关于Word2Vec文本分类效果若干影响因素的分析
2024-04-14谢庆恒
DOI:10.19850/j.cnki.2096-4706.2024.01.026
收稿日期:2023-03-21
摘 要:Word2Vec向量模型参数众多,在不同情景下分类效果不一,分析其影响因素很有必要。从Word2Vec模型基本原理出发,分析讨论了预训练语料、词向量预训练参数以及分类模型参数三大因素对模型分类效果的影响。结果表明限定域预料效果好于广域预料;预训练参数中向量维度越大,效果越好,窗口大小存在最优值,分类算法影响不大;分类模型参数中学习率、激活函数、批次大小对模型分类效果影响较大,训练轮次相对较小。
关键词:Word2Vec;文本分类;模型效果;影响因素
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2024)01-0125-05
Analysis of Several Influencing Factors on Word2Vec Text Classification Effect
XIE Qingheng
(National Library of China, Beijing 100081, China)
Abstract: The Word2Vec vector model has numerous parameters, and its classification effect varies in different scenarios. It is necessary to analyze its influencing factors. Starting from the basic principles of the Word2Vec model, this paper analyzes and discusses the impact of three major factors of pre trained corpus, pre trained parameters of word vectors, and classification model parameters on the model's classification effect. The results indicate that the effect of limited domain prediction is better than that of wide domain prediction. And the larger the vector dimension in the pre trained parameters, the better the effect. There is an optimal value in window size, and the classification algorithm has little impact. The learning rate, activation function and batch size of the classification model parameters have a greater impact on the classification effect of the model, and the training round is relatively small.
Keywords: Word2Vec; text classification; model effect; influencing factor
0 引 言
文本分類是自然语言处理领域的经典问题,2003年Bengio提出的NNLM[1]是早期使用神经网络实现语言模型的经典模型。2013年,Word2Vec模型[2]借鉴NNLM的思想,提出用语言模型训练得到词向量。尽管GPT2、BERT、XLNet等深度学习神经网络模型在分类效果上取得了突破性进展,但这些模型的预训练对硬件要求较高,一般用户难以承受。相对而言,Word2Vec模型对硬件要求不高,并且在近义词分析,相近词的关联分析中仍有不错的表现,因此Word2Vec模型至今仍在大量使用。有的学者关注Word2Vec词向量的优化与改进。张克君等[3]从训练词向量的语言模型入手,提出了一种基于关键词改进的语言模型,在查准率和相似度方面有一定优化。彭俊利等[4]通过融合单词贡献度与Word2Vec词向量提出一种新的文档表示方法,使得模型的准确率、召回率和F1值均有所提升;有的关注其与其他模型的结合使用。唐焕玲等[5]针对文本表示中的语义缺失问题,基于LDA主题模型和Word2vec模型,提出一种新的文本语义增强方法,较其他经典模型效果均有所改善。席笑文等[6]针对传统LDA主题模型忽略专利文本上下文间语义关联的问题,提出了基于word2vec和LDA主题模型的技术相似性可视化研究方法,实验证明了该模型在技术相似性测度分析中具有较好的效果;有的则基于Word2Vec词向量探讨行业应用问题,开拓模型的应用场景。周丰等[7]基于Word2Vec大数据语义分析工具,通过大数据分析各种瓶装水的评论信息,挖掘其深层印象,从而指导瓶装水的设计实践。谢爽等[8]针对体检数据中文本型数据特征提取问题,提出利用Word2vec和卷积神经网络相结合的方法对数据中的文本特征进行特征提取,建立高血压和高血脂疾病的预测模型。可见Word2Vec模型在自然语言处理领域仍有自身优势和存在价值。然而,Word2Vec模型参数较多,在不同场合表现出的效果差异较大,到底哪些因素影响了模型分类效果?是如何影响的?影响有多大?如何改进提升模型效果?带着这些问题,本文将从模型原理出发,通过数据分析实验找出模型分类效果的影响因素,以期为模型的后期使用提升提供一些参考。
1 模型原理
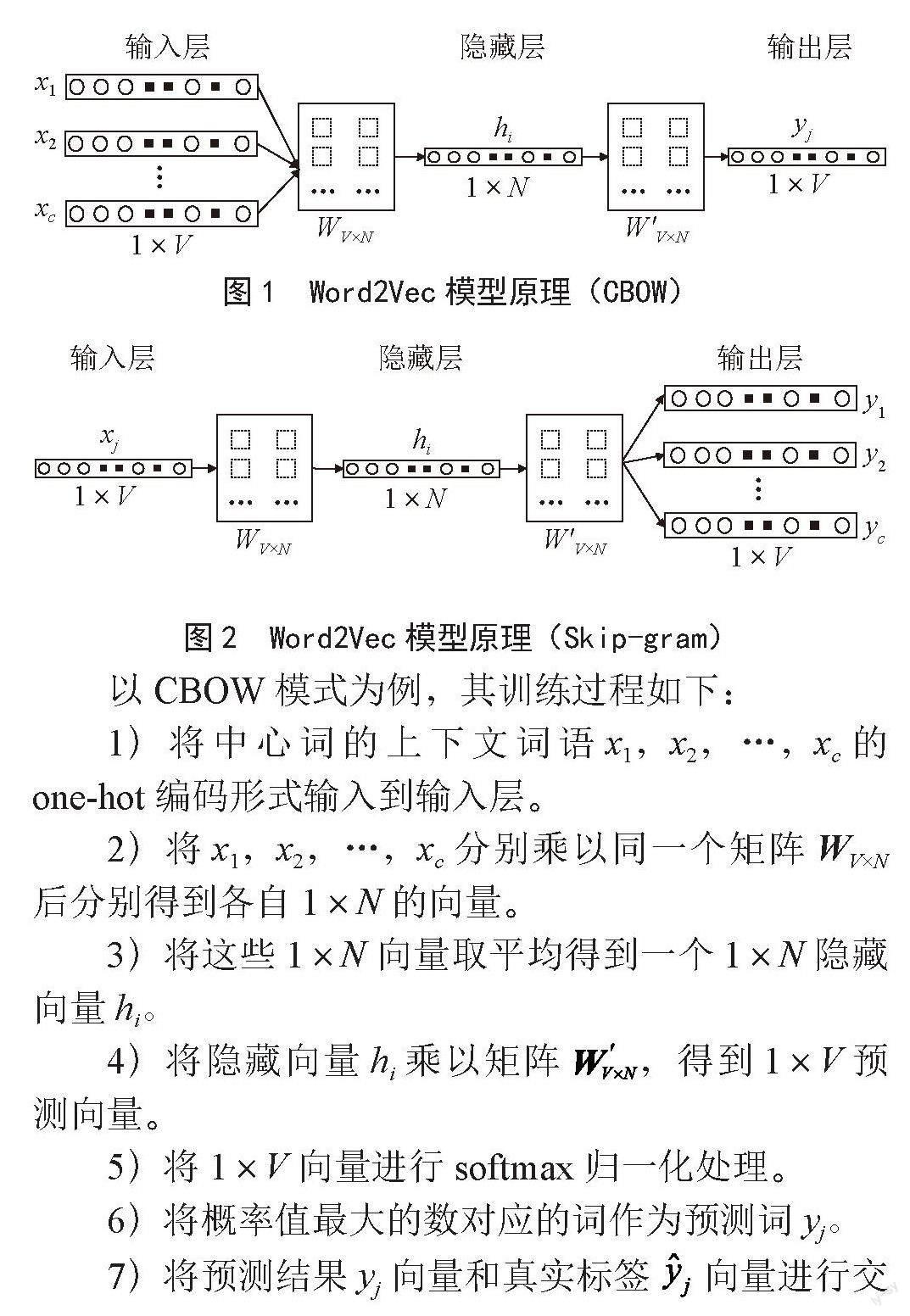
Word2Vec是由Google的Mikolov等[2]人提出的一个词向量计算模型。基本模式是输入大量已分词的文本,输出稠密表示的词向量。词向量的重要意义在于将自然语言转换成了计算机能够理解的向量。词向量就是用来将语言中的词进行数学化的一种方式,顾名思义,词向量就是把一个词表示成一个向量,One-Hot编码和分布式编码是其常见的两种编码方式。相对于词袋模型、TF-IDF等模型,词向量能抓住词的上下文、语义,衡量词与词的相似性,在文本分类、情感分析等许多自然语言处理领域有重要作用。由于One-Hot编码存在维度灾难、词汇鸿沟、强稀疏性等缺陷,Word2Vec主要采用分布式编码方式。Word2Vec是轻量级的神经网络,主要包括CBOW(图1)和Skip-gram(图2)两种模式,它们的最大区别是Skip-gram是通过中心词去预测中心词周围的词,而CBOW是通过周围的词去预测中心词,二者本质上区别不大。
以CBOW模式為例,其训练过程如下:
1)将中心词的上下文词语x1,x2,…,xc的one-hot编码形式输入到输入层。
2)将x1,x2,…,xc分别乘以同一个矩阵WV×N后分别得到各自1×N的向量。
3)将这些1×N向量取平均得到一个1×N隐藏向量hi。
4)将隐藏向量hi乘以矩阵 ,得到1×V预测向量。
5)将1×V向量进行softmax归一化处理。
6)将概率值最大的数对应的词作为预测词yj。
7)将预测结果yj向量和真实标签 向量进行交叉熵误差计算。
8)在每次前向传播之后反向传播误差,不断更新调整WV×N和 矩阵的值直至误差达到预先设定的某个值。
训练结束后WV×N权重矩阵就是词向量的集合,每行对应一个词向量。比如第n个词对应WV×N中的第n行,这样,就把词向量从V维的稀疏向量表示转换成N维的稠密向量表示,便于后续进一步的处理计算。
2 影响因素
2.1 数据来源
2.1.1 语料数据
百度百科中文数据来自互联网公开数据,文件大小1.42 GB,涵盖科技、音乐、医学、文学等社会各方面的各类数据共计4 410 426条;R73类摘要数据来自万方在线学位论文数据库。具体处理过程是,采集万方官网学位论文栏目下近十年来中图分类号为R733.7、R734.2、R735.1、R735.2、R735.3、R735.7、R737.1、R737.3、R737.9的9类学位论文摘要数据,每类5 000条,共45 000条;同样的,S5类摘要数据也来自万方在线学位论文数据库,采集万方官网学位论文栏目下近十年来中图分类号S511、S512、S513、S52、S53、S54、S562、S565.1、S565.2、S566、S567的11类论文摘要数据共32 118条。
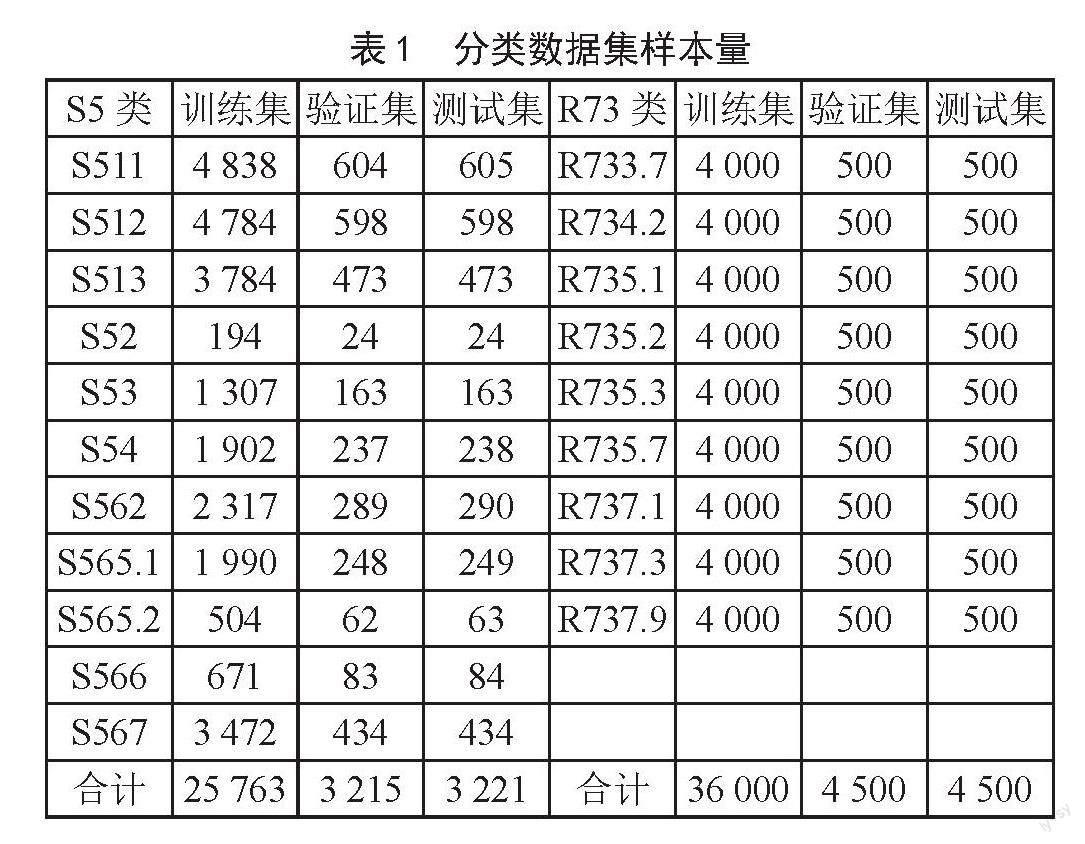
2.1.2 分类数据
分类数据来自万方在线学位论文数据库,如表1所示。其中R73类标题数据采集万方官网学位论文栏目下近十年来中图分类号为R733.7、R734.2、R735.1、R735.2、R735.3、R735.7、R737.1、R737.3、R737.9的9类学位论文标题数据。去除纯英文标题样本,有多分类号的论文数据则确保只使用一次,经过数据清洗去重后,筛选出每类5 000条数据,并从中分别随机抽取10%作为验证数据,10%作为评价数据。故训练样本集共9类36 000条数据,评价样本集为9类4 500条数据,验证样本集为9类4 500条数据,并且各数据集之间不存在任何重复。同样地,S5类标题数据采集自万方官网学位论文栏目下近十年来中图分类号S511、S512、S513、S52、S53、S54、S562、S565.1、S565.2、S566、S567的11类学位论文标题数据,经过删除纯英文标题样本、清洗去重、确保多分类号的论文数据只使用一次等处理之后,得到非平衡数据样本总量32 199条,其中样本量最大的为S511类共6 047条,最小的为S52类共242条,同样按照8:1:1的比例随机划分为训练集(25 763条)、验证集(3 215条)和测试集(3 221条)。
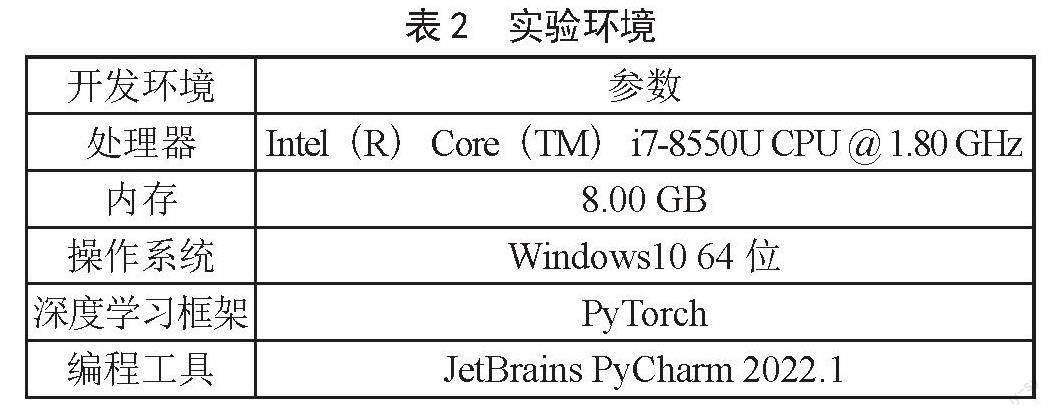
2.2 实验环境
由于PyTorch在易用性与速度方面较优,因此本文采用PyTorch搭建深度学习框架,实验环境如表2所示。
2.3 预训练语料
分别选取百度百科中文数据、R73类摘要数据和S5类摘要数据作为预训练语料,词向量训练模型参数设置为:向量维数300,其他均采用gensim模块中Word2Vec的默认参数设置;分类模型采用softmax线性分类器,将分类样本词向量(即基于词向量模型的学位论文标题数据)直接输入到线性分类器中得到分类结果,参数dropout率设置为0.5,损失函数采用交叉熵函数。
运行结果如表3所示,R73类中基于百度百科问答资料训练语料的词向量特征的分类F1值比基于R73类肿瘤学摘要数据训练语料得到的词向量的分类F1值低10.02个百分点,后者分类效果显著高于前者,表明基于限定域语料预训练的词向量表示的文本特征效果优于广域语料;从S5类的分类结果也可得出同样结论,基于S5类摘要数据语料的分类结果比基于百度百科语料的分类结果高出11.16个百分点。由此可见,预训练语料在很大程度上影响了Word2Vec模型的词向量训练效果,选取预训练语料对于Word2Vec模型分类至关重要。限定领域语料相对于广域语料针对性更强,关注点更聚焦,训练出的词向量在限定领域的表征能力更强,从而使得模型分类效果更好。表3显示基于R73类摘要数据的模型分类效果最佳,故下文的实验数据集采用R73类数据集,包括摘要数据和标题分类数据。
2.4 词向量预训练参数
Gensim中Word2Vec模型参数主要包括词向量维度、窗口大小、算法选择、是否采用负采样、词向量最小词频、最大迭代次数等。前三个是比较重要的参数,如表4所示。词向量维度表示词向量的表达空间大小,维度越大,对文本的表征能力就越强。窗口大小表示词向量上下文的最大距离,窗口越大,则与该词产生上下文关系的词的范围就越广。算法包括CBOW和Skip-gram两种,主要区别在于前者是用周围词去预测中心词,后者是用中心词去预测周围词。默认参数为:词向量维度为300,窗口大小为5,算法为CBOW。
1)分别设置词向量维度参数为100、200、300进行实验(其他参数设为默认),结果表明300维分类结果高出200维0.65个百分点,高出100维5.28个百分点,可见维度越大,分类效果越好;
2)分别设置窗口大小为4、5、6、7进行实验(其他参数设为默认),结果表明窗口大小对分类效果的影响呈现倒“U”型,窗口大小设为6时分类效果最优,达到96.81%,可见窗口大小设置存在一个最优值;
3)分别设置算法参数分别为0(CBOW)和1(Skip-gram),其他参数设为默认,实验结果表明CBOW算法效果略优于Skip-gram,效果几乎相当。
2.5 分类模型参数
1)分别设置学习率参数为0.000 01、0.000 1、0.001、0.002、0.005、0.008、0.01、0.1、0.15、0.2、0.25,选取300维词向量模型,训练轮次为3,批次大小为128,采用Softmax线性分类器,结果表明(图3),F1值在0.000 01时最小为0.145 3,0.000 1处陡增至0.763 8,在0.001处再次增至0.929 3,之后平缓增加,直至0.008处达到最大值0.938 1,之后保持在最大值附近上下微小波动,说明学习率的选取对模型分类效果影响较大。学习率主要影响损失函数后向传播中对权重系数的更新(式(1))。学习率lr过小则可能出现权重系数w′更新不充分,使模型陷入局部最优陷阱,找不到全局最优解。图4显示学习率在0.12时模型具有较好的收敛性。
(1)
2)分别设置激活函数为ReLU、Sigmoid、Tanh,选取300维词向量,学习率设为0.12,训练轮数为3,批次大小为128进行实验,结果(表5)显示Tanh激活函数的F1值最高为93.51%,其次是Sigmoid的93.27,最小是ReLU的91.57%,表明Tanh为激活函数分类效果最佳,优于在大多数任务中表现突出的ReLU函数。这也说明激活函数的选取需要根据特定任务进行调整,并非一成不变,需要具体问题具体分析。
3)设置批次大小分别为50、60、80、100、140、160、180,选取300维词向量,学习率设为0.12,训练轮数为3进行实验,结果(图5)显示F1值呈现双波峰形态,在80和160处取到波峰值,在50、128、180处取得波谷值,表明批次大小并非越大越好,也并非越小越好,而是存在一个中间值使模型效果最优。批次大小表示每批数据量的大小,决定了每次迭代用来更新模型权重的数据样本量,值越小,随机性越大,越便于模型寻找全局最优,但缺点是模型不易收敛;值越大,越能够表征全体数据的特征,其确定的梯度下降方向越准确,且迭代次数少,总体速度更快,缺点是相对来讲缺乏随机性,容易使梯度始终向单一方向下降,陷入局部最优。
4)设置训练轮次分别为3、4、5、6、7、8,选取300维词向量,学习率设为0.12,批次大小128,softmax作为分类器,损失函数为交叉熵函数。结果(图6)显示F1值呈现“锯齿”形态,在3处取到最小值93.48%,在6处取得最大值94.06%,整体是呈上升趋势。表明在一定范围内,训练轮数越大,模型效果越好,但模型整体效果相差不大,考慮到时间经济性,选取较小轮数比较合适。
3 结 论
本文讨论了影响Word2Vec文本分类效果的3大主要因素,即预训练语料、词向量预训练参数以及分类模型参数,得出以下结论:
1)相对于广域预训练语料,限定域(专业领域)预训练语料针对性更强、关注点更聚焦,因此基于限定域训练得到的词向量表征能力更强,能更准确的表达文本语义,语料的选取对模型分类效果影响较大。
2)词向量预训练参数中向量维度越大,表征能力越强,分类效果越好;窗口大小则呈现到“U”型影响效果,即存在一个最优窗口使得向量表达效果最佳,可见窗口大小选择对模型效果影响较大;而分类算法在本实验中则表现出几乎相当的效果,算法选取对模型分类效果影响不大。
3)分类模型参数中学习率对模型效果的影响存在突变现象,可见学习率选取对模型影响较大;不同激活函数在分类效果是存在差异,本实验中Tanh函数效果最佳,优于在大多数任务中表现突出的ReLU函数,说明激活函数的选取需要根据特定任务进行调整,并非一成不变,需要具体问题具体分析;批次大小对模型效果的影响呈现双波峰形态,即批次大小不宜过大过小,需合理选取,说明批次大小对模型分类效果影响较大;训练轮次对模型的影响则呈“锯齿”状缓慢上升,但整体差异较小,考虑到时间经济性,选取较小轮数比较合适,也说明训练轮次对模型分类效果影响不大。
参考文献:
[1] BENGIO Y ,DUCHARME R,VINCENT P,et al. A Neural Probabilistic Language Models [J]. Journal of Machine Learning Research ,2003,3:1137-1155.
[2] MIKOLOV T,CHEN K,CORRADO G,et al. Efficient Estimation of Word Representations in Vector Space [J/OL].arXiv: 1301.3781 [cs.CL].(2023-01-16).https://arxiv.org/abs/1301.3781.
[3] 张克君,史泰猛,李伟男,等.基于统计语言模型改进的Word2Vec优化策略研究 [J].中文信息学报,2019,33(7):11-19.
[4] 彭俊利,谷雨,张震,等.融合单词贡献度与Word2Vec词向量的文档表示 [J].计算机工程,2021,47(4):62-67.
[5] 唐焕玲,卫红敏,王育林,等.结合LDA与Word2vec的文本语义增强方法 [J].计算机工程与应用,2022,58(13):135-145.
[6] 席笑文,郭颖,宋欣娜,等.基于word2vec与LDA主题模型的技术相似性可视化研究 [J].情报学报,2021,40(9):974-983.
[7] 周丰,殷丽丽,沈琼,等.基于word2vec的瓶装水线上评论智能分析 [J].包装工程,2022,43(S1):48-55.
[8] 谢爽,范会敏.基于Word2vec和卷积神经网络特征提取的双高疾病预测 [J].计算机应用与软件,2021,38(2):93-96+125.
作者简介:谢庆恒(1988—),男,汉族,江西丰城人,馆员,硕士,研究方向:文献编目。
