基于大语言模型的电力系统通用人工智能展望:理论与应用
2024-03-26赵俊华文福拴黄建伟刘嘉宁程裕恒董朝阳薛禹胜
赵俊华,文福拴,黄建伟,刘嘉宁,赵 焕,程裕恒,董朝阳,薛禹胜
(1.香港中文大学(深圳)理工学院,广东省深圳市 518172;2.深圳市人工智能与机器人研究院,广东省深圳市 518038;3.浙江大学电气工程学院,浙江省杭州市 310027;4.广东电网电力调度控制中心,广东省广州市 510030;5.南洋理工大学电气与电子工程学院,新加坡 639798,新加坡;6.南瑞集团有限公司(国网电力科学研究院有限公司),江苏省南京市 211106)
0 引言
近年来,全球范围气温持续升高,极端天气频发,减少温室气体排放以支撑可持续发展已成为21世纪人类社会的重大目标之一。在此背景下,国际上对减少温室气体排放达成诸多重要共识,中国也明确提出“碳达峰·碳中和”的目标和具体要求。通过大规模开发利用太阳能、风能等可再生能源,实现全社会减排,已成为国际社会的普遍共识[1]。
为了实现可再生能源对传统化石能源的替代,构建可再生能源发电占比逐步提升的新型电力系统已成为行业发展共识。根据国家能源局提出的定义,新型电力系统是“以新能源为主体,以创新为根本驱动力、以数智化为关键手段的新一代电力系统”[2]。新型电力系统具备“安全高效、清洁低碳、柔性灵活、智慧融合”[2]四大重要特征。通过推动电力生产、传输、消费、储蓄各环节的电力流、信息流、价值流的融合和综合调配,新型电力系统实现了绿色低碳、安全可控、经济高效、柔性开放、数字赋能的电力系统。新型电力系统可以明显提高可再生能源发电的消纳能力,显著降低化石能源发电的占比,从而减少温室气体的排放。因此,新型电力系统是实现国家“双碳”战略的重要手段和保障。
新型电力系统的发展代表了对传统电力系统的颠覆性变革。建设新型电力系统将面临以下重大挑战[2]:
1)在电力供应安全方面,长期来看,由于电源结构的根本性变化、电力需求的持续增长趋势以及尖峰负荷特征的日益突出,确保电力供应安全将面临长期挑战。
2)在新能源消纳方面,随着新能源转变为主体电源,其间歇性、随机性和波动性特点对电力系统的调节能力提出了更高的要求,新能源消纳面临巨大的技术挑战。
3)在系统运行压力方面,新型电力系统中高比例可再生能源发电和高比例电力电子设备的“双高”特性日益凸显,系统运行压力持续增加。
4)在新形势与新业态方面,传统电力系统的调度方式和技术难以适应海量分布式设备(如分布式电源、新型储能、电动汽车等)接入、电力市场环境下交易计划频繁调整、源网荷储“多相互动”等新形势与新业态。
5)在电力市场体制方面,现有电力市场体制与新型电力系统的特征不匹配,难以满足建设新型电力系统的要求。
要应对这些挑战,需要从政策、机制、装备、技术等各方面进行全方位的创新。
人工智能(artificial intelligence,AI)是计算机科学的一个重要分支,专注于研究和开发能够模拟、扩展和增强人类认知功能的智能机器和软件。这些功能包括理解、学习、推理、解决问题、感知和语言交流等。大语言模型(large language model,LLM)[3]是近年来AI 领域的重大突破之一。LLM 源自深度学习和自然语言处理(natural language processing,NLP)的交叉发展。深度学习架构Transformer 的出现使得LLM 的能力获得了本质性的突破。Transformer 架构通过自注意力机制解决了自然语言处理中长期存在的长距离依赖问题,使模型能够处理更长的文本序列。目前,以ChatGPT(chat generative pre-training transformer)为 代 表 的LLM已经在机器翻译、文本摘要、问答系统、文章编写、自动绘图等众多领域中获得广泛应用。ChatGPT 在2022 年11 月推出后,仅用2 个月时间就实现了用户数破亿,是史上用户数增长最快的互联网应用。
研究发现,具有千亿参数量的LLM 在各种多模态任务中展现出传统AI 模型不具备的强大常识理解和逻辑推理能力。这意味着LLM 已为通用人工智能(artificial general intelligence,AGI)技术的发展奠定了初步基础。AGI 指在大多数任务中具有超越人类能力的自主智能系统[4]。一般认为,AGI 系统应具有以下能力[4]:
1)推理、策略、解决问题和在不确定环境下做出决策:能够处理复杂的问题和任务,并且在面临不确定性和模糊性时做出正确的决策。
2)理解和表示知识:能够学习和理解各种类型的知识,并以可操作的形式表示这些知识。
3)规划:能够规划未来的行动和决策,并且考虑多种可能性和场景。
4)学习:能够从经验中学习和改进自己的行为和决策,并自适应地适应新环境和新任务。
5)自然语言处理和交互:能够理解和处理人类的自然语言,并与人类进行有效的交互和沟通。
AGI 技术的实现将为构建更加智能的电力系统和解决新型电力系统所面临的挑战提供新路径。LLM 已在一定程度上具有了AGI 的基本特征。本文旨在探索基于LLM 构建的AGI 技术在电力系统中的潜在应用,讨论LLM 可为电力系统研究和工程应用带来的发展和挑战,并展望以LLM 为基础的电力系统AGI 理论体系和实现技术的发展前景。
1 LLM
LLM[3]是一种利用大规模文本语料进行预训练与微调的深度学习语言模型,能够理解和生成与人类语言相似的表达。预训练语言模型(pretrained language model,PLM)[5]以神经网络为基础,通过在大量无标注文本上进行无监督学习,学习文本的统计规律和语义信息,然后在特定的下游任务进行微调,以提高任务性能。LLM 与PLM 有相似的架构和预训练任务,区别在于LLM 使用了更多的模型参数和训练数据,例如BLOOM(bigscience large open-science open-access multilingual)模型[6]有1 760 亿个参数,PaLM(pathways language model)模型[7]有5 400 亿个参数。LLM 能够处理更长的文本输入,并具有更强的上下文感知能力。研究表明,与参数量较小的PLM(例如110 亿个参数量的T5[8])相比,LLM 在一些少样本(few-shot)或零样本(zeroshot)的任务中,表现出了超越人类水平的涌现能力[9],即不需要额外的训练数据或标签,就能够完成特定的任务。LLM 已经在多个领域得到广泛的应用,例如常识对话、文本生成、逻辑推理等,并取得了令人瞩目的成果。
1.1 LLM 的原理、方法与实现技术
LLM 的基本原理是通过神经网络来进行序列建模。它将输入的文本序列映射到输出的文本序列,中间通过多层Transformer 网络[10]进行信息的传递和处理。Transformer 网络能够在不同位置的单词之间建立关联,从而捕捉长距离的依赖关系。在输入文本的位置编码方面,部分LLM(例如LLaMA(large language model meta AI)模 型[11]、PaLM 模型)使用了基于绝对位置特定的旋转位置编码(rotary position embedding,RoPE)[12],以增强模型的上下文感知能力。这些网络结构能够有效捕捉到序列数据中的长期依赖关系,并且具有强大的表达能力。LLM 的训练方法是通过在大规模语料库上进行无监督的预训练,学习语言的统计规律和语义信息,然后在特定任务或者数据集上进行有监督的微调,以达到更好的性能。
LLM 的实现技术包含深度学习框架、分布式训练和模型压缩等。深度学习框架(例如TensorFlow框架[13]和PyTorch 框架[14]等)是指提供了丰富的神经网络模型和优化算法的软件平台,方便研究人员快速搭建和训练LLM。分布式训练技术(例如DeepSpeed 技术[15])可以将LLM 的训练过程分布到多台服务器上,利用分布式计算技术可对训练进行可观的加速。模型压缩技术通过量化[16]和蒸馏[17]等方法,减少LLM 的参数量和计算量,提高模型推理和计算的效率和性能。
1.2 LLM 的神经网络结构及训练方法
在 LLM 中,常用的神经网络结构为Transformer,包含编码器与解码器两部分,如图1 所示。其中,编码器负责将输入的文本序列转换为高维表示,以便后续处理。编码器由多个相同的层堆叠而成,每个层都包含2 个主要子层:多头注意力与前馈神经网络。多头注意力将每个位置的单词与其他所有位置的单词建立注意力关系,从而捕获全局的上下文信息;前馈神经网络将每个位置的向量映射到更高维度的空间,有助于模型捕获更复杂的语义信息。每个子层后都有累加和层标准化,以稳定训练并加速收敛。编码器融合输入序列的特征,采用多层堆叠结构便于模型的逐层提取。而解码器与编码器不同的是,在解码器中还引入了遮蔽多头注意力,用于对输入序列和当前解码位置的输出建立关联,以便生成所需的输出序列。相比于传统的循环神经网络[18]与长短期记忆网络[19],Transformer 网络通过自注意力机制实现对全局信息的建模和更高效的特征抽取,且能在训练过程中有效防止梯度爆炸与梯度消失等问题,使语言模型的参数量可以扩展到千亿级别。
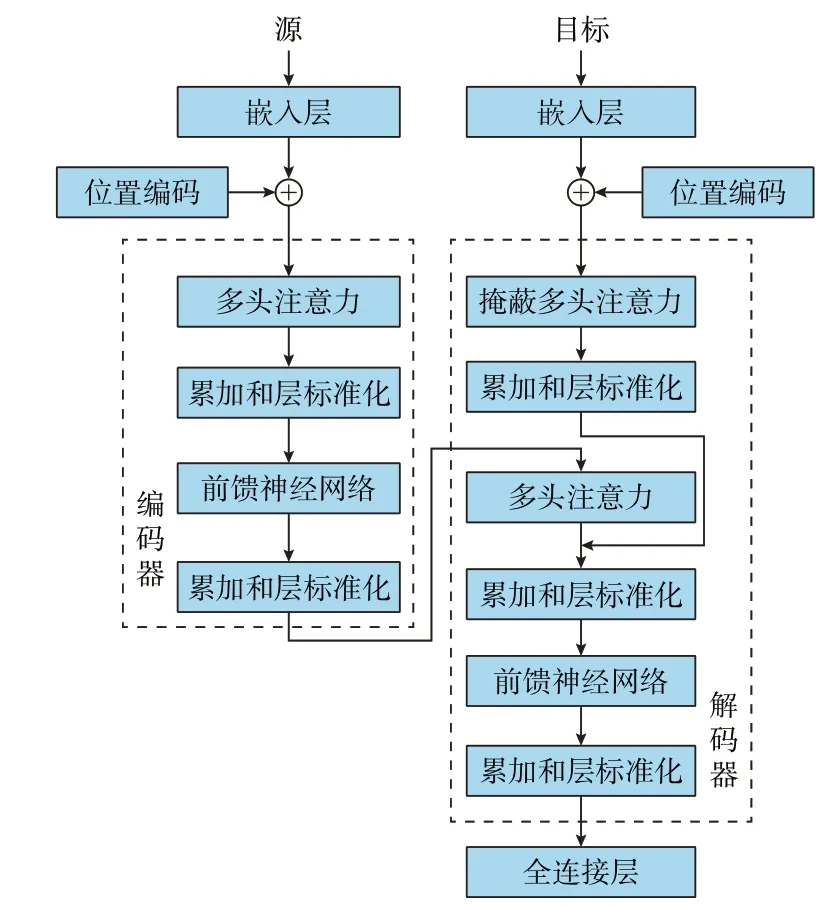
图1 Transformer 架构Fig.1 Transformer architecture
不同语言模型使用的Transformer 网络结构不尽 相 同。 例 如,BERT(bidirectional encoder representations from transformers)[20]和RoBERTa(robustly optimized bert pretraining approach)[21]使用编 码 器 结 构(encoder-only);GPT(generative pretraining transformer)[22]和GPT2[23]使 用 解 码 器 结 构(decoder-only);T5 使用编码器-解码器(encoderdecoder)结 构;GLM-130B[24]使 用 前 缀 解 码 器(prefix-decoder)结构。目前,LLM 使用最多的底层结构是解码器结构,因为该结构相比于其他结构更有利于文本生成[25]。
LLM 的训练方法通常采用预训练和微调的策略。预训练阶段通过无监督学习,让模型学习到语言的潜在表示。在微调阶段,通过在特定任务上进行监督学习,进一步优化模型的性能。在预训练阶段,通常采用无监督学习方法,例如使用自编码器或语言模型进行训练。在预训练阶段,模型通过学习大规模的文本语料库,构建了对语言的潜在表示。预训练的目标是使模型能够学习到语言的统计规律和语义信息。预训练数据一般使用网页、书籍、对话文本、代码等作为语料。预训练任务一般为语言模型任务。给定一个文本序列S={s1,s2,…,sn},语言模型任务目标是基于序列中前序文本s1,s2,…,si-1,通过自回归地预测目标文本si。目标函数L(s)可表示为如式(1)所示的最大似然函数。
式中:n为文本个数;P(·)为似然函数。
在预训练完成后,LLM 将进入微调阶段。在微调阶段,模型的参数会根据任务的损失函数进行优化,使其更好地适应具体任务的要求。PLM 微调的任务是通过在特定场景进行训练,而LLM 使用指令微 调(instruction tuning)与 对 齐 微 调(alignment tuning)进一步优化模型的性能。
指令微调的本质目的是将自然语言处理任务转换为自然语言指令,再将其投入模型进行训练,通过给模型提供指令和选项的方式,使其能够提升零样本任务的性能表现。具体而言,需要构建多任务指令集合,其中一个格式化的指令实例包括一个任务描述指令、一对输入(input)与输出(output)以及少量示例。指令微调后,LLM 可展现出处理泛化到再训练过程中从未见过任务的卓越能力。为增强模型推理能力,可采用思维链(chain-of-thought)指令微调策略[26],LLM 在微调过程中可以利用包含在中间推理步骤的提示机制来解决这些任务,得到最终答案。
部分LLM 如InstructGPT[27]完成指令微 调后,会额外使用对齐微调,目的是让LLM 输出内容更加可靠、安全,符合人类的偏好。研究人员提出了基于人类反馈的强化学习(reinforcement learning from human feedback,RLHF)[28],通过 奖励模 型使LLM产生的文本更符合人类期望的回答。RLHF 的第1 步是训练奖励模型,将指令数据集输入LLM 并得到一定数量的输出文本。然后,让有领域经验的标注人员进行排序标注,再训练奖励模型来预测文本的排名。第2 步是强化学习微调,在InstructGPT中会使用近端策略优化(proximal policy optimization,PPO)[29]来针对第1 步训练的奖励模型进一步优化LLM。其中,强化学习的状态为生成的文本序列,动作空间为LMM 的词汇库,奖励模型的排序分数为奖励。
1.3 LLM 的智能水平
现有研究表明,LLM 在逻辑推理、编程与代码理解、数学推理等领域展现出了远超传统AI 技术的智能水平。
1.3.1 逻辑推理
逻辑推理任务需要LLM 运用常用知识与一般事实的逻辑关系和证明来解答任务所提出的问题,一般而言,可分为常识理解推理与科学推理。目前的研究主要通过特定的常识理解或科学问答数据集来评估不同类型推理的能力。例如,常识理解推理可使用CommonSenseQA 数据集[30],而科学推理可使用ScienceQA 数据集[31]。对于任务评测方法,除了人为评测以外,还可以使用如双语互译质量评估(bilingual evaluation understudy, BLEU)[32]、ROUGE (recall-oriented understudy for gisting evaluation)[33]等指标来评估生成的推理过程质量。这些任务要求LLM 根据事实和知识逐步进行推理,直至给出问题的答案。其中,大型语言和视觉助理(large language and vision assistant,LLaVa,即GPT-4)[34]在ScienceQA 数 据 集 上 评 价 得 分 最 高(92.53 分),超过了人类平均评分(88.40 分)。
1.3.2 编程与代码理解
相比于预训练语言模型,LLM 在生成和理解格式化语言方面有显著的突破,尤其是在生成和理解计算机程序和代码方面,这种能力被称为编程和代码理解。与生成自然语言不同,生成的代码可通过相应语言的编译器进行编译运行,可基于此评估生成代码的准确率。目前的研究主要通过计算测试用例的通过率来评估LLM 生成代码的质量。近期已有研究提出了评测代码正确率的基准数据集,用于评 估LLM 的 代 码 生 成 能 力,例 如,APPS[35]与HumanEval[36]。基准数据集包含多种编程问题,每个编程问题包括题目描述和用于检查正确性的测试用例。文献[37]评测发现GPT-4[38]的编程与代码理解能力在LeetCode 评测集上pass@1 与pass@5已经超过了人类平均水平。此外,LLM 还可以理解、注释和修正现有的代码。文献[37]阐述了可以通过问答方式让LLM 对已有代码进行修改,经过文本提示,可以描述一个深度学习中全新的梯度下降算法,GPT-4 可以理解提示文本内容,实现编码并成功编译。
1.3.3 数学推理
数学推理任务一般包含数学计算任务或者推理证明任务。任务需要LLM 使用基本数学知识、逻辑与计算来解决任务提出的计算问题或者生成证明过程,并且需要按照推理过程生成逐步的中间推导过程与答案。LLM 中评估数学推理能力常用的数据集 包 含GSM8K[39]和MATH[40]数 据 集。其 中,GSM8K 是小学数学数据集,MATH 是高中数学数据集。LLM 需要根据描述生成准确的具体数字、方程以及推理证明过程来回答数学问题。目前,数学推理能力表现较好的LLM 有GPT-4、Minerva,其中,性能最好的模型为GPT-4,在GSM8K 和MATH 数据集的准确率分别达到了87.1% 和42.5%[37]。
从总体来讲,LLM 展现了在逻辑推理、编程与代码理解以及数学推理领域的强大能力,并在某些任务评测中超过了人类的平均水平。然而,LLM 还是会在复杂推理中出现上下文不一致[41]与数值计算偏差[42]的问题,这可以通过细化思维链及指令数据方式进行改进。
根据AGI 的定义[3],LLM 已经具备了AGI 的基本特征。AGI 系统应具备推理、学习、理解与表示知识、规划以及自然语言交流等能力,而LLM 已经在这些方面取得了重要进展,能够通过逻辑推理和证明解决问题,理解和生成复杂的计算机代码,并在数学推理中展示出准确的解题能力。目前,虽然仍存在一些挑战和局限性,但LLM 展现的强大能力为构建AGI 系统提供了有力的基础。
2 LLM 在新型电力系统中的应用展望
LLM 在新型电力系统中具有广泛且前景可期的应用潜力,这些应用场景包括但不限于电力系统负荷预测与发电出力预测、电力系统规划、电力系统运行、电力系统故障诊断与系统恢复以及电力市场等领域,具体如图2 所示。
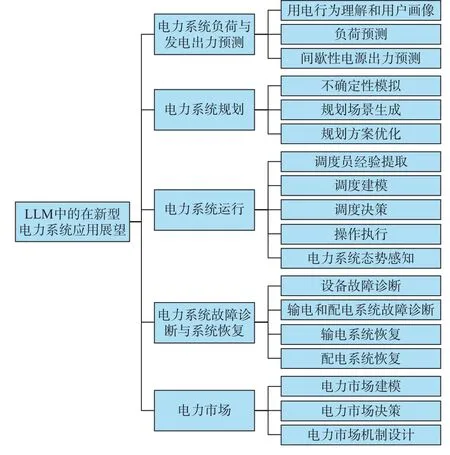
图2 LLM 在新型电力系统的应用展望框架Fig.2 Framework for application prospect of LLM in new power system
2.1 电力系统负荷与发电出力预测
电力系统的独立系统运营商(independent system operator,ISO)通过准确的电力系统负荷与发电出力预测实现经济安全的电力系统运行规划和管理。该部分从用户行为理解与用户画像、负荷预测以及间歇性电源出力预测3 个角度分析LLM 的潜在应用。
2.1.1 用电行为理解和用户画像
电力用户行为理解和用户画像构建通过分析和理解电力用户在不同时空条件和系统环境下的行为特征,构建用户行为画像,为负荷预测、节能减排以及需求侧资源聚合控制等问题提供用户行为方面的预测信息。目前的用户行为分析主要针对的是居民用户、商业楼宇以及电动汽车用户。
近期研究中,通常采用聚类方法或者社会心理学方式来对用电行为进行理解。文献[43]使用自编码器和聚类方法分析了复杂电网环境下的居民用户和电动车用户的用电行为特征。文献[44]从社会心理学角度分析了影响人们能量消费的重要因素,如家庭成员数量、年龄构成、教育程度、经济状态、房屋类型等。文献[45]通过分析用户活动、使用电器及其时间来了解家庭用电特征。文献[46]研究了瑞士第一个真实世界的点对点能源市场中家庭和商业实体的行为。文献[47]基于聚类方法分析了工商业用户的负荷特征,用于电力套餐设计。
目前,以电表为基本单位的用电行为模式研究正向更精细化的以个人和设备为基本单位的用电行为模式转变,进而考虑天气变化、心理偏好、社会环境等超出能源系统环境的因素,理解差异化的用电行为并构建精准用户画像。但是,由于天气、心理、社会等数据获取困难,且现有数据样本量较小,难以实际支撑具体的分析研究。LLM 的强泛化能力减少了对用户标注数据的依赖,有助于解决用电行为分析中用户特征缺失、多源数据融合困难等问题。同时,利用LLM 的潜在知识和理解能力,有望实现以自然语言为核心,基于数据的用户行为理解方法。
2.1.2 负荷预测
负荷预测利用历史和实时负荷数据、季节变化、节假日条件、天气状况等信息预测未来一段时间内的电力系统负荷需求。负荷预测按照预测时间长短可以划分为短期预测、中期预测与长期预测。
文献[48]提出利用卡尔曼滤波和微调技术解决无法捕捉特殊社会状态下的短期负荷预测问题。文献[49]提出一种结合迁移学习和图神经网络的短期电力负荷预测方法,以解决新居民用户缺少数据的问题。文献[50]提出一种集成机器学习的中期负荷预测方法。文献[51]提出一种基于长短期记忆网络的配电网馈线长期负荷预测方法。考虑多能负荷之间的空间耦合关系和时间耦合关系,文献[52]提出一种基于ResNet-LSTM(residual network and long short- term memory)网络和注意力机制多任务学习的预测方法。
可以发现,目前大部分机器学习方法需要海量数据的支撑才能实现负荷的精准短期预测,但新增用户和低频用电场景下的数据匮乏问题仍待解决。而LLM 在通用数据上进行预训练和学习,迁移能力强,其小样本学习能力有望解决该问题。对于中长期负荷预测问题,如何选取合适的经济、气候和社会环境特征并生成数据是主要问题。LLM 学习了大量的通用知识,经过少量领域数据进行微调,便可以通过提问、对话和提示(prompt)命令等方式形成专门的数据集。在解决可信度等问题的基础上,LLM可以解决长期负荷预测的特征选择和非用电数据生成问题。
2.1.3 间歇性电源出力预测
间歇性电源出力预测主要针对风能和太阳能等间歇性电源,基于历史和实时发电数据、天气状况等信息,预测未来一段时间内的电源出力。不同类型的可再生能源出力由于间歇性和波动性体现的时间尺度(分钟级、小时级和日级)和因素不同,在出力预测时间和特征选择上存在一定的差异。
现有研究一般基于机器学习或者深度学习模型结合多种数据源进行出力预测。文献[53]总结了不同类型可再生能源的出力预测方法和变化性评估方法。文献[54]提出一种基于贝叶斯模型,适用于小时以上不同时间尺度的光伏出力概率预测方法。文献[55]基于卫星图像数据结合时空图神经网络追踪云运动变化,以预测短期的太阳能出力。文献[56]提出一种利用超分辨率技术提高超短期风力预测准确性的方法。文献[57]提出一种基于双重注意力长短期记忆网络的超短期海上风电出力预测方法。
目前,间歇性电源出力预测向超短期预测发展,并且越来越多地考虑天气因素的影响。与负荷预测类似,新能源的数据匮乏和高频出力数据缺失是当前的重要问题之一。LLM 的小样本数据学习能力和知识迁移能力有望帮助间歇性电源实现更准确的超短期预测。同时,LLM 的知识提取能力有望帮助超短期出力预测提供实时的天气信息。
2.2 电力系统规划
电力系统规划以满足电力需求增长、系统安全运行、可再生能源消纳、系统整体经济性等为目标,对电力系统的发电资源配置、电网结构等进行综合性规划。本节从不确定性模拟、规划场景生成和规划方案优化3 个角度分析LLM 的潜在应用。
2.2.1 不确定性模拟
不确定性模拟基于历史数据和专家知识模拟电力系统的不确定性因素(例如负荷、可再生能源、经济环境等)变化的可能性来评估电力系统规划方案的预期和风险。对不确定性因素的选取与概率分布的合理假设是不确定性模拟需要解决的核心问题。
已有研究中一般使用马尔可夫链或者蒙特卡洛方法进行不确定性模拟。文献[58]针对天气、光伏和暖通空调构建概率密度函数和马尔可夫链,并用于配电网规划问题。文献[59]选取电源点和负荷作为系统的不确定性,并直接给定了具体概率。文献[60]考虑了负荷、能源价格、风电出力和设备可用性的不确定性,并对前3 个特征的不确定性构建最坏场景,最后一个特征的不确定性采用蒙特卡洛采样。文献[61]提出一种改进马尔可夫链的蒙特卡洛模拟方法,同时考虑时间独立性和不同资源的关联性。文献[62]结合蒙特卡洛模拟和价值风险指标解决可靠性评估问题。
尽管大部分因素的概率分布是可以确定的,例如风电出力服从Weibull 分布、负荷服从正态分布,但是采样数量随特征数量和时间长度呈指数级增加,难以准确模拟系统所有的不确定性因素。对于特定置信度/区间下的不确定性模拟和复杂依赖关系下的不确定性模拟问题,LLM 在微调后有望基于知识生成直觉性的模拟结果,以节省采样计算时间并达到近似的结果。同时,LLM 通过专家反馈学习,还有望实现基于不确定性模拟结果的电力系统风险评估。
2.2.2 规划场景生成
在电力系统规划中,规划场景生成主要利用历史数据、算法和专家知识,生成差异性的未来典型场景,以支撑系统规划和扩展,评估规划方案的效果。根据规划目标、系统特点和时间长度的不同,规划场景生成和选择的方法也不尽相同。
文献[63]用分层聚类获取代表日作为可再生能源不确定性的场景表示,以求解发电和输电扩展问题。针对输电扩展规划问题,文献[64]提出一种以成本为目标的动态场景聚类方法。文献[65]针对具有互相依赖特性的热电联产能源系统扩展规划问题,考虑了基于历史数据的负荷和可再生能源出力场景。文献[66]提出一种利用故障特征和故障网络特点进行规划场景选择的方法。文献[67]针对电力系统扩展规划的信息物理系统协同安全提出一种多种系统攻击场景生成方法。
规划场景生成方法绝大部分是针对特定电网目标和结构,难以将已有的场景快速迁移到具有不同结构、出力、负荷等特性的电网中,且需要选择代表性场景以减少场景数量。通过微调学习不同场景生成方法在各类型电网多种状态下的典型规划场景特征,LLM 有望实现规划场景的自动生成,即通过自然语言描述自动生成典型规划场景,并调整优化具体场景。例如,通过输入“考虑新能源、负荷和网络信息攻击,生成20 个IEEE 30 节点系统的典型场景”,可以依靠LLM 直接完成。
2.2.3 规划方案优化
规划方案优化通过物理模型和不确定性场景描述系统特征,以经济性、安全性、可再生能源消纳等为目标,利用优化算法求解最优的电力系统规划方案。由于目标和场景的差异性,模型选择上也存在差别。
目前,已有的研究通常根据不同目标使用优化算法来求解规划方案。文献[68]考虑了可再生能源装机容量和环境成本目标,提出一种结合容量规划和运行优化的两阶段优化方法。针对具有能源-水-排放关系的区域电力系统规划问题。文献[69]综合多种优化方法,提出一种解决冲突和顺序目标的优化框架。文献[70]总结了高比例可再生能源下电力系统规划优化中的系统模型、约束条件和不确定性因素。文献[71]提出一种考虑投资成本、系统效率和系统可靠性的离岸风力发电场规划模型。文献[72]提出一种基于合作博弈的共享储能与分布式光伏容量协同规划方法。
总体来说,规划方案优化是一个构建模型、确定约束和不确定性、优化求解的过程,而LLM 主要可以从两方面改进这个过程。一方面,尽管规划优化能够求解得到规划方案,但是该方案难以被直观理解,LLM 的自然语言生成能力可以应用于优化方案自动解释中,通过对比理解不同方案,生成最优方案的自然语言说明;另一方面,规划方案优化需要考虑不同的模型和约束条件,以求解得到更准确的规划结果。但是,过于复杂的模型和约束会导致优化难以求解。因此,需要大量尝试不同的模型和约束条件。通过训练规划方案与模型和约束之间的关系,LLM 有望通过自然语言快速生成对应的规划模型和约束条件,以减少电力系统规划的工作量。
2.3 电力系统运行
电力系统在运行过程中,不仅需要调度模型进行最优调度决策,还需要调度员根据实时负荷偏差通过操作票对发电机组、线路等设备进行人为调度修正。本节从以调度员为核心,围绕调度员经验提取、调度建模、调度决策、操作执行和电力系统态势感知5 个角度分析LLM 的潜在应用。
2.3.1 调度员经验提取
调度员经验提取的目标是通过从调度员调度数据中获取对调度调整、紧急事件处理等系统运行相关的经验和知识,以帮助新调度员快速学习调度知识、提供紧急调度辅助优化决策以及调度模式分析等。
现有的相关研究相对较少,主要采用知识图谱和生成对抗网络方法提取调度员的行为经验。文献[73]通过构建配电网拓扑知识图谱实现配电网拓扑识别。文献[74]提出一种构建电网调度知识图谱的方法。文献[75]总结和展望了知识图谱在电力系统调度和运作的潜在应用。文献[76]针对短期调度任务提出一种基于生成对抗网络的调度行为学习方法。
现有的调度员经验提取方法最大的问题在于提取的经验可拓展性和可迁移性较弱,难以形成通用和全面的电网调度经验知识并适用于具有不同网架结构、负荷、出力以及设备特点的电网。利用LLM泛化性强的特点,可以将调度员行为数据总结为更加通用的、可解释的调度经验知识,以改进结构化知识的弱点。
2.3.2 调度建模
调度建模通过对电力系统拓扑、设备状态和运行规则进行建模,以支撑电力系统调度决策和分析。根据系统特性、设备条件、系统约束等不同,调度建模也不尽相同。
近期研究中,一般根据不同场景建立目标优化模型。文献[77]考虑了5 种不同的调度模式和动态碳排放交易系统,提出了风光火一体化多能源混合电力调度模型。文献[78]针对火电、水电和可控负荷作为可调度资源的电力系统,提出一个日前调度模型。文献[79]由可再生能源和能源中心组成的孤岛电网进行分布式运行管理。文献[80]针对区域综合能源系统提出了考虑可再生能源不确定性和电动汽车的多目标优化模型。文献[81]针对信息物理融合的微能源网,提出综合多种因素的统一调控模型。
目前,调度建模正向多能源种类、多设备类型和多系统融合发展,这将导致调度建模越来越复杂,对调度员的要求越来越高。与程序代码类似,LLM 有望从两方面辅助调度员进行调度建模。一方面,可以利用LLM 对建好的调度模型进行特性解释,生成调度员可以理解的模型特征描述,例如,设备类型、能源种类等;另一方面,基于自然语言生成和改进调度模型的设备、约束等函数,可减少调度员构建模型的工作量。
2.3.3 调度决策
调度决策基于调度模型和优化目标求解包括启停机计划、发电机组出力、输配电线功率、可控负荷等控制变量,以满足电力系统经济安全低碳运行需求。在这个过程中,调度员要根据经验对调度决策结果进行分析评估和调整。
目前已有研究中通常采用目标优化或者博弈方法进行建模。文献[82]提出一种同时考虑经济成本、电压偏差和统计电压稳定指数的多目标调度方法。文献[83]提出一种基于Stackelberg 博弈的综合能源系统低碳经济调度方法。针对园区综合能源系统,文献[84]提出一种以经济和环境为目标的优化调度方法,并考虑了碳市场的影响。文献[85]提出一种基于有限时间共识的分布式优化算法来解决经济调度问题。文献[86]采用滚动优化方法在线求解每个调度时段的孤岛运行方案,并提出了间歇性电源的有功出力控制策略。
多目标是未来电力系统调度决策的重要发展方向,这需要调度员从经济性、安全性、低碳性、各个主体的博弈关系、与其他能源系统的配合等多个角度综合评价调度决策的好坏,增加了判断的难度。
LLM 可以对决策进行快速评估,输出自然语言的决策评估结果,以帮助调度员快速分析调度决策在各个维度的表现。同时,调度员可以利用自然语言让LLM 提供决策改进建议,以辅助调度员进行快速的调度决策调整。
2.3.4 操作执行
操作执行是将调度决策落实到电力系统的实际操作过程。具体而言,就是调度员根据经验进行调度计划的调整,并编写操作票。
目前还没有专门针对操作执行的具体研究。在写作辅助任务方面,LLM 已经表现出强大的上下文生成和泛化能力。文献[87]提出一种基于LLM 的AI 辅助邮件写作工具。文献[88]探索了指令微调在不同写作辅助场景对LLM 的改进效果。
与其他写作辅助任务类似,经过特定任务微调后的LLM 可以根据调度员的调度决策关键信息生成规范化的业务操作票,以节省调度操作执行的时间。
2.3.5 电力系统态势感知
电力系统态势感知针对大规模复杂电网系统状态难以直观理解的问题,通过历史和当前电网的测量数据,基于事件分析和系统状态预测算法实现对电力系统状态的监测、分析和预测,并通过可视化技术展示结果。
已有研究通常使用基于测量系统或者神经网络方法进行态势感知。文献[89]提出一种基于广域测量系统的同步发电机一致性检测方法,用于电力系统态势感知中。文献[90]提出一种基于配电网相位测量单元数据的事件提取和检测方法。文献[91]提出基于卷积神经网络和长短期记忆网络的态势感知方案,用于检测故障位置和预测稳定性。文献[92]利用迁移学习解决电力系统少样本事件的识别问题。文献[93]分别对电力系统态势感知在电力系统事件监测、电力系统事件辨识、电力系统风险预测、态势可视化技术、广域控制和风险调度进行了技术总结和展望。
现有电力系统态势感知的难点在于如何融合多类型事件识别结果形成未来态势预测,并可视化展示。LLM 可以将态势预测数值结果转化为调度员可以理解的系统态势自然语言表示,然后结合图像化插件,形成可视化态势感知展示结果,以辅助调度员快速理解系统整体运行态势。
2.4 电力系统故障诊断与系统恢复
电力系统故障诊断通过对监测信息和报警信息的分析确认故障的类型、位置和原型,并采用设备修复、切机切负荷、主动解列等措施将电力系统恢复到正常状态。本节从设备故障诊断、输电和配电系统故障诊断、输电系统恢复和配电系统恢复4 个角度分析LLM 的潜在应用。
2.4.1 设备故障诊断
电气设备故障诊断针对不同类型设备结构和功能特性,利用气体、光学等传感器数据信息进行设备的故障特征提取与分类。不同类型设备的监测数据和故障诊断方法差异较大。
目前,已有研究中一般基于不同的传感器数据整合及处理方式进行故障诊断。文献[94]基于有载分接开关振动信号数据,提出一种基于同源异构数据特征融合的机械故障诊断方法。文献[95]基于变压器溶解气体分析数据,提出一种结合序贯卡尔曼滤波的故障诊断方法。文献[96]提出一种基于定子电力和振动信号的感应电动机多类型故障诊断方法。文献[97]提出一种基于红外图像切割和温度分析的变电站绝缘子故障诊断方法。文献[98]提出基于数字孪生的小型变压器管开路故障诊断方法。
设备故障检测主要利用感应数据进行故障类型识别,但各类型故障数据量小,环境、天气、系统等外部因素难以采集是设备故障监测的主要难点。LLM 的泛化性优势有望帮助设备故障检测解决该问题,即利用小样本微调学习适合于目标设备的诊断模型。同时,LLM 也可以基于诊断结果和系统状态自动生成故障诊断综合报告,减少后续决策时间。
2.4.2 输电和配电系统故障诊断
电网故障诊断需要从故障数据和监测数据中快速匹配故障特征,分析故障的原因和位置,为故障恢复提供可靠依据。输电系统故障诊断主要涉及高压输电线路、变电站等设备的故障,而配电系统故障诊断主要涉及低压配电线路、配电变压器等设备的故障。
在目前的研究中,通常基于非线性或者深度学习模型进行故障诊断。文献[99]考虑电力物联网信息下,基于分布式相位测量单元数据判断故障位置和类型。文献[100]提出一种基于深度学习的紫外线-可见光视频处理方法,用于配电网线路故障诊断。文献[101]提出一种针对主动配电网的高阻抗故障诊断的非线性等效模型。文献[102]通过将自觉模糊逻辑加入脉冲神经P 系统,提出一种改进的电力系统故障诊断方法。文献[103]提出一种基于卷积神经网络的交直流输电系统故障诊断方法。
输配电系统故障诊断情况复杂、可能影响因素多且存在信息误报和多故障同时发生的可能性,很难做到对所有的故障类型同时诊断。LLM 的通用性有望将不同类型故障诊断的知识学习融汇到一个模型中,实现多类型故障的同时诊断。
2.4.3 输电系统恢复
输电系统恢复的目标是在发生输电系统故障后,恢复输电系统的供电能力和稳定性,更关注输电网解列后子系统如何快速协调恢复的问题。
目前,一般采用整数规划求解方法来完成输电系统恢复。文献[104]提出一种基于两阶段混合整数线性规划问题的自适应输电系统恢复决策方法,以减少系统恢复时间。文献[105]提出双层决策的多分区输电网系统恢复方法。文献[106]针对高风电渗透率的输电系统恢复,提出一种鲁棒分布式的并行子系统协调方案。文献[107]提出一种计及通信系统失效的信息物理协同恢复策略。
输电网恢复需要在确保电网安全的基础上采用多阶段方式逐步恢复电网稳定输电的能力,在高比例新能源渗透的情况下其安全性和稳定性愈发难以保障。LLM 更适用于对恢复方案的多维度安全综合评估,以辅助调度员进行恢复方案调整和确认。
2.4.4 配电系统恢复
配电系统恢复主要涉及修复故障设备、恢复接通用户和运行备用设备等操作,以恢复配电系统的供电服务能力。
在已有研究中通常使用调度与协调方式完成配电系统的恢复。文献[108]提出一种考虑柔性软开关的多周期配电系统恢复模型。文献[109]提出一种考虑电-水-气互相依赖的配电系统恢复方法。文献[110]提出一种协调维修人员、移动电源、可再生能源和储能资源的稳健恢复方法。文献[111]通过调度分布式能源、配电系统控制设备的输出以及输电系统恢复的功率消耗,逐步恢复配电系统平衡。文献[112]提出一种考虑间歇性电源出力不确定性的配电系统恢复模型。
相对于输电系统恢复,配电系统恢复可控对象更少,决策时间更短,更容易形成标准化的恢复方案。一方面,LLM 可以基于调度员的语言提示快速生成恢复方案,并通过具体标准进行评价,以帮助调度员快速选择合适的恢复方案;另一方面,对于维修人员,LLM 可以通过视频接入实现恢复过程中的设备操作指导和监督,进一步确保操作人员的行为安全。
2.5 电力市场
目前,很多国家和地区都在经历深刻的电力市场化变革。美国、欧洲、澳大利亚等已从传统的垄断型电力体制转向更加开放和竞争的电力市场模式,以提高效率和鼓励创新。从2015 年开始,中国的电力市场改革也正在快速推进。在电力市场改革的推动下,正在逐步引入竞争机制,同时也在积极推动电力系统的清洁和智能化。
电力市场研究涵盖了一系列复杂且相互关联的问题和环节,主要包括电力市场建模、电力市场决策、电力市场机制设计等。LLM 在这些问题中均有很大的应用潜力。
2.5.1 电力市场建模
电力市场建模是对电力市场进行定量研究的基础。典型的电力市场模型包括以下几个方面。首先,它涉及物理电力系统的建模,包括发电机、电力网络和负荷。其次,需要构建电力市场交易机制的模型,例如现货电力市场的出清机制模型。最后,还需要构建市场参与者交易行为的模型。其中,对物理电力系统和电力市场交易机制的建模研究相对成熟,但市场参与者行为的建模仍面临许多未解决的挑战。
在经济学的传统研究方法中,交易行为的建模主要依赖于博弈论或优化模型,这些模型的优势在于它们拥有严谨的理论基础。然而,这些模型通常需要对市场参与者做出严格的理论假设,例如理性人假设或完全信息假设,这些假设在真实市场中可能并不总是成立,从而可能导致模型结果与市场实际情况的偏差。而利用机器学习等AI 技术可以基于历史数据,对市场主体交易行为进行更加精确的建模。文献[113]对基于AI 的电力市场建模研究进行了较为完整的论述。现有文献已将监督学习(如神经网络与支持向量机)、无监督学习(如聚类算法)、智能优化(如遗传算法)等多类AI 技术应用于解决电力市场交易行为建模问题。相关研究覆盖了主网市场、配电网市场、微电网交易、端到端(peerto-peer,P2P)交易等多种市场类型[113]。
虽然基于机器学习技术的交易行为建模方法可以不受传统经济学理论假设的限制,但这些方法属于数据驱动方法,需要足够的历史数据保证模型准确性。在实际应用中,可能面临历史数据不足,或在市场基本面发生结构性变化时,模型泛化能力差等难题。如1.3 节所示,LLM 在很多应用中已经展现了远超传统机器学习方法的常识理解和逻辑推理能力。因此,LLM 在少样本和无样本的应用中具有显著优势。文献[114]研究表明,基于ChatGPT 可以在不需要历史数据的情况下,真实地模拟人类在一个小型社区中的常识性行为。基于类似思路,在市场建设初期、历史交易数据不足或难以获取、市场基本面突然发生结构性变化等情况下,利用LLM 有可能构建更加精确,且能够基于常识考虑各种市场外生变量影响的交易行为模型。
2.5.2 电力市场决策
在给定市场机制的前提下,市场主体如何优化自身决策是电力市场研究中的一个重要课题。现有文献中,针对相关问题的研究包括利用时间序列模型与深度学习模型对市场边界条件(如负荷、碳价格)进行预测[115]、利用深度强化学习等技术解决现货市场竞价策略优化[116]、双边交易策略优化[117]、需求响应策略优化[118]、风险管理[119]等各类决策问题。与上述方法相比,LLM 的主要优势是在给定不同的市场机制与边界条件的情况下,具有基于常识和逻辑推理自主生成策略的能力。因此,可以探索基于LLM 的能够应对市场环境快速变化的电力市场决策方法。
2.5.3 电力市场机制设计
电力市场机制设计是指为电力产业制定一套规则和机制,以便在电力生产、传输、分配和消费的各个环节中实现有效的资源配置。这涉及一系列关键决策,包括市场结构(如垄断、寡头或竞争)、定价机制(如成本加成定价或竞争拍卖)、交易规则(如双边合同或集中市场)等。现有的电力市场设计研究通常以机制设计理论为基本理论工具[120]。机制设计理论主要研究在信息不对称的情况下如何设计一种机制,使得每个参与者在追求自身利益的同时,整个系统能够达到某种预定的社会目标(如市场效率、公平性、可持续性、激励相容等)。现有文献中,机制设计理论一般以博弈论作为量化建模的工具[121],将机制设计理论与LLM 结合,利用LLM 的常识理解与逻辑推理能力,更精确合理地模拟市场主体行为,从而更好地保证电力市场机制设计的合理性与实用性,是一个很有前景的研究方向。
3 基于LLM 构建电力系统AGI 所面临的挑战
3.1 数据管理问题
在电力系统应用研究中,LLM 的一个重要挑战是数据管理问题,具体来说是数据质量和可获取性的挑战。这2 个问题对于电力系统的分析和优化具有关键性的影响。
1)数据质量问题。电力系统中的数据通常来自各种传感器和监测设备,如同步测量单元和智能电表[122]等。数据格式通常包含复杂操作调度指令、信号序列等信息。这些设备可能存在噪声、缺失值、异常值等问题,导致数据质量不高[123]。这些问题会对LLM 的训练与推理产生影响,从而影响电力系统的稳定性和可靠性。
2)数据可获取性问题。电力系统中的数据通常分布在不同的地方,包括各个电站、变电站、输电线路等,数据的获取和整合比较困难[124]。此外,电力系统中的数据通常是实时生成的,需要实时采集和处理,这也增加了数据获取的难度。为了解决这些问题,研究人员需要开发高效的数据采集和处理方法,以便在保证数据质量的同时,提高数据的可获取性。
为了应对这些挑战,研究人员可以采用多种方法来提高数据质量和可获取性。例如,可以使用数据清洗和预处理技术来消除噪声、填补缺失值和检测异常值[125]。此外,可以利用分布式计算和云计算技术来实现数据的实时采集和处理[126]。通过这些方法,研究人员可以在保证数据质量的同时,提高数据的可获取性,从而为电力系统的优化和分析提供更可靠的支持。
3.2 LLM 的透明可靠性
LLM 的另一个挑战是其可解释性和可靠性。
1)可解释性问题。LLM 通常是黑盒模型,难以解释其预测结果的详细机理。在电力系统中,LLM产生的决策和预测的可解释性对于操作人员和决策者至关重要。然而,由于LLM 的复杂结构和参数数量巨大,其内部机制和决策过程往往难以解释和理解[127]。这可能导致研究员与调度员对模型的信任度降低,影响电力系统的调度建模与决策模型的应用和接受度。另外,LLM 在训练过程中可能受到数据偏差和样本不平衡的影响,导致模型在特定场景下的可靠性不足。因此,如何提高LLM 的可解释性和可靠性,使其能够给出可信的预测结果,并与操作人员和决策者进行有效的沟通和交互,是电力系统应用中亟待解决的问题。
2)可靠性问题。LLM 的可靠性是指模型的预测结果是否准确可靠。在电力系统中,模型的负荷或者电源出力预测结果直接关系到电力系统的安全和稳定运行[128]。因此,需要对模型的可靠性进行评估和验证,以确保模型的预测结果准确、可靠。常用的评估方法包括交叉验证[129]、测试集验证[130]等。
3.3 信息安全与隐私保护
LLM 在电力系统应用中还面临着信息安全和隐私保护的挑战。
1)信息安全问题。LLM 通常需要在网络上进行传输和共享,涉及网络信息安全问题。需要采取一系列的网络安全措施,如防火墙、加密传输、身份认证[131]等方法,确保模型在传输和共享过程中的安全性。
2)数据隐私问题。电力系统作为关键基础设施,涉及大量敏感信息和关键操作。LLM 在训练和应用过程中,需要使用和处理大量的电力系统数据。然而,这些数据往往包含相关设备、网络拓扑、运行状态和安全策略等敏感信息,并且涉及能源安全和国家安全等重要领域,需要保证数据的安全性和隐私性[132]。在收集LLM 训练语料时需要注意去除用户用电信息、电力系统拓扑结构及运行等敏感信息。在使用LLM 进行数据分析和预测时,需要采取一系列隐私保护措施,如数据加密、权限控制和安全传输等方法,确保数据的安全性和隐私性。
3)模型隐私问题。LLM 通常是基于大规模数据训练得到的,可能包含一些敏感信息。在使用这些模型进行数据分析和预测时,需要采取一些隐私保护措施,如差分隐私[133]、模型剪枝[134]等方法,确保模型的隐私性。
为了应对LLM 在电力系统应用中的信息安全与隐私保护挑战,需要采取综合性的应对策略。这些策略包括以下3 个方面:1)安全开发和部署,在LLM 的开发和部署过程中,应遵循安全开发生命周期的原则,确保模型在设计、开发、测试和部署阶段都符合安全要求[135];2)数据脱敏和匿名化,在收集和处理电力系统数据时,应采用数据脱敏和匿名化技术,以降低数据泄露的风险[136];3)安全审计和监控,对LLM 的使用和访问进行实时监控,以便及时发现和应对潜在的安全威胁[137]。通过实施这些综合性应对策略,可以有效处理LLM 在电力系统应用中的信息安全和隐私保护。
4 结语
建立新型电力系统被视为实现国家“碳中和”目标的关键策略和必要保障。运用AGI 技术进一步增强电力系统的智能水平,为解决新型电力系统所面临的各种挑战提供了全新的途径。近年来,LLM代表了AI 领域的重大突破,标志着AGI 发展的新方向。本文首先对LLM 的原理和实现技术进行了介绍,同时探讨了与传统AI 技术相比,LLM 在智能水平上的核心优势。接着,对LLM 在电力系统领域的潜在应用进行了展望,包括负荷预测、发电出力预测、电力系统规划、电力系统运行、电力系统故障诊断与系统恢复、电力市场等领域,以及通向新型电力系统的自主调度、可靠规划与决策、智能诊断与恢复等目标。最后,探讨了LLM 在数据管理、模型透明可靠、信息安全等方面所面临的挑战。
