面向真实世界的知识挖掘与知识图谱补全研究(三):基于正则表达式对膀胱癌真实世界数据的结构化信息抽取
2024-04-08马文昊石涵予王永博王诗淳任相颖靳英辉阎思宇
马文昊,石涵予,黄 桥,黄 兴,王永博,王诗淳,任相颖,施 悦,靳英辉,阎思宇
1. 武汉大学中南医院循证与转化医学中心(武汉 430071)
2. 武汉大学第二临床学院(武汉 430071)
3. 武汉大学弘毅学堂(武汉 430072)
4. 浙江大学医学院附属第一医院泌尿外科(杭州 310003)
5. 武汉大学中南医院信息中心(武汉 430071)
美国食品和药物监督管理局在《真实世界证据方案的框架》[1]中将真实世界数据(realworld data,RWD)定义为“与患者健康状况有关的和(或)日常医疗过程中收集的各种来源的数据”。RWD 包括来源于卫生信息系统、电子病历(electronic medical record, EMR)、医保系统的数据和来自移动设备端如可穿戴设备获得的相关数据等。随着诊疗数据的几何级增长,基于EMR 数据开展的真实世界研究越来越受重视,如进行真实环境下干预措施效果和安全性的评价研究[2],但在实施时仍面临一些挑战。EMR 数据产生的初始目的不是用于临床研究而是服务于临床实践,因此除结构化字段外,还包括大量半结构化、非结构化文本,并且各医疗机构之间数据的记录与储存尚缺乏统一标准,对于数据记录方面的规范化培训和质量控制不足,导致原始数据质量参差不齐,增大了研究者数据挖掘工作的难度。因此如何基于现有EMR 数据进行结构化信息抽取是一个不小的挑战。
信息抽取作为自然语言处理的子领域,其方法主要包括基于人工编写规则的信息抽取方法和基于统计学方法的信息抽取方法[3]。基于人工编写规则的信息抽取方法相对简单但高度依赖于人工编写的规则集,适用于有一定结构规律的自然语言文本。正则表达式(regular expression, RE)是对字符串操作的一种逻辑公式,即是用事先定义好的一些特定字符及其组合,组成一个“规则字符串”,用以表达对字符串的一种过滤逻辑。RE 是一种文本模式,该模式描述了在搜索文本时要匹配的一个或多个字符串[4],可以作为一种过滤工具,实现对RWD 的结构化信息抽取。近些年来,RE 在医学领域有着广泛的应用。例如国外学者应用RE于神经外科手术登记表的构建,显著减少了人工工作量并促进相关临床研究[5];Flores 等[6]使用RE 从生物医学文本中提取特征值,有较高的准确性,可为数据集进一步分析奠定基础;在对医学指南中事件句型进行相关匹配与抽取的研究中,RE 可高效准确地将医学指南中的事件自动转换成XML 结构化数据[7]。
考虑到EMR 数据中大部分目标字段具有一定的表达规律,故本研究以武汉大学中南医院近7 年膀胱癌患者EMR 中的入院记录、病理报告、手术记录和影像记录等非结构化文本数据为例,采用基于人工编写规则并以RE 为编程基础的信息抽取方法对膀胱癌自然语言文本数据进行结构化信息抽取。
1 资料与方法
1.1 数据源及抽取字段
以武汉大学中南医院2015—2021 年出院诊断包含膀胱癌的患者EMR 数据中的入院记录、病理记录、手术记录以及影像学记录为研究数据源,其中病理记录示例见表1。本研究已通过武汉大学中南医院伦理委员会审核批准(批号:科伦[2022002K]),所有数据均已进行了去隐私化处理。

表1 病理记录示例Table 1. Example of pathological record
在咨询临床、病理、流行病学等专家意见和查阅相关文献后,结合膀胱癌RWD 的表达规律与结构特点,本研究确定需抽取的结构化字段包括32 个目标字段(表2)。其中“肿瘤浸润深度”以膀胱壁的解剖结构层级为标准进行抽取,包括固有层、浅深肌层等;“区域淋巴结浸润情况”的描述通常涵盖了送检淋巴结位置、送检数量及阳性数量;“变异组织学”采用2016 年第4 版《WHO 泌尿系统及男性生殖器官肿瘤分类》[8]标准进行抽取;当病理记录未明确记录T、N 分期时,依据美国癌症联合委员会2017 年制订的第8版《膀胱癌TNM 分期手册》[9],分别通过对“肿瘤浸润深度”“是否有输尿管残端、输精管断端癌浸润”“是否有精囊腺、前列腺组织、子宫、阴道癌浸润”3 个字段和“区域淋巴结浸润情况”字段的抽取结果推理得到T、N 分期。“M 分期”也属于推理字段,需要以影像学记录中“肿瘤转移情况”字段抽取结果并结合分期依据推理得到。

表2 抽取的结构化字段Table 2. Extracted structured fields
1.2 抽取方法
本研究是基于Python 环境下利用RE 进行文本信息的抽取。
1.2.1 正则概述
RE 提供对于基本字符、特殊字符、数量词、边界位置等文本的匹配。每一个字符代表不同的匹配规则,例如,字符“d”表示匹配数字字符;“*”“+”“?”分别表示匹配前一个字符零次或多次、一次或多次、零次或一次;{n, m}表示匹配至少n 次,最多m 次。完整RE 规则可参考相关文献[10]。
1.2.2 数据集划分及字段词典编写
使用随机抽样的方法,从入院记录、病理记录、手术记录、影像学记录四个表单中分别抽取300 条数据的样本,其中200 条用于规则抽取集,100 条用于评测集。通过人工抽取规则抽取集中的结构化数据,得到目标字段的不同描述,将其归纳总结为规则集,即字段词典(示例见表3)。以字段词典为规则撰写RE。

表3 字段词典示例Table 3. Example of field dictionary
1.2.3 正则抽取实现
在Python 编译器中,主要通过Python 强大的库和re 模块实现正则抽取。本研究整体抽取方法流程图见图1。
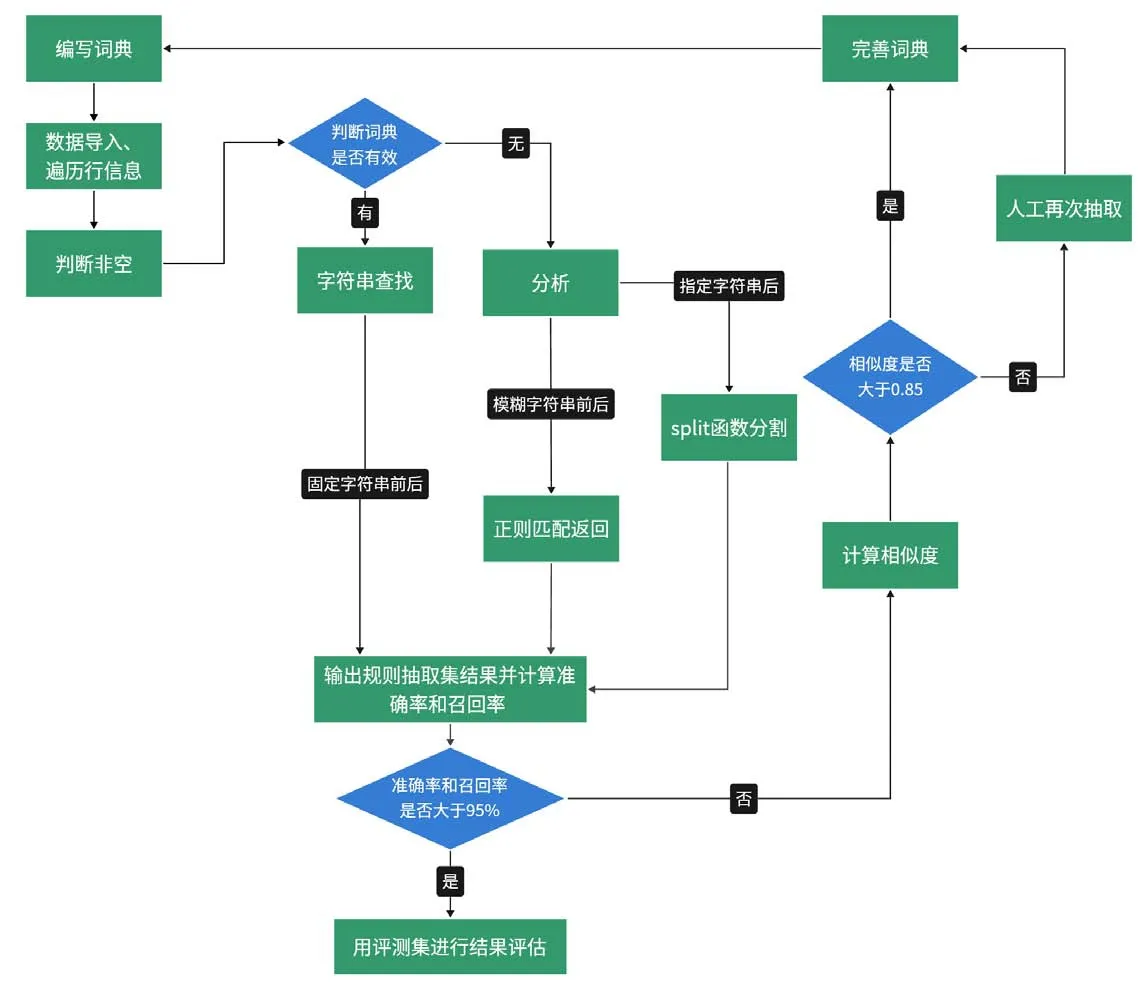
图1 抽取方法流程图Figure 1. Flowchart of extraction method
步骤一,数据导入及遍历行信息。使用pandas 库中的dataframe,读写Excel 表格工作簿以及单元格信息,利用read_excel 对工作簿赋名及操作。本文以“病理记录”工作簿(赋名为df)的处理情况示例。读取“病理诊断”信息列(即目标字段所在列)信息后,对每一列分配出独立的代码块,利用for i in range(len (df))完成对df 工作簿每一行的遍历工作。
步骤二,判断非空。某些信息列中存在信息缺失的情况,此时单元格的类型被判定为float 类型,而float 类型不支持有关字符串处理的内容。直接利用步骤一的方式遍历会报错,因此需要在进入遍历后且参与if语句判断之前,利用if type (df['病理诊断'] [i])!=float 对信息列是否空白进行判断,非空白的行再进行下一步操作。
步骤三,判断词典是否有效并抽取结构化信息。包括以下几种情况:(1)若词典有效,可直接抽取出信息列中的字符串,如“分级”字段需要抽取出文本中的“高/中/低分化”“高/低级别”或“1/2/3 级”;或查找信息列中是否有特定的字符串,如“是否为膀胱标本”“是否包含肌层”等。(2)若词典无效:在本研究中,主要有以下两种情况:①需要“指定字符串后”处理的组合字段,如“区域淋巴结浸润情况”需要抽取出淋巴结的位置及对应的送检淋巴结与阳性淋巴结的数量,需要利用split 函数识别关键词,由于该字段需抽取出不同位置淋巴结浸润数量,因此将抽取出来的数量存储到局部变量里,以便对不同区域的淋巴结进行描述。②需要“模糊字符串前后”处理的字段,通常无固定词组搭配,如“膀胱肿瘤直径”常在“新生物”周围出现,应抽取出“新生物”前后若干字符中含有的数字,即肿瘤的大小;或是在同一词组后跟随有干扰信息,如“入院记录”中的“饮酒时间”字段常跟在“饮酒史(年)”后,但该字符串后不仅有饮酒时间,还有判断是否饮酒的结果。利用RE 中的re 函数re. findall(pattern, string, flags=0),可将所有匹配内容以列表形式返回。可以定义任意pattern 为匹配模式,选择所要匹配的内容。
步骤四,输出规则抽取集结果计算准确率和召回率,计算相似度并完善词典。使用上述代码对规则抽取集进行字段抽取并输出结果,将该结果与人工抽取结果进行比对并计算其准确率和召回率。准确率=正确抽取的数量/已抽取到的数量,反映查准率;召回率=正确抽取的数量/待抽取的数量,反映查全率。
在根据规则抽取集抽取结果对词典进行完善以及后期根据新的语料补充词典时,需要人工对RE 未能抽取出结果的文本进行抽取,该工作耗时耗力,故本研究利用自然语言处理方法,首先利用jieba 库进行中文文本的分词工作words=jieba. lcut(s),然后利用Word2Vec 模型对每一个分词的结果转化为向量(Vector)。
for word in words:
v+=model [word]
接着将所有的Vector 相加并求平均,得到整个句子的词向量(Sentence Vector)。
v/=len(words)
将关键词已经纳入词典的信息列与其余信息列比对,并对Sentence Vector 夹角的余弦值计算相似度,挑选相似度高(>0.85)且用RE 无法抽取出结果的语句,用这些语句进行词典更新,可大大减少人工工作量。
审核规则抽取集准确率和召回率低于95%的字段,通过上述过程完善词典。同一个变量中不同的描述字段均有一定的相似性,因此通过计算词典中已有字段和词典中没有但信息列中存在字段的相似度,筛选出相似度较高的字段,由机器直接提取,录入词典;相似度不高的字段则通过人工再次提取的方式录取词典进行再提取。重复执行以上步骤直到目标字段的召回率和准确率高于95%。
步骤五,采用评测集进行结果评估。使用经由人工抽取并加以完善后的词典对评测集字段进行抽取,计算其准确率和召回率。由于EMR 数据存在稀疏性特点,部分字段只存在于个别患者的记录中,目标字段的缺失率将对抽取结果有显著影响。因此本研究设定了评测集目标字段缺失率的最大阈值为40%,若人工抽取的结果显示该字段缺失率大于40%,则将从数据源中重新抽取数据对原评测集进行补充,直至该字段缺失率降低至40%以下,以此作为新的评测集,进行结果评估。
1.3 代码示例及详解
以“区域淋巴结浸润情况(送检淋巴结位置、数量及阳性数量)”和“饮酒史:时间(年)”字段抽取为示例进行代码展示及解释,详见框1。

框1 部分目标字段抽取代码示例Box 1. Code examples for some target fields extraction
(1)字段“区域淋巴结浸润情况(送检淋巴结位置、数量及阳性数量)”属于词典无效字段并且需抽取信息位于指定字符串后。这类字段有多种情况,此处选取一种送检(左、右闭孔)情况进行说明,使用split 函数将“(左、右闭孔”后,“、”前的内容抽取出来,并存放在局部变量a 中,一般为左闭孔淋巴结的数量,再通过分割将第一个“枚”字后和第二个“枚”字前的内容抽取出来,一般为右闭孔淋巴结的数量,存放在另一个局部变量b 中,若有癌转移,且a、b 变量中含有“/”时,前面的数字代表阳性淋巴结的数量,后面的数字代表送检淋巴结数量,用split 函数将两个数字分别分割出来,存放进不同的局部变量。
(2)入院记录中的字段“饮酒史:时间(年)”属于词典无效字段并且需抽取信息位于模糊字符串后。为抽取“个人史”信息列中的饮酒年份,使用re. findall 函数查找,并用RE 规则d+,抽取出在“饮酒史(年)”后的所有数字以列表形式返回。
2 结果
在对评测集中缺失率过高的字段进行补充抽样后,本研究以“未删除缺失数据集”“删除缺失数据集”为评测集分别进行结果评估,若将缺失值认为是抽取结果之一,那么可得到包含所有正误对比的完整结果,但无法直观获得准确率和召回率对于字段词典的准确性、完整性以及RE抽取效果的不同体现,因为已抽取到的数量即为待抽取的数量,准确率和召回率的结果相同。如果删除缺失,即待抽取数量只包含有目标值的情况,区别于已抽取数量,将得到不一致的召回率和准确率从而对正则抽取效果进行评估,但是因为空值均被删除,无法反映实际为空却被RE 抽取到了错误值的情况,因此同时报告两个数据集的结果,进行综合评估。结果详见表4。
未删除缺失数据集的评估结果显示,病理记录中的大部分目标字段准确率和召回率均可达到80%以上,只有3~4 个目标字段准确率和召回率低于80%但水平仍可达到60%~80%之间;手术记录中的“膀胱肿瘤是否单发”“膀胱肿瘤直径”“膀胱肿瘤位置”和影像学记录中“膀胱肿瘤直径”字段的准确率和召回率相对较低,在60%左右,手术记录和影像学记录中其它目标字段的准确率和召回率均可达到95%以上;入院记录的所有目标字段召回率与准确率均在90%左右。
删除缺失数据集的评估结果显示,大部分目标字段的准确率较未删除前有显著提升,可达到95%以上;但是召回率结果差异较大,病理记录中目标字段平均召回率在75%左右,手术记录中目标字段平均召回率约为63%,入院记录中目标字段平均召回率为94%,而影像学记录中除“膀胱肿瘤直径”召回率为37%外,其余字段召回率均高于90%。
3 讨论
本研究结果显示,总体上基于RE 方法抽取目标字段的准确率较高,说明人工总结的字段词典的查准率较高、准确性较强,原因可能是基于RE方法的信息抽取可精准匹配特定的文本模式。但是基于RE 方法抽取目标字段的召回率相对较低且差异较大,反映出在部分字段上词典的查全率相对较低,完整性相对较差。原因可能有两种,一是由于规则抽取集不够具有代表性,导致人工总结的词典不够完整,后续可通过增加规则抽取集、迭代完善词典的方式解决;二是文本中目标字段对应的语言结构复杂、文本表述变化多样,RE 方法难以归纳概括全部规律而导致漏抽,查全率低,需要尽量全面总结字段表达规律以改善抽取结果。需注意的是,对高缺失率目标字段补充抽样时,受限于原数据,个别目标字段如“是否浸润神经”“戒烟时间(年)”等的补充抽样仍不能达到缺失率小于40%的目标,其评估结果可能随着包含目标值样本量的增大而波动。
既往有研究者以层叠条件随机场机器学习模型为基础,对包含入院记录、出院记录、辅助检查报告等非结构化文本的呼吸专科住院EMR 进行了信息抽取,结果显示病历中各类文本信息抽取准确率和召回率分别为92.12%、92.42%[11]。与本研究抽取结果对比发现,一方面,基于RE的信息抽取方法其准确率较高,对于大部分变量可以达到98%甚至是100%的准确率,但是召回率就显著逊色于基于机器学习的信息抽取方法,因为RE 无法抽取规则集之外的文本信息;其次,对于表述简单的字段,如病理记录中的“是否为膀胱标本”“是否为膀胱尿路上皮癌”等字段,或半结构化文本中的字段抽取,如入院记录,RE规则集的编写会相对简单,其抽取效果优于机器学习,可达到较高的准确率和召回率(98%以上)。但是对于像影像学记录与手术记录中的“膀胱肿瘤直径”“膀胱肿瘤位置”等表述形式较为繁杂的非结构化文本,由于自由度过大、语法语义复杂,基于人工编写规则的信息抽取方法就难以较好归纳概括其表达规律,导致规则的编写过程耗时耗力,抽取的效果不佳。
本研究对于四类文本规则集归纳总结的时间耗时较久,侧面说明RE 的人工依赖性较强。某些字段在文本中的出现频次低,其固有稀疏性导致研究者难以充分总结表达规律,而文本中有时出现的不规范数据输入情况也会直接影响规则集的总结和抽取结果的可靠性,并且在前期规则集的编写过程中需要大量的人工参与,而人工制定规则集的质量由文本的结构化程度决定并直接影响最终信息抽取效果。例如吴欢等的研究表明,针对语义简单、结构规范的文本,基于规则的模式匹配方法的信息抽取技术更简单、快速、易实现[12];对于像冠状动脉CT 血管成像及钙化积分这类单病种且比较规范的报告,RE 是实现其结构化的最佳投入产出比方案,其制定的规则对于报告的结构和语言描述具有较高的依赖性[13]。RE 始终是基于人工制定的规则进行信息抽取,但是由于RWD 的多样性,可能会出现字符一致但是语境不同而导致抽取错误的情况,需要人工对表达式进行完善,也可能会影响该方法的适用、推广和维护。
需要注意的是,RE 规则集跨学科、跨单位、跨病种的可迁移性和可复用性较弱。在不同学科之间各类文本所涉及知识、术语、数据大相径庭以及RE对于规则集准确性有着高要求的前提下,对于某一学科中某一文本构建的规则集难以进行跨学科迁移。因不同机构、系统或医生记录习惯的不同,可能会导致无法实现规则集的大规模跨机构使用。对于围绕单一病种EMR 记录构建的规则集,除入院记录中部分信息不具有疾病特异性,大部分记录如病理记录、手术记录、影像学记录等均具有疾病特异性表达,其规则集难以跨病种。
在对规则抽取集的词典进行革新迭代过程中,本研究采用了计算文本相似度的方法,通过计算无法抽取出信息或新纳入的文本与已归纳总结出规则集文本的相似度进行比对,从而提高词典更新的效率,一方面可减少人工工作量,提高信息抽取的召回率与准确率,另一方面则可更准确、高效地服务于新文本数据。该方法可以在一定程度上为上述RE 规则集可迁移性、可复用性弱以及人工依赖性强的问题提供解决思路。
近年来,越来越多的研究者将目标聚焦于医疗文本中结构化信息的抽取,相关的方法与算法优化不断涌现。例如安辉对RE 可视化编辑的实现,以降低RE 的学习和使用难度[14];相关研究者提出的基于文本表示的RE 自动生成技术,可大大减少研究者概括规则集、撰写RE 过程中耗费的时间以及人力资源成本[15];同时ChatGPT 类大型预训练语言模型的出现和发展,也为文本挖掘、信息抽取领域开辟了新的途径[16]。吴骋等积极探索新的多层次信息抽取模式,实现了对医疗文本中各种信息的多维解析与分类存储[17]。抽取方法的不断革新为医疗大数据的价值挖掘提供了有力抓手。
对于研究中发现的问题,可考虑以下解决方法:选择基于统计学方法的信息抽取方法,如机器学习、深度学习等,以大量样本数据为训练集进行模型训练从而实现对于非结构化数据的信息抽取[18]。已有研究者采用机器学习方法识别并抽取病历中药物滥用和药物使用障碍等相关信息[19];从源头解决数据质量差、结构化程度低的问题,加强医院信息系统的顶层设计,树立医务人员对高质量数据价值的正确认识,规范医务人员对EMR 等医疗数据的书写和核对,提高数据的结构化程度和质量。
本研究以RE 为基础,针对膀胱癌EMR 数据开展实践应用,具有一定的应用价值,但该方法存在一定局限性,诸如人工依赖性较强,部分字段抽取的准确率与召回率偏低等问题。并且本研究并未对RE 规则集在跨病种、跨单位等的其他数据集上的抽取效果进行测试。后期研究团队将使用基于Transformer 架构的深度学习模型对相同的数据进行信息抽取,并对比二者在操作流程、适用样本、构建时间、构建难度、抽取效率、抽取效果等方面的优劣,并纳入其他单位以及其他病种的EMR 数据,以此为基础构建可视化平台,为研究者提供参考。
