免局部区域欠增强和过增强问题。该模块的具体网络架构图如图4所示,它由9个卷积块和最后顶部的1×1 卷积层组成,每个卷积块由2 个3×3的卷积层接着ReLU(rectified linear unit)激活函数和批归一化处理函数组成,在下采样阶段,每个卷积块与2×2 的最大池化层相连,在上采样阶段,本文利用2×2 的转置卷积提取特征图,并将其与下采样步骤中得到的特征图进行拼接融合。
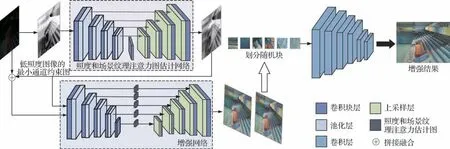
图4 算法网络架构图Fig.4 The architecture diagram of the algorithm
本文采用均方误差(mean square error,MSE)作为照度和场景纹理注意力图估计模块的损失函数,这是本文经过多次实验对比的经验选择。另外,相比于ℓ1损失函数,它能够更准确地反映实际预测误差的大小,在图像增强方面,不会过度惩罚图像的差距,可以更稳定、更快地捕获低照度图像和正常曝光图像最小通道约束图之间的共同信息,其表达式为
另外,本文通过照度和场景纹理注意力图估计模块得到的照度和场景纹理注意力估计图,具有亮度越高,其值反而越低的特点,如图5 所示,因此,为了使照度和场景纹理估计图更好地服务于增强网络,本文需要将得到的照度和场景纹理注意力估计图再次进行反转,为增强网络提供引导信息。

图5 照度估计示意图Fig.5 The figure of illuminance estimation((a)low-light image;(b)illuminance and scene texture attention estimation map;(c)inverted illuminance and scene texture attention estimation map)
1.3 图像增强网络
面向光照不均匀的低照度图像,如逆光图像、夜晚有额外光源的室外图像等,现有增强算法容易产生过曝光和细节模糊现象。为了解决此问题,本文提出一种全局与局部增强相结合的增强网络,在改善图像全局亮度的同时,可自适应地提高局部暗区的亮度,使视觉增强效果更自然。其先使用一个全局增强网络对图像整体亮度进行调整,然后通过对全局增强图像中划分的随机块进行局部亮度调整,在一定程度上避免了局部过增强和欠增强问题,下面对全局—局部相结合的增强网络进行介绍。
本文使用U-Net 基础网络架构作为全局增强部分的主体,它是由10个包含两个3×3卷积层的卷积块组成,每个卷积块后有LeakyReLU 激活函数层和一个批归一化层,网络卷积层后加入批归一化层会很大程度提升网络性能。在上采样阶段,本文利用双线性上采样层和一个卷积层代替了原来U-Net 网络中的标准反卷积层以减少图像棋盘格和伪影现象的发生。另外,本文将2.2 节得到的照度和场景纹理注意力估计图通过跳跃连接(skip connection)加入网络,帮助网络对图像亮度不同的区域施加不同的注意和处理。在这里,将原始低照度图像与照度和纹理注意力估计图进行拼接融合作为全局增强网络的输入,使注意力图进一步提供信息引导。
在局部增强模块,本文将全局增强后的图像剪裁划分成小图像块,然后经过多个3×3的小卷积核来提取图像特征,增加网络深度的同时有效捕捉图像的局部特征和边缘信息,实现局部细节增强同时进一步去除影响图像质量的噪声等因素。另外,为了使训练模型更稳定,在此之后还加入批归一化层。
多尺度结构相似性指数(multi-scale structural similarity,MS-SSIM)(Wang 等,2003)是一种基于有参考的多尺度图像质量评价标准,它关注了图像的亮度、对比度和结构等指标,更符合人眼对细节的感知,多尺度结构相似性的具体计算为
式中,l,c,s分别是亮度度量模块、对比度度量模块和结构相似性度量模块,j和M均为尺度参数,Ien和IGT分别代表增强后的预测图像和作为真值的正常曝光图像。基于此,本文在全局增强网络中使用了MS-SSIM 损失函数,从图像结构失真和人眼感知两个方面度量增强图像质量,从而使增强结果更符合人眼感知特性,具体计算为
MS-SSIM 虽然能保留图像的高频信息,在纹理结构上起到很好的调整作用,但它对均值的偏差不敏感容易导致图像亮度改变和色差问题。因此,为了较好地保持颜色和亮度,加强图像低频信息的准确性,本文还引入ℓ1损失函数,具体表达式为
为了更好地度量增强图像Ien和真值IGT之间的差异,在全局增强模块中,本文使用联合损失函数,具体为
式中,参数λ1和λ2之和为1。本文基于以往在低照度图像增强任务中研究者的经验并经过多次手动调参测试对比,设置λ1=0.85,λ2=0.15。
另外,在局部增强网络模块中,为了保证图像结构和细节,本文使用了感知损失函数,可以在一定程度上保持图像结构和内容的一致性,其具体表达式为
综上所述,本文将LIL、LGE和LLE分别加权,其中LGE和LLE的加权和作为增强子网络的联合损失函数,以实现亮度提升和图像细节恢复的目的,总损失函数可表示为
式中,ω1,ω2,ω3为超参数。
2 实验结果及分析
2.1 数据集与实验设置
本文在LOL 数据集(low light image datasets)上训练图像增强网络模型。LOL-v1(Wei 等,2018)和LOL-v2(Yang 等,2021)这两个数据集图像中都有非常显著的噪声。LOL-v1中有485对低光和对应的正常曝光的图像对用于训练,15 对用于测试。LOL-v2分为LOL-v2-real 和LOL-v2-synthetic 两个数据集,其中,LOL-v2-real 包含689 对低光和正常光的对应图像对和100 对测试数据集。LOL-v2-synthetic 数据集是通过分析RAW(raw image format)格式下的光照分布改变相机曝光时间和感光度(ISO)等获取的。为了提高本文网络的泛化能力,本文在LOL-v2-real数据集上进行训练,所有图像都被调整为PNG(portable network graphics)格式,尺寸为600×400 像素。对于测试数据集,除了LOL数据集,本文还选了一些之前常用的低光增强数据集(约178 幅)进行测试,包括DICM(digital images from commercial cameras)(Lee 等,2012),LIME(low-light image enhancement)(Guo,2016),MEF(multi-exposure image fusion)(Ma等,2015),NPE(naturalness preserved enhancement algorithm)(Wang 等,2013),VV(Vasileios Vonikakis)(Vonikakis,2017)等。
本文算法运行平台为Pycharm2020,模型使用PyTorch 框架实现,并在Windows10+NVIDIA GeForce RTX 2080Ti GPU 的计算机上对网络模型进行训练。在训练低照度图像增强网络模型的实验时,将batch size 设置为8,一共迭代了200 个epoch。同时,在训练过程中使用学习率为1×10-4的Adam优化器对网络参数进行优化。对于网络中损失函数的超参数,根据大量实验分析,将其分别设置为ω1=5,ω2=ω3=1。另外,在本文网络中,全局图像增强模块需要用到照度估计网络的输出,因此两个子网络相当于两个级联网络的训练,本文采用固定一个网络训练一个网络的训练方法。
2.2 不同增强方法评估
为了验证本文提出的低照度图像增强方法的有效性,从主观视觉评价和客观质量评价指标两方面将本文算法与现有的一些主流的低照度图像增强算法进行增强对比,包括两个传统方法,半解耦分解(semi-decoupled decomposition,SDD)(Hao 等,2020)和即插即用的Retinex 模型(plug-and-play Retinex model,PnPRetinex)(Lin 和Lu,2022),以及4 个基于深度学习的方法,EnlightenGAN(Jiang 等,2021)、零参考深度曲线估计(zero-reference deep curve estimation,Zero-DCE)(Li 等,2022b)、基于Retinex 的深度展开网络(Retinex-based deep unfolding network,URetinex-Net)(Wu 等,2022)和SNR-aware(signal-tonoise-ratio aware low light image enhancement)(Xu等,2022)方法。上述基于深度学习的增强方法与本文网络训练采用了相同的数据集,参数等均采用作者提供的默认参数设置。
2.2.1 主观评价
图6 和图7 分别是多幅低照度图像在无对应正常曝光图和有对应正常曝光图上的对比结果。图8是不同增强算法在极低照度图像上的增强结果。SDD方法对于包含复杂纹理和图案的低照度图像在分解过程中无法准确分离低频和高频成分,导致暗区的部分细节增强不足,如图6(b)中图像A和图7(b)中图像I所示。PnPR 通过估计Retinex 模型中的初始照明来实现增强,对于极低对比度和颜色饱和度的图像,其增强结果如图7(c)中图像F所示,亮度提升不明显,且色彩不自然。EnlightenGAN 的增强效果是基于光照条件进行调整的,从图6(d)中图像C和图6(d)中图像D可看出,其增强结果容易受到噪声影响且在背景处会产生伪影,导致增强后的图像质量降低。Zero-DCE 算法对图像颜色的处理不够精细,会在增强图像的同时引入色彩失真并放大噪声,另外增强结果存在细节丢失和模糊,整体增强效果有待提高。SNR-aware 面向一般低照度图像表现出色,但对于具有特殊纹理的照度极低图像会出现过度平滑问题。如图7(f)中图像H所示。另外,该方法会出现局部过增强问题,如图7(f)中图像F所示。URetinex-Net 整体取得了较理想的增强效果,但对于细节丰富、多光源的情况性能有待提高,如图6(f)中图像D以及图7(g)中图像G所示。与上述6 种方法相比,本文的增强结果在提升图像亮度及对比度的同时,一定程度上抑制了噪声,避免伪影的出现,增强效果更自然。另外,对于照度不均匀图像,在提升暗区亮度时,可较好地恢复纹理细节信息,且有效抑制了噪声的干扰,这表明本文提出的照度和纹理粗估计模块对后续增强起到正向的引导作用。由于全局与局部区域的联合优化,本文方法有效避免了局部欠增强和过增强的问题,如图7(h)中图像F、图像G、图像H放大区域所示。

图6 无真值低照度图像利用不同增强算法的结果示意图Fig.6 Results of different enhancement algorithms for low-light images without ground truth((a)low-light images;(b)SDD;(c)PnPR;(d)EnlightenGAN;(e)Zero-DCE;(f)URetinex-Net;(g)ours)

图7 有真值低照度图像利用不同增强算法的结果示意图Fig.7 Results of different enhancement algorithms for low-light images with ground truth((a)low-light images;(b)SDD;(c)PnPR;(d)EnlightenGAN;(e)Zero-DCE;(f)SNR-aware;(g)URetinex-Net;(h)ours;(i)ground truth)

图8 极低照度图像不同增强算法结果示意图Fig.8 Results of different enhancement algorithms for extremely low-light images((a)low-light images;(b)SDD;(c)PnPR;(d)EnlightenGAN;(e)Zero-DCE;(f)SNR-aware;(g)URetinex-Net;(h)ours;(i)ground truth)
除此之外,在极低照度图像上不同算法的表现如图8 所示。两种传统方法对于亮度提升均不明显,EnlightenGan 和Zero-DCE 均会放大噪声,SNRaware 在图8(f)中图像J中有严重的噪声伪影,URetinex-Net 在极低照度图像上也表现良好,但其增强结果整体偏红,不符合人眼视觉特性。而本文在极低照度图像上表现出色,不仅能提高亮度和对比度,还有一定的抑噪效果。
2.2.2 客观评价
因为本文所选取的普通低照度图像测试集无可参考的正常曝光图像,本文采用3 个无参考质量评价指标对算法进行分析,包括自然图像质量评价(natural image quality evaluator,NIQE)(Mittal 等,2013)、盲色调映射质量指数(blind tone-mapped quality index,BTMQI)(Gu 等,2016)和对比度失真无参考图像质量度量(no-reference image quality metric for contrast distortion,NIQMC)(Gu 等,2017)。NIQE是将图像与设计的自然图像模型进行比较,数值越低说明图像质量越高;BTMQI 通过分析图像自然度和结构来评估经过色调映射处理后的图像的感知质量,其值越低说明图像越自然,质量越高;NIQMC 利用图像中块的局部性质和块之间的相关性质,通过计算其间的对比度来评估图像质量,其评分越高图像质量越好。
VV 数据集因为增强难度较大在图像增强领域为人们所熟知,由于分辨率大小原因,表1 显示了不同方法在部分VV 数据集上的定量增强结果,可以看到本文方法在BTMQI,和NIQMC 上均获得了最优值,但在NIQE 指标上表现不佳。表2 显示了实验对178 幅普通低照度图像数据集整体增强效果的评估结果,从表中可以看到本文方法在BTMQI和NIQMC上均获得了次优值,而NIQE指标有待提高。因为本文在进行增强前对照度和场景纹理注意力图进行粗估计并初步抑噪,会平滑图像中的细节,使其色彩丰富度降低并在一定程度上降低图像的清晰度,导致NIQE 测试值偏高。表1—表2 中,↑表示数值越大图像质量越好,↓表示数值越小图像质量越好。
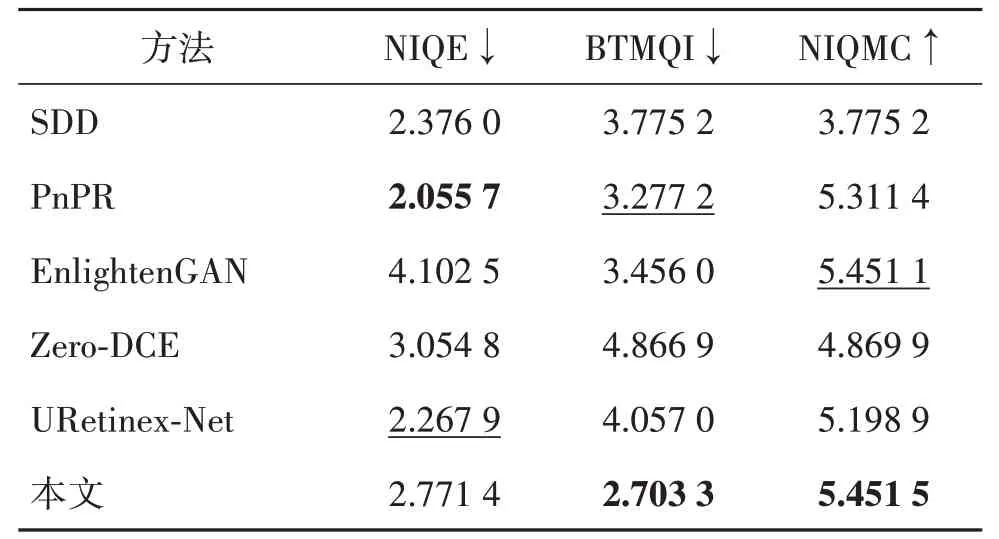
表1 不同算法在VV数据集上增强结果定量评价Table 1 Quantitative evaluation of different algorithms enhancement results on VV datasets
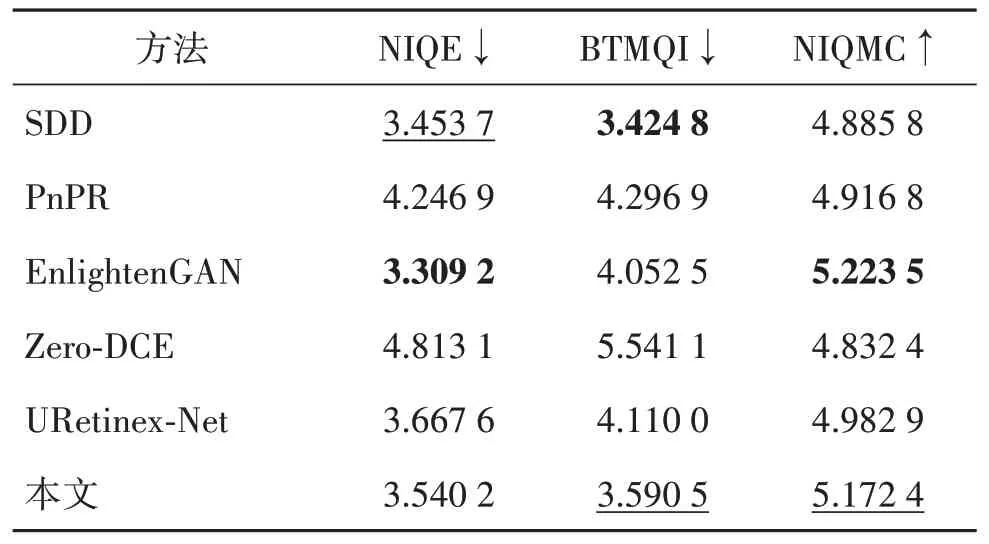
表2 不同算法的增强结果定量评价Table 2 Quantitative evaluation of different algorithms enhancement results
3 结论
针对低照度图像增强中的亮度、对比度增强以及噪声抑制问题,本文利用最小通道约束图具有噪声抑制和纹理突出的优势,结合注意力机制,提出了基于照度与场景纹理注意力图的低照度图像增强方法。首先,通过色彩均衡处理,降低低照度图像色彩偏差对照度和纹理估计的干扰。然后,求取照度和场景纹理注意力估计图为后续增强模块提供信息引导。最后,通过全局和局部增强模型得到最终增强结果图。实验结果表明,本文算法对低照度图像和极低照度图像在亮度和对比度提升,以及噪声抑制方面都有较好的效果,能有效避免颜色失真和局部欠曝和过曝问题,增强效果更自然。但是,本文方法在照度和场景纹理注意力图估计阶段降低部分噪声的同时也平滑了图像细节。在未来研究中,将考虑低照度图像边缘提取和真实噪声处理的问题,进一步提升性能。
