机器学习算法构建慢性肾脏病伴高血压或糖尿病的预测模型
2024-04-11曾慧娟袁红伶李冠羲茹国佳
曾慧娟 ,田 波 ,袁红伶 ,何 杰 ,李冠羲 ,茹国佳 ,许 敏 ,詹 东
(1)昆明医科大学第一附属医院肾脏内二科,云南 昆明 650032;2)云南省第一人民医院科研科,云南 昆明 650034;3)昆明医科大学基础医学院,云南 昆明 650500)
慢性肾脏病(chronic kidney disease,CKD)早期发现和诊断较为困难,随疾病不断进展,最后成为终末期肾脏病而使肾功能衰竭[1]。若能早期识别、发现CKD 并准确诊断,便可及早干预和治疗[2]。全球约5%~7%的人口患有中等程度CKD,其主要病因为糖尿病和高血压,尤其发展中国家、贫困地区、少数民族人群中慢性肾病发病率更高[3-4]。此外,CKD 患者治疗费用昂贵,给家庭带来沉重经济压力、给医疗保障带来沉重社会负担,已成为一个世界性公共健康问题[5]。然而,CKD 的诊断基于回顾性数据,起病隐匿、症状不明显,难以早期发现,延迟治疗和干预会增加肾衰竭可能[6]。本研究结合社区问卷调查、基本资料、实验室检查、PVT1 基因多态性等多领域交叉,采用4 种机器学习算法构建CKD 预测模型,辅助医生、患者及家人早识别,为评估提供参照、为诊断提供参考。
1 对象与方法
1.1 一般资料
随机抽样4 个昆明市区域中的1 个社区卫生服务中心建档居民。于2019 年11 月至2023 年11 间招募CKD 患者256 例和健康志愿者1 577 例。CKD 纳入标准:(1)CKD 诊断符合《慢性肾脏病早期筛查、诊断及防治指南》[7];(2)患有血尿、蛋白尿、水肿、高血压或肾功能异常等临床表现伴有肾小球滤过率或肾组织学异常、肾脏影像学异常,病程持续3 个月以上;(3)年满18周岁及以上居民;(4)诊断明确的2 型糖尿病患者,且至少6 个月以上或已建立慢性病健康管理档案;(5)诊断明确的高血压病患者,且至少6 个月以上或已建立慢性病健康管理档案。排除标准:(1)患有其他系统疾病或脏器功能异常者;(2)患有恶性肿瘤者;(3)精神疾病患者;(4)妊娠及哺乳期女性患者。本研究获得昆明医科大学第一附属医院医学伦理委员会批准[(2022)伦审L 第264 号],研究人员严格遵照《赫尔辛基宣言》实施。
1.2 研究方法
(1)问卷调查:内容包括一般人口学资料,13 条目患者积极度量表测量(PAM13)[8],居民个人生活习惯调查(饮食、睡眠、烟酒摄入等)。调查员培训后上岗,调查员与患者一对一完成问卷。(2)体格检查:调查员行身高、体重、腰围、臀围等测量。(3)实验室检查:收集志愿者尿液行尿常规、肾功能、随机尿微量白蛋白测定等检查;抽取外周血提取DNA 进行人浆细胞瘤变异易位基因(PVT1)基因进行单核苷酸多态位点(rs1499368、rs1121947/rs2608030、rs11993333、rs2720659 和rs2720660)检测。(4)构建预测模型:采用Logistic 回归对变量进行筛选。变量被随机分为训练集和测试集,分别占全体数据2/3 和1/3,用于建立预测模型和评价预测模型。归一化处理,二分类变量取值0 或1,计量资料变量值取值范围为0~1 之间。分类变量因素不存在赋值0,存在赋值1。使用R 软件工具包(e1071,caret,nnet 和Neural NetTools)构建基于支持向量机(SVM)、随机森林(RF)、朴素贝叶斯(N B)和人工神经网络(ANN)算法的CKD 预测模型。依据构建的CKD预测模型计算结果对检测集数据进行对比分析,评价指标包括灵敏度、特异度、准确率、原错率、Kappa 系数、阳性预测值、阴性预测值等。Kappa 系数用于评价模型预测值和真实值间的一致性。若Kappa 系数≤0.2 则认为一致性极低;若0.2
1.3 统计学处理
采用R 软件(版本4.1.3)处理数据。符合正态分布且方差齐的计量资料,行Student’s T 检验;不符合正态分布或方差不齐的计量资料则采用Wilcox 检验。计数资料比较用卡方检验。检验水准设置为α=0.05,且双尾设置。P<0.05 认为差异具有统计学意义。
2 结果
2.1 基线数据特征
对照组共有1267 人纳入研究,平均年龄(65.90±9.01)岁;疾病组患单纯高血压344 例,患单纯糖尿病96 例,同时患高血压和糖尿病者126 例,平均年龄(65.67±9.77)岁,2 组间差异无统计学意义(P=0.314)。对照组和疾病组男女比例分别为45.30%、54.70%和41.67%、58.33%,差异无统计学意义(P=0.699)。疾病组患CKD 率为30.41%显著高于对照组7.58%,差异具有统计学意义(P<0.000 1),见表1。对比训练集(n=1 222)和测试集(n=611),各项指标差异均无统计学意义,P>0.05。

表1 研究对象分组数据分析[n(%)]Tab.1 Base line data analysis between control group and disease group[n(%)]
2.2 Logistic 回归筛选CKD 风险指标
采用Logisitc 回归分析发现13 项指标对判定非CKD 和CKD 具有统计学意义,分别是年龄(P=0.699)、疾病类型(高血压、糖尿病、高血压合并糖尿病)(P<0.000 1)、民族(P=0.040)、血尿素氮(P=0.032)、血肌酐(P=0.015)、MDRD 公式计算eGFR≤60 mL/(min·1.73 m2)(P=0.007)、ACR≥30 mg/g(P<0.000 1)、EPI2009 肌酐方程公式计算eGFR≤60 mL/(min·1.73 m2)(P=0.017)、PAM13 量表分数(P=0.001)、睡眠质量调查表(P=0.016)、熬夜情况(P=0.012)、PVT1 基因SNP 位点rs11993333(P=0.026)和rs2720659(P=0.012),见图2。
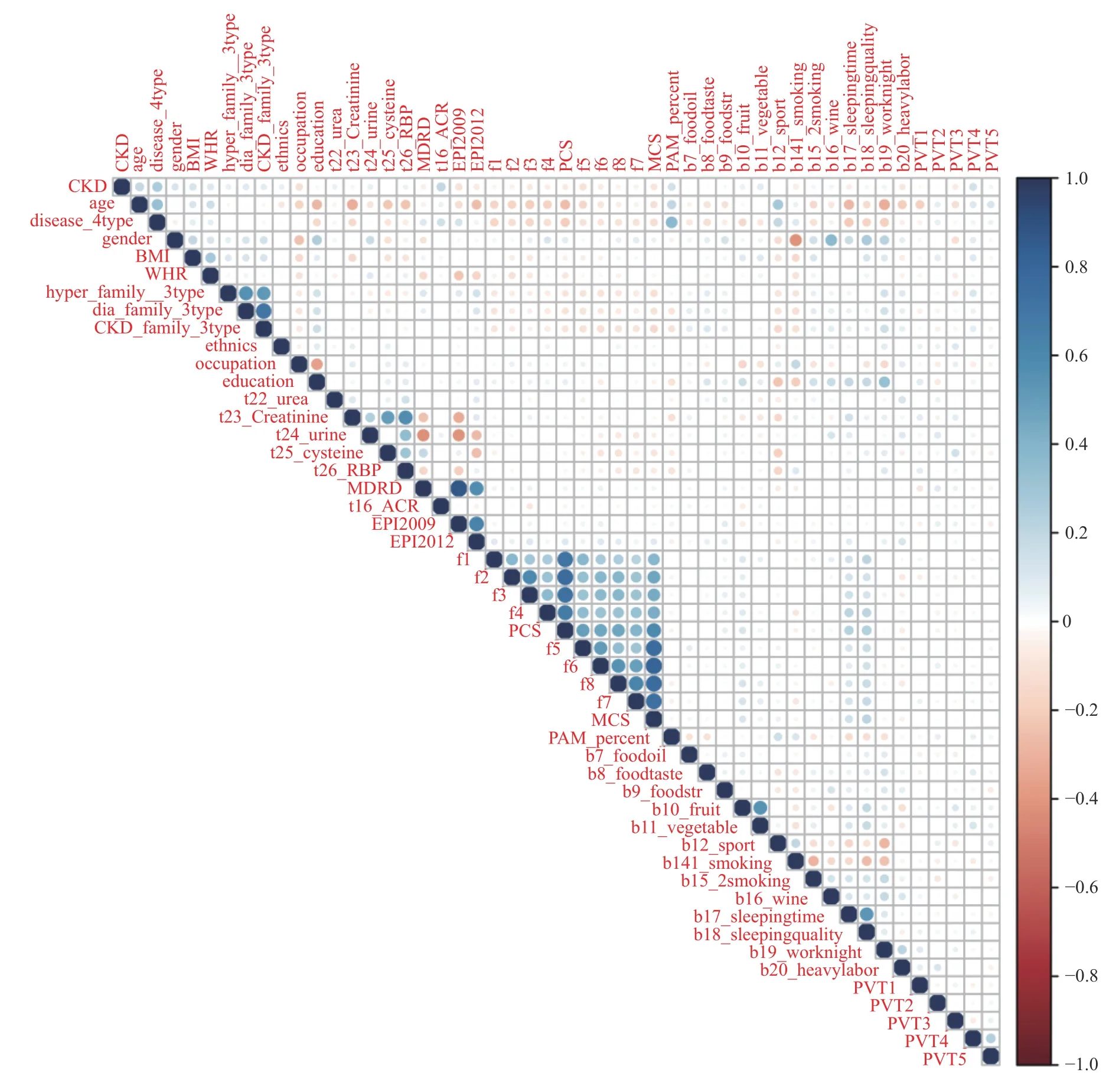
图2 Logisitc 回归分析热图Fig.2 Heatmap of Logistic regression
2.3 模型的建立和评估
13 项指标纳入机械学习算法,用于构建模型。PVT1 基因SNP 位点rs11993333 非优势基因型TC 和TT,位点rs2720659 非优势基因型AG 和GG。
SVM 算法建立模型的准确率为86.25%(95%CI:83.26%~88.88%)小于原错率87.23%,差异无统计学意义(P=0.786 3)。该模型的Kappa值为0.081,该模型预测值与真实值间一致性极低,模型预测精度极差。同时,SVM 模型灵敏度为97.75%,而特异度仅为7.69%。阳性和阴性预测值分别为95.29%和33.33%。SVM 模型中ROC 和PRC 的AUC 分别为0.895 7 和0.713 9 均大于0.70,SVM 模型的真实度和精确度较高,见图3A 和图3B。
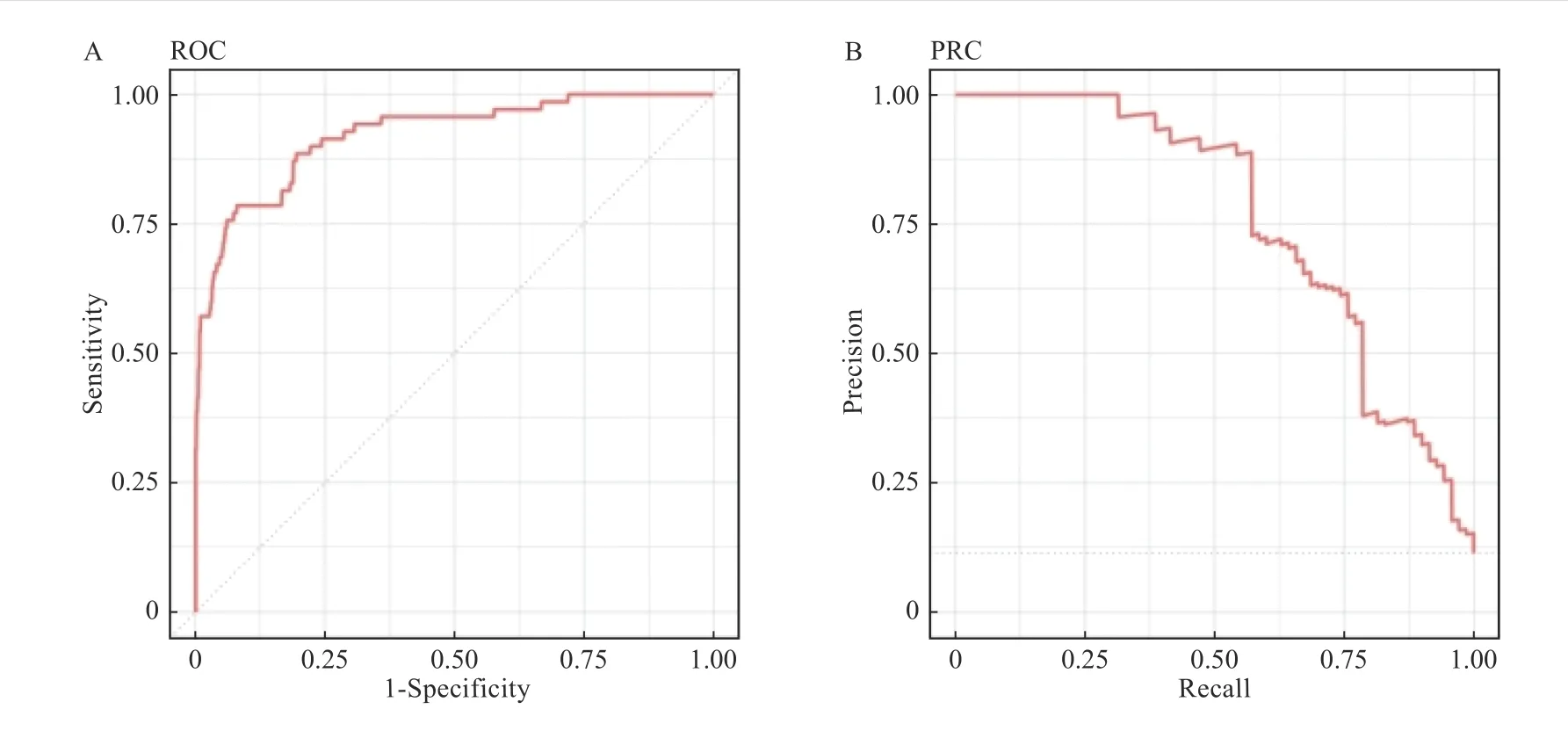
图3 支持向量机模型ROC 和PRC 的AUCFig.3 AUC of ROC and PRC in Support Vector Machine(SVM)
RF 算法建立模型准确率为88.54%(95%CI:85.75%~90.96%)小于原错率87.23%,差异无统计学意义(P=0.182 3)。该模型的Kappa 值为0.166 2 <0.2,预测值与真实值间一致性极低,模型预测精度极差。同时,RF 模型灵敏度为100%,而特异度仅为10.26%。阳性和阴性预测值分别为88.29%和100%。RF 模型中,ROC 的AUC 为0.921 0 大于0.90,说明模型准确度较高,见图4A,但PRC 的AUC 为0.650 2 小于0.7,说明模型精确性较差,见图4B。
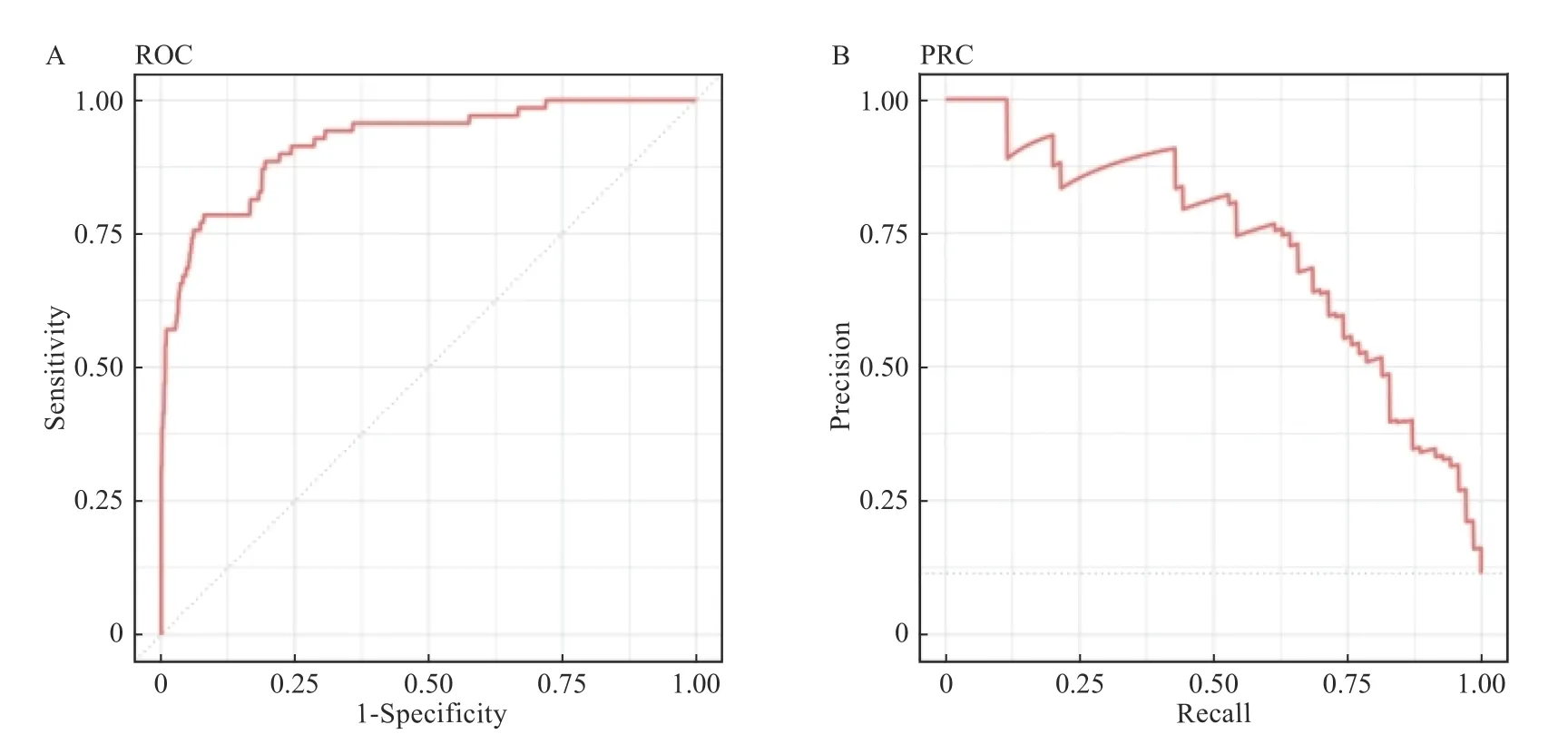
图4 自由森林模型ROC 和PRC 的AUCFig.4 AUC of ROC and PRC in Random Forest(RF)
NB 算法建立模型的准确率为92.14%(95%CI:89.72%~94.15%)大于原错率87.23%,差异具有统计学意义(P<0.000 1)。该模型的Kappa 值为0.603 9,大于0.41 而小于0.60,预测值与真实值间一致性中等,模型预测精度尚可。同时,NB模型灵敏度为97.37%,而特异度仅为56.41%。阳性和阴性预测值分别为93.85%和79.86%。
NB 模型中,ROC 的AUC 为0.936 9 大于0.90,见图5A,说明模型准确度较高,而且PRC 的AUC 为0.779 3 大于0.7,说明模型精确性较也好,见图5B。
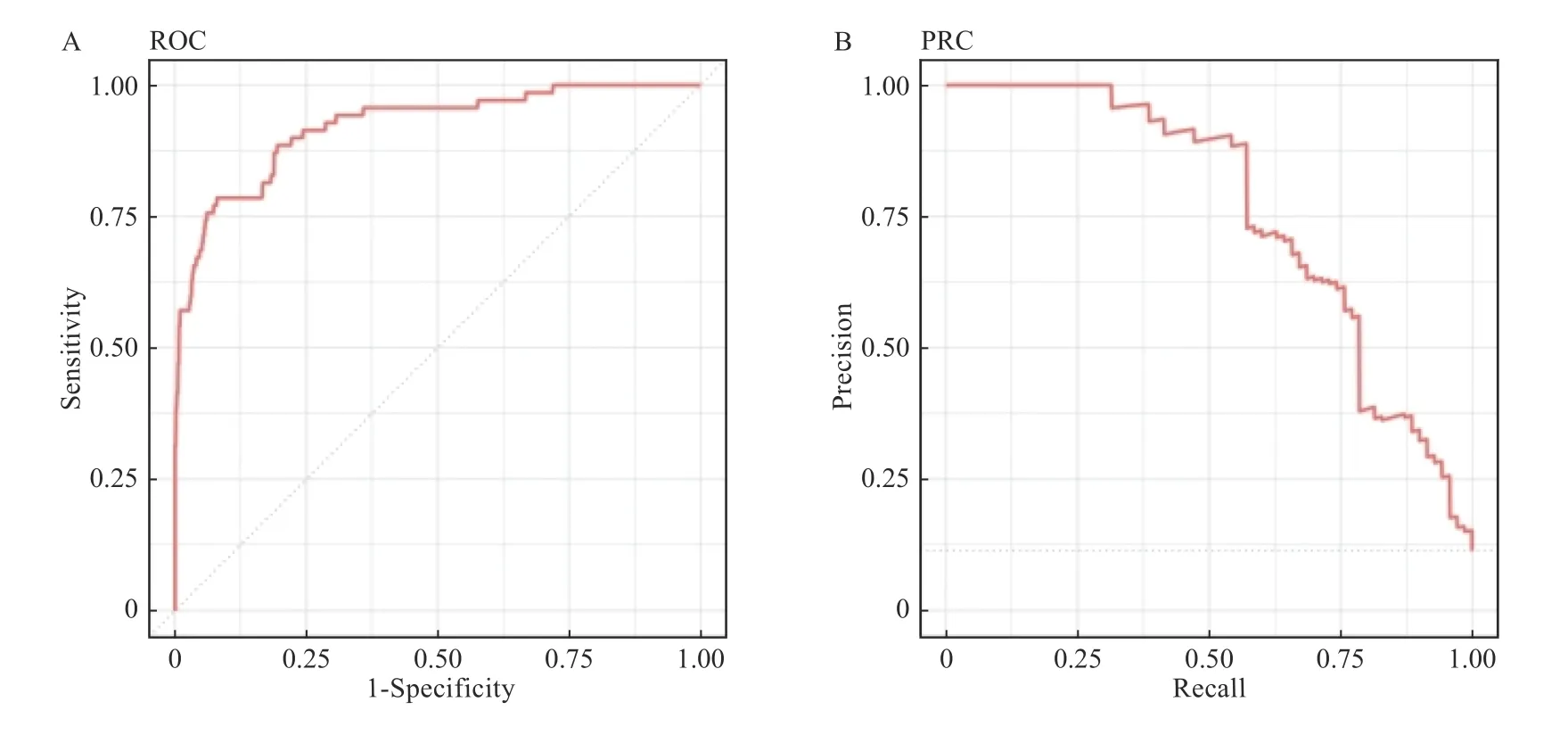
图5 朴素贝叶斯模型ROC 和PRC 的AUCFig.5 AUC of ROC and PRC in Naïve Bayes(NB)
ANN 模型输入层包含15 个神经节点,隐藏层包含11 个神经节点,输出层为目标疾病,包含1 个神经节点,见图6A。各变量对建立ANN模型的相对重要性不同,采用Garson 算法评价各变量对ANN 模型的相对重要性见图6B。相对重要性贡献最大的是ACR,其次为肌酐creatinine,第三为EPI2009。相对重要性贡献最小的为疾病类型。ANN 算法建立模型的准确率为94.60%(95%CI:92.50%~96.25%)大于原错率87.23%,差异具有统计学意义(P<0.000 1)。该模型的Kappa 值为0.729 4,大于0.60,预测值与真实值间一致性较高,模型预测精度较高。同时,ANN模型灵敏度为98.69%,而特异度仅为66.67%。阳性和阴性预测值分别为95.29%和88.14%。ANN模型中,ROC 的AUC 为0.941 8 大于0.90,说明模型准确度较高,见图6C,而且PRC 的AUC 为0.926 1 大于0.9,说明模型精确性较也高,见图6D。ANN 模型的准确率、特异性、Kappa 系数和AUC 均高于SVM 模型、RF 模型和NB 模型,然而ANN 模型灵敏度(98.69%)却低于RF 灵敏度(100%)。
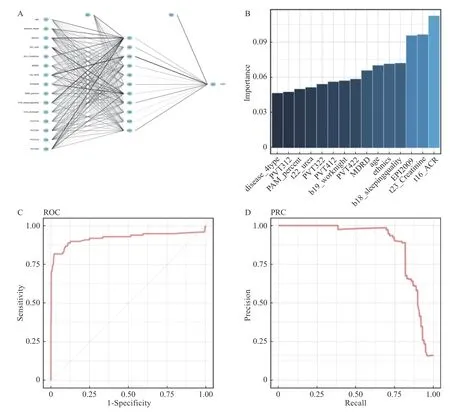
图6 人工神经网络评价Fig.6 Evaluation for artificial neuron net(ANN)
3 讨论
SVM、RF、NB 和ANN 是目前较常见的机器学习算法用于CKD 诊断。我国学者也采用机器学习建立IgA 肾病的诊断模型,其准确率及可信度高[9]。国外学者采用CKD 患者临床资料和症状建立SVM 模型能够区分CKD 患者和非CKD 患者,准确率达到99%,明显好于本研究的SVM 模型准确率(86.25%)[10]。另1 项研究通过对指标进行等级排序算法从25 项指标中选取了15 项建立SVM模型,可提高模型的准确率和Kappa 值[11]。通过筛选算法选取CKD 特征性指标建立SVM 模型,使其准确率提高到98.5%。由此CKD 患者指标的选择、参数的设置可影响SVM 模型准确率[12]。
本研究中选取了这4 种算法对CKD 患者临床资料、流行病学特征和分子基因SNP 等建立模型。结果发现建立的ANN 模型准确率高于其他3 种模型,达到94.60%;同时ANN 的Kappa 值大于其他3 种模型,ANN 预测值和真实值间一致性较高,精确度较好。基于前期调查和实验数据,通过Logistic 回归分析,发现13 个指标对模型建立起主要作用,分别为年龄、疾病类型(高血压、糖尿病、同时患高血压糖尿病)、民族、血尿素氮urine、血肌酐creatinine、MDRD 公式计算eGFR≤60 mL/(min·1.73 m2)、ACR≥30 mg/g、EPI2009肌酐方程公式计算eGFR≤60 mL/(min·1.73 m2)、PAM 量表分数、睡眠质量调查、熬夜情况、PVT1 基 因rs11993333 及rs2720659(P<0.05)。纳入指标建立SVM、RF、NB 和ANN 模型预测社区卫生服务中心中CKD 患者。结果显示,在社区糖尿病高血压人群中,需要通过一些重要的因素早期筛查CKD,这些指标主要为:患者血尿素氮及血肌酐检测,患者eGFR 测定(主要通过MDRD 公式计算及EPI2009 肌酐方程公式),筛查ACR,PAM 量表分数、睡眠质量、熬夜情况;如能开展基因检测,可以检测PVT1 基因rs119-93333 及rs2720659[13-14]。另一方面,ANN 模 型各项性能优于其他3 种模型,ANN 模型的准确率和精确率较高、分类效果较好;但特异性欠佳,有待完善特征选择算法,剔除无关和冗余特征。建立社区CKD 诊断ANN 模型,目的是在社区卫生服务中心为社区医护提供方便实用的诊断预测模型,让社区医护、社区慢性病患者提高对CKD的认识及早期预警,逐步实现筛查、疾病追踪、诊断疾病及预测疾病预后的社区CKD 管理模型[15]。下一步研究团队期望继续开发基于社区卫生服务中心CKD 早期诊断小程序、APP 等,更方便模型的使用,逐步实现CKD 诊断模型、风险预测模型、预测预后模型及评估CKD 进展的一系列模型,最终实现早期发现CKD、延缓CKD 进展,让更多的人群不走进尿毒症、减轻医疗负担。
