基于集成学习的近实时FY-4A反演降水快速订正方法
2024-04-17吕毅雍斌沈哲辉李季梅俊
吕毅,雍斌,沈哲辉,李季,梅俊
1.河海大学 水灾害防御全国重点实验室,南京 210098;
2.河海大学 水文水资源学院,南京 210098
1 引言
降水是全球水循环系统的重要组成部分,其时空分布的变化深刻影响着陆地水文变化过程(张建云,2010)。获取高时空分辨率降水信息,尤其是近实时降水数据,对径流预报、洪水预警、水库调度等与人民群众生命财产安全息息相关的重大科学问题起着关键作用(刘苏峡等,2005),进一步深入影响着社会经济的稳定发展(刘志雨,2009)。
卫星反演具有不受下垫面限制、快速获取大范围降水信息、时空分辨率高的优点(刘元波等,2011;唐国强等,2015)。目前,新一代全球多卫星联合反演降水计划GPM(Global Precipitation Measurement)能提供整体质量好、时空分辨率高、应用途径广泛的卫星反演降水估计产品(陈晓宏等,2017)。IMERG(Integrated Multi-satellitE Retrievals for GPM)作为GPM 的核心产品之一,在中国大陆上已经多次被验证其具有较好的精度(任英杰等,2019;张茹等,2021)。”然而,由于中国未被列入GPM 计划的核心研发成员国,国内科研人员难以获取GPM 的底层观测信息和反演算法。
风云四号系列卫星是中国自主研发的新一代静止轨道运行的气象卫星(董瑶海,2016)。2016年,搭载着性能位于国际前列的静止轨道辐射成像仪AGRI(Advanced Geosynchronous Radiation Imager)的风云四号A 星(FY-4A)成功发射并投入使用(唐世浩和毛凌野,2020)。AGRI 可通过搭载的双扫描镜进行二维指向,首次实现了分钟级的区域快速扫描,可高频获取14 个波段以上的地球云图(王淦泉,2004)。不再受限于单一可见光通道,FY-4A 首次回传了更高质量的彩色卫星云图(陆风等,2017)。
AGRI 获取到的反照率、云顶亮温等数据,也为风云系列卫星降水反演提供了重要依据(钟宇璐,2021a)。从2018年3月起,国家气象中心(http://www.nsmc.org.cn/[2022-11-15])开始提供降水估计实时产品:FY-4A REGC(中国区域近实时降水估计产品)和FY-4A DISK(全圆盘近实时降水估计产品)。相较于FY-4A DISK 覆盖整个亚洲地区,FY-4A REGC 仅覆盖中国大陆区域,但有着更高的扫描频率(田昊,2021)。此外,FY-4A REGC 没有融合雨量计信息,更能反映卫星反演降水的真实能力。GPM 计划中,与FY-4A REGC 对标的产品是IMERG 的近实时版本IMERGEarly(钟宇璐,2021b)。迄今,部分研究已经评估了FY-4A REGC 和IMERG-Early 在中国区域近实时估计的精度,发现FY-4A REGC 虽然较上代产品有了明显提升,但相较于IMERG-Early 仍有差距。这主要因为IMERG-Early 扫描时间更长、数据源更多、反演算法更成熟(高浩等,2021)。与应用于气候研究的多源融合降水产品不同,近实时产品更多运用于水文预报、灾害预警等领域,对时效性要求高(龙柯吉等,2020)。因此,如何快速订正FY-4A REGC,使其具有媲美IMERGEarly的精度,成为了亟待解决的问题。
目前,订正卫星反演降水产品的方法主要思路是建立历史卫星测雨估计与历史降水真值(一般是雨量计或雷达测量值)之间的线性先验关系模型。当获取到新的观测信息后,再利用上述关系反推订正后的降水(王超,2019)。然而,大量研究表明单纯的线性模型很难精准刻画卫星测雨与降水真值间的关系(魏义熊,2022;李昕潼等,2023)。
集成学习是一种将几种元机器学习模型组合成一个模型的非线性算法(陈凯和朱钰,2007;何清等,2014)。作为传统机器学习的凝练和提升,集成学习在偏差订正、方差减少、预测改进等领域取得了较大发展(徐继伟和杨云,2018)。其中,专注于偏差订正的Boosting 算法或有潜力应用于卫星降水领域,这已经在宋蕾(2015)、陈浩等(2017)、王超(2019)、钟宇璐(2021a)的研究中有所体现。Boosting 算法根据上一次训练得到的子模型结果,调整数据集样本分布,而后生成下一个子模型(于玲和吴铁军,2004)。每个子模型的重要度作为模型输出结果的权重,通过迭代的方式加权计算得出最终结果。根据模型结构设计的不同,产生了GBDT(Friedman,2001;Gradient Boosting Decision Tree,梯度提升决策树)、LightGBM(Ke等,2017;Light Gradient Boosting Machine,轻量级梯度提升机)、XGBoost(Chen 和Guestrin,2016;eXtreme Gradient Boosting,极限梯度提升树)等重要分支算法,这些算法各有优势,在众多科学问题中都发挥了重要作用。
相较于深度学习,集成学习算法的模型训练速度更快、所需数据量更少、模型稳定性强(Shinde 和Shah,2018;Chauhan 和Singh,2018;Nguyen等,2019),更适合于近实时降水的研究。因此,本研究借助极具潜力的集成学习理论,选取并比较典型的集成学习模型LightGBM、XGBoost和Random Forest,从而快速高效地订正近实时FY-4A降水数据。
2 研究区、研究数据和评估方法
2.1 研究区
研究区域为中国(香港、澳门、台湾数据缺失)。研究区地处亚欧大陆东部,太平洋西岸,南北跨度近50°,地势西高东低且地形复杂。研究区降水的空间分布不均匀,年平均降水量呈现由东南沿海向西北内陆递减的趋势(左洪超等,2004)。由于对季风活动响应较强,中国的降水季节性变化显著,呈现出冬季降水少,夏季降水多的特性(翟盘茂和潘晓华,2003),其中夏季降水是造成中国洪涝灾害的主要原因。
2.2 研究数据
2.2.1 FY-4A REGC
风云四号A星是风云二号C星(中国第一代静止气象卫星第一颗业务卫星)的迭代产品。除了具有通过静止轨道观测云、水汽、植被、地表的基础功能,FY-4A 还具备了捕捉气溶胶、雪的能力,并且能清晰区分云的不同相态和中、高层水汽(范存群等,2018)。FY-4A的AGRI每小时完成一次全圆盘观测,每15 min 在观测空隙进行定位定标观测,覆盖范围为亚太地区;当无全圆盘观测时每5 min进行一次中国区域观测,覆盖范围为3°N—55°N,60°E—137°E(张环宇和唐伯惠,2021)。
国家气象中心于2018年3月12 日发布降水反演产品FY-4A REGC 和FY-4A DISK。本研究使用FY-4A REGC 作为模型输入。FY-4A REGC 的原始时空分辨率为5 min(不连续)/4 km。在本研究中,将FY-4A REGC的时空分辨率重采样至1 h/0.1°以匹配地面观测分辨率。数据的时间范围为2018年6月1 日至2019年9月30日,覆盖两年的夏季(6、7、8月)。
2.2.2 IMERG-Early
IMERG 是全球卫星降水观测计划GPM 的代表性卫星反演降水产品之一,其核心卫星上搭载的微波成像仪(GMI)和支持Ku 波段(13.6 GHz)和Ka 波段(35.5 GHz)的双频降雨雷达(DPR)提供了时空采样更精密的信息源,再通过其反演算法得到满足不同时效和质量需求的全球降水数据集(Smith等,2007)。作为GPM 时代的重要成果,IMERG 使用的算法由TRMM(Tropical Rainfall Measuring Mission)时代3 套主流的降水反演算法(TMPA、GSMaP 和PERSIANN)融合发展而产生,它同时引进了卡尔曼滤波和云移动矢量传播两种算法(Draper等,2015)。IMERG 系统在近实时阶段运行两次,先后得到IMERG-Early 和IMERG-Late(Skofronick-Jackson等,2017)。其中IMERG-Early仅使用了云移动矢量传播算法中的前向传播算法以相对快速地提供结果。IMERG-Early的原始时空分辨率为30 min/0.1°。为与地面参考、FY-4A 降水数据匹配,将IMERG-Early 的时间分辨率重采样到1 h。
2.2.3 CMPA
CMPA(中国自动站与CMORPH融合的逐时降雨量0.1°网格数据集)使用地面和卫星两个来源的降雨数据:地面观测降雨资料来自全国3万多个自动观测站(包括国家级自动站和区域自动站)逐时降雨量,卫星反演降雨产品选用由美国环境预测中心开发的实时卫星反演降雨产品,应用了概率密度匹配和最优插值算法分两步融合数据(张强等,2007)。在本研究中,仅使用地面自动站观测数据,将其作为卫星降水数据质量检验的真值。以上3套数据的信息已在表1中给出。

表1 研究使用数据Table 1 Data used in this research
2.3 评估方法
本研究为定量评估订正结果的表现采用了3种常用的精度指标(廖荣伟等,2015;曾岁康和雍斌,2019),其中包括:(1)相关系数CC(Correlation Coefficient)用于量化降水数据与实测数据之间的线性相关程度,最优值为1;(2)均方根误差RMSE(Root Mean Square Error)用于量化降水数据与实测数据之间的离散程度,最优值为0;(3)相对偏差Bias(relative Bias)用于反映卫星降水数据与实测数据之间的偏差程度,最优值为0。各指标计算表达式和最优值见表2。

表2 统计评估参数Table 2 Statistical evaluation parameters
3 基于集成学习的快速订正算法
3.1 LightGBM
LightGBM 是集成学习中经典Boosting 方法GBDT的改进。LightGBM在传统的梯度提升树的基础上引入直方图决策算法、单边梯度采样和互斥特征捆绑算法(Lundberg等,2019)。在样本数据量和特征量增长的情况下,LightGBM 的精度却不受影响,并且能够有效提升模型训练速度。
直方图决策算法通过构建直方图得到分集。将连续的输入值离散化成k个整数并构造一个宽度为k的直方图,遍历直方图的值以找最优分割点,有效减少了候选分裂点数量。由于目标函数增益主要来自于梯度绝对值较大的样本,因此单边梯度采样只考虑梯度绝对值小于一定阈值的样本,保留绝对值较大的样本。互斥特征捆绑算法则可以通过对某些特征的取值重新编码,将多个互斥的特征绑定为一个新特征,以降低计算复杂度(Ke等,2017)。这使得该算法在保证训练精度的同时,极大提升了算法的运行速度。
3.2 XGBoost
XGBoost 是经典Boosting 方法GBDT 的另一种改进。相较于GBDT,XGBoost 基于二阶泰勒公式并引入了正则化方法。对于一般模型,目标函数可以表示为
式中,L(θ)是训练损失函数,Ω(θ)是正则化项。L(θ)的常见选择是均方根误差,它由下式给出:
式中,yi是样本,是样本均值。
正则化方法定义了模型复杂度:
式中,T是决策树的叶子数,γ是折算系数,是叶子结点对应的值向量的L2范数。
XGBoost 运行的一般步骤是:首先,从深度为0 的树开始,对每个叶子节点枚举所有可用特征。其次,针对每个特征,把属于该节点的训练样本根据该特征值升序排列,通过线性扫描的方式来决定该特征的最佳分裂点,并记录该特征的最大收益。然后,选择收益最大的特征作为分裂特征,用该特征的最佳分裂点作为分裂位置,并为每个新节点关联对应的样本集。最后,反复递归执行到满足特定条件为止(Chen和Guestrin,2016)。
3.3 Random Forest
Random Forest 是集成学习中Bagging 方法的代表模型之一。其一般步骤是:从训练集中有放回地抽样,取样多次形成一个新训练用子集D,随机选择m个特征。使用新的训练集D和m个特征,学习出一个完整的决策树,反复进行多次,最后得到随机森林(Breiman,2001)。
与GBDT 相比:Random Forest 是并行生成的,而GBDT是串行生成的;Random Forest的结果是多数表决形成的,而GBDT的结果则是多棵树累加所得。本研究中,主要使用Random Forest 与两种Boosting方法模型LightGBM 和XGBoost对比。
3.4 算法流程
本研究提出的基于集成机器学习的快速订正算法如图1(a)所示。具体可分为4个步骤。
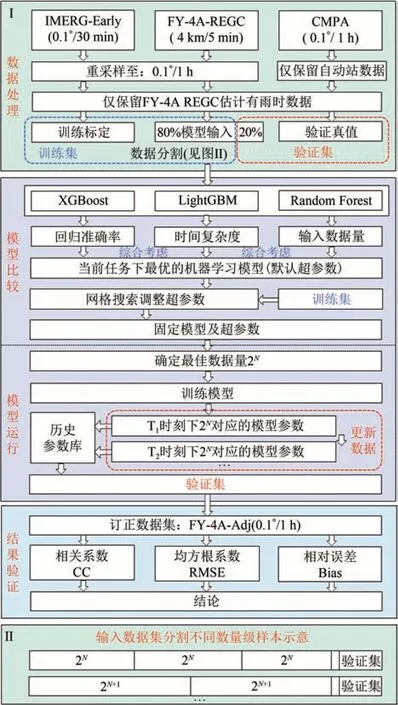
图1 基于集成学习的快速订正算法Fig.1 Fast correction algorithm based on ensemble machine learning
步骤一,数据处理。本步骤首先将FY-4A REGC和IMERG-Early 的时空分辨率重采样至0.1°/1 h,以匹配CMPA的自动站观测数据。为确保在没有其他气象(降水)数据输入的情况下仍能完成订正任务,本研究仅针对FY-4A REGC 估计有雨时的数据。与此同时,CMPA 则仅使用有自动观测站点的格点。在本研究中,我们选取了80%的FY-4A REGC 作为训练集的输入,并将IMERG-Early 作为训练数据集标定。然后,训练集将按不同数量级进一步分割,具体分割方式如图1(b)所示。不同的分割方法将产生不同的模型参数和运行时间。此处,220个样本数量级约包含3 h 的数据特征,而225个样本数量级约包含4 d 的数据特征。分割后,剩余的20%的FY-4A REGC 将用作验证集,输入训练完成的模型以获得订正结果。此外,研究未打乱输入数据的时间顺序。因此训练集大约对应2018年6月1 日至2019年6月30日,而验证集大约对应2018年7月1 日至2019年9月30 日。最后将CMPA中的自动站观测数据用作验证真值,以评估订正效果。评估结果的时间范围与验证集相同。
步骤二,模型比较。本研究选取了两种Boosting方法模型LightGBM 和XGBoost以及一种Bagging方法模型Random Forest。本研究通过综合评估回归准确率、时间复杂度与输入数据量的关系,获取在默认参数设置下,最适合当前任务的集成学习模型。一旦确定被选模型,我们将使用网格搜索方法对其超参数进行进一步优化。
图2 使用泰勒图比较了FY-4A REGC 和IMERG-Early在2018年夏季和2019年夏季的表现。在泰勒图中,估计点距离“观测值”越近,说明数据集越接近观测值。结果显示,IMERG-Early在2018年夏季和2019年夏季的表现几乎相同,而FY-4A REGC 则有明显不同:2019年夏季点与观测点的距离较2018年夏季更小。这表明FY-4A REGC 的数据质量随着时间的推移有明显的提升。这主要是由于官方对反演算法和定标结果进行了调整。为了使模型能够清晰反映FY-4A REGC 和IMERG-Early之间的隐含关系,我们提出了一种滚动输入最新数据并不断更新模型参数的运行方法。

图2 2018年、2019年夏季3套产品统计性能泰勒图Fig.2 Taylor diagram of statistical performance for three datasets of products in the summers of 2018 and 2019
步骤三,模型运行。首先,固定模型及其超参数,确定模型训练合适的输入数据量2N(N为待确定值)。其次,训练模型并获得T1时刻下2N对应的模型参数并记录到历史参数库。然后,当获取到新数据时,记为T2时刻。此时删除最旧的数据并加入新数据,始终保持数据总量为2N。重复训练模型的过程。最后,获得模型参数库,加载最接近参数库所载时间Ti(i=1,2,3,…)的模型参数以运行模型。
图3展示了随着时间推移,在训练集上不同模型参数更新后的输出结果评估对比。结果显示,随着时段数的增加,输出结果的评估效果明显改善。
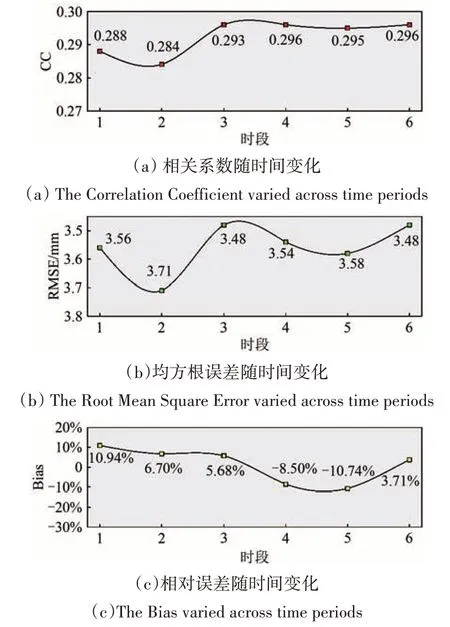
图3 模型内不同参数随时段变化输出结果的评估对比(基于训练集和CMPA)Fig.3 Evaluation comparison of model output with different parameters varied across time periods(based on training datasets and CMPA)
步骤四,结果验证。我们固定模型并输入验证集,将模型输出的数据作为输出订正数据集FY-4A Adj(时空分辨率为1 h/0.1°)。最后,通过计算CC、RMSE、Bias等指标以评估模型效果。
4 结果与讨论
4.1 模型的选取
鉴于FY-4A REGC 的数据质量随着时间推移有明显提升的特性,滚动输入新观测信息以更新模型的最优参数有其必要性。此外,FY-4A REGC是近实时降水反演产品,更新订正模型参数的过程必须考虑时效性。因此,挑选一种在输入数据量级逐步提升条件下,仍能兼顾运行时间和订正精度的模型成了本研究的首要问题。图4通过热力图的形式,给出了每种集成学习模型运行各数据量级的输入数据后,训练模型的回归精度和所需时间(运行平台如表3 所示)。需要指出的是,模型使用默认超参数且运行同一模型时仅改变输入数据的量级。
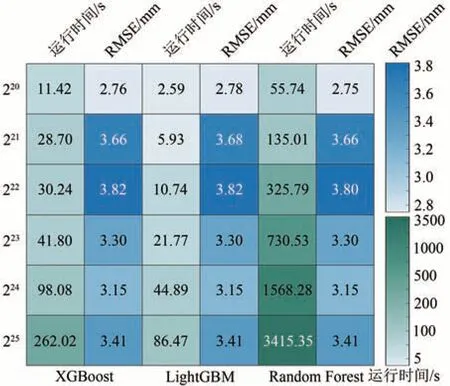
图4 3种模型不同数量级数据输入下的回归精度和运行时间Fig.4 Regression accuracy and execution time of three models with varying magnitudes of data input
表3 实验平台Table 3 Experiment platform
根据训练精度表现可知,在数据量提升至223之前,代表Bagging 算法的Random Forest 模型要优于代表Boosting 算法的XGBoost 和LightGBM 模型,但当XGBoost 和LightGBM 在223数据输入时,它们的训练效果与Random Forest 持平。从训练时间方面来看,尽管3种模型获得了类似的训练效果,但XGBoost 在220的训练时间为LightGBM 的4.4倍,而Random Forest 所需的训练时间更是为LightGBM 的21.5 倍。在数据量进一步增加至225后,所需时间更是增长到了LightGBM的39.5倍。
经过上述分析,可以得出以下结论:随着训练数据量的增加,所有集成学习模型的训练时间都呈线性增长趋势。训练精度相对稳定,受训练数据量级的影响不大。Bagging 算法在数据量较少时略好于Boosting 算法,但随着数据量的增加,Bagging 算法的运行复杂度显著增加,而Boosting算法则只需要延拓部分误差传播模型即可。在Boosting 算法中,LightGBM 的直方图决策算法、单边梯度采样和互斥特征捆绑算法对维持训练精度和提升训练速度起到了显著作用。在样本数据量和特征量增长的情况下,LightGBM 不但能保持训练精度,而且模型训练速度明显更快。因此,当数据量较少时,更推荐使用包括Random Forest 模型在内的Bagging 算法,而当数据量较大时,更推荐使用Boosting 算法,尤其是LightGBM 模型,因为它可以兼顾训练精度和训练时间。在本研究中,我们将选取LightGBM 作为快速订正近实时降水反演产品FY-4A REGC的主要方法。
4.2 分割输入量级的选取
此外,对新生成的产品FY-4A Adj 进行了分析,该产品是未参与训练的验证集数据,输入经过网格搜索法调参后的LightGBM 模型产生的输出结果。我们将FY-4A Adj与CMPA 观测资料进行比较,以确定最适合的输入量级。表4列出了网格搜索法调整的超参数。图5 则展示了训练结果与IMERG-Early计算所得的均方根误差值RMSE。
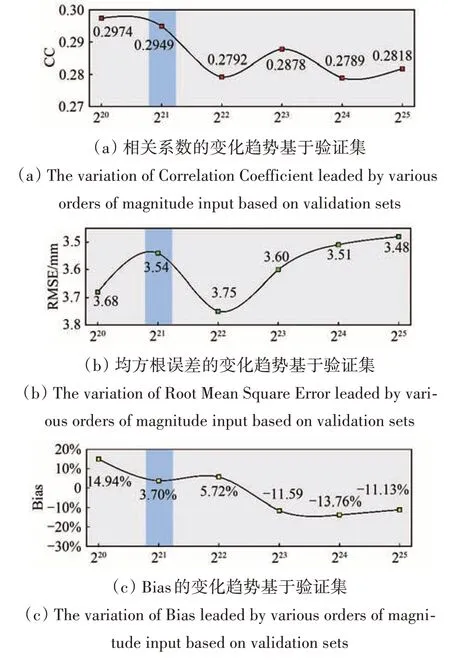
图5 各数量级输入导致评估结果(蓝色代表优选数据量)Fig.5 Performance changing trends(The blue areas represent the best)
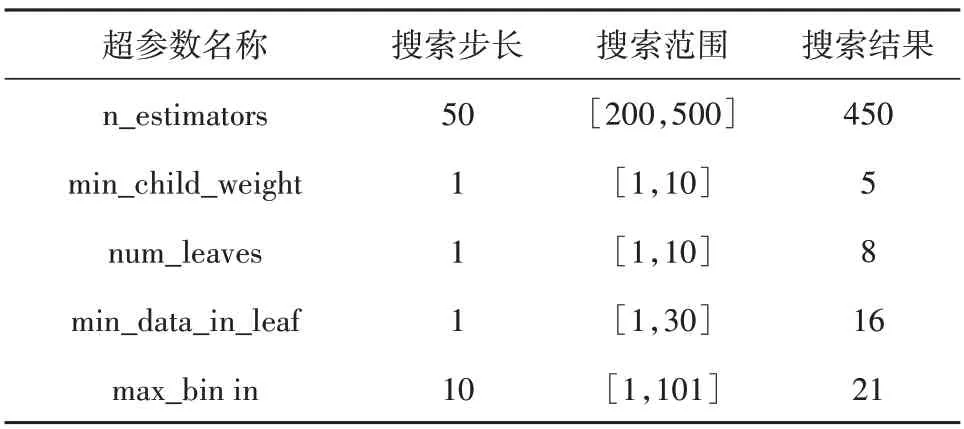
表4 网格搜索法调整超参数Table 4 Grid search for hyper-parameters tuning
如图5 所示,我们展示了不同输入量级下FY-4A Adj 对比验证真值的评估结果。总体而言,随着输入量级的增加,相关系数CC 下降,均方根误差RMSE 波动上升,偏差Bias 轻微下降。这表明,在相似的模型结构和参数设置下,当数据输入量过多时,模型的泛化能力可能会降低。这主要是由于Boosting 算法框架下,模型误差是通过生成和累积决策树来实现的。输入量级的增加可能会导致决策树结构更加复杂,从而产生更多的不确定性。因此,集成模型需要考虑数据输入量以获得更好的效果。这与深度学习要求更多的数据输入相反(Bottou和Bousquet,2007)。
图5中用蓝色标识的部分,是总体表现最好的模型。因此,本研究将使用由221作为分割输入数量级以训练生成的模型。
4.3 订正产品FY-4A Adj的空间分布
图6展示了FY-4A Adj、FY-4A REGC、IMERGEarly 等3 种降水估计产品在中国大陆各区域空间分布表现。可以发现,这3种产品的降水分布趋势大致相似,均能反映出雨季的降水地域性分异特征。其中,IMERG-Early的表现整体更加精细,而FY-4A 系列产品则表现出明显的插值特征。在中国东南部地区,FY-4A REGC和IMERG-Early的降水估计存在明显的差异,FY-4A REGC 相比IMERG-Early有显著的高估现象。在中国西北部地区,两者的表现差异不大。

图6 中国东南部、中国中部、中国东北部、中国西北部各区域上FY-4A Adj,FY-4A REGC,IMERG-Early,FY-4A Adj减去FY-4A REGC的小时平均降水量(时间范围:2019年7月1日至2019年9月30日,即验证集)Fig.6 Southeast China,Central China,Northwest China,Northwest China:Average hourly precipitation of FY-4A Adj,FY-4A REGC,IMERG-Early,FY-4A Adj minus FY-4A REGC in other regions of China(Time range:July 1,2019 to September 30,2019,i.e.based on validation datasets)
由于算法只考虑FY-4A REGC 估计有降水的区域,而降水事件数量远少于非降水事件,因此在平均小时降水尺度上很难反映两套产品的差距。图6 中所示的FY-4A Adj 和FY-4A REGC 降水空间分布较为相似。因此,本研究还提供了FY-4A Adj减去FY-4A REGC 的结果,如图6 所示。可以看出,在与IMERG-Early 的估计有较大分歧的地区,FY-4A Adj几乎都进行了降水量上的调整,使其更接近IMERG-Early。整体而言,FY-4A Adj 进行了许多正向的调整:在中国中部和北部进行了一些上调;而在中国的西部,进行了轻微的下调。在中国的东南部,FY-4A Adj 进行了较大程度的下调,使其更加接近IMERG-Early。
4.4 订正产品FY-4A Adj的地面验证
图7展示了FY-4A Adj、FY-4A REGC、IMERGEarly和CMPA 自动站数据之间的散点关系图。从图7(b)和图7(c)可以看出:在研究时间段内,IMERG-Early和FY-4A REGC估计的小时降水主要分布在0—5 mm,且分布相对均匀,接近45°线。然而,IMERG-Early的表现明显优于FY-4A REGC,因为FY-4A REGC 有更多的数据点分布在接近坐标轴的区域,这意味着CMPA 观测到的降水量较FY-4A REGC 估计的降水量偏移较多。此外,在45°线上,IMERG-Early 有更多的数据点,呈现出“凸型”,而FY-4A REGC 则较为分散,呈现出“凹型”。从精度指标来看,IMERG-Early 的CC 和RMSE 都明显优于FY-4A REGC,这与散点图的结果一致。
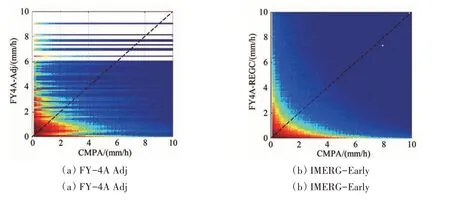
图7 FY-4A Adj、FY-4A REGC、IMERG-Early和CMPA小时降水散点对比及评估结果(2019年7月1日至2019年9月30日,即基于验证集)Fig.7 Scatter comparison and evaluation results of FY-4A Adj、FY-4A REGC、IMERG-Early and CMPA about hourly precipitation(From July 1,2019 to July 30,2019,i.e.based on validation dataset)
图7(a)展示了FY-4A Adj和CMPA自动站数据之间的散点关系图。值得注意的是,经过订正后,更多的数据点集中在45°线上(尤其是在0—2 mm降水区间范围内),这表明本方法对FY-4A REGC的订正在雨强较小时效果显著。
然而,当降水强度超过6 mm时,散点图中出现了部分“断层”。这主要是因为在中、高雨强下,输入的训练样本过少,导致模型会笼统地把一定范围内的输入都映射到同一个标定值附近。因此,需要对中、高雨强的样本进行强化训练。但由于中、高雨强仍然占少数,因此上述因素对订正结果的质量影响有限。从另一方面来看,尽管对中、高雨强的订正仍有明显缺陷,但经本方法订正后的FY-4A 降水数据更接近IMERG-Early的质量,证明了本方法的潜力。此外,整个降水分布出现了一定的“倾斜”现象,说明本算法对整体降水估计进行了调整。这样的调整有利于订正结果,使得FY-4A Adj对于降水总量的估计更加准确(Bias由14.15%降至3.70%,超过IMERG-Early)。
5 结论
本研究提出了一种基于集成学习的快速订正算法,实现了基于地面站点观测的近实时FY-4A卫星反演降水数据的快速校正。经评估分析表明,该方法能够有效且快速地提升FY-4A REGC 的精度,使其达到了全球降水观测计划近实时产品IMERG-Early的数据质量。具体结论如下:
(1)FY-4A Adj 相较于FY-4A REGC,评估指标CC、RMSE 和Bias 值有明显提升,有效降低了FY-4A REGC 在中国南部的显著高估,改善了风云卫星反演降水估计的准确性。
(2)集成学习算法的选取会受到输入数据量级的影响。对于数据量较少的情况,建议使用Bagging 算法,如Random Forest;而对于数据量较大的情况,建议使用Boosting 算法,如LightGBM模型,以兼顾精度和运行时间。
(3)输入训练集数据数量的增加并不一定能够提高集成学习模型的精度。在本研究中,221个样本量是训练模型参数的最佳数量级。
(4)由于缺乏中高雨强的样本数据,本算法对于此类情况的预测存在偏向同一值的问题。在获取更多样本数据后,可以考虑使用强化学习算法对中、高雨强的情况进行训练,以提高模型的准确性。
