基于轻量化YOLOv5的新型菜品识别网络
2024-03-21张成涵宇林钰哲谭程珂王俊帆顾烨婷董哲康高明煜
张成涵宇,林钰哲,谭程珂,王俊帆,2,顾烨婷,2,董哲康,2,高明煜,2*
(1.杭州电子科技大学 电子信息学院,杭州 310018;2.浙江省装备电子研究重点实验室(杭州电子科技大学),杭州 310018)
0 引言
随着人工智能等新技术与餐饮行业的结合日益紧密,餐饮行业也逐渐朝着数字化、智能化方向迭代升级[1],其中智能餐饮系统、餐饮机器人等都是餐饮行业数字化、智能化转型的重要产物。同时,由于餐饮企业的“用工荒”、招人难、人力成本高等问题难以解决,对餐饮企业的服务质量产生了较大的影响,一系列智能产品的诞生能替代部分餐厅服务人员的工作,减少劳动力成本;且为了更好地适应餐饮行业的无人化及智能化需求,加快推进餐饮行业智能化发展刻不容缓。同时,随着人工智能领域的发展,神经网络在菜品识别领域上的应用也越来越广泛。为了更好地完成实际菜品识别的功能,近年研究得到的菜品识别模型准确率正不断提高,并且为了更好地将菜品识别模型应用于实际场景中,也出现了一系列减小模型尺寸、提高识别速度的研究,为本文进一步推动菜品识别模型轻量化的实际应用奠定了基础。
刘丽芳急于将这一结果告诉丈夫彭伟民,一遍接一遍地拨打他的手机号码。彭伟民始终不接。无奈之下的刘丽芳只能给他编发了一条短信。
Kawano 等[2]通过结合传统机器学习的HOG(Histogram of Oriented Gradient)算法以及卷积神经网络(Convolutional Neural Network,CNN)提取菜品图片的图像特征,在其自主创建的日式菜品数据集UEC-Food100 中top-1 准确率达到72.26%。苏国炀[3]提出了一种基于双线性结构的双流卷积神经网络,通过结合全局中餐菜品图像以及局部中餐菜品图像分别提取图像的全局特征和局部特征识别菜品,在ChineseFoodNet 数据集上达到了81.14%的准确率。边竞等[4]提出基于Inception-V3 模型的中餐菜品标签分类模型,对VIDEO Food-172 数据集进行标签分类,完成了中餐菜品名称及成分的识别工作,其中菜品名称准确率为80.85%,菜品原料识别率为56.26%。王晓朋[5]分别使用基于目标边界框再定位、结合多感受野注意力与特征通道加权等方式研究如何有效提高菜品识别准确率,在自主创建的35 种中餐菜品数据集中最高可达85.28%的准确率。吴正东[6]提出了基于注意力机制的双线性网络,并创新性地将注意力机制、通道注意力机制以及混合注意力机制分别作为双线性网络的两路分支在VIREO Food-172 菜品数据集上进行菜品识别,最高可以达到84.51%的准确率。何志洋[7]以ResNet-50 作为Backbone 搭建神经网络,通过加入可变形卷积和CBAM 注意力机制模块等,在自主创建的菜品数据集上可以达到91.85%的top-1 准确率。综合上述研究成果,应用一系列机器学习以及深度学习的方法可以有效提高模型的菜品识别准确率,但同时也会导致模型结构愈发复杂,深度不断增加,从而降低模型的识别速度,难以应用在实际的硬件设备中。
朱瑶[8]设计了改进的YOLOv3-ShuffNet 完成菜品检测,再使用ResNet-50 在Linux 系统一体机上实现对菜品的识别分类,其中菜品检测模型大小为191 MB。朱凌云[9]利用Transformer 模型进行少样本情况下的菜品识别,在少样本的Food-270 数据集上准确率为77%,检测精度和检测速度相较类差异性对比学习有明显提高。姚华莹等[10]设计了一种轻量型卷积神经网络MobileNetV2-pro 实现菜品的识别分类工作,通过引入通道混洗、注意力机制提高网络的检测能力的同时利用随机擦除等图像预处理技术处理菜品图像,提高系统的泛化能力。在FOOD-101 数据集上可以达到76.82%的准确率,且模型大小仅为6.98 MB。邓志良等[11]提出了一种基于改进残差网络的菜品识别模型RNA-TL(ResNet with Attention and Triplet Loss),通过使用多尺度特征以及注意力机制提取图像深层的信息特征,并使用了三元组损失和支持向量机(Support Vector Machine,SVM)进行分类操作,能在FOOD-208 和FOOD-292 数据集上分别达到83.62% 和90.32%的准确率,且训练时间相较于同等大小的网络模型也更少。上述研究通过改进模型结构有效提升了识别速度,但同时也导致菜品识别准确率有了一定的下滑,依旧难以满足实际的需求。因此在保证模型原有的识别精度的基础上尽可能提高模型的识别速度,减小模型尺寸,使它可以流畅应用在实际的硬件设备中成为本文亟待解决的问题。
基于以上文献以及实际的研究,本文提出了一系列的创新。针对文献[2-7]中网络识别准确率较高,但存在结构复杂、冗余参数较多、识别速度较慢等问题,本文在保持模型原有识别准确率的基础上对其进行轻量化,提高了识别速度;针对文献[8-11]中网络无法兼具识别准确性与实时性,对硬件设备算力要求较高、难以实际应用等问题,本文基于Qt 软件将它移植至嵌入式开发板内并进行优化,降低成本使它可以有效应用于实际餐饮场景中。
今年9月,石屏县脱贫出列,成为全省15个脱贫摘帽的贫困县之一。为积极响应乡村振兴计划,今年上海方面给予援滇项目资金410.5万元,用于龙武镇龙武村功能提升项目及法乌村产业振兴综合项目,项目建成之后,将促进两个村在办公服务、建设多功能阵地、强化产业发展方面的条件得到较好改善。此外,省投资促进局积极开展教育帮扶,借助上海市资金、平台条件,加强本地招商引资干部走出去培训,与上海知名学府建立长期的干部培训合作关系,举办招商引资专题培训班,进一步开阔干部视野,创新工作思路,学习发达地区招商引资工作经验,更好地服务于本职工作。
1 智能出餐系统搭建
为验证新型菜品识别网络的轻量性与实用性,本文将它移植至开发板内后,与机械臂等硬件设备相结合,构建了智能出餐系统,初步实现落地应用。该系统主要由三大子系统组成,分别为云端服务器系统、主控系统、从控系统,具体如图1 所示。

图1 智能出餐系统构建方案Fig.1 Construction scheme of intelligent service system
云端服务器系统采用基于微信公众号平台的WebApp应用方案实现用户在移动端上的点餐工作,在阿里云服务器中设计并搭载数据库和相关前后端界面,实现用户的点餐功能以及餐厅管理人员对系统的控制维护。主控系统以瑞萨核心开发板RZ/G2L 作为核心。根据订单信息,通过摄像头以及部署在开发板上的新型菜品识别模型识别传入的菜品视频流,完成识别后会将菜品结果以及坐标信息传输至从控系统,实现上位控制。从控系统使用固定在机械臂头部的勺子作为打菜工具,通过上位机总线信号改变舵机的路线坐标,完成不同的打菜动作,完成后便会向后台发送命令,结束订单。主控系统与云端服务器系统通过cURL(commandline Uniform Resource Locator)进行网络通信,主控系统与从控系统之间则通过GPIO(General Purpose Input Output)按照自定义协议进行通信,实现信息的交互。
土墙日光温室在降雨后,特别是强降水过程时,常常形成温室前后积水,主要原因是温室墙体筑造时土方工程量大,如就近取土,畦面下沉幅度小,不异地取土就会造成温室就边取土,形成低洼,如没有良好的排水渠道,雨水易汇集到温室前后低洼处,倒灌进入温室,或长期浸泡墙体,对温室造成危害。
本文的主要贡献在于依据实际餐厅出餐需求,即检测时要在保证识别精度的前提下尽可能提高识别速率,基于YOLOv5 提出了一种新型的菜品识别模型。首先为了提高模型的识别精度,本文对原网络结构进行了改进,通过对浅层特征图与深层特征图的拼接,丰富网络对图像的特征表示,提高图像特征检测的精度,增强特征提取能力。其次通过强化网络对特征图的采样能力,扩大感受野范围,提高特征图分辨率以及菜品识别的精确度。之后为提高模型实际菜品识别的速度,本文还对YOLOv5 模型进行了轻量化处理,减小了模型尺寸,减少了参数量,有效提高了模型的识别速度,从而能够满足菜品识别的时效性需求,并降低后续对嵌入式开发板性能的损耗,使识别程序能够长时间地流畅运行。
2 新型菜品识别网络搭建与移植
本文为了保证实际中餐菜品识别的高准确率[12-14],最终决定选用YOLOv5 模型为基本框架完成菜品识别的工作。但由于YOLOv5 模型本身参数量较多,实际进行菜品识别时会出现嵌入式开发板运算量大、识别速度慢的问题。因此,本文在原模型的基础上进行一系列轻量化操作[15-16],包括模型剪枝以及模型量化,在保证原有高准确率的同时,提高模型的识别速度并减小模型整体的尺寸,从而使它在移植到嵌入式开发板后,可以较为流畅地进行使用。
2.1 模型剪枝
由于神经网络模型从卷积层到全连接层存在大量冗余参数,这些神经元在实际模型运行过程中对结果影响较小,但却极大地降低了模型的运行速率。为了更好地提高菜品识别模型实际的识别速度,本文使用模型剪枝技术筛除网络中这类影响较小的神经元。
针对新型菜品识别网络,本文使用结构化剪枝中的通道剪枝实现速度的优化,它的核心思想是去除模型结构中影响较小的通道以减少整体的运算量。在Wen 等[17]的研究中可知,如果深度神经网络(Deep Neural Network,DNN)中卷积层的权值形成了一个四维张量其中Nl、Cl、Ml、Kl为第l个权重张量中的卷积核数、通道数、高和宽。实现DNN 结构稀疏化规范的公式如下:
其中:W代表的是DNN 中的权值矩阵,ED(W)表示数据上的损失;R(·)表示每个权值的非结构化正则化项;R(g·)表示应用于每一层的结构化稀疏项。
由于模型网络的宽度决定了输出维度,即特征的丰富程度,仅选择少量维度进行修剪,会限制模型的压缩率和精度。故在此研究的基础上,为了保证菜品识别的精度,本文在实际模型剪枝时将维度选择拓展到了4 个维度,包括filter、channels、filter shapes 和depth 进行剪枝,而对这四个维度剪枝率的分配,本文则通过将模型精度与各维维数之间的关系化为一个多项式问题[18]进行求解,即
但由于批归一化(Batch Normalization,BN)层中的缩放因子γ与卷积层中的每个通道都有所关联,本文在对菜品识别模型剪枝前还需进行稀疏训练,自动识别出对最终结果影响较小的通道,同时修剪缩放因子值较小的通道,从而获得相对更紧凑的模型。这些剪枝后的模型相较于原网络结构会变得更窄,在模型大小、内存和计算上也会变得更加紧凑。虽然修剪后可能会降低部分性能,但这些可以通过微调进行一定的补偿,从而能基本达到与未经过剪枝的网络相当的识别精度[19]。具体公式如下所示:
本文通过随机梯度下降法学习Supermask[21]。针对每一个要剪枝的权值矩阵W,都将创建一个与W形状相同的门控矩阵G。G将决定哪个参数ω∈W将参与正向执行与反向传播,上标(·)b则表示门控矩阵G的一个二进制变量。对于一个R层的网络,将有两个参数:门控参数Φ={G1:R}和网络参数θ={W1:R,B1:R},通过对两个参数内的元素逐个相乘,可以计算得到权值参量W':
同时,主要为了解决各级党的机构和人员编制快速膨胀、各级领导班子人员过多、年龄老化的问题,党中央部门机构也进行了改革,党中央30个直属机构的内设局级机构减少了11%,处级机构减少了10%,总编制减少17.3%,各部门领导职数减少15.7%。
其中:Γ(f,c,fs,d;Θ)代表模型精度预测器(Model Accuracy Predictor,MAP)的求解函数;f、c、fs和d分别代表预测得到的filter、channels、filter shapes 和depth 这4 个维度对模型精度的影响量化值;Θ代表MAP 的参数;θijkl为Θ内与上述4 个维度相关的参数。依据求解得到的结果判断4 个维度对模型精度的影响比例,从而得到对4 个维度剪枝率的分配结果,并以此对这4 个维度分别进行剪枝。
4.进一步放大我省水稻水产“两水”资源优势,大力发展稻渔综合种养,全省大面积推广“双水双绿”技术规范,利用国家财政政策性支持资金大面积改造适宜稻田,鼓励农业龙头企业流转抛荒的稻田,大面积示范“双水双绿”技术,建立公司+农户的农业合作社模式,打造绿色水稻、绿色水产的新模式。
实际的代码运行环境均为Anaconda 所创建虚拟环境,使用pytorch1.7.1 以及python3.7 进行代码的编写,并使用cuda11.7 来加速模型的训练。云端服务器通过Tomcat、MySQL 以及Redis 部署智能出餐系统的前后台界面以及实际菜品的数据库;PC 端运行使用Inter Core i7-10875H(2.3 GHz)CPU 以及NVIDIA GeForce RTX 2060 进行模型训练,并最终将得到的模型移植进入瑞萨RZ/G2L 开发板内进行系统的搭建与测试。
Joan Rubin认为“学习策略是语言学习者用以获取知识的技术或手段。”[14]她指出,有意识地采用学习策略的学习者能够帮助自己习得第二语言。按照她的研究,优秀语言学习者具备的条件之一就是要在犯错中提高自己的语言纠错意识,不断调整自己的学习策略。
其中:zin和zout分别为BN 层的输入和输出;В 指代现在的minibatch;μB和σB为输入激活的平均值和标准差值;γ和β是可训练的仿射转换参数,这样的改变提供了将归一化激活线性转换回任何尺度的可能性,同时没有给网络带来额外损耗。
实际训练时首先对菜品识别模型中BN 层的γ施加L1 正则约束,使模型可以朝着结构性稀疏的方向调整参数。此时BN 层的γ的作用类似于信息流通道的开关系数,它可以控制信息流通道的开关闭合。在完成稀疏训练或者正则化后,便按照既定的剪枝率δ对模型进行剪枝操作,从而能够生成低存储占用的精简模型,并大幅提升菜品识别速率。为避免剪枝过量导致识别准确率有较大损失,本文将剪枝率δ设为0.8,确保有20%的通道将被保留,再对模型整体结构进行微调后进行训练即可完成整体的模型剪枝。
但以这种剪枝方法得到的菜品识别模型准确率相较于原模型仍有一定的下降。为了进一步提高新型菜品识别网络的准确率,本文在原剪枝方法的基础上引入了一种改进型的Supermask 剪枝方式,使剪枝后得到的菜品识别网络可以更符合实际嵌入式设备的应用需求。
Supermask 是一种新型的剪枝网络训练方法,Zhou 等[20]发现通过迭代进行剪枝循环产生的模型中,如果将网络模型权重随机初始化后作为原始模型的初始权重,则网络模型识别准确率可以得到比使用剪枝率随机剪枝后的模型更好的结果,甚至可以达到与原始网络相当的准确率。这是通过对网络权重应用一组精心选择的Supermask 实现的。
完善校内师生创新、创业激励机制 依照国家、省、市关于科研院所等事业单位人员离职创业的文件,建立健全教师创业、创新的配套政策[7],支持有能力的教师走出去创办企业,在企业稳定后回馈学生实践和一线教学,实现个人与学校互惠互利;依托职教集团搭设学生创新创业平台,立足行业一线有前景的项目,从调研论证、小额金融服务、办公场地、用水用电、手续审批等各方面帮扶学生创新创业,实现从校内教学育人到职场育人的转变。
对filter 维度剪枝的优化目标是去掉模型结构中对识别结果影响较小的filter;对channel 维度剪枝的优化目标是去掉模型结构中对识别结果影响较小的channel;对shape 维度剪枝的优化目标是通过读取filter 中所有空间位置的对应权值所构成的向量集合后,去除其中部分的向量调整filter 的形状,使它可以在更好地提取菜品图片特征的同时减少网络的计算成本;对depth 维度剪枝的优化目标是去掉模型结构中对识别结果不重要的网络层,转而使用shortcut 传递特征数据。其中filter 和channel 维度的剪枝主要减小了网络的宽度,filter shape 维度的剪枝主要优化了网络内filter 的形状,depth 维度的剪枝主要减小了网络的深度。再通过对4 个维度向量中跨cl个通道的2D 滤波器空间位置(ml,kl)中所有权值向量进行处理,减小模型的计算成本,提高识别速度,最终达到整个网络的优化目标:
但实际上,通过Supermask 进行对菜品识别模型的剪枝较为复杂。为了在保证剪枝效果的前提下简化剪枝的步骤,本文利用L1正则约束后的Gamma系数作为稀疏损失,施加一个向下的压力,让门控变量Φ变化到指定的稀疏度等级,在训练结束时,使大多数对结果不重要的权重的门控参数大小会小于零。这些负值的门控参数在理想情况下代表最不重要的权重,可以在不产生性能影响的情况下被删除,从而在训练后得到菜品识别准确率与原模型基本一致的剪枝后模型。
2.2 模型量化
由于YOLOv5 原模型网络深度较深,若将它直接移植到嵌入式开发板上使用时会占据较大的使用内存以及计算资源。因此本文进行了Int8 量化,主要通过存储以及计算两个方面进行量化,使它可以使用更少的bit 数完成原先需要浮点数存储的tensor 以及计算工作,使训练后的菜品识别模型中32 位的单精度浮点型参数转为8 位的整型参数,从而减小模型体积,提高运算速度。
本文训练菜品识别模型时使用静态量化来实现模型尺寸的压缩[22-24]。通过少量无标签校准数据,采用KL(Kullback-Leibler)散度等方法计算量化比例因子。在进行静态量化前还需对缩放因子进行校准,对初步量化后的模型进行部分输入预测结果,使模型的缩放因子根据输入数据的分布进行一定的调整,直至fine-tuning 完成。
实际对模型量化的操作一般可以用式(7)表示:
在实际对菜品识别模型进行静态量化操作时,通过PyTorch 内置的函数将模型结构中的部分网络层进行了融合,如Conv 层与BN 层进行融合、Conv 层与线性整流函数(Rectified Linear Unit,ReLU)层进行融合等减少模型使用的参数。同时在每个支持量化的模块中加入两个观测器,分别用于监测Activation 与Weight,从而能够在几次迭代后对数据进行统计分析得到scale以及zero_point两个参数,对模型进行Int8 量化。之后还需将准备好的校验数据输入到模型进行训练以获得模型权重的量化参数信息并对它进行一定的调整,进行模型结构的转换,即可得到Int8 量化后的模型。
具体将fp32 类型模型量化为Int8 类型模型伪代码如下所示:
伪代码内部的qconfig 用于定义量化时的配置方式;fuse_modules 用于融合代码内部的部分层,使融合后得到的模型能够在完成基本运算的同时,减少所需要经过的层数,从而减少运算量;prepare 用于对每个需要量化的层插入观测器,并最后通过convert 进行转化得到最终量化后的模型。
经过对原YOLOv5 模型的模型轻量化(包括剪枝以及量化)后,实际使用的模型大小从原来的28.501 MB 减小到了6.192 MB,共减小了78%,其能够更好地部署在嵌入式开发板中,且识别速度得到了有效提高,实现了轻量化的需求。本文最终得到的改进型YOLOv5 模型架构如图2 所示。
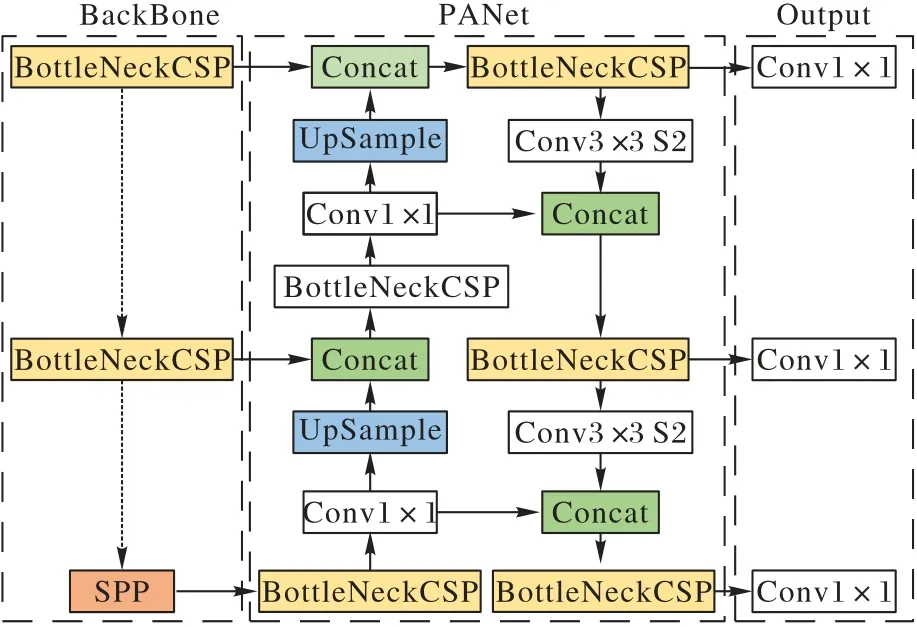
图2 优化后YOLOv5模型架构Fig.2 Architecture optimized YOLOv5 model
由于本文针对YOLOv5 模型的优化方法包括模型剪枝与模型量化等主要着重于对整体模型结构的处理,通过去除模型内冗余的参数和连接等方式,旨在减少模型的存储与计算成本以提高模型的识别速度,但这将不可避免地导致识别精度的下降。为了保证新型菜品识别网络的高精度,本文还调整原YOLOv5 模型卷积层数、卷积核大小和部分超参数等,使本文提出的新型菜品识别网络相较于原有的YOLOv5模型在准确率与识别速度上达到了一个较好的权衡,同时计算成本的减少使它在硬件设备中也能够较为流畅地完成菜品识别的工作。
2.3 模型移植
由于目前的嵌入式开发板并未完全普及与支持神经网络模型的直接部署与应用,仅有一些高端的边缘计算设备如Jetson Nano 等可以对它进行有效的支持并实现一定的硬件加速功能,因此还需要对模型代码进行一系列调整才能将它移植到开发板上实现菜品识别功能。
实际通过在开发板普遍支持的Qt 软件上对代码进行一定的改写,以OpenCV 为核心代码框架实现YOLOv5 的菜品识别。之后再运用Oracle VM Virtual Box 虚拟机在瑞萨RZ/G2L 开发板系统内进行配置,并调用aarch64-poky-linux交叉编译链在开发板系统上搭建编译Qt 代码所需的运行环境,完成OpenCV 以及一系列Qt 所需要动态库的编译工作,再通过ARM 架构的qmake 工具对Qt 代码进行相关库的链接和编译,从而调用需要的库文件。最后仅需在Qt 代码中输入YOLOv5 的模型权重,并在虚拟机中对它进行交叉编译,生成可执行文件后安装至开发板内,即可在开发板上利用Qt软件实现对菜品的识别操作。
运用Origin(Origin Pro 2016)软件绘图,运用SPSS(IBM SPSS Statiatics 20)软件进行显著性检验(单因素方差分析-LSD,P<0.05)。
3 综合实验结果与分析
本文针对新型菜品识别网络的研究实验数据集来自自主创建的真实菜品数据集和模拟菜品数据集。真实菜品数据集包含85 种真实菜品的目标对象,具体信息采集来源于3个月的实际食堂餐厅拍摄,共计12 361 张食堂菜品图片。其中选用8 652 张作为训练集,2 472 张作为验证集,1 237 张作为测试集;模拟菜品数据集则包含4 种模拟菜品,包括花生、瓜子、糖以及绿豆,共计408 张模拟菜品图片。其中选用316张作为训练集,56 张作为验证集,36 张作为测试集。真实菜品数据集用于验证模型的泛用性,证明本文所提出的新型菜品识别网络可以识别真实餐厅内的多样菜并进行实际应用;而模拟菜品数据集则用于测试整体的出餐流程,减轻开发板的运行负担。
其中:(x,y)表示训练的输入以及目标;Wt表示可训练的权值;g(·)是训练时对尺度因子的稀疏度惩罚;λ是对式子两项的平衡处理;第一项表示的是神经网络正常训练时产生的损失。本套系统中采用g(γ)=|γ|作为实际的算式实现YOLOv5 网络的稀疏化处理,使其稀疏性能够更强。在此基础上,针对整个BN 层的输入输出则发生了一定的改变:
文稿中计量单位一律使用国家法定计量单位,所有计量单位符号均为正体,用标准符号表示,如“m”“m2”“t”等。各种专业术语按国家标准使用,同一名词术语、计量单位、人名、地名等要求全文统一。变量采用斜体,但数字采用正体。
·算术中包含丰富的逻辑推理,对于培养学生的分析与创造思维能力极其有益;对其智力发育起着不可替代的作用.
实际测试中本文选用了RetinaNet[25]、FasterRCNN[26]、YOLOv3[27]、YOLOv5、YOLOv5-Lite、YOLOv6[28]、NanoDet-Plus作为对比模型,以验证本模型设计的合理性;同时为保证模型测试的有效性,采用了统一的模型训练标准。上述5 种模型所使用的初始学习率均为0.005,所使用的优化器均为Adam 算法,最大迭代次数均为300。
(5)发展村级集体经济,提升村干部在群众中的影响力。将国家帮扶项目、上级帮扶资金等事宜的办理由村干部出面办理,坚持好事让村党总支做,好人让村干部当;积极引导村干部解放思想、更新观念、加强学习、提高本领,鼓励村干部带头发展致富项目,为农民群众做出榜样。县里可根据自治区相关文件精神,结合本地实际,制定有关优惠政策,鼓励村干部和优秀农村青年创办种植合作社、养殖合作社、专业协会、地毯加工、手工刺绣工厂等,利用住村工作组的帮扶优势,发展村级集体经济,解决村级集体收入渠道匮乏,村干部服务手段弱化,无钱办事的问题,增强村级班子的凝聚力、吸引力、号召力,提高在群众中的威信。
3.1 评估指标
1)准确率测试。
本文主要使用平均精度均值(mean Average Precision,mAP)对不同的模型进行评估,根据交并比(Intersection over Union,IoU)值的不同,即目标检测中真实框与预测框的重叠度不同,可以分为mAP@0.5 和mAP@0.5:0.95 评估模型的性能,其中mAP@0.5 指代当IoU 值为0.5 时每一个类别下计算所有图片得到的mAP 值;mAP@0.5:0.95 指代在不同IoU阈值(0.5~0.95,步长0.05)上得到的mAP 值
