基于眼动信号的感兴趣检测方法研究*
2024-03-23王新志张华宇宋爱国
王新志,曾 洪,张华宇,宋爱国
(东南大学仪器科学与工程学院,江苏 南京 210096)
0 引 言
如今,基于机器智能的目标检测技术飞速发展,并在人脸识别、遥感图像识别等领域取得广泛应用。然而,对于目标遮挡或部分缺失等难例样本,机器智能难以有效检测,使用输入设备,如键盘、鼠标等为机器智能提供人工标注难例样本是常见的解决方案,但是存在标注效率较低的问题[1,2]。
眼动信号是人眼球注视位置随时间变化的时间序列数据,其中的注视事件能够分析人的相关认知信息。通过分析被试执行标注任务的眼动信号可以自然地实现难例样本标注,已在实践中探索出许多应用[3,4],但现有研究多基于提取眼动信号特征、使用浅层模型分类的方法。受到深度学习取得广泛应用的启发,有学者提出InceptionTime 网络[5],卷积长短期记忆(convolutional long short-term memory,ConvLSTM)网络[6],LSTM-全卷积网络(fully convolutional network,FCN)[7]等用于时间序列分类的深度网络。深度学习方法具有无需特征工程、支持端到端训练等优势,但以上研究中未充分提取注视序列的不同尺度特征,未考虑各卷积通道的重要性关系。因此,研究多尺度特征和卷积通道权重分配对注视序列分类的影响很有意义。
本文提出一种基于眼动信号的感兴趣检测深度学习方法,旨在提高感兴趣检测精度,应用于难例样本标注场景中。本文的创新点在于:一方面,使用眼动仪无接触采集被试浏览图像的眼动信号,并通过自适应阈值算法提取出注视序列;另一方面,设计多尺度卷积残差模块学习注视序列不同尺度特征,并结合特征通道权重重分配模块为不同卷积通道分配权重,提升感兴趣检测的精度和鲁棒性。
1 感兴趣检测方法的总体设计
感兴趣检测方法的总体设计(图1)先通过眼动仪采集被试浏览图像的眼动信号;其次,通过自适应阈值算法提取出注视序列,注视序列是信息加工的主要过程,也即当前感兴趣区域(region of interest,ROI);最后,通过多尺度残差网络对目标ROI和非目标ROI识别,提高感兴趣检测精度。

图1 感兴趣检测方法的总体设计
1.1 注视序列提取算法
人的眼球运动能够反映大脑内部信息的加工过程,根据眼动速度可分为3 种基本眼动事件:注视(fixation)、扫视(saccade)和追随运动(pursuit movement)。注视眼动是眼睛在目标物体上的停留,是进行信息加工的主要过程,也即当前ROI[8]。眼动仪以高时空分辨率精确地记录眼睛注视位置以及运动轨迹,为研究视觉信息加工过程提供了有效的数据支持。
在眼动数据分析研究中,区分具体的眼动事件是至关重要的步骤。常用的眼动事件检测是根据经验设置眼动速度阈值,根据阈值区分不同的眼动事件[9,10],但是由于个体差异,具体阈值的设置会对事件检测结果产生影响。鉴于此,本文使用自适应阈值算法实现眼动事件检测,该算法主要包含预处理和眼动事件检测。
首先,眼动信号预处理,目的是去除噪声和获取眼动速度序列。采用尖峰滤波器滤除异常尖峰,之后通过中值滤波和Savitzky-Golay滤波对数据平滑处理。最后按式(1)和式(2)分别计算出眼动角速度v和眼动角加速度a
式中t为2个注视点之间的时间间隔;x0,y0为第1 个注视点的像素坐标;xt,yt为第2个注视点的像素坐标;d为被试物与显示器的距离。
其次,眼动事件检测。计算扫视速度阈值,初始速度阈值为PT1(初始值范围100 ~300°/s)[8],逐步计算n-1 范围内眼动角速度的中值和方差更新扫视速度阈值,更新公式如式(3)所示
式中 median 为中值;F为绝对中位差(median absolute deviation,MAD)缩放因子;vn-1为前n-1 个眼动角速度序列。
不断更新扫视速度阈值,直到其稳定在一定范围内,停止条件如式(4)所示
在获得扫视速度阈值后,将眼动角速度序列按照该阈值分块,将大于追随速度阈值的样本标注为追随事件,其余样本归类为注视事件。保存所有注视序列,作为感兴趣检测样本数据。
1.2 多尺度残差网络模型
注视序列是一种随时间变换的时间序列,感兴趣检测是判断某个注视序列是否为目标注视序列,即注视目标的认知过程,非目标注视序列是由图片中干扰信息产生[11]。针对目前模型缺乏多尺度特征和各卷积通道重要性的研究,本文提出一种基于特征通道权重重分配的多尺度残差网络Res_Fix(如图2),不但通过多尺度卷积捕获不同时间尺度的眼动信号特征,而且通过特征通道权重重分配模块分配各卷积特征通道的权重。网络模型包括卷积滤波模块、特征学习模块和分类输出模块3 部分。卷积滤波模块主要功能是增强眼动信号信噪比,特征提取模块通过多尺度卷积和卷积特征通道权重重分配实现,最后使用全连接(fully connected,FC)层和SoftMax函数实现分类,以下内容将主要介绍多尺度卷积和卷积特征通道权重重分配的具体实现方法。

图2 Res_Fix网络结构
一个健壮的时间序列分类算法应该能够捕获不同时间尺度的序列数据,因为长期特征反映总体趋势,短期特征反映局部区域的细节变化。本文提出一种新的神经网络构建块ResTnet,通过在单个残差块内构建分层类残差连接,增加了每层网络感受野(receptive field)的多样性,从而更好地获得时间序列的多尺度特征。ResTnet 将多个一维卷积组通过残差连接,增加了每层网络感受野的多样性,其内部结构如图3(右)所示,图3(左)表示残差网络的瓶颈(Bottleneck)模块结构。ResTnet采用一维卷积核处理时间序列,将不同卷积组之间以类似分层残差的方式连接起来,最后将卷积输出特征块按通道拼接。这种特征先拆分后融合的方案,使得单个残差块内融合多尺度特征。

图3 Bottleneck模块(左)和ResTnet模块结构(右)
SE 模块的内部结构如图4 右图所示[12],包括“压缩”(squeeze)操作、“激励”(exciation)操作和“缩放”(scale)操作。首先,通过全局平均池化(Global pooling)实现二维张量的压缩整合;其次,使用2个含激活函数且无偏置的FC层实现不同卷积通道特征重要性权重学习,r为控制FC层通道数的超参数;最后,将学习的权值与原特征映射进行逐通道的自适应加权,实现卷积特征通道权重重分配。
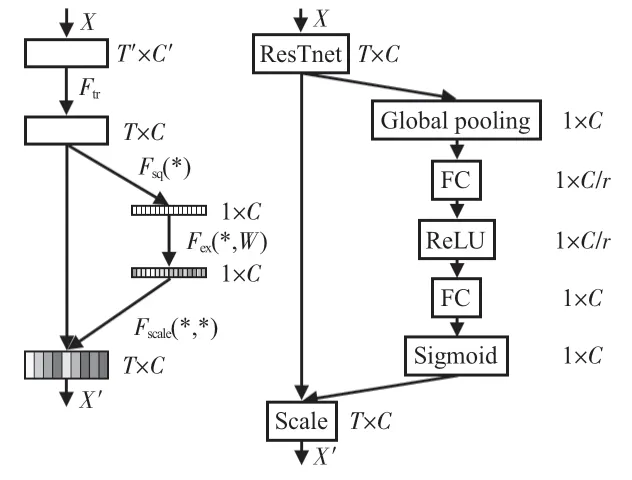
图4 嵌入SE模块的ResTnet结构(左)和SE模块内部结构(右)
2 实验平台与方案
2.1 实验平台
本文使用实验室现有设备搭建感兴趣检测实验平台,主要使用Tobii Eye Tracker 4C眼动仪、戴尔台式计算机和戴尔1 920 ×1 080 LCD 显示器等硬件设备,图5 为本文的实验现场。视觉刺激程序和分类算法在Spyder 编译器下通过Python编程实现,所有深层网络模型均通过调用开源深度学习框架Keras实现,交叉验证、模型评估和浅层模型通过调用开源机器学习框架Scikit-learn实现。

图5 实验现场
本文实验所使用的图像是从图像公开数据集RSOD[13]、UCAS_AOD 中筛选出的,共包含198 张实验图像,图像中1 ~3架飞机作为待搜索对象,为了缓解被试疲劳,单个被试实验分为4 组。本文使用自由搜索视觉(free view)刺激范式采集被试搜索飞机目标过程中的眼动信号,实验流程如图6所示。实验前先校正眼动仪,并显示提示语,1 s后开始实验;然后,被试者自由搜索图片中的飞机目标,眼动仪记录搜索过程中的眼动信号,搜索完显示1 s灰色背景;最后,每搜索10 张图片休息1 min,直到完成一组实验,休息5 min后进行下一组实验。

图6 自由搜索视觉刺激范式流程
按照此实验范式,本文共采集8 位健康被试者的眼动数据,其中包括2名女性,6 名男性,年龄范围在23 ~26 岁之间。所有被试者实验前精神状态良好,均熟悉了自由搜索视觉刺激实验流程。
2.2 实验方案
本文感兴趣检测实验的具体方案为,首先,采用自适应阈值算法从自由搜索视觉范式采集的眼动数据中提取注视序列,所有被试共提取到4 300 个有效的待检测注视序列;其次,采用本文提出的基于特征通道权重重分配多尺度残差网络对注视序列分类实现感兴趣检测,主要目的是对眼动数据中由“飞机”目标(target)诱发的注视序列与其他非目标(nontarget)注视序列进行分类。设计对比验证实验,将基于传统浅层机器学习模型的方法支持向量机(support vector machine,SVM)和K 近邻(K-nearest neighbor,KNN),以及文献[5,6]提出的基于深层模型方法InceptionTime、ConvLSTM为基线(baseline),模型的特征、参数设置参考原文中的设置,在注视序列分类实验中与本文所提方法的结果进行对比。网络训练采用Adam优化器和交叉熵损失函数,在对模型分类结果进行评估时,使用准确率(accuracy)作为评价指标。
3 实验结果与分析
3.1 网络模型超参数选择
本文对Res_Fix 中降维超参数r(图4)的数值选取进行调试,结果如表1所示。可知,降维超参数使FC 层有不同的神经元,对分类结果和参数量略有影响,当r=4 时新增训练参数量较少且分类准确率较高。因此,以下实验中Res_Fix降维超参数均设置为4。

表1 Res_Fix中超参数r调试结果
3.2 注视序列分类结果分析
本文使用共计5种方法对注视序列数据进行了分类实验,实验结果如图7 所示。为了比较各方法间是否具有显著性差异(统计显著性阈值选取为0.05),首先对所有方法的分类结果进行单因素方差检验,然后对各方法进行多重比较检验。实验结果表明,相比于KNN、SVM、文献[5,6]中深层模型,本文提出的Res_Fix 模型在注视序列分类上取得最优结果。本文提出多尺度残差网络的分类准确率和标准差达到0.960 5 ±0.005 1,一方面,说明本文提出的多尺度残差网络充分提取了注视序列特征、SE模块能合理分配各卷积通道的权重;另一方面,深层模型分类结果的标准层较低,说明其对被试者的个体差异性具有更好的鲁棒性。才会在注视序列分类任务上具有较好的准确率和鲁棒性。

图7 各方法注视序列分类结果
统计显著性检验结果表明,本文各方法的分类结果单因素方差检验中,P值远小于0.01,因此各方法分类结果之间存在统计显著性差异。首先,文献[5,6]以及本文的基于深层模型的方法(ConvLSTM,InceptionTime,Res_Fix)相比于基于浅层模型的方法(SVM、KNN)在注视序列分类任务上存在显著性差异。本文提出模型与现有注视序列分类方法均存在显著性差异,说明基于特征通道权重重分配多尺度残差网络能够自动的学习注视序列中的特征信息并对其进行分类,该模型通过提取多尺度特征和特征通道权重重分配提高了刻意注视序列的预测准确率。
4 结 论
为解决机器视觉中难例样本标注问题,本文引入视线追踪技术,通过检测目标诱发的感兴趣注视序列来实现难例样本标注。该方案创新性在于,采用自适应阈值算法提取出注视序列;使用多尺度残差网络模型提取注视序列不同尺度特征、为不同卷积通道分配权重。对比实验结果表明,本文提出的基于特征通道权重重分配多尺度残差网络的感兴趣检测方法,在注视序列分类准确率和鲁棒性上优于对比模型,达到了96%的检测准确率且提升效果具有统计差异。
本文研究的基于眼动信号的感兴趣检测方法可准确分类注视序列,方便在难例样本标注应用中使用。在未来工作中,将考虑融合多种自主神经信号(如脑电信号)实现感兴趣检测,进一步提升感兴趣检测的精度和鲁棒性。
