基于可解释人工智能的数据安全风险识别研究
2024-04-14贾晓旭
贾晓旭


摘要:在构建以数据驱动为主要学习模式的深度神经网络模型过程中,如何有效辨识数据的安全风险已成为研究中的重要议题。数据安全风险识别面临的“黑盒”挑战,致使其难以被人类现有的认知结构完全理解,并对数据安全风险治理带来诸多影响。在厘清可解释人工智能的基本概念、可解释性是提高识别数据安全风险效率的基础需求、基于数据安全风险沟通的可解释人工智能范式的基础上,探讨可解释性强的深度学习模型和基于表征一致性技术的解释方法在数据安全风险识别中的具体应用。
关键词:XAI;生成式人工智能;深度学习;深度神经網络
一、前言
在新一代信息技术的加持下,数字经济对各国经济发展具有重要意义。根据2022年《全球数字经济白皮书》显示,2021年,全球47个主要经济体数字经济占GDP比重为45.0%,同比提升1个百分点,数字经济在国民经济中的地位稳步提升[1]。由此可见,以数据为核心竞争资源的数字经济正在成为改变社会生产方式、生活方式的关键力量。党的十九届四中全会指出要“健全劳动、资本、土地、知识、技术、管理、数据等生产要素由市场评价贡献、按贡献决定报酬的机制”[2]。作为新的生产要素,数据能够进一步推动社会生产力解放、促使其实现质的飞跃。在人工智能领域,海量的高质量数据被公认为是训练生成式人工智能的核心要件。因此,在构建以数据驱动为主要学习模式的深度神经网络模型过程中,如何有效辨识数据的安全风险已成为研究中的重要议题。
二、数据安全风险识别面临的“黑盒”挑战
现代人工智能技术的“黑盒”性,亦为“黑箱”性,多指深度学习模型内部工作机制的不透明性。与控制理论往往使用微积分和矩阵代数等方法描述由连续变量集合表示的系统等传统研究领域不同,现代人工智能技术并不依赖于具体方法与问题的直接对应关系,而是基于“独立同分布”的统计学假设识别和解决问题。这种特性致使其难以被人类现有的认知结构完全理解,并对数据安全风险治理带来可解释性不足、稳定性不足、隐私保护及合规性不足等具体影响。
(一)深度神经网络的黑盒特性
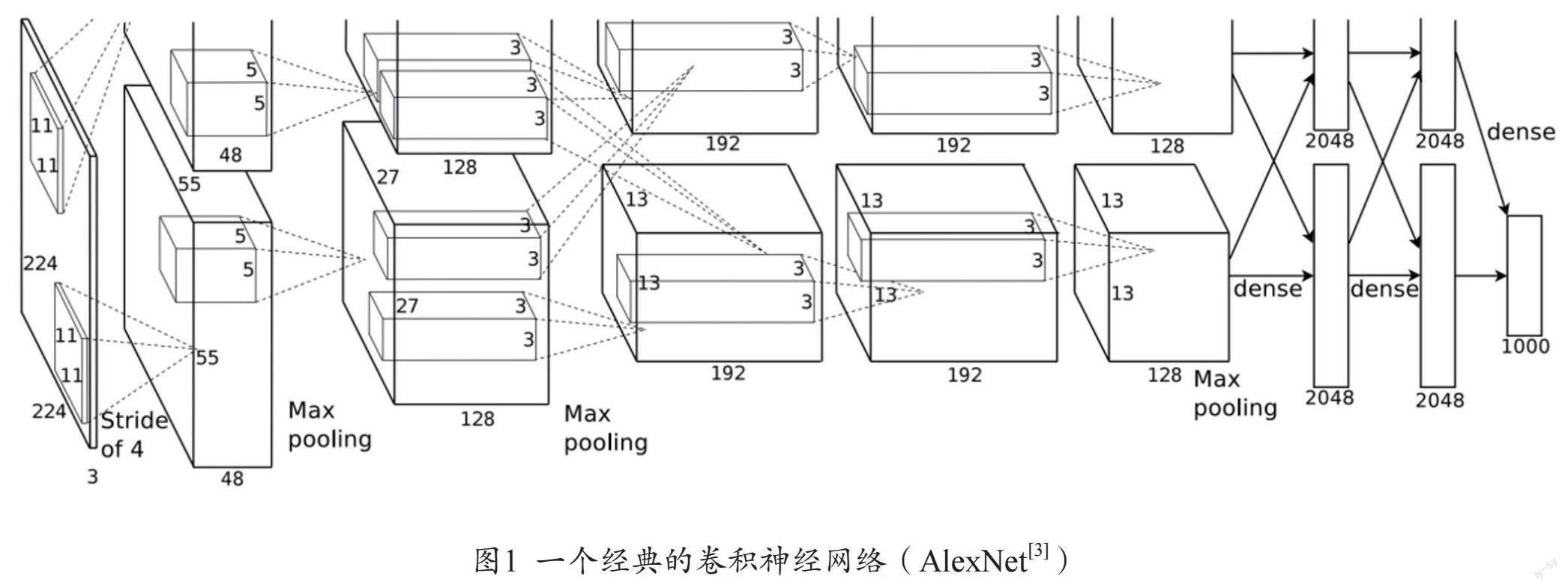
随着可用于训练的海量数据的迅速增长,软硬件一体化协同发展致使算力大幅提升,基于深度神经网络的机器学习模型已经被广泛运用在各领域中。然而,深度学习模型的内部工作方式往往隐藏在数以百万计的参数和复杂的层次结构之中。即使能够知道网络结构形式、权重关联性、激活函数等细节,但并不等同于能够从上述细节中理解网络对此进行输出的理由,特别是与人类的认知结构相一致。以卷积神经网络为例(见图1),作为深度学习领域中最受欢迎的,也是最常见的神经网络结构之一,卷积神经网络被广泛用于计算机视觉任务中。首先,通过卷积核进行图像特征的提取,从而获得输入图像的局部特征。在这一过程中,卷积核选择某一特征或尺度(边缘、纹理)的理由是未知的,这些特征之间存在何种关系与联系,包括其中所蕴含的具体含义都是难以被解释的;其次,为了缩减卷积层提取的特性大小和参数数量,以达到方便计算的目的,需要使用池化层进行特征下采样。尽管这一操作的目的是明确的,但这一输出结果将会对神经网络的全局决策产生何种影响,往往难以解释;最后,使用全连接层进行最终的决策和分类。全连接层通常涉及处理大量的权重和节点,每个节点都基于前一层的输出进行计算。如何从这么多权重中解释单个决策、每个权重对决策的相对重要性,以及节点间的交互,都是困难的。
(二)“黑盒”挑战对数据安全风险识别的影响
随着数据价值的不断提升,社会各界不仅关注如何最大限度地将其激发、激活,对数据进行全生命周期保护的理论研究和现实探索也在与日俱增,如利用隐私保护机器学习使用同态加密、安全多方计算、差分隐私等技术保护数据安全。机密计算利用可信执行环境工具,从系统领域出发,聚焦数据处理中必须经历的计算、存储、传输等关键过程开展研究。机器学习算法的自身脆弱性,使其可能成为安全链中最薄弱的环节。已有研究表明,攻击者可以通过攻击其中的漏洞来破坏整个基础架构,也可以注入恶意数据破坏学习过程,或者在测试时操作数据,利用算法的弱点和盲点逃避检测[4]。仍以卷积神经网络为例,其深层次的内部特征和参数难以被直观解释,导致误差的源头及产生原因在很多时候不易被定位。在此基础上,恶意攻击者可以通过微调输入或投毒攻击,导致该模型在卷积和池化过程中提取错误的特征或丢失重要信息。在风险数据的影响下,当应用模型的计算机视觉系统出现错误的判断时,尽管人类可以发现这一错误的结果,然而却不知从何角度对其进行修正,并对此产生关于未来的深层次忧虑——该系统是否会在未来某个更重要的时刻产生更严重的错误。
三、数据安全风险识别领域中的可解释性分析
在人工智能治理的理论研究与现实实践中,各国政府与相关行业已在立法层面、行业准入层面逐步加强和落实实施。在《阿西洛马人工智能原则》《人工智能北京共识》《经合组织人工智能原则》以及欧盟的《人工智能法案》等比较重要和有影响力的政策文件中,皆在透明度、可问责性、算法偏见、隐私保护与非歧视等领域提出了共同的价值取向。统合上述要求,其最终目的是实现一种能够合理解释其决策机制与过程的人工智能系统,即实现可信任的人工智能。为此,有必要从人工智能模型训练的核心要素——数据出发,探讨模型的可解释性对数据安全风险治理的基本概念和重要意义。
(一)可解释人工智能的基本概念
作为当前人工智能前沿研究领域中的一个火热议题,可解释人工智能(Explainable AI,简称XAI)是指智能体以一种可解释、可理解、人机互动的方式,与人工智能系统的使用者、受影响者、决策者、开发者等达成清晰有效的交流沟通,以获得人类信任,同时满足各类应用场景对智能体决策机制的监管要求[5]。在该语境下,“可解释性”涉及三个重要的概念——解释、理解和信任。首先,“解释”是人与人之间建立联系、形成社会关系的基本方法。智能体也必须通过为其决策提供与人类认知逻辑相一致的描述,最终达到被人类所信任的目的。这一过程不仅涉及对输出结果的解释,也应包含对模型的内部工作机制,特别是对结果产生关键影响部分的解释;其次,“理解”强调了“解释”的效能,即人类对解释内容的消化、把握程度。这不仅能够衡量解释的精确度和完整度,还涉及其直观性和方便性的内在尺度。作为解释与信任之间的途径,“理解”将促使人类与模型之间的交互更加透明,使之能够更加全面地解释模型的行为;最后,“信任”是可解释人工智能的最终目标,即用户、开发者或决策者基于对智能体功能和行为的理解后,愿意信赖并采纳其建议或决策的心理过程。如评估模型是否按照预期的方式工作,是否符合伦理、法律和社会规范等,从而推动人工智能在更广泛领域的应用。
(二)可解释性是提高识别数据安全风险效率的基础需求
数据是人工智能发展的前提与应用的核心。早有研究指出,将数据集的规模增加两到三个数量级所获得的性能提升会超过调整算法带来的性能提升(Banko and Brill,2001)[6]。实践也印证了这一点,以算力为核心的驱动模式正逐渐向以数据为核心的驱动模式转变。从数据安全风险的角度来看,一方面,通过刷题式学习得到的人工智能模型往往存在着一系列被公认的安全风险:算法偏见 、低级错误和欠解释性,致使其很难被大规模地部署和应用,即“AI Safety”问题;另一方面,深度神经网络被人工智能算法所寻找的对抗样本(一种经过精心设计的输入数据)所误导,进而产生错误决策,即“AI Security”问题。而且,在特定的情境下,“AI Security”问题可以发展为“AI Safety”问题。由此可见,从数据要素出发探讨“AI Security”问题,是提高识别人工智能安全风险效率的基础需求。与基于联邦学习、安全多方计算以及可信执行环境等围绕处理数据的关键过程而提出的隐私保护方案与技术不同,基于可解释性的人工智能数据安全风险研究是从模型构建的原则出发,关注确保数据完整性、机密性及代码完整性的解释路径。
(三)基于数据安全风险沟通的可解释人工智能范式
从识别数据安全风险出发,构建可解释的人工智能范式需要参照用户群体的实际需要,设置所提供解释的倾向性与差异性。根据主要不同群体的具体期望与知识背景,分为以下三类:第一,面向开发者的层次。此类用户常具备计算机、数学、统计学或相关学科背景,对数据的处理、存储、传输和加密技术具有深入的了解。他们需要明确模型训练、测试和部署过程中所有潜在的安全隐患和脆弱性,确保训练数据的安全性,避免数据泄露、篡改或非授权访问。识别和防御对抗攻击,确保模型在受到恶意输入时仍然具有稳健性,对于模型中任何不可解释的部分,判断其是否受到了恶意数据的影响;第二,面向使用者、受影响者的层次。此类用户可能对数据安全有基本的理解和关注,更在意人工智能所做出的决策或预测是否符合自身利益。为此,他们需要确信自身提供给人工智能系统的数据是安全的,且不会因非法利用或泄露造成损失。当系统为其提供建议或决策时,希望上述建议没有受到恶意数据的影响。把握人工智能系统使用其个人数据的方式和目的,确保没有违反法律及道德原则;第三,面向决策者的层次。此类用户可能对技术细节不太熟悉,但对国家安全政策、法规和人工智能风险治理有深入了解。在此基础上,他们的工作往往聚焦于从宏观角度评估人工智能系统引入的安全风险和潜在的法律责任,获取关于模型性能和风险指数的未来图景,为做出长远的决策提供依据,确保模型和算法的决策符合所在群体的目标与价值观。图2展现了基于数据安全风险沟通的可解释人工智能的不同层次。
四、可解释人工智能在数据安全风险识别中的应用方法
需要承认,部分机器学习模型本身具备较好的可解释性,根本原因在于其往往是按照可解释性进行建构的。如决策树模型、线性回归模型、朴素贝叶斯、K近邻等算法具有较强的可解释性。然而,当前阶段所广泛应用的大部分深度学习算法是很难被解释的,即算法自身的不可解构性。但是,算法的不可解构性并不等同于完全不能被解释。面对深度神经网络的“黑盒”特性,除了选取可解释强的模型,还可以通过评估两个或多个独立训练的神经网络对相似或相同知识表征的建模程度的方法。
(一)选取可解释性强的深度学习模型
相较于从事后的角度对深度学习模型的决策或预测结果进行非直接阐释,“可解释的神经网络”是以可解释性为学习目标的神经网络,即在从底层向顶层的训练过程中增强模型的可解释性。为实现有效识别数据安全风险的目的,可以采取可解释的卷积神经网络[7]、胶囊网络[8]、神经网络决策树[9]等方法。以可解释的卷积神经网络在图像方面的应用为例,传统的卷积神经网络中的参数是在训练过程中自动生成的,而可解释的卷积神经网络在被设计和训练时,被赋予了特殊设计的卷积核,以便于神经网络学习到的特征是具有明确结构的视觉语义信息,包括不符合常规模式的数据、隐藏信息等风险迹象。再如胶囊网络,由多层表示特定类型的实体属性的神经元组成,其激活向量的幅度表示实体存在的概率,而方向意味着实体的属性。胶囊网络通过引入动态路由机制,将较低层次的胶囊输出发送到适合的高层胶囊,以此捕捉层次化的特征和空间关系。由于胶囊网络能够捕捉不同层次的特征和关联,因此在面对一些常见的攻击(如对抗样本攻击)时具有更高的鲁棒性。更重要的是,胶囊网络的层次化特性使得其能够进行更细粒度的分析,如在入侵检测系统中识别攻击的不同阶段和特点。
(二)基于表征一致性技术的解释方法
运用在深度神经网络中的表征一致性技术在比较和分析同一任务中不同神经网络中层特征的基础上,对表现一致或不一致的特征分量进行识别与提取。例如,通过给定两个独立训练的神经网络A和B,表征一致性技术旨在判断上述两个网络是否具有相同或相似的中层特征表征,即使用A神经网络的中层特征重现B神经网络的中层特征。具体而言,假设ha和hb分别表示神经网络A和B的中层特征,可以通过一个度量两个表征之间一致性的函数寻找误差最小的重现过程:minimize?∥hb-f(ha)∥22。在数据安全风险识别的背景下,需要更关注被识别为不一致的特征,因为不一致的特征可能意味着神经网络被某些特定的数据或噪声误导。例如,攻击者试图通过在训练数据中注入恶意数据干扰网络,表征一致性可以帮助识别这些异常特征。在上述公式的基础上,期望神经网络A和B对正常数据产生相似的中间表示,对于给定的输入x,它们的中间特征表示分别为ha(x)和hb(x),可得出如下公式:Consistency Loss =∥hb(x)-f(ha(x))∥22。其中,f是一个变換,尝试将一个模型的中层特征映射到另一个模型。当该值超过某一阈值时,即可以怀疑数据x可能是风险数据,因为它导致了两个模型的显著差异性。此外,还可以对每个训练样本x引入一个额外的一致性正则项,以鼓励模型在对抗性攻击(如FGSM或PGD)下的中间表示保持一致,即Robustness Loss =∥h(x)-h(x+δ)∥22。其中,δ是一个通常由对抗性攻击生成的、对输入x的小扰动。
五、结语
随着深度神经网络的广泛应用,如何确保数据的安全已经成为学界和业界关注的焦点。从“黑盒”挑战到识别数据安全风险的各种问题,都凸显了可解释性在人工智能研究中的重要意义。本文通过对可解释人工智能的深入剖析,阐明了可解释性是确保数据安全的关键。为了应对“黑盒”挑战,强化模型的可解释性显得尤为关键。一个可以被理解和解释的深度学习模型,意味着可以更加明确地知道模型为什么做出某个决策,进而确保数据安全并及时响应潜在的风险。本文还探讨了如何运用表征一致性技术提高数据安全风险识别的效率,确保数据的完整与安全。
参考文献
[1]中国信息通信研究所.全球数字经济白皮书(2022)[R].http://www.caict.ac.cn/english/research/whitepapers/202303/P020230316619916462600.pdf?eqid=a12c38b10015ecc1000000026488df4e.
[2]中共中央.中共中央关于坚持和完善中国特色社会主义制度 推进国家治理体系和治理能力现代化若干重大問题的决定[M].北京:人民出版社,2019:19.
[3]Krizhevsky A,Sutskever I,Hinton G.E.ImageNet classification with deep convolutional neural networks[J].Communications of the ACM,2017,Vol.60(6):87.
[4]西科斯.基于人工智能方法的网络空间安全[M].北京:机械工业出版社,2021:46.
[5]杨强,范力欣,朱军,等.可解释人工智能导论[M].北京:电子工业出版社,2022:8.
[6]Michele Banko,Eric Brill.Scaling to Very Very Large Corpora for Natural Language Disambiguation [A].Association for Computational Linguistics 39th Annual Meeting and 10th Conference of the European Chapter[C].2001.
[7]Haoyu Liang,Zhihao Ouyang,Yuyuan Zeng,Hang Su,Zihao He,Shu-Tao Xia,Jun Zhu,Bo Zhang.Training Interpretable Convolutional Neural Networks by Differentiating Class-Specific Filters[J].Computer Vision – ECCV 2020,2020,Vol.12347:622-638.
[8]Sara Sabour, Nicholas Frosst, Geoffrey E. Hinton. Dynamic Routing Between Capsules [A]. 31st Conference on Neural Information Processing Systems (NIPS 2017) [C].2017:1-11.
[9]Yongxin Yang, Irene Garcia Morillo, Timothy M. Hospedales. Deep Neural Decision Trees [A]. 2018 ICML Workshop on Human Interpretability in Machine Learning (WHI 2018) [C].2018:34-40.
基金项目:教育部产学合作协同育人项目(课题编号:220505402254146)
作者单位:哈尔滨工业大学应用思想政治教育研究所
责任编辑:尚丹
