基于多元融合的企业技术创新合作预测方法研究
2024-03-20琚春华曹倩雯
琚春华,诸 惠,曹倩雯
(1.浙江工商大学现代商贸研究中心,浙江 杭州 310018;2.浙江工商大学管理工程与电子商务学院,浙江 杭州 310018;3.浙江金融职业学院电子商务与新消费研究院,浙江 杭州 310018;4.浙江工商大学工商管理学院 (MBA学院),浙江 杭州 310018)
0 引言
技术创新合作在全球范围内深入凸显了知识经济时代的重要特征,即强调知识流动的重要性[1]。知识随着技术合作行为在主体间交互,进而重塑主体知识结构,促进技术创新[2],提升合作主体竞争力。技术创新复杂度日益提升,知识基础和资源储备的局限性迫使企业不得不寻找合作伙伴,以获取异质性知识和互补性资源,降低创新成本,提高技术创新成功概率,保障自身行业地位和竞争实力。
数字技术的发展拓展了企业探寻技术创新合作伙伴的范围,基于互联网的企业交互和知识流动打破地理界限[3],为企业开放式创新提供了便利条件。技术创新合作更强调知识的融合和重组,传统以经验和合作历史为轴寻找合作伙伴的方式显然已经不再适合企业对多元化知识的需求,广泛获取行业领域内的企业信息,并加以挖掘,从中选择适配的企业开展技术合作,更具现实意义。然而,尽管大数据为企业提供足够的信息资源,但是信息冗余和信息过载让寻找合作伙伴这一过程异常艰难[4],信息检索能力不足加重了企业获取完整信息和高价值信息的难度[5],造成合作错配,从而影响知识融合的质量,并存在高成本合作的可能性,不利于技术创新。因此,针对技术创新合作需求,对基于数字化环境下探索技术创新合作伙伴进行深入研究,能够提高合作伙伴匹配的准确率,进一步提升技术创新合作绩效。
1 相关研究
技术创新合作对企业的创新绩效产生正向影响作用,有利于推动各行业领域的创新发展[6-7]。合作推荐的研究起源已久,学术合作、技术合作、产学研合作等都是研究关注的焦点。在开放创新环境下,企业需要吸收外部知识资源,减少技术创新的时间跨度、分散创新风险以提升创新绩效[8]。因此,企业技术创新合作伙伴的评估和选择得到了持续关注。
1.1 基于多属性决策的合作推荐
企业在选择技术创新合作伙伴时,重点关注潜在合作伙伴的技术特征与技术实力。文本挖掘技术在现有研究中经常用于提取主体的科研成果技术主题[9],如LDA算法[10]、Word2vec模型[11]、SOA[12-13]、网络表示学习[14]等,结合K-mean等[15]的聚类算法,能够有效识别潜在合作伙伴的技术特征,以评估企业与潜在合作伙伴的技术兼容性。技术实力是企业选择技术创新合作伙伴的重要依据,包括技术份额、技术领先地位、技术影响[16]、技术集中度和技术规模[17]等。另外,与信任相关的指标也被纳入合作伙伴选择的参考因素,如金融资产、无形资产[18]、抗风险能力、互信互通程度、相容性 (文化、管理理念、品牌形象、战略目标)[19]、国家政策、行业协会情况、多维 (制度、地理、技术)临近[20]、CEO特征[21]等因素,企业根据自身需求选择合适的指标对潜在合作伙伴进行科学评价,以选择有利于技术创新的合作伙伴。
1.2 基于复杂网络的合作推荐
企业之间的合作网络本质上也是一种复杂社会网络,符合小世界[22]与无标度网络[23]的性质,将链路预测方法引入到复杂网络模型中,并用于解决合作预测问题,发现主体之间的潜在合作联系[24-26],更适合候选群体不确定的情况。常用的链路预测指标包括Common Neighbors (CN)[27]、Adamic-Adar (AA)[28]、Resource Allocation (RA)[29]、
Leicht-Holme-Newman Local (LHNL)[30]、SimRa-
nk[31]等。学者从构建创新成果合作关系网络[32]出发,根据节点的邻居和路径[33]预测节点未来合作的可能性。为了不断优化合作预测的结果,学者提出结合文献耦合分析方法[34],通过挖掘作者的研究方向与内容,在对合作网络进行链路预测的基础上,综合分析作者研究内容的相似程度,以修正预测结果[35-36]。为进一步反映技术内容和企业之间的双重关系,多层网络被引入合作预测,从技术角度应用链路预测探索组织间的合作潜力[37]。
根据对现有研究的梳理和分析可以看出,目前对企业筛选合作伙伴的研究已经取得了丰富的成果,但仍然在以下3个方面存在优化的空间。①基于多属性决策的合作推荐方法中,需要对备选合作企业进行逐一评价,忽略了数据平台提供的大数据所具备的信息价值,容易因信息掌握不足或信息错误而疏漏潜在的合作伙伴,推荐的精准度和效率较低;②虽然有学者提出根据创新成果的合作关系,融合链路预测与耦合分析方法进行合作关系挖掘[38],但融合算法多用于科研合作,在向企业合作推荐迁移过程中的稳定性需要进一步验证;③在推荐指标的选择中,并未考虑企业在合作网络中的位置,而现有研究已经证明,企业在合作网络中的位置能够体现企业对知识资源的控制能力[39],相似且合适的网络位置会正向影响企业合作的成功率、持续合作的意愿以及创新绩效[40]。因此,本文提出基于多元融合的企业技术创新合作预测方法,应用大规模专利数据,在融合路径相似性和内容相似性的基础上,结合企业节点在专利合作网络中的位置相似性,构建潜在合作关系挖掘算法,以提升企业选择合作伙伴的效率和适配度。
2 研究思路与方法
主体相似是能够促进合作并从知识融合、知识吸收、双方信任等角度提升合作成功率及持续合作意愿的必要条件[5,41-42]。技术创新合作有别于贸易合作等其他类型合作的重要特征是更为强调基于知识背景的融合与重组,因而,合作主体间知识流动促进创新的机制包含动态拓扑结构特征和知识内容特征,在预测网络中各主体未来合作趋势时,融合主体路径相似性和技术内容相似性是具备理论依据的。同时,迟嘉昱等[43]证明网络位置相似性与企业研发技术相似性能够相互作用,进而影响企业合作创新,而企业在合作网络中的位置关系到知识获取广度与深度,反映企业知识地位和知识资源获取能力,相似的合作网络位置能够促进合作双方达成合作意愿。因此,在路径相似性和内容相似性的基础上,融入网络位置相似性作为决策依据,有助于增加企业选择技术创新合作伙伴的适配程度。
综上分析,本文应用企业公开发表的专利数据,构建基于专利所有权人共现的企业专利合作网络,选择链路预测中的Katz指标计算企业节点之间的路径相似性,结合企业的专利研究内容与方向,使用耦合分析方法计算企业之间的内容相似性。进一步地,根据企业在合作网络中的节点中心性计算企业之间的网络位置相似性,在结合路径与内容相似性的基础上引入网络位置相似性,构建混合预测算法,挖掘企业之间的潜在技术创新合作关系,为企业推荐合适的合作伙伴。研究思路如图1所示。
2.1 企业路径相似性计算
本文在路径相似性预测中采用链路预测算法,在构建企业专利合作网络的基础上,选择基于全局网络结构的Katz指标作为链路预测相似性指标。该指标能够考虑到两个节点企业之间的全部路径,从而更加准确地了解两个节点合作路径的相似性,预测精度更高。Katz指标对两个节点之间的全部路径依照不同路径长度赋予对应的指数级惩罚机制,最后计算得到两个节点之间的所有不同长度路径数量的加权和作为节点vx与节点vy之间的路径相似性[44],计算公式为:
α3(A3)xy+…
(1)
式中,α(0<α<1)是一个用于改变路径权重的可调节参数,A代表该网络的邻接矩阵, (An)xy代表在该网络中节点vx与节点vy之间长度为n的路径数量,长度越长的路径对于两个节点之间相似性预测的影响程度越小。
2.2 企业内容相似性计算
技术创新合作伙伴的选择关注企业与潜在合作伙伴的知识基础及技术特征的兼容性。在进行企业技术创新合作关系的预测挖掘中,企业技术的研究内容是专利合作网络中企业节点知识属性的重要表现。本文采用关键词耦合分析方法对企业技术研究的内容相似性进行计算。为了充分考虑关键词出现的各类情况从而确定企业的技术内容耦合程度,本文选择使用TF-IDF算法[45]构建企业技术特征向量,该方法能够在考虑关键词重复情况的同时,综合关键词出现的相对频次与绝对频次,得到更精准的企业技术研究内容,结合余弦相似性作为计算企业之间技术特征接近程度的方法,从而得到企业之间技术研究内容相似性。
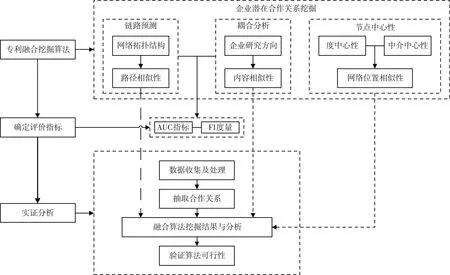
图1 研究思路
(1)关键词重要性计算。本文采用TF-IDF方法计算企业的专利关键词重要程度,计算公式为:
Wxt=TF×IDF
(2)
(3)
(4)
式中,Wxt代表关键词t在企业x的专利集合中的权重,M代表在企业x全部的关键词出现的频次之和,m代表在企业x全部专利集合中关键词t出现的全部次数;N代表企业x的专利总数,而n代表企业x的专利中包含关键词t的专利数量。
(5)
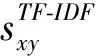
2.3 企业网络位置相似性计算
相似的位置获取知识资源的能力以及拥有知识的水平相似,能够避免合作双方对于另一方 “搭便车”的担心,有利于构建更为坚固的信任关系[46],增强合作双方知识共享意愿,进而促进技术创新。因此,本研究考虑企业在合作网络中的位置相似性,以修正路径相似性和内容相似性产生的预测偏差,提高预测结果的精确程度。
在企业合作网络中,企业节点的度中心性与中介中心性能够代表企业节点在合作网络中的网络位置重要性[47]。其中,度中心性表示网络中与企业节点直接关联的其他节点数量占网络中所有其他节点数量的比值,体现了企业能在多大的范围内获取知识资源,计算公式为:
(6)
(7)
其中,aij表示节点i和节点j是否有直接的关联关系。如果有,则为1;如果没有,则为0。N表示网络中节点数量。
中介中心性表示网络中一个企业节点位于其他两个节点之间的最短路径中担任桥梁的次数,是企业接触重要知识的体现,计算公式为:
(8)
式中,Dxy表示节点vx到节点vy的全部最短路径数量,Dxy(i)表示从vx到vy的全部最短路径中经过了节点i的最短路径数量。
为了衡量两个企业节点之间基于中心性的位置相似性,利用企业节点在专利合作网络中的度中心性与中介中心性构建企业节点中心性向量,通过计算企业节点中心性向量的余弦相似性作为企业之间融合的网络位置相似性数值,计算公式为:
(9)
式中,Lxr与Lyr分别为节点vx与vy的节点中心性向量,即Lir= (DCi,BCi)。根据余弦相似性得到的计算结果代表了融合节点度中心性与中介中心性的网络位置相似性。
灯草老爹回答说:“太君,烧这三窑瓦我可用心了,坯是最好的坯,柴是最好的柴,火候把得好,出窑的时候,这瓦啊,一敲响当当!”
2.4 混合预测算法的构建
由于节点网络位置相似性仅关注节点的连接数量和连接地位,与是否在网络上存在关联及研究内容是否相似无关,即便两个节点之间不存在路径或内容上合作的可能性,网络位置依然可能存在较高的相似性。因此,本文在指标融合过程中,将位置相似性作为后置条件,用于修正推荐列表的排名,提升推荐结果的适配性,融合过程为:首先,根据计算得到融合路径相似性与内容相似性的企业合作可能性;其次,为了进一步获得这些企业潜在的合作可能性排序,引入网络位置相似性,确定最终的企业两两合作预测矩阵,为企业选择合作伙伴提供推荐,其定义公式为:
SWeight=ωSKatz+ (1-ω)STF-IDF
(10)
SMix=SWeight×SClose
(11)
式中,矩阵SKatz、STF-IDF、SClose分别表示企业之间的路径相似性、内容相似性和网络位置相似性,SWeight为路径相似性和内容相似性加权后的结果,矩阵SMix表示结合路径相似性、内容相似性和网络位置相似性构建的企业技术创新合作相似性。ω(0<ω<1)是加权算法的可调节参数,用于调节在综合算法中路径相似性和内容相似性的权重。为了保证预测结果的准确性,借助算法评价指标AUC指标和F1度量确定加权预测算法中可调节参数ω的取值,取AUC指标值最接近1且F1度量值最大时的ω值作为权重。位置相似性的融合选择相乘计算,即在两个企业存在路径相似性和内容相似性的前提下融入位置相似性,起到后置排序作用。
3 实证研究
3.1 数据来源与处理
为了验证本文所提出的合作预测模型的可用性和有效性,选择聚焦石墨烯行业获取相关的专利数据对模型进行分析验证。石墨烯在材料学、生物医学以及药物传递等各方面具有重要的应用前景,目前对于石墨烯的研究仍然处于初期阶段,研发人员在创新过程中产生丰富的成果,能够获取足够的数据用于验证模型的有效性,同时石墨烯领域还存在许多挑战,技术创新难度大,预测未来合作关系是必要的,符合建立潜在技术创新合作关系挖掘模型的目标。因此,本文选择石墨烯领域企业合作申请的专利作为数据源,以验证本文所提出的模型是有效且更优的。
(1)数据来源。本文使用的专利数据来源于德温特专利数据库 (Derwent Innovations Index,DII),应用关键词 “graphene (石墨烯)”对数据库中的专利主题进行检索,选取时间段为2017—2021内与石墨烯材料主题相关的专利文献为本研究的研究数据集,得到专利数据共79806篇,去除关键字段缺失的专利文献,得到有效专利数据共71285条。
(2)数据处理。将数据集中2017—2021年间的全部专利文献依照申请日期划分为两部分,其中2017—2019年的50468篇专利文献数据作为研究模型的训练集T_1进行挖掘与分析,2020—2021年的20817篇专利文献数据作为研究模型的测试集T_2验证预测结果的准确性。为了筛选核心企业以简化后续研究的计算复杂度,选取在训练集T_1和测试集T_2中均有发表专利的企业作为后续构建企业专利合作网络以及进行企业专利关键词耦合分析的筛选对象。考虑到专利数量过少的企业在技术创新方面的贡献较低,本文选择拥有专利数量超过5项的企业作为研究对象,共计611家。其中,我国企业共352家,占比57.61%,且专利拥有量排名靠前,美国、韩国紧随其后,分别为125家和71家,占比20.46%和11.62%,与我国共同构成石墨烯领域技术创新的第一梯队。尽管我国石墨烯行业相比发达国家起步较晚,但是随着 “中国制造2025”国家战略及石墨烯扶持力度加强,产业发展迅速。
为了掌握企业在石墨烯领域的技术创新实力,本文对各企业专利数量进行统计,表1为专利数量前10的企业,其中包括中国石油化工股份有限公司、国家电网有限公司、韩国的三星电子等。
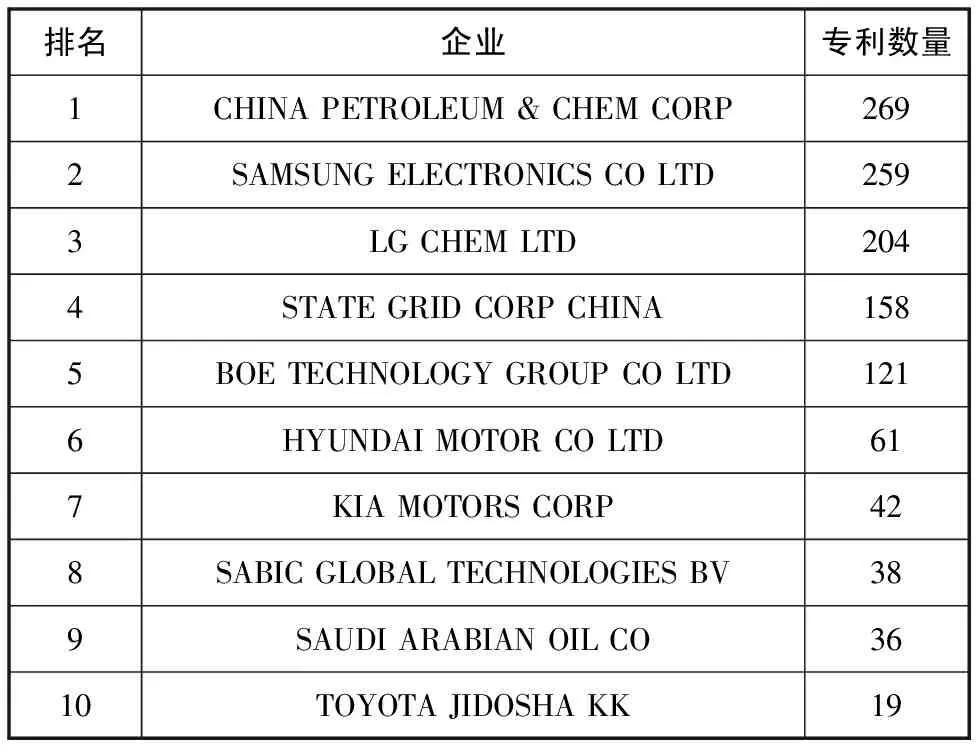
表1 石墨烯领域排名前10位的企业及其专利数量
3.2 企业合作网络构建
本文以两个企业共同出现在同一个专利中构建企业技术创新合作关系矩阵,并依照该矩阵构建企业合作网络,网络中节点为企业,连边为企业之间的合作关系,由于算法只涉及共同邻居、企业技术研发内容以及合作网络位置,故合作网络为无向无权网络。根据所构建的企业合作网络发现,石墨烯行业的企业之间是存在合作的,但是合作网络较为稀疏,网络密度仅为0.0577,因此为企业寻找合适的合作伙伴,促进企业之间合作,并进一步提升行业技术创新能力是必要的。
3.3 路径相似性计算结果
为了计算得到企业之间的路径相似性,首先需要确定Katz指标计算公式中的参数取值。计算不同随机参数α取值下的AUC指标并绘制变化曲线,表现不同参数取值下的路径相似性模型预测效果,如图2所示。
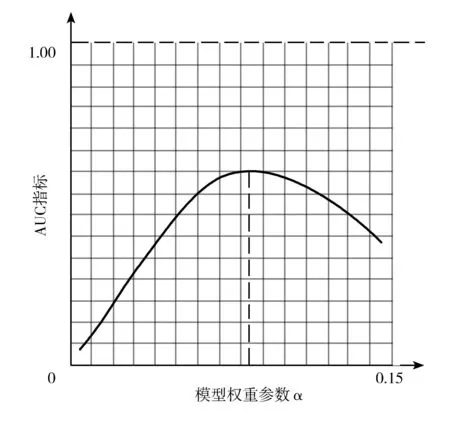
图2 路径相似性模型中AUC指标变化
当选取可调节参数α=0.084847时,路径相似性模型的AUC指标取值达到最大,即路径相似性模型预测效果达到最优。此时,根据Katz指标计算公式得到的路径相似性结果见表2。
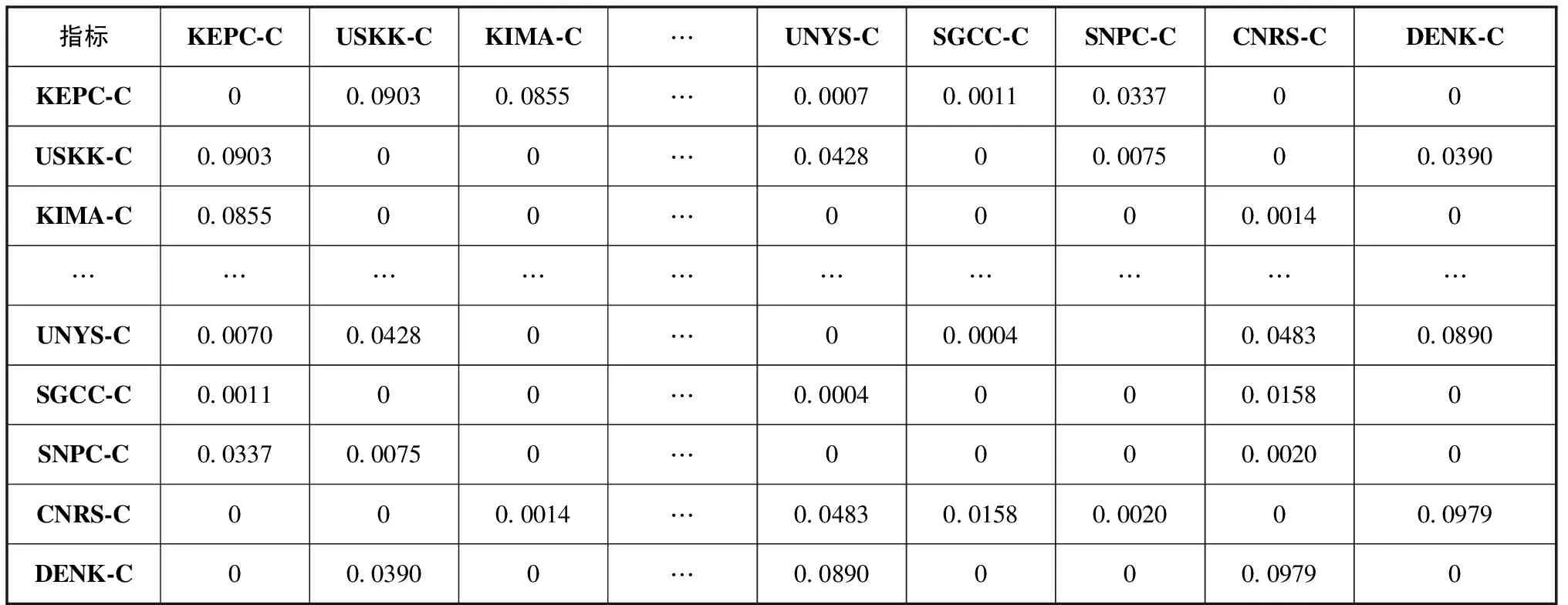
表2 路径相似性计算结果 (部分)
3.4 内容相似性计算结果
应用TF-IDF算法确定企业的关键词向量,以此表示企业技术创新的研究方向,并且结合空间向量理论,使用余弦相似性公式计算得到企业之间的内容相似性结果见表3。根据表3的内容相似性计算结果可以发现,路径相似性模型并未预测到但在测试集出现的企业KEPC-C (KOREA ELECTRIC POWER CORP)与企业DENK-C (TDK ELECTRONICS AG)之间的合作关系,根据内容相似性模型的计算结果可以预测得到。同时,应用两种模型预测两个相同企业之间的合作可能性结果不同,为了构建更加准确的挖掘模型,得到更优的预测效果,考虑将路径相似性与内容相似性加以结合,构建融合的加权预测算法模型,从不同角度对企业之间的潜在合作关系进行预测。
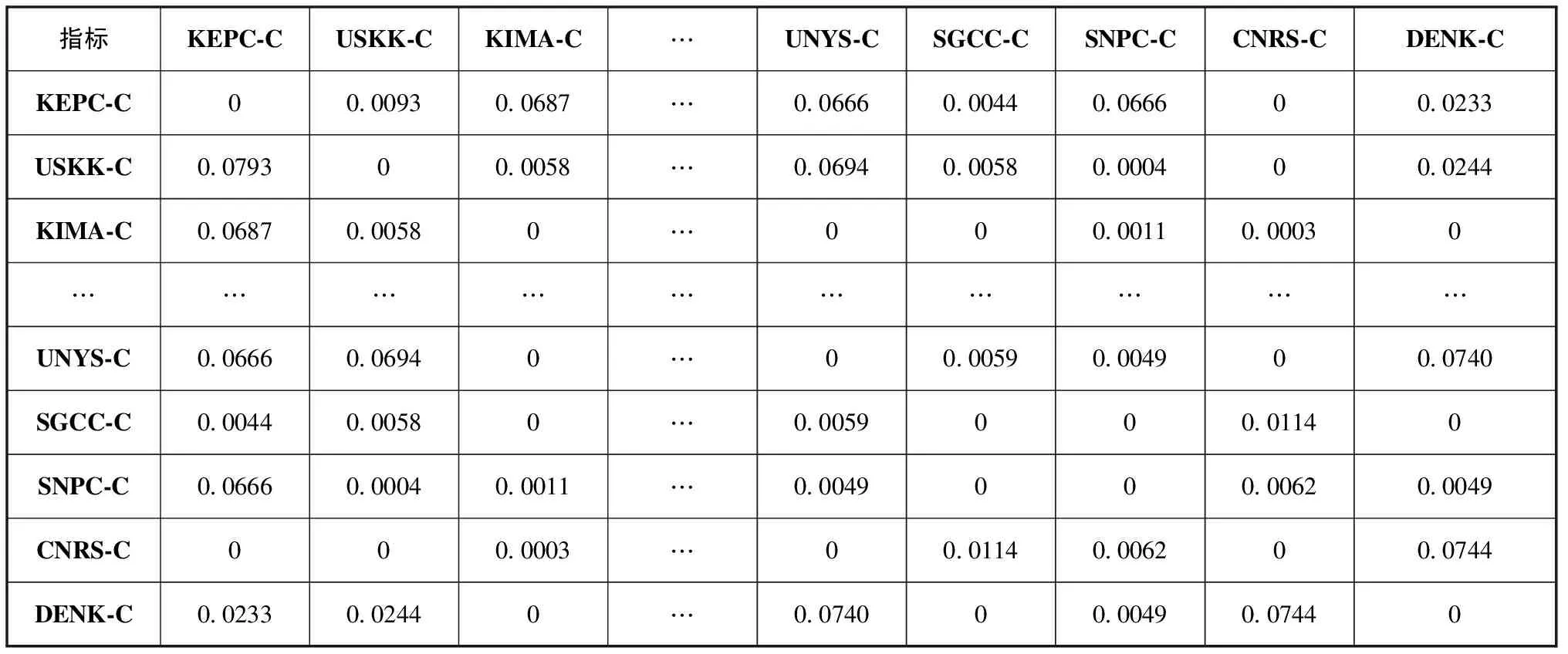
表3 内容相似性计算结果 (部分)
3.5 融合路径、内容相似性的计算结果
根据公式 (10)计算融合路径、内容相似性的企业合作预测结果,为了确定加权算法中可调节参数ω的权重取值,需要依据AUC指标和F1度量评价不同权重取值下加权算法模型的最终预测效果,从而选取效果综合最优的加权算法权重取值。分别计算不同参数ω取值下的AUC指标和F1度量的数值,并绘制变化曲线,如图3所示。由图3可知,AUC指标随着加权算法中权重参数ω的取值增大而改变,当权重参数取值位于ω=0.5周围时,AUC指标接近最大值;由图4可知,F1度量随着加权算法中权重参数ω的取值增大而改变,当ω=0.4968时,F1度量达到最大值。因此,综合考虑AUC指标与F1度量,取ω=0.4968作为加权算法的最终参数取值,进而得到融合路径相似性与内容相似性加权的计算结果,见表4。
3.6 融合网络位置相似性的计算结果
根据表4加权算法的计算结果,能够得到企业之间可能存在合作关系的企业组合,为了提升企业合作伙伴的适配度,需要综合考虑企业在合作网络中的重要性地位。根据式 (6)~ (9)计算得到企业之间的网络位置相似性结果,见表5。
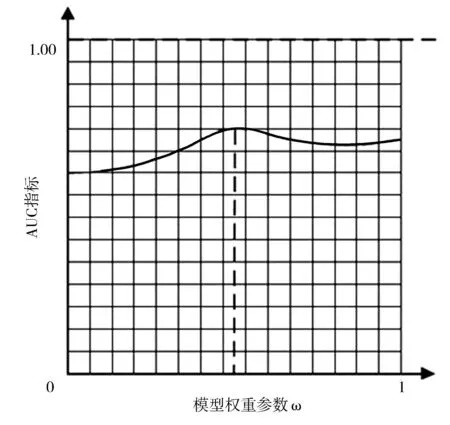
(a)AUC指标变化
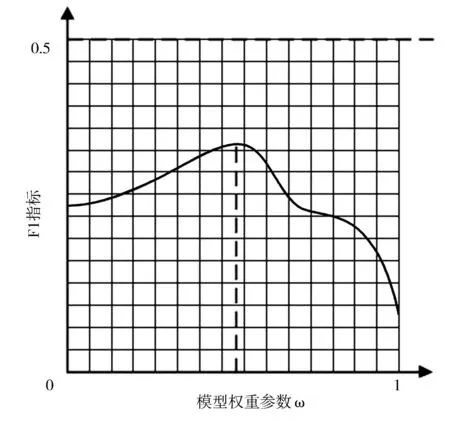
(b)F1度量变化
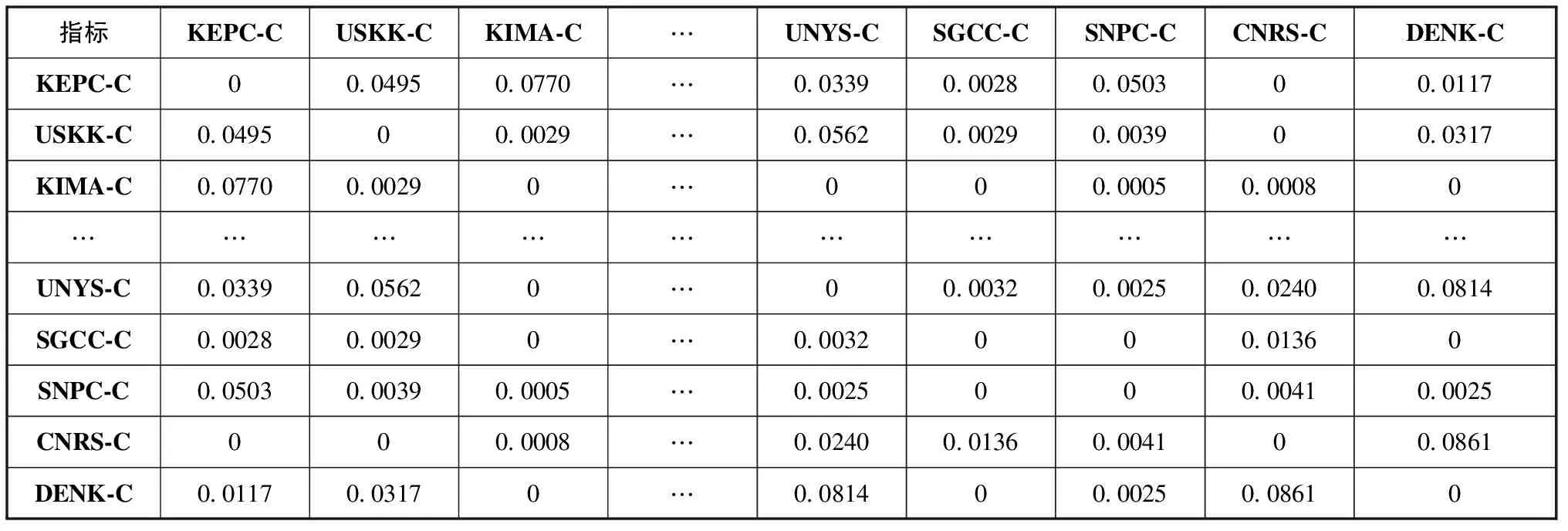
表4 路径与内容相似性加权的计算结果 (部分)
由表5可知,在网络位置相似性的计算结果中,尽管两个企业之间不存在合作关系,但网络位置依然有可能存在较大的相似性。可以解释为,尽管两个企业不存在共同邻居或专利研究方向完全不同,但只要这两个企业在各自的合作网络区域或研究领域内的重要性相似,那么这两个企业就可能具有较高的网络位置相似性,但并不代表企业之间会产生合作关系。进一步验证了将网络位置相似性作为后置因素用于合作企业预测的排序是合理的。根据式 (11)计算得到融合路径、内容与网络位置相似性的混合预测算法最终结果见表6。
由表6可知,最终混合预测算法的计算结果,以企业KEPC-C为例,表中显示它的合作企业根据可能性由大到小排序依此为KIMA-C (KOREA INST MACHINERY &MATERIALS)、USKK-C (UNIV SUNGKYUNKWAN RES &BUSINESS FOUND)、SNPC-C (CHINA PETROLEUM &CHEM CORP)、UNYS-C (UNIV NEW YORK STATE RES FOUND)、DENK-C (TDK ELECTRONICS AG)以及SGCC-C (STATE GRID CORP CHINA)。观察比较融入网络位置相似性前后两次的排序结果,可以发现对于企业KEPC-C的合作企业排序在融入网络位置相似性之后企业USKK-C与企业SNPC-C的排序发生了变化。结合表5可知,由于企业USKK-C与企业KEPC-C之间的网络位置相似性较高,因此在融入计算网络位置相似性之后,企业USKK-C的推荐排序得到了提升,经验证发现在测试集T_2中企业USKK-C与KEPC-C在2020—2021确实存在专利合作关系,且合作产出的成果更多,验证了混合预测算法的准确性。
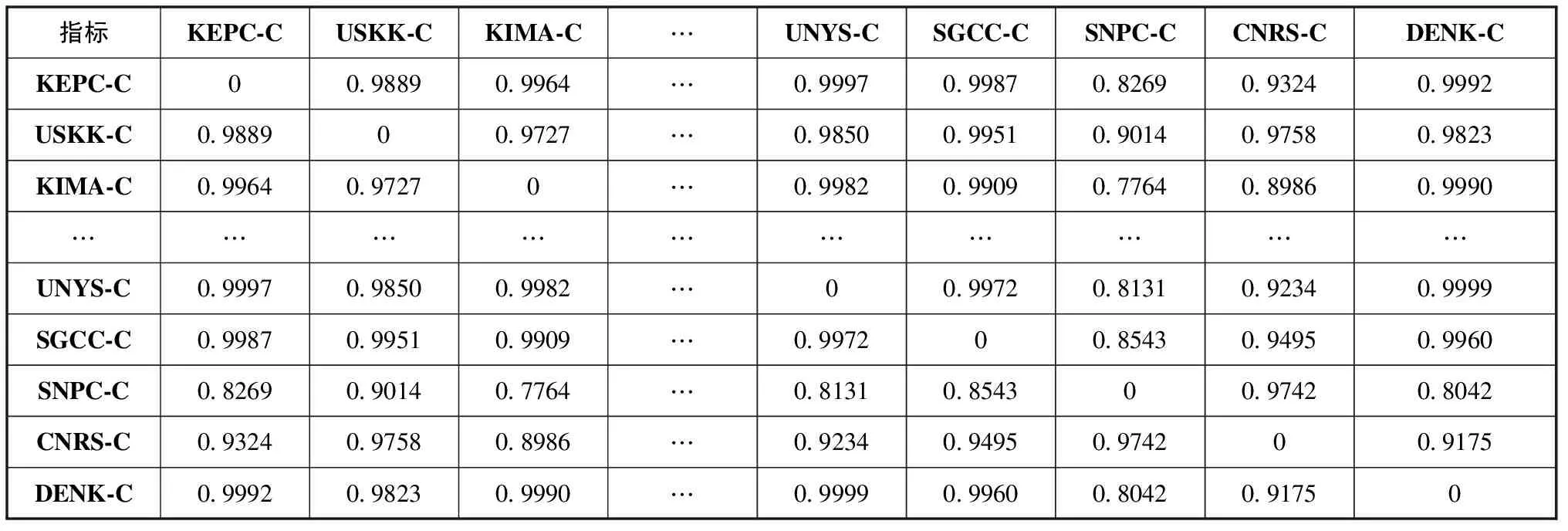
表5 网络位置相似性计算结果 (部分)

表6 融合路径、内容与网络位置的相似性计算结果 (部分)
为了进一步验证混合算法预测的准确性,分别计算路径相似性模型、内容相似性模型、加权模型以及混合模型的AUC指标,结果见表7,表明将多元相似性融合后的混合模型相较于单一的路径相似性模型、内容相似性模型以及简单结合路径与内容相似性的加权模型,具有更加准确的合作关系预测结果。

表7 不同预测模型的AUC指标值
进一步地,以企业KEPC-C为例,使用本文提出的融合模型进行预测,筛选出相似性最高的10个企业作为推荐合作企业列表,能够得到企业KEPC-C的合作企业推荐列表,结果见表8。
表8融合模型给出10个预测合作企业,其中有6家企业在2020—2021年与该企业存在专利合作关系,即基于该融合模型对企业选择合作伙伴进行推荐,具有一定的准确率,能够验证本研究提出的多元融合企业技术创新合作推荐方法是有效的。另外,由表8可知,应用该融合模型的计算结果,对企业KEPC-C进行合作伙伴推荐时,企业SMSU-C的排序为第3名,表明模型计算得到这两个企业之间的合作相似性较高,但在测试集中这两个企业在2020—2021年间并未产生合作关系。进一步分析两个企业的基本信息可以发现,两者皆为相同属地的企业,但是由于所属的行业领域不同并未产生合作,经过本文的相关研究发现两企业之间存在较高的研究合作相似性,可以帮助企业KEPC-C发现其遗漏但合适的合作对象,促进其与企业SMSU-C之间的技术创新合作。
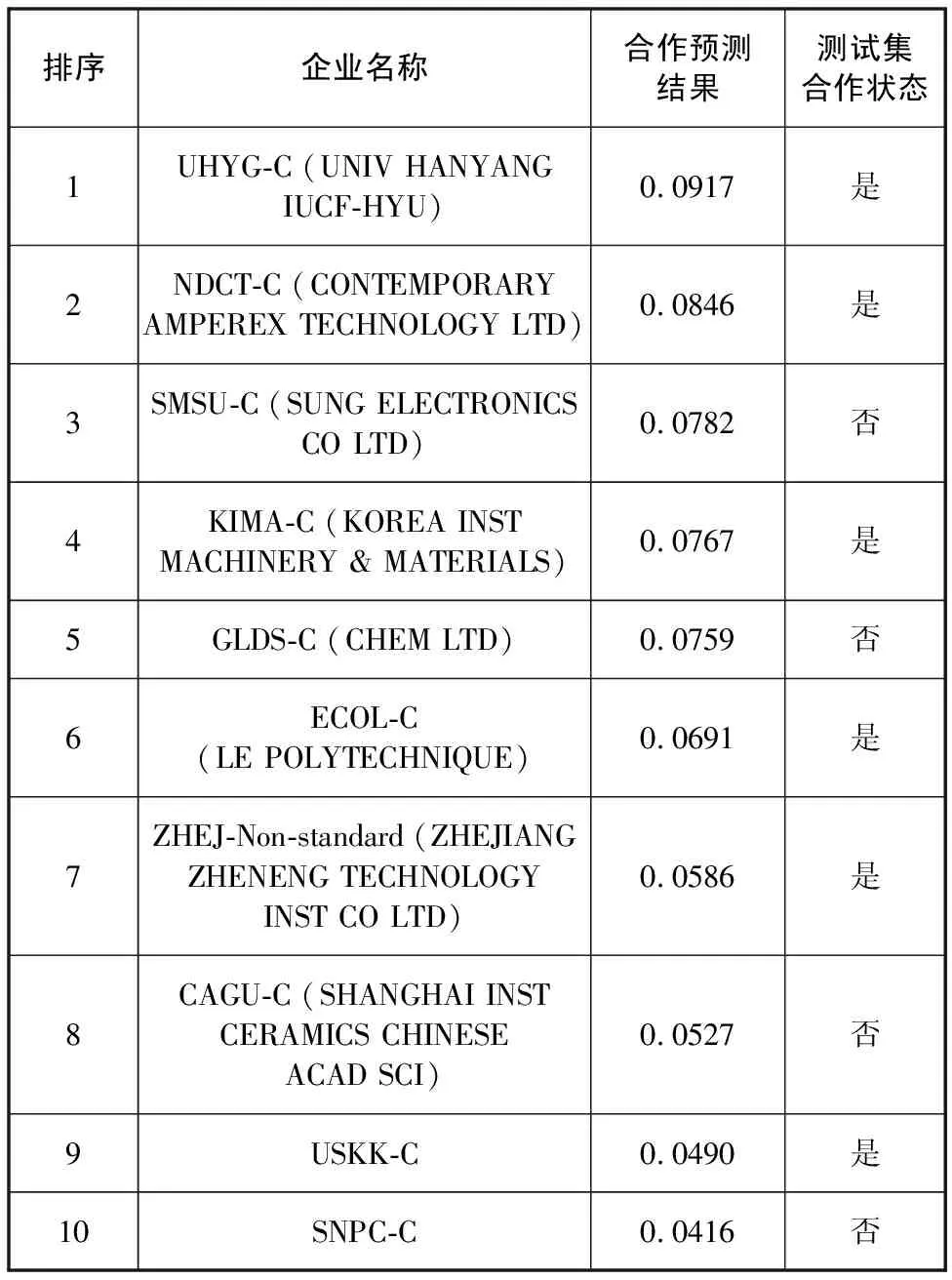
表8 企业KEPC-C合作企业预测排序结果
4 讨论与总结
本研究提出建立一种融合路径、内容与网络位置相似性的混合预测算法,帮助企业挖掘潜在的技术创新合作关系。与单一相似性指标预测算法相比,本研究提出的混合算法从企业专利数据出发,结合不同方向角度研究企业之间的潜在合作关系,在提高算法预测结果精度的同时,使算法更具合理性,对于挖掘因客观条件、知名度、企业规模等限制而可能错失的合作关系效果更佳。通过对石墨烯行业内企业合作的预测可以验证本研究提出的模型在挖掘潜在技术合作关系时具备以下优势。
(1)本文提出的预测方法基于专利数据挖掘,不受地理位置限制,更有助于避免因地理位置较远而忽略的合作可能性。以企业USKK-C与企业UNYS-C为例,二者在地理位置上相距甚远,通过本文提出的融合预测方法得出两企业之间的潜在合作相似度较高,且在测试集数据中显示这两家企业在2020—2021年确实产生了专利合作。由此可见,本方法有助于企业突破地理局限,在更广泛的区域内选择合适的合作伙伴,并借助数字化的知识流动媒介,合作进行技术创新。
(2)本文提出的预测方法有助于挖掘企业细小的技术领域,从而促进技术创新合作。对于两个存在较高合作相似度的企业,可能因其中的某个企业主营业务规模较大,而被忽略了其他业务的技术先进性,错过合作的机会。例如,企业KEPC-C与企业SMSU-C之间的合作关系,类似地归于这类情况。由于SMSU-C (三星)的主营业务规模过大,掩盖了它在其他领域的一些先进技术。通过本文提出的融合预测方法进行预测挖掘,能够发现它在一些细小领域的先进技术,这为技术创新合作提供了可能性。
(3)本文提出的预测方法融合了位置相似度,更强调合作企业 “合适”的程度,有助于促进中小企业之间的合作。无论哪个领域,位于头部的知名企业都只是少数,对于非巨头企业而言,选择合适的合作伙伴更加重要。现有技术市场存在一些专业性强,但规模不大的企业,能够作为其他同类型企业的最优合作伙伴,通过相互间的知识融合从而提高创新效率。虽然本文选择专利数量较多的企业进行研究,但是所构建的融合预测方法能够推广到各个行业领域内不同规模的企业,从而帮助各类型企业选择与自身匹配的合作企业。
另外,受限于数据获取难度,本研究提出的合作挖掘模型仍存在一些不足。例如,除专利合作外,企业可以通过贸易、人才流动等行为产生关联,由此形成隐形的知识流动以促进技术创新,且基于上述关联所增加的信任更利于形成合作意向,通过构建更为丰富的关联网络,能够进一步挖掘可能的技术合作关系。现有算法在石墨烯行业的有效性得到了验证,石墨烯行业属于技术密集型行业,技术创新成果丰富,而对于技术创新成果较少的行业,如何应用小样本预测合作机会,是未来可以进一步研究的方向。
