从局部到全局的零参考低照度图像增强方法
2024-04-10杨伟王帅吴佳奇陈伟田子建
杨伟,王帅,2,吴佳奇,陈伟,3,田子建
(1. 中国矿业大学(北京)人工智能学院,100083,北京; 2. 国家矿山安全监察局内蒙古局,010010,呼和浩特;3. 中国矿业大学计算机科学与技术学院,221116,江苏徐州)
低照度条件下如夜间、阴天和地下空间等,物体表面反射光较弱,拍摄到的图像受到背光、不均匀光照、低对比度和密集噪声的影响,不仅图像质量严重降低,难以获得理想的采集效果和关键信息,而且为后续的高层视觉任务带来巨大挑战,如目标检测、图像分割和物体追踪等[1-2]。因此,低照度图像增强在计算机视觉领域具有重要的研究意义和应用价值[3]。
随着计算机视觉的快速发展,低照度图像增强算法在视觉监控、自动驾驶、智能交通和摄影等领域有广泛应用,主要分为基于传统的低照度图像增强方法和基于深度学习的低照度图像增强方法。传统低照度图像增强算法包括直方图均衡化方法[4]、频域方法[5]、基于Retinex理论的方法[6-7]和基于去雾模型的方法[8-9]。此类方法一定程度上提高了主观视觉效果,但优化过程较为复杂,运行时间较长,图像的照度调整不够灵活,增强效果往往伴随着严重的色彩失真和细节损失。
相比于传统低照度图像增强算法,凭借大规模数据中提取先验的强大能力,基于深度学习的低照度图像增强算法具有更强的鲁棒性、适应性和处理速度[10],根据学习策略可以分为监督学习、强化学习、无监督学习和零次学习。其中,Lü等[11]基于监督学习设计了端到端的多分枝增强模型。部分基于监督学习的方法采用了Retinex理论[12-14],如Wei等[15]通过新的约束条件和先进的模型设计,使得Retinex-Net达到了较好的增强性能。Zhang等通过图层分解、反射率恢复和照度调整提出了KinD[16]和KinD++[17]方法,有效缓解了图像增强后的主观视觉缺陷问题。Yu等[18]基于强化学习提出了DeepExposure方法,在没有配对数据集的情况下,通过融合不同曝光下的多个修饰图像获得增强后的图像。Jiang等[19]基于无监督学习提出了EnlightenGAN方法,通过全局-局部判别器和特征保留损失函数,解决了基于合成数据训练的过拟合和难以泛化的问题。基于监督学习的模型需要基于配对数据进行训练,因此模型泛化性不强,对现实低照度图像的增强效果不理想;基于无监督学习的模型较大,不利于模型部署;基于强化学习的模型难以实现高效稳定的训练。因此,使用零次学习实现低照度图像增强具有重要意义。零次学习仅从训练数据中学习照度增强过程,应用过程中不需要配对或非配对的数据。Zhang等[20]通过估算适合输入图像的S曲线来调整滤波器分离出来的基础层,融合调整后的基础层和细节层得到增强后的图像。Guo等提出Zero-DCE[21],将低光增强作为针对图像光照曲线的估算任务,利用高阶曲线对输入图像光照的动态范围进行调整得到增强图像,并在此基础上提出了轻量化版本Zero-DCE++[22],通过共享高阶曲线的权重参数和模型优化达到了增强过程的快速推算,但增强结果存在不同程度的偏色、亮区增强过度和暗区增强不足现象。以上低照度增强方法在人眼主观视觉和客观评价指标取得了明显提升,一定程度上提高了目标检测与识别的性能,但低照度增强任务和目标检测任务的目的不同,前者对细节敏感侧重于抽象度低的特征,后者侧重于抽象度高的目标特征,经过低照度增强后的图像可能包含不利于目标检测的噪声,无法保证增强后图像有更好的目标检测效果。
综合以上分析,本文从图像视觉质量和目标检测效果两个角度考虑,提出了一种从局部到全局的零参考低照度图像增强方法,解决了以下几个问题:Zero-DCE的自适应光照映射估计函数的动态调整范围不足;多次生成像素级的高阶迭代参数需要较多的参数量和运行时间;增强图像的对比度不足、噪点突出和曝光现象;低照度图像的目标检测精度低。
1 从局部到全局的零参考低照度图像增强方法
提出的低照度图像增强方法的总体架构如图1所示,主要包含两部分:①局部照度增强,由7个卷积组成,每个卷积后采用ReLU激活函数,最后1个卷积采用Tanh激活函数,并对自适应光照映射估计函数进行改进,采用倒数函数取代原有的二次迭代函数,提高照度的调整范围,降低参数量和运算时间;②基于Transformer的全局图像调整,包含Transformer结构、颜色校正矩阵和伽马变换,通过捕获单个像素和周围像素之间的关系,获得更丰富的全局特征信息,解决亮区增强过度和暗区增强不足的问题,提高图像的整体对比度。
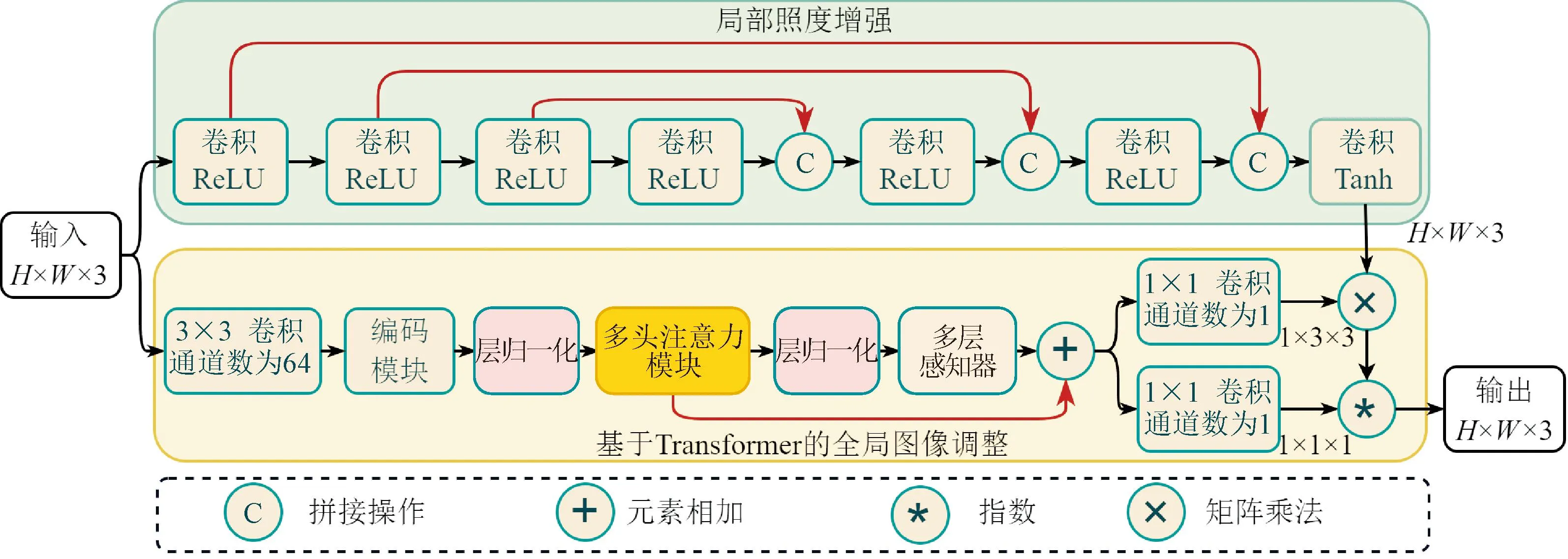
图1 提出的低照度图像增强方法的总体架构Fig.1 Overall architecture diagram of proposed low-light image enhancement method
1.1 局部照度增强
局部照度增强用于估计像素级的照度映射关系以校正光照的影响,结构如图1所示,采用了7个卷积和3次拼接操作,每个卷积后采用ReLU激活函数,最后1个卷积采用Tanh激活函数,未采用下采样和采样操作,尽可能保留图像的细节信息。局部照度增强是在Zero-DCE的基础上改进了自适应光照映射估计函数。Zero-DCE方法提出的基于二次函数迭代的光照映射估计函数为
E(X)=X+αX(1-X)
(1)
En(X)=Xn-1+αnXn-1(1-Xn-1)
(2)
式中:X表示输入;E(X)表示为给定输入X的增强版;En(X)表示迭代第n次产生的增强结果;αn∈[-1, 1]是通过模型训练得到的参数,用于第n次叠代调整映射曲线,控制曝光水平。
由于调整参数α为像素级的参数,即输入图像的每一个像素都有一个最适合的α曲线来调整其动态范围,因此基于二次迭代函数的像素级光照映射关系可表示为
En(X)=En-1(X)+AnEn-1(X)(1-En-1(X))
(3)
式中:An与输入X的维度相同,表示第n次迭代的权重。
提出的基于倒数函数的光照映射估计函数可表示为
(4)
式中:X表示输入;E(X)表示为给定输入X的增强版;α∈ [-∞, -1]∪ [0, +∞]是通过模型训练得到的参数。
由于调整参数α为像素级的参数,即输入图像的每一个像素都有一个最适合的α曲线来调整其动态范围,因此提出的基于倒数函数的像素级光照映射关系可表示为
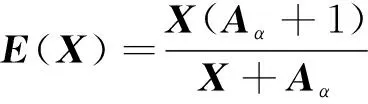
(5)
式中:Aα是与输入X维度大小相同的权重。所有像素都被归一化为 [0, 1],并将曲线分别作用于RGB的3个通道。
图2为自适应光照映射估计函数曲线。从图中可以看出,迭代次数越多,光照调整能力越强,但表征范围仍有缺失。同时,迭代次数越多,计算量和参数量越多,模型结构越复杂,模型推理时间越长。提出的基于倒数函数的光照映射估计函数如图2(c)所示,光照调整范围更大,不需要迭代计算,因此学习参数更少,模型更加轻量化。
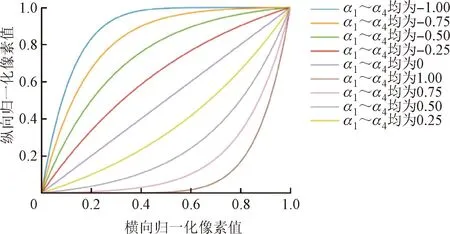
(a)二次迭代函数(n=4)
1.2 基于Transformer的全局图像调整
全局图像调整过程中,首先对输入图像进行卷积,获得高维度和低分辨率的图像特征,低分辨率可以节省计算成本,有利于模型实现轻量化,较高的维度特征有利于提取图像的全局特征。然后,通过特征编码后进入多头注意力模块,捕获周围像素和单个像素之间的全局交互,获得图像的全局特征[23-25]。全局图像调整的具体计算过程如图3所示。
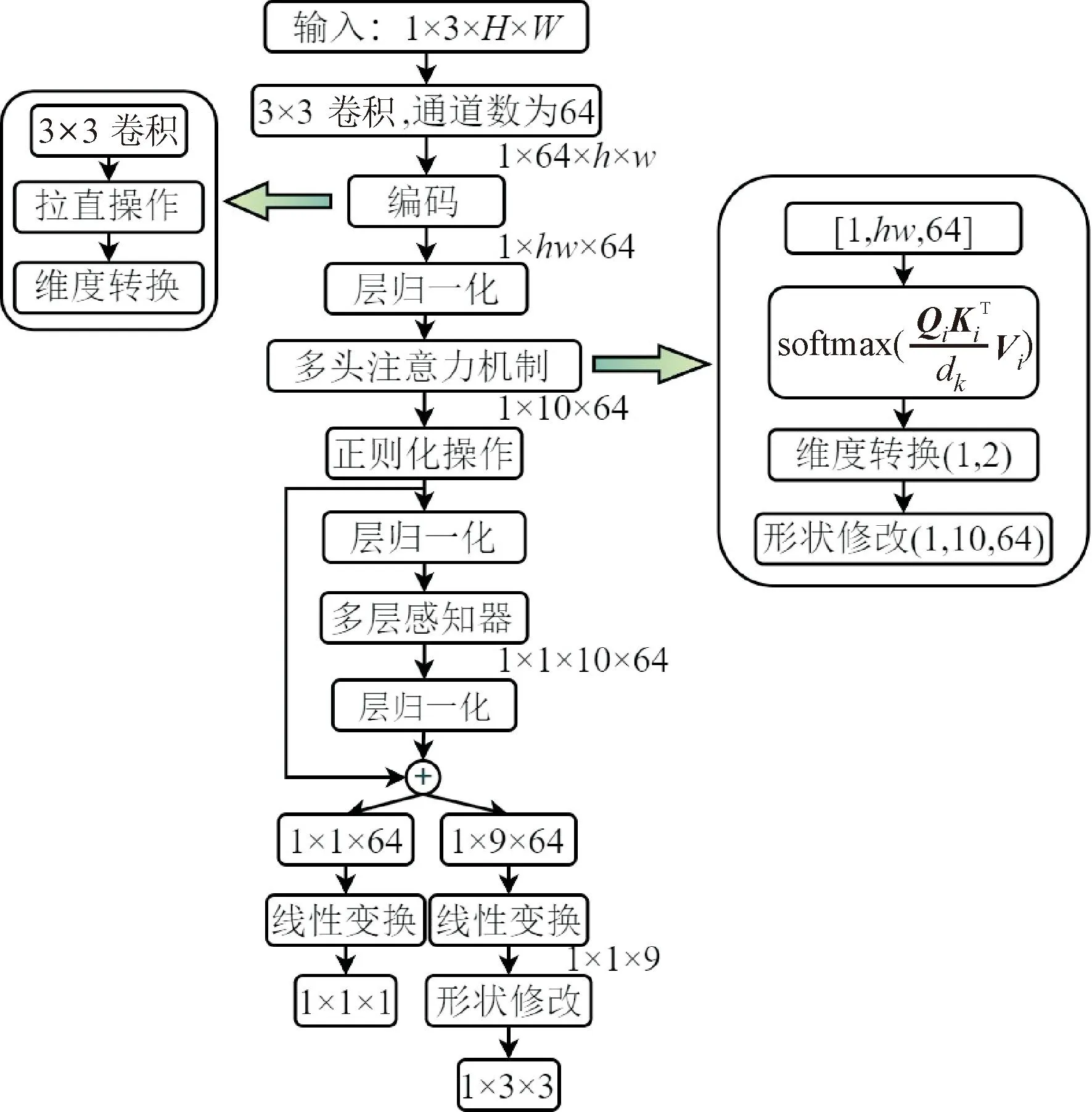
h,w—第一次卷积后图像的高和宽;Q,K,V—多头注意力机制的3个向量;dk—向量k的维度。图3 全局图像调整的计算过程Fig.3 Calculation process of global image adjustment
进入多头注意力模块之前,首先要进行特征编码,特征序列化过程如图4所示。第一次卷积后的特征图大小为64×h×w,首先将h×w大小的特征图的每个像素作为一个token,并在通道上拉直展开得到64维的特征向量,即(h×w)×64的二维矩阵X′T,将X′T经过线性变换进行编码,得到满足条件的输入序列XT。
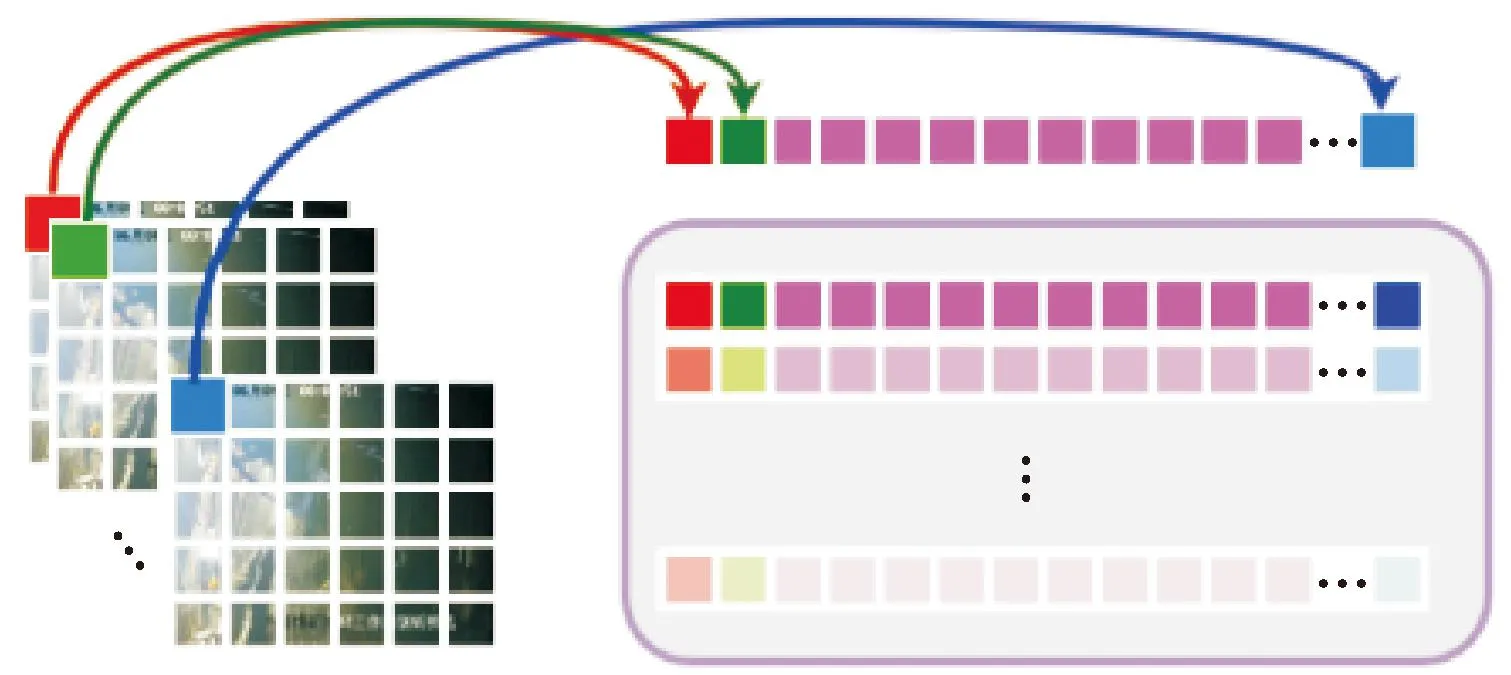
图4 特征图的序列化过程Fig.4 Serialization process of feature maps
输入序列XT分别乘上模型自行学到的权重Wq、Wk、Wv得到Q、K、V,并拆分得到Qi、Ki、Vi在多个空间内进行注意力计算,计算过程可表示为
(6)
(7)
式中:Attention为求取注意力机制操作;softmax为softmax函数;Wq、Wk、Wv是由模型自行习得的权重;Wqi、Wki、Wvi分别为Q、K、V的第i个子空间的权重;Zi为第i个子空间的注意力计算结果;dq、dk、dv分别分Q、K、V的维度,且dq=dk=dv。
多头自注意力是在多个子空间进行注意力计算,该过程可表示为
Z=MultiHead(Q,K,V)=
Concat(Z1,Z2,Z3,Z4)Wo
(8)
式中:MultiHead为求取多头注意力机制操作;Concat为拼接操作;Wo为权重矩阵。输入序列XT经过式(6)得到Q、K、V,分别进入不同的子空间,通过式(7)得到所有子空间的注意力权重Z1~Z4,通过式(8)得到多头注意力机制权重Z。
多头注意力的输出大小为1×10×64,经过多层感知机和线性变换生成一个3×3的颜色矩阵和一个1×1的伽马值。颜色矫正矩阵对R、G、B三通道颜色进行色彩调整,伽马值用于全局图像照度的非线性调节。对局部增强后的图像进行全局调整的过程可表示为
G(X)=(max(∑Wcol×E(X),ε))γ
(9)
式中:E(X)表示局部增强后的图像;G(X)表示全局调整后的图像;Wcol表示颜色变换矩阵;γ表示伽马校正的指数值;ε表示一个非负最小值,实验中设为ε=e-8。
1.3 损失函数
低照度图像增强模型的整体损失Ltotal由空间一致性损失Lspa、曝光控制损失Lexp、色彩不变性损失Lcol和特征相似性损失Lfs共4个损失函数联合计算,具体可表示为
Ltotal=Lspa+Lexp+Lcol+Lfs
(10)
为引导模型学到适合的低光和正常光的映射关系,采用了Zero-DCE方法提出的3个非参考损失函数用于训练低光增强模型。空间一致性损失[21]通过控制输入图像和增强图像相邻区域的梯度来保持图像的空间一致性,可表示为
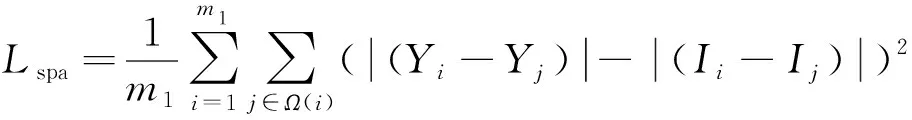
(11)
式中:m1表示为局部区域的数量;Ω(i)表示以区域i为中心的4个相邻区域(上、下、左、右);Y和I分别为增强图像和输入图像的局部区域平均强度值。
曝光控制损失通过测量局部区域的平均强度与正常曝光水平E[26]之间的距离控制曝光水平,避免曝光过度或曝光不足现象,可表示为
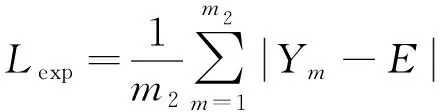
(12)
式中:m2表示不重叠的局部区域数量;Ym表示各个局部区域的平均强度;E表示正常曝光水平,根据文献[21]和文献[26],E设定为0.6。
色彩恒定损失通过建立三通道R、G、B之间的关系矫正潜在的色彩偏差,使得增强后的颜色尽可能保持一致,可表示为
(13)
式中:Jp和Jq表示增强图像对应的p通道和q通道的平均强度值;(p,q)表示一对通道。
为提升目标检测的精度,提出了基于KL散度的特征相似性损失。KL散度又叫相对熵或信息熵,用于衡量两个变量之间的差异[27]。假设两个特征序列为F1和F2,对应的概率分布函数为f1(x)和f2(x),KL散度可以表示为
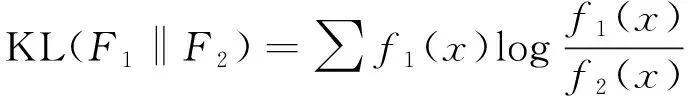
(14)
模型训练过程中,通过YOLOv7的主干网络分别抽取原始图像和增强后图像的特征,对抽取的特征进行全局平均池化,得到两个1×1×C大小的向量,逐点计算两个向量的KL散度,衡量低照度图像和增强图像的特征差异。通过约束增强前后图像的特征相似性,避免增强过程产生对后续检测不利的影响。基于KL散度的特征相似性损失表示为
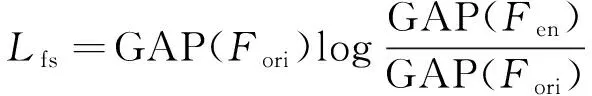
(15)
式中:GAP(Fori)为原始低照度图像特征的全局池化操作;GAP(Fen)为增强后图像特征的全局池化操作。
2 实验与结果分析
实验操作系统为64位Windows11,CPU为AMD Ryzen 7 5800H with Radeon Graphics,显卡为NVIDIA RTX 3070 GPU。网络模型基于Python3.9.0,Pytorch1.12.1和Cuda11.6框架搭建,开发环境为PyCharm 2022.3.2。模型训练采用的SICE数据集[28],包含589个室内和室外场景的多重曝光图像,每个场景包含3~18张不同曝光的低对比度图像。模型训练中,学习率为0.000 1,batch size为8,epoch为100,动量为0.9,为避免训练过程中出现过拟合现象,采用余弦退火降低学习率,衰减系数为0.000 05。
2.1 数据集和评价指标
为验证提出的低照度图像增强方法的性能,从主观视觉和客观指标两方面,将本文方法与最先进的方法:Retinex-Net[15](2018年)、MIRNetv2[29](2023年)、SCI[30](2022年)、Zero-DCE[21](2020年)、Zero-DCE++[22](2022年)和EnlightenGAN[19](2021年)在LOL数据集[15]和MIT-Adobe FiveK数据集[31]上进行对比。其中,Retinex-Net和MIRNetv2方法是监督学习方法,EnlightenGAN和SCI是无监督学习方法、Zero-DCE和Zero-DCE++是零次学习方法。LOL数据集是在真实场景下拍摄的配对数据集,通过改变曝光时间和感光度ISO收集了500对大小为400×600像素的低光/正常光图像。MIT-Adobe FiveK数据集包含5 000张图像,每张图像由5位专业摄影师(A/B/C/D/E)修图并保存为raw格式,本文选取了专家A的修图结果作为对照,并将图像转换为JPG格式。
低照度图像增强对比实验采用了峰值信噪比(PSNR,用符号PSNR表示)和结构相似性(SSIM,用符号SSIM表示)作为客观评价指标。其中,峰值信噪比对增强前后图像像素点的灰度值进行对比计算,用于评估图像的处理质量,单位为dB,数值越小表示失真程度越大,计算过程如下
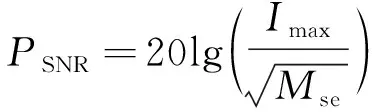
(16)
式中:Imax表示输入数据最大值;Mse表示增强前后图像之间的均方误差。
结构相似性从亮度、对比度和结构信息三方面对增强前后的图像进行相似度对比,取值范围为 [0, 1],数值越大表示相似度越大,具体计算过程如下
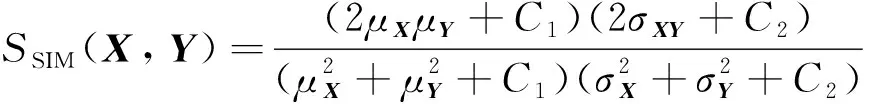
(17)
式中:μX、μY表示图像均值;σX、σY表示标准差;σXY表示图像X和Y的协方差。
2.2 客观评价指标
选取峰值信噪比和结构相似性作为客观评指标,将本文方法与其他6种低照度增强方法在LOL数据集和MIT-Adobe FiveK数据集上进行对比。选取参数量、计算量和单张图像测试时间,在400×600像素的图像上进行效率对比,结果如表1所示。
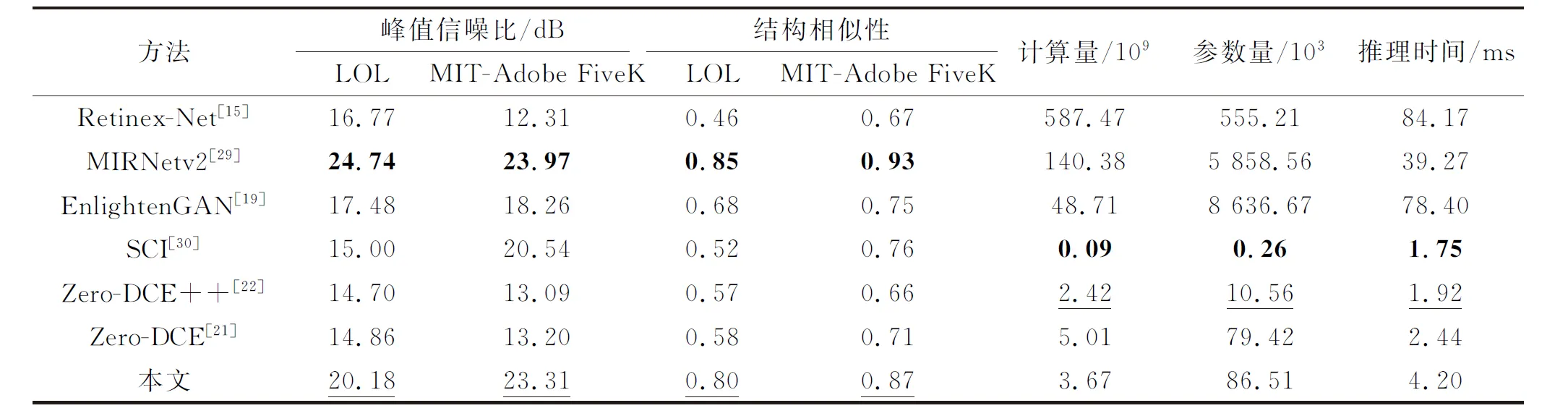
表1 不同方法客观评价指标和模型效率对比结果Table 1 Comparative results of objective evaluation indicators and model efficiency between different methods
从表1可以看出,所提算法在LOL数据集上的PSNR达到了20.18 dB,SSIM达到了0.80,在MIT-Adobe FiveK数据集上的PSNR达到了23.31 dB,SSIM达到了0.87,仅次于MIRNetv2方法的增强效果。同时,相比与MIRNetv2方法140.38×109次的计算量,5.90×106个参数和39.27 ms的测试时间,本文提出的方法仅需要3.67×109次的计算量,0.09×106个参数和4.2 ms的测试时间,所提方法的综合性能优于其他低照度增强方法。
2.3 主观视觉效果
在LOL数据集上将本文方法与其他六种低照度图像增强方法进行对比,选取其中7个场景的对比结果进行主观性分析,对比结果如图5所示。从图中可以看出,Retinex-Net方法增强后,图像亮度提升明显,颜色饱和度高,但增强后的图像模糊,出现了颜色和纹理失真,如场景2、4、6和7。MIRNetv2方法增强后,整体色彩恢复比较真实,亮区的增强效果较好,如场景1、2、3和5,暗区的增强效果较差,如场景4和7。EnlightenGAN方法增强后的图像颜色偏黄如场景7,亮度提升有限如场景4和6。SCI方法增强后的图像未出现颜色和纹理失真现象,但整体亮度和对比度较低,如场景4和7。Zero-DCE++方法的照度调整不足,增强后的图像整体偏暗,出现严重偏色现象,视觉效果较差,如场景2、3和5的偏蓝现象非常明显。Zero-DCE方法增强后的图像没有出现严重的偏色现象,但整体亮度提升不足,如场景2、4和7。本文方法增强后的图像未出现颜色偏差和纹理失真现象,颜色饱和度较好,亮度提升明显,整体视觉效果较好。

图5 LOL数据集上的低照度图像增强结果Fig.5 Low-light image enhancement results on LOL dataset
在MIT-Adobe FiveK数据集上将本文方法与其他6种低照度图像增强方法进行对比,选取其中6个场景的增强结果进行主观性分析,对比结果如图6所示。从图中可以看出,Retinex-Net增强后的图像颜色过度饱和,如场景1、场景6和场景7,纹理过于突出如场景2,该方法难以恢复较好的视觉效果。MIRNetv2方法对亮区的增强效果较好,如场景1、2和5,暗区增强后略有失真,如场景3中人脸面部模糊,细节丢失,且不同光源下的颜色失真程度不同,如场景3和4。EnlightenGAN增强后的图像出现了明显的色彩偏差,整体图像偏黄严重,无法恢复图像原本的色彩,如场景1的水面和波光、场景3的人脸和衣服条纹、场景4的墙面和场景5玻璃上的白色贴纸,并且出现了严重的光晕和细节丢失现象,如场景6右上角和场景3左上角。SCI增强后图像的整体亮度提升明显,但暗区域照度提升有限,如场景3的人物背景和场景6的地面,亮区域容易增强过度产生严重的曝光现象,如场景1的喷泉和场景5的右侧部分。Zero-DCE++增强后图像的偏色现象不明显,但依旧存在,如场景4的白色墙壁和场景5的整体光线,且整体增强效果较暗。Zero-DCE的增强效果略有提升,但整体亮度依旧较暗,如场景4的墙壁。暗区增强后噪点明显,如场景3左侧阴影区域和场景7地面。增强后细节较为模糊,如场景6中墙上的字母。本文所提方法增强后的图像未出现明显的光晕、偏色和细节丢失现象,色彩恢复效果较好,照度提升明显。在主观视觉效果方面,本文提出的方法优于其他6种低照度图像增强方法,两个数据集上的增强结果表明所提方法的泛化性和鲁棒性较好。

图6 MIT-Adobe FiveK数据集上的低照度图像增强结果Fig.6 Low-light image enhancement results on MIT-Adobe FiveK dataset
为验证本文提出的方法在真实低照度条件下室内和室外实拍图像上的增强效果,将本文方法与其他6种低照度图像增强方法进行对比。在夜间,于中国矿业大学(北京)校园内8处景点拍摄真实低照度图像,拍摄设备为iPhone13,图像最大分辨率为4 032×2 024像素,这些图像没有参与模型的训练,仅用以验证提出方法的适应性,增强对比结果如图7所示。从图中可以看出,Retinex-Net增强后图像的亮度和对比度明显提升,但颜色饱和度过高如场景3和场景5,纹理过于突出导致图像失真严重如场景1和场景4,场景3增强后黑暗处出现明显光晕。MIRNetv2方法增强后的图像整体泛白如场景4和场景6,部分细节纹理丢失如场景2中的桌面和场景5中的台阶,场景3增强后的天空产生了明显光晕。EnlightenGAN增强后图像的整体亮度和对比度提升明显,但仍有不足如场景3和场景5,颜色偏黄如场景2和场景7,场景3和场景6增强后的天空以及场景8中的窗户均产生了明显的光晕现象。SCI方法增强后的图像颜色保真度较好,但明亮区域过度增强产生了严重的曝光现象,导致部分特征丢,如场景3中的窗户和场景4中水塔,图像暗处增强不足如场景7和场景8的地面。Zero-DCE++增强后图像的整体亮度不足,偏色(蓝)现象明显,如场景4中的白色石柱和场景7中的白色房子等。Zero-DCE增强后图像的细节纹理保留较好,未出现纹理失真现象,偏色(蓝)现象有所缓解,但依然存在,如场景2和场景7,图像的整体亮度提升不足如场景1、场景5和场景7。本文所提方法增强后图像的亮度和对比度提升明显,颜色饱和度较好,未出现颜色失真和纹理失真现象,在室内和室外的真实低照度条件下有较好的增强效果。
2.4 目标检测及特征可视化
为探究本文提出的增强方法对目标检测性能的影响,基于YOLOv7在Exdark数据集上与其他6种方法增强后的检测结果进行对比。低照度图像增强模型联合YOLOv7检测模型的应用框架如图8所示,表2中的“原始图像+YOLOv7”表示使用图8中的方式a,“增强方法+YOLOv7”表示使用图8中的方式b,即原始图像首先经过低照度图像增强模型进行增强,增强后的结果作为YOLOv7检测网的输入。对比结果如表2所示,可以看出,Retinex-Net和EnlightenGAN增强后图像的检测精度分别降低了1.6%和0.7%,在人眼视觉上取得了一定的提升,但对于目标检测损失了重要的特征信息。MIRNetv2、Zero-DCE++和Zero-DCE增强后的检测精度分别提升了5.6%、4.2%和4.4%,本文方法增强后的目标检测精度提升了7.6%,检测时间仅需42.23 ms,因此本文所提方法更有助于低照度条件下的目标检测任务。

a—低照度图像直接进入检测网络;b—低照度图像增强后进入检测网络。图8 低照度图像增强模型联合检测网络的应用架构Fig.8 Application architecture diagram of joint detection network for low-light image enhancement networks
除此之外,为进一步探究提出的低照度增强方法对目标检测的影响,在ExDark数据集上,基于YOLOv7对原始图像和增强后图像进行目标检测,并对检测目标进行特征可视化,直观显示出低照度图像和增强图像对特征提取和目标识别的影响,结果如图9所示。可以看出,正常亮度区域内的目标,图像增强前后的检测结果差距不大,如场景1中的第一个目标(增强前检测精度为85%,增强后为86%)和场景2中的前3个目标(增强前检测精度为89%、89%和83%,增强后为89%、86%和88%)。低照度区域内,增强前后的目标检测结果差异很大,主要表现在3个方面:黑暗中的目标无法识别、相邻目标无法区分以及目标特征边界不明显。例如,场景2中低照度图像的目标7和8,场景3中低照度图像的目标2和3无法识别,对应的增强后的图像可以准确检测出目标。场景4中,低照度图像中的目标1与目标2的特征边界无法区分、检测框定位错误,对应的增强后的图像中的目标特征定位准确。场景1和2中原始图像的对比度低,目标特征无法区分,对应可以准确检测出目标。场景4中,低照度图像中的目标1与目标2的特征边界无法区分、检测框定位错误,对应的增强后的图像中的目标特征定位准确。场景1和2中原始图像的对比度低,目标特征无法区分,对应的增强后的图像的特征位置集中且边界明显。

(a)场景1
2.5 消融实验分析
为探究光照映射估计曲线和全局调整的必要性和有效性,进行了相关的消融实验,测试图像是在真实场景下拍摄的低照度图像,拍摄设备为iPhone13,图像最大分辨率为4 032×2 024像素。主观视觉对比结果如图10所示。其中:Global-false表示去掉全局图像调整,仅保留局部增强;Curve-quadratic iterative表示局部增强采用二次迭代函数作为自适应光照映射估计函数。从图中可以看出,去除全局图像调整后,整体亮度提升依旧明显,但部分区域过度增强,如场景2和3中的天空增强过度,噪点明显,细节失真,场景4中白色框内的路灯被过度增强导致严重曝光。光照映射估计曲线采用二次迭代函数增强后,亮度增强依旧明显,但边缘纹理突出,细节信息丢失严重,亮度对比度不足,如场景2和3。

图10 消融实验对比结果Fig.10 Comparative results of ablation experiments
为验证特征相似性损失函数对目标检测性能的影响,在Exdark数据集上进行了消融实验,结果如表3所示。Ldec为YOLOv7的检测损失函数,Lspa、Lexp、Lcol分别为空间一致性损失、曝光控制损失和色彩不变性损失函数,Lfs为特征相似性损失函数。从结果可以看出,照度增强后目标检测的性能提升明显(5.3%),特征相似性损失通过约束目标特征,使得增强后图像的目标特征更有利于目标检测任务,目标检测的精度提升了2.3%。
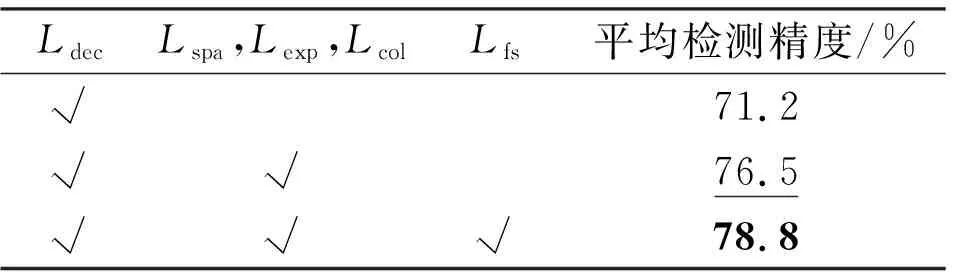
表3 损失函数对目标检测性能的影响Table 3 Impact of loss function on object detection performance
3 结 论
针对低照度图像存在的多种退化现象,现有的图像增强方法存在颜色失真、亮度提升有限、细节损失严重和噪声放大的问题,严重影响了图像的可视化效果和目标检测精度。为解决上述问题,提出了一种从局部到全局的零参考低照度图像增强方法。
(1)提出的低照度图像增强方法仅需要3.67×109次的计算量和0.09×106个参数,单张图像测试时间仅4.2 ms,具有轻量化优势,便于模型部署。
(2) LOL数据集、MIT-Adobe FiveK和真实低照度图像上的实验结果表明,所提方法有效提高了低照度图像的客观评价指标和主观视觉效果,未出现伪影和噪声放大问题,增强了图像的整体亮度和对比度,避免了颜色失真和细节损失现象。
(3) ExDark数据集上的目标检测和特征可视化结果表明,所提方法增强后图像的目标轮廓更加清晰,定位更加准确,提高了低照度图像的目标检测的精度,证明了所提方法的有效性。
