基于情境感知和序列模式挖掘的气象学习资源推荐算法
2024-04-19王帅马景奕周远洋王甫棣
王帅 马景奕 周远洋 王甫棣*
(1 国家气象信息中心,北京 100081;2 中国气象局气象干部培训学院甘肃分院,兰州 730000)
引言
气象职工的在职教育是气象部门人才队伍建设的关键,针对不同个体如何设计出一套符合个人与单位情境需要的学习方案至关重要。所以引入信息智能技术,从气象职工学习需求的内生动力为切入点,通过教学数据自动分析获取个体在组织情境影响下的学习需求数据,有了这些数据就可以针对气象部门内不同的基层单位,开展具有单位特色的、个性化的学习型组织建设工作。为每个有学习需求的气象职工推送时空差异化、知识个性化、课程碎片化[1]的学习资源,通过这种定时、定点、精准的资源推送机制,将大幅度提高气象职工学习的针对性和培训效益。
随着学习资源呈指数级增长,气象职工作为学习者在选择相关的学习资源时会遇到信息过载的困难。推荐系统可以克服这一问题,即根据学习者的个性化偏好,过滤并推荐适合自身知识储备和岗位特点的学习资源。学习资源推荐系统可以为学习者提供相关的、有用的在线学习资源建议[2]。推荐系统在虚拟经济、在线学习等领域中对用户自动推荐相关条目起到了重要作用[3]。
现有的推荐技术如协同过滤CF(Collaborative Filtering)[4]和基于内容CB(Content-Based)[5]的推荐算法分别依赖于用户/物品评价和内容特征来计算相似度、进行预测和生成对用户的物品推荐。然而,在线学习资源推荐系统中,学习者的偏好会随着情境的变化而变化。现有的推荐技术如CF和CB只涉及两类实体,即条目和用户,在进行推荐时不考虑学习者的情境[6]。因此,准确推荐学习资源需要结合学习者的情境信息,以提高推荐的个性化和准确性。在向目标学习者提出建议时,需要考虑学习目标、知识水平等情境信息。此外,由于不同的学习者对学习资源可能有不同的序列访问模式,那么序列访问模式也应该被整合到计算学习者的建议之中。通过将情境感知CA(Context Awareness)[7]和学习者的序列访问模式[8]引入到推荐系统中,可以使推荐结果更加符合学习者的偏好。当前情境下,知识水平为初学者的学习者在未来情境中的知识水平变为中级学习者时,对学习资源的偏好可能会发生变化。在推荐学习的背景下,基于CA的推荐系统在建模学习者偏好和生成推荐时考虑到了学习者的背景[9]。Dec等[10]指出,整合用户的其他附加信息(包括用户情境、序列访问等信息)对于提高推荐质量十分重要。魏杰等[11]指出,序列模式挖掘SPM(Sequential Pattern Mining)关注于发现和挖掘一系列序列发生的事件,常被用于事务性的数据环境中。因此,基于SPM的CA推荐算法可以解决学习者情境特征差异引起的推荐问题。
本文将CF、CA和SPM算法中的GSP(Generalized Sequential Pattern)算法[12]结合到推荐系统中,提出了一种混合推荐算法来向学习者推荐学习资源。混合推荐算法中,CA被用来整合学习者的情境信息,如知识水平和学习目标;SPM被用来对网络日志进行挖掘,发现学习者的序列访问模式;CF被用来根据学习者的情境数据和序列访问模式为目标学习者计算预测并生成建议,避免了CB等推荐算法对于学习者复杂属性处理的局限和不足[13]。通过实验证明,本文结合CF、CA和GSP算法的推荐算法比其他相关推荐算法提供了更准确、更有针对的学习资源推荐。
1 推荐模型与混合算法
1.1 学习资源推荐模型
本文提出的混合推荐算法结合了CF、CA和GSP对学习资源的推荐。图1中的混合推荐模型总结了混合推荐算法的具体功能。推荐模型的主要组成部分是学习者档案、学习对象模型、情境化数据准备、推荐引擎、GSP算法和CA推荐组件。
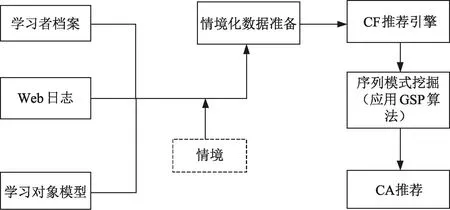
图1 混合推荐算法模型
学习者档案组件存储关于学习者的信息和偏好。学习者档案部分包含的信息是通过隐式和显式两种算法获得的。学习者的数据,如个人信息数据(姓名、性别、年龄、专业、学历、岗位、职称等)以及学习者的背景信息(知识水平和学习目标等)都存储在学习者档案中。推荐系统利用学习者情境信息对学习者的特征和偏好进行个性化设置。
类似地,学习对象模型组件包含有关学习资源的信息。该组件存储有关学习资源的信息,包括学习资源的格式、大小、内容分类、知识点等,可以是文本、图像、音频或视频。学习资源将根据学习者对学习资源和情境信息的评价推荐给目标学习者。
情境化数据准备组件包含清除web日志、准备学习者的情境信息和学习资源的数据以适合推荐系统的格式。
推荐引擎组件包含分析学习者偏好、情境信息和评价聚合而来的情境化数据。CF推荐引擎先收集学习者的情境预测目标、学习者的评价数据,然后使用情境化的数据计算相似度,并根据情境化的学习者偏好生成前N个学习资源推荐。
GSP算法对Web日志进行挖掘,以发现学习者的序列访问模式,并将发现的序列访问模式应用于前N个学习资源推荐结果中,再根据学习者的序列访问模式过滤推荐结果,最后结合CA得到学习者的情境化建议。
1.2 混合推荐算法的实现
混合推荐算法包括3个主要步骤:①使用情境预过滤算法将情境信息整合到推荐过程中。②基于情境化数据计算学习者相似度并预测学习资源的评价。③为目标学习者生成前N个推荐,并采用GSP算法应用到结果中,根据学习者的序列访问模式过滤最终的推荐。这些步骤在图1所示的建议框架中总结,并在本小节中详细说明。
1.2.1 将情境信息纳入推荐系统
将情境信息合并到推荐系统中所采用的范例是由Adomavicius和Tuzhilin提出的情境预过滤算法[14]。采用情境预过滤算法的好处是很容易与任何现有的推荐系统集成。在这项研究中,学习者的情境信息的一个维度,即知识水平。在混合推荐算法中,知识水平作为情境维度随着学习者知识水平的提高而发生变化。例如,对某一岗位专业背景知识很少的学习者,作为初学者可能不具有该专业知识水平的背景,然而,随着时间的推移,学习者获得更多的知识,知识水平情境会发生变化。初始情境数据知识水平在新学员帐户注册期间捕获。在注册到系统中时,通过在线评估问题对新学习者进行测试,根据测试分数确定学习者的知识水平。这种学习者知识等级数据获取算法也被应用于基于本体的学习推荐系统的相关研究中。定期开展在线知识水平测试来跟踪学习者的知识水平背景变化,更新推荐系统的学习者情境化数据。
情境化数据用于计算学习者相似度和目标学习者对学习资源的评价。为便于数据集计算和推荐系统使用,本文将知识水平情境定义为3个值:
知识水平={初级、中级、高级}={1,2,3}
知识水平{1,2,3}元素的赋值用于学习者、学习资源和情境价值的情境化评价矩阵。
1.2.2 学习者相似度测量与学习资源预测计算
一旦情境信息被推荐系统捕获,推荐引擎组件计算学习者的相似性,并预测学习资源的情境化评价(图1)。在计算学习者的相似性时,考虑了情境信息。在推荐系统中使用皮尔逊相关系数来计算学习者的相似性[15]。目标学习者l和学习者u之间的情境相似性S计算如下:
(1)
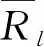
为了计算目标学习者l对学习资源b的情境化评价预测,使用式(1)中获得的对学习资源b进行评价的最相似学习者的KNN(K邻近)算法[16-17]。目标是使用其他类似学习者给b的评价来预测新学习资源b的等级Pl,b。为了计算目标学习者l对学习资源b的预测等级Pl,b,使用式(2)所示的预测公式。
(2)
其中,Pl,b是目标学习者l对学习资源b的预测,n表示邻域内的学习者总数,Ru,b是学习者u对学习资源b的评价,S是目标学习者l和学习者u之间的情境相似性。
1.2.3 情境化推荐生成及GSP算法的应用
为了生成情境化的推荐,将SPM算法中改进的GSP算法应用于前N个推荐,根据学习者的序列访问模式过滤前N个推荐结果。因为情境在学习资源方面的适应性和有效性,这项工作采用了GSP算法。针对目标学习者l的学习资源的前N个建议是基于情境化的学习者相似性和预测评价生成的。图2展示了基于GSP算法生成最终情境化推荐的过程。图中M是一组学习资源{a,b},学习资源a已被目标学习者评价,学习资源b表示目标学习者未评价的学习资源,目标学习者正在寻求对其评价的预测。C是本研究中代表知识水平的情境。知识水平的元素是{1,2,3}表示的{初级,中级,高级}。Pl,a是目标学习者l对学习资源a的评价,Pl,b是目标学习者l对未分级学习资源b的预测评价。其他表示为u的学习者将学习资源评为b一旦得到前N个推荐,则对推荐结果应用GSP算法,根据学习者的序列访问模式过滤前N个推荐。

图2 基于GSP算法生成情景化推荐流程
使用GSP算法发现序列访问模式包括3个主要阶段:①确定每个学习资源的支持度(第一阶段);②潜在频繁序列的生成(候选序列生成);③删除支持数小于最小支持度的候选序列(剪枝阶段)。在学习资源推荐中,学习者的序列访问模式是重要的,在推荐过程中应加以考虑。因此,将GSP算法应用于初始推荐结果的前N个,根据学习者的序列学习访问模式过滤推荐结果。
2 实验与分析
2.1 实验设置与数据集
为了评估所提出的混合推荐算法(GSP-CA-CF)的性能,本文进行了一系列的实验。数据集来自一所使用学习管理系统(LMS)[18]的大学。收集时间为6个月,从2015年9月到2016年3月。在实验期间,使用LMS支持其学习的学习者总数为1200人。LMS允许学习者对学习资源按1~5分(1分非常不相关,2分相当不相关,3分不相关,4分相关,5分非常相关)。推荐系统能够通过匹配学习者的偏好和情境信息向学习者推荐学习资源。初始情境信息(知识水平)是在学习者注册到LMS时收集的,随后随着学习者使用LMS访问在线学习资源并定期更新。学习者的情境信息,即知识水平,随着学习者对某一学科知识的提高而不断变化。学习者的知识水平分为初级、中级或高级。在数据集收集期间,从推荐系统数据库中提取学习者评价和学习者情境信息,并使用GSP算法挖掘Web日志,得到序列访问模式。然后将数据集分成训练子集(80%)和测试子集(20%),以进行实验评估。
为了评估所提出的混合推荐算法的有效性,在相同数据集上评估了其他三种算法,并对结果进行了比较。评估的算法是:①提出结合GSP、CA和CF算法的混合推荐算法(GSP-CA-CF);②基于CA结合CF的算法(CF-CA);③GSP算法;④CF算法。
2.2 实验结果分析
2.2.1 精确度实验
在改变邻域大小的同时进行了一系列实验,以确定最佳邻域的大小,以便在后续实验中使用。推荐系统中最近邻的大小对推荐的预测精确度和质量都有影响[19]。同样,在不同邻域大小下,对四种推荐算法的预测精确度进行了测试。使用平均绝对误差MAE计算预测精确度。MAE值越低,预测精确度越高[20-21]。
(3)
其中,MAE表示平均绝对误差,n表示测试集中的案例数,pi表示项目的预测评价,ri表示真实评价。
图3显示了使用MAE测量的四种推荐算法对邻域大小的敏感度和对最近邻数的预测精确度。从图3中可以看出,所提出的混合推荐算法(GSP-CA-CF)以及其他三种推荐算法(CF-CA,GSP和CF)随着邻域数从5个增加到25个,当最近邻数目为25个时,达到最佳预测精确度,GSP和CF)稳定增加。超过25后,四种算法(GSP-CA-CF,CF-CA,GSP和CF)的曲线开始以较小的间隔上升,四种算法的预测精确度会降低。因此,25作为剩余实验的最佳邻域大小。此外,从图3可以观察到,对于任意数量的最近邻,与其他三种推荐算法相比,推荐算法(GSP-CA-CF)提供了更好的准确性。

图3 不同算法随邻域大小的平均绝对误差MAE
2.2.2 不同稀疏度实验
通过不同稀疏度实验对混合推荐算法预测精确度的影响。实验采用之前邻域实验中最佳邻域值为25的邻域进行。原始数据稀疏度为93.7%。图4显示了稀疏度对预测精确度影响的结果。从图4可以看出,混合推荐算法(GSP-CA-CF)在所有稀疏度级别上的MAE最低,优于其他三种推荐算法。随着稀疏度的增加,三种推荐算法(GSP-CA-CF,CF-CA,CF)的MAE也随之增加。其中,因为在预测学习资源时使用了学习者的序列访问模式,而不是评价,所以GSP算法的MAE随稀疏度的增加变化不大。
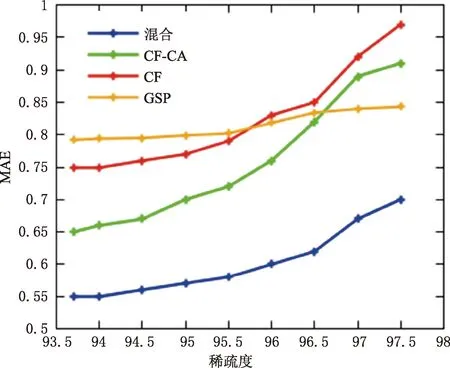
图4 不同稀疏度不同推荐算法预测平均绝对误差MAE
2.2.3 性能评估实验
为了衡量推荐算法(GSP-CA-CF)的性能,本文使用召回率、精确度和F1度量指标[22]进行评估。精确度(Precision)是指推荐的学习资源与所选学习资源数量的比率。召回率(Recall)是正确推荐的学习资源与相关学习资源的比率。
在使用精确度和召回率评估指标时,学习资源的等级为1~5。评价为1~3的学习资源被视为“不相关”,而评价为4~5的学习资源被视为“相关”。
(4)
(5)
其中,精确度P的tp表示被检索到的推荐学习资源数量,fp表示应该未被检索到的推荐学习资源数量;召回率R的tp同样表示被检索到的推荐学习资源数量,fn表示被检索到的不推荐学习资源数量。
表1显示了本文所提出的混合推荐算法(GSP-CA-CF)与其他三种推荐算法(CF-CA,GSP和CF)在不同推荐数量下的精确度P和召回率R方面的性能。从表1可以看出,对于任意数量资源的推荐,本文所提出的推荐算法(GSP-CA-CF)在精确度和召回率指标方面都优于其他三种推荐算法。在增加推荐数量时会导致四种算法的精确度全部下降,随着推荐数量的增加,四种算法的召回率也随之增加。
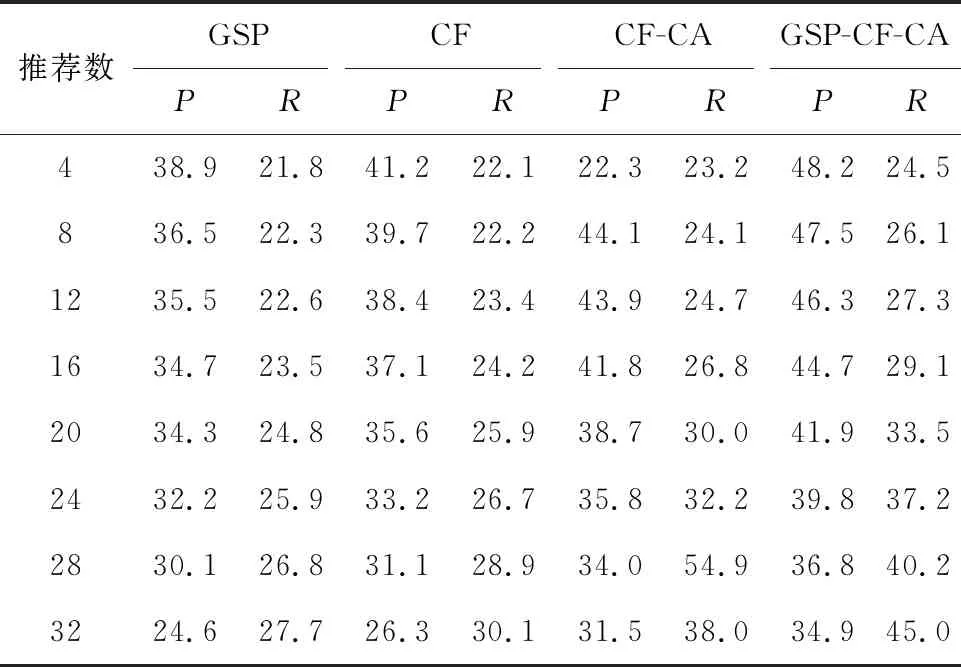
表1 推荐算法性能对比试验结果
F1度量指标是将精确度和召回率合并为一个值,以便于比较几种算法的综合性能指标,并获得性能的平衡视图。F1指标对精确度和召回率给予同等的重视。
(6)
其中,F1表示F1度量指标。
图5显示了所提出的混合推荐算法(GSP-CA-CF)与其他三种推荐算法(CF-CA、GSP和CF)的F1度量的性能相比,混合推荐算法(GSP-CA-CF)在所有实验的推荐数量上都表现出良好的性能。
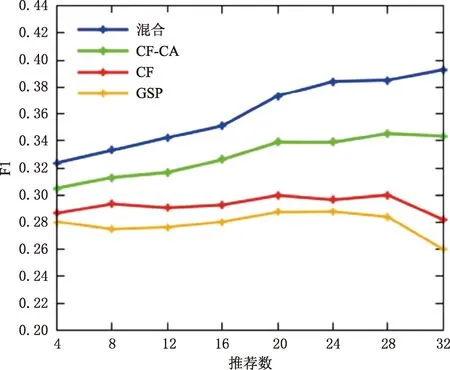
图5 不同推荐算法F1指标随推荐数的变化
各项实验结果表明,将GSP、CA和CF相结合的混合推荐算法可以提高学习者个性化资源推荐的准确性和精确度,该混合算法相比其他三种算法(CF-CA、GSP和CF)的性能优势可用于各类在线学习资源推荐。
3 应用情况
中国气象局干部培训学院甘肃分院基于GSP-CA-CF混合推荐算法设计开发了雲智培智能教学管理系统,该系统主要针对西北区域气象部门职工日常政务、党务和业务知识学习和管理。目前,系统中气象职工注册用户数达到3400余人,在线学习资源170000余份。
系统依靠气象部门政务管理信息系统的气象部门人力资源采集系统的人口统计数据、工作和学习背景等精准的气象职工数据信息开展学习者信息初始化;借助学习者登录系统时的培训知识考试评估系统,对资源进行评价,更新用户情境。
系统采用自适应页面方式展示,每页默认显示8份学习资源,尽量最大化程度满足用户需求。经过1年左右稳定运行,对部分用户数据进行抽测,系统混合推荐资源准确率和召回率分别为48.7%和26.8%。准确率的提升主要是由于地域、单位和职责细化,情境特性相对明显,有利于推荐系统相似度计算并对学习资源的评价。该系统用户满意度调查达93.7%。
4 结论
本文提出了一种基于情境感知和序列模式挖掘的混合推荐算法,用于向在线学习环境中的学习者推荐学习资源。混合推荐算法使用GSP算法挖掘Web日志数据并发现学习者的序列访问模式,通过情境感知合并学习者的情境信息(如知识水平),再由协作过滤生成基于情境化数据的推荐,并将GSP算法应用于情境化推荐,根据学习者的序列访问模式对推荐进行过滤,生成最终的个性化推荐结果给学习者。该混合推荐算法结合多种推荐技术,根据学习者的情境和序列访问模式进行个性化资源推荐,有助于缓解数据稀疏问题。实验结果表明,该推荐算法具有更好的性能和推荐质量。应用于气象教学管理信息系统中资源的推荐也取得了较好的效果。
随着国产化[23]和大数据分析模型[24]的不断深化,混合推荐算法将以气象决策管理协同支撑建设项目为抓手,应用于电子公文和制度树的搜索与推荐,为气象职工推荐准确的参考文件提供助力;同时,也可以与ElasticSearch[25]相结合,对异构数据进行重定位和价值挖掘,提升业务和管理历史数据价值。
