复杂人机共融场景中人体姿态识别及避碰策略综述
2024-03-20高春艳梁彧浩李满宏张明路孙立新
高春艳, 梁彧浩, 李满宏, 张明路, 孙立新
(河北工业大学机械工程学院, 天津 300401)
人机协作(Human-robot collaboration, HRC)是指人与机器人共享协作工作空间,在同一目标任务下,进行协调或同步地联合活动作业[1]。随着人工智能和自动化技术的不断发展,人机协作广泛应用在制造业、医疗、服务[2-4]等领域。
人机协作共融将人类强大的认知推理和决策能力以及机器人高精度特性和高效的计算能力结合起来,实现复杂条件下的协同工作[5]。对于一些不可预知或动态的因素,人机协作共融也能够使机器人精确识别人类意图并适应障碍,从而更好地完成作业任务。
自然、精确的人机交互是人机协作的基础[6]。针对各种复杂的环境,机器人需要理解人类的意图,识别协作环境中人体的运动情况,并采用适当的避让策略来防止碰撞,并在发生意外或不可避免的撞击时最大限度地减少对人的伤害[7]。因此,机器人的识别预测能力成为当下人机协作环境中的研究重点。然而,人机协作过程中仍存在环境光照变化,目标背景遮挡,人或机器人产生相对运动等复杂情况,现针对人机共融工作中机器人对于人的体态姿势识别技术以及避碰策略进行对比分析,并基于深度学习的方法及应用进行展望。
1 基于机器视觉的姿态识别
在人机共融场景中,机器视觉系统能使机器人对协作场景有全面的了解,便于后续机器人的决策和主动规划[8]。
1.1 机器人视觉系统构成
人体姿态识别通过图像采集系统进行数据采集,采用视觉传感器收集图像信息。协作环境下,单目相机由于视角限制会影响检测结果的鲁棒性,且对遮挡、光照变化较敏感,通过引入深度学习方法,可被应用到3D姿态识别领域[9-10];立体相机[11]可采集和呈现立体图像,鲁棒性较强,但特征匹配难度高,标定比较困难;深度相机可输出3D深度信息,校准和照明条件对识别结果影响较小;TOF和Kinect两种包含彩色和深度传感器的RGB-D相机,可在复杂场景下实现稳定的识别效果。表1为各视觉系统传感器的特征对比。

表1 各视觉系统传感器特征对比
针对复杂协作场景的传感器应用,Antão等[12]采用ZED立体相机捕获3D协作空间的点云数据,用于后续未标记的体素网格的创建,使用红绿蓝(red-green-blue,RGB)图像和人机关节位置信息,标记体素网格中的关键元素,在复杂背景下模拟的协作区域姿态识别效果较好。文献[13]采用粒子滤波器并引入长短期记忆网络(long short-term memory, LSTM),通过融合多个从深度相机中提取的二维关节位置来估计3D人体姿势,结果表明在遮挡、不受约束的照明和运动模糊情况下均可增强协作场景的姿态识别性能。RGB-D相机可通过深度与颜色信息辅助识别阴影的形状与位置,并判断物体间的遮挡关系,具有较强的环境适应性与实时性。Hu等[15]利用Kinect相机获取人体关节信息,采用偏圆定界方法解决了人体关节偏移现象,从而实现运动情况下对人体关节点的精确估计。
1.2 关键特征及其识别
协作场景的图像处理过程中,机器人通过分析图像或视频中的像素信息来精准识别人体部分关键特征,从而实现姿态识别。
1.2.1 表观特征
表观特征主要包括颜色、轮廓等视觉属性,系统分析颜色时通过颜色直方图或颜色矩来提取特征。在复杂的协作环境中,视觉系统对基于颜色的识别与分析结果易受到光照、阴影和肤色的影响而产生畸变。基于此,Al Naser等[17]开发一种结合Otsu方法和YCrCb色彩空间的新型算法,实现热信息与颜色信息的数据融合来进行人体部位检测,与传统OpenPose算法相比识别速度快5倍,且可减少光照及人体肤色的影响。Zabalza等[18]开发了一种基于低成本相机和基于色调、饱和度、亮度(hue-saturation-value, HSV)空间颜色检测的机器视觉模块,该模块可使机器人意识到变化的环境并精确检测障碍物,提升了光照以及移动情况下的识别精度。
1.2.2 局部特征
局部特征相较表观特征对光线并不敏感,可通过预处理和归一化的操作提升识别的质量。尺度不变换特征(scale-invariant feature transform, SIFT)能在不同大小和旋转方向的图像中识别关键点并提取局部特征[19],抗遮挡干扰情况较好;ORB(oriented FAST and rotated BRIEF)将FAST(features from accelerated segment test)的高速特征检测及BRIEF(binary robust independent elementary features)的高效特征描述结合起来,相比SIFT在计算速度上有更快的优势;方向梯度直方图(histogram of oriented gradients, HOG)基于提取图像中不同区域的梯度直方图,并将其作为特征向量进行人体姿态识别,对光照和视角变化具有一定的不变性。在遮挡条件下的协作环境中, Vinay等[20]提出一种基于ORB的交互式人脸识别框架,引入考虑遮挡等非线性因素的核主成分分析不相关分量,识别精度提高了5%。巫晓康等[21]提出一种采用HOG提取特征矩阵的骨架旋转投影描述子(rotational and projective skeleton signature,RPSS)来识别人体骨架,该方法在动作序列的时空信息不充分的情况下,识别鲁棒性和实时性均较好。
1.2.3 骨骼特征
复杂场景的完整人体模型通常不易识别,而骨骼特征通过定量描述关节位置和角度,可提取骨骼的空间与动态信息,免受照明和背景干扰且准确性高[22]。
骨骼特征提取采用骨骼几何信息构成分类特征,通过骨骼识别算法提取人体15个骨骼关键点坐标信息,如图1所示。

1为头;2为左肩;3为脖子;4为右肩;5为左肘;6为躯干;7为右肘;8为左手;9为左臀;10为右臀;11为右手;12为左膝;13为右膝;14为左脚;15为右脚
设bi=(x,y,z)为第i个关节点三维坐标i=1,2,…,15,则bi,bj间的距离δ(bi,bj)计算公式为
δ(bi,bj)=
(1)
避免异构需计算手肘肩膀及脚膝盖臀部所构成的角度θi,公式为
(2)
由式(1)和式(2)即可识别关节间距离与角度信息,由此类信息共同构成所需特征。文献[23]采用骨骼识别算法,从RGB图像中恢复3D人体网格,通过关节回归模块估计单目视频中的三维人体骨骼信息,解决了人体在环境中的姿势和特征差异以及人体的部分遮挡问题。文献[24]提出一种基于姿态运动的时空融合图卷积网络,引入基于局部姿态运动的时间注意力模块进行骨骼信息提取,与语音交互相比准确性较高且在时间域内可高效抑制运动扰动信息。
1.2.4 运动特征
在移动情况下的协作环境,对运动特征的检测识别也可保障人类安全。运动特征领域的典型研究方法包括差像法和光流法,可用于提取运动信息。差像法通过相邻帧间的像素值进行差分运算来检测运动,适用于背景变化剧烈的情况。而光流法则通过分析邻域像素之间的亮度变化,来估计每个像素的运动向量,适用于平缓运动[25]。
文献[26]提出一种结合强特征提取器、注意力轮廓及中间特征的改进光流法,在交互系统中可实现速度精度权衡,能更好地理解运动并精确地表示轮廓。Agarwal等[27]利用Vanilla-LSTM和Social-LSTM时间深度神经网络检测人类运动轨迹,引入密集光流法,用以稳定来自数据集中的输入注释并减少相机运动的影响。
1.3 识别算法
协作环境中,视觉识别算法对从原始传感器获取的数据即人体肢体和姿态等进行识别。姿态识别算法在目标检测基础上,通过对目标位置信息进行分析和推理,推断出目标姿态。
应用在协作领域的OpenPose[28-29]、Media-pipe[30-31]、DeepPose[32-33]、AlphaPose[34]等姿态识别算法可识别出人体关键点的坐标信息。其中Open-Pose和Mediapipe属于自底向上的方法,需要检测图像关键点,通过组合来形成人体姿态,可能会因为遮挡、相同目标距离较近等情况造成关键点的误连接。DeepPose和AlphaPose是自顶向下的方法,通过神经网络监测到人体实例,再根据关键点检测算法检测人体关节点,可以减少误检测与冗余检测的情况。文献[35]表明多目标协作环境中,自顶向下的关键点检测方法相较自底向上方法更适合近距离检测。表2为几种人体姿态识别算法的特征对比。
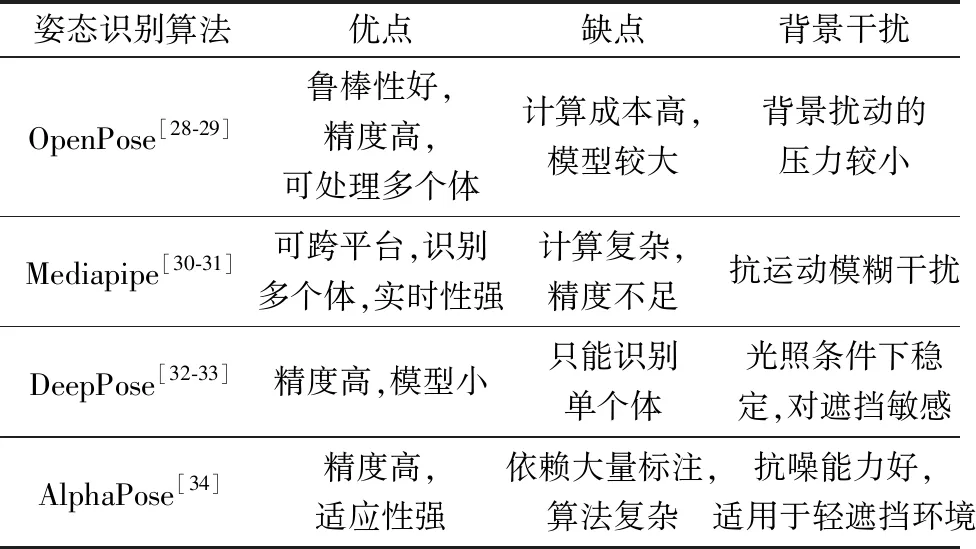
表2 人体姿态识别算法特征对比
OpenPose的鲁棒性与精准度优良,适用于单人和多人环境及各类背景复杂的体态识别。Gao等[36]基于改进OpenPose算法,对采用双流注意模型分割的手部图像进行识别,通过加权融合方法结合骨架数据,实现复杂环境的姿势动态感知。文献[37]提出一种采用OpenPose进行关键点提取和基于深度卷积神经网络(DCNN)分类的新型KPE-DCNN模型,用于遮挡和移动等复杂协作场景的姿态识别,与CNN等标准算法相比提高了最少8.87%的识别精度。文献[38]提出的Lightweight OpenPose轻量级方法,相较于 OpenPose 所占资源更少,适用于对硬件设备要求不高的场景。
2 基于机器学习的避碰策略
机器人在协作过程中需根据先前行为信息进行分类并预测人体运动轨迹,计算最佳避免碰撞路径,以保证人体安全。预测运动轨迹的方法包括监督学习、无监督学习和深度学习。
2.1 传统机器学习算法
2.1.1 监督学习方式
监督学习可通过建模人体动作序列并预测运动,具有高准确性及快速决策的优势,常用于协作环境中的人体运动估计。几种典型分类模型:隐马尔可夫模型(hidden Markov model, HMM)基于时间序列数据,可将获取的行为数据特征向量化并利用向量序列来训练,在对动作序列建模和分类方面效果较好[39];马尔可夫模型(Markov model, MM)相较HMM主要考虑状态之间的转移概率,对协作环境中的动态运动场景具有适应性[40];支持向量机(support vector machine, SVM)通过将数据映射到高维空间,寻找最大间隔超平面来进行分类实现运动预测[41];动态贝叶斯网络(dynamic Bayesian network, DBN)可对变量间的概率关系进行建模和预测[42],与SVM融合可适当降低系统复杂性并提高预测准确性。HMM对光照及遮挡影响较敏感,而MM、SVM和DBN对这类因素具有不同程度的适应能力,更适合复杂环境下的协作任务。
在运动下的人机协作场景中,Grigore等[43]从由人类工人组成的训练集中学习一个HMM,使用其在任务执行期间对有关人类行为模式的信息进行编码,能够隐式灵活地表示任务相关结构,并辅助预测机器人的运动。Wang等[44]将基于注意机制的扩展马尔可夫迁移特征集成到传统的MM中,通过解决人体运动的长期相关性和上下文依赖的问题,实现高性能的运动预测,经评估表明,所提出的新型算法模型优于传统算法6.6%以上。董宁等[45]提出一种基于DBN的人体动作识别方法,通过提取人体的关节点并计算躯干角度,使用后验概率动态调整SVM分类器和朴素贝叶斯分类器权重,使其互为补充来增加识别率,通过与单分类器的对比试验验证了对人体的运动预测。
2.1.2 无监督学习方式
监督学习方法存在两大局限性:机器人在碰撞数据收集过程中可能会损坏;只有作为碰撞学习的场景才能被鲁棒检测[46]。而无监督学习能自动发现数据间的关联性并识别潜在特征,适用于处理未知类别训练样本的情况。
高斯混合模型(Gaussian mixture model, GMM)可被用来对人体的关键点进行建模和分析,建立人体动作数据集,运用回归方式预测人体动作[47]。设GMM由m个高斯模型组成,每个高斯模型为一个分量,则GMM的概率密度函数为

(3)
式(3)中:x为D维特征向量,p(x|m)=N(x|μm,Σm)为第m个高斯模型的概率密度函数,可以看作是第m个高斯模型选择后产生的x概率,表达式为
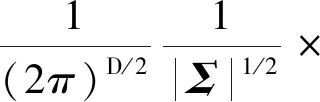
(4)

Luo等[49]提出了一个由两层的GMM库组成的,用于无监督在线人体运动识别和预测的框架,如图2所示。该框架可以实时生成模型,能适应新的人与动作,预测准确率达到95.3%。康杰等[50-51]提出一种基于ROS的人体姿态的实时运动估计框架,利用GMM算法和期望最大化算法,根据采集到的坐标点进行聚类估计,并为每个类别添加标签来获取关节的顺序,该方法能够准确描述人体运动并做出预测。

Gn为库中GMM;Xj为轨迹
无监督学习不需要大规模的监督数据集,也不需要传统的训练过程和手工标注,就可以构建人体运动模型并进行预测。但是在相对复杂的协作环境,采用无监督学习模型的分类结果鲁棒性较低,相比监督学习有指导性和反馈机制的优势,其准确性和效率还需提高。
2.2 深度学习方法
深度学习方法是一种端到端的学习方法,不需要人工干预,而是依靠算法自动提取特征。可直接从原始输入数据开始,通过层次化的神经网络结构自动完成特征提取和模型学习[52]。深度学习方法由神经网络发展而来,神经网络在数据学习过程中能够辨识样本数据内部结构特性与隐含规则,具有分析处理相似性数据,表达非线性函数关系并找到系统输入输出关系的能力。
在协作环境下的预测领域,深度学习常用网络模型有用于处理视觉信息的深度卷积神经网络,以及用于特征学习的堆栈式自编码网络和深度置信网络。郑涵等[53]通过改进的Faster R-CNN网络进行手部及其关键点检测,使用MANO(hand model with articulated and non-rigid deformations)模型获取手部关键点的三维坐标,最终得到手部的三维位姿估计结果,该方法能够解决手部自遮挡和尺度问题,并提高检测结果的准确性。针对运动的复杂情况,陈鹏展等[54]提出一种融合骨骼耦合的预测方法,采用增加原始输出处理层的改进LSTM网络模型框架,通过拉普拉斯评分算法和动态聚类算法实现基于骨骼耦合性的约束条件来减小关键点轨迹预测误差,装配协作场景中的准确率达80%以上。Wang等[55]提出了一个基于卷积神经网络和LSTM架构的手部运动预测系统,系统结构如图3所示,引入优化的机器人轨迹规划算法,利用视觉模块的预测进行复杂协作环境的运动轨迹优化计算。
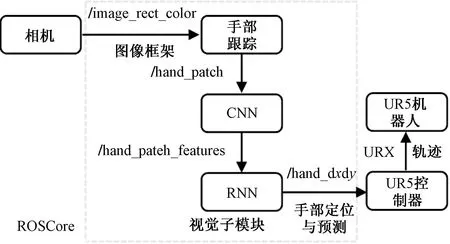
图3 安全协作系统结构[56]
为提高协作避碰能力与安全性,Choi等[56]提出一种基于扩展现实的人机互助应用程序来跟踪人体骨骼和同步机器人,采用基于深度学习的分割和迭代最近点匹配算法实时测量人类操作员与机器人之间的安全距离。Zheng等[57]提出一种基于编码器-解码器网络的人手运动预测模型,融合模型预测控制框架,能够基于人体运动轨迹来规划共享工作空间中的机器人无碰撞轨迹。
3 总结与展望
基于以上综述,分析了部分方法中可能存在的不足,并做出总结与展望,具体如下。
(1)人机协作中,机器人需高度关注人类的识别感知。然而,目前的方法仅能通过可穿戴设备[58]对人体的局部进行感知,或者仅能通过视觉检测和骨骼识别来确定人体的粗略位置与建模,而不是准确的3D几何建模。为应对复杂协作环境,计算机视觉领域中出现一种密集人体姿势建模的趋势,包括精密的身体姿态建模[59]和手部姿势建模,被用于更精细的人体感知来应对变化的环境,提高姿态估计精度。
(2)人机协同作业面临环境复杂,视觉传感器在协作过程中可能会存在延迟问题,而仅使用单一的视觉传感器已不能满足工作需求。因此,可采用触觉、听觉等多传感器融合的方式,赋予机器人更立体的感知能力。除人体动作外,机器人对多模态信息的识别也影响着人体姿态预测,有学者采用肌电信号、脑电信号[60]融合等方式使机器人预测人类意图,以支持更主动的人机协作。
4 结论
人机协作的安全性和实时性是人工智能行业的重要问题,基于此探讨了复杂协作环境的姿态识别与避碰策略。相较传统方法,基于深度学习的人体姿态识别与预测方法拥有强大的学习能力、较高的准确性、良好的实时性与适应性,使其能够有效应对复杂动态人机共融环境的变化和不确定性,为实时交互提供可靠帮助,在复杂协作场景中的姿态预测领域有较大的学术潜力和研究价值。
