Recent Advances on Deep Learning for Sign Language Recognition
2024-03-23YanqiongZhangandXianweiJiang
Yanqiong Zhang and Xianwei Jiang
School of Mathematics and Information Science,Nanjing Normal University of Special Education,Nanjing,210038,China
ABSTRACT Sign language,a visual-gestural language used by the deaf and hard-of-hearing community,plays a crucial role in facilitating communication and promoting inclusivity.Sign language recognition (SLR),the process of automatically recognizing and interpreting sign language gestures,has gained significant attention in recent years due to its potential to bridge the communication gap between the hearing impaired and the hearing world.The emergence and continuous development of deep learning techniques have provided inspiration and momentum for advancing SLR.This paper presents a comprehensive and up-to-date analysis of the advancements,challenges,and opportunities in deep learning-based sign language recognition,focusing on the past five years of research.We explore various aspects of SLR,including sign data acquisition technologies,sign language datasets,evaluation methods,and different types of neural networks.Convolutional Neural Networks(CNN)and Recurrent Neural Networks (RNN) have shown promising results in fingerspelling and isolated sign recognition.However,the continuous nature of sign language poses challenges,leading to the exploration of advanced neural network models such as the Transformer model for continuous sign language recognition (CSLR).Despite significant advancements,several challenges remain in the field of SLR.These challenges include expanding sign language datasets,achieving user independence in recognition systems,exploring different input modalities,effectively fusing features,modeling co-articulation,and improving semantic and syntactic understanding.Additionally,developing lightweight network architectures for mobile applications is crucial for practical implementation.By addressing these challenges,we can further advance the field of deep learning for sign language recognition and improve communication for the hearing-impaired community.
KEYWORDS Sign language recognition;deep learning;artificial intelligence;computer vision;gesture recognition
1 Introduction
Effective communication is essential for individuals to express their thoughts,feelings,and needs.However,for individuals with hearing impairments,spoken language may not be accessible.In such cases,sign language serves as a vital mode of communication.Sign language is a visual-gestural language that utilizes hand movements,facial expressions,and body postures to convey meaning.This unique language has a rich history and has evolved to become a distinct and complex system of communication.Sign languages differ across regions and countries,with each having its own grammar and vocabulary.
Stokoe W.C.made a significant contribution to the understanding of sign language by recognizing its structural similarities to spoken languages.Like spoken languages,sign language has a phonological system.Signs can be broken down into smaller linguistic units[1].As shown in Fig.1,sign language can be categorized into manual and non-manual features.Manual features can be further divided into handshape,orientation,position,and movement.Non-manual features include head and body postures,and facial expressions.These features work together to convey meaning and enable effective communication in sign language.
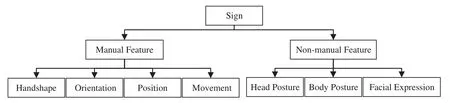
Figure 1:Structural features of sign language
According to the World Health Organization,there are over 466 million people globally with disabling hearing loss,and this number is expected to increase in the coming years.For individuals who are deaf or hard of hearing,sign language is often their primary mode of communication.However,the majority of the population does not understand sign language,leading to significant communication barriers and exclusion for the deaf community.Sign language recognition(SLR)refers to the process of automatically interpreting and understanding sign language gestures and movements through various technological means,such as computer vision and machine learning algorithms.By enabling machines to understand and interpret sign language,we can bridge the communication gap between the deaf community and the hearing world.SLR technology has the potential to revolutionize various sectors,including education,healthcare,and communication,by empowering deaf individuals to effectively communicate and access information,services,and opportunities that were previously limited[2,3].In addition,SLR technology can be expanded to other areas related to gesture commands,such as traffic sign recognition,military gesture recognition,and smart appliance control[4–8].
Research on SLR dates back to the 1990s.Based on the nature of the signs,these techniques were categorized into fingerspelling recognition,isolated sign language recognition,and continuous sign language recognition,as depicted in Fig.2.
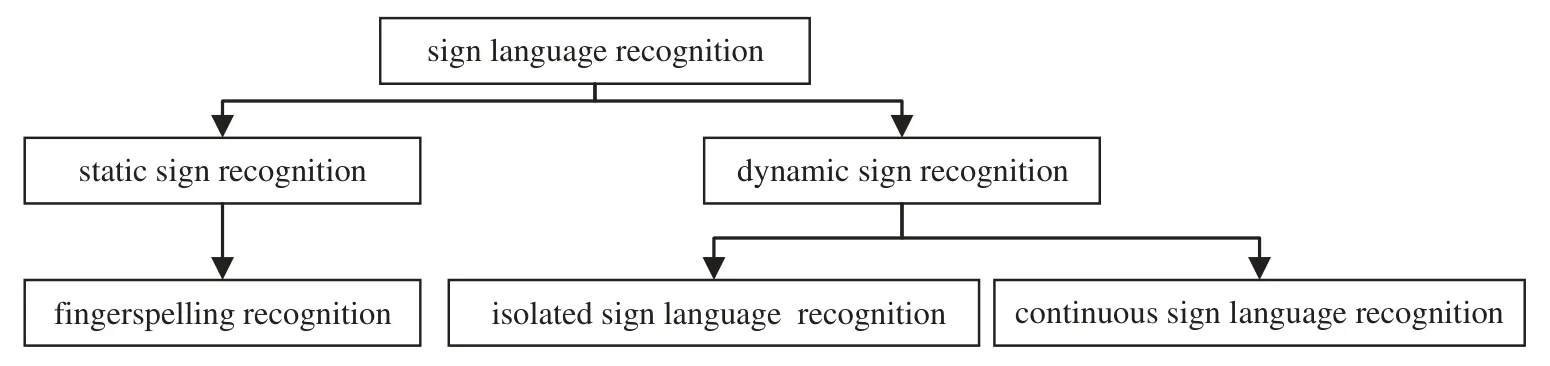
Figure 2:Sign language recognition classification
Static signs,such as alphabet and digit signs,primarily belong to the category of fingerspelling recognition.This type of recognition involves analyzing and interpreting the specific hand shapes and positions associated with each sign.Although it is important to acknowledge that certain static signs may involve slight movements or variations in hand shape,they are generally regarded as static because their main emphasis lies in the configuration and positioning of the hands rather than continuous motion.
On the other hand,dynamic signs can be further classified into isolated sign recognition and continuous sign recognition systems.Isolated sign gesture recognition aims to recognize individual signs or gestures performed in isolation.It involves identifying and classifying the hand movements,facial expressions,and other relevant cues associated with each sign.In contrast,continuous sign recognition systems aim to recognize complete sentences or phrases in sign language.They go beyond recognizing individual signs and focus on understanding the context,grammar,and temporal sequence of the signs.This type of recognition is crucial for facilitating natural and fluid communication in sign language.
In the field of sign language recognition,traditional machine learning methods have played significant roles.These methods have been utilized for feature extraction,classification,and modeling of sign language.However,traditional machine learning approaches often face certain limitations and have reached a bottleneck.These limitations include the need for manual feature engineering,which can be time-consuming and may not capture all the relevant information in the data.Additionally,these methods may struggle with handling complex and high-dimensional data,such as the spatiotemporal information present in sign language gestures.Over recent years,deep learning methods outperformed previous state-of-the-art machine learning techniques in different areas,especially in computer vision and natural language processing[9].Deep learning techniques have brought significant advancements to sign language recognition[10–14],leading to a surge in research papers published on deep learningbased SLR.As the field continues to evolve,it is crucial to conduct updated literature surveys.Therefore,this paper aims to provide a comprehensive review and classification of the current state of research in deep learning-based SLR.
This review delves into various aspects and technologies related to SLR using deep learning,covering the latest advancements in the field.It also discusses publicly available datasets commonly used in related research.Additionally,the paper addresses the challenges encountered in SLR and identifies potential research directions.The remaining sections of the paper are organized as follows:Section 2 describes the collection and quantitative analysis of literature related to SLR.Section 3 describes different techniques for acquiring sign language data.Section 4 discusses sign language datasets and evaluation methods.Section 5 explores deep learning techniques relevant to SLR.In Section 6,advancements and challenges of various techniques employed in SLR are compared and discussed.Finally,Section 7 summarizes the development directions in this field.
2 Literature Collection and Quantitative Analysis
In this study,we conducted a systematic review following the Preferred Reporting Items for Systematic Review and Meta-Analysis (PRISMA).We primarily rely on the Web of Science Core Collection as our main source of literature.This database encompasses a wide range of high-quality journals and international conferences.Additionally,we have also supplemented our research by searching for relevant literature on sign language datasets and the application of SLR in embedded systems in other databases.To ensure the relevance of our research,we applied specific selection criteria,focusing on peer-reviewed articles and proceeding papers published between 2018 and 2023 (Search date:2023-06-12).Our review targeted sign language recognition in deep learning and also included papers related to sign language translation,considering its two-step process involving continuous sign language recognition (CSLR) and gloss-to-text translation.After eliminating irrelevant papers,our study encompassed 346 relevant papers.The PRISMA chart depicting our selection process is presented in Fig.3.

Figure 3:The PRISMA flow diagram for identifying relevant documents included in this review
A comprehensive literature analysis was performed on various aspects of SLR using deep learning,including annual publication volume,publishers,sign language subjects,main technologies,and architectures.Fig.4 demonstrates a consistent increase in the number of publications each year,indicating the growing interest and continuous development in this field.Fig.5 highlights the prominent publishers in the domain of deep learning-based SLR.Notably,IEEE leads with the highest number of publications,accounting for 37.57% of the total,followed by Springer Nature with 19.36% and Mdpi with 10.41%.Table 1 displays the primary sign language subjects for research,encompassing American SL,Indian SL,Chinese SL,German SL,and Arabic SL.It is important to note that this data is derived from the experimental databases utilized in the papers.In cases where a paper conducted experiments using multiple databases,each database is counted individually.For instance,experiments were conducted on two test datasets: the RWTH-PHOENIX-Weather multi-signer dataset and a Chinese SL(CSL)dataset[15].Therefore,German SL and Chinese SL are each counted once.Table 2 presents the main technologies and architectures employed in deep learning-based SLR.In Session 5,we will focus on elucidating key technological principles to facilitate comprehension for readers new to this field.The statistical data in Table 2 is obtained by first preprocessing and normalizing the keywords in the literature,and then using VOSviewer software to analyze and calculate the keywords.

Table 1:The main sign language subjects on sign language recognition in deep learning(No.>=5)

Table 2:The main technologies or architectures of sign language recognition in deep learning (No.>=5)
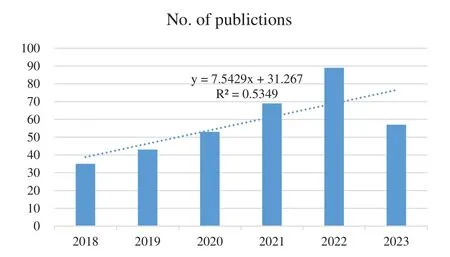
Figure 4:Number of publications on sign language recognition by year

Figure 5:Number of publications on sign language recognition by publisher
3 Sign Data Acquisition Technologies
The techniques used to acquire sign language can be categorized into sensor-based,vision-based,or a combination of both.Sensor-based techniques rely on a variety of sensors to capture and record the gesture information of signers,while vision-based techniques utilize video cameras to capture the gestures performed by signers.
3.1 Sensor-Based Acquisition Technologies
With the development of electronic science and technology,sensors have garnered significant attention and found applications in various fields.In the context of sign language,sensors play a crucial role in measuring and recording data related to hand movements,including bending,shape,rotation,and position during the signing process.Several approaches exist for acquiring sign language data using sensors,such as strain sensors,surface electromyography (sEMG) sensors,tactile or pressure sensors,as well as inertial sensors like accelerometers,magnetometers,and gyroscopes.Technological progress has led to the development of compact and affordable sensors,microcontrollers,circuit boards,and batteries.These portable systems have the capacity to store large amounts of sensor data.However,a drawback of sensor-based approaches is the potential discomfort or restriction of movement caused by the sensor configuration.To address this issue,sensors can be integrated into wearable devices such as digital gloves,wristbands,or rings[16].
Digital gloves are one of the most common sensor-based devices for acquiring sign language data.Fig.6 illustrates examples of these glove sensors.The sensors attached to digital gloves for sign language data acquisition can be categorized into those measuring finger bending and those measuring hand movement and orientation [17].Lu et al.[18] developed the Sign-Glove,which consisted of a bending sensor and an inertial measurement unit (IMU).The IMU captured the motion features of the hand,as shown in Fig.7b,while the bending sensor collected the bending (shape) features of the hand,as shown in Fig.7c.Alzubaidi et al.[19] proposed a novel assistive glove that converts Arabic sign language into speech.This glove utilizes an MPU6050 accelerometer/gyro with 6 degrees of freedom to continuously monitor hand orientation and movement.DelPreto et al.[20] presented the smart multi-modal glove system,which integrated an accelerometer to capture both hand pose and gesture information based on a commercially available glove.Oz et al.[21]used Cyberglove and a Flock of Bird 3-D motion tracker to extract the gesture features.The Cyberglove is equipped with 18 sensors to measure the bending angles of fingers,while the Flock of Bird 3-D motion tracker tracks the position and orientation of the hand.Dias et al.[22] proposed an instrumented glove with five flex sensors,an inertial sensor,and two contact sensors for recognizing the Brazilian sign language alphabet.Wen et al.[23]utilized gloves configured with 15 triboelectric sensors to track and record hand motions such as finger bending,wrist motions,touch with fingertips,and interaction with the palm.

Figure 6:Examples of these glove sensors
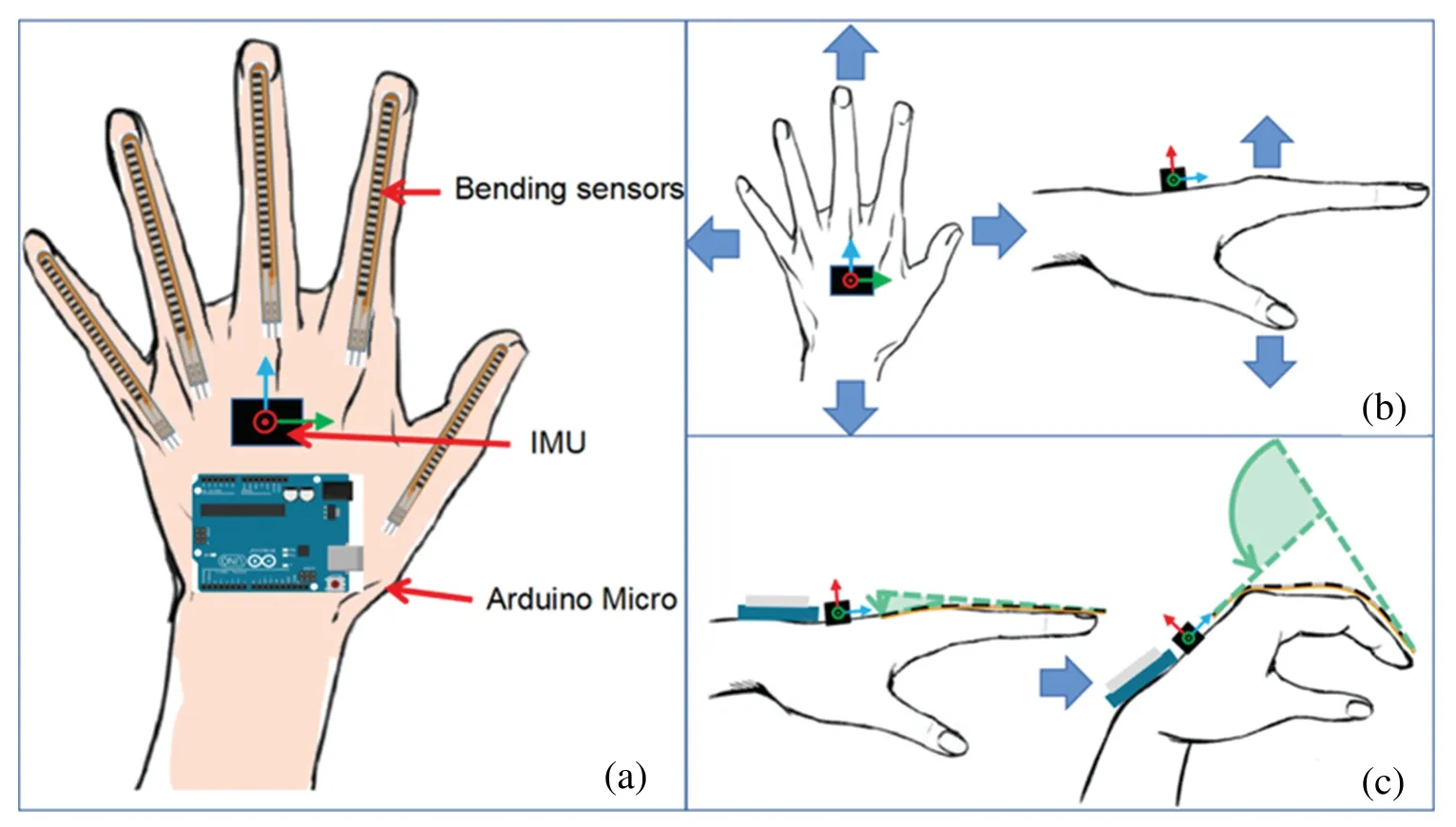
Figure 7:(a)System structure.(b)IMU collecting the hand motion data.(c)Bending sensor collecting the hand shape data
Leap Motion Controller (LMC) is a small,motion-sensing device that allows users to interact with their computer using hand and finger gestures.It uses infrared sensors and cameras to track the movement of hands and fingers in 3D space with high precision and accuracy.In the field of sign language recognition,by tracking the position,orientation,and movement of hands and fingers,the Leap Motion Controller can provide real-time data that can be used to recognize and interpret sign language gestures[24–26].
Some studies have utilized commercially available devices such as the Myo armband [27–29],which are worn below the elbow and equipped with sEMG and inertial sensors.The sEMG sensors can measure the electrical potentials produced by muscles.By placing these sensors on the forearm over key muscle groups,specific hand and finger movements can be identified and recognized[30–32].Li et al.[27]used A wearable Myo armband to collect human arm surface electromyography(sEMG)signals for improving SLR accuracy.Pacifici et al.[28] built a comprehensive dataset that includes EMG and IMU data captured with the Myo Gesture Control Armband.This data was collected while performing the complete set of 26 gestures representing the alphabet of the Italian Sign Language.Mendes Junior et al.[29]demonstrated the classification of a series of alphabet gestures in Brazilian Sign Language(Libras)through the utilization of sEMG obtained from a MyoTMarmband.
Recent literature studies have highlighted the potential of utilizing WiFi sensors to accurately identify hand and finger gestures through channel state information [33–36].The advantage of WiFi signals is their nonintrusive nature,allowing for detachment from the user’s hand or finger and enabling seamless recognition.Zhang et al.[33] introduced a WiFi-based SLR system called Wi-Phrase,which applies principal component analysis (PCA) projection to eliminate noise and transform cleaned WiFi signals into a spectrogram.Zhang et al.[35] proposed WiSign,which recognizes continuous sentences of American Sign Language(ASL)using existing WiFi infrastructure.Additionally,RF sensors provide a pathway for SLR[37–41].
Sensor-based devices offer the benefit of minimizing reliance on computer vision techniques for signer body detection and segmentation.This allows the recognition system to identify sign gestures with minimal processing power.Moreover,these devices can track the signer’s movements,providing valuable spatial and temporal information about the executed signs.However,it is worth noting that certain devices,such as digital gloves,require the signer to wear the sensor device while signing,limiting their applicability in real-time scenarios.
3.2 Vision-Based Acquisition Technologies
In vision-based sign acquisition,video cameras and other imaging devices are used to capture sign gestures and store them as sequences of images for further processing.Typically,three types of outputs are generated:color images,depth images,and skeleton images.Color images are obtained by using standard RGB cameras to capture the visible light spectrum.They provide detailed information about the appearance and color of the signer’s gestures.However,they can be sensitive to lighting conditions and prone to noise from shadows or reflections,which may affect accuracy.Depth images are generated through depth-sensing technologies like Time-of-Flight(ToF)or structured light.These images provide 3D spatial information,offering a better understanding of the signer’s 3D structure and spatial relationships.Skeleton images,on the other hand,are produced by extracting joint positions and movements from depth images or similar depth-based techniques.Like depth images,skeleton images also provide 3D spatial information,enabling a deeper understanding of the signer’s body movements and posture.The combination of color,depth,and skeleton images in vision-based acquisition allows for a comprehensive analysis of sign gestures,providing valuable information about appearance,spatial structure,and movements.
Microsoft Kinect is a 3D motion-sensing device commonly used in gaming.It consists of an RGB camera,an infrared emitter,and an infrared depth sensor,which enables it to track the movements of users.In the field of sign language recognition,the Kinect has been widely utilized [42–45].Raghuveera et al.[46]captured hand gestures through Microsoft Kinect.Gangrade et al.[47,48]have leveraged the 3D depth information obtained from hand motions,which is generated by Microsoft’s Kinect sensor.
Multi-camera and 3D systems can mitigate certain environmental limitations but introduce a higher computational burden,which can be effectively addressed due to the rapid progress in computing technologies.Kraljević et al.[49] proposed a high-performance sign recognition module that utilizes the 3DCNN network.They employ the StereoLabs ZED M stereo camera to capture real-time RGB and depth information of signs.
In SLR systems,vision-based techniques are more suitable compared to sensor-based approaches.These techniques utilize video cameras instead of sensors,eliminating the need for attaching sensors to the signer’s body and overcoming the limited operating range of sensor-based devices.Visionbased devices,however,provide raw video streams that often require preprocessing for convenient feature extraction,such as signer detection,background removal,and motion tracking.Furthermore,computer vision systems must address the significant variability and sources of errors inherent in their operation.These challenges include noise and environmental factors resulting from variations in illumination,viewpoint,orientation,scale,and occlusion.
4 Sign Language Datasets and Evaluation Methods
Sign Language Datasets and Evaluation Methods are essential components in the development and advancement of SLR systems.They provide researchers with the necessary resources and tools to train,evaluate,and improve deep learning models for accurate and reliable SLR.
4.1 Sign Language Datasets
A sign language dataset is crucial for training and evaluating SLR systems.Factors for a good dataset include diversity of gestures,sufficient sample size,variations in conditions,inclusion of different users,and accurate annotations.Table 3 provides an overview of the most commonly used sign language databases,categorized by sign level (fingerspelling,isolated,and continuous).These databases are specifically designed for research purposes.
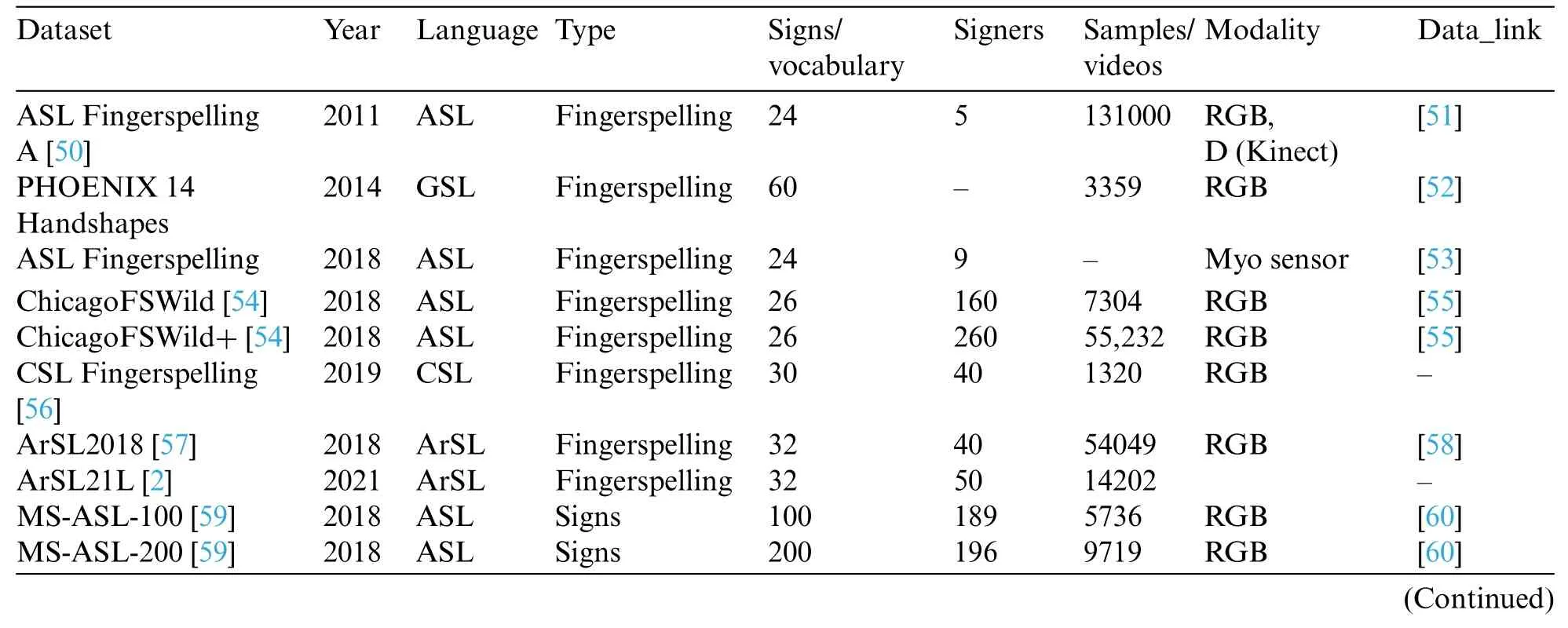
Table 3:The most common databases used for SLR
Fingerspelling datasets primarily focus on sign language alphabets and/or digits.Some exclude letters that involve motion,such as‘j’and‘z’in American Sign Language[50].The impact of signer variability on recognition systems is minimal in fingerspelling databases since most images only display the signer’s hands.These datasets mainly consist of static images as the captured signs do not involve motion[61,64,65].
Isolated sign datasets are the most widely used type of sign language datasets.They encompass isolated sign words performed by one or more signers.Unlike fingerspelling databases,these databases contain motion-based signs that require more training for non-expert signers.Vision-based techniques,such as video cameras,are commonly used to capture these signs[66,72,82].However,there are other devices,like the Kinect,which output multiple data streams for collecting sign words[71,69].
Continuous sign language databases comprise a collection of sign language sentences,where each sentence consists of a continuous sequence of signs.This type of database presents more challenges compared to the previous types,resulting in a relatively limited number of available databases.Currently,only PHOENIX14 [76],PHOENIX14T [77] and CSL Database [78] are used regularly.The scarcity of sign language datasets suitable for CSLR can be attributed to the time-consuming and complex nature of dataset collection,the diversity of sign languages,and the difficulty of annotating the data.
Upon analysis,it is evident that current sign language datasets have certain limitations.
(1) Small scale and limited vocabulary
These datasets are often small in scale and have a limited vocabulary.This poses a challenge for training models to recognize a wide range of signs and gestures accurately.A larger and more diverse dataset with a comprehensive vocabulary would enable better performance and generalization of SLR systems.
(2) Lack of diversity in terms of the signers included
Sign language users come from various backgrounds,cultures,and regions,leading to variations in signing styles,handshapes,and facial expressions.By including a more diverse set of signers,the datasets can better represent the richness and complexity of sign languages,improving the robustness and accuracy of recognition systems.
(3) Lack of variability in controlled environments
Most existing datasets are collected in controlled settings,such as laboratories or studios,which may not accurately reflect real-world scenarios.Sign language is often used in various contexts,including different lighting conditions,backgrounds,and levels of noise.Incorporating such variability in dataset collection would enhance the robustness of SLR models,enabling them to perform well in real-world applications.
(4) Lack of multimodal data
The current sign language datasets often lack multimodal data,which includes video,depth information,and skeletal data.By incorporating multimodal data,the datasets can capture the full range of visual cues used in sign language and improve the accuracy and naturalness of recognition systems.
4.2 Evaluation Method
Evaluating the performance of SLR techniques is crucial to assess their effectiveness.Several evaluation methods are commonly used in this domain.
4.2.1 Evaluation Method for Isolated SLR and Fingerspelling Recognition
Methods for evaluating Isolated SLR and fingerspelling recognition generally include Accuracy,Precision,Recall,and F1-Score.
Accuracy measures the overall correctness of the model’s predictions and is calculated as the ratio of the number of correctly classified instances to the total number of instances.Precision measures the proportion of correctly predicted positive instances out of all instances predicted as positive.It focuses on the model’s ability to avoid false positives.Recall,also known as sensitivity or true positive rate,measures the proportion of correctly predicted positive instances out of all actual positive instances.It focuses on the model’s ability to avoid false negatives.Their calculation formulas are as follows:
To understand these metrics,let us break down the components:
-True Positive(TP)represents the number of correctly recognized positive gestures.
-True Negative(TN)represents the number of correctly recognized negative gestures.
-False Positive(FP)represents the number of negative gestures incorrectly classified as positive.
-False Negative(FN)represents the number of positive gestures incorrectly classified as negative.
4.2.2 Evaluation Method for CSLR
Methods for evaluating CSLR generally include Word Error Rate(WER)and Accuracy.However,it is important to note that Accuracy in CSLR is not calculated using the same formula as mentioned previously.WER calculates the minimum number of insertions,deletions,and substitutions needed to transform the recognized sequence into the ground truth sequence,divided by the total number of words or gestures in the ground truth sequence.The formula to calculate WER is as follows:
Here,nsrepresents the number of substitutions.ndrepresents the number of deletions.nirepresents the number of insertions.Lrepresents the total number of words or gestures in the ground truth sequence.
Accuracy and WER are a pair of opposite concepts,and their calculation method is as follows:
In CSLR,a higher WER indicates a lower level of Accuracy and a lower WER indicates a higher level of Accuracy.
5 Deep Learning–Based SLR Approach
The development of deep learning techniques has greatly advanced the field of SLR.In the following section,we will introduce some commonly used deep learning techniques in the field of sign language recognition.
5.1 Convolutional Neural Networks(CNNs)
Convolutional Neural Networks (CNNs) are a type of deep learning algorithm that excels in processing visual data,making them highly suitable for analyzing sign language gestures.In the field of sign language recognition,CNNs have gained widespread use.
The main components of CNNs include convolutional layers,pooling layers,and fully connected layers.The simplified structure diagram of CNNs is depicted in Fig.8.
Input Layer:This layer receives the raw image as input.
Convolutional Layer:By applying a series of filters(convolutional kernels)to the input image,this layer performs convolution operations to extract local features.Each filter generates a feature map.
2D convolution is the fundamental operation in CNNs.It involves sliding a 2D filter(also known as a kernel)over the input image,performing element-wise multiplication between the filter and the local regions of the image,and summing the results.This operation helps in capturing local spatial dependencies and extracting spatial features.The following takes an image as an example to show 2D convolution,as shown in Fig.9.
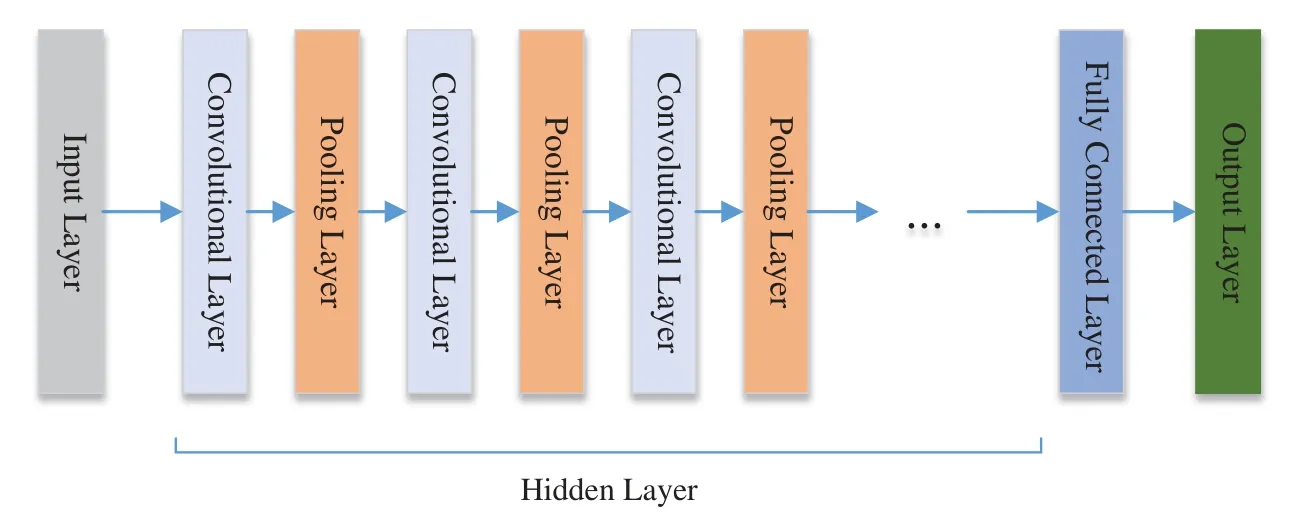
Figure 8:A simple CNN diagram
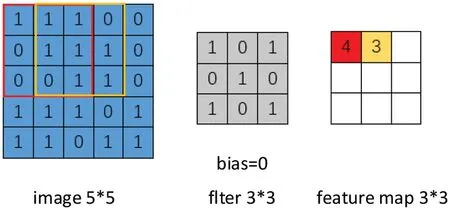
Figure 9:Illustration of 2D convolution
The calculation process of the first value of the feature map is as follows:
Fig.9 illustrates the convolution operation with an input.Assuming the input image has a shape ofHin×Win,convolution kernels is with a shape ofKh×Kw.Convolution is performed using a kernel of sizeKh×Kwon a 2D array of sizeHin×Win.The results are then summed,resulting in a 2D array with a shape ofHout×Wout.The formula to calculate the size of the output feature map is as follows:
Here,ShandSwrepresent the stride value in the vertical and horizontal directions,respectively.PhandPwdenote the size of padding in the vertical and horizontal directions,respectively.
Unlike traditional 2D CNNs,which are primarily employed for image analysis,3D CNNs are designed specifically for the analysis of volumetric data.This could include video sequences or medical scans.3D CNNs model utilizes 3D convolutions to extract features from both spatial and temporal dimensions.This allows the model to capture motion information encoded within multiple adjacent frames [83].This allows for enhanced feature representation and more accurate decision-making in tasks such as action recognition[10,84,85],video segmentation[86],and medical image analysis[87].
Activation Function:The output of the convolutional layer is passed through a non-linear transformation using an activation function,commonly ReLU(Rectified Linear Unit),to introduce non-linearity.
Pooling Layer:This layer performs down sampling on the feature maps,reducing their dimensions while retaining important features.
Max pooling and average pooling are two common types of pooling used in deep learning models as shown in Fig.10.Max pooling is a pooling operation that selects the maximum value from a specific region of the input data.Average pooling,on the other hand,calculates the average value of a specific region of the input data[88].
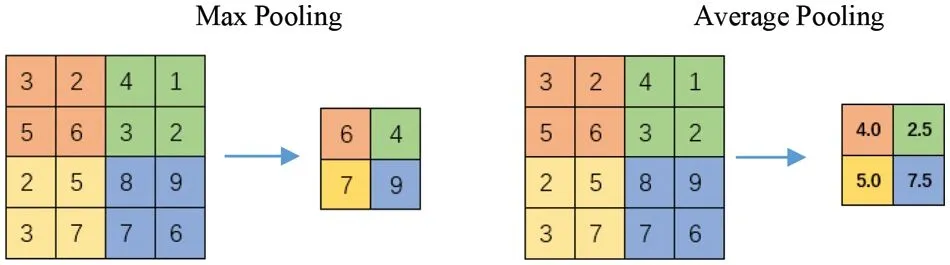
Figure 10:The pooling operation(max pooling and average pooling)
Fully Connected Layer:The output of the pooling layer is connected to a fully connected neural network,where feature fusion and classification are performed.
Output Layer:Depending on the task type,the output layer can consist of one or multiple neurons,used for tasks such as classification,detection,or segmentation.
The structure diagram of CNNs can be adjusted and expanded based on specific network architectures and task requirements.The provided diagram is a basic representation.In practical applications,additional layers such as batch normalization and dropout can be added to improve the model’s performance and robustness.
5.2 Recurrent Neural Networks(RNNs)
Recurrent Neural Networks (RNNs) are a specific type of artificial neural network designed to effectively process sequential data.They demonstrate exceptional performance in tasks involving time-dependent or sequential information,such as natural language processing,speech recognition,and time series analysis.RNN also plays a crucial role in SLR.In the following sections,we will introduce the fundamental concepts of RNN,as well as their various variants,including Long Short-Term Memory Networks(LSTM),Gate Recurrent Units(GRU),and Bidirectional Recurrent Neural Networks(BiRNN).
5.2.1 Basics of RNNs
One of the main advantages of RNNs is their ability to handle variable-length input sequences.This makes them well-suited for tasks such as sentiment analysis,where the length of the input text can vary.Additionally,RNNs can capture long-term dependencies in the data,allowing them to model complex relationships over time[89].Fig.11 displays the classic structure of a RNNs and its unfolded state.
The left side of Fig.11 represents a classic structure of a Recurrent Neural Network(RNN),whereXrepresents the input layer,Srepresents the hidden layer,andOrepresents the output layer.U,V,andWare parameters in the network.The hidden state represented bySis not only used to pass information to the output layer but also fed back to the network through the arrow loop.Unfolding this recurrent structure results in the structure shown on the right side of Fig.11:Xt-1toXt+1represent sequentially input data at different time steps,and each time step’s input generates a corresponding hidden stateS.This hidden state at each time step is used not only to produce the output at that time step but also participates in calculating the next time step’s hidden state.

Figure 11:A classic structure of RNN and its unfolded state
RNNs are neural networks that excel at processing sequential data.However,they suffer from the vanishing or exploding gradient problem,which hinders learning.To address this,variants like Long Short-Term Memory Networks(LSTM)and Gate Recurrent Units(GRU)have been developed,incorporating gating mechanisms to control information flow.
5.2.2 Long Short-Term Memory Networks(LSTM)
LSTM[90]are a type of RNN that have gained significant popularity in the field of deep learning.LSTM is specifically designed to address the vanishing gradient problem,which is a common issue in training traditional RNNs.
The key characteristic of LSTM networks is their ability to capture long-term dependencies in sequential data.This is achieved through the use of memory cells that can store and update information over time.Each memory cell consists of three main components:an input gate,a forget gate,and an output gate[89],as shown in Fig.12.
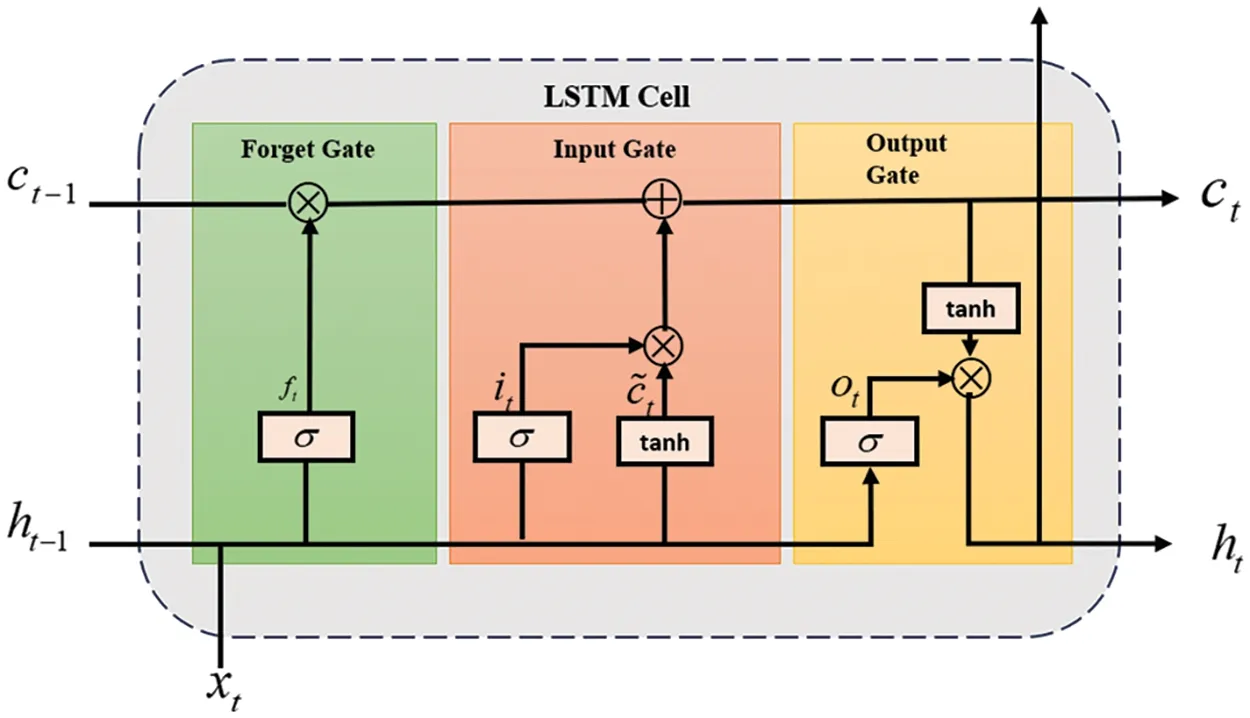
Figure 12:Typical structure of LSTM
The input gate determines how much new information should be added to the memory cell.It takes into account the current input and the previous output to make this decision.The forget gate controls the amount of information that should be discarded from the memory cell.It considers the current input and the previous output as well.Finally,the output gate determines how much of the memory cell’s content should be outputted to the next step in the sequence.By using these gates,LSTM networks can selectively remember or forget information at each time step,allowing them to capture long-term dependencies in the data.This is particularly useful in tasks such as speech recognition,machine translation,and sentiment analysis,where understanding the context of the entire sequence is crucial.
Another important characteristic of LSTM is its ability to handle gradient flow during training.The vanishing gradient problem occurs when gradients become extremely small as they propagate backward through time in traditional RNNs.LSTM addresses this issue by using a constant error carousel,which allows gradients to flow more freely and prevents them from vanishing or exploding.
5.2.3 Gate Recurrent Unit(GRU)
Similar to LSTM,the GRU is a RNN architecture that has gained significant attention in the field of natural language processing and sequence modeling[91,92].It shares similarities with LSTM in terms of its ability to capture long-term dependencies in sequential data and mitigate the vanishing gradient problem encountered in traditional RNN.
One key feature of the GRU is its utilization of two gates:the update gate and the reset gate.These gates play a crucial role in controlling the flow of information within the network.The update gate determines how much of the previous hidden state should be retained and how much new information from the current input should be incorporated into the next hidden state.This allows the GRU to selectively update its memory and capture relevant information over long sequences.
The reset gate,on the other hand,determines how much of the previous hidden state should be forgotten or reset.By resetting a portion of the hidden state,the GRU can adaptively discard irrelevant information and focus on capturing new patterns in the input sequence.
In addition to its gating mechanism,the GRU offers certain advantages over LSTM in terms of computational efficiency and simplicity.With a reduced number of gates,the GRU requires fewer computational resources and is easier to train,especially when dealing with smaller datasets.The GRU achieves this efficiency while still maintaining its ability to selectively update its memory and control the flow of information.
Furthermore,the GRU is flexible and adaptable,making it suitable for various tasks and datasets.Researchers have proposed variations of the GRU,such as the Gated Feedback Recurrent Neural Network(GF-RNN),which further enhance its memory capacity and extend its capabilities.
5.2.4 Bidirectional RNN(BiRNN)
Bidirectional Recurrent Neural Networks(BiRNN)[93]have gained significant attention in the field of natural language processing and sequential data analysis.The unique characteristic of BiRNN lies in their ability to capture both past and future context information in sequential data.This is achieved through the use of two recurrent neural networks,one processing the input sequence in the forward direction and the other in the reverse direction.By combining the outputs of both networks,BiRNN can provide a more comprehensive understanding of the sequential data[94].The structure of a BiRNN is shown in Fig.13.

Figure 13:The structure of BiRNN
In terms of training,BiRNN typically employs backpropagation through time(BPTT)or gradient descent algorithms to optimize the network parameters.However,the bidirectional nature of BiRNN introduces challenges in training,as information from both directions needs to be synchronized.To address this issue,techniques such as sequence padding and masking are commonly used.The basic unit of a BiRNN can be a standard RNN,as well as a GRU or LSTM unit.In practice,for many Natural Language Processing(NLP)problems involving text,the most used type of bidirectional RNN model is the one with LSTM units.
5.3 Deep Transfer Learning
Transfer learning,initially proposed by Tom Mitchell in 1997,is a technique that aims to transfer knowledge and representations from one task or domain to another,thereby improving performance[95].In recent years,deep transfer learning has emerged as a prominent approach that leverages deep neural networks for effective knowledge transfer[96–98].The following will introduce the pre-training model commonly used in the field of sign language recognition.
5.3.1 VGGNet
VGGNet [99] was developed by the Visual Geometry Group at the University of Oxford and has achieved remarkable performance in the ImageNet Large Scale Visual Recognition Challenge(ILSVRC).One of VGGNet’s notable characteristics is its uniform architecture.It comprises multiple stacked convolutional layers,allowing for deeper networks with 11 to 19 layers,enabling the network to learn intricate features and patterns.
Among the variants of VGGNet,VGG-16 is particularly popular.As shown in Fig.14,VGG-16 consists of 16 layers,including 13 convolutional layers and 3 fully connected layers.It utilizes 3×3 convolutional filters,followed by max-pooling layers with a 2×2 window and stride of 2.The number of filters gradually increases from 64 to 512.The network also incorporates three fully connected layers with 4096 units each,employing a ReLU activation function.The final output layer consists of 1000 units representing the classes in the ImageNet dataset,utilizing a softmax activation function.
While VGGNet has demonstrated success,it has limitations.The deep architecture of VGGNet results in computationally expensive and memory-intensive operations,demanding substantial computational resources.However,the transfer learning capability of VGGNet is a significant advantage.With pre-trained VGG models,which have been trained on large datasets such as ImageNet,researchers and practitioners can conveniently utilize them as a starting point for other computer vision tasks.This has greatly facilitated research and development in the field.

Figure 14:Architecture of VGG-16
5.3.2 GoogLeNet(Inception)
GoogLeNet,developed by a team of researchers at Google led by Christian Szegedy,aimed to create a more efficient and accurate Convolutional Neural Network (CNN) architecture for image classification tasks[100].
One of the key innovations introduced by GoogLeNet is the Inception module,as shown in Fig.15 This module utilizes multiple parallel convolutional layers with different filter sizes,including 1×1,3×3,and 5×5 filters.This allows the network to capture features at various scales,enhancing its ability to recognize complex patterns.The parallel layers within the Inception module capture features at different receptive field sizes,enabling the network to capture both local and global information.Additionally,1×1 convolutions are employed to compute reductions before the more computationally expensive 3×3 and 3×3 convolutions.These 1×1 convolutions serve a dual purpose,not only reducing the dimensionality but also incorporating rectified linear activation.
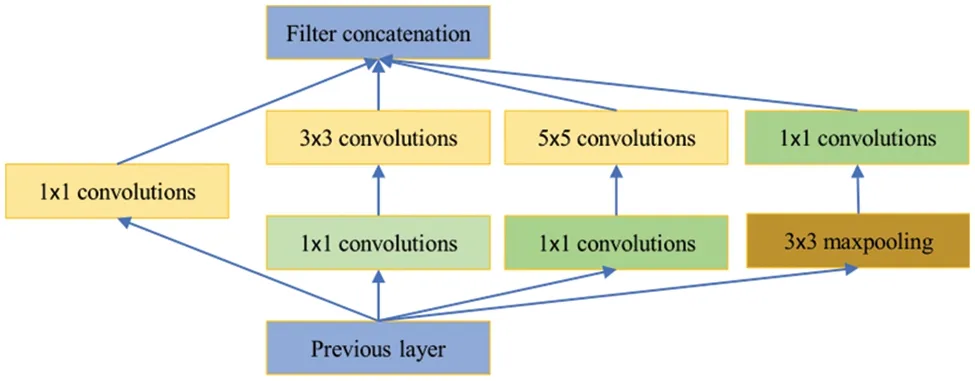
Figure 15:Inception module with dimension reductions
Over time,the Inception of GoogLeNet evolved with versions like Inception-v2[101],Inceptionv3[102],Inception-v4[103],and Inception-ResNet[103].These versions introduced various enhancements,including batch normalization[101],optimized intermediate layers,label smoothing,and the combination of Inception with ResNet’s residual connections.These improvements led to higher accuracy,faster convergence,and better computational efficiency.
5.3.3 ResNet
ResNet,short for Residual Network,was introduced by Kaiming He and his team from Microsoft Research in 2015[104].It was specifically designed to address the problem of degradation in very deep neural networks.
Traditional deep neural networks face challenges in effectively learning transformations as they become deeper.This is due to the vanishing or exploding gradients during backpropagation,making it difficult to optimize the weights of deep layers.ResNet tackles this issue by introducing residual connections,which learn the residual mapping—the difference between the input and output of a layer[104].The architecture of residual connections is illustrated in Fig.16.The input passes through convolutional layers and residual blocks.Each residual block contains multiple convolutional layers,with the input added to the block’s output through a skip connection.This allows the gradient to flow directly to earlier layers,addressing the vanishing gradient problem.

Figure 16:The architecture of residual connections
Mathematically,the residual connection is represented asH(x)=F(x)+x.Here,xis the input to a layer,F(x)is the layer’s transformation,andH(x)is the output.The residual connection adds the input x to the transformed output F(x),creating the residual mappingH(x).The network learns to optimize this mapping during training.ResNet’s architecture has inspired the development of other residual-based models like ResNeXt[105],Wide ResNet[106],and DenseNet[107],which have further improved performance in various domains.
5.3.4 Lightweight Networks(MobileNet)
Traditional CNN architectures are often computationally intensive and memory-consuming,posing challenges for deployment on resource-constrained devices.To address these challenges,Lightweight Networks have emerged as a solution.These networks are specifically designed to be compact and efficient,enabling their deployment on devices with limited computational resources.Lightweight Networks achieve this by employing various strategies such as reducing the number of parameters,employing efficient convolutional operations,and optimizing network architectures.Several specific models have been developed in the realm of Lightweight Networks like MobileNet[108],ShuffleNet [109],SqueezeNet [110],and EfficientNet [111].One of the most prominent and widely used models is MobileNet.
MobileNet is designed to strike a balance between model size and accuracy.It adopts depthwise separable convolutions to significantly reduce the computational cost compared to standard convolutional layers.This approach decomposes the convolution operation into a depthwise convolution followed by a pointwise convolution,effectively reducing the number of operations required.Fig.17 compares a layer that uses regular convolutions,batch normalization,and ReLU nonlinearity with a layer that utilizes depthwise convolution[112],followed by a 1×1 pointwise convolution,along with batch normalization and ReLU after each convolutional layer.The two layers are different in terms of their architectural design and the operations performed at each step,as shown in Fig.17b.
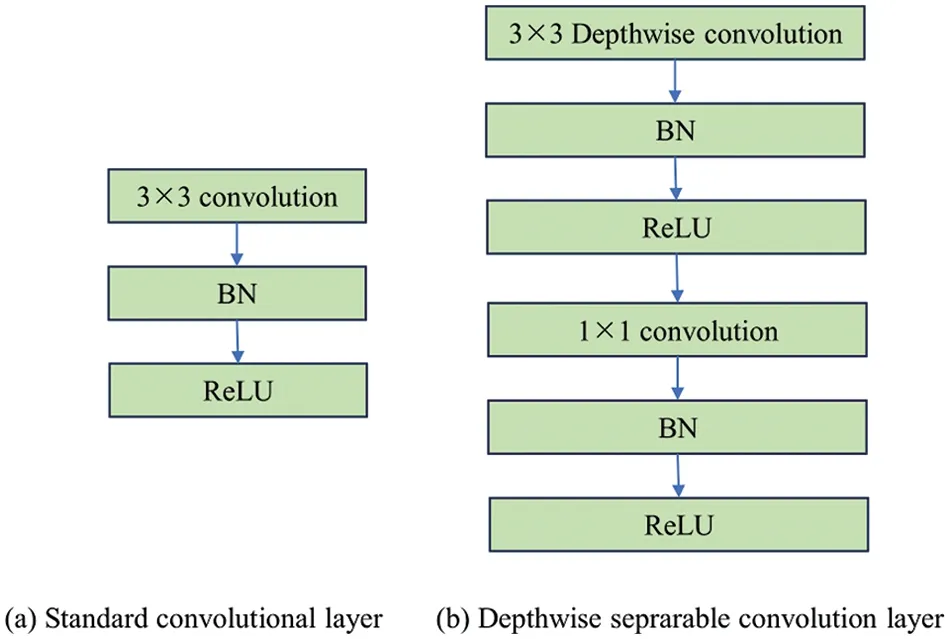
Figure 17:Comparison between standard convolutional layer and depthwise seprarable convolutions
MobileNet has multiple variations,including MobileNetV1 [108],MobileNetV2 [113],and MobileNetV3 [114].Each version improves upon the previous one by introducing new techniques to further enhance efficiency and accuracy.MobileNetV2,for example,introduces inverted residual blocks and linear bottleneck layers to achieve better performance.MobileNetV3 leverages a combination of channel and spatial attention modules to improve both speed and accuracy.
5.3.5 Transformer
The transformer model,proposed by Vaswani et al.in 2017,has emerged as a breakthrough in the field of deep learning.Its self-attention mechanism,parallelizable computation,ability to handle variable-length sequences,and interpretability have propelled it to the forefront of research in natural language processing and computer vision[115].
The Transformer model architecture consists of two main components: the encoder and the decoder.These components are composed of multiple layers of self-attention and feed-forward neural networks,as shown in Fig.18.
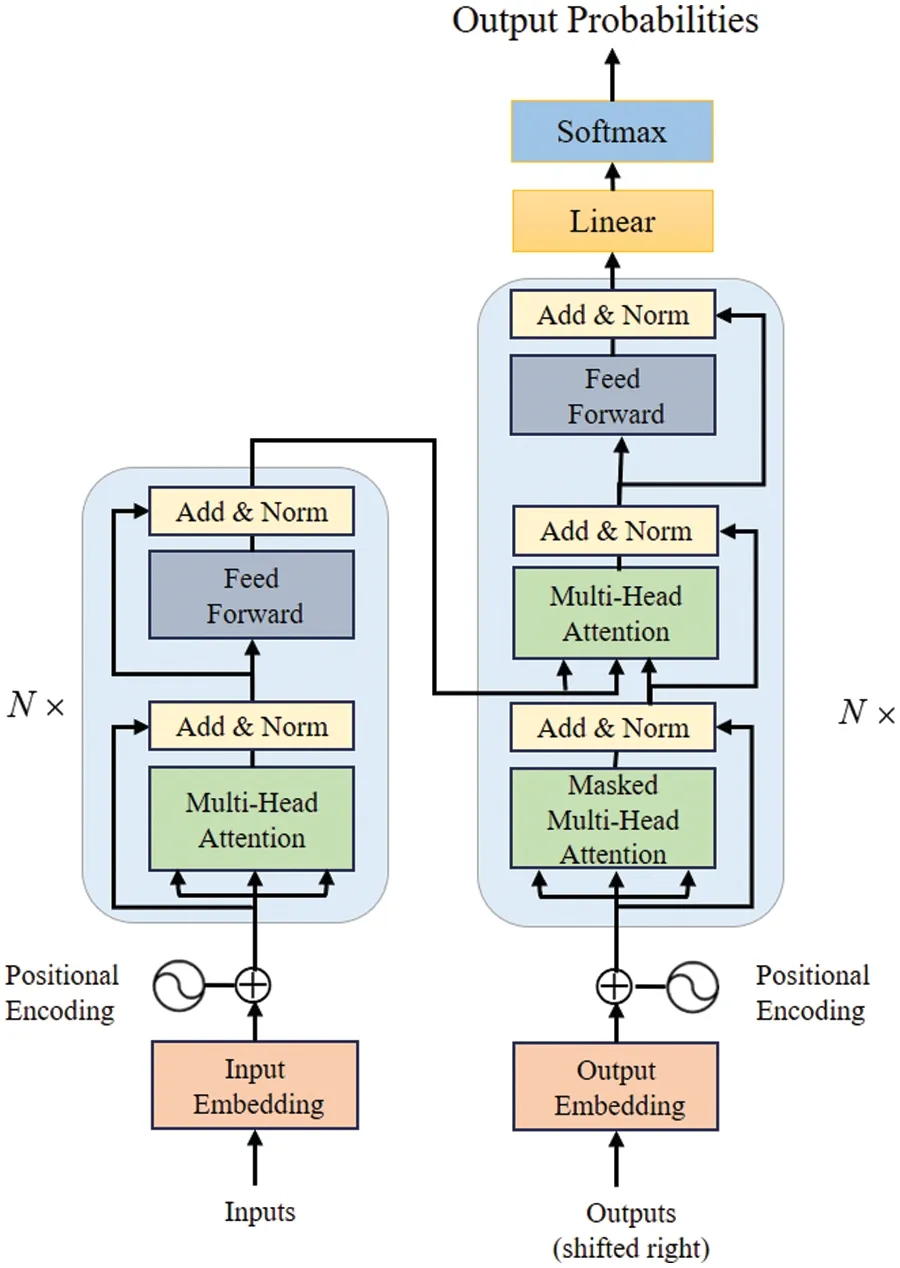
Figure 18:The transformer-model architecture
The encoder takes an input sequence and processes it to obtain a representation that captures the contextual information of each element in the sequence.The input sequence is first embedded into a continuous representation,which is then passed through a stack of identical encoder layers.
Each encoder layer in the Transformer model architecture has two sub-layers:a multi-head selfattention mechanism and a feed-forward neural network.The self-attention mechanism allows the model to attend to different parts of the input sequence when processing each element,capturing the relationships and dependencies between elements.The feed-forward neural network applies a nonlinear transformation to each element independently,enhancing the model’s ability to capture complex patterns in the data.
The decoder,on the other hand,generates an output sequence based on the representation obtained from the encoder.It also consists of a stack of identical layers,but with an additional sublayer that performs multi-head attention over the encoder’s output.This allows the decoder to focus on relevant parts of the input sequence when generating each element of the output sequence.
In addition to the self-attention mechanism,the Transformer model architecture incorporates positional encodings to handle the order of elements in the input sequence.These positional encodings are added to the input embeddings,providing the model with information about the relative positions of elements.This enables the model to differentiate between different positions in the sequence.
The Transformer model architecture is trained using a variant of the attention mechanism called“scaled dot-product attention”.This mechanism computes the attention weights between elements in the sequence by taking the dot product of their representations and scaling the result by the square root of the dimension of the representations.The attention weights are then used to compute a weighted sum of the representations,which forms the output of the attention mechanism.
The impact of the Transformer architecture is evident in its state-of-the-art performance across various domains,establishing it as a fundamental building block in modern deep learning models.These new models,including GPT [116],BERT [117],T5,ViT [118],and DeiT,are all based on the Transformer architecture and have achieved remarkable performance in a wide range of tasks in natural language processing and computer vision,making significant contributions to these fields.
6 Analysis and Discussion
In this section,we have organized the techniques and methods of SLR based on deep learning,focusing on fingerspelling,isolated words,and continuous sign language.To ensure our readers stay abreast of the latest advancements in SLR,we have placed a strong emphasis on recent progress in the field,primarily drawing from cutting-edge research papers published within the past five years.
To help understand more clearly,we provided a table with all abbreviations and full names as follows in Table 4.
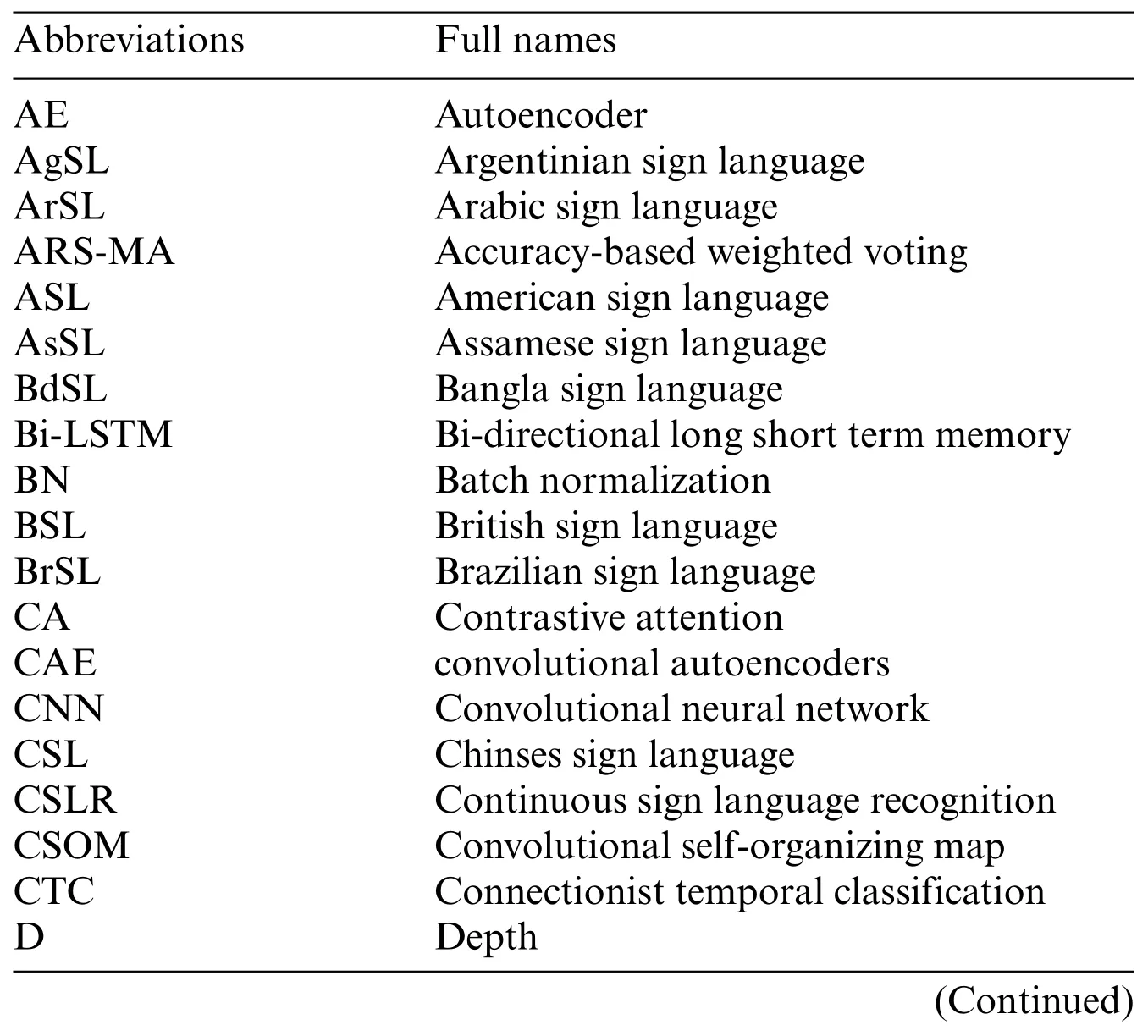
Table 4:List of all abbreviations and full names
6.1 Fingerspelling Recognition
In recent years,numerous recognition techniques have been proposed in the literature,with a specific focus on utilizing deep learning methods to recognize fingerspelling symbols.Table 5 provides a summary of various example fingerspelling recognition systems.
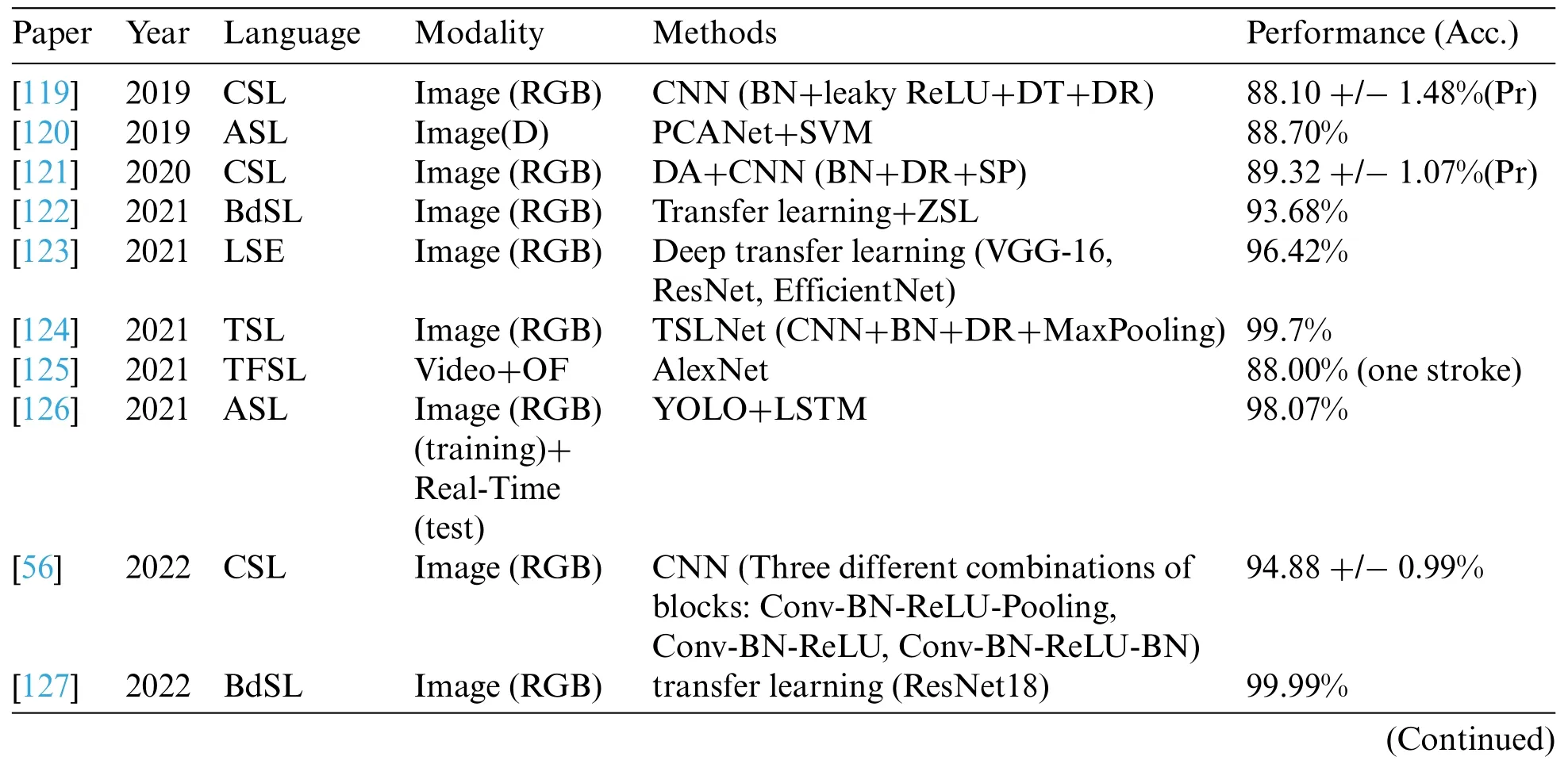
Table 5:Summary of various example fingerspelling recognition systems(Pr:Precision)
6.1.1 Analysis of Fingerspelling Recognition
As shown in Table 5,CNN has emerged as the dominant approach in fingerspelling recognition technology,demonstrating excellent performance.Jiang et al.employed CNN on fingerspelling recognition of CSL.In 2019,they proposed a six-layer deep convolutional neural network with batch normalization,leaky ReLU,and dropout techniques.Experimental results showed that the approach achieved an overall accuracy of 88.10%+/-1.48% [119].In 2020,they further proposed an eightlayer convolutional neural network,incorporating advanced techniques such as batch normalization,dropout,and stochastic pooling.Their method achieved the highest accuracy of 90.91%and an overall accuracy of 89.32% +/-1.07% [121].Their latest contribution in 2022 is the CNN-CB method,which employed three different combinations of blocks: Conv-BN-ReLU-Pooling,Conv-BN-ReLU,and Conv-BN-ReLU-BN.This new method achieved an outstanding overall accuracy of 94.88%+/-0.99%[56].Martinez-Martin et al.[123]introduced a system for recognizing the Spanish sign language alphabet.Both CNN and RNN were tested and compared.The results showed that CNN achieved significantly higher accuracy,with a maximum value of 96.42%.Zhang et al.[129] presented a realtime system for recognizing alphabets,which integrated visual data with a data glove equipped with flexible strain sensors and somatosensory data from a camera.The system utilized CNN to fuse and recognize the sensor data.The proposed system achieved a high recognition rate of up to 99.50%for all 26 letters.Kasapbaşi et al.[131]established a new dataset of the American Sign Language alphabet and developed a fingerspelling recognition system using CNN.The experiments showed that the accuracy reached 99.38%.
In recent years,there has been rapid development in the field of deep transfer learning and ensemble learning,and a set of pre-trained models has been applied to fingerspelling recognition.Sandler et al.[113]introduced two methods for automatic recognition of the BdSL alphabet,utilizing conventional transfer learning and contemporary zero-shot learning (ZSL) to identify both seen and unseen data.Through extensive quantitative experiments on 18 CNN architectures and 21 classifiers,the pre-trained DenseNet201 architecture demonstrated exceptional performance as a feature extractor.The top-performing classifier,identified as Linear Discriminant Analysis,achieved an impressive overall accuracy of 93.68%on the extensive dataset used in the study.Podder et al.[127]compared the classification performance with and without background images to determine the optimal working model for BdSL alphabet classification.Three pre-trained CNN models,namely ResNet18[104],MobileNet_V2[113],and EfficientNet_B1[111],were used for classification.It was found that ResNet18 achieved the highest accuracy of 99.99%.Ma et al.[128] proposed an ASL recognition system based on ensemble learning,utilizing multiple pre-trained CNN models including LeNet,AlexNet,VGGNet,GoogleNet,and ResNet for feature extraction.The system incorporated accuracy-based weighted voting(ARS-MA)to improve the recognition performance.Das et al.[132]proposed a hybrid model combining a deep transfer learning-based CNN with a random forest classifier for automatic recognition of BdSL alphabet.
Some models have combined two or more approaches in order to boost the recognition accuracy.Aly et al.[120] presented a novel user-independent recognition system for the ASL alphabet.This system utilized the PCANet,a principal component analysis network,to extract features from depth images captured by the Microsoft Kinect depth sensor.The extracted features were then classified using a linear support vector machine (SVM) classifier.Rivera-Acosta et al.[126] proposed a novel approach to address the accuracy loss when training models to interpret completely unseen data.The model presented in this paper consists of two primary data processing stages.In the first stage,YOLO was employed for handshape segmentation and classification.In the second stage,a Bi-LSTM was incorporated to enhance the system with spelling correction functionality,thereby increasing the robustness of completely unseen data.
Some SLR works have been deployed in embedded systems and edge devices,such as mobile devices,Raspberry Pi,and Nareshkumar et al.[133] utilized MobileNetV2 on terminal devices to achieve fast and accurate recognition of letters in ASL,reaching an accuracy of 98.77%.MobileNet was utilized to develop a model for recognizing the Arabic language’s alphabet signs,with a recognition accuracy of 94.46%[134].Zhang et al.[138]introduced a novel lightweight network model for alphabet recognition,incorporating an attention mechanism.Experimental results on the ASL dataset and BdSL dataset demonstrated that the proposed model outperformed existing methods in terms of performance.Ang et al.[139] implemented a fingerspelling recognition model for Filipino Sign Language using Raspberry Pi.They used YOLO-Lite for hand detection and MobileNetV2 for classification,achieving an average accuracy of 93.29% in differentiating 26 hand gestures representing FSL letters.Siddique et al.[140]developed an automatic Bangla sign language(BSL)detection system using deep learning approaches and a Jetson Nano edge device.
6.1.2 Discussion about Fingerspelling Recognition
According to the data in Table 4,fingerspelling recognition has achieved impressive results,with the majority of models achieving accuracy rates of 90% or higher.This high performance can be attributed to several factors.
Firstly,fingerspelling recognition focuses on a specific set of alphabets and numbers.For instance,in Chinese fingerspelling sign language,there are 30 sign language letters,including 26 single letters(A to Z)and four double letters(ZH,CH,SH,and NG)[141].This limited vocabulary simplifies the training process and contributes to higher accuracy rates.
Secondly,fingerspelling recognition primarily deals with static images,allowing it to concentrate on recognizing the hand configurations and positions associated with each sign.As a result,there is no need to consider continuous motion,which further enhances accuracy.
Thirdly,sign language databases are typically captured in controlled environments,free from complex lighting and background interference.This controlled setting reduces the complexity of the recognition task,leading to improved accuracy.
While fingerspelling recognition has achieved remarkable results due to the limited vocabulary and clear visual cues of static signs,there are still areas that can be improved.These include addressing the variability in hand shapes among handling variations in lighting and background conditions,and the development of real-time recognition systems.
6.2 Isolated Sign Language Recognition
Isolated sign language recognition (isolated SLR) refers to the task of recognizing individual sign language gestures or signs in a discrete manner.It focuses solely on recognizing and classifying isolated signs without considering the temporal relationship between them.In this approach,each sign is treated as an independent unit,and the recognition system aims to identify the meaning of each individual sign.Table 6 lists a number of proposed approaches for isolated SLR.

6.2.1 3DCNN-Based Approach for Isolated SLR
3DCNN can analyze video data directly,incorporating the temporal dimension into the feature extraction process.This allows 3DCNN to capture motion and temporal patterns,making them suitable for isolated SLR.
Liang et al.[10]presented a data-driven system that utilizes 3DCNN for extracting both spatial and temporal features from video streams.The motion information was captured by observing the depth variation between consecutive frames.Additionally,multiple video streams,such as infrared,contour,and skeleton,are utilized to further enhance performance.The proposed approach was evaluated on the SLVM dataset,a multi-modal dynamic sign language dataset captured with Kinect sensors.The experimental results demonstrated an accuracy improvement of 89.2%.Huang et al.[61]introduced attention-based 3DCNN for isolated SLR.The framework offered two key advantages:Firstly,3DCNN was capable of learning spatiotemporal features directly from raw video data,without requiring prior knowledge.Secondly,the attention mechanism incorporated in the network helped to focus on the most relevant clues.Sharma et al.[13]utilized 3DCNN,which was effective in identifying patterns in volumetric data such as videos.The cascaded 3DCNN was trained using the Boston ASL(Lexicon Video Dataset)LVD dataset.The proposed approach surpassed the current state-of-the-art models in terms of precision(3.7%),recall(4.3%),and f-measure(3.9%).Boukdir et al.[138]proposed a novel approach based on a deep learning architecture for classifying Arabic sign language video sequences.This approach utilized two classification methods: 2D Convolutional Recurrent Neural Network (2DCRNN) and 3D Convolutional Neural Network (3DCNN).In the first method,the 2DCRNN model was employed to extract features with a recurrent network pattern,enabling the detection of relationships between frames.The second method employed the 3DCNN model to learn spatiotemporal features from smaller blocks.Once features were extracted by the 2DCRNN and 3DCNN models,a fully connected network was utilized to classify the video data.Through fourfold cross-validation,the results demonstrated a horizontal accuracy of 92% for the 2DCRNN model and 99% for the 3DCNN model.
6.2.2 CNN-RNN Hybrid Models for Isolated SLR
The CNN-RNN (LSTM or GRU) hybrid model offers a powerful framework for isolated SLR by leveraging the spatial and temporal information in sign language videos.
Rastgoo et al.[145] introduced an efficient cascaded model for isolated SLR that leverages spatio-temporal hand-based information through deep learning techniques.Specifically,the model incorporated the use of Single Shot Detector(SSD),CNN,and LSTM to analyze sign language videos.Venugopalan et al.[146]presented a hybrid deep learning model that combined a convolutional LSTM network for the classification of ISL.The proposed model achieved an average classification accuracy of 76.21% on the ISL agricultural word dataset.Rastgoo et al.[149] introduced a hand pose-aware model for recognizing isolated SLR using deep learning techniques.They proposed various models,incorporating different combinations of pre-trained CNN models and RNN models.In their final model,they utilized the AlexNet and LSTM for hand detection and hand pose estimation.Through experimental evaluation,they achieved notable improvements in accuracy,with relative improvements of 1.64%,6.5%,and 7.6% on the Montalbano II,MSR Daily Activity 3D,and CAD-60 datasets,respectively.Das et al.[158]proposed a vision-based SLR system called Hybrid CNN-BiLSTM SLR(HCBSLR).The HCBSLR system addressed the issue of excessive pre-processing by introducing a Histogram Difference(HD)based key-frame extraction method.This method improved the accuracy and efficiency of the system by eliminating redundant or useless frames.The HCBSLR system utilized VGG-19 for spatial feature extraction and employed BiLSTM for temporal feature extraction.Experimental results demonstrated that the proposed HCBSLR system achieved an average accuracy of 87.67%.
Due to limited storage and computing capacities on mobile phones,the implementation of SLR applications is often restricted.To address this issue,Abdallah et al.[156] proposed the use of lightweight deep neural networks with advanced processing for real-time dynamic sign language recognition (DSLR).The application leveraged two robust deep learning models,namely the GRU and the 1D CNN,in conjunction with the MediaPipe framework.Experimental results demonstrated that the proposed solution could achieve extremely fast and accurate recognition of dynamic signs,even in real-time detection scenarios.The DSLR application achieved high accuracies of 98.8%,99.84%,and 88.40%on the DSL-46,LSA64,and LIBRAS-BSL datasets,respectively.Li et al.[153]presented MyoTac,a user-independent real-time tactical sign language classification system.The network was made lightweight through knowledge distillation by designing tactical CNN and BiLSTM to capture spatial and temporal features of the signals.Soft targets were extracted using knowledge distillation to compress the neural network scale nearly four times without affecting the accuracy.
Most studies on SLR have traditionally focused on manual features extracted from the shape of the dominant hand or the entire frame.However,it is important to consider facial expressions and body gestures.Shaik et al.[147]proposed an isolated SLR framework that utilized Spatial-Temporal Graph Convolutional Networks (ST-GCNs) [151,152] and Multi-Cue Long Short-Term Memories (MCLSTMs) to leverage multi-articulatory information (such as body,hands,and face) for recognizing sign glosses.
6.2.3 Sensor—DNN Approaches for Isolated SLR
The advantages of sensor and DNN make sensor-DNN approaches a promising choice for effective and practical isolated SLR systems.Lee et al.[142]developed and deployed a smart wearable system for interpreting ASL using the RNN-LSTM classifier.The system incorporated sensor fusion by combining data from six IMUs.The results of the study demonstrated that this model achieved an impressive average recognition rate of 99.81% for 27 word-based ASL.In contrast to video,RF sensors offer a way to recognize ASL in the background without compromising the privacy of Deaf signers.Gurbuz et al.[37] explored the necessary RF transmit waveform parameters for accurately measuring ASL signs and their impact on word-level classification accuracy using transfer learning and convolutional autoencoders(CAE).To improve the recognition accuracy of fluent ASL signing,a multi-frequency fusion network was proposed to utilize data from all sensors in an RF sensor network.The use of the multi-frequency fusion network significantly increased the accuracy of fluent ASL recognition,achieving a 95% accuracy for 20-sign fluent ASL recognition,surpassing conventional feature-level fusion by 12%.Gupta et al.[157] proposed A novel ensemble of convolution neural networks(CNN)for robust ISL recognition using multi-sensor data.
6.2.4 Other Approaches for Isolated SLR
Some researchers used Deep belief net(DBN),Transformer,and other models for isolated SLR.Aly et al.[143]proposed A novel framework for recognizing ArSL that is not dependent on the signer.This framework utilized multiple deep learning architectures,including hand semantic segmentation,hand shape feature representation,and deep recurrent neural networks.The DeepLabv3+model was employed for semantic segmentation.Handshape features were extracted using a single layer Convolutional Self-Organizing Map (CSOM).The extracted feature vectors were then recognized using a deep BiLSTM.Deep belief net(DBN)was applied to the field of wearable-sensor-based CSL recognition[144].To obtain multi-view deep features for recognition,Shaik et al.[147]proposed using an end-to-end trainable multi-stream CNN with late feature fusion.The fused multi-view features are then fed into a two-layer dense network and a softmax layer for decision-making.Eunice et al.[161]proposed a novel approach for gloss prediction using the Sign2Pose Gloss prediction transformer.
6.2.5 Discussion about Isolated SLR
Deep learning techniques have emerged as prominent solutions in isolated SLR.One approach involves the use of 3DCNN to capture the spatiotemporal information of sign language gestures.These models can learn both spatial features from individual frames and temporal dynamics from the sequence of frames.Another approach combines Recurrent Neural Networks(RNN),such as LSTM or GRU,with CNN to model long-term dependencies in signs.Additionally,deep transfer learning leverages pre-trained models like VGG16,Inception,and ResNet as feature extractors.
Furthermore,various techniques have been applied to address specific challenges in isolated SLR.Data augmentation,attention mechanisms,and knowledge distillation are employed to augment the training dataset,focus on relevant parts of gestures,and transfer knowledge from larger models,respectively.Multi-modal fusion and multi-view techniques are also utilized to combine information from different sources and perspectives,further improving recognition performance.
Despite the remarkable progress made in isolated SLR,several challenges remain to be addressed.
(1) The availability of large and diverse datasets
As the dataset size increases,there is a risk of overfitting,which can lead to a decrease in recognition accuracy.For example,Eunice et al.proposed Sign2Pose,achieving an accuracy of 80.9%on the WLASL100 dataset,but the accuracy dropped to 38.65%on the WLASL2000 dataset[161].
(2) The user-dependency and user-independency of recognition systems
User-dependency refers to the need for personalized models for each individual user,which can limit the scalability and practicality of the system.On the other hand,user-independency aims to develop models that can generalize well across different users.Achieving user-independency requires addressing intra-class variations and adapting the models to different signing styles and characteristics.
(3) The lack of standard evaluation metrics and benchmarks
The lack of standard evaluation metrics and benchmarks hinders the comparison and benchmarking of different approaches.Establishing standardized evaluation protocols and benchmarks would facilitate fair comparisons and advancements in the field.
6.3 Continuous Sign Language Recognition
Continuous Sign Language Recognition (CSLR) refers to the recognition and understanding of sign language in continuous and dynamic sequences,where signs are not isolated but connected together to form sentences or conversations.CSLR presents unique challenges compared to Isolated SLR,including managing temporal dynamics,variations in sign durations and speeds,co-articulation effects,incorporating non-manual features,and real-time processing.Table 7 lists a summary of CSLR techniques.

6.3.1 CNN-RNN Hybrid Approaches for CLSR
The CNN-RNN hybrid approach is a powerful framework in the field of deep learning that combines the strengths of CNN and RNN.It is commonly used for tasks that involve both spatial and sequential data,such as dynamic sign video analysis.
Koller et al.[163] introduced the end-to-end embedding of a CNN into an HMM while interpreting the outputs of the CNN in a Bayesian framework.Cui et al.[164] presented a developed framework for CSLR using deep neural networks.The architecture incorporated deep CNN with stacked temporal fusion layers as the feature extraction module,and BiLSTM as the sequence-learning module.Additionally,the paper contributed to the field by exploring the multimodal fusion of RGB images and optical flow in sign language.The method was evaluated on two challenging SL recognition benchmarks: PHOENIX and SIGNUM,where it outperformed the state of the art by achieving a relative improvement of more than 15% on both databases.Mittal et al.[12] proposed a modified LSTM model for CSLR.In this model,CNN was used to extract the spatial features,A modified LSTM classifier for the recognition of continuous signed sentences using sign sub-units.
6.3.2 RNN Encoder-Decoder Approaches
The Encoder-Decoder approach is a deep learning model used for sequence-to-sequence tasks.It consists of two main components: an encoder and a decoder.In the Encoder-Decoder approach,the encoder and decoder are typically implemented using RNNs such as LSTM or GRUs.the RNN Encoder-Decoder approach is well-suited for tasks involving sequential data,where capturing dependencies and context is crucial for generating accurate and coherent output sequences.
Papastrati et al.[167]introduced a novel unified deep learning framework for vision-based CSLR.The proposed approach consisted of two encoders.a video encoder was proposed that consists of a CNN,stacked 1D temporal convolution layers(TCL),and a BiLSTM.a text encoder is implemented using a unidirectional LSTM.The outputs of both encoders are projected into a joint decoder.The proposed method on the PHOENIX14T dataset achieved a WER of 24.1% on the Dev set and 24.3% WER on the Test set.Wang et al.[175]developed a novel real-time end-to-end SLR system,named DeepSLR.The system utilized an attention-based encoder-decoder model with a multi-channel CNN.The effectiveness of DeepSLR was evaluated extensively through implementation on a smartphone and subsequent evaluations.Zhou et al.[176]proposed a spatial-temporal multi-cue(STMC)network for CSLR.The STMC network comprised a spatial multi-cue(SMC)module and a temporal multicue(TMC)module.They are processed by the BiLSTM encoder,the CTC decoder,and the SA-LSTM decoder for sequence learning and inference.The proposed approach achieved 20.7% WER on the test set,a new state-of-the-art result on PHOENIX14.
6.3.3 Transformer(BERT)Based Approaches for CSLR
The transformer is a neural network architecture that utilizes the encoder-decoder component structure.In the encoder-decoder framework,the transformer replaces traditional RNNs with selfattention mechanisms.This innovative approach has demonstrated impressive performance in a range of natural language processing tasks.The remarkable success of transformers in NLP has captured the interest of researchers working on SLR.Chen et al.[177] proposed a two-stream lightweight multimodal fusion sign transformer network.This approach combined the contextual capabilities of the transformer network with meaningful multimodal representations.By leveraging both visual and linguistic information,the proposed model aimed to improve the accuracy and robustness of SLR.Preliminary results of the proposed model on the PHOENIX14T dataset have shown promising performance,with a WER of 16.72%.Zhang et al.[180] proposed SeeSign,a multimodal fusion transformer framework for SLR.SeeSign incorporated two attention mechanisms,namely statistical attention and contrastive attention,to thoroughly investigate the intra-modal and inter-modal correlations present in surface Electromyography(sEMG)and inertial measurement unit(IMU)signals,and effectively fuse the two modalities.The experimental results showed that SeeSign achieved a WER of 18.34% and 22.08% on the OH-Sentence and TH-Sentence datasets,respectively.Jiang et al.[182]presented TrCLR,a novel Transformer-based model for CSLR.To extract features,they employed the CLIP4Clip video retrieval method,while the overall model architecture adopts an end-to-end Transformer structure.The CSL dataset,consisting of sign language data,is utilized for this experiment.The experimental results demonstrated that TrCLR achieved an accuracy of 96.3%.Hu et al.[183] presented a spatial-temporal feature extraction network (STFE-Net) for continuous sign language translation (CSLT).The spatial feature extraction network(SFE-Net) selected 53 key points related to sign language from the 133 key points in the COCO-WholeBody dataset.The temporal feature extraction network(TFE-Net)utilized a Transformer to implement temporal feature extraction,incorporating relative position encoding and position-aware self-attention optimization.The proposed model achieved BLUE-1=77.59,BLUE-2=75.62,BLUE-3=74.25,and BLUE-4=72.14 on a Chinese continuous sign language dataset collected by the researchers themselves.
BERT(Bidirectional Encoder Representations from Transformers)is based on the Transformer architecture and is pre-trained on a largecorpusof unlabeled text data [117].This pre-training allows BERT to be fine-tuned for various NLP tasks,achieving remarkable performance across multiple domains.Zhou et al.[174]developed a deep learning framework called SignBERT.SignBERT combined the BERT with the ResNet to effectively model underlying sign languages and extract spatial features for CSLR.In another study,Zhou et al.[11]developed A BERT-based deep learning framework named CASignBERT for CSLR.the proposed CA-SignBERT framework consisted of the cross-attention mechanism and the weight control module.Experimental results demonstrated that the CA-SignBERT framework attained the lowest WER in both the validation set(18.3%)and test set(18.6%)of the PHOENIX14.
6.3.4 Other Approaches for CSLR
Some researchers used capsule networks(CapsNet),Generative Adversarial Networks(GANs),and other models for CSLR.In [166],a novel one-dimensional deep CapsNet architecture was proposed for continuous Indian SLR using signals collected from a custom-designed wearable IMU system.The performance of the proposed CapsNet architecture was evaluated by modifying the dynamic routing between capsule layers.The results showed that the proposed CapsNet achieved improved accuracy rates of 94% for 3 routings and 92.50% for 5 routings,outperforming the CNN which achieved an accuracy of 87.99%.Elakkiya et al.[172] focused on recognizing sign language gestures from continuous video sequences by characterizing manual and non-manual gestures.A novel approach called hyperparameter-based optimized GANs was introduced,which operated in three phases.In Phase I,stacked variational auto-encoders (SVAE) and Principal Component Analysis(PCA)were employed to obtain pre-tuned data with reduced feature dimensions.In Phase II,H-GANs utilized a Deep LSTM as a generator and LSTM with 3DCNN as a discriminator.The generator generated random sequences with noise based on real frames,while the discriminator detected and classified the real frames of sign gestures.In Phase III,Deep Reinforcement Learning (DRL) was employed for hyper-parameter optimization and regularization.Proximal Policy Optimization(PPO)optimized the hyper-parameters based on reward points,and Bayesian Optimization(BO)regularized the hyperparameters.Han et al.[178]built 3D CNNs such as 3D-MobileNets,3D-ShuffleNets,and X3Ds to create compact and fast spatiotemporal models for continuous sign language tasks.In order to enhance their performance,they also implemented a random knowledge distillation strategy(RKD).
6.3.5 Discussion about CSLR
CSLR aims to recognize and understand sign language sentences or continuous streams of gestures.This task is more challenging than isolated SLR as it involves capturing the temporal dynamics and context of the signs.
In recent years,CSLR has made significant progress,thanks to advancements in deep learning and the availability of large-scale sign language datasets.The use of 3DCNN,RNN,and their variants,and transformer models,has shown promising results in capturing the temporal dependencies and context in sign language sentences.
CSLR is a more complex and challenging task compared to isolated SLR.In CSLR,two main methods that have shown promising results are the RNN encoder-decoder and Transformer models.
The RNN encoder-decoder architecture is widely used in CSLR.The encoder processes the input sign language sequence,capturing the temporal dynamics and extracting meaningful features.Recurrent neural networks(RNN)such as LSTM or GRU are commonly used as the encoder,as they can model long-term dependencies in sign language sentences.The decoder,also an RNN,generates the output sequence,which could be a sequence of words or signs.The encoder-decoder framework allows for end-to-end training,where the model learns to encode the input sequence and generate the corresponding output sequence simultaneously.
Another notable method in CSLR is the Transformer model.Originally introduced for natural language processing tasks,the Transformer has also been adapted for SLR.The Transformer model relies on self-attention mechanisms to capture the relationships between different parts of the input sequence.It can effectively model long-range dependencies and has been shown to be highly parallelizable,making it suitable for real-time CSLR.The Transformer model has achieved competitive results in CSLR tasks and has shown potential for capturing the contextual information and syntactic structure of sign language sentences.
Despite the progress made,CSLR still faces great challenges.One major challenge is the lack of large-scale and diverse datasets for training and evaluation.Collecting and annotating continuous sign language datasets is time-consuming and requires expertise.Additionally,the variability and complexity of CSLR make it more difficult to capture and model the continuous nature of sign language.The presence of co-articulation,where signs influence each other,further complicates recognition.
Another challenge in CSLR is the need for real-time and online recognition.Unlike isolated SLR,where gestures are segmented and recognized individually,CSLR requires continuous processing and recognition of sign language sentences as they are being performed.Achieving real-time performance while maintaining high accuracy is a significant challenge that requires efficient algorithms and optimized models.
Additionally,CSLR often involves addressing the semantic and syntactic structure of sign language sentences.Sign languages have their own grammar and syntax,which need to be considered for accurate recognition.Capturing the contextual information and understanding the meaning of the signs in the context of the sentence pose additional challenges.
Furthermore,user-independency and generalization across different sign languages and users are crucial for CSLR systems.Developing models that can adapt to different signing styles,regional variations,and individual preferences is a complex task that requires extensive training data and robust algorithms.
7 Conclusions and Future Directions
In this survey paper,we have explored the application of deep learning techniques in SLR,involving fingerspelling,isolated signs,and continuous signs.We have discussed various aspects of SLR,including sign data acquisition technologies,sign language datasets,evaluation methods,and advancements in deep learning-based SLR.
CNN has been widely used in SLR,particularly for its ability to capture spatial features from individual frames.RNN,such as LSTM and GRU,has also been employed to model the temporal dynamics of sign language gestures.Both CNN and RNN have shown promising results in fingerspelling and isolated SLR.However,the continuous nature of sign language poses additional challenges,which have led to the exploration of advanced neural networks.One notable method is the Transformer model,originally introduced for natural language processing tasks but adapted for SLR.The Transformer model’s self-attention mechanisms enable it to capture relationships between different parts of the input sequence,effectively modeling long-range dependencies.It has shown potential for real-time CSLR,with competitive results and the ability to capture contextual information and syntactic structure.
Despite the significant advancements in SLR using deep learning approaches,there are still several great challenges that need to be addressed in this field.Through research,we believe that there are still the following challenges in the field of SLR,as shown in Table 8.
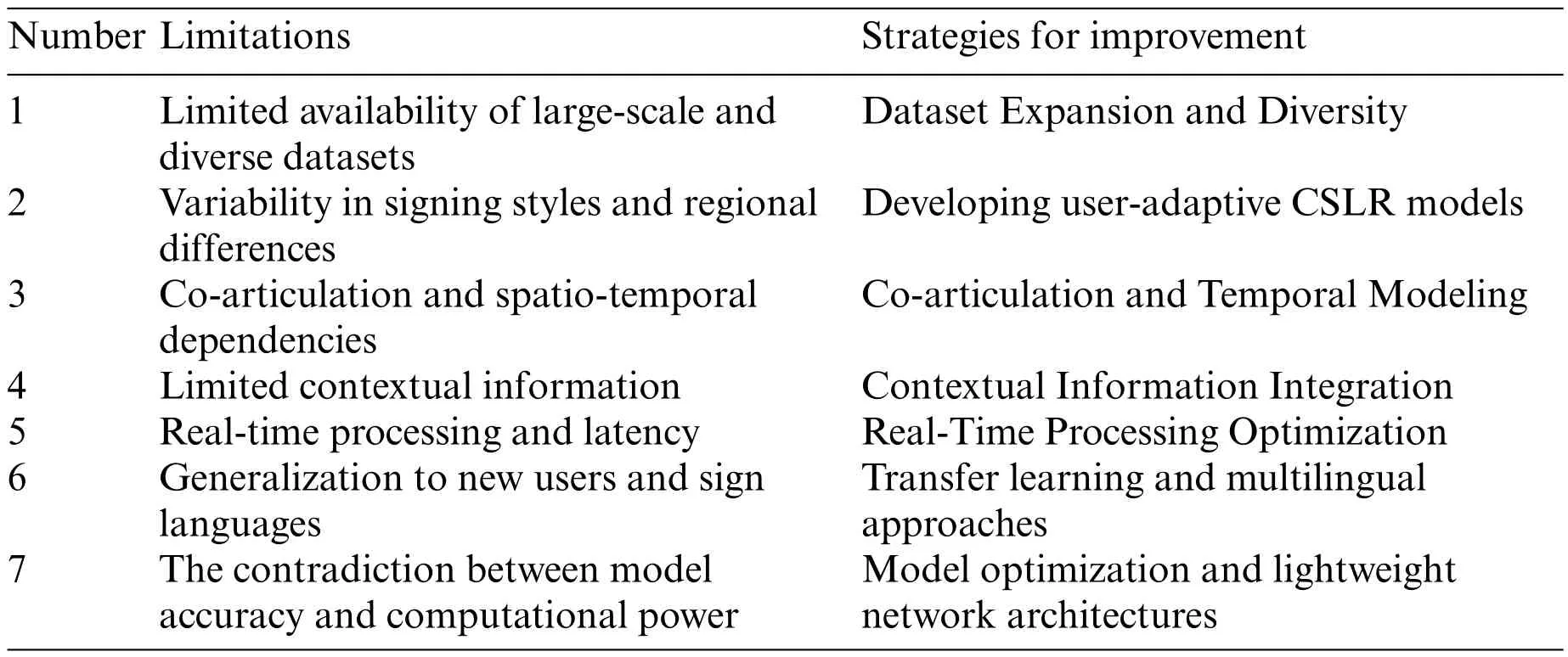
Table 8:The main limitations in SLR
(1) Limited availability of large-scale and diverse datasets
Obtaining comprehensive datasets for SLR is challenging.Scarce annotated datasets accurately representing sign language’s variability and complexity restrict the training and evaluation of robust models.To overcome this,efforts should be made to collect larger-scale and more diverse datasets through collaboration among researchers,sign language communities,and organizations.Incorporating regional variations and different signing styles in the dataset can improve generalization.
Additionally,existing datasets are recorded in controlled environments,which may not accurately represent real-world conditions.Here are some suggestions for collecting sign language in more realistic contexts:
a) Record sign language conversations between two or more people in natural settings,such as a coffee shop or a park.This will help capture the nuances of sign language communication that are often missed in controlled environments;
b) Collaborate with sign language communities to collect data that is representative of their language and culture.This will ensure that the data collected is relevant and accurate.
c) Collect sign language data from social media platforms,such as YouTube or Instagram.This will allow for the collection of data from a wide range of sign language users and contexts.
d) Use crowdsourcing to collect sign language data from a large number of users.This will allow for the collection of a diverse range of data from different sign language users and contexts.
(2) Variability in signing styles and regional differences
Sign language exhibits significant variability in signing styles and regional variations,making it difficult to develop user-independent recognition systems.To enhance recognition accuracy,useradaptive CSLR models should be developed.Personalized adaptation techniques such as user-specific fine-tuning or transfer learning can allow systems to adapt to individual signing styles.Incorporating user feedback and iterative model updates can further improve user adaptation.
(3) Co-articulation and temporal dependencies
Co-articulation,where signs influence each other,poses challenges in accurately segmenting and recognizing individual signs.To address the issue of co-articulation,it is essential to consider different modalities for SLR,including depth,thermal,Optical Flow (OF),and Scene Flow (SF),in addition to RGB image or video inputs.Multimodal fusion of these modalities can improve the accuracy and robustness of SLR systems.Furthermore,feature fusion that combines manual and nonmanual features can enhance recognition accuracy.Many existing systems tend to focus solely on hand movements and neglect non-manual signs,which can lead to inaccurate recognition.To capture the continuous nature of sign language,it is crucial to model temporal dependencies effectively.Dynamic modeling approaches like hidden Markov models(HMMs)or recurrent neural networks(RNNs)can be explored to improve segmentation and recognition accuracy.These models can effectively capture the co-articulation and temporal dependencies present in sign language.da Silva et al.[186]developed a multiple-stream architecture that combines convolutional and recurrent neural networks,dealing with sign languages’visual phonemes in individual and specialized ways.The first stream uses the OF as input for capturing information about the“movement”of the sign;the second stream extracts kinematic and postural features,including “handshapes”and “facial expressions”;the third stream processes the raw RGB images to address additional attributes about the sign not captured in the previous streams.
One of the major challenges in SLR is capturing and understanding the complex spatio-temporal nature of sign language.On one hand,sign language involves dynamic movements that occur over time,and recognizing and interpreting these temporal dependencies is essential for understanding the meaning of signs.On the other hand,SLR also relies on spatial information,particularly the precise hand shape,hand orientation,and hand trajectory.To address these challenges,researchers in the field are actively exploring advanced deep learning techniques,to effectively capture and model the spatio-temporal dependencies in sign language data.
(4) Limited contextual information
Capturing and utilizing contextual information in CSLR systems remains a challenge.Understanding the meaning of signs in the context of a sentence is crucial for accurate recognition.Incorporating linguistic knowledge and language modeling techniques can help interpret signs in the context of the sentence,improving accuracy and reducing ambiguity.
(5) Real-time processing and latency
Achieving real-time and low-latency CSLR systems while maintaining high accuracy poses computational challenges.Developing efficient algorithms and optimizing computational resources can enable real-time processing.Techniques like parallel processing,model compression,and hardware acceleration should be explored to minimize latency and ensure a seamless user experience.
(6) Generalization to new users and sign languages
Generalizing CSLR models to new users and sign languages is complex.Adapting models to different users’signing styles and accommodating new sign languages require additional training data and adaptation techniques.Transfer learning can be employed to generalize CSLR models across different sign languages,reducing the need for extensive language-specific training data.Exploring multilingual CSLR models that can recognize multiple sign languages simultaneously can also improve generalization.
By addressing these limitations,the field of SLR can make significant progress in addressing the limitations and advancing the accuracy,efficiency,and generalization capabilities of SLR systems.
(7) The contradiction between model accuracy and computational power
As models become more complex and accurate,they often require a significant amount of computational power to train and deploy.This can limit their practicality and scalability in real-world applications.To address this contradiction,several approaches can be considered:
a) Explore techniques to optimize and streamline the model architecture to reduce computational requirements without sacrificing accuracy.This can include techniques like model compression,pruning,or quantization,which aim to reduce the model size and computational complexity while maintaining performance.
b) Develop lightweight network architectures specifically designed for SLR.These architectures aim to reduce the number of parameters and operations required for inference while maintaining a reasonable level of accuracy,such as[187–190].
Acknowledgement:Thanks to three anonymous reviewers and the editors of this journal for providing valuable suggestions for the paper.
Funding Statement:This work was supported from the National Philosophy and Social Sciences Foundation(Grant No.20BTQ065).
Author Contributions:The authors confirm contribution to the paper as follows:study conception and design:Yanqiong Zhang,Xianwei Jiang;data collection:Yanqiong Zhang;analysis and interpretation of results: Yanqiong Zhang,Xianwei Jiang;draft manuscript preparation: Yanqiong Zhang.All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials:All the reviewed research literature and used data in this manuscript includes scholarly articles,conference proceedings,books,and reports that are publicly available.The references and citations can be found in the reference list of this manuscript and are accessible through online databases,academic libraries,or by contacting the publishers directly.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
杂志排行

Computer Modeling In Engineering&Sciences的其它文章
- A Study on the Transmission Dynamics of the Omicron Variant of COVID-19 Using Nonlinear Mathematical Models
- Novel Investigation of Stochastic Fractional Differential Equations Measles Model via the White Noise and Global Derivative Operator Depending on Mittag-Leffler Kernel
- Saddlepoint Approximation Method in Reliability Analysis:A Review
- A Review of the Tuned Mass Damper Inerter(TMDI)in Energy Harvesting and Vibration Control:Designs,Analysis and Applications
- A Survey on Blockchain-Based Federated Learning:Categorization,Application and Analysis
- Full-Scale Isogeometric Topology Optimization of Cellular Structures Based on Kirchhoff–Love Shells