自动泊车多任务轻量化感知模型研究
2024-04-18李景俊黄辉翁茂楠
李景俊 黄辉 翁茂楠

摘 要:随着深度学习模型的发展,越来越多的模型用于各个行业,包括自动驾驶行业,但同时也面临着轻量化感知模型以及产品落地的挑战。然而在自动驾驶泊车感知中,常常受到光照、阴影等环境变化的影响,对空车位检测和可行使区域的识别是很大的难题。本文的算法通过车身左侧、右侧、前侧、后侧等四个车载180度广角鱼眼摄像头实时获取视频流,先將采集到的图像利用卷积神经网络对车辆所处区域周边各车位的状态、车辆可行驶的区域进行计算推理,然后对模型推理结果进行解析与融合。利用一个轻量级网络解决自动泊车过程中进行车位的感知和路面可行驶区域的感知,实验结果表明,帧率可达到19FPS,模型推理帧率可达到29FPS,单车位角中心点定位世界坐标系下平均误差为2.65cm,空车位检测成功率90%以上,满足实际应用对实时性、准确性、鲁棒性的要求。
关键词:自动泊车;深度学习;空车位检测;可行使区域检测
中图分类号:TM911.42 文献标识码:A 文章编号:1005-2550(2024)02-0021-07
Research on Automatic Parking Multi-task Lightweight Perception Model
LI Jing-jun, Huang Hui, Weng Mao-nan
(Advanced Technology Department, Automotive Research & Development Center, Guangzhou Automobile Group Co., Ltd., Guangzhou 510614, China)
Abstract: With the development of deep learning models, more and more models are used in various industries, including the autonomous driving industry, but at the same time, they also face the challenges of lightweight perception models and product implementation. However, in the perception of autonomous parking, it is often affected by environmental changes such as lighting and shadows, and it is a great problem to detect empty parking spaces and identify the driving area. The algorithm in this paper obtains the video stream in real time through four 180-degree wide-angle fisheye cameras on the left side, right side, front side, and rear side of the vehicle, and first uses the convolutional neural network to calculate and reason the status of each parking space around the vehicle area and the area where the vehicle can drive, and then parses and fuses the model reasoning results. Using a lightweight network to solve the perception of parking spaces and the perception of road drivable areas in the process of automatic parking, the experimental results show that the frame rate can reach 19FPS, the model reasoning frame rate can reach 29FPS, the average error of single parking corner center point positioning world coordinate system is 2.65cm, and the success rate of empty parking space detection is more than 90%, which meets the requirements of real-time, accuracy and robustness in practical applications.
Key Words: Automatic Parking; Deep Learning; Detection Of Empty Parking Spaces; Area Detection Can Be Exercised
引 言
各个行业都广泛地应用深度学习算法。尤其最近比较火热的自动驾驶赛道,深度学习算法被广泛使用。在自动泊车应用场景就是一个很好的例子。车位检测和可行使区域检测就是自动泊车技术中的基础。当前技术路线,车位检测算法主要可分为基于超声波雷达、基于高精度定位、基于计算机视觉等三种车位定位方式。基于超声波雷达的车位定位算法中利用超声波雷达对周围环境(车辆、障碍物等)进行感知,但超声波雷达无法对车位线进行检测,只能够规划出可行驶或无障碍区域的大致范围,无法对车位的具体边界、姿态进行精确感知;基于高精度定位的车位检测算法需要提前实现对停车区域的整体改造;基于深度学习的车位定位算法通过环视摄像头进行实时图像采集,对图像中的车位进行提取,并结合对周围环境的感知结果确定目标空车位,具有无附加成本、应用场景广泛、精度较高等优点。同时,基于深度学习的语义分割方法不易受道路是否结构化影响,且不易受光照、阴影等环境因素影响,具有较好的实时性与准确性。
本文的算法通过车身左侧、右侧、前侧、后侧等四个车载180度广角鱼眼摄像头实时获取视频流,先将采集到的图像利用卷积神经网络对车辆所处区域周边各车位的状态、车辆可行驶的区域进行计算推理,然后对模型推理结果进行解析与融合。利用一个轻量级网络解决自动泊车过程中车位的感知和路面可行驶区域的感知,满足工程应用对准确性、鲁棒性、实时性的要求。
1 自动泊车技术介绍
(1)深度学习与卷积神经网络
深度学习是学习样本数据的内在规律和表示层次。深度学习的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。而卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。卷积神经网络具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类。
(2)环境感知
环境感知处于智能驾驶车辆与外界环境信息交互的关键位置,其关键在于使智能驾驶车辆更好地模拟人类驾驶员的感知能力,从而理解自身和周边的驾驶态势。摄像头、雷达、定位导航系统等为智能驾驶车辆提供了海量的周边环境及自身状态数据。环境感知需要遵循近目标优先、大尺度优先、动目标优先、差异性优先等原则,采用相关感知技术对环境信息进行选择性处理。
(3)目标车位与车位角中心点
一个目标车位常由4个车位角组成。按照车位的排列方式,可将车位类型分为垂直车位、平行车位、斜列车位等车位类型;按照车位线的划线方式,可将车位线的划线方式分为封闭型、半封闭型、开放型等划线方式。车位角中心点定义为两条相交车位线的重叠区域所对应四边形对角线的相交点。
(4)语义分割
语义分割是计算机视觉中的基本任务。在宏观意义上来说,语义分割是为场景理解铺平了道路的一种高层任务。在语义分割中我们需要将视觉输入分为不同的语义可解释类别,语义的可解释性即分类类别在真实世界中是有意义的。给出一张街景图像,通过基于深度学习的语义分割模型识别后能够生成可以划分不同区域的图,人、车、路将分别被赋予红、蓝、紫色的标签。
(5)车辆可行驶区域识别
车辆的可行驶区域包括了结构化路面、半结构化路面、非结构化路面。可行驶区域的检测主要是为自动驾驶提供路径规划辅助,可以实现整个的路面检测,也可以只提取出部分的道路信息。
2 关键算法
2.1 车位检测算法
车位检测是自动泊车技术中的基础。当前车位检测算法主要可分为基于超声波雷达、基于高精度定位、基于计算机视觉等三种车位定位方式。基于超声波雷达的车位定位算法中利用超声波雷达对周围环境(车辆、障碍物等)进行感知,但超声波雷达无法对车位线进行检测,只能够规划出可行驶或无障碍区域的大致范围,无法对车位的具体边界、姿态进行精确感知;基于高精度定位的车位检测算法需要提前实现对停车区域的整体改造;基于计算机视觉的车位定位算法通过环视摄像头进行实时图像采集,对图像中的车位进行提取,并结合对周围环境的感知结果确定目标空车位,具有无附加成本、应用场景广泛、精度较高等优点。
2.2 可行使区域检测算法
可行驶区域识别主要是为自动驾驶提供路径规划辅助,可以实现整个的路面检测。从当前的论文、专利来看,不同场景中使用的方法有相同的地方,基本可分为有基于路面颜色、基于纹理特征、基于深度学习的语义分割等方式来获取路面的基本结构特征。基于路面颜色的可行驶区域识别方法当在路面区域内车辆较少,前景与背景之间分割效果较好,其局限性在于当前景的物体太多且颜色分布范围太广时,前景和背景分割成两个部分难度较大,且基于颜色的方法容易受到光照、阴影等环境变化影响;基于纹理特征的方法可提取出路面边缘的方向,同时具有尺度不变性,但在非结构化道路上,很难提取规则化的道路边缘特征,且夜间的识别效果较差;基于深度学习的语义分割方法不易受道路是否结构化影响,且不易受光照、阴影等环境因素影响,具有较好的实时性与准确性。
3 算法流程
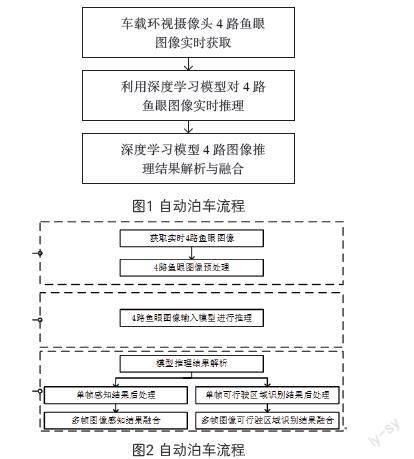
本算法的技术方案主要可以分为图像获取与预处理、模型实时推理、推理结果解析与融合等三个步骤,研发流程图如技术方案流程图1所示。其为本文中技术方案主要组成,图2为对应的技术实现。
3.1 图像的实时获取与预处理
因在自动泊车过程中需要标定摄像头的内部参数和外部参数用于目标车位定位结果从图像坐标系到世界坐标系的转化,且位于车身各侧的摄像头安装高度、角度存在差异,所以需要分别对各路车载摄像头进行内部参数和外部参数的标定。因为鱼眼图像具有较广的视野,所以在本算法中并不利用摄像头的内部参数和外部参数对采集到的鱼眼图像进行畸变矫正以及全景图像的拼接。通过分别安装在车辆前侧、后侧、左侧、右侧的180度广角鱼眼摄像头获取4路视频流,对各路图像的大小进行归一化操作,所有图像大小均从1280×720缩放至640×360。
3.2 卷积神经网络的设计与训练
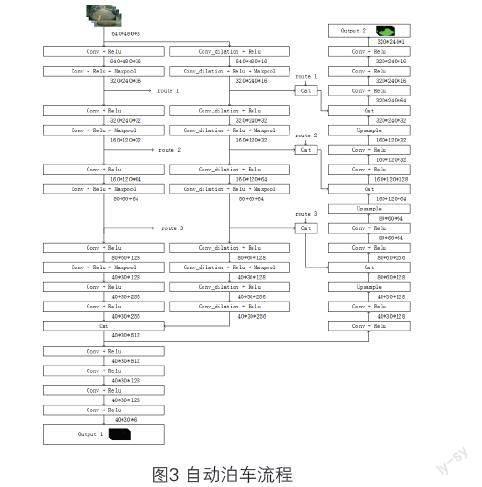
本文设计了基于深度学习的卷积神经网络模型结构用于实现对摄像头视野范围内的车位检测和可行駛区域识别,模型结构图如图3所示,模型的整体结构可以分为共用层、车位检测分支层、可行驶区域识别分支层等3个子部分组成。模型的输入为尺度为640×480的3通道RGB图像;模型有两个输出,一个用于输出车位检测的模型推理结果,另一个用于输出可行驶区域识别的模型推理结果。
(1)共用层结构设计
两个推理任务共用前20层共用层,前20层卷积层由2个10层的分支并联构成,前一个分支中的卷积核均采用3×3的卷积核,后一个分支中的卷积均采用空洞尺度为5的3×3的卷积核,2个分支给后续的推理带来了不同的感受野,能够使提取出的更加丰富的特征,且每个卷积层后均使用修正线性单元激活函数Relu,在每个分支第2、4、6、8个卷积后使用下采样层,最后将两个分支的推理结果进行拼接;
(2)车位检测分支结构设计
车位检测分支层由4层卷积层构成,每层卷积层均采用3×3的卷积核,且每个卷积层后均使用修正线性单元激活函数Relu,最终输出的车位识别模型推理结果的尺度为40×30×6,可表示为:
输出结果将原始图像分为30行40列的等大小矩形块,原始图像中第i行j列的矩形块对应的预测结果为车位识别模型推理结果的第i行j列的6位输出:(cre1, x1, y1, cre2, x2, y2),其中cre1、cre2分别表示该矩形块中含有车位角中心点、空车位中心点的概率,x1、y1、x2、y2分别表示就当前块而言归一化后的车位角中心点横坐标、车位角中心点纵坐标、空车位中心点横坐标、空车位中心点纵坐标。
(3)可行驶区域识分支结构设计
可行驶区域识别分支层含有9层卷积层构成,每个卷积层后均使用修正线性单元激活函数Relu,在该部分的第2、4、6、8个卷积后增加上采样层,每个上采样层后分别拼接共用层中两个分支对应的第6、4、2个卷积层后的下采样层的推理结果,最终输出尺度的长、宽均会恢复至原始输入图像尺度的二分之一,将共用层的浅层推理结果传入可行驶区域识别分支层中的结构设计方式能够提高可行驶区域识别推理结果的精确度,获得更加精细的可行驶区域识别结果。
3.3 深度学习模型多路图像推理结果解析与融合
在上一阶段中,利用深度学习模型对输入的图像进行计算推理,得到模型输出的车位检测结果和可行驶区域识别结果,模型的输出结果存在大量的冗余信息,需通过解析算法从模型推理结果中提取出有用的结构化信息用于后续操作。模型的输出信息是尺度为40×30×6的车位检测推理结果和320×240×1的可行驶区域识别推理结果。
在车位检测分支推理结果中,每张图片对应40×30个检测框,每个检測框推理出6维的预测信息(cre1, x1, y1, cre2, x2, y2)。假定当前判定块为第i行第j列的矩形块,当前块的可信度cre1i,j若满足cre1i, j>0.9, 则判定当前块中含有车位角中心点,否则不含有。同理,若满足cre2i,j>0.9,则判定当前块中含有空车位中心点,否则不含有。由于预测的坐标值x1、y1、x2、y2为就当前块而言经归一化处理后的坐标值,则在解析阶段需要将坐标值转换为对应的图像坐标系下的坐标值,转化公式为式2和式3:
其中,x和y为转换前矩形块内的横、纵坐标值,x'和y'为转换后图像坐标系下的横、纵坐标值,w和h为输入图像的宽和高,i和j分别对应当前块的行号和列号。将转化得到的车位角中心点坐标和空车位中心点坐标分别以(x,y,cre)的形式存放至Setcorner,cam和Setplace,cam中。其中,cam表示摄像头标号,取值为front、back 、left、right,分别对应前侧、后侧、左侧、右侧摄像头;x、y分别为对应图像坐标系的坐标值;cre为当前点的可信度,cre介于0至1之间,越接近1代表该点的可信度越高。经解析后的车位检测分支推理结果可视化如图4和图5所示,图中红色叉代表车位角中心点,红色叉旁对应红色数字代表对应车位角中心点识别结果的可信度cre,图中黄色线代表识别的空车位区域。图7为将图8的可视化结果叠加至原始采集图像上的可视化效果图。
在可行驶区域分支推理结果中,推理结果的尺度为320×240×1,长、宽均为模型输入图片尺寸大小的二分之一。首先将可行驶区域分支推理结果进行上采样操作,即将长、宽均扩大1倍,则可以得到与输入图像相同大小的推理结果,推理结果的每个像素点表示对应原始图像像素点处为可行驶区域的可行度cred,该值介于0至1之间,cred越大表示当前像素点为可行驶区域的可能性越大。在本算法中将满足cred>0.9的像素点判定为可行驶。模型推理的可行驶区域识别结果解析后的可视化效果如图6和图7所示,绿色区域为识别的可行驶区域,黑色区域为识别的不可行驶区域。图7为将6的可视化结果叠加至原始采集图像上的可视化效果图。
如图4和图6所示,已经将模型的推理结果去冗余解析为规则化的车位角中心点坐标、车位角中心点坐标、可行驶区域识别结果。由于相邻摄像头的视野范围存在一定得重叠,所以现实中的一个车位角至多同时出现在2个相邻摄像头的视野范围内。那么,在同一时刻的4路图像识别结果中可能出现相同车位角的不同摄像头识别结果。在本论文的算法中分别将Setcorner,cam和Setplace,cam的识别结构映射车辆坐标系下,当前车辆坐标系的原点选取为车辆后轴中心在地面方向的投影点,x轴方向选取为车辆后轴中心向前轴中心方向,y轴与x轴垂直水平向右,坐标的单位为厘米,映射后的坐标集分别为Set'corner,cam和Set'place,cam。根据摄像头安装位置关系,前侧摄像头与右侧摄像头之间、右侧摄像头与后侧摄像头、后侧摄像头与左侧摄像头之间、左侧摄像头与前侧摄像头之间存在重叠区域,则分别在对应的2个坐标集中判定是否存在相同车位角中心点的不同识别结果,两点之间是否相同的判定依据为公式4:
其中x1、x2分别表示两个预测点的横坐标,y1和y2分别表示两个预测点的纵坐标;thresh为距离阈值,在本论文的算法中thresh取值为5。当判定两个点为同一车位角中心点时,则需要对两个预测点的精确度进行度量,选取可信度更大的坐标值作为当前车位角中心的坐标值,并加入至最终的车位角中心点检测结果集Setcorner中。按照同样的策略生成空车位中心点检测结果集Setplace。
同理,可行驶区域的识别结果中相邻摄像头之间也存在视野的重叠区域,由于不同摄像头安装的视角存在差异,相邻摄像头的重叠区域的识别结果可能存在差异。在视野的重叠区域中,当前像素点在任一摄像头采集图像中判定为可行驶区域的可信度cred>0.9时,则判定当前像素点为可行驶区域。最终生成的可行驶区域俯视图如图8所示。并将车位检测的结果集Setcorner和Setplace映射至可行驶区域俯视图上,生成最终的车位检测可视化结果,如图9所示:
3.4 卷积神经网络的设计与训练
用于计算机视觉的目标检测模型结构繁多,如Faster R-CNN、SSD、YOLO系列等,模型与模型之间在准确性、实时性、鲁棒性上存在一定的差异。由于车载硬件平台对自动泊车系统中空车位检测算法算力要求的限制,无法直接采用已开源的深度学习模型结构,需要对模型结构的深度和宽度进行一定的裁剪、优化,并对模型的输入图像尺寸进行评估选定。本论文提出了一种轻量化的深度学习卷积神经网络模型结构,如图2所示。该模型的整体结构可以分为共用层、车位检测分支层、可行驶区域识别分支层等3个子部分组成。模型的输入为尺度为640×480的3通道RGB图像;模型有两个输出,一個用于输出车位检测的模型推理结果,另一个用于输出可行驶区域识别的模型推理结果。一个模型结构能够同时完成自动泊车过程中基于视觉的车位感知和可行驶区域感知,并且能够满足工程应用对准确性、实时性、鲁棒性的要求。
4 仿真验证
测试采用电动车作为线控平台车,车周安装4个180度720p环视摄像头,运行计算器采用笔记本电脑,通过视频采集卡读取4路摄像头信息运行处理后再通过USB-CAN卡控制车辆。
实车测试整体运行通过四个摄像头采集图像信息,并且传递给实验电脑,实验电脑运行多任务轻量级感知模型,输出车位角信息和可行使区域信息,并且以100ms为周期进行动态规划路径,可以满足实时性要求,整个泊车过程运转流畅舒适,很好的完成了整个泊车。如图12,实测垂直车位、平行车位及斜列车位均可自适应并较好完成泊车。单车位角中心点定位世界坐标系下平均误差为2.65cm,空车位检测成功率93%以上,验证了以上方法可以在实际工程应用的可行性。
实测垂直车位、平行车位以及侧方位均可以自适应并较好泊车,测试结果如表1表2所示,泊入成功率95%以上,空车位识别93%以上,优于行业内的量产产品。
5 结论
本文中算法使用的数据集包含15k张样本,数据集样本涵盖包含露天停车场、地下停车场等场景。经测试,本算法(包含图像预处理、模型推理、后处理解析融合)帧率可达到18FPS,模型推理帧率可达到30FPS,单车位角中心点定位世界坐标系下平均误差为2.5cm,空车位检测成功率90%以上,满足实际应用对实时性、准确性、鲁棒性的要求。
参考文献:
[1]https://robotcar-dataset.robots.ox.ac.uk/.
[2]Joseph Redmon, Santosh Divvala, Ross Girshick. You Only Look Once: Unified, Real-Time Object Detection[C]// 2016 IEEEConference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2016.
[3]Redmon J , Farhadi A. [IEEE 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) - Honolulu, HI (2017.7.21-2017.7.26)]2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR)- YOLO9000: Better, Faster, Stronger[J]. 2017:6517-6525.
[4]Redmon J , Farhadi A . YOLOv3: An Incremental Improvement[J]. 2018.
[5]Gordon D, Kembhavi A , Rastegari M , et al. IQA: Visual Question Answering in Interactive Environments[J]. 2017.
[6]Chen, Liang-Chieh, Papandreou, George, Kokkinos, Iasonas, et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 40(4):834-848.
[7]Chen L C, Papandreou G, Schroff F, et al. Rethinking Atrous Convolution for Semantic Image Segmentation [J]. 2017.
[8]Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation[J]. 2018.
[9]Chollet, Fran?ois. Xception: Deep Learning with Depthwise Separable Convolutions[J].2017.
[10]Badrinarayanan, Vijay, Kendall, Alex, Cipolla, Roberto. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Scene Segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence:1-1.
