基于机器学习和未来气候变化模式的埃塞俄比亚粮食产量预测*
2024-03-25李发东张秋英艾治频冷佩芳乔云峰
徐 宁 ,李发东 ,张秋英 ,艾治频 ,冷佩芳 ,舒 旺 ,田 超,李 兆,陈 刚,乔云峰**
(1.中国科学院地理科学与资源研究所生态系统网络观测与模拟重点实验室 北京 100101;2.中国科学院大学中丹学院北京 100049;3.中国环境科学研究院 北京 100012;4.美国佛罗里达州立大学 塔拉哈西 32306)
尽管全球绿色革命取得了成功,粮食产量提高了100%~200%[1],但全球仍有超过10 亿人面临饥饿和营养不良的困境[2]。在非洲,粮食缺乏尤为严重,21.5%的人口处于高度粮食不安全状态,高于全球平均水平的9.2%[3-5]。埃塞俄比亚是粮食不安全情况最严重的国家之一[6],因此农业对于埃塞俄比亚人民的生活至关重要,在严酷的气候条件下粮食产量的变化也严重影响着该国的粮食安全。
气候变化影响下的全球粮食安全问题是21 世纪最重要的挑战之一[7-11]。通过研究气候变化对玉米(Zea mays)、小麦(Triticum aestivum)和水稻(Oryza sativa)等作物生产的影响[12-21],以及气候变化对流域水资源[22-23]、森林[24]、工业和自然景观的影响[25],学界发现气候变化是影响作物年产量的最重要因素之一,气候变化的不确定性将大大增加粮食生产的不确定性。
气候变化情景是基于一系列气候关系和辐射强迫假设对未来气候的合理描述[26-29]。第六次国际耦合模式比较计划(CMIP6)应用了最新的共享社会经济路径-代表性浓度路径情景(SSP-RCP)模拟不同的未来发展情景,并通过全球气候模式(GCM)[28]进行气候变化预测。GCM 是模拟当前和未来气候变化的重要工具,可以使研究人员更 好地了解气候变化在区域尺度上对作物生产的影响[30]。
近年来,随着人工智能的快速发展,机器学习逐渐被引入各个应用领域的研究中。机器学习应用于产量预测的主要优势是能够基于复杂的非线性农业数据建立作物产量预测模型[31]。Gonzalez-Sanchez等[32]选择了10 种作物,利用5 种机器学习模型构建了作物产量预测模型并评估了每种机器学习算法的表现。Filippi 等[33]结合多属性数据划分生长期,并构建随机森林产量预测模型。Khanal 等[34]采集了土壤样本,结合多光谱影像数据,构建了玉米产量预测模型。综合来看,机器学习在作物产量预测方面的精度优于一般统计方法,通过选取适当算法、合理添加关键参数、精准调参等优化后的机器学习可胜任数据稀缺地区(如埃塞俄比亚)粮食产量预测。
埃塞俄比亚约有9100 万人口,位居非洲第二[35],其主要粮食作物有玉米、苔麸(Eragrostis tef)、大麦(Hordeum vulgare)、小麦、高粱(Sorghum bicolor)及各种豆类[35]。该国农业产业规模较小、作物生产力不高,同时粮食生产结构较为单一,这就直接导致了该地区农业敏感性较高,抵御气候波动的能力较差[36]。与此同时,严重的水土流失和干旱也对其农业生产造成不良影响[37-38]。自“一带一路”倡议中明确把非洲纳入“21 世纪海上丝绸之路”以来,东非国家在“一带一路”合作中所处的地位愈发重要[19],其中埃塞俄比亚的发展对“一带一路”倡议在非洲的推进发挥着重要作用。粮食安全作为保障埃塞俄比亚健康发展的重点抓手,是我国国家战略推进的关键制衡因素,也是实现联合国可持续发展目标的国际研究热点。
鉴于此,本研究拟以埃塞俄比亚为研究区,基于历年作物产量数据、未来气候变化模式模拟数据和其他农业相关的环境及社会经济数据,针对埃塞俄比亚产量排名前五的粮食作物(即苔麸、玉米、高粱、小麦和大麦),利用多种机器学习算法训练产量预测模型并进行预测,通过多种模型结果的分析对比,确定表现最佳的机器学习算法,进一步结合CMIP6 中提供的SSP-RCP 情景,预测研究区2050 年之前不同未来情景下粮食产量的变化,并对研究区未来粮食生产情况进行分析。
1 材料与方法
1.1 研究区概况
埃塞俄 比亚位 于非洲 东北部(3°~15°N,33°~48°E),国土面积112.68 万km2,北部、南部、东北部的沙漠和半沙漠约占领土面积的28%。65%的国土为可耕地,实耕13.2 万km2,其中粮食耕地占3/4[36-37]。埃塞俄比亚地区海拔主要分布在2500~3000 m。国家划分3 级行政区级别,分别是州(Region)、区(Zone)、县(Woreda),行政区划如图1 所示。埃塞俄比亚分布有7 种气候类型,兼有热带气候、温带气候以及干旱气候。高海拔地区年平均气温约为15℃,低海拔地区年平均气温约为25 ℃。此外,埃塞俄比亚平均年降雨量在西部出现极大值(>2000 mm·a-1),在东北低海拔地区以及东南部出现极小值(<200 mm·a-1)[5-6]。
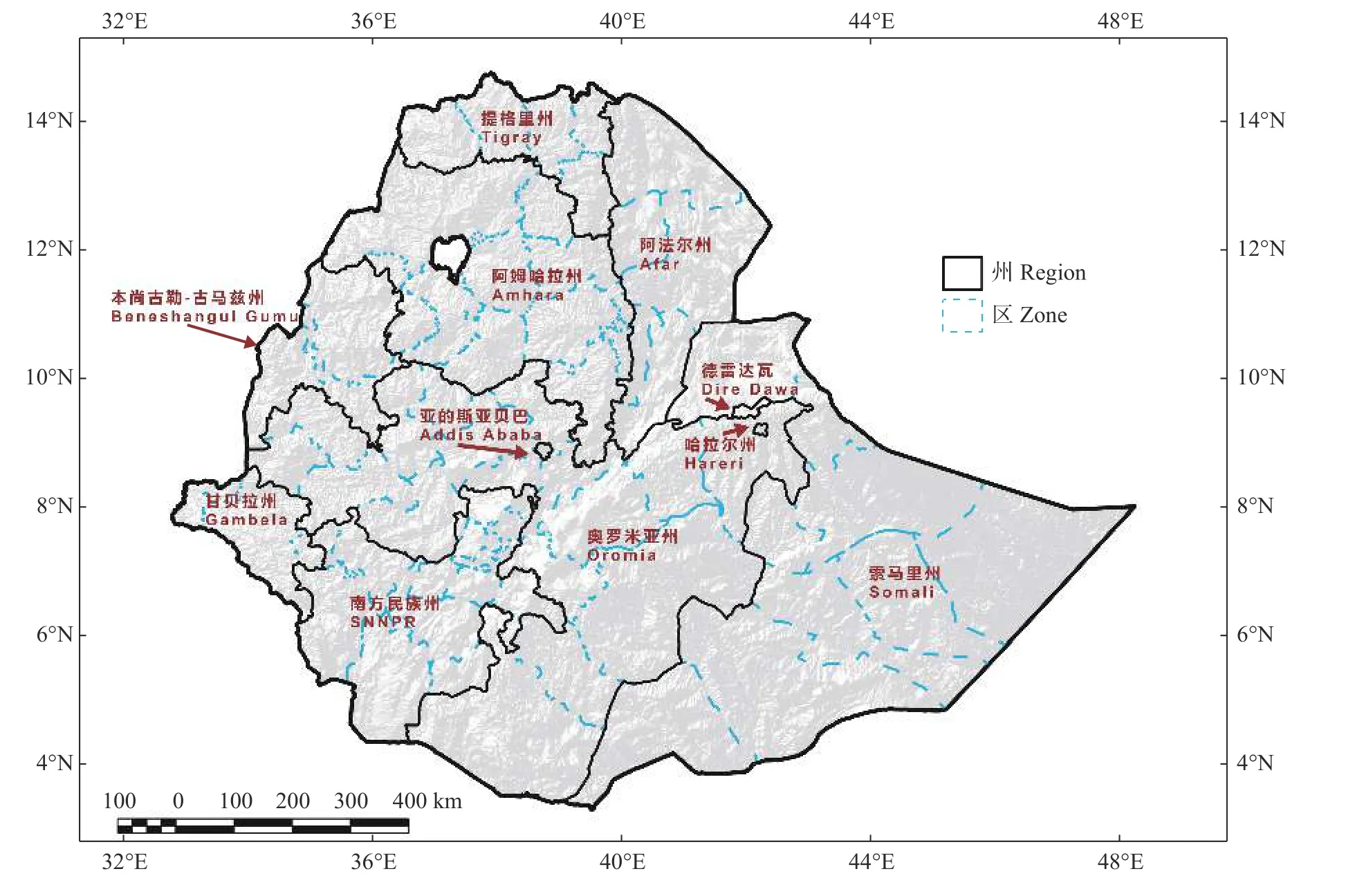
图1 埃塞俄比亚行政区划Fig.1 Administrative division of Ethiopia
1.2 数据准备
1.2.1 粮食产量数据
通过检索联合国粮食及农业组织统计数据库(https://www.fao.org/faostat/en/#home)、埃塞俄比亚中央统计局数据库(http://www.csa.gov.et/),获取1995—2020 年埃塞俄比亚市级5 种主要粮食作物(即苔麸、玉米、小麦、大麦和高粱)单位面积产量数据,其原始数据的产量单位均为t·hm-2。
埃塞俄比亚全年粮食生产活动主要划分为两个主要生产季: 梅赫季(Meher season)和贝尔格季(Belg season)。梅赫季(每年的4—12 月)粮食产量约占全年粮食产量的90%以上,其粮食的主要生长时间为7—9月;贝尔格季为每年的2—9 月,粮食的主要生长时间为4—5 月。研究中所使用的作物产量数据包含该作物当年梅赫季产量和贝尔格季产量。由于贝尔格季作物产量较低,且部分地区不适宜粮食作物种植,该季数据在时间和空间尺度上的缺失均较为严重。
1.2.2 GCM 数据
本研究所使用的未来气候变化模式数据是CMIP6 中参与模式比较的GCM 模拟结果数据。从CMIP6 项目官方网站的下载通道(https://esgf-node.llnl.gov/search/cmip6/)收集了37 个数据较为完整的常用GCM,附表1 中为所选取的GCM 列表及相关信息(见文后电子版链接)。选取GCM 中数据相对较全的9 个变量: 近地面比湿度(huss)、降水量(pr)、近地面气压(ps)、地面下行短波辐射量(rsds)、近地面气温(tas)、近地面日最高气温(tasmax)、近地面日最低气温(tasmin)、近地面东向风速(uas)和近地面北向风速(vas)。变量信息如表1 所示。

表1 研究初步选用的未来气候变化模式气候参数列表及信息Table 1 List and information of preliminarily selected Global Climate Model (GCM) variables
本研究所选取的全球气候模型 GCM 变量均源自于统一的实验场景设置,即在模型运行次数(Run)、初始条件(Initialization)、物理方案(Physics)以及强迫数据(Forcing) 4 个方面均采用第1 个方案(均标记为1),即r1i1p1f1。具体而言,本研究包括历史情景(historical)以及3 个代表性浓度路径(Shared Socioeconomic Pathways,SSPs),分别为SSP1-2.6 (SSP-126)、SSP2-4.5 (SSP245)和SSP5-8.5 (SSP585)。这些情景将被分别应用于历史及未来气候变化数据的计算与分析中。此方法论的应用旨在确保模型输出的一致性与可比性,为评估不同气候情景下的潜在变化提供了坚实的基础。
1.2.3 格点化再分析数据
GCM 输出结果是基于大尺度(比如大陆尺度)的气候数据,空间分辨率较低,一般在百公里尺度以上。统计降尺度方法是提高GCM 预测精度的常用方法,该方法可以通过使用真实或近似真实的高分辨率历史气候数据作为参考,将低分辨率的GCM 输出数据转化为较为准确的高分辨率气候数据[39]。
本研究选择ERA5 (欧洲中期天气预报中心)数据作为高分辨率历史气候数据参与GCM 降尺度。ERA5 提供了大量大气、陆地和海洋气候变量的每小时估计值[40-41]。具体使用的数据集为ERA5-land的月平均数据,它与ERA5 的其他部分相比分辨率更高,为0.1°(≈9 km)。选取的变量为1995—2020 年2 m空气温度、总降水量、地面下行短波辐射量、10 m东向风速、10 m 北向风速作为降尺度输入数据。
1.2.4 土壤性质数据
土壤属性分布情况在空间尺度上极大程度地影响了粮食种植和产量分布。本研究将土壤属性参数作为不随时间变化的空间分布属性参与模型计算。
选取国际土壤参考和资料中心(ISRIC)土壤信息数据库中的SoilGrids250m 2.0[42]数据集作为土壤属性参数数据(https://soilgrids.org/)。SoilGrids 的输出结果是6 个标准深度间隔的全球土壤属性地图,空间分辨率为250 m。本研究中首批参数选择5~15 cm 深度土壤的容重、阳离子交换量、总氮、pH、有机质含量作为土壤参数。为缩减运算量,选择SoilGrids 中低分辨率(5 km)子数据库。
1.3 原始数据优化
1.3.1 GCM 模型评价和筛选
使用泰勒图和技能得分进行37 个GCM 表现的比较,泰勒图是气候模式评价中应用较为广泛的一种方法[43-46],它主要通过相关系数、均方根误差和标准差对GCM 的表现进行综合评判。对于给定的N个散点数据的相关系数(R)、模拟场(Xmi)的标准差(dm)、观测场(Xoi)的标准差(dg)和均方根误差(RMSE)的计算方法分别如下:
此外量化指标技能得分(S)[43]可以量化模拟场与观测场之间的相关系数以及两者的标准差,以评估模型模拟能力的强弱。技能得分的计算方式如下:
式中:R为模拟场与观测场的相关系数;R0为所有模拟场和观测场所能达到的最大相关系数,即所有模型相关系数中的最大值;σf为模拟场标准差dm与实测场标准差dg之比,即 σf=dm/dg。
从37 个GCM 中选取降水量(pr)和近地面气温(tas)两个变量参与评价。计算各模型技能得分,统计各个GCM 的pr 和tas 技能得分,并分别按照两个变量对GCM 进行排名并打分。打分原则是技能得分最低(第37 名)的GCM 获得1 分,技能得分最高(第1 名)的GCM 获得37 分,以此类推,最终将每个GCM 两个变量的分数平均值作为最终得分。
在气候模式评估及其应用的相关研究中,极少直接将表现最优的模型作为唯一选择,往往同时选取表现较为优秀的多个模型组成最优模型集合(MME)[47],并将MME 的加权平均值输出为最终变量值。因此本研究选取模型表现平均得分最高且数据完整的5 个GCM 组成MME,并以其得分作为分配权重的依据,计算5 个GCM 中各个变量的加权平均值,得到各个变量的最优模型集合平均值(MMME),并作为机器学习模型的输入数据。MMME的计算方法如下:
式中:N为最优模型集中的模型个数,即为5;Tn为第n个模型的得分; Modn为第n个模型的模拟结果。
1.3.2 变量的相关性分析和筛选
初步选择的9 个GCM 气候变量以及5 个土壤变量都是基于其在过往文献中的使用频率,并没有判断这些变量是否适用于研究区。因此,本研究需要先判断它们是否对研究区粮食作物产量具有足够影响,以及它们之间是否存在共线性过高的问题。通过去除高相关性变量以及数据降维处理等方式可以降低变量之间的共线性,去除冗余的特征变量,使机器学习模型具有更高的鲁棒性以及更强的可解释性[48-50]。
使用斯皮尔曼相关系数进行变量之间的相关性分析。对于样本容量为n的两个样本,其相关系数ρ的计算方法如下:
式中:xi、yi为两个变量中的第i项数据。
1.4 GCM 模型降尺度
利用机器学习降尺度方法对GCM 数据进行空间降尺度。采用随机抽样一致算法、K 近邻回归算法(K-neighbors)和线性回归算法(LR)训练以重采样GCM 数据和ERA5 格点化数据为自变量的数据集,训练集与验证集的数据比为3∶1。进一步利用投票回归算法(VR)将这3 个回归器打包为投票机制下的多模型加权融合机器学习模型,即集成学习模型,将这种集成学习算法的输出数据作为GCM 的降尺度数据。这种集成学习的机器学习方法可以显著提高GCM 数据的偏差修正效果,研究表明该方法可将大部分参数修正值相对于观测值的R2提升至0.85 以上[51]。
降尺度后的GCM 数据与ERA5 数据分辨率相同,均高于土壤和作物产量数据的分辨率。因此,在输入模型前使用KD-Tree 算法将土壤和作物产量因子重采样到GCM 数据分辨率上,从而保证输入模型的数据点一一对应。
1.5 模型训练
对MMME进行变量筛选后,利用选出的变量计算年平均值,并对4—5 月(贝尔格季作物的主要生长期)和7—9 月(梅赫季作物的主要生长期)的上述数据取平均值,以保证每种情景下各参数均具有年平均、贝尔格季平均和梅赫季平均作为气候自变量,与土壤变量共同组成自变量数据集。分别将10 个粮食作物产量数据集(5 种作物梅赫季产量和贝尔格季产量)作为因变量进行预处理,与自变量数据形成数据库,用于训练机器学习模型。
初步选取了3 类共6 种机器学习模型进行训练,分别为: 1)梯度提升算法(Boosting),包括直方图梯度提升回归(HGB)、极端梯度提升随机森林(XGBRF)算法以及轻梯度提升树(LGBM)算法;2)随机森林算法,包括随机森林(RF)以及极限树(ET)算法;3) K 近邻(K-neighbors)算法。
将上述6 种算法分别基于梅赫季苔麸产量数据进行训练后,使用统计指标评价模型表现。然后采用集成学习的思想,取表现较好的3 个算法进行打包训练。这里采用的集成学习方法是堆叠,即在3个算法的基础上再使用一个线性回归模型进行二次计算。
参与训练的数据被分为训练集(75%)和验证集(25%),其中训练集用于模型训练,验证集用于和模型结果比对以判定模型表现。使用模型判决系数(R2)、平均绝对误差(MAE)和解释方差评分(EVS)作为评价模型效果和判断模型可信度的依据。同时绘制每种模型在验证过程中对真实产量和模型预测产量的散点图,从而为模型精度的评价提供直观判断。由于数据量较大,为方便观察仅随机选取了验证集中的10 000 个数据点进行散点图的绘制。
在6 种机器学习模型的横向比较中,使用梅赫季苔麸产量数据对6 个模型进行训练和验证,选择表现较高的3 个模型进行堆叠训练,将训练完成后的最终模型分别应用于10 个因变量粮食数据集,进行针对10 个不同作物数据模型精度的验证和评价,方法与模型横向比较方法相同。
1.6 产量预测
使用训练完成的堆叠模型对自变量数据集进行预测,并输出预测结果。共输出30 个产量预测结果,即10 个作物数据在3 个未来情景下的不同产量结果。进一步计算每个未来情景下各作物类别的产量变化,并交叉引用同一作物在不同未来情景下的产量,分析2021—2050 年埃塞俄比亚主要粮食作物产量趋势以及气候变化对其的影响。
2 结果与分析
2.1 GCM 模型评价结果
37 个GCM 的pr 和tas 变量泰勒图如图2 所示,附表2 提供了37 个GCM 两个变量下的技能得分、表现评分以及综合评分(见文后电子版链接)。
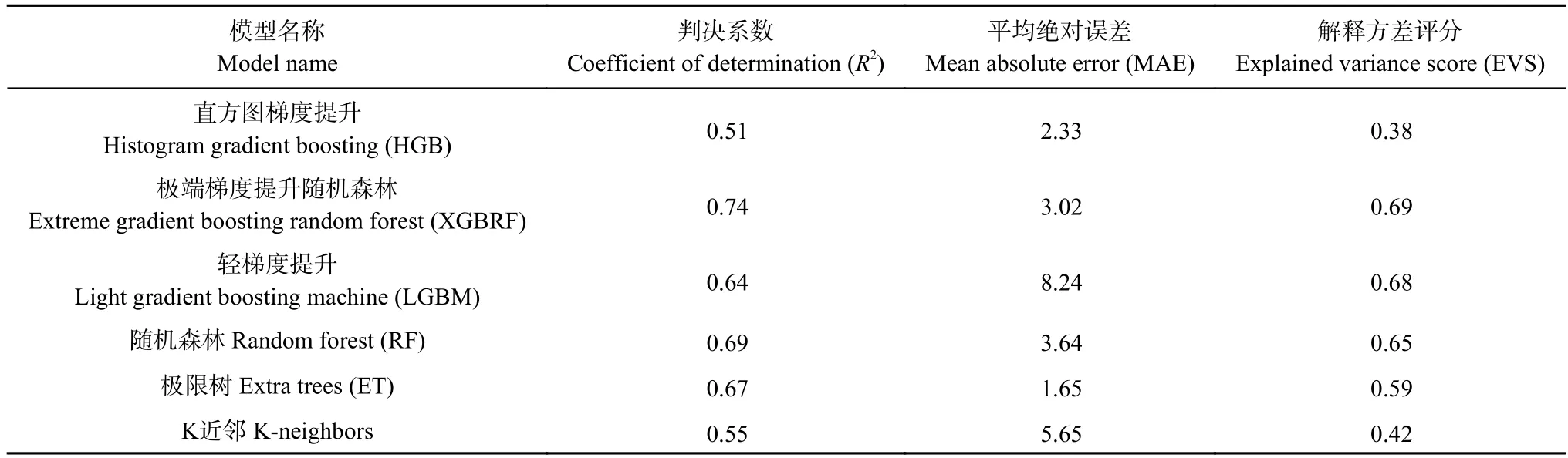
表2 6 种不同机器学习模型的模拟梅赫季苔麸产量的表现Table 2 Prediction performance of teff yield (Meher season) of 6 different machine learning models
从图2 可以看出在研究区范围内,GCM 之间的表现具有较大差距,这也符合区域尺度全球气候模式表现的一般情况。有研究显示CMCC-CM2-SR5、AWI-ESM-1-1-LR 两种模式在东非地区表现优良[52],这与本研究结论一致;EC-Earth系列、MPI-EMS 系列模型在非洲、东亚中亚等地都被证明具有较好的预测表现[53],在本研究区范围内也呈现出相同结果。FIO-ESM-2-0 模型在非洲以及中亚地区的模型比较研究中表现并不优秀,这与本研究结论相反,原因可能在于时间范围划定以及用于比对的数据库准确度等不同,ERA5 作为再分析数据与众多研究中使用的实际观测数据不同,出现离群值的概率较低,方差分布更平均,但会与观测值有所偏差。
同一GCM 在两个变量中的表现也不尽相同。如AWI-CM-1-1-MR、NorESM2-MM、MPI-ESM-1-2-HAM 等模型在两个参数下的排名相差甚至超过20,在综合加权评分机制的影响下,这种变量间表现差异较大的GCM 也不在研究考虑选取的范围内。
最终选择的最优模型集合包括以下5 个GCM:CMCC-CM2-SR5、MPI-ESM1-2-LR、EC-Earth3-Veg-LR、EC-Earth3-Veg 和MPI-ESM1-2-HR,其综合得分在37 个GCM 中分别排名2、3、4、8 和9,一些GCM 排名高于上述GCM 但并未入选,原因是在它们设定的实验情景、初始场以及时间分辨率下不包含全部的9 个变量,无法参加后续变量相关性分析和模型训练。
2.2 变量筛选结果
14 个变量和5 种梅赫季作物数据的斯皮尔曼相关性热图如图3 所示。在气候变量中,近地面压强与3 项气温指标之间呈现强正相关关系,这是由于大气压强与气温线性相关。在土壤变量中,各变量之间的相关性明显高于气候变量,高相关性出现在与容重以及土壤有机碳相交叉的行列中,例如容重与有机碳相关系数为-0.84,呈高度负相关;容重与总氮和pH 相关系数的绝对值均在0.7 以上,土壤有机碳与总氮和pH 相关系数的绝对值也均高于0.7,且呈高度负相关。
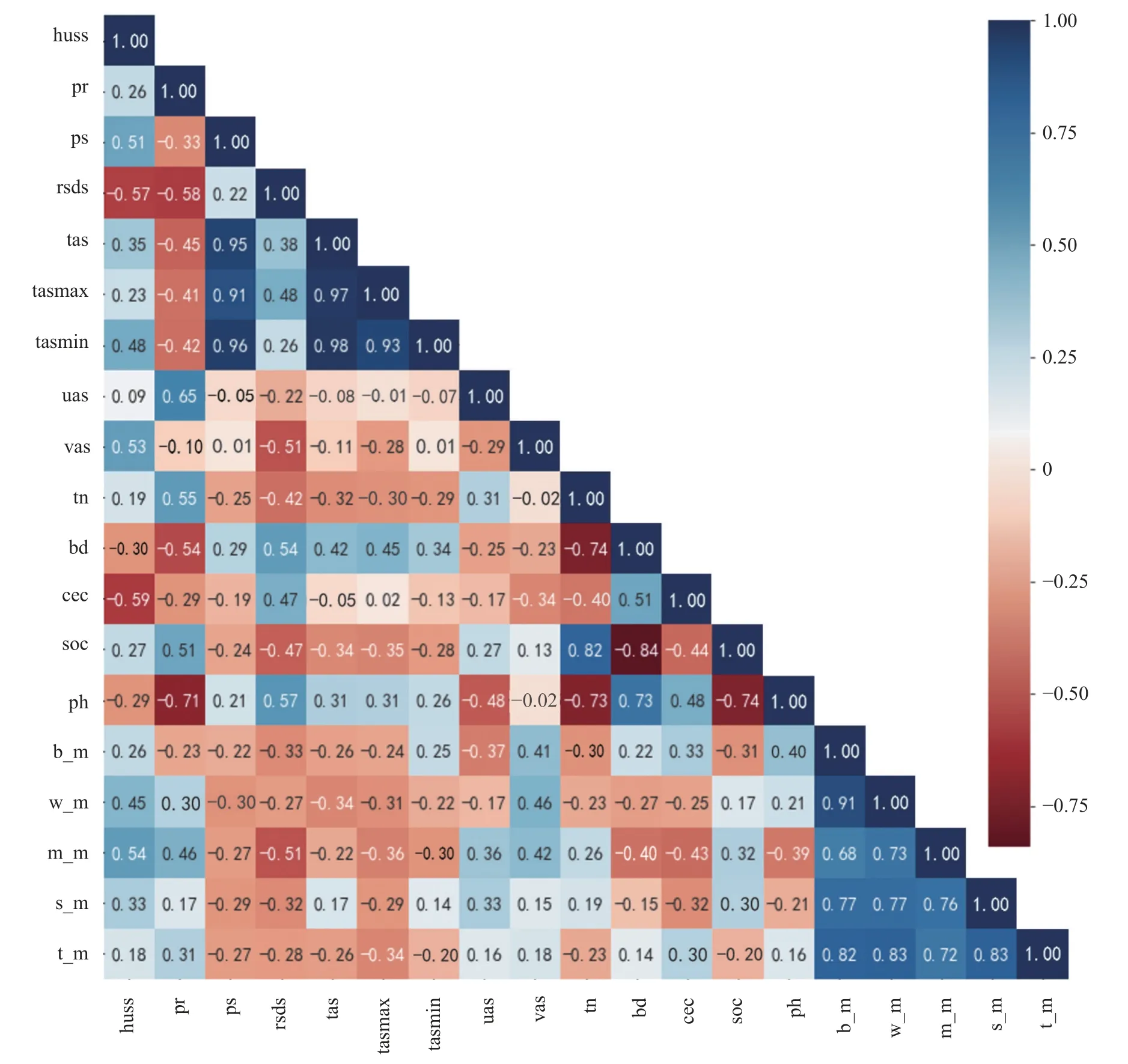
图3 14 个变量和5 种梅赫季作物产量的斯皮尔曼相关性热图Fig.3 Spearman correlation heat map with 14 variables and yield of 5 crops in Meher season
从不同变量组之间的关系来看,降水量与土壤pH 之间有较强的负相关性,原因是土壤中微生物分解以及根系呼吸作用会产生CO2等酸性物质,而降水会将参与中和酸性的盐离子通过淋溶作用带走,使得土壤pH 降低。作物对于以上全部变量的相关性反应较为稳定,相关系数范围在0.13~0.56 之间,未呈现出明显的趋势。这同样表明作物产量与上述各因子间具有复杂的内在联系,但目前理论无法充分解释这种关系。
通过变量之间的相关性分析,决定剔除气候变量中的近地面气压、近地面平均日最高与最低气温、土壤变量中的容重和土壤有机碳含量。
2.3 机器学习模型评价
2.3.1 不同机器学习模型的比较结果
对6 种不同的机器学习模型针对同一作物的模拟结果进行评价,粮食产量数据选择梅赫季的苔麸产量。评价指标的结果如表2 所示。
从结果中可以看出综合表现较好的模型为极端梯度提升随机森林、随机森林以及极限树模型。在6 个模型中表现较差的是直方图梯度提升和K 近邻,其中K 近邻是应用最为广泛且最简单的机器学习模型之一,其计算路径较短,善于求解线性问题,但在面对复杂问题时解释性不足;直方图梯度提升作为梯度提升决策树模型,虽然其R2和EVS 表现最差,但却有较低的MAE,说明该模型虽然尽量逼近了因变量变化范围,但是对因变量变化趋势的把握较差,其预测结果几乎不能解释因变量方差变化规律。
整体来看,在粮食产量长期预测方面,较为复杂、运算量大的机器学习模型的模拟能力占优势。本研究最终选择参与堆叠的模型是极端梯度提升随机森林、随机森林以及极限树模型。
2.3.2 不同作物模型的比较结果
将上述3 种模型使用线性回归模型进行堆叠,针对10 种作物产量数据分别进行训练,最终得出10 个作物产量模型,对它们的模拟能力分别进行评价,评价指标结果如表3 所示。
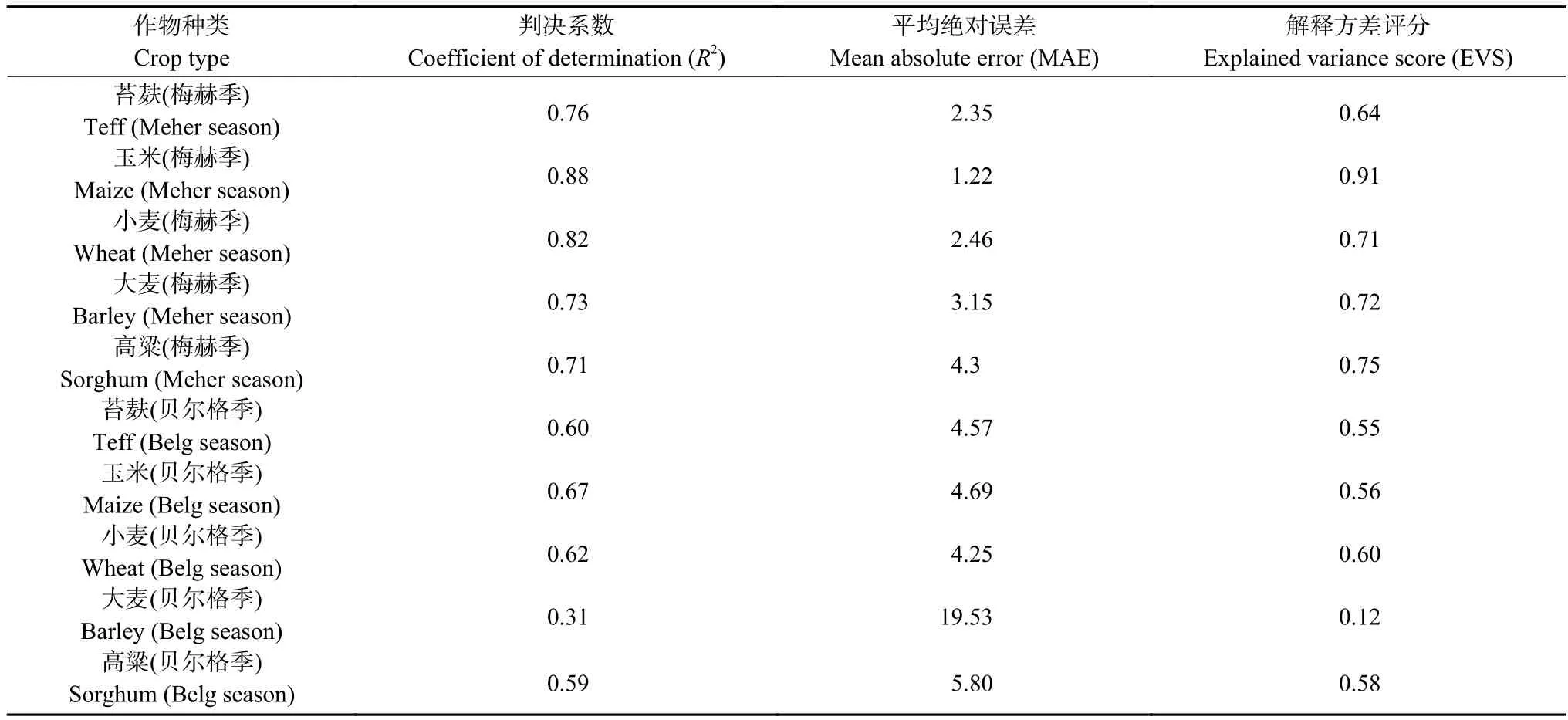
表3 最终模型对不同作物产量的模拟表现Table 3 Prediction performance of the stacked model for yields of different crops
整体来看,机器学习模型的预测结果较为准确,除贝尔格季大麦模型外,所有模型的R2均在可信范围内,且与实际值的误差都控制在了1 t·hm-2以内。其中梅赫季的小麦和玉米产量表现较为突出,R2在0.8 以上。此外,堆叠后模型的表现明显优于单一模型,说明集成学习的方法将不同模型的优点进行了整合,显著提升了模型表现。对于不同种类作物,梅赫季作物模型表现要明显优于贝尔格季作物模型表现,这是由于贝尔格季因变量作物产量数据质量较差,缺失数据较多,经预处理后参与训练的数据量仅为梅赫季的60%左右。
贝尔格季大麦模型表现较差,其R2、EVS 均低于0.4~1.0 的可信范围,同时MAE 高达20,甚至超出2020 年产量的两倍。因此,在后续分析中不再考虑贝尔格季大麦模型。
2.4 粮食产量预测结果及分析
2.4.1 埃塞俄比亚1995—2020 年粮食产量情况
本研究分析了埃塞俄比亚地区1995—2020 年粮食产量变化情况(图4),结果表明,研究区中部地区种植的作物品种最为全面,但单一作物产量低于周边地区。这是由于中部地区气候条件较好,气候带适宜种植,降水条件优渥,鲜有干旱发生,因此多数作物都可以在此地种植。但是由于中部地区地势较高,多见山地丘陵地形,使适宜种植作物的区域变得碎片化,因此限制了粮食总产量的增加。研究区外围地区具有各自的作物种植特色,其中苔麸多种植于西北部地区,玉米多种植于东南及东北部地区,大麦及小麦在除了极东部和极西部地区均有种植,高粱种植则较为分散。
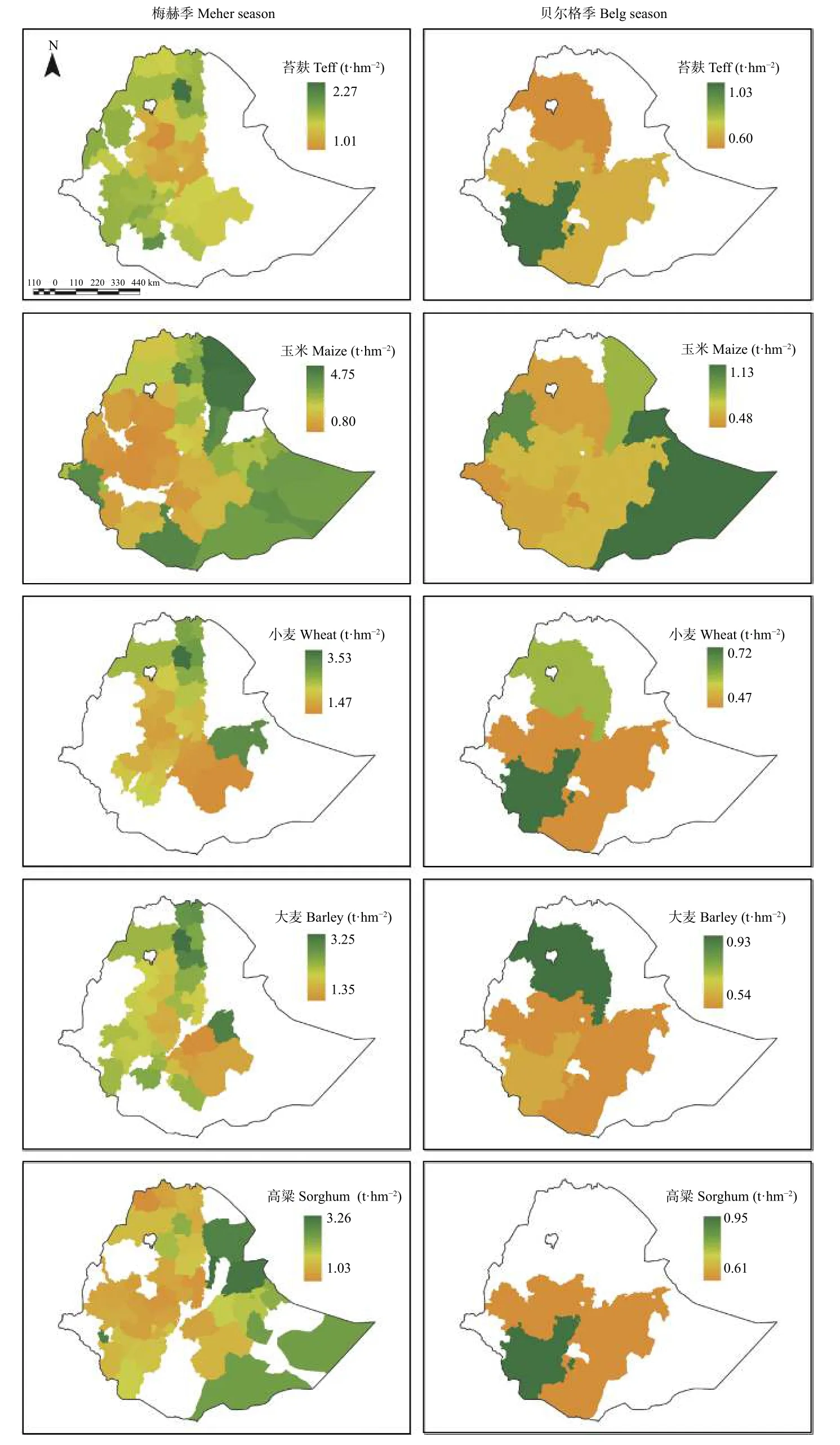
图4 2020 年埃塞俄比亚5 种主要粮食作物产量(统计数据)Fig.4 Yields of 5 main staple crops in 2020 in Ethiopia (statistical data)
玉米是埃塞俄比亚种植最为广泛的作物,也是全国总产量最高的粮食作物,这是由于玉米相较于其他粮食作物较为耐旱,在非洲充足的光热条件下,玉米生长和种植也相较于其他作物更为容易。反观小麦,虽然保证了充足的光热,但干旱导致的水分不足严重影响了小麦的生长发育,因此,小麦在埃塞俄比亚主要粮食作物中总产量最低。这种情况也出现在其他的东非国家,它们都重度依赖小麦进口。
1995—2020 年埃塞俄比亚粮食产量变化如图5所示,整体来看梅赫季粮食产量整体呈缓慢上升的趋势,部分地区有所下降;贝尔格季苔麸、玉米、小麦、大麦平均增长约0.6 t·hm-2,高粱则有所下降。所有作物在梅赫季产量增减最为不均,中西部地区增长近3 t·hm-2,而在北方和南方则出现了近2 t·hm-2左右的下降,这可能是由于自20 世纪80 年代起东非地区流行的干旱所致,在干旱较为严重且降水不足的北方和南方,其直接展现出对作物生长的抑制[54]。在中西部地区,气候条件变暖以及高种植密度带来的耕作技术提升缓和了这种状况。

图5 1995—2020 年间埃塞俄比亚5 种主要粮食作物产量变化(统计数据)Fig.5 Changes of yield of 5 main staple crops in Ethiopia from 1995 to 2020 (statistical data)
2.4.2 埃塞俄比亚2021—2050 年作物产量预测
从梅赫季产量变化(图6)可以看出,苔麸产量增减在0.6 t·hm-2之内,增长主要发生在中西部,大幅减产出现在东南沙漠地区。玉米的强烈波动主要出现在东南沙漠地区,其大部分区域都出现了2 t·hm-2以内的产量增长。在绝大多数地区小麦产量波动幅度都在2 t·hm-2以内,但SSP126 情景下东南地区产量下降而另外两种情景下却在上升。大麦的产量变化情况在空间上类似于苔麸,但其产量变化集中在1.5 t·hm-2以内,剧烈变化出现在中部地区。对于高粱来说,SSP126 和SSP585 情景下的变化情况相似,以东南部1.5 t·hm-2左右的增产为主,SSP245 情景下的产量变化则较为平均。
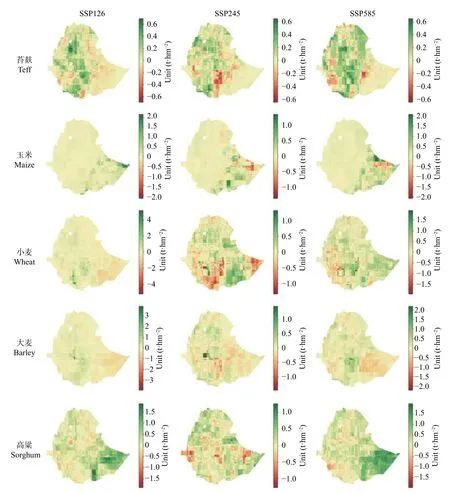
图6 2021—2050 年SSP126、SSP245、SSP585 情景下梅赫季5 种主要粮食作物产量变化量Fig.6 Yield changes of 5 main staple crops under SSP126,SSP245 and SSP585 scenarios in Meher season from 2021 to 2050
总的来看,未来30 年梅赫季5 种主要粮食作物产量增幅以<2 t·hm-2为主(图6),不同作物产量变化的空间特征呈现出一定的互补性,例如东南地区苔麸和大麦产量的下降与小麦和高粱产量的上升。
贝尔格季产量变化可以看出(图7),苔麸产量变化与梅赫季极为相似,但是其变化量为梅赫季的1/2左右,这与贝尔格季本身产量较低有关。对于玉米来 说,SSP245 和SSP585情景出现了全国范围 内1 t·hm-2左右的增产,唯有阿法尔地区出现大幅减产,但在SSP126 情景下中南部地区将出现0.5~0.8 t·hm-2左右的减产。小麦增产集中在中部地区,但中东部和南部地区在SSP126 情景下出现了0.4 t·hm-2左右的减产。SSP126 情景下的减产情况同样延续到了高粱的产量: 全国大规模出现>1 t·hm-2的减产,中部地区的1 t·hm-2的增产发生在其他两个情景中。
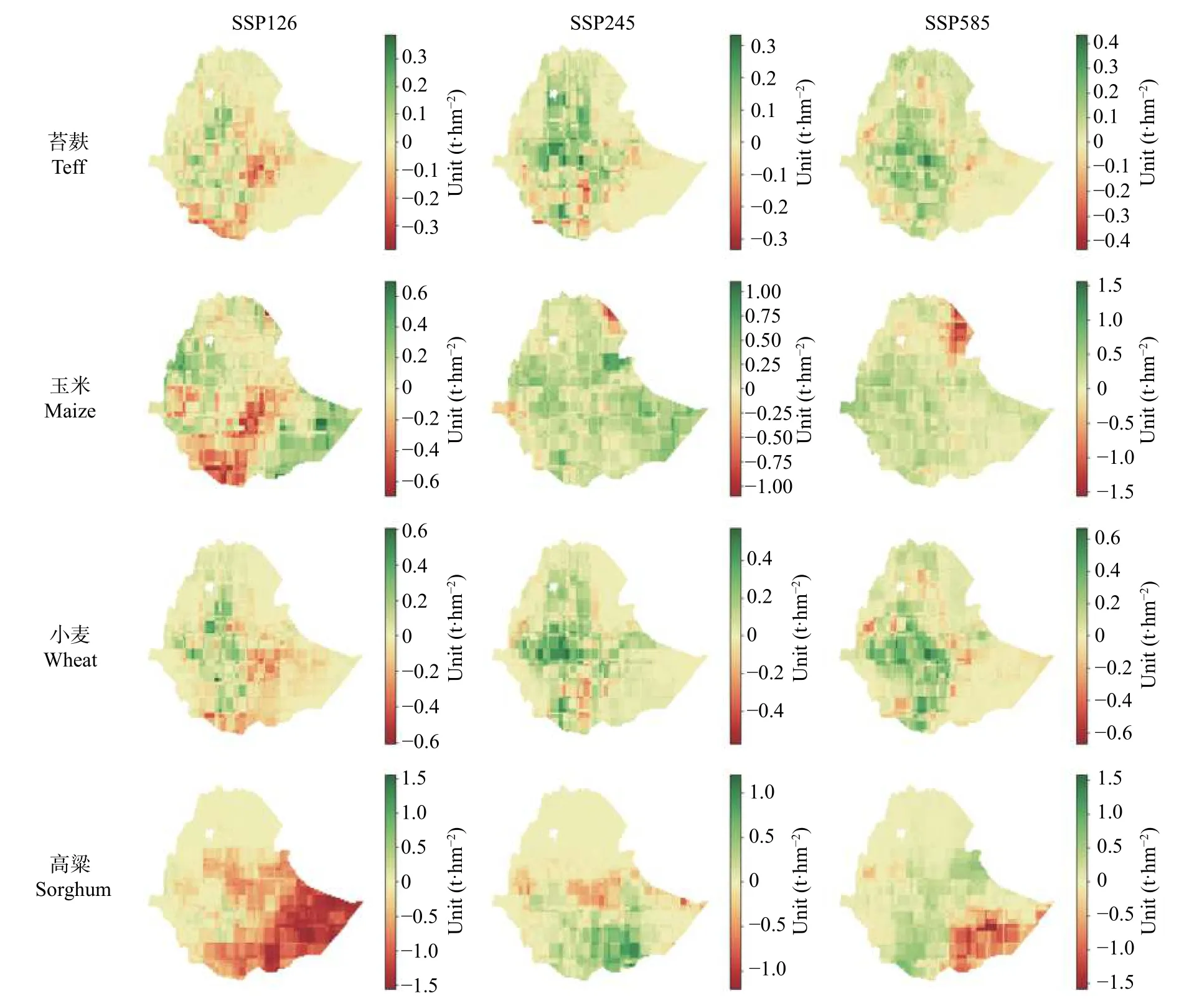
图7 2021—2050 年SSP126、SSP245、SSP585 情景下贝尔格季4 种主要粮食作物产量变化量Fig.7 Yield changes of 4 main staple crops under SSP126,SSP245 and SSP585 scenarios in Belg season from 2021 to 2050
贝尔格季粮食变化情况反映出SSP126 情景与其他两种情景下的较大差异,即明显减产的趋势。这与部分前人研究结果类似[2,55],一般是由于环境条件改变使作物脱离原有适宜生长范围。贝尔格季主要播种时间为夏季,干旱区夏季种植习惯和作物生长规律与SSP126 情景提供的良好生态条件不符,可能会导致部分作物减产。SSP245 情景下作物在中部及南部地区的产量将普遍增加,这符合过去26 年作物产量发展趋势,进一步验证了SSP245 情景与现今社会发展情况的一致性。
进一步分析往年贝尔格季结果可以发现主要粮食作物种植主要集中在中部和南部地区,只有小麦种植范围向东南方向延伸,而在实际情况中,相对于梅赫季存在大量零散种植的情况,贝尔格季粮食种植基本局限于中部和南部地区。虽然模型给出了贝尔格季其他区域的预测产量,但与实际情况不符,其参考性较差。因此,具有较高参考性的变化趋势应该主要在中部和南部地区,这些地区的产量将随着未来情景从SSP585 到SSP126 的转变而减少。
3 讨论
总体来看,2050 年SSP245 情景下作物产量普遍低于SSP126 情景,而SSP585 情景作物产量相较于SSP245 情景则更高。这在梅赫季作物产量变化中较为明显,即SSP126 情景下作物增产占主导,而在另外两种情景下作物减产规模有所升高。这说明在3个情景中,SSP245 情景可能是粮食产量增长最为缓慢的情景。这种现象意味着SSP245 情景对于粮食作物生产来说,表现出情景变化间的拐点特征。本研究认为,这种情景间产量先减后增的过程是由情景所代表的气候原因造成的。对于地处干旱区的埃塞俄比亚来说,SSP245 和SSP126 情景下生态环境的改善(即干旱的缓解)意味着各种作物的生存环境都将得到改善,从而带来增产的结果。SSP585 情景中人为活动带来的温室气体排放将加快全球变暖的进程,大量研究表明一定程度下的全球变暖可以为作物生长提供更充足的光合作用原料,这在一定程度上会带来作物的增产,这也是SSP245 情景粮食产量相较于另外两种情景增长更慢的原因。
有研究曾提出SSP585 情景下的农业发展会受到社会发展压力的影响,未来社会形势从优质和谐社会向复杂矛盾社会转变时,作物产量增减趋势将会变得更加突出[56],这与本研究结果相同。这是由于在社会复杂化的过程中,社会对粮食供给结构的优化程度需求更大,这不仅仅意味着人们对粮食需求量的增加,同时代表着人们希望粮食生产结构更加合理化,在最优的田间管理条件下,尽可能地利用自然条件的便利最大化生产,以对冲日益加深的社会矛盾。出于上述原因,在SSP585 情景下,多数作物呈现出的变化趋势与SSP245 情景大致相同,但幅度更大,即在相同地区更剧烈地增产或减产;而相比之下,SSP126 情景中粮食生产结构性改革和社会生产能力的再分配似乎不那么紧迫,这使得极端值在相应图像中出现的频率更低。
4 结论
本文利用机器学习算法将埃塞俄比亚粮食产量统计数据与CMIP6 未来气候模式数据相结合,训练模型并预测了2021—2050 年不同未来社会情景下埃塞俄比亚两个主要生产季的5 种粮食作物产量,得出以下结论:
1)本研究选取的37 个GCM 中,CMCC-CM2-SR5、MPI-ESM1-2-LR、EC-Earth3-Veg-LR、ECEarth3-Veg、MPI-ESM1-2-HR 在埃塞俄比亚地区的模拟效果较好,且数据完整。采用泰勒图和技能得分结合排序评分和加权平均算法可以方便快捷地评价GCM 的表现,综合多个优秀模型可以进一步减少误差。
2)在使用气候变量和土壤变量预测粮食产量的机器学习模型训练过程中,极端梯度提升随机森林、随机森林、极限树3 种模型的表现要优于直方图梯度提升、轻梯度提升以及K 近邻。
3)未来30 年间,梅赫季5 种主要粮食作物产量变化以<2 t·hm-2为主,不同作物空间变化存在一定程度互补;在SSP126 情景下贝尔格季出现减产较多,其他两种情景则以增产为主,这可能与SSP126 情景下的生态环境改善与生产季种植习惯的不匹配有关。
4)从SSP126 情景到SSP585 情景,随着社会矛盾加剧和人为环境恶化,粮食作物生产结构改革和生产资源再分配的需求增加,导致各种作物的生产力向新出现的适宜地区转移。研究区在SSP126 和SSP585 情景下分别会因为免于干旱和温室效应加剧获得更高的粮食作物生产力。
