基于DWT-Informer模型的水量预测研究
2024-04-14孙杰岳宁冉涂平
孙杰 岳宁 冉涂平

DOI:10.19850/j.cnki.2096-4706.2024.01.034
收稿日期:2023-06-20
摘 要:为准确呈现水消耗的变化趋势以及预测未来的用水需求,提出一种基于DWT-Informer模型的用水量预测方法。与传统方法相比,该预测方法具有以下优势:1)对历史用水量数据进行DWT分解,可以更好地捕捉用水量信号的不同频率成分和变化趋势;2)Informer模型具有更强的时间序列建模能力和预测能力,可以更准确地预测未来日用水量;3)采用多头注意力机制构建输入与输出的全局关系,有利于提升参数水平。通过实际日用水量数据进行算例分析,分析结果表明,相较于其他常用预测方法,该文提出的方法在MAE、RMSE、MAPE等指标上均表现优异。
关键词:用水量;DWT分解;多头注意力;DWT-Informer模型
中图分类号:TP391;TV312 文献标识码:A 文章编号:2096-4706(2024)01-0160-05
Research on Water Consumption Prediction Based on DWT-Informer Model
SUN Jie, YUE Ning, RAN Tuping
(School of Intelligent Technology and Engineering, Chongqing University of Science & Technology, Chongqing 401331, China)
Abstract: To accurately present the trend of water consumption changes and predict future water demand, a water consumption prediction method based on the DWT-Informer model is proposed. Compared with traditional methods, this prediction method has the following advantages: 1) DWT decomposition of historical water consumption data can better capture the different frequency components and changing trends of water consumption signals; 2) The Informer model has stronger time series modeling and prediction capabilities, which can more accurately predict future daily water consumption; 3) Using a multi-headed attention mechanism to construct a global relationship between input and output is beneficial for improving parameter levels. Example analysis is conducted based on actual daily water consumption data, the results show that compared to other commonly used prediction methods, the method proposed in this paper performs excellently in MAE, RMSE, MAPE and other indicators.
Keywords: water consumption; DWT decomposition; multi-headed attention; DWT-Informer model
0 引 言
近年来,随着我国经济的快速发展和人口数量的持续上升,如何更有效地节约资源、保护环境、降低能耗成为社会关注的重要话题。水作为生命必需物质之一,水资源的缺乏直接影响人们的日常生活,也将对社会的可持续发展产生威胁。因此,找到提高供水预测精度的方法对于解决未来城市水资源供需矛盾至关重要。
现有传统预测方法有时间序列法和人工神经网络分析法。时间序列法要求历史数据具有较强的周期性与规律性。人工神经网络分析法能够更好地处理具有复杂非线性关系的数据,具有较好的灵活性和鲁棒性。
然而,关于用水量预测的研究还存在一些问题。首先,在递归神经网络(RNNs)中,后续时间步的预测需要等待前面时间步的计算完成,无法实现并行计算。这种限制在进行反向传播时也会导致梯度计算异常,可能会出现梯度消失或爆炸的情况。其次,在用水量预测中,数据往往会呈现季节性和周期性的变化,而传统的RNNs无法很好地处理这种情况。为了克服这些问题,研究人员提出许多改进的模型。Seo采用VMD对历史用水数据进行分解,得到多个局部频率模态后通过ELM进行训练预测,进而得到最终预测结果。梁现斌提出一种基于SSA-Conv LSTM-LSTM混合模型,该模型融合了空間、时间和特征注意力机制,用于校园短期需水预测,具有较好的泛化性,可提高预测的准确性。运用注意力机制,模型可以更好地捕捉到序列中的重要信息,减少不相关信息的影响。另外,当前用水量预测研究还存在一些挑战。通常,实际应用中的用水量数据具有高维度、非线性和动态性等特征,这对模型的设计和优化提出了更高的要求。
在此背景下,本文提出一种基于DWT-Informer的预测方法,旨在提高长序列预测的精度。建模之前首先基于Person相关系数和Copula非线性分析等手段分析数据特征,然后采用DWT技术提取用水趋势和细节信号,最后通过Infomer模型充分捕获空间和时间依赖性,挖掘与特征序列之间的时序关系,从而实现用水量的预测。这种方法能够提高长序列预测的准确性,具有广泛的应用前景。
1 实验数据
1.1 数据选取
根据文献研究可知,水质和气候是两个可能对用水量变化产生重要影响的因素。李贤雅等研究发现城市水生态系统与水质存在一定的关联性,而针对气候变化对农业用水的影响分析,谢诗猛等采用AquaCrop模型分析结果表明,气候变化对用水量具具有较为显著的影响。此外,丁浩探究了气象因素对灌区农业需水的影响发现,风速、相对湿度、日照等因素均会对市民的用水量产生影响。综上所述,我们将拟采用的特征因子分为两类:水质数据(pH 酸碱度、水硬度、浊度)和气象数据(露点温度、湿度、风速、气压、日照)。
根据以上分析,收集Kaggle公开数据集WaterQuality、DailyClimateTimeSeries上的数据,结合重庆市沙坪坝区某小区10栋居民楼2013年1月1日至2017年1月1日的逐日用水数据,共1 462组,数据采集频率为1天1次,部分缺失数据采用双线性插值进行填补。本次研究针对该小区10栋居民楼所有单元日用水进行分析建模。
1.2 数据分析
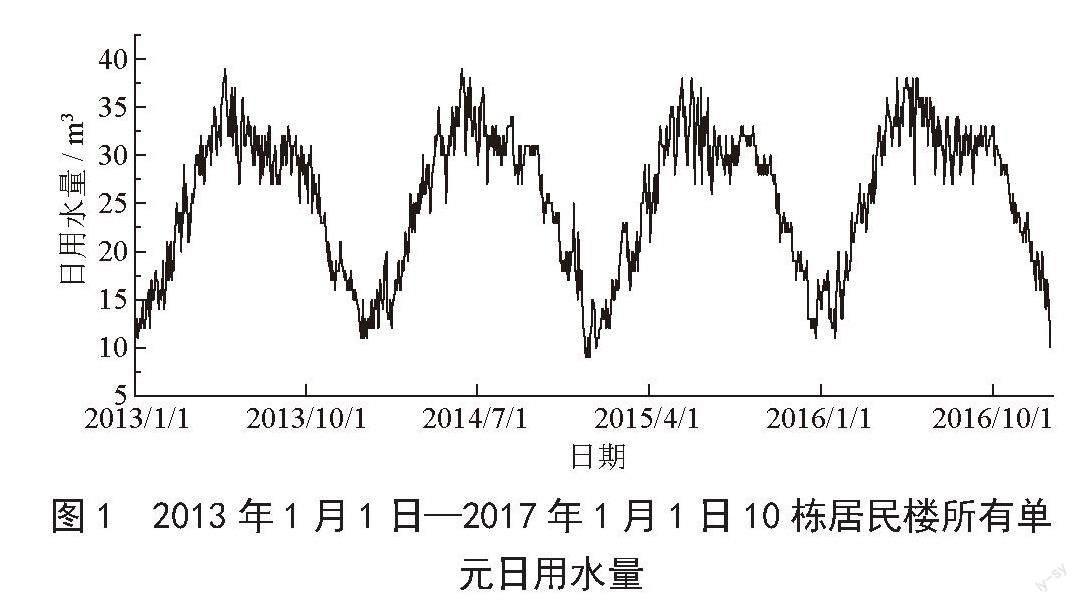
如图1所示,通过对日用水趋势进行分析可知,日用水量变化具有周期性,大致表现为“春冬低、夏秋高”的规律,这种现象表明,在不同的季节和环境下,人们对水资源的需求量存在差异。本文将从线性相关和非线性相关两个角度分析各因素对用水量的影响机理,采用Pearson相关系数分析法和基于Copula理论的相关分析法来研究各因素与用水量之间的关系。
对日用水量与特征因子之间的相关性进行验证分析,计算皮尔逊系数,由此可见日用水量与湿度、风速、pH酸碱度、水硬度呈负相关,与平均压力、日照、浊度、露点温度呈正相关,此外,用水量数据与湿度、平均压力、日照的相关系数绝对值均大于0.2,说明用水量数据与气象数据存在线性关系,如表1所示。
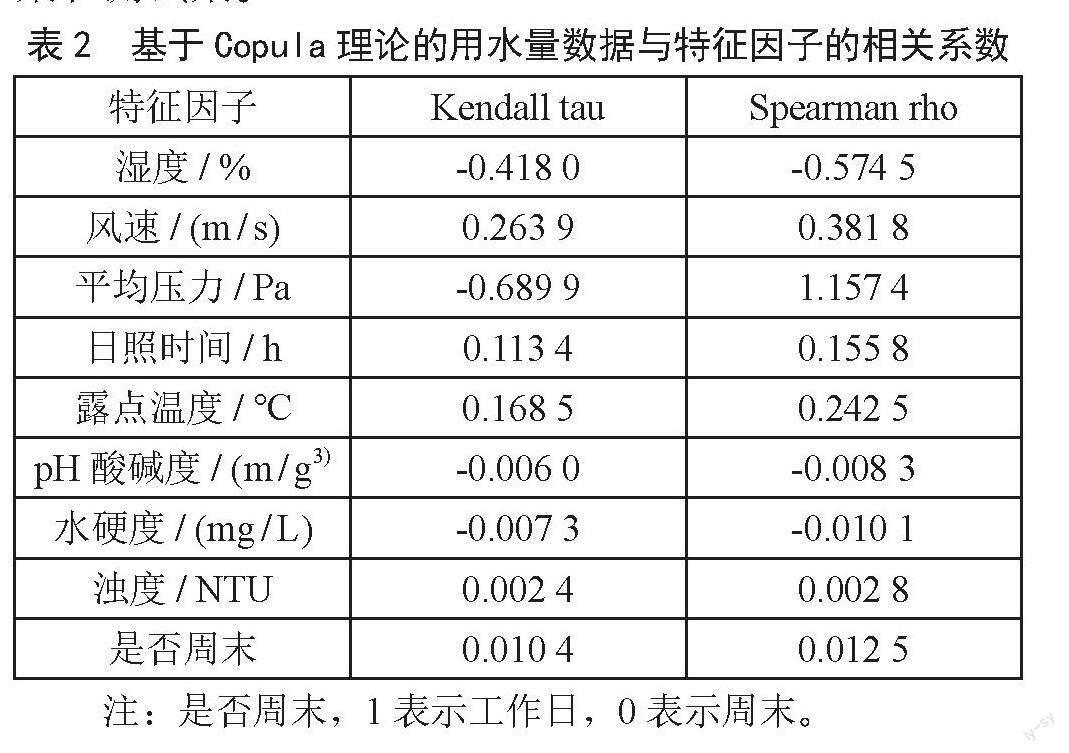
另外,Pearson相关系数分析方法关注的是变量之间的线性相关性,不能描述变量之间的非线性相关性。Copula理论作为一种新兴的相关性分析方法,能够准确捕捉变量之间的非线性特征。为此,采用新兴的相关性分析方法Copula理论结合秩相关系数对用水量与特征因子进行相关性分析。
根据Copula理论采用Kendall tau、Spearman rho导出相关性分析结果,发现用水量数据与气象因子(湿度、风速、平均压力、露点温度)的绝对值均大于0.2,表明用水量数据与其存在非线性关系,结合Person相关系数的分析表明,用水量数据与气候数据同时存在线性与非线性关系。由于气象数据和水质数据与用水量的相关性仅在0.2左右,在此研究中仅作为模型输入参数的辅助,如表2所示。
1.3 数据预处理
在模型训练之前,需要先对数据进行预处理,包括缺失值处理、异常值处理以及数据集划分。首先针对样本数据的缺失值采用双线性插值进行填补后,使用箱线图4分位分析各个特征因子的异常值,将异常值置空后,采用线性插值填补,得到最终的样本数据。再将样本数据按照8:1:1的比例划分为训练集、验证集和测试集。
2 实验原理与方法
2.1 离散小波DWT理论
离散小波变换(DWT)是广泛应用的小波变换(WT)的离散版本。它通过串行数字滤波器计算信号系数,降低了连续小波变换的计算成本。滤波器组由高通滤波器(HP)和低通滤波器(LP)组成,通过对信号进行平移与伸缩实现多尺度细化,捕捉各频率段的信息,适用于非稳定信号分析,计算式如下:
(1)
(2)
其中,S表示输入信号,αg和αh分别表示低通滤波器和高通滤波器,H和L表示滤波器输出结果。高通滤波器的输出结果包含输入信号的细节系数(D),低通滤波器的输出为近似系数(A),通过滤波器的信号下采样2提高频率分辨率。
2.2 Informer算法设计
2021年,美国人工智能协会提出的Informer模型为长时间序列预测提供了解決方案,是一种基于Transformer的改进算法。该算法提出一种概率稀疏自注意力机制、自注意蒸馏,以及带掩码的解码器,在计算复杂度和时间复杂度方面得到了有效的提升。
2.2.1 Informer模型的输入输出
t时刻的Informer模型输入为xt = {x1t,x2t,…,x9t},包括气候数据、水质数据、独热编码后的周末数据以及日用水量数据。模型输出为DWT分解后的序列信号X t = {K1t,K2t,…,K6t}。
2.2.2 Encoder-Decoder结构
编码器Encoder的目的是解决计算复杂度高的问题,Informer编码器针对输入序列使用概率稀疏自注意力机制,其计算流程可以由式(3)表示:
(3)
其中,Q、K和V分别表示输入特征变量经过线性变换得到的三个大小相同的矩阵,T表示矩阵转置,d表示输入的维度。在这个模型中使用Softmax作为激活函数,它可以将一个数值向量转化为一个概率分布向量,使得每个元素都在0和1之间,并且所有元素之和等于1。采用自注意力蒸馏操作,使用一维卷积和最大池化减少冗余特征,修剪输入序列维度。蒸馏操作从第j层至第j+1层如式(4)所示:
(4)
其中,[AB]表示注意力块及其他必要操作;Conv1d使用ELU激活函数执行一维卷积滤波;该机制下每层编码器输入时间序列长度减半,减少内存占用,提升计算速度。
解码器Decoder的目的是预测长序列的输出,为避免预测过程中的过拟合现象,采用默认为0多头注意力机制,使用生成式预测直接预测多步预测结果,其解码器输入格式如式(5)所示:
(5)
其中,Xtoken表示开始字符,X0表示占位符,Concat表示将Xtoken与X0合并连接。
最后,通过1个全连接层获取最终的信号分解后各频段的预测值,进行求和重构得到最终的日用水量预测结果。
3 基于DWT-Informer算法的水量预测模型
针对日用水量数据,使用DWT降低原始特征序列的复杂度,多尺度分解出不同频段的特征,发挥不同算法的优势,以更加完整地凸显波动趋势,加入水质数据、气候数据作为特征因子后使用Informer捕捉长序列的变化规律,预测窗口长度选择24,即每次輸入24天的用水序列矩阵,预测未来日用水量。本文设计了基于WD-Informer算法的用水量组合预测模型,具体步骤如下:
1)收集历史用水量数据及外部影响因子(采集频率为1天1次),并对它们进行预处理,针对缺失的数据,取前后两个数据的平均值进行填补,周末情况数据使用独热编码(1表示工作日,0表示周末),最终得到数据样本。
2)对日用水量数据进行DWT分解,采用DB6小波基函数对数据进行5层离散小波分解得到数个趋势分量和细节分量,原始信号x可以通过各分量的信号累加得到,计算式为:
(6)
其中,a5表示最低尺度的近似系数,di表示第i层的高频系数,二者相加得到原始信号x。
3)将与气候数据、水质数据、日用水量数据整合后得到的特征因子作为模型输入,将2)中分解后得到的日用水量数据作为模型标签。每次训练的预测结果为K1,K2,…,Ki。
4)调整Informer中的超参数,进行训练,建立模型。
5)对3)中的预测结果求和重构,得到日用水量的最终预测结果X:
(7)
4 算例分析
4.1 评价指标
本文主要采用三个指标(分别为MAE、RMSE、MAPE)来评价模型的性能,三个指标的计算式为:
(8)
其中,WMAE表示日用水量数据的平均绝对误差,WRMSE表示均方根误差,WMAPE表示平均绝对百分比误差,N表示测试样本的数量,ytrue表示日用水量数据的真实值,ypred表示求和重构后的日用水量预测值。
4.2 对比实验
从超参数敏感性分析、预测性能结果分析两个方面进行对比实验。
4.2.1 超参数敏感性分析
Informer模型的encoder输入长度和decoder先验序列长度对模型性能有影响。较长的序列可以更好地捕捉时间序列的依赖关系和周期性趋势,但可能会增加计算成本并导致过拟合现象。在设计模型时,需要根据任务和数据特征选择适当的长度。由表3可以看出,encoder输入序列长度为24、decoder先验长度为12时,各评价指标均最小。Informer的其他超参数设定如表4所示。
4.2.2 预测性能结果分析
加入GRU、BIGRU深度学习网络,对未来1天该栋日用水量预测结果如图2所示。可以看出:Informer相比于其他模型,预测值可以很好地贴合真实值,有效捕捉日用水量的突变。从表5中各模型数值可以看出,Informer模型相较于其他模型,MAE、RMSE、MAPE的值均有所减小,表明本文模型运算效率较高,预测值与真实值之间的误差较小,离散程度较小,预测效果更好。同时表明合理选择输入序列长度和decoder先验长度可以显著提高日用水量预测效果。
三种模型对未来14天(2016年12月17日—30日)日用水量预测结果如图3(a)所示,相较预测一天的预测较差点,均出现不同程度的偏差,但Informer仍优于GRU和BIGRU,说明Informer在长序列预测上的效果更佳。
5 结 论
本文通过DWT分解和Informer模型对小区10栋居民楼日用水量进行分析,经多次验证,得出以下结论:
1)将历史一维日用水量数据进行DB6,5层小波分解转换为高维数据,可以更好地表征用水特点及趋势,降低高频信号的波动率及随机性,提升模型的预测效果。
2)本文提出使用DWT分解用水量数据结合采用多头注意力机制的Informer模型,构建输入与输出的全局关系,提升参数特征水平,最大限度提升预测性能和拟合效果。
3)本文针对未来不同天数进行预测,结果表明Informer在长跨度预测上的预测性能更优,可行性较高。
本文提出的DWT-Informer日用水量预测能够预测未来的用水情况,可用于水资源调度以节省成本,此外还可以考虑将该模型应用于其他水资源管理任务(如水质预测或水位预测等),据以提高水资源管理的精准度和可靠性。
参考文献:
[1] SEO Y,KWON S,CHOI Y. Short-term water demand forecasting model combining variational mode decomposition and extreme learning machine [J].Hydrology,2018,5(4):54.
[2] LI Y G,YANG W X,SHEN X J,et al. Water environment management and performance evaluation in central China: A research based on comprehensive evaluation system [J].Water,2019,11(12):2472.
[3] 李贤雅,陶佳音,李非凡,等.基于PSR模型的城市水生态韧性评价——以武汉市为例 [C]//2022/2023中国城市规划年会.武汉:[出版者不详],2023:1-15.
[4] 谢诗猛,刘登峰,刘慧,等.气候变化影响下澜湄流域下游水稻生产用水量模拟与分析 [J/OL].人民珠江:1-35[2023-
05-20].http://kns.cnki.net/kcms/detail/44.1037.TV.20231211.1537.
002.html.
[5] 丁浩.气候变化条件下宝鸡峡灌区主要作物需水量时空演变及节水潜力分析 [D].咸阳:西北农林科技大学,2017.
[6] 梁现斌.基于SSA-ConvLSTM-LSTM短期需水预测的智慧校园节水系统研究与应用 [D]. 邯郸:河北工程大学,2022.
[7] 王冠智,粟晓玲,张特,等.基于DWT-WFGM(1,1)-ARMA组合模型的农业用水量预测 [J].灌溉排水学报,2021,40(11):106-114.
[8] ZHOU H Y,ZHANG S H Y,PENG J Q,et al. Informer: Beyond efficient transformer for long sequence time-series forecasting [C]//Proceedings of the AAAI conference on artificial intelligence.[S.l]:AAAI Press,2021:11106-11115.
[9] 曾婧婧,黄桂花.科技项目揭榜挂帅制度:运行机制与关键症结 [J].科学学研究,2021,39(12):2191-2200+2252.
[10] 吴正新.如何构建政府采购信用体系 [J].中国招标,2021,1460(4):33-36.
作者简介:孙杰(1998—),男,汉族,江苏盐城人,硕士研究生在读,主要研究方向:智慧安全。
