分子体系自由能地貌图的变分分析及AI 算法实现*
2024-04-02杜泊船田圃2
杜泊船 田圃2)†
1) (吉林大学生命科学学院,长春 130012)
2) (吉林大学人工智能学院,长春 130012)
精确描述复杂分子体系的自由能地貌图是理解和操控其行为,并进一步实现分子设计制造工业化的重要基础.刻画高维空间自由能地貌图的主要挑战是其往往在不同时空间尺度上具有多个层次,每个层次都可能有不止一个亚稳态被相应的自由能垒分开,且跨越路径有可能不止一条.另外很多体系涉及非线性行为,这使得理论解析和直接使用分子模拟都有很大困难.针对这些挑战,多年来研究者们发展了多种多样的增强采样方法,但往往需要很多经验选择和操作,从而一方面使得研究进程较为缓慢,另一方面也让误差控制成为困难.变分虽然在物理、统计和工程中已经被广泛应用并取得巨大成功,但在复杂分子体系中的应用却随着神经网络的发展刚刚开始.本文将对这些探索性工作的主要方向、进展和局限进行简要总结,也对将来的可能发展给出展望,希望能够激发更多对基于变分的分子体系自由能地貌图人工智能算法的关注和努力,促进大分子药物、分子生物机器等实践应用的发展.
1 引言
大多数复杂分子,尤其是生物大分子体系,都是通过构象变化或者在一定尺度上的相变实现其功能的[1–6].和诸多分子的实验合成与表征测试过程相比较,一方面分子模拟的代价往往更低廉;另一方面很多生物大分子复合体的大量合成非常困难甚至不可能,或者在能够获取的前提下动态表征很难实现.因此分子模拟被广泛用于研究复杂分子体系[7–9].决定分子体系各种行为的基础是对应的自由能地貌图,因此对其准确刻画成为必要.实现这一目标的主要挑战是复杂分子体系一般不止一个亚稳态并且相互之间有较高的自由能垒.所以对典型的复杂分子体系(如核糖体),想要从全原子分子模拟中完成所有亚稳态的充分采样,观察对应的构象变化过程往往需要生成毫秒级甚至更长时间的模拟轨迹[10].这对百万或更多原子的分子体系一方面算力需求很难满足,另一方面在高维空间中理解所生成的轨迹也很不容易.因此人们发展了各种各样的增强采样方法[11–26]和轨迹降维分析方法[27].增强采样方法大致可以分为两大类,一类是保持分子体系的玻尔兹曼分布不变,通过改变温度加速分子体系跨越能垒的方法[12,13].另外一类则是通过加持偏置力/势(bias force/potential)(如元动力学方法[8]、自适应偏置力方法[28]),这类方法的主要依据是虽然一般分子体系的总自由度数目成千上万甚至更多,但在跨越能垒的时间尺度上很多局部的原子运动都由于时间尺度的分离而成为近似白噪声,使得体系在对应时空间尺度的运动可以用较少的反应坐标(reaction coordinates,RC)或者集合自由度(collective variable,CV)成功描述,下文中统称集合自由度(CV).这类采样算法的主要困难是集合自由度的构建没有系统的方法和步骤,研究者往往依靠物理直觉选择部分体系自由度进行组合尝试.由于我们生活中感受到的都是三维空间中的物理存在,所以在体系维度升高后直觉判断的准确性会大打折扣.如何准确地构建有效的CV是目前复杂分子体系模拟中尚未解决的重大挑战之一.集合自由度空间中主要有3 类互相关联的问题,其一是准确描述体系的集合自由度的构建;其二是绘制出该空间内主要亚稳态所在的构象空间位置和统计权重,并计算不同亚稳态之间的转化速率;其三是构建不同亚稳态之间的过渡路径.这几类问题的传统应对策略已经被多个优秀综述覆盖[14,29–41],本文主要简述变分及其神经网络实现在这些领域的应用,限于作者所熟悉研究工作的范围,会遗漏一些优秀的研究进展,在此表示歉意.
本文的内容组织如下,首先将对CV、变分和神经网络及自动微分进行简要说明,其次对目前已有的针对复杂分子体系自由能地貌图的主要变分构造方法加以讨论,再次对这些基于变分的和其他CV 相关的神经网络方法进行比较分析,最后展望将来的发展.
2 集合变量、相关神经网络架构、自动微分和变分简介
对一个在给定温度T和势能U(R) 下的分子体系,用R表示其 3N-3 维坐标,则平衡态玻尔兹曼分布为µ(R∫)=e-βU(R)/Z,其中β=(kBT)-1为逆温度,Z=dRe-βU(R)为配分函数,kB为玻尔兹曼常数.在较长时间尺度上,这个分子体系的动力学一般可以使用比 3N维度低很多也平滑很多的d(d≪N) 维自由能面描述,对应一组由原来坐标R的函数构建的新变量s(R)=(s1(R),s2(R),···,sd(R)),分子体系自由能在这个低维空间也可表示为
人们通常称这组新变量s(R) 为集合变量,δ(·) 表示δ函数.
神经网络是目前人工智能技术浪潮的核心理论方法,简而言之是由多个神经元组成的复合函数网络.每个神经元可以接受不同维度的输入,经过线性组合和非线性激活函数作用后输出.虽然原则上神经元之间的连接可以是任意的,但受视神经分层分布的启发和随之带来的并行计算方便,常用的各种神经网络架构都是层状结构.神经网络最有力的特点是只需要一个隐藏层,足够多神经元组成的网络就可以无限逼近任意函数映射,这就是著名的万能逼近理论(universal approximation theorem)[42–44].但这个理论并没有指出如何在有限的神经元数目的情况下有效拟合各种映射,所以其发现虽然在很大程度上增强了人们使用神经网络拟合各种函数映射的信心,却并没有迅速推动其在诸多实际问题中的应用.后来多种神经网络架构(卷积[45]、循环[45]、残差[46]、注意力机制transformer[47]和扩散模型[48])的发展推动了神经网络在多个学科领域应用的爆发.当然另外一个不可或缺的基础是自动微分的发现[49]和在神经网络中的成功应用[50],这使得理论上基于任意阶导数的优化方法都能够被有效用来训练神经网络参数,当然实际应用中由于算力和内存限制,人们往往限于使用基于一阶和二阶导数的优化方法,诸多具体实例和相关文献可以参考 PyTorch 中的 Optim 模块.如下所述,在众多神经网络架构中,分子体系自由能地貌图刻画中应用最为广泛的是自编码器(auto-encoder)架构[51](如图1 所示),该架构把高维输入映射到一个低维空间的降维部分被称为编码器(encoder),而随后从低维逆向映射到高维(一般与输入同维度以方便训练)空间的部分则被称为解码器(decoder).这显然与人们试图在更低维度空间理解复杂分子体系的目标在形式上较为吻合.虽然在架构形式上非常相似,但变分自编码器(variational auto-encoder,VAE)[52]的目标和训练过程却与自编码器显著不同,其中的隐变量(z)是个概率分布而非特定构型.如果分别用ϕ和ψ表示编码器和解码器网络中的参数,qϕ(z|x)和pθ(x) 表示隐变量(z)和(x)的分布,则似然函数可表述如下:
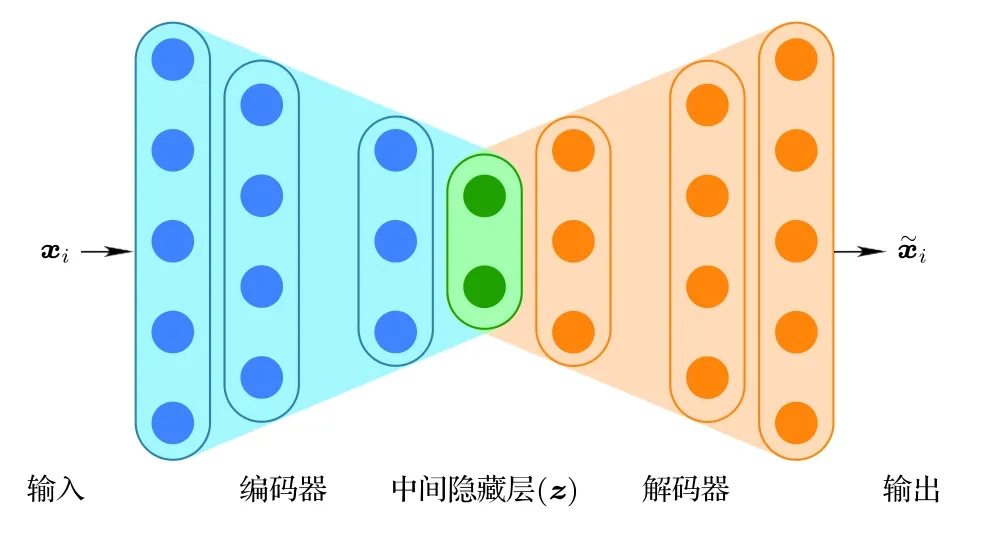
图1 自编码器神经网络架构示意图,蓝色部分表示编码器(encoder)函数 f(·),橙色部分表示解码器(decoder)函数 g(·),维度最低的绿色表示中间隐藏层(z),对自编码器,损失函数是输出()与输入 xi 的差别的函数(也可以加正则化项,如参考文献[58] (5)式所示),每一个输入数据点对应隐藏层空间的一个点Fig.1.Schematic representation of an auto-encoder neural network.The blue part on the left represents the encoder,the orange part on the right represents the decoder,and the middle green layer is the hidden layer (z).The loss is always a function of the difference between the input and the output vectors (xi and ),one may add some form of regularization when necessary (e.g.Eq.(5) in Ref.[58]).
其中,DKL(qφ(z|x)||pθ(z|x))≥0,所以Lθ,φ(x)=Eqϕ(z|x)[logpθ(x,z)-logqϕ(z|x)] 就是似然函数的下界,也称为证据下界(evidence lower bound,ELBO)或变分下界,是变分优化的目标,而非自编码器中解码器输出构型与数据中实际构型差别的函数.为了对随机隐变量(z)对自动微分,Waterfall等[53]发展了二次参数化技巧(reparameterization trick).
变分的历史非常悠久,也是诸多理工科研究生的必修课程内容.变分在物理、统计和工程领域都已经取得了非常广泛和成功的应用[49,54],如量子力学中的 Releigh-Ritz 方法[55]也正是本文中要讨论的分子体系变分计算的基础.另外统计学中的大量应用展示了变分推断方法同采样计算相比高效、收敛性较好和更容易扩展的特点[56,57].在神经网络广泛应用之前,由于各种未知统计分布的解析和(或)参数化构造较为困难,因此基于平均场的变分成为统计变分分析中最为常用的近似[56].但在分子模拟及其增强采样中的应用却在最近十多年才陆续发生.原因主要有两点,其一是和很多统计模型与工程应用不同,分子体系中的集合变量很难找到直接的方程或模型解析描述,其二是传统数值拟合方法(如最小二乘法[58])中导数计算昂贵且精度不高,各种优化方法实现困难,而且在变量较多(大于10 个)时会收敛困难[53].不过最近十多年以来基于自动微分[49]的多个人工智能框架Pytorch[59],Tensorflow[60],PaddlePaddle[61]迅速发展成熟,与之伴随的神经网络架构[62]也得到了迅猛发展.这使得在拥有较为充足数据的前提下,任意函数的稳健拟合成为可能,因此增强采样和轨迹分析的变分应用也随之发展.传统上人们探索复杂分子体系自由能地貌图的主要手段是(加速)采样,变分的突出优点是用优化取代采样过程,从而显著提高效率.现代神经网络架构的强大拟合能力和基于自动微分的各种优化方法的结合为变分在复杂分子体系中的应用提供了巨大的潜力空间.这也正是本文想要讨论的话题.
3 分子体系集合变量空间的变分方法
同物理学、工程和统计应用比较,变分在复杂分子体系自由能地貌图应用相对较少,主要是近十多年的工作,不过目前正在迅速增长中.目前的发展大致可以分为利用转移矩阵算子特征值和特征向量频谱分解分析(spectral decomposition analysis)的变分构建[63–68];基于自由能垒跨越概率时间关联函数的变分[69–71];利用偏置势(bias potential)的变分构建[72];不受线性假设局限的可汇集性(lumpability)与可分解性(decomposobility)泛函变分构建[73];基于过去-将来信息瓶颈的变分构建[74,75];同时考虑粗粒化、集合变量和增强采样的自适应[76];以及直接利用变分自编码器的分析[77],这些方法的简要总结比较见表1.具体如下所述.
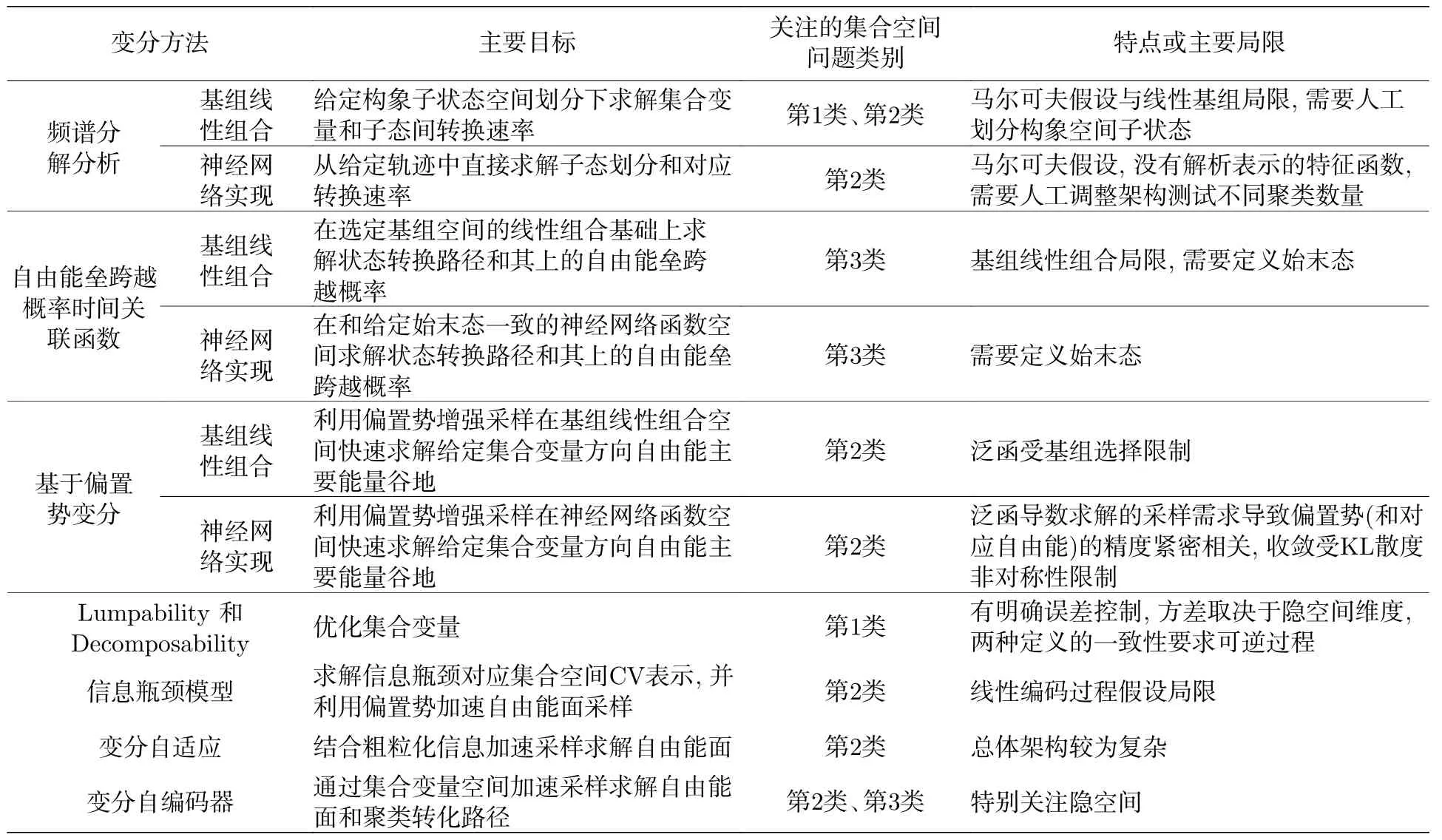
表1 复杂分子体系低维隐空间的变分方法简要总结,表中所述集合空间问题类别是指引言中提到的三类问题Table 1.A brief summary of variational methods for low-dimensional hidden spaces in complex molecular systems.The category of collective space problems mentioned in the table refers to the three types of problems defined in the introduction.
3.1 频谱分解分析
在严格马尔可夫过程和细致平衡假设下,针对给定的子态构象空间划分,Perez-Hernandez 等[65]发展了利用演化算子P(propagator)特征函数自相关构建的变分实现了对最慢动力学过程集合变量(CV)的逼近,分子体系动力学可以被下式表述为演化算子特征函数ϕi(i=1,2,···,∞) 的叠加:
其中ti是和第i个特征值λi(τ)=e-τ/ti对应的时间尺度,尖括号代表标量积,〈ψi,ρt〉的结果表征概率密度ρt和ψi的重叠程度,体现了第i个特征函数对总体动力学的贡献.因为ψi=µ-1(x)ϕi,也可以认为概率密度函数ρ是基于特征函数ϕi展开的.显然随着τ→∞,概率密度会趋于平衡态,(3)式中只有第1 项有贡献,对应于λ1=1 .如果人们感兴趣的时间尺度τ≫td+1,则分子体系的动力学主要取决于对应于 (λ1,λ2,···,λd)的d个特征函数,也对应于前面(见方程(1)中的s(R) 定义)所说的d个集合变量.(3)式可近似为
对于分子体系坐标的任意函数f(x),其自相关函数可以表述为
显然如果取f=ψi(x),则
显然(8)式中转化过程χ0和χ1一般是非线性并且未知的.神经网络的可训练万能逼近能力为其构建未知转换的提供了可能性.VAMPNets[67]正是在这种思考下构建的.对于给定的χ0和χ1变换可以构建3 个方差矩阵:
这些方差矩阵被用来构建了一个VAMP-2 打分[66]:
该分值最大化时对应在转化后的低(d)维空间分子构象分布被准确复现.以这个分值作为损失函数的神经网络通过训练就有可能实现从体系原始高维坐标向低维空间较为准确的映射,实际上起到了低维空间模糊分类器的功能,消除了前述变分理论[65]中对人工聚类及以前各个步骤的需求.具体实现架构如图2(a)所示[67].对丙氨酸二肽体系,Mardt 等[67]利用图2(b)的特定架构,设定低维空间类别数目为6(也尝试了从2—8 的其他类别数目),首先从250 ns 的分子动力学模拟轨迹中每皮秒提取一帧得到250000 个构型,并通过和第一帧对齐除去分子的整体平移和旋转.使用十个重原子的三维空间(即长度为30 的向量)坐标作为神经网络输入,取延迟时间τ=40 ps (也尝试了从4—32 ps的其他延迟时间),通过最大化VAMP 打分,成功实现了在二维二面角空间 (φ,ψ) 的构象聚类.他们同时使用MSM 流程聚类,当构象类别数目小于20 时得到VAMP 打分都低于VAMPnets 的结果.此外Mardt 等[67]还尝试分析了简单双势阱和NTL9蛋白折叠轨迹,均展示了和原来人工复杂流程可比拟的准确性,也说明这个思路有望在将来通过逐步发展真正实现自动分析分子模拟轨迹得到动力学特性的可能性.不过目前该方法还不够成熟,尚不能用于多系综组合数据[79–84],也不能有效集成模拟轨迹与相关实验数据,另外还缺乏严格清楚定义的误差估算指标[85–87].但该研究结合变分理论和非线性的神经网络拟合,取代了原来 MSM 方法管线中一系列复杂步骤,并在简单体系中实现了首次成功应用,是人工智能用于分析复杂分子体系轨迹的重要进展.VAMPNets 的神经网络架构较为简单,鉴于图神经网络[88–91]和注意力机制[92]在网络型数据中的优异表现,考虑到复杂分子体系可以被视为由相互作用的单元构成的网络图,Brooks 等[93]构建了包含这两种架构要素的 GraphVAMPnet,该模型实现了更高精度的构象嵌入表示,也能够通过注意力机制给出蛋白质中对结构聚类起决定性作用的重要氨基酸.在20-氨基酸的 Trp-cage 蛋白,35-氨基酸的 Vilin 蛋白和 NTL9 蛋白轨迹上的成功应用展示了这些神经网络构架改变的好处.
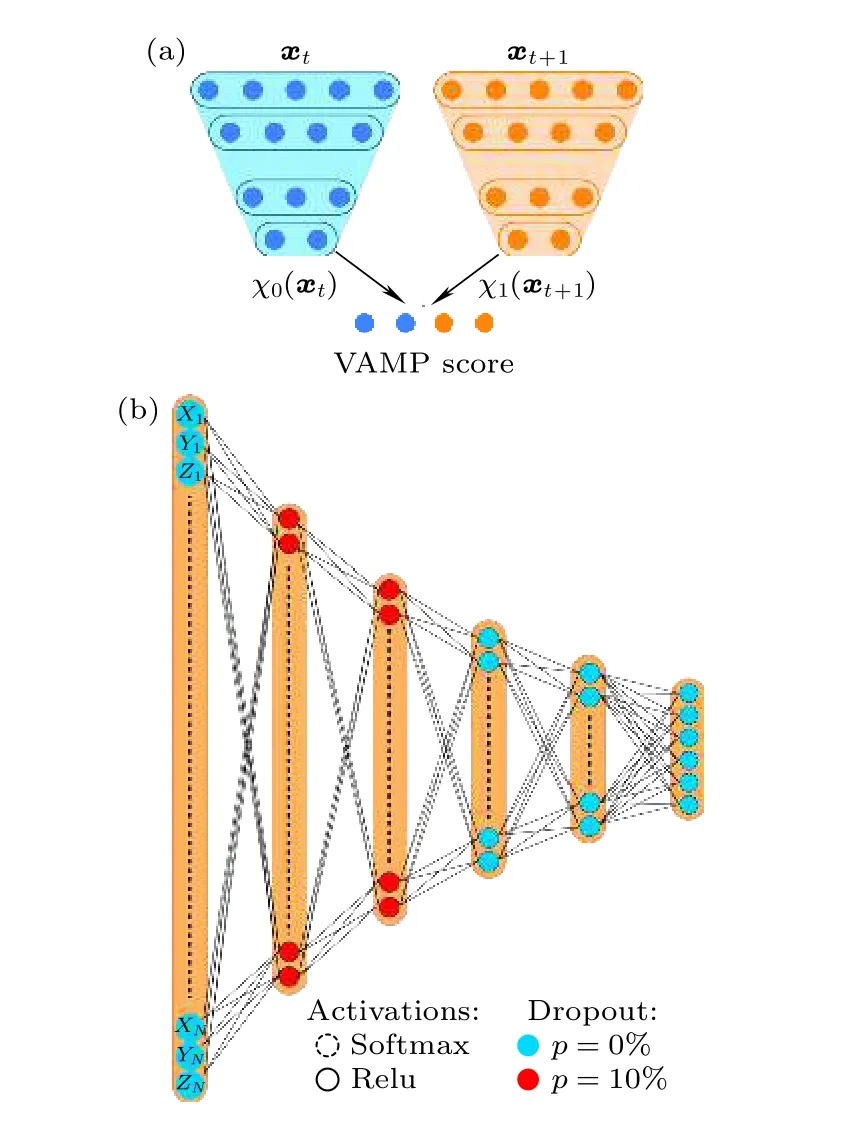
图2 (a) VAMPnets 构建VAMP 打分((10)式)的神经网络总体架构示意图;(b)丙氨酸二肽轨迹分析实例中的典型神经网络架构,各层神经元数目为 32-22-16-9-6,前两层使用10%的dropout,除最后的softmax 层外,其余各层激活函数均使用Relu[67]Fig.2.(a) Schematic illustration of VAMP score construction from VAMPnets (see Eq.(10)).(b) A typical neural network architecture for analine dipeptide analysis,with the number of neurons being 32-22-16-9-6 for five layers.The first two layers utilized a 10% dropout.Relu was selected as the activation function for all layers except the last softmax layer[67].
随着人们使用电子显微镜解析生物大分子复合体的能力越来越强,如何解释这些复合体的动力学过程变成了亟待解决的问题.为了增进处理较大分子的能力并在将来能够有可能延伸到大复合体,Noé等[94]结合独立马尔可夫分解方法(independent Markov decomposition,IMD)构建了由多个独立的VAMPNets 构成的iVAMPNets.其中不同独立模块的划分由一个可训练的MASK 实现,通过竞争训练使每个不同的子网络仅处理不与其他子网络相互重叠的部分.虽然该方法在Synaptotagmin-C2A 蛋白质分子中成功应用,但显然这种处理仅适用于不同子模块间耦合程度较弱的情况,距离准确描述不同组成分子之间有较强关联的复杂复合体仍然有较大距离.利用VAMPNets 输出的子构象空间(状态)概率,Kleiman 和Shukla[68]尝试了结合3 种不同后续处理,包括最小计数(least count,LC),多目标强化学习(multiagent reinforcement learning-based,MA REAP)和最大熵(MaxEnt),显著促进了构象空间搜索能力.这3 种方法的宗旨基本一致,就是利用前期生成的轨迹对VAMPNets 进行初步训练后,在后续的采样中按照上述不同标准聚焦前期采样最少访问的构象空间,从而实现更进一步的增强采样.其中最大熵和VAMPNets 的结合在促进采样的同时消除了聚类步骤.
3.2 自由能垒跨越概率时间关联函数的变分
弦方法[95–99]和过渡路径理论(transition path theory,TPT)[40]致力于寻找不同亚稳态之间过渡路径及其过渡态的关键细节.不过这些方法在得到最低自由能过渡路径的同时,却不能直接给出人们非常感兴趣的路径上任意一点的 自由能垒跨越概率.针对此问题,文献[71,100]基于两个亚稳态之间的净向前反应通量构造了自由能垒跨越概率时间关联函数,发展了通过变分最小化该函数获得最佳过渡路径并同时给出自由能垒跨越概率的方法.对两个亚稳态 A和B,集合变量空间从A 到B 在时间步长τ基于算子Pτ(s′|s) 的向前演化可表示为
其中ρ(s,t)和ρ(s′;t+τ) 分别对应于时刻t(t+τ)在路径位置s(s′)处的概率密度.则自由能垒跨越概率q(s),即从s开始最终到达亚稳态B 并且在此前从未到达亚稳态A 的所有过渡路径概率之和,可定义如下:
则净向前(从 A到B)反应流为
也可以表达为自由能垒跨越概率的自相关函数:
其中二次方形式可以作为任意给定始末态时尝试自由能垒跨越概率q(s′) 的变分优化目标.该方法使用基组展开,通过优化系数来达到变分优化的目标,在模型双势阱问题中展示了简化子空间(CV 空间)中理想一维反应坐标走向沿着 自由能垒跨越概率梯度,与高维空间中的 Kramers-Langer 理论[101,102]一致.文献[100]是针对过渡路径变分构建的首次尝试,并在双势阱问题和丙氨酸二肽中展示了应用.由于变分函数限于选定基组函数的线性组合空间,其结果显然会受到基组选择和线性组合的制约.Chipot 等[69]将自由能垒跨越概率时间关联函数的变分方法延伸到了神经网络(variational committor-based neural networks,VCN),从而可以拟合任意非线性映射.同基于特征值变分优化的 VAMPNets 相比较,在双势阱体系和N-acetyl-N′-methylalanylamide 异构化过程中均得到一致结果.不过显著不同的是 VCN 需要已知始末态,针对的目标是一对始末态之间的过渡路径,而 VAMPNets 则是从轨迹数据开始的无监督学习.另外一点是有时候人们最感兴趣的慢过程可能不是分子体系中最慢的过程,这种情况下显然VCN 更为适合.这两类方法可以协同使用从而结合其各自优势,当然也有可能在将来集成到更复杂的神经网络架构中.
3.3 基于偏置势的变分
在给定CV 的前提下,Valsson 和Parrinello[103]构建了一个基于CV 空间偏置势V(s) 的泛函:
其中p(s) 是一个自由选择的目标分布,这赋予人们使用该泛函的灵活性(当然也伴随着选择的挑战).该泛函是一个凸函数并且不随偏置势任意给定的有限常数的改变而变化.用F(s) 表示体系自由能,则当V(s)=-F(s)-(1/β)logp(s) 时,泛函Ω[V] 取极小值,因此在选定p(s) 的前提下通过参数化的V(s),以Ω[V] 极小值为目标的变分优化即可求解自由能地貌图.该方法使用线形基组组合在丙氨酸三肽分子中成功应用.另外,该泛函同Kullback-Leibler (KL)散度(DKL)的关系如下所示[46,104,105]:
其中PV和P0分别是 偏执势为V和0 时体系的概率密度分布.由于凸函数特性,使得偏置势与自由能面有确定关系的驻点也是其极值点.因此通过参数化偏置势,就可以对参数实施变分优化从而求解自由能面.这在原理上比元动力学采样方法要高效很多,不过,其表现受限于所选CV 在较长时间尺度上描述自由能面的能力.为了克服对该泛函线性展开可能出现的一些麻烦(比如自由能变化剧烈的区域需要很多项才能实现较好拟合,集合变量增大时需要变分优化的参数空间指数增长),Bonati 等[72]用神经网络表示偏置势泛函,在给定的集合变量定义下通过优化神经网络参数实现,如下所示:
泛函数值微分需要统计平均((17)式中的尖括号表示系综平均),因此需要采样获取.直接高精度确定最低点较为困难,因此Bonati 等[72]在实现过程选择获得达到一定近似程度的偏置势,评判的标准选用了pV(s)和p(s) 在迭代次数n时的KL 散度距离:
显然,此过程在数值实现中需要选定两个参数,一个是选定每次迭代计算KL 散度之间的模拟更新次数,另一个是每次更新时学习率调整的幅度.为了集成CV 构建和偏置势优化,Bonati 等[106]利用VAMPNets 的VAMP 打分作为损失函数,利用深度神经网络和TICA (time-structure based independent component analysis)结合生成CV,随后在更新的CV 空间采用OPES[100]增强采样思路,实现了CV 优化和自由能地貌图收敛的迭代.他们在丙氨酸二肽、chignolin 蛋白折叠和材料结晶过程的成功展示了该方法的应用[106].
3.4 基于可汇集性(lumpability)和可分解性(decomposability)的非线性变分描述
由于马尔可夫假设和特征函数构建中的线性假设,基于频谱分解分析的变分优化无法正确处理非马尔科夫过程[40]和线性无关特征函数之间的非线性关联,这些根本上的局限无法在后期变分优化中被消除.针对这个问题,Bittracher 等[73]通过延伸过渡流形理论(transition manifold theory)发展了不包含任何线性假设,只关注于长时间尺度分子体系行为,显式包含误差量且在可逆体系中互相等价的条件,lumpability和decomposability(详见文献[73]的definition 3.2,3.4),这两个条件都可以作为损失函数变分.此外该变分在近似损失函数时只要求在集合变量子空间的稀疏采样,而且损失函数的蒙特卡罗积分误差取决于集合变量子空间而非原高维空间的方差,这会带来巨大的算力节省.该理论和过渡路径理论的连接仍然有待阐明.另外这些理论上的优势在百万级甚至更大的复杂分子体系如何得以实现也有待于进一步探索.
3.5 过去-将来信息瓶颈模型
Wang 等[74]将分子体系中的集合变量空间视为其演化过程中的过去-将来信息瓶颈(pastfuture information bottleneck,PIB[107,108]),对 给定分子体系任意时刻坐标X和下一时刻坐标X∆t,通过瓶颈变量χ(与集合变量类似的分子体系低维空间描述)分别和编码器P(χ|X) 与解码器P(X∆t|χ) 联系 (注意文献[74]中结果部分第1段把坐标X误解释 为N个粒子 体系中的d维(1≪d≪N) 表示,容易引起混乱).PIB 的目标是瓶颈变量χ相对于过去应该尽量简单但对于将来则应该有尽可能好的预测力,Wang 等[74]据此构建了如下优化目标:
其中I(χ,X∆t)和I(X,χ) 分别 表示瓶颈变量与X∆t和X的互信 息,常数γ∈[0,∞) 用来平衡瓶颈变量χ的复杂程度和预测力.进一步通过选择确定性的线性编码器,则第2 项可以忽略.他们然后利用Gibbs 不等式构建了可变分优化的PIB 下限近似:
其中H和C分别表示香农和交叉熵,Qϕ为随机深度神经网络构建的解码器.由于选择Pθ为确定性线性编码器,香农熵项退出优化目标,可得更新变分下界:
其中ϕ为随机神经网络中的变分优化参数.对平衡态轨迹{X1,···,XM+k}(Xn和Xn+k之间的时间间隔为 ∆t),方程(20)可被离散为
其中χn从P(χn|Xn) 中采样得到.对于有对应偏置势{V1,V2,···,VM+k}下模拟的轨迹则可在假设偏置势不改变解码器的情况下近似表述为
实际计算中Wang 等[74]选择用坐标的线性基组组合得到CV,首先对平衡态轨迹通过逐步增加 ∆t观察基组各项的权重变化,并取其趋于稳定后最小的 ∆t.随后则按照方程(24)和(25)计算偏置势并重新估算机组系数,反复迭代:
其中w=eβVbias,Pu(χ) 是没有偏置势的情况下χ的平衡态分布.简单的确定性线性编码器在带来方便的同时也在一定程度上限制了该方法的灵活性,但PIB 的优点之一是原则上没有其他线形假设,不过在PIB 思路下(见(19)式)使用非线性编码器后的变分优化方法仍有待发展.该方法在苯-溶菌酶复合体模拟中获得了成功,在几百纳秒的加速模拟中观察到了几百毫秒常规模拟所观察到的解离过程.Beyerle 等[75]后来使用该方法成功描述了双势阱模型和苯甲酸在双分子层膜中扩散这两个分别由能量和熵主导的过渡路径,进一步展示了该方法的稳健性.
3.6 变分自适应
与前述变分方法主要关注集合变量和偏置势不同,对有明确集合变量的情况,Zhang 等[76]结合生成式深度学习和基于能量模型[109](energy based models,EBM)发展了对抗密度估计变分,直接计算自由能地貌图中的概率密度分布.将平衡态真实自由能对应的概率分布记为p,在集合变量空间的参数化自由能地貌图和对应的分布分别记为Fθ(s)和pθ(s),则KL 散度DKL(p||pθ)对θ的导数可表示为
其中〈f(x)〉p(x)表示函数f(x) 在分布p(x) 下的期望值.(26)式和对抗神经网络[76,110]高度相似,因此在原文中被称为变分对抗密度估计 (variational adversarial density estimation,VADE).在实际操作中可以用粗粒化实验数据PFG(s) 取代真是分布p.再通过粗粒化模拟计算〈β∇θFθ(s)〉pθ(s).对于集合变量维度较高的情况,由于直接采样计算代价过于昂贵,Zhang 等[76]通过加入可训练生成神经网络模块作为神经采样器(neural sampler)qψ,采用下式实现变分训练:
加速分子体系自由能地貌图统计概率分布参数的训练.对于没有集合变量函数的更一般情况,通过加入了强化学习模式,较好地解决了固定偏置势在动态采样中尴尬的同时,实现了粗细两个不同粒度的有效采样补充.这些方法都被集成在SPONGE[111]平台上.
3.7 变分自编码器的直接应用
上述构建显式变分优化目标函数的做法能够给出更有效的物理图像,神经网络主要用于拟合其中未知非线性映射过程.不过即使没有直接显式变分目标函数的构建,变分的思想依然可以被利用.最简单的做法就是直接使用变分自编码器VAE 架构[77]对自己感兴趣的目标数值分布进行优化,同时在生成的隐空间(对应于分子体系集合变量空间)展开一系列增强采样的操作,必要时再引入迭代机制.
Ribeiro 等[112]发展了重配权变分贝叶斯增强采样(reweighted auto encoded variational Bayes for enhanced sampling,RAVE)方法,通过隐空间分布和模拟的KL 散度优化自编码器,更新偏置势模拟后迭代优化直至收敛,实现了独立于传统方法的隐空间增强采样.针对在MSM 模型中使用过渡路径理论方法时会得到大量子状态之间的路径,从而使结果难以理解的困境,Qiu 等[113,114]利用VAE的数值分布变分优化,在隐空间实现了类似过渡路径的合并.该方法被成功应用在两个不同的简单体系,分别是一对疏水粒子在水溶液中的聚集和Fip35WW 结构域折叠路径的分析中.利用VAE能够有效预测编码空间、隐空间和解码空间概率密度的特性,Monroe 和Shen[115]发展了基于隐空间的蒙特卡罗移动建议方法,再通过编码和解码,从而实现在真实高维空间有效且高接受率的移动.该方法的突出优点是直接满足细致平衡要求,不需要一般偏置势加速采样生成轨迹后的权重调整,从而避免了与之伴随的所有潜在问题和困难.这个思路和通过粗粒化模拟促进(细粒度)全原子模拟[76],以及把低维子空间视为信息瓶颈[74,75]的具体方式虽然差别较大,但总体基本思路一致.不同粒度之间更加高效准确的构型映射和信息传递还有很大的方法学发展空间,这方面的新发展也大概率会显著促进复杂分子体系高精度多尺度模型的构建.
4 其他神经网络方法在自由能地貌图相关研究中的应用
神经网络网络的万能逼近能力使得其在自由能面探索中从多个角度被加以应用.其中很多工作都致力于获得更好的集合变量以改善复杂体系的增强采样.早在2005 年,Ma 和Dinner[116]就开始使用神经网络用来寻找复杂体系的反应坐标.针对各种传统降维方法不能直接把结果中的低维空间(集合)变量表达为原空间坐标的问题,Chen 和Ferguson[117]利用自编码器可以实现从高维输入空间到低维隐空间之间的可训练映射,把通过已有轨迹数据训练生成的隐空间自由度作为集合变量,从而实现了对集合变量偏置势通过自编码器对高维空间坐标的直接微分计算偏向受力,集成了集合变量的神经网络构建和在加速采样中的直接应用,该方法在丙氨酸二肽和TrpCage 蛋白体系中被成功使用.与此类似,Chen 等[118]也采用自编码器进行降维训练获得CV,然后通过自动微分把施加于CV 上的偏置势传递到分子体系中去实现模拟采样和自由能计算.
与使用变分优化特征函数不同的另外一种思路是回归方法.Wehmeyer 和Noé[119]尝试了选择对N个连续时间坐标序列(Xt,Xt+τ,t=1,2,···,N)最小化回归误差[120–122]:
其中D和E分别为编码器和解码器.在对已有轨迹数据的时间序列坐标构型按照下式进行均值归零((28)式和(29)式)和白化((30)式和(31)式):
然后对处理后的坐标优化训练,实现编码器降维和解码器对原空间的映射:
通过训练过程中在输出端使用相对输入端t时刻的延后t+τ时刻坐标,也实现了演化的预测.对于在构象空间中线性可分的不同亚稳态,该方法被证明同Koopman 模型[49,68]等价.但对非线性可分的体系,与PCA 和TICA 及人工构造特征空间相比,文献[119]的丙氨酸二肽体系显示通过编码器和解码器的深度学习拟合则可以更好地处理.
Zhang 和Chen[123]针对不恰当的CV 会在其正交空间出现亚稳态简并(degeneracy)从而导致对应方向不能加速采样的问题,发展了利用随机动力学嵌 入(stochastic kinetic embedding,StKE)的半监督学习方法增加对当前信息最匮乏区域(current least informative regions,CLIRs)的主动学习采样(active enhanced sampling,AES),这与Kleiman 和Shukla[68]在VAMPNets 输出构象类型采样最少的部分增加后续采样的思路类似.该方法成功在丙氨酸二肽和五肽met-enkephalin体系中从随意给定的无效CV 开始,以较短时间实现了对自由能地貌图的可靠采样.Rydzewski和Valsson[124]提出的多尺度重配权重随机嵌入(multiscale reweighted stochastic embedding,MRSE)则在此基础上更进一步,通过高斯混合模型描述高维特征空间和重配权重,实现对平衡态和偏置势采样数据在训练中的有效使用.该方法被Rydzewski和Valsson 应用到-Brown Potential以及丙氨酸二肽和四肽体系,也已被整合到开源的PLUMMD 软件包(https://www.plumed-nest.org/eggs/21/023/).类似地,Belkacemi 等[125]发展了利用自编码器的自由能偏置势迭代学习 (free energy biasing and iterative learning with auto encoders,FEBILAE),该方法可以对在平衡态或者偏置势下采样的轨迹重配权重后作为自编码器的输入(既可以是原来构象空间的,也可以是某种转换之后的构型).其中自编码器的瓶颈层确定了CV 的维度,但显然需要自行选择,他们也给出了探索的建议.可能的问题是迭代收敛的CV 并不能保证自由能地貌图的全局充分采样.和大多数类似研究一样,这类编码过程不具备直接可解释性,人们无从知道输入构型中不同的参数对CV 的贡献.虽然原则上可以间接从计算过程中的自动微分步骤获取一定信息,但目前所有的方法中没有提供这种分析.针对这个问题,Kikutsuji 等[126]利用模型无关的局部解释(local interpretable model agnostic explanation,LIME)和沙普利加和解释(shapley additive explanations,SHAP)框架,给出各个输入量对RC 的贡献,能够在一定程度上增进我们对体系的直观物理认知.
Sun 等[127]发展了由一个降维编码器,构象分类器和势能预测器组成的多任务CV 学习构架,在几个简单测试系统(包括5DBrown model、丙氨酸二肽和金(110)晶面重建单元反应体系)与单目标训练优化相比较展示了一定优势.与很多应用中系统演化过程在原有高维空间进行不同,隐空间模拟器[128](latent space simulator,LSS)在训练产生编码器和解码器后,在CV 空间快速展开系统演化,然后通过解码器生成原有高维空间的细粒度轨迹.这些在隐空间或者集合变量空间进行操作的思路是很多工作中利用自编码器的重要方式.比大多数方法在诸如丙氨酸二肽或类似模型体系中展示更进一步的是该方法在两个较大体系(264 残基的PROTAC 蛋白和DNA 序列5′-GCGGTTTCCGC-3′ 对应的双螺旋结构)获得了较为成功的应用.
Jung 等[129]以水溶液中离子的聚集和聚合物折叠为例,集成了深度学习和过渡路径理论实现了复杂分子体系自组织模型的构建、验证和更新,并在此基础上通过符号回归总结出更容易理解的可观测量连接,是分子复杂体系的深度学习和可解释性方面有意义的尝试和进步.比变分求解自由能上界更进一步,Zhao和Wang[130]用流匹配 (flow matching)同时求解上下界,从而提供更好地逼近目标体系自由能的可能途径.
鉴于生成式模型在语言图像绘画等方面的巨大成功[131],Janson 等[132]基于生成对抗模型和transformer 架构训练的构象系综生成神经网络成功产生了训练数据集中没有的内秉无序蛋白(IDP)构象,该过程与分子模拟直接采样相比所用计算代价非常小,不过正确性依然有待进一步在更多体系中验证.
5 结论
综上所述,变分方法处理分子体系自由能地貌图目前已经有了较多不同视角的尝试,但还都限于在较为简单的体系探索,和其他理论上不甚严格的刻画分子体系自由能地貌图的神经网络方法相比较也还没有展示出明显的系统优势.比如使用变分的VAMPNets[67]和使用回归[119]两种方法在丙氨酸二肽体系中就没有明显的表现差异.不过变分更严格的理论基础有可能会让误差控制更加容易,也很可能会在将来较大分子体系的应用和进一步发展中体现出更多的优势.从理论方法的角度,现有的这些不同变分目标函数都是为了更好地逼近分子体系自由能地貌图的准确描述,如何将它们集成并能够依据应用需求灵活选择关注视角显然是个有价值的任务.当前的变分和自编码器模型中还有很多需要人工调节和尝试的环节,最为突出的就是目前的所有方法都不能通过自主学习优化获得自编码器中间低维隐空间的适当维度.另外变分计算本身原则上也可以在神经网络中数值实现,从而有可能增加灵活性和可泛化能力,不过目前尚没有见到这类尝试,有可能是个有价值的发展方向.
从应用的角度,目前最迫切需要解决的问题可能是将这些变分构建向更大更复杂分子体系的延伸.从自由能地貌图构象空间的层次来看,超过两个时空间尺度的体系显然会带来更多挑战,在同一个自由能地貌图时空间尺度层次上,多个亚稳态之间过渡路径交汇的可能性和准确处理也有待解决.这些问题的可靠处理在较大的复合体分子机器的理解中很有必要.
目前大模型的应用如火如荼[133],不过在AI 的科学应用领域尚没有发力.主要原因之一是作为通用大模型训练素材的语音图像材料非常丰富,而特定科学领域的数据一般都不够丰富或者很多都难以理解.不过这些模型集成多模态的能力显然对AI 在广泛科学应用中和特定的复杂分子体系中都有参考价值.已有的这些变分构建方法,还有未来可能出现的其他新颖构建,很可能在将来被统一到一个多目标大模型中.
