基于多尺度卷积和自注意力特征融合的多模态情感识别方法
2024-03-21蔡从虎袁晓辉罗蓓蓓
陈 田,蔡从虎,袁晓辉,罗蓓蓓
(1.合肥工业大学 计算机与信息学院,合肥 230009;2.智能互联系统安徽省实验室,合肥 230009;3.情感计算与先进智能机器安徽省重点实验室,合肥 230009;4.北德克萨斯大学 计算机科学与工程系,丹顿 76207)
0 引言
情感对人类生活生产有巨大意义,随着情感计算技术的不断发展,使用情感计算辅助计算机理解和表达人类情感成为潜在需求[1]。人的生理信号是人在面对不同外部环境时产生的电信号,主要包括脑电(ElectroEncephaloGram,EEG)信号、心电(ElectroCardioGram,ECG)信号、眼动信号等。一方面,这些信号源自生理反应,无法被个体主观掩饰,具有客观性[2];另一方面,生理信号与情感的产生和表达具有相关性,数据包含大量情感相关信息,也易于采集,因此,基于生理信号的情感识别方法具有很大的研究价值和广泛的应用场景[3-4]。
脑电、心电和眼动等生理信号本身呈现非平稳随机信号的特点,普通的时频域分析能得到的信息量较少,识别结果也存在准确率低、跨个体泛化能力弱的问题。近年来,许多研究使用深度学习方法学习生理信号特征,以增强提升情感识别能力[5-6]。然而,以卷积为代表的深度学习方法存在参数量大、训练成本高的问题,导致方法的实用性低。不同生理信号在个体之间的特征和变化规律存在差异,因此Chen等[7]提出结合多种生理信号进行多模态生理信号的情感识别,以提高跨个体的情感识别能力。基于决策层融合的多模态方法需要构建多个分类器,对不同的信号分别进行处理,这进一步加大了参数规模。使用统一模型进行数据训练和情感分类的特征层融合的方法有利于减小参数规模;然而多模态特征在融合时可能相互干扰,影响识别效果[8],因此需要进一步地研究有效的特征融合方法。
本文提出一种基于EEG、ECG 和眼动信号的特征层融合的多模态情感识别方法。首先通过适用于生理信号的1D-Inception(One-Dimensional-Inception)多尺度深度学习结构对EEG、ECG 和眼动信号进行特征学习。1D-Inception 通过设置多尺度卷积核降低卷积参数规模,在有限的卷积层内提取更高维度的情感相关特征。不仅如此,本文还通过自注意力(Self-Attention)机制将不同生理信号所提取的特征在特征层融合。本文所做的主要工作如下:
1)使用1D-Inception 结构对生理信号进行特征学习。相较于传统卷积神经网络(Convolutional Neural Network,CNN),该结构更适合生理信号的特征学习。1D 卷积保证了不同生理信号单独进行特征提取,排除其他模态的干扰。
2)使用自注意力和双向长短期记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)网络对各生理信号的特征进行融合和分类。前者用于多模态特征融合,后者则通过时序特征学习对情感进行预测。
1 相关工作
EEG、ECG 和眼动信号都具有非稳态特点,并不具有特定的波形模式。有研究使用时频域和统计学特征提取特征。Chen 等[9]使用了EEG 的Lempel-Ziv 复杂性和小波细节因子特征组成综合特征进行情感识别;Katsigiannis 等[8]使用ECG中的波形统计特征,结合心率变异度(Heart Rate Variability,HRV)和功率谱密度(Power Spectral Density,PSD)等特征检测情感。对于眼动信号,陈田等[10]使用眼球上下运动模式的波形相关性系数和作为特征,取得了一定的识别效果。
生理信号在个体间存在差异,传统的时频域和统计学特征的固定计算方法难以体现差异,通常存在识别率低、跨个体分类的泛化能力弱的问题[11]。随着深度学习的发展,基于CNN 的特征学习方法成为研究热点。CNN 通过堆叠网络和调整参数自动学习特征表示,在面对不同个体差异时分类更具有可泛化性。Singson 等[12]使用ResNet 架构的CNN 对实验采集的ECG 数据进行特征学习和情感识别,取得了68.42%的识别准确率。Chen 等[13]将EEG 原始数据和PSD特征组合,并使用CNN 进行分类,在DEAP 数据集[14]上取得了85.57%的准确率。然而,传统CNN 为了学习高维度特征需要累加多层网络,导致方法参数量大、训练成本高、可实用性低。
Inception[15]是一种更高效的卷积结构。传统卷积只考虑固定范围内的数据,单层视野域有限,因此需要多层卷积叠加提升视野域范围。而Inception 设置多个尺度的卷积核,使卷积过程中具备更多的视野域,既能考虑大范围整体数据,又能考虑小范围的局部数据。相较于传统卷积,Inception 单层卷积就能获得信息量更丰富的特征,具有更强的特征学习能力和更低的参数代价。文献[16-17]中分别使用2 维和3 维的卷积核搭建Inception 结构,用于EEG 的运动想象识别,取得了良好的识别效果,证明了Inception 结构能有效学习生理信号特征。在多模态信号中采用多维卷积核会导致不同生理信号在卷积中相互干扰,因此,本文拟采取1D-Inception 的结构进行特征学习,既保留Inception 的优势,同时1 维卷积核又可以保证不同通道的信号之间彼此隔绝,避免信号互相干扰而导致特征的可识别性下降。
基于生理信号的情感识别通常受噪声、个体差异的影响,而生理信号的多模态融合方法则可以让各种生理信号达成信息互补,提高方法的识别效果。Kwon 等[18]融合EEG 和皮肤电反应(Galvanic Skin Response,GSR)信号,在DEAP 数据集上取得了73.4%的情感识别率。Chen 等[7]将实验采集的EEG 和ECG 数据分别使用支持向量机(Support Vector Machines,SVM)和长短期记忆(Long Short-Term Memory,LSTM)网络进行分类,最终在决策层融合,取得了85.38%的准确率。然而决策层融合需要训练多个分类器,会极大增加参数规模而降低实用性。在特征层融合的方法中,由于不同模态的异质性,进行简单的特征连接会造成模态相互干扰。Katsigiannis 等[8]分别使用EEG 的PSD 特征和ECG 的HRV 等特征在DREAMER 数据集[8]上训练分类器,结果表明特征层融合的多模态方法相较于单模态性能提升有限,一些情况下甚至逊于单模态。对于不同模态的特征融合,使用自注意力机制可能是一种有效的方法。自注意力通过学习特征之间的相关性,将相关性高的特征赋予高权重,低的则相反。因而每个模态的特征在融合后充分考虑了它与其他模态的相关性,能得到模态间干扰程度低、信息量丰富的融合特征。Chen 等[19]使用自注意力对EEG 多个通道特征进行学习融合,在DEAP 数据集的情感识别任务上取得了93.72%的准确率,证明了自注意力特征融合方法的有效性。
2 本文方法
本文基于EEG、ECG 和眼动信号,使用1D-Inception 特征学习模块、自注意力模块和Bi-LSTM 网络组成骨干网络,对三种生理信号进行特征提取和融合,最终使用全连接层输出预测概率。多模态情感识别方法的模型结构如图1 所示,主要由4 个模块构成。其中,频带注意力学习模块对EEG 多个频带的数据进行处理,1D-Inception 特征学习模块用于各种生理信号的特征学习,自注意力模块学习不同生理信号的各个特征之间的相互关系并为这些特征添加权重,最后使用Bi-LSTM 网络提取时序信息,并通过全连接层(Fully Connection layer,FC)完成分类。

图1 多模态情感识别方法的模型结构Fig.1 Model architecture of multimodal emotion recognition method
2.1 频带注意力学习模块
EEG 不同于其他生理信号,它的频率范围被认为和情感高度相关[20],EEG 不同频带对应的大脑活动如表1 所示(δ 频段由于频率过低,能采集的数据较少,因此不考虑采用)。不同频带的EEG 信号对应不同的大脑活动,因此有必要对EEG 信号分频;然而,高频率的EEG 频带并不包含所有的情感信息,一些情感对应的大脑活动并不是很激烈,因此只考虑单频带的EEG 也不妥。为了解决这个问题,本文提出对EEG 的频带数据使用注意力机制的方法。

表1 EEG不同频带对应的大脑活动Tab.1 Brain activities corresponding to different frequency bands of EEG
注意力机制是一种为数据加权的自适应方法,通过学习数据之间的关系来分配权重。注意力机制使得与情感高度相关的频带特征被强化,无关数据则被抑制。传统人工赋予权值的方法无法考虑个体信号差异,导致方法跨个体分类性能不佳[9]。本文采用的自适应的注意力机制可以综合考虑数据,根据不同个体的特征重要程度给出不同的权重配置。
在频带注意力学习模块中,首先计算EEG 样本中各个频带的平均值,结果表示为x=(x1,x2,…,xr),其中xi是频带的EEG 平均值,r是频带数。随后采用两个全连接层进行权值学习,它们的作用不同:第一层是参数为W1和b1的升维层,第二层则是参数为W2和b2的降维层。升维使用tanh 作为固定激活函数增加注意力学习网络的非线性,避免计算结果中出现过多线性组合。降维的激活函数选择使用sigmoid,作用是将网络计算的分数转换为取值在0~1 的权值。如式(1)所示:
通过权值学习,EEG 频带的重要性转化为了频带的注意力a=(a1,a2,…,ar),其中ai是某一频带的注意力。依据式(2)对于不同的EEG 频带数据添加注意力:
其中:Di∈Rn×t(i=1,2,…,r)表示某频带EEG 数据;n和t是EEG 信号通道数和时间维度;Ofreq为加权结果,显然Ofreq∈Rn×t。经过添加注意力的操作后,情感关键的频带数据被赋予了高权重,在分类模型中的作用会被强化。
2.2 1D-Inception特征学习模块
在生理信号情感计算中,基于CNN 的特征学习方法是有效的[13]。然而CNN 存在的问题为:CNN 在一层卷积内,卷积核大小是固定不变的,因此单层卷积的视野域也是固定的。如果想要扩展卷积的视野域,就需要叠加多层的卷积,造成参数规模和训练代价上升,也容易造成过拟合。而Inception 结构则是对CNN 的一种改进方案。Inception 结构在一层卷积内使用多个尺度的卷积核提供各种视野域,单层卷积就能得到信息量丰富的特征,且具有较小的参数规模。因此,本文对原始Inception 结构进行改进,提出一种适合于生理信号特征学习的1D-Inception 结构用于生理信号的多尺度卷积,如图2 中的框内部分所示。对于生理信号数据,1D-Inception 的卷积操作包含3 个分支:第1 个分支首先使用宽度为1 的卷积核对原始数据进行升维,之后使用宽度为d的卷积核进行卷积;第2 个分支使用宽度为2d的卷积核,与第1 个分支相比,视野域扩大一倍;第3 个分支对原始数据进行池化采样和升维,采样宽度为1.5d,这个分支保留了原始的数据信息,并进行了通道映射。最后将3 个分支的卷积池化结果在通道维度上连接,计算结果既包含两种尺度的卷积结果,又包含原始的数据特征,因此可以得到相较于一般卷积信息量更丰富的特征。
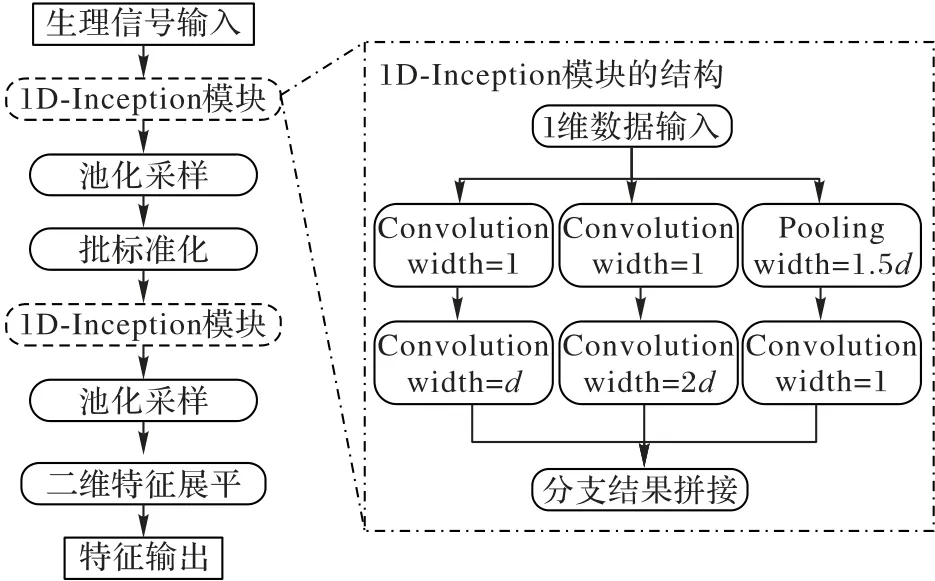
图2 1D-Inception特征学习模块的结构Fig.2 Structure of 1D-Inception feature learning module
为进一步减少参数规模和降低训练代价,本文使用池化层和批标准化对1D-Inception 的卷积结果进行处理。采用平均池化将计算结果采样后,使用批标准化将批次内的特征调整到标准正态分布下,使损失函数更平坦,加速学习过程[21]。由于单层参数规模和训练代价并不高,因此本文将两个1D-Inception 块堆叠以增加模块学习能力,中间使用池化采样和批标准化进行连接,组成本文所使用的1D-Inception 特征学习模块,如图2 所示。模块最终输出的特征是维度为时间和通道的二维特征,通过特征展平最终输出一维特征。在使用1D-Inception 特征学习模块时,将EEG 的各个通道、ECG 信号和眼动信号分别单独送入模块提取特征避免不同模态之间的数据互相干扰。
2.3 自注意力模块
对各生理信号完成特征学习后,需要对特征进行有效融合。如果只对不同模态的特征简单拼接,由于不同生理信号的信号模式存在差异,特征可能会相互干扰,降低识别准确率,因此,本文提出使用自注意力[22]进行不同生理信号的特征融合。自注意力机制可以学习特征向量之间的相关性,进而提高关键特征的权重,降低非关键特征对于结果的影响。
使用自注意力机制对多模态生理信号特征进行融合,自注意力模块的结构如图3 所示。实验采用的EEG 数据的通道数为32,因此首先分别训练32 个EEG 信号、1 个ECG 信号和1 个眼动信号总计34 个特征向量的query、key和value向量;然后通过计算不同特征之间的query与key向量的相关性来代表特征之间的相关性,通过softmax 标准化后,得到向量之间的注意力;最后将注意力值和各特征向量的value向量进行加权和,得到的新特征向量会根据学习的注意力值的不同,区别关注各输入特征向量的信息。

图3 自注意力模块的结构Fig.3 Structure of self-attention module
特征向量的query、key和value向量的计算方法如式(3)所示:
其中:ci∈Rt(i=1,2,…,34)为特征向量,34为多模态生理信号的特征向量数,t为特征维度都是维度变换的参数矩阵,t' 是变换后维度,显然之后,使用各特征的keyj和queryi的向量点积来计算特征之间彼此的注意力,如式(4)所示:
其中:atti,j代表特征i对特征j的注意力值,softmax 函数起到归一化作用,使点积值映射到(0,1)区间内形成权值。注意力值计算完成后,使用注意力值对各个输入向量的valuej加权叠加,如式(5)所示:
其中mi即为特征i的加权后结果。可看出此过程中的每个特征综合考虑了其他所有特征的相关性,对计算后的特征进行拼接可以减少不同模态信号之间的相互干扰。
2.4 Bi-LSTM网络
生理信号是连续的生物电信号,因此信号的特征片段之间并非孤立,存在时序关系。而卷积网络受制于其结构,不适合处理序列关系。LSTM 是一种常用于序列分析的网络模型。生理信号的顺序并不固定,从左到右或从右到左可能都存在时序信息[7],传统的LSTM 网络只能按一个顺序学习分类,存在局限性。为了解决上述问题,本文采用Bi-LSTM 网络对融合后的多模态生理信号特征进行时序特征学习。Bi-LSTM 网络既可以学习正向的时序特征,考虑每个特征与后续特征之间的关系,又可以学习反向时序特征,考虑和前序特征的关系,与多模态生理信号的特点相匹配。
本文搭建的Bi-LSTM 网络如图4 所示,网络由两层的LSTM 单元构成。LSTM 单元之间并非独立存在,单元会考虑上一单元的输出结果和输出给下一单元的结果。LSTM 单元使用3 个门控函数实现这种功能,即:输入门、遗忘门和输出门。Bi-LSTM 网络的各单元所作的计算如式(6)所示:
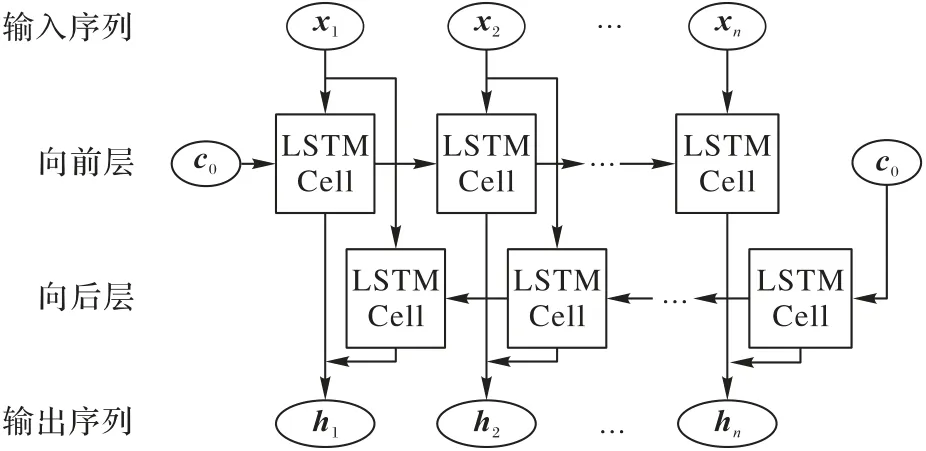
图4 Bi-LSTM网络的结构和数据流向Fig.4 Structure and data flow of Bi-LSTM network
对于第T个时序片段xT∈R34t',将它和上一层的输出向量hT-1进行拼接,分别使用4 组参数矩阵Wi、Wf、Wo、W和偏置向量bi、bf、bo、b计算输入权重zi、遗忘权重zf、输出权重zo和候选记忆状态z。其中:输入权重决定在多大程度上接受输入数据,遗忘权重决定在多大程度上考虑上一单元的输出结果,输出权重则决定将多少计算结果输出给下一个单元,候选记忆状态起到了标准化数据的作用。每一份LSTM 单元会根据所学习到的上下文序列信息计算自己的记忆状态,并提供给下一单元参考来体现网络之中各个单元的接续性。
LSTM 单元进行的运算如式(7)所示。首先需要将遗忘权重zf和上一层的记忆状态CT-1进行哈达玛积运算(⊙),以决定保留多少上一层的记忆;然后将候选记忆状态z和输入权重zi作哈达玛积,决定保留多少本单元的记忆;最后计算本单元的记忆状态。这个记忆状态综合考虑了前序单元的记忆状态和输入向量,并考虑了它们之间的权重配置。第二层的反向LSTM 的计算方法相同,不同在于每个单元通过考虑后一个单元的输出结果来决定自己的记忆状态。最终Bi-LSTM 将两个方向对应的运算结果拼接并输出为最终运算结果。这个结果包含了两个方向上的时序特征学习的结果,相较于单向LSTM 时序,信息量更丰富,更适合生理信号的时序特征学习。
3 实验与结果分析
3.1 生理信号采集实验
为了采集实验所需要的生理信号数据,本文进行了志愿者招募、情感激励实验和数据预处理等工作,多模态情感识别的总体实验流程如图5 所示。在情感激发的过程中,视频激励相较于音乐、图像等激励源具有更好的情感激发效果[23]。首先筛选了50 段备选视频,招募了110 名观众在线上观看视频,并对各个视频对情感的激励程度打分。最终35段情感激发效果最好的视频被选为实验采用的情感激励源,这些视频经过实验证明可以有效激发积极和消极情感。
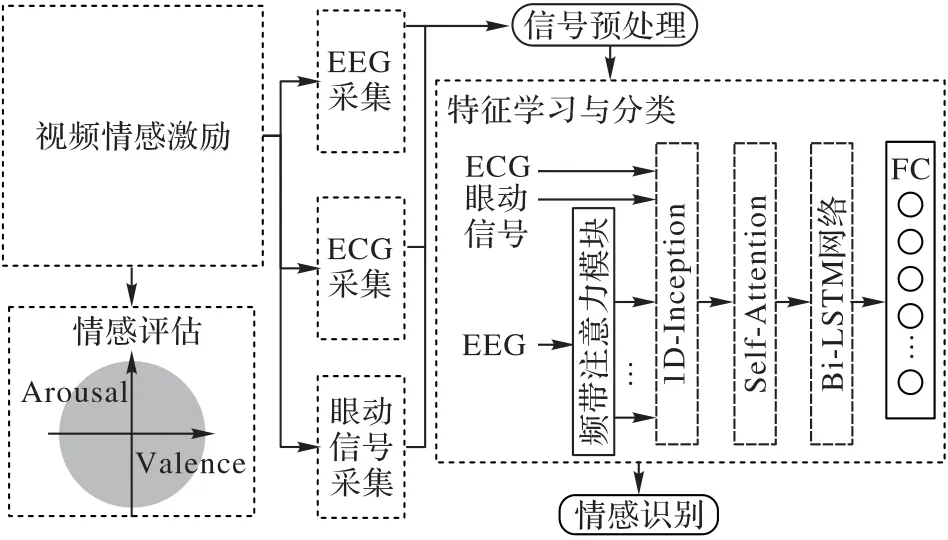
图5 多模态情感识别的总体实验流程Fig.5 Overall experimental flow of multimodal emotion recognition
数据采集实验首先招募了15 名志愿者,其中男性8 人,女性7 人。他们均是年龄在19 岁到26 岁的在校学生,精神健康状况良好且无精神疾病史。数据采集的流程如图6 所示,每名实验人员需要进行35 次实验。在每次实验中,实验者有5 s 的时间闭眼进行情绪平复,在此期间记录个体不受情感激励时的生理信号作为基线数据。之后实验者需要观看长度在60~242 s 的激励视频。观看结束后实验者有60 s时间对自己的情绪进行评分,包括效价维度(Valence)和唤醒度维度(Arousal)的1~9 分,鼓励实验者根据自己的真实情感打分。实验工作通过了伦理委员会的许可,在参与者的知情和允许下进行。

图6 数据采集的实验流程Fig.6 Experimental flow of data acquisition
实验采用3 种设备采集信号。Emotiv 的32 导电极帽用于采集EEG 数据,电极按照国际10-20 系统均匀分布在头皮上,如图7 所示。实验中还使用导电膏增强头皮到电极的导电性。基于AD8232 芯片的双电极传感器用于采集ECG 信号,其中两个电极佩戴在实验者双腕的脉搏处。Tobii 眼动追踪仪用于采集眼动信号,追踪仪可以实时采集实验者眼球注视位置。EEG、ECG 和眼动信号设备的采样频率分别为128 Hz、500 Hz 和133 Hz。
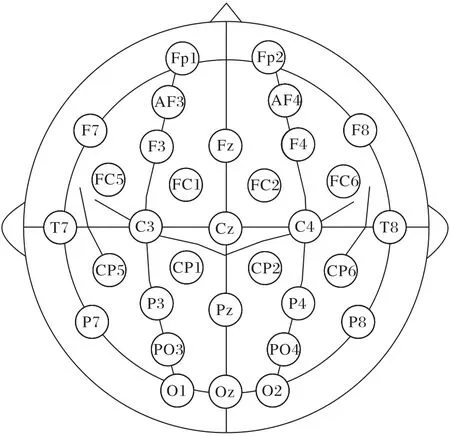
图7 实验使用的32导设备的电极分布Fig.7 Electrode distribution of 32-channel devices used in experiment
标签处理方面,本文以5 为中间值,将标签在效价和唤醒度两个维度上分为了高和低两个类别,转换为二分类任务和效价/唤醒度四分类任务。
3.2 数据预处理
原始的生理信号数据受噪声和基线漂移影响较大,其中噪声主要来源于人体皮肤电信号和采集设备本身的工频信号,基线漂移则是因为实验者在实验过程中的运动幅度过大,导致信号整体参考水平发生变化。对于ECG 信号,采用小波变换将原始信号分解为不同频率的子信号分量,再利用阈值去噪的方法设定一个噪声阈值,只保留大于阈值的信号分量,再通过小波反变换还原去噪后的ECG 信号。噪声阈值的计算方法如式(8)所示,这是一种基于鲁棒估计的阈值去噪方法,可以有效去除信号中的高频噪声部分[24]:
其中:median(abs(signalECG))表示原始ECG 数据的绝对值的中位数,L表示数据长度。
对于EEG 信号,首先使用乳突处电极的平均波形对原始信号进行重参考,之后使用独立成分分析(Independent Component Analysis,ICA)删除EEG 信号中的眼电信号(ElectroOculoGram,EOG)成分[25]。EOG 是眼球运动时产生的电信号,对于EEG 信号来说是干扰因素。在信号采集时会采集实验者未受情感激发时的EEG 基线数据,它记录了大脑在平静情况下产生的自然电位变化,可以利用基线信号解决EEG 的基线漂移问题。具体地,本文按照1 s 的宽度将原始信号分成若干段,求得基线信号各段的平均波形,再使用原始信号实验部分的各数据段减去基线部分的平均波形,如式(9)所示:
其中:Xbase(i)代表第i段EEG 的基线数据,l代表基线数据段数,Xtrial(j)和分别代表处理前和处理后的受情感激励的实验部分EEG 分段。
本文实验采用眼动信号记录实验者在屏幕上的注视点Y轴坐标。这是因为X坐标可能受实验者阅读字幕等的影响,而Y轴受影响较小。眼动数据受抖动的影响很大:一方面,传感器记录的位置会有微弱抖动;另一方面,人的眼睛长期看向某一点时,会下意识瞥向周围,然后迅速回到原始点以缓解视觉疲劳。因此,需要对原始的眼动数据平滑处理,去除由于传感器和人眼本身造成的抖动异常,本文方法使用高斯滤波器。具体地,利用窗口内的数据加权平均值取代窗口内中心点的值,可以有效过滤短时的高频噪声,达到平滑窗口内曲线的目的。在计算加权平均值时,权值的计算如式(10)所示:
其中:w表示窗口内的某个点到中心点的距离,σ是控制高斯滤波的参数,G(w)为计算的权值。
预处理完成后,需要对处理后的数据进行分段,作为模型的训练测试数据。本文使用1 s 的宽度对数据进行切分,每1 s 切分出对应的EEG 的32 导的数据、1 导的ECG 数据和1 导的眼动数据片段,共34 导的信号波形。为了统一3 种生理信号的维度,将3 种信号统一采样至128 Hz,形成维度为(34,128)的数据单元。根据2.1 节的方法介绍,EEG 的数据还需要进行分频处理,分为θ、α、β 和γ 这4 个频段,δ 频段EEG 在人清醒环境下很少会出现所以不使用。显然分频后的EEG 数据维度为(32,4,128)。
3.3 情感分类实验
3.3.1 1D-Inception模块的有效性验证
为了证明1D-Inception 特征学习模块相较于传统特征提取方法和传统CNN 的有效性,本文进行了有效性验证实验。首先使用信号的PSD 作为特征,使用SVM 作为分类器,高斯核作为核函数。之后搭建了一个3 层的简单CNN 用于原始信号的直接分类。1D-Inception 特征学习模块被单独设置,在特征学习后直接进行分类,验证三者的分类能力。实验结果如表2 所示,ACC(Accuracy)和STD(STandard Deviation)是平均分类准确率和准确率标准差。1D-Inception 模块取得了最高的分类准确率,相较于前两者在平均准确率上提升了28.98 个百分点(效价)和30.05 个百分点(唤醒度)。个体之间的准确率标准差也降低至8.77%(效价)和7.91%(唤醒度),且1D-Inception 模块的参数规模要小于3 层CNN,说明本文模块具有更小的参数代价和更高的特征学习性能,学习的特征可分类性更好,在不同个体之间的泛化能力更强。由此证明了本文提出的1D-Inception 特征学习模块更适合于生理信号特征学习。
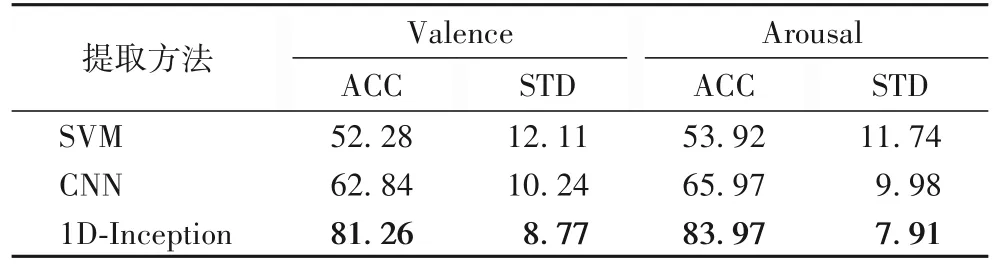
表2 1D-Inception与其他特征提取方法的准确率对比 单位:%Tab.2 Accuracy comparison of 1D-Inception with other feature extraction methods unit:%
3.3.2 特征融合的有效性验证
为了验证本文采用的基于自注意力的特征融合方法的有效性,实验使用特征直接融合方法、决策层融合方法和本文融合方法进行对比。在进行对比实验之前,本文使用的Bi-LSTM 模块使用的序列长度需要被确定,即模型在多大序列范围内提取时序特征。本文中针对这一问题尝试了5 种序列长度:1、3、6、10 和15。实验结果如表3 所示。当6 作为序列长度时,模型取得了最好的分类效果;15 作为序列长度时尽管标准差略低,但是准确率出现了大幅下降。
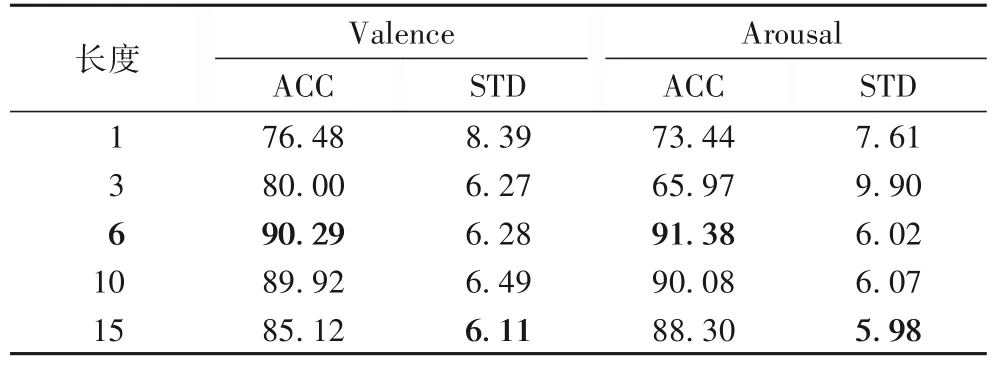
表3 不同的Bi-LSTM序列长度的实验结果对比 单位:%Tab.3 Comparison of experimental results with different sequence lengths of Bi-LSTM unit:%
序列长度确定后,对三种融合策略进行了对比实验,结果如表4 所示。直接融合方法是将特征提取模块输出的各个模态的特征直接进行向量拼接,再送入Bi-LSTM 网络进行分类;决策层融合方法则是将不同模态的特征单独送入独立的Bi-LSTM 网络进行单独分类,再将分类结果通过最大值融合方法进行决策层融合。结果表明,自注意力融合方法在效价、唤醒度和效价唤醒度四分类任务上分别取得了90.29%、91.38%和83.53%的识别准确率,个体的识别标准差降低至6.28%、6.02%和9.77%。相较于其他融合方法取得了最好的识别效果,证明了本文提出的自注意力融合方法对于多模态生理信号特征融合的有效性。

表4 自注意力融合方法和其他融合方法的准确率对比 单位:%Tab.4 Accuracy comparison between self-attention-based fusion method and other fusion methods unit:%
3.3.3 多模态方法的有效性验证
本文使用三种生理信号的单模态、EEG+ECG 双模态、EEG+眼动双模态和本文使用的三模态融合方法进行了对比。在实验环境上,本文在Pytorch1.8.1 深度学习环境下搭建模型,使用的硬件加速设备和驱动版本分别为Nvidia 1660S 和CUDA11.1。在实验设置上,使用交叉熵作为损失函数,Adam 为优化器,采用10 折交叉训练验证的方法提升模型的情感识别能力。批大小(Batch Size)设置为80,最大迭代次数为100。在算法的运行时间上,每位受试者的数据训练平均花费389.49 s,测试平均花费1.25 s。
实验结果如表5 所示。可以看出在单模态实验中,EEG单模态相较于其他两种生理信号取得了最优的识别效果,效价唤醒度四分类准确率高达76.42%,明显高于ECG 的45.39%和眼动的39.28%。这说明相较于ECG 和眼动信号,EEG 更适合用于情感识别任务。
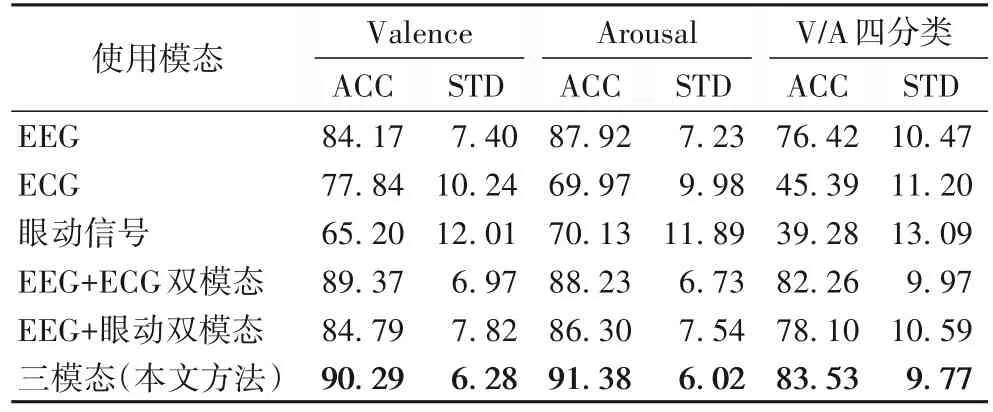
表5 多模态方法与单、双模态方法的准确率对比 单位:%Tab.5 Accuracy comparison between multimodal method with unimodal and bimodal methods unit:%
进行模态融合后,多模态方法相比EEG 单模态方法取得了更好的识别效果。EEG+ECG 双模态的准确率提升至89.37%(效价)、88.23%(唤醒度)和82.26%(效价唤醒度四分类),而且标准差更低,跨个体的识别准确率更加稳定。而三模态融合取得了最好的识别效果,在三个分类任务上分别取得了90.29%、91.38%和83.53%的识别准确率。相较于EEG 单模态提升了3.46~7.11 个百分点,相比EEG+ECG 双模态提升了0.92~3.15 个百分点,而且个体间准确率的标准差降至最低。这说明三模态比EEG 单模态和双模态的识别方法更加优越,ECG 和眼动这两个模块的加入有效提升了基于EEG 情感识别的准确率和跨个体识别的稳定性。
3.4 与其他方法的比较
表6 给出了本文方法和其他的生理信号情感识别方法的准确率对比。其中文献[18]方法融合了EEG 和皮肤电信号并使用CNN 进行情感识别。文献[26]方法将脑磁图、EOG 和ECG 等多种生理信号模态融合,构建层次模块化神经网络对情感进行分类。文献[27]方法融合EEG 和眼动特征并使用深度典型相关分析进行多模态情感识别。文献[7,28]方法均是EEG 和ECG 和双模态融合,它们分别使用了时频域特征计算和图神经网络对生理信号进行特征提取。本文方法在唤醒度上取得了最好的识别准确率,效价的准确率也提升了3.68~13.73 个百分点。效价的准确率虽然略低于文献[28]方法,但是在唤醒度上提高了3.14 个百分点。
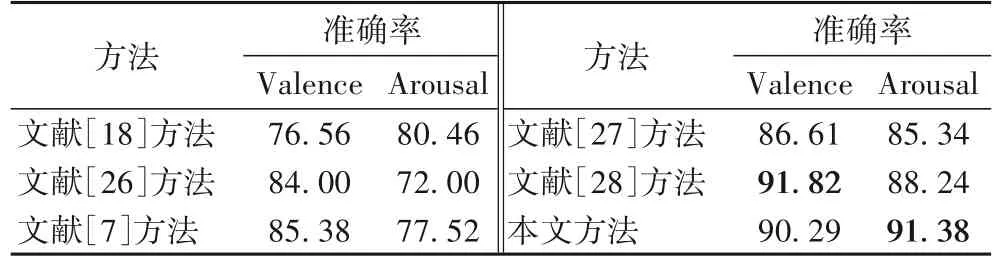
表6 与现存的基于生理信号情感识别方法的准确率对比 单位:%Tab.6 Accuracy comparison with existing physiological signal-based emotion recognition methods unit:%
本文的多模态方法能取得优秀的识别效果与多模态模型结构有关。首先,1D-Inception 模块的多尺度卷积方法能学习更稳定、更高维度的生理信号特征;其次,频带注意力机制能有效放大EEG 中的关键频带中的数据,而基于自注意力机制的特征融合也能增加多模态信号中的关键特征的权重,降低非关键特征对于分类结果的影响;最后,多模态的方法利用信号之间的互补性,各种生理信号之间相互补充情感信息,有效提升了分类准确率,并且使得跨个体的识别效果更稳定。
然而,本文方法仍有改进空间。需要注意到,实验结果中识别准确率的标准差尽管有所改进,但是跨个体的识别效果仍然存在一些波动。本文经过分析认为标签的比例失衡可能是潜在原因,因为实验采用的标签处理方法是以5 为界进行划分,少数实验者将大部分打分都打在5 以上,造成了反例数据的不足,导致识别效果下降。因此情感标签的处理方法可能需要进一步研究,以优化样本比例[29]。
4 结语
本文提出了一种基于EEG、ECG 和眼动信号三种模态的特征层融合的情感识别方案,通过有效的特征学习和特征层融合方法提升了情感识别准确率和跨个体的识别稳定性。对于生理信号的特征提取,首先使用频带注意力处理EEG信号的多频带问题,通过自适应添加权重的方法放大EEG中情感关键频带的数据。之后本文提出一种1D-Inception 模块对数据进行多尺度卷积,提高模型识别准确率和减小卷积参数规模。对于多个模态生理信号的特征融合,本文使用了自注意力机制在多模态特征之间进行注意力学习,提高关键特征的权重并降低非关键特征对于结果的影响。最后,通过Bi-LSTM 网络对融合后的特征进行时序特征学习和情感分类。实验结果表明,本文方法在效价、唤醒度和效价/唤醒度四分类的识别任务上分别取得了90.29%、91.38% 和83.53%的识别准确率,体现了多模态融合方法的有效性。未来的工作中,将结合更好的情感标签处理方法进行进一步的研究。
