采用差分星座图的SDR设备射频指纹识别*
2024-03-26安永丽申俊峰纪占林
安永丽,申俊峰,纪占林
(1.华北理工大学 人工智能学院,河北 唐山063000;2.河北省工业智能感知重点实验室,河北 唐山063000)
0 引 言
在人们享受物联网(Internet of Things,IoT)的快速发展带来便利的同时,安全问题也渐渐浮出水面[1]。射频指纹[2]是一种新颖的物理层安全技术,与生物指纹相似,是无线设备本身的固有特性,不易伪造。基于射频指纹的身份认证可以极大地增加无线传输安全性。
目前的射频指纹识别方法可以分为两类。一类是基于瞬态的射频指纹提取技术,即使用小波变换[3]、经验模态分解(Empirical Mode Decomposition,EMD)[4]或赤池信息准则(Akaike Information Criterion,AIC)[5]等方法分析无线设备的射频指纹。但是这种技术对设备的灵敏度有极高的要求,不仅传输过程中信号容易被噪声干扰,还会增加射频指纹提取的成本。另一类是基于调制域的射频指纹提取方法,可以很好避免噪声的干扰并降低提取的成本。调制特征包括I/Q偏移、载波频率偏移[5]、星座轨迹图(Constellation Trace Figure,CTF)[7]等。调制方法是将射频指纹转换为含有特征的星座轨迹图(图像中样本点分布的情况即为射频指纹特征),再通过卷积神经网络完成复杂分类。文献[8]提出了使用卷积神经网络来识别使用差分星座图(Differential Constellation Trace Figure,DCTF)特征的不同设备,但DCTF在低信噪比下表现得不理想。文献[9]提出了使用注意力残差网络来识别不同设备,虽然可以达到较好的准确率,但是其网络结构过于复杂,计算量较大。以上方法在特征提取时没有考虑噪声对模型性能的影响,也存在网络结构复杂、感受野不足以及模型容易过拟合的问题。
为了解决以上问题,本文提出了一种改进的Res2Net50网络模型,即DCTF-Res2Net模型。该模型不仅在提取特征时通过增大感受野来获取更多的特征信息,还缓解了离散点对模型性能的影响。具体如下:首先,针对实际的无线传输场景,选用合适的正交相移键控(Quadrature Phase Shift Keying,QPSK)调制方式生成DCTF,无需再进行可视化预处理。然后,引入了注意力模块,此模块通过捕获位置信息和通道间的关系,以增大感受野和过滤掉无关信息,达到增强提取有效特征和提高识别精度的目的。最后,使用标签平滑交叉熵损失函数来替代交叉熵损失函数,缓解了由于样本点散乱导致网络模型容易过拟合的问题。将所提出的DCTF-Res2Net模型在数据集上进行了充分的实验,结果表明,DCTF-Res2Net模型具有更好的准确性和鲁棒性。
1 基于DCTF的射频指纹提取
实验系统框图如图1所示,实验设备包含3个可收发的软件无线电设备。为了更好地体现出射频指纹的特征和完成基于传输距离辅助的多种差分间隔的差分星座图的绘制,接收机使用60 Msamples/s的过采样率,是发射机采样率的10倍。
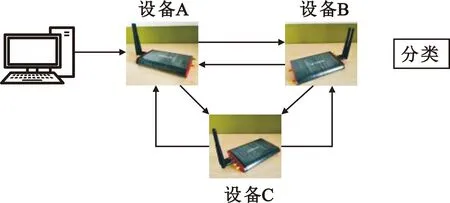
图1 整体系统框图Fig.1 Overall system diagram
软件无线电发射机发送的信号可以用公式(1)表示:
(1)
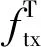
接收机接收的信号可以用公式(2)表示:
(2)

为了获得更稳定的差分星座图,首先将接收到的信号在I/Q延迟器中执行相同的移位值为τ的移位操作,以突显特征,如公式(3)所示:
Y′(t)=((βIχI(t+τ)+φI)+(βQχQ(t+τ)+φQ)j)e-j2πγt
(3)
再对其进行差分处理,解决由于传输距离引起的特征发散的问题。差分过程如公式(4)所示:
Z(t)=Y′(t)·Y′(t+λ)
(4)
式中:λ表示选取的差分间隔。实验时,3个软件无线电设备之间进行相互传输,传输方式如表1所示。A→C表示设备A作为发射机,设备C作为接收机;d1和d2代表不同的传输距离;λ1,λ2和λ3代表不同的差分间隔。

表1 设备之间传输方式Tab.1 Transmission methods between devices
将上述处理后的数字信号在复平面上绘制出来即为星座图,可以更直观地表示信号之间的关系。通过星座图中样本的分布来研究接收信号中所包含的射频指纹特征。按照上述差分间隔的选取对星座图进行差分处理得到差分星座图。DCTF本质上提供了差分运算的统计分布的可视化。差分结果中样本点的分布代表了在不同信噪比和传输环境下的射频指纹特征。发射机和接收机采用QPSK调制方式,进行差分处理后,在不同信噪比的情况下的DCTF示例如图2所示。针对实际的无线传输场景,设置了5~20 dB的信噪比,以达到模仿真实传输环境的目的。

图2 在不同信噪比环境下提取的DCTFFig.2 DCTF extracted in different SNR environments
由于载波频率偏移、I/Q偏移和非线性变化,DCTF中的样本点轨迹分布密度不同。从图2中可以看出,在信噪比10~20 dB情况下,DCTF样本点分布密集,特征明显,且覆盖范围小;在信噪比为5 dB情况下,DCTF样本点分布散乱,特征模糊,且覆盖范围广。传统的残差网络对噪声的适应能力较差,无法解决由于DCTF的模糊,导致网络模型易过拟合和特征提取不完整的问题,因此,针对DCTF特征模糊问题,本文提出DCTF-Res2Net模型来提高射频指纹的身份识别精度。
2 基于DCTF-Res2Net的射频指纹识别
残差网络[10]虽然在分类任务方面远胜于传统的卷积神经网络,但是传统的残差网络的感受野受限,在低信噪比情况下不能完全提取有效信息。因此,借鉴了多尺度神经网络Res2Net50[11]中的残差模块,其采用了传统的残差网络ResNet50中瓶颈块的变体,将瓶颈块中的3×3的卷积用分组卷积来替代,增加每个网络层的感受野范围,达到能在更细的粒度中提取多尺度特征的目的。
如图3(a)所示,在DCTF-Res2Net的残差模块中,将1×1卷积层输出的数据被平均分成4组,分别为x1,x2,x3和x4。x1直接得到输出y1。y2是通过一个3×3的卷积得到的输出,因此y2得到的是3×3的感受野。y3是通过两个3×3卷积优化后得到的输出,因此y3得到是5×5的感受野。y4是融合了3×3的感受野和5×5的感受野处理后的输出,因此y4得到是7×7的感受野。最后将y1,y2,y3和y4进行拼接,再通过1×1的卷积进行跨通道信息融合,最后再与恒等映射分支进行累加得到输出,达到多尺度融合提取DCTF特征的目的。
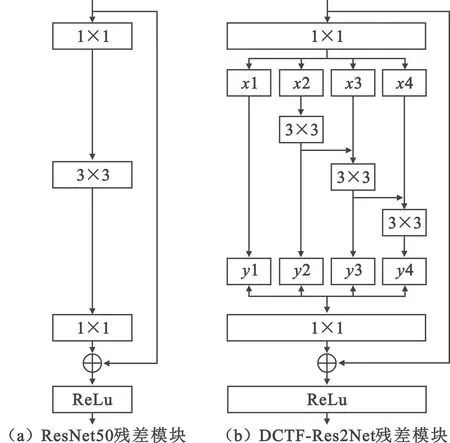
图3 残差模块Fig.3 Residual module
在低信噪比情况下,若网络模型的感受野太小,则只能观察到DCTF的局部特征,没法提取到关键信息;若感受野太大,虽然可以提取DCTF整体的信息,增强对全局信息理解,但是也会将噪声误认为成有效信息。
为了提高有效感受野和避免冗余信息干扰,采用了多尺度模型。多尺度模型不仅可以对DCTF进行不同尺度的采样,提取DCTF不同的特征,还降低了网络模型中参数的数量。多尺度模型在提取有效特征时,既提取了DCTF整体的信息,减少了关键信息的丢失,又提取了DCTF中每个样本点的具体的细节信息。
2.1 基于注意力机制对模型的改进
在低信噪比情况下,DCTF会由于噪声的影响使得离散点增多和形状发生改变,进而导致模型不能精准提取关键信息。为了过滤掉噪声等冗余信息并自适应地提取DCTF的细节特征,在网络模型中添加注意力模块。
压缩激活(Squeeze and Excitation,SE)模块只考虑了通道注意力关系,不适合图像的特征提取。卷积块状注意力模块(Convolution Block Attention Module,CBAM)采用通道注意力和空间注意力结合的设计,虽然能对DCTF的识别有略微的改善,但是其忽略了位置信息,无法解决由于样本分布散乱而导致模型精度降低的根本问题。
然而,CA(Coordinate Attention)[12]模块(图4)通过将通道与位置结合,可以捕获精确的差分星座图中离散点位置信息,将通道注意力分解为水平和垂直的两个一维特征编码,再分别沿这两个空间方向聚合特征。这样可以保留精确的位置信息,更细致地获取图像的关键信息,解决样本散乱等根本问题。
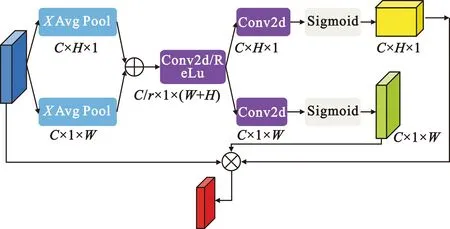
图4 CA模块Fig.4 CA module
图4中,Avg Pool为全局平均池化层,Conv2d为1×1卷积层。首先将任意输入的差分星座图F∈C×H×W,分成水平和垂直两个维度,分别进行全局平均池化和编码,获得水平方向的差分星座图FH∈C×H×1和垂直方向的差分星座图FW∈C×1×W,分别提取水平和垂直方向的离散点的分布特征。然后,将得到的水平和垂直方向的差分星座图进行拼接融合,以达到增加感受野的目的,再经过1×1的卷积层,使用卷积变换函数f对其进行变换操作得到公式(5):
S=δ(f([FH,FW]))
(5)
式中:[FH,FW]为拼接融合操作;δ为ReLu激活函数;S为差分星座图在水平和垂直维度进行分别编码为一对可以互补的方向感知和位置敏感的特征图,将其沿着水平和垂直维度分解为两个独立的张量SH∈C/r×H和SW∈C/r×W,再经过1×1的卷积,将通道降为C,最后经过Sigmoid函数得到公式(6):
(6)
式中:σ是Sigmoid激活函数;GH是差分星座图在水平维度的注意力权重;GW是差分星座图在垂直维度的注意力权重。通过乘法加权计算,得到在水平和垂直维度上带有注意力权重的特征图:
y(h,w)=F(h,w)×GH(h)×GW(w)
(7)
CA的使用需要更多的模型推理时间,但是可以使高层次的特征表达更强。将网络模型与CA模块结合,使得模型更精准地分析到DCTF中每个样本点的位置信息,以达到提高识别精度的目的。
2.2 基于交叉熵损失函数的改进
交叉熵损失通常使用one-hot向量处理分类任务,但是,对于此数据集并不会产生很好的效果。这是因为当使用one-hot向量计算损失时,会使模型无法充分考虑到离散样本点的位置,导致模型非常容易过拟合。因此,采用了标签平滑[13]来改进交叉熵损失函数,以这种标签平滑的方式会使原本置信度高的类别置信度轻微降低,但是依然与其他类别的置信度保持明确的决策边界。这种方式不仅给予标签一定的容错概率,还提高了模型对离散点的适应能力。
交叉熵损失的公式如(8)所示:
(8)
式中:M=6表示类别的数量;p表示one-hot标签;q表示该样本进行Softmax的概率矩阵。当使用one-hot向量进行交叉熵损失计算,p=1,lnqξ就得到保留;反之p=0,lnqξ被舍弃。
公式(9)所示,标签平滑引入了一个平滑因子为ε=0.1,p为平滑之前的one-hot标签,p′为平滑之后的标签,μ=0.166是引入的固定分布的噪声。
p′=(1-ε)·p+ε·μ
(9)
平滑过后的交叉熵损失如公式(10)所示:
(10)
在训练过程中既考虑到了正确标签位置的损失,也考虑到其他错误标签位置的损失,使训练得到的损失增大,进而提高了模型的学习能力,缓解了DCTF中离散点对模型的干扰。
DCTF-Res2Net的整体结构如图5所示。
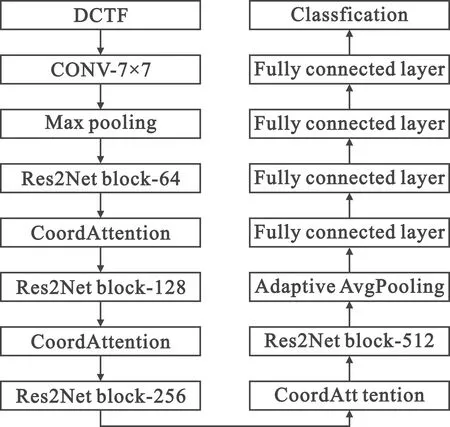
图5 DCTF-Res2Net网络模型Fig.5 DCTF Res2Net network model
输入层:为了降低模型的复杂度,输入端使用64×64的图像进行分类,即输入端的大小为128×64×64×3。
7×7的卷积层:使用一个较大感受野的7×7卷积层来提取DCTF的整体样本点的分布结构。
最大池化层:在第一个7×7卷积层输出后,使用最大池化层降低计算的复杂度。
Res2Net残差模块:对特征图进行多尺度特征提取,不仅提取了DCTF整体的信息,还提取了DCTF中每个样本点的细节信息。
CA模块:通过将通道信息与位置信息结合,更精准地分析到DCTF中每个样本点的位置信息。
自适应平均池化层:对特征进行压缩,同时取出对应维度的均值,在一定程度上可以抑制冗余特征。
全连接层:使用4层全连接层达到平滑降低通道的目的。使用Dropout层将其值设置为0.5,提高模型的泛化能力。
最后,发送到Softmax分类器以获得预测的设备编号。
3 仿真实验与结果分析
3.1 数据集及实验环境介绍
实验使用的软件无线电设备为威视锐公司生产的可收发YunSDR Y310设备。接收机和发射机的部分带宽为50 MHz。接收机使用60 Msample/s的过采样率,是发射机采样率的10倍。无线设备通过千兆网线与电脑主机连接。每一个无线设备连接一个主机,主机的配置为Intel(R) Core(TM) i7-10700 CPU 64位处理器、16 GB内存,并采用GTX 1060运算加速,操作系统为 Win 10,主机使用Matlab对设备进行调试。设备经过2 min的预热,达到稳定的工作状态后开始进行射频指纹采集。接收机从无线设备中捕获射频波形,每次在真实室内传输采集1 400个DCTF,将样本分成两组,训练集和测试集随机分成70%和30%。为了模拟真实的传输环境,又在真实室内场景和真实室外场景分别进行了训练样本和测试样本分开采集的实验,室内场景传输共采集700个样本,室外场景传输共采集700个样本,训练集和测试集分别占总样本的70%和30%,再分别进行识别精度实验,并使用2-Fold 交叉验证得到最合理的结果。在实验过程中加入了5~20 dB的加性高斯白噪声。
在DCTF-Res2Net模型中,损失函数采用交叉熵损失函数及标签平滑,使用Adam优化算法进行训练,从学习率从0.000 1开始,逐步减少初始学习率进行测试,最终设置为动态学习率,在周期为2,5和10时进行减半,周期设为20。batch size设为128,输入图像为64×64。网络模型使用ImageNet预训练权重,加速网络训练,网络模型是在Pytorch1.6环境下建立的。
3.2 对比实验结果
3.2.1 相同场景下DCTF-Res2Net与传统的残差网络对比
为充分分析和验证DCTF-Res2Net模型的性能,分别使用DCTF-Res2Net模型和ResNet18模型对DCTF进行识别精度对比实验,结果如图6所示。DCTF-Res2Net和ResNet18在信噪比为15 dB和20 dB情况下,DCTF的样本点分布集中,特征明显,身份识别的准确率可以达到99%。这是因为此数据集对噪声具有一定的适应能力,不需要再对DCTF进行额外的预处理,依然可以达到较高的准确率。随着信噪比不断降低,噪声不断增加,DCTF的模糊程度也在不断增加,样本点无法集中分布,DCTF的形状也渐渐发生改变。在信噪比为5 dB情况下,DCTF的模糊程度最具有代表性,此时,传统的残差网络其对此数据集不再具有很强的适应能力。但是,DCTF-Res2Net模型依然具有很好的鲁棒性,这是因为DCTF-Res2Net模型在残差模块和注意力机制等方面优于传统的残差网络模型。
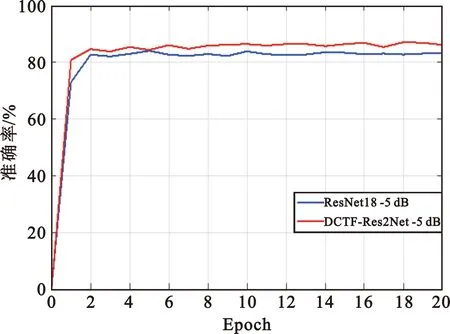
(a)SNR=5 dB
为了体现出DCTF-Res2Net针对此数据集具有很强的鲁棒性,将DCTF-Res2Net、Res2Net50、ResNet18和ResNet34模型在同等实验环境下对DCTF的适应能力进行测试,实验结果如图7所示。
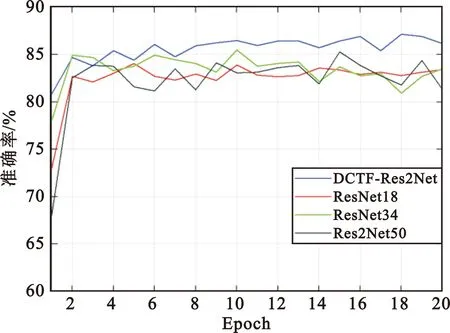
图7 SNR=5 dB下模型准确率对比Fig.7 Comparison of accuracy among models when SNR=5 dB
由图7可以看出,DCTF-Res2Net、Res2Net50、ResNet18和ResNet34针对5 dB情况下的DCTF的识别精度具有明显的差距。从ResNet18和ResNet34的对比实验结果中可以看出,增加网络的复杂度和参数会导致模型过分记住噪声特征,加快过拟合;从ResNet18和Res2Net50的对比实验结果中可以看出,增加网络的感受野利于有效离群点的位置特征的提取。从DCTF-Res2Net和Res2Net50的对比实验结果中可以看出,减少网络的复杂度和加入注意力模块可以缓解噪声的干扰,极大提高识别精度。
3.2.2 相同场景下不同注意力模块的对比
并不是所有注意力模块都可以改善模型的精度,随意添加注意力模块可能会给模型带来负担,不利于射频指纹的分类任务。
表2所示为在信噪比为5 dB情况下,不同注意力模块对模型产生的影响。从表中可以看出,对于DCTF来说,SE模块并不能给模型带来优化,因为其不适于二维图像的特征提取,随意添加会给网络模型增加了参数,导致模型精度降低;CBAM模块对模型的精度有略微的改善,但是其依然无法获取样本点的精确位置,没有解决模型精度降低的根本问题;CA模块则是通过将空间维度分成水平和垂直两个维度,这两个维度通过互补的关系达到精确捕获DCTF中样本点的位置信息的目的,解决了根本问题,使得模型可以更精准地提取到有效特征,增强模型的表达能力。

表2 不同注意力模块的对比Tab.2 Comparison of different attention modules
3.2.3 在相同场景下,不同损失函数的对比
损失函数是网络模型在向前传播阶段产生的,通过反向传播来达到更新模型的目的,损失越大,真实值与预测值差别就越大,促使网络模型不断学习,缓解离散点对模型的影响。
图8比较了5 dB情况下不同损失函数得到的准确率,可以看出改进后的损失函数的分类精度不仅高于原来的模型,还使得准确率可以稳定在一个很小的区间内。而使用交叉熵损失函数的分类精度相对分散,波动较大,准确率不稳定。这表明平滑过后的损失函数不仅提高了分类精度,而且使模型的结果更加稳定。
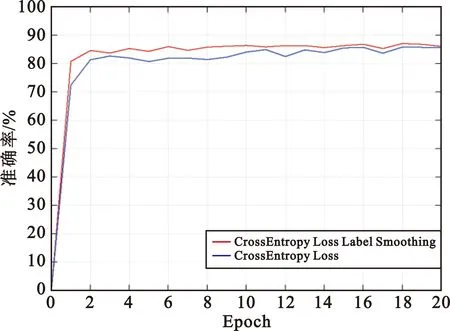
图8 损失函数的对比Fig.8 Comparison of loss functions
3.2.4 在不同场景下,识别精度对比
将室内采集的样本和室内外采集的样本分别使用DCTF-Res2Net模型对DCTF进行识别精度对实验。
在不同场景下,信号受到的干扰不同,因此为了更好地验证此模型的鲁棒性,使用相同的模型和相同的设备,针对不同场景进行了2-Fold 交叉验证实验分析,结果如图9所示。DCTF-Res2Net在信噪比为15 dB和20 dB情况下,即使在不同的场景下,依然达到很高的准确率。这是因为实验中的DCTF不仅对人为加的噪声具有一定的适应能力,还对不同环境中的噪声具有一定的适应能力。随着信噪比不断降低,场景发生改变,噪声越来越复杂,加剧了DCTF的模糊程度,但是依然可以达到一个不错的准确率。这是因为DCTF-Res2Net模型可以将所结合的注意力机制的优势发挥出来,不仅在一定程度上避免了冗余信息干扰,还提高了特征表达能力。
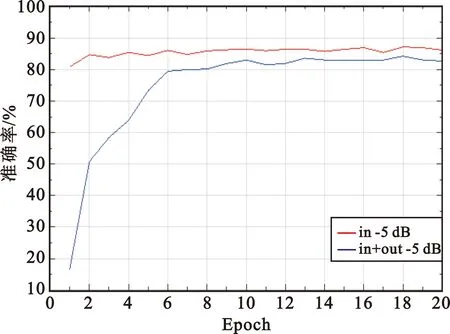
(a)SNR=5 dB
3.2.5 不同场景下DCTF-Res2Net与改进的传统残差网络对比
将传统的ResNet18模型与文献[3]和[4]结合,实现新ResNet18模型,并将室内采集的样本和室外采集的样本分别使用DCTF-Res2Net模型和新ResNet18模型进行实验对比。
当实验场景发生改变后,实验会变得更复杂,实验环境会对实验产生不同的影响。随着信噪比不断降低,噪声不断增多,再加上环境的复杂度不断增加,进而加剧了DCTF的模糊程度。图10(a)和(b)分别为信噪比为5 dB和信噪比为10 dB情况下的对比实验结果,表明新模型并不会提高识别精度。这是因为新模型只会增加网络的复杂度和参数,导致模型过分记住噪声特征,加快过拟合。所以只有在不添加网络参数的前提下,增加网络的感受野和加入注意力模块可以增强特征表达能力和缓解噪声的干扰,极大提高识别精度。
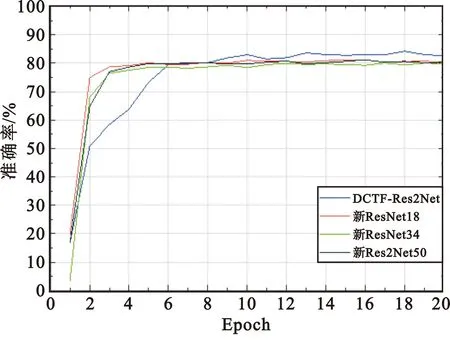
(a)SNR=5 dB
4 结 论
本文针对噪声对射频指纹识别的影响,设计了DCTF-Res2Net模型。首先,对数据集进行了详细的分析,此数据集不需要进行预处理可视化就可以在信噪比为10dB时达到很高的准确率。然后,对DCTF-Res2Net模型进行了详细的分析,并证明在相同场景下和不同场景下,其在射频指纹识别领域优于传统的残差网络。最后,DCTF-Res2Net模型中注意力模块可以大幅度提高特征表达能力,并且采用了损失标签平滑的方法,减缓了在低信噪比下DCTF中样本点离散会导致模型容易过拟合的问题。实验结果表明,DCTF-Res2Net与传统的ResNet18和Res2Net50网络相比,不仅具有更简洁的网络结构,还具有更高的准确率和更强的鲁棒性。
